EM 算法(Expectation-Maximization)是处理隐变量模型的通用框架——当数据含有未观测的隐变量时,直接最大化似然困难,EM 通过迭代"期望"和"最大化"两步,保证似然单调上升直至收敛。从高斯混合模型的参数估计到图像分割、语音识别,EM 算法展现了强大的理论美感与实用价值。Jensen 不等式保证了算法的收敛性,ELBO(证据下界)提供了优化目标,而 GMM 则是 EM 算法最经典的应用场景。


隐变量与不完全数据
问题背景
完全数据:观测数据 = {_1, , _N}
不完全数据:只观测
目标:最大化不完全数据对数似然
困难:对数内有求和(或积分),难以直接优化。
示例:高斯混合模型
- 观测:数据点
- 隐变量:所属成分
- 似然:
对数内的求和使直接求导困难。
Jensen 不等式与对数似然下界
Jensen 不等式:对于凹函数$f
对于
应用到对数似然:引入任意分布
ELBO (Evidence Lower Bound):
KL 散度与紧界条件
改写 ELBO:
其中 KL 散度:
紧界条件:当
EM 算法推导

算法框架
初始化:参数
循环(第
E 步( Expectation):固定
计算 Q 函数:
M 步(Maximization):固定
终止:收敛(对数似然或参数变化小于阈值)
Q 函数的意义
解释: Q 函数是完全数据对数似然在隐变量后验分布下的期望。
收敛性证明
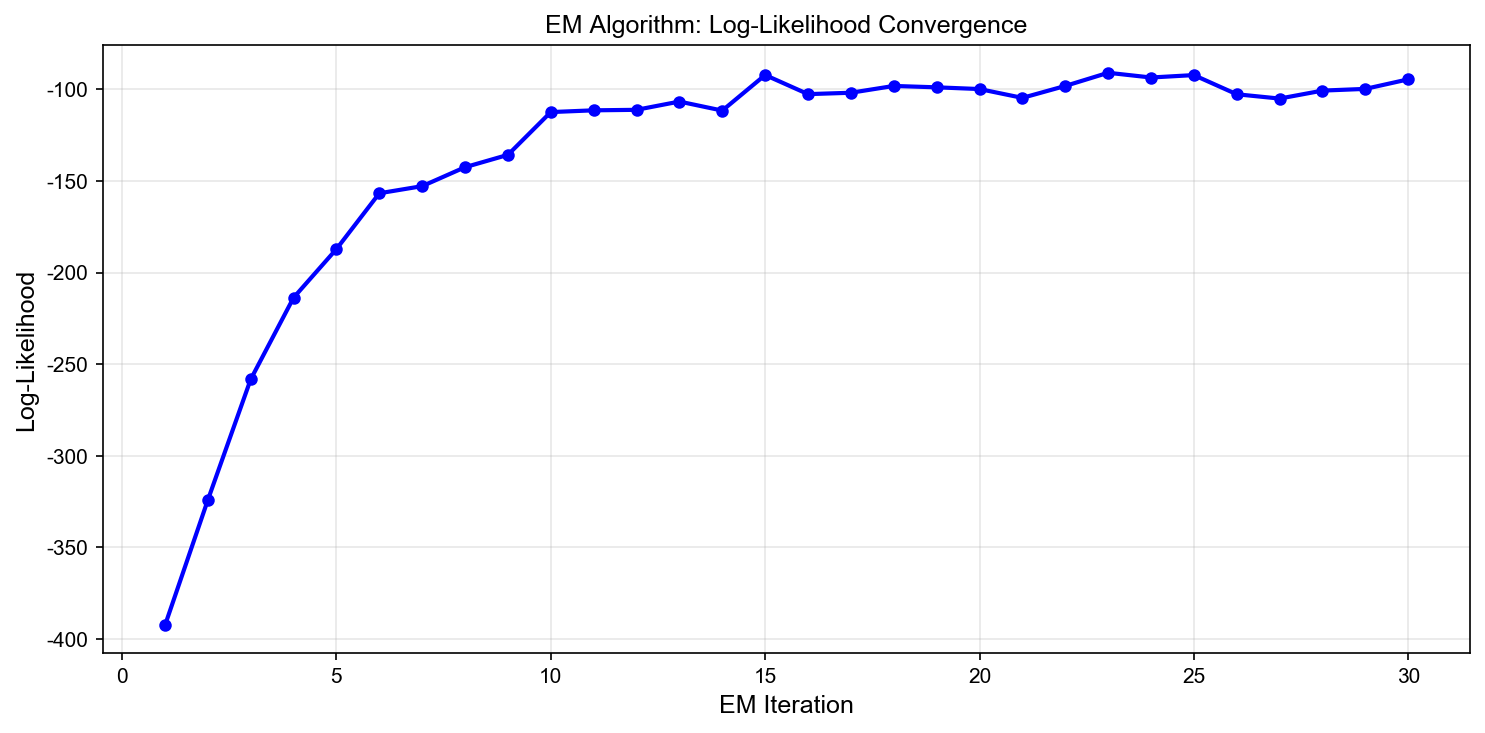
定理:EM 算法保证对数似然单调递增:
证明:
其中
推论:EM 算法收敛到对数似然的(局部)极大值或鞍点。
高斯混合模型(GMM)
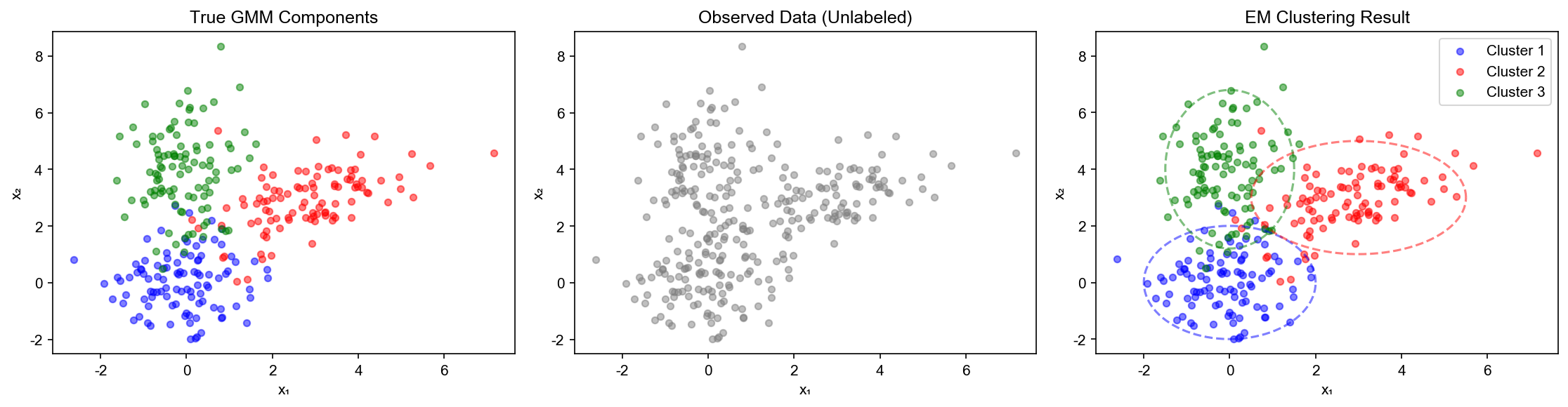
模型定义
生成过程:
- 选择成分
,其中 是成分 的先验概率 - 从成分
生成数据:
联合分布:
边缘分布(观测数据的似然):
参数:
约束:
EM 算法 for GMM
E 步:计算责任度 (responsibility):
物理意义:样本
M 步:更新参数。
Q 函数:
更新
其中
更新
加权平均:样本
更新
加权协方差。
GMM 的几何解释
K-means vs GMM: -
K-means:硬分配(
GMM 的优势: - 允许重叠簇 - 不同簇不同形状(协方差) - 提供不确定性估计
初始化策略
EM 算法对初始值敏感。常用策略:
K-means 初始化:用 K-means 结果初始化
, , 随机初始化:从数据中随机选择
个点作为 多次重启:运行多次 EM,选择对数似然最大的结果
GMM 的应用
密度估计
目标:学习数据分布
应用:异常检测,生成新样本,概率预测。
聚类分析
硬聚类:
软聚类:保留
BIC 模型选择:选择成分数
其中
图像分割
问题:将图像像素聚类为
特征:RGB 颜色,位置坐标,纹理特征。
GMM 模型:每个成分对应一个区域。
分割结果:像素
完整实现
1 | import numpy as np |
Q&A 精选
Q1:EM 算法为什么叫期望最大化?
A:E 步计算 Q 函数(完全数据对数似然的期望),M 步最大化Q 函数。名字直接描述算法步骤。
Q2:EM 算法会收敛到全局最优吗?
A:不保证。 EM 保证对数似然单调上升,但可能收敛到局部最优或鞍点。解决方法: - 多次随机初始化 - 更好的初始化(K-means) - 结合其他优化算法(如梯度下降)
Q3:如何选择 GMM 的成分数 K?
A:模型选择准则: - BIC:
通常选择 BIC 最大的
Q4:GMM 与 K-means 的关系?
A:K-means 是 GMM 的特殊情况: - 所有协方差
GMM 是 K-means 的软化和推广。
Q5:EM 算法能并行化吗?
A:E 步天然并行(每个样本独立计算
Q6:协方差矩阵奇异怎么办?
A:常见原因:数据维度高,某成分样本少。解决方法: - 正则化:
Q7:EM 算法的变种有哪些?
A: - 增量 EM:在线学习,逐批更新 - 随机 EM:每次迭代随机采样子集 - 变分 EM:E 步用变分推断近似后验 - 广义 EM:M 步不完全优化(如梯度上升几步)
Q8:GMM 能处理高维数据吗?
A:高维困难(维度灾难): - 协方差参数
解决方法: - 对角协方差(假设特征独立) - 因子分析(低秩协方差) - 特征选择/降维
Q9:如何可视化高维 GMM?
A: - PCA 降维:投影到前 2-3 个主成分 -
t-SNE:非线性降维 -
责任度热图:样本×成分的
Q10:EM 算法在其他模型中的应用?
A: - 隐马尔可夫模型:Baum-Welch 算法 - 主题模型:LDA 的变分 EM - 缺失数据插补:EM 迭代估计缺失值 - 混合专家模型:门控网络+专家网络
EM 是处理隐变量的通用框架。
✏️ 练习题与解答
练习 1:E步计算
题目:GMM两分量,
练习 2:M步更新
题目:3个样本
练习 3:EM收敛性
题目:EM算法保证收敛到什么? 解答:局部最优(或鞍点)。EM保证似然单调不减,但不保证全局最优。多次随机初始化可提高找到好解的概率。
练习 4:GMM vs K-means
题目:GMM和K-means区别? 解答:K-means硬分配,GMM软分配(概率)。GMM建模簇形状(协方差),K-means假设球形簇。
练习 5:缺失数据场景
题目:数据
参考文献
- Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society: Series B, 39(1), 1-22.
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer. [Chapter 9: Mixture Models and EM]
- Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT Press. [Chapter 11: Mixture Models and EM]
- McLachlan, G., & Krishnan, T. (2007). The EM Algorithm and Extensions (2nd ed.). Wiley.
- Neal, R. M., & Hinton, G. E. (1998). A view of the EM algorithm that justifies incremental, sparse, and other variants. Learning in Graphical Models, 89, 355-368.
EM 算法以其优雅的数学结构和广泛的实用价值,成为现代机器学习的基石之一。从高斯混合模型的参数估计到隐马尔可夫模型的训练,从缺失数据处理到半监督学习,EM 算法展现了"化繁为简"的智慧——将困难的不完全数据优化问题分解为简单的"期望"和"最大化"两步。理解 EM 算法,不仅是掌握经典算法,更是领悟概率推断与优化的深刻联系——这一思想贯穿变分推断、蒙特卡洛方法等现代贝叶斯机器学习技术。
- 本文标题:机器学习数学推导(十三) EM 算法与 GMM
- 本文作者:Chen Kai
- 创建时间:2021-11-05 09:45:00
- 本文链接:https://www.chenk.top/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%95%B0%E5%AD%A6%E6%8E%A8%E5%AF%BC%EF%BC%88%E5%8D%81%E4%B8%89%EF%BC%89EM%E7%AE%97%E6%B3%95%E4%B8%8EGMM/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!