降维(Dimensionality
Reduction)是机器学习中处理高维数据的核心技术——当特征维度达到数千甚至数百万时,维度灾难使得学习变得困难,降维通过保留数据的主要结构将其投影到低维空间。从
PCA 的特征分解到 LDA 的类间分离,从核技巧的非线性映射到 t-SNE
的流形学习,降维算法为数据可视化、特征提取与预处理提供了强大工具。PCA
有最大方差和最小重构误差两种等价视角,核 PCA
通过隐式映射实现非线性降维,LDA 用 Fisher 准则最大化类间距离,t-SNE
则通过概率分布匹配保持局部邻域结构。
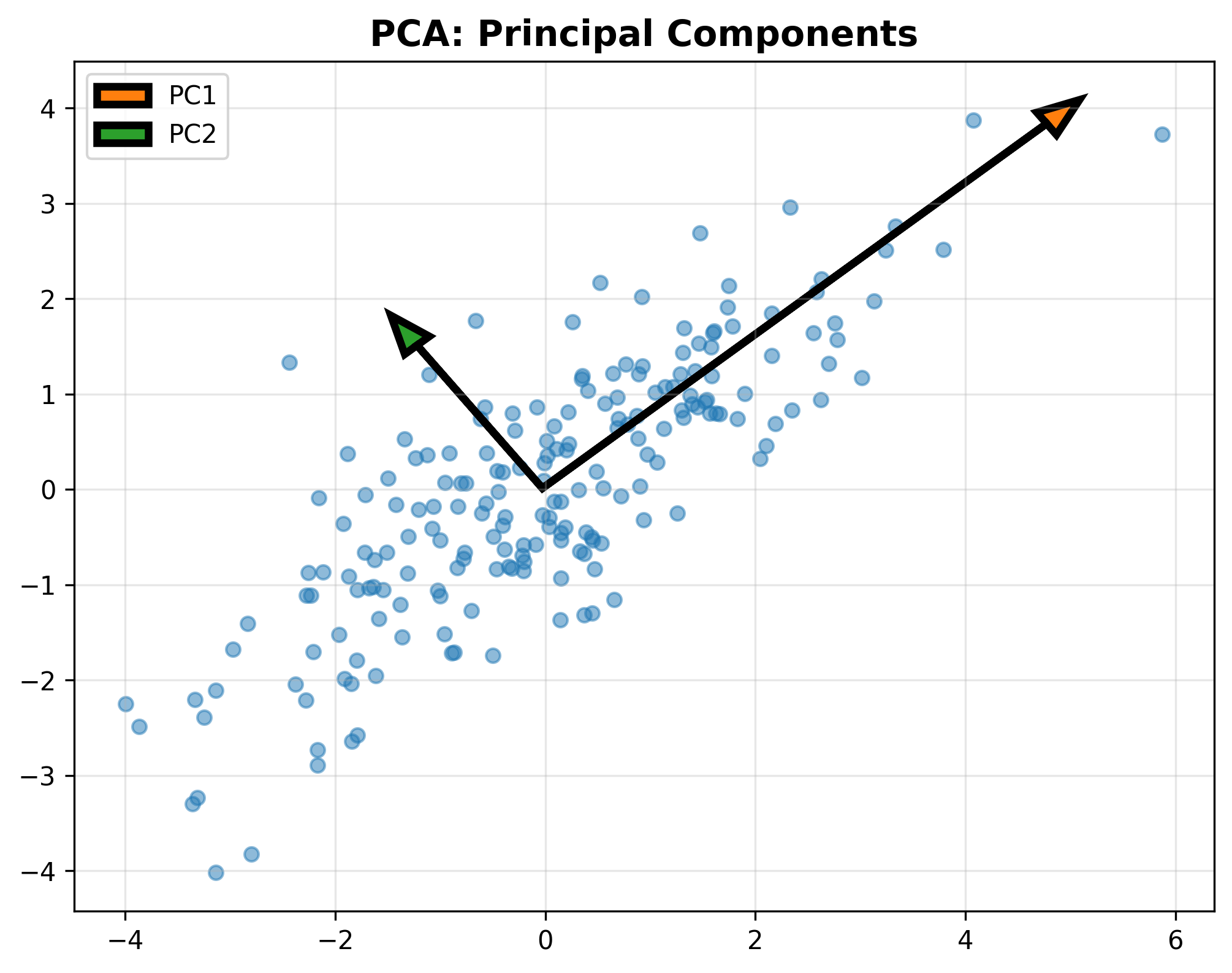
PCA Principal Components
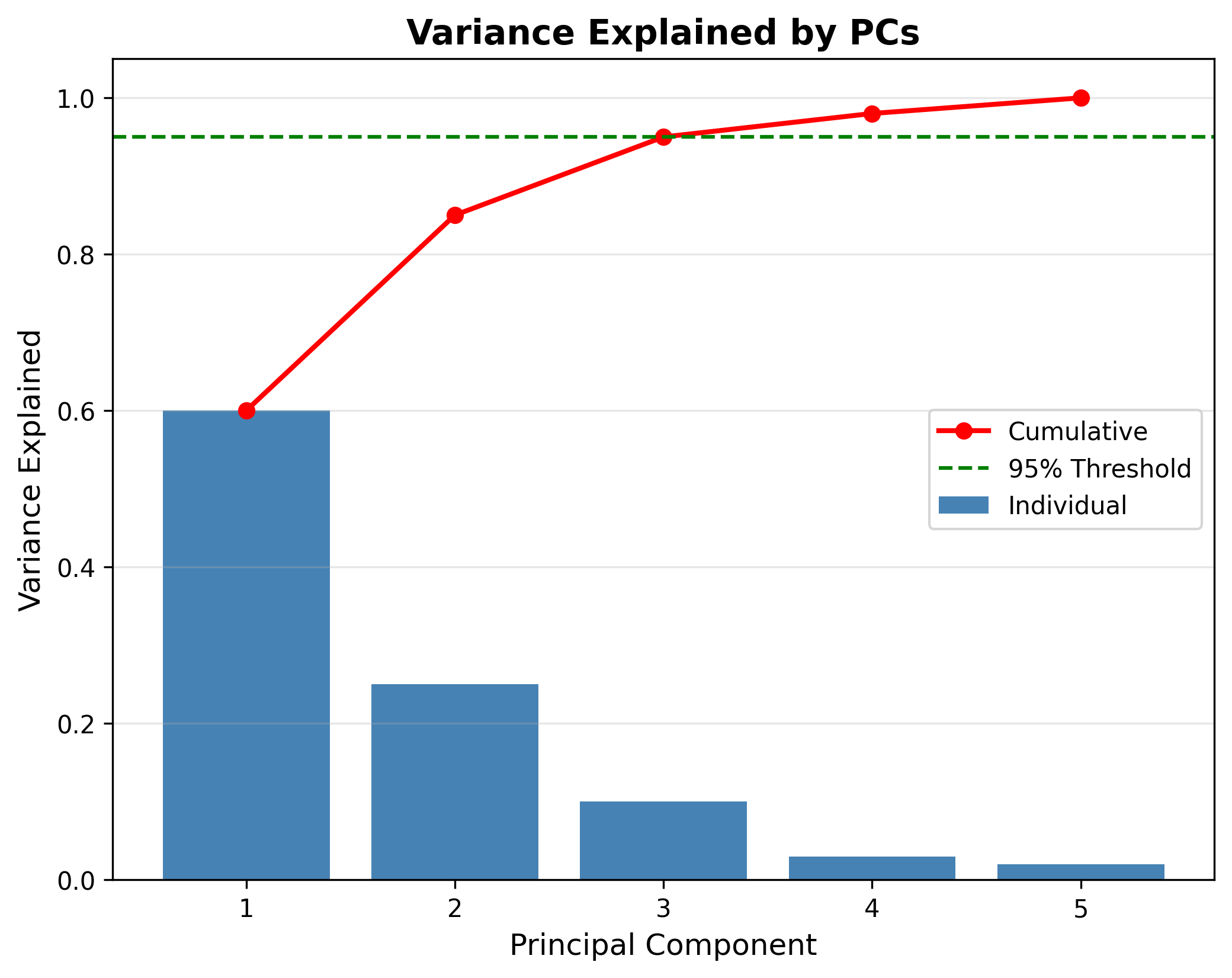
Variance Explained
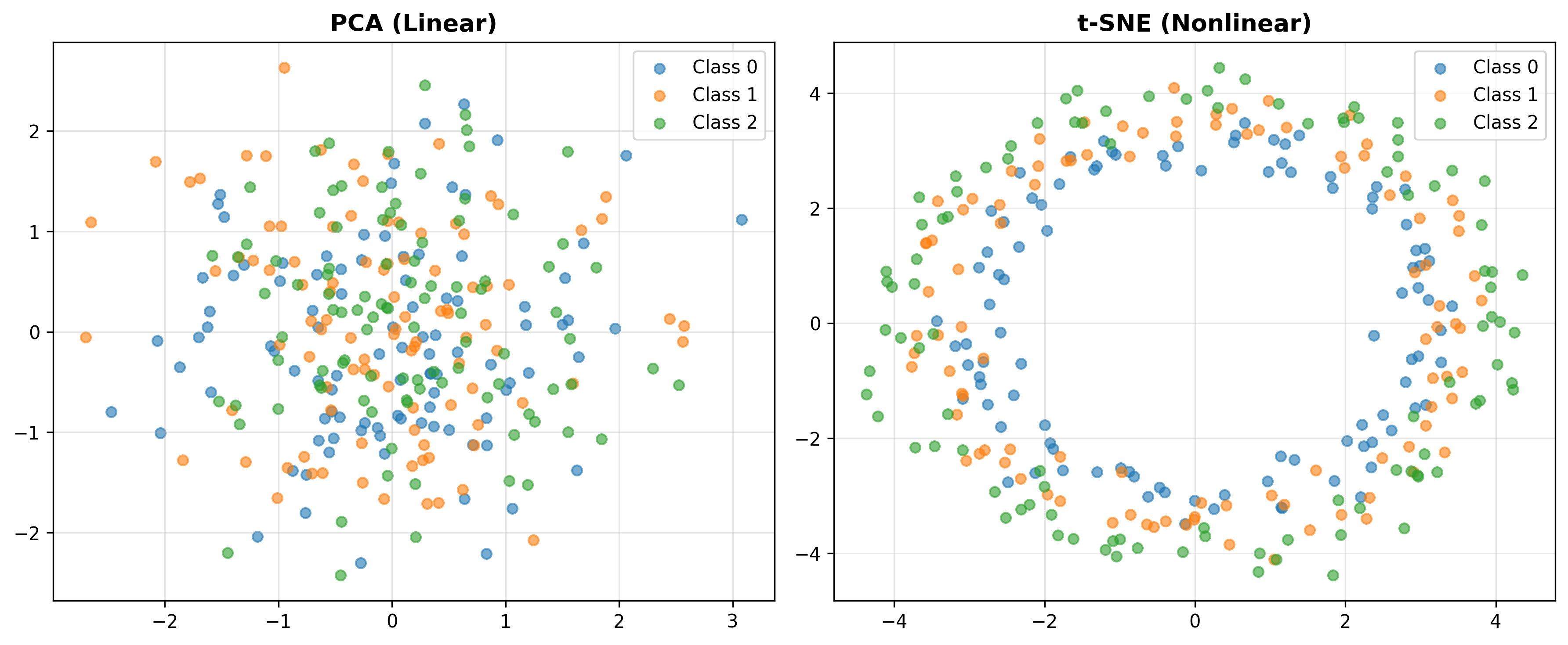
t-SNE vs PCA
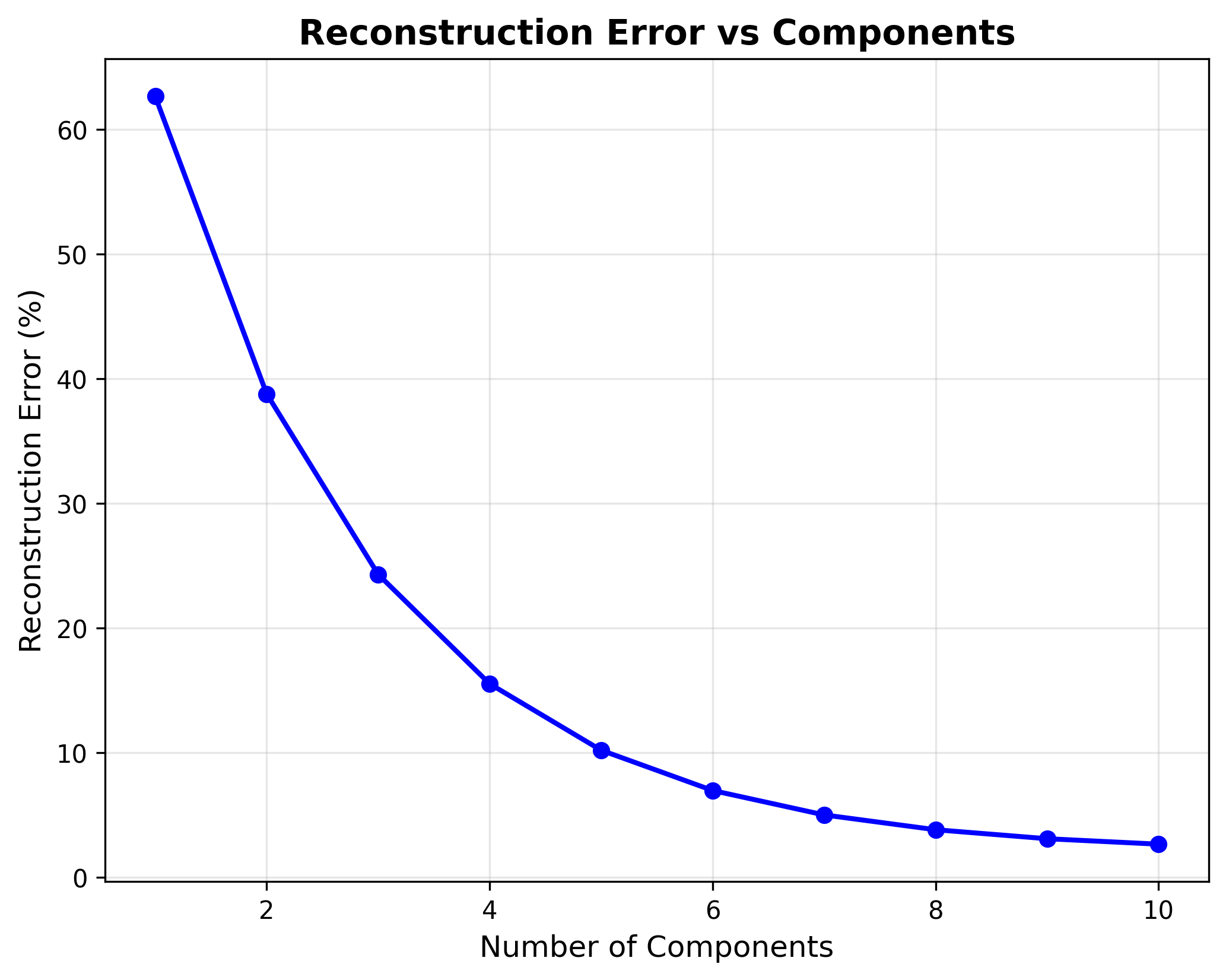
Reconstruction Error
Kernel PCA
维度灾难与降维的必要性
高维空间的反直觉现象
维度灾难 (Curse of
Dimensionality):数据维度增加时,样本变得稀疏,算法性能急剧下降
现象 1:体积集中
当
现象 2:距离集中
高维空间中,随机点之间的距离趋于相等:
导致最近邻、聚类等算法失效
降维的两大目标
1. 特征提取 :去除冗余特征,保留重要信息
2. 数据可视化 :投影到 2D/3D 空间
降维方法分类
线性降维 :
PCA:无监督,最大方差/最小重构误差
LDA:有监督,最大类间距离
ICA:独立成分分析
FA:因子分析
非线性降维 :
核 PCA:核技巧扩展 PCA
Isomap:保持测地线距离
LLE:局部线性嵌入
t-SNE:保持局部概率分布
PCA:最大方差视角
问题形式化
数据 :
中心化 :
目标 :找到投影方向
投影值 :
方差 :
注意中心化后
第一主成分推导
目标函数 :
改写为矩阵形式 :
其中协方差矩阵 :
优化问题 :
拉格朗日函数 :
求导 :
特征值方程 :
结论 :
最优解 :选择最大特征值
多个主成分
第二主成分 :在与
拉格朗日函数 :
求解 :由于
一般结论 :前
投影矩阵 :
降维 :
方差保留比例
总方差 :
保留方差 :
实践 :通常选择
PCA:最小重构误差视角
重构目标
投影 :
重构 :
重构误差 :
目标 :
推导过程
展开重构误差 :
注意
转换为迹形式 :
优化等价于 :
拉格朗日函数 :
求导 :
特征值方程 :
结论 :
核 PCA:非线性降维
核技巧回顾
想法 :数据在原始空间线性不可分,在高维特征空间可能线性可分
显式映射 :
核函数 :
常用核 :
核 PCA 推导
映射后的数据 :
中心化 (在特征空间):
特征空间的协方差矩阵 :
主成分方程 :
关键观察 :
其中
代入特征值方程 :
两边左乘 :
其中中心化核矩阵 :
简化为 :
求解步骤 :
计算核矩阵
中心化:
特征分解
归一化:
新样本投影 :
其中
核 PCA vs 线性 PCA
复杂度 :
线性 PCA:
核 PCA:
适用场景 :
-
LDA:线性判别分析
Fisher 判别准则
有监督降维 :利用类别标签
数据 :
目标 :找到投影方向
类间距离最大(不同类的均值分得开)
类内距离最小(同类样本聚得紧)
投影后的均值 :
其中
二分类 LDA 推导
类间散度 ( Between-class scatter):
其中:
类内散度 ( Within-class scatter):
其中:
Fisher 准则 :
优化 :
求导 (分子分母同时对
简化为 :
广义特征值问题 :
求解 :
注意
多分类 LDA
类间散度矩阵 :
其中
类内散度矩阵 :
优化目标 :
求解 :广义特征分解
选择前
LDA vs PCA
相同点 :都是线性投影,都涉及特征分解
不同点 :
维度
PCA
LDA
类型
无监督
有监督
目标
最大方差
最大类间/最小类内
输出维度
任意
最多
适用
可视化、预处理
分类任务
t-SNE:流形学习与可视化
从 SNE 到 t-SNE
目标 :将高维数据映射到低维(通常
2D/3D),保持局部结构
SNE
思想 :在高维空间定义点对的相似度概率,在低维空间也定义概率,最小化两个概率分布的
KL 散度
高维空间的概率
条件概率 (
对称化 :
困惑度 (Perplexity):控制
通常设置 , 用 二 分 搜 索 找
低维空间的概率
t 分布 (Student-t):长尾分布,避免拥挤问题
为什么用 t 分布?
高斯分布衰减太快,远点被挤在一起
t 分布长尾,给远点更多空间
KL 散度与梯度
目标 :最小化 KL 散度
梯度 :
物理意义 :
t-SNE 算法流程
输入 :数据
步骤 :
计算高维概率
随机初始化低维坐标
迭代 (
计算低维概率
计算梯度
更新:
输出:低维坐标
t-SNE 的优化技巧
早期夸张 (Early Exaggeration):
Barnes-Hut 近似 :
复杂度从
学习率自适应 :
代码实现:完整降维工具包
PCA 实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 import numpy as npimport matplotlib.pyplot as pltclass PCA : """主成分分析""" def __init__ (self, n_components=2 ): """ 参数: n_components: 保留的主成分数量 """ self.n_components = n_components self.mean = None self.components = None self.explained_variance = None def fit (self, X ): """ 学习 PCA 模型 参数: X: (N, D)数组 """ self.mean = np.mean(X, axis=0 ) X_centered = X - self.mean cov_matrix = np.cov(X_centered, rowvar=False ) eigenvalues, eigenvectors = np.linalg.eigh(cov_matrix) idx = np.argsort(eigenvalues)[::-1 ] eigenvalues = eigenvalues[idx] eigenvectors = eigenvectors[:, idx] self.components = eigenvectors[:, :self.n_components] self.explained_variance = eigenvalues[:self.n_components] return self def transform (self, X ): """ 投影到低维空间 参数: X: (N, D)数组 返回: Z: (N, K)数组 """ X_centered = X - self.mean return X_centered @ self.components def fit_transform (self, X ): """拟合并转换""" self.fit(X) return self.transform(X) def inverse_transform (self, Z ): """ 从低维重构到高维 参数: Z: (N, K)数组 返回: X_reconstructed: (N, D)数组 """ return Z @ self.components.T + self.mean def explained_variance_ratio (self ): """返回方差解释比例""" return self.explained_variance / np.sum (self.explained_variance)
核 PCA 实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 from scipy.spatial.distance import pdist, squareformclass KernelPCA : """核主成分分析""" def __init__ (self, n_components=2 , kernel='rbf' , gamma=1.0 , degree=3 , coef0=1 ): """ 参数: n_components: 保留的主成分数量 kernel: 'linear', 'poly', 'rbf' gamma: RBF 核参数 degree: 多项式核次数 coef0: 多项式核常数项 """ self.n_components = n_components self.kernel = kernel self.gamma = gamma self.degree = degree self.coef0 = coef0 self.X_fit = None self.alphas = None self.lambdas = None def _compute_kernel (self, X, Y=None ): """计算核矩阵""" if Y is None : Y = X if self.kernel == 'linear' : return X @ Y.T elif self.kernel == 'poly' : return (X @ Y.T + self.coef0) ** self.degree elif self.kernel == 'rbf' : sq_dists = np.sum (X**2 , axis=1 ).reshape(-1 , 1 ) + \ np.sum (Y**2 , axis=1 ) - 2 * X @ Y.T return np.exp(-self.gamma * sq_dists) else : raise ValueError(f"Unknown kernel: {self.kernel} " ) def fit (self, X ): """学习核 PCA 模型""" N = X.shape[0 ] self.X_fit = X.copy() K = self._compute_kernel(X) one_N = np.ones((N, N)) / N K_centered = K - one_N @ K - K @ one_N + one_N @ K @ one_N eigenvalues, eigenvectors = np.linalg.eigh(K_centered) idx = np.argsort(eigenvalues)[::-1 ] eigenvalues = eigenvalues[idx] eigenvectors = eigenvectors[:, idx] self.lambdas = eigenvalues[:self.n_components] self.alphas = eigenvectors[:, :self.n_components] for i in range (self.n_components): self.alphas[:, i] /= np.sqrt(self.lambdas[i]) return self def transform (self, X ): """投影到低维空间""" K = self._compute_kernel(X, self.X_fit) N_train = self.X_fit.shape[0 ] one_N = np.ones((K.shape[0 ], N_train)) / N_train K_centered = K - one_N @ self._compute_kernel(self.X_fit) - \ K @ np.ones((N_train, N_train)) / N_train + \ one_N @ self._compute_kernel(self.X_fit) @ np.ones((N_train, N_train)) / N_train return K_centered @ self.alphas def fit_transform (self, X ): """拟合并转换""" self.fit(X) return self.transform(X)
LDA 实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 class LDA : """线性判别分析""" def __init__ (self, n_components=None ): """ 参数: n_components: 保留的判别方向数量( None 表示 C-1) """ self.n_components = n_components self.components = None self.mean = None self.class_means = None def fit (self, X, y ): """ 学习 LDA 模型 参数: X: (N, D)数组 y: (N,)数组,类别标签 """ n_samples, n_features = X.shape classes = np.unique(y) n_classes = len (classes) self.mean = np.mean(X, axis=0 ) S_W = np.zeros((n_features, n_features)) S_B = np.zeros((n_features, n_features)) self.class_means = {} for c in classes: X_c = X[y == c] mean_c = np.mean(X_c, axis=0 ) self.class_means[c] = mean_c S_W += (X_c - mean_c).T @ (X_c - mean_c) n_c = X_c.shape[0 ] mean_diff = (mean_c - self.mean).reshape(-1 , 1 ) S_B += n_c * (mean_diff @ mean_diff.T) eigenvalues, eigenvectors = np.linalg.eig(np.linalg.pinv(S_W) @ S_B) eigenvalues = np.real(eigenvalues) eigenvectors = np.real(eigenvectors) idx = np.argsort(eigenvalues)[::-1 ] eigenvectors = eigenvectors[:, idx] if self.n_components is None : self.n_components = min (n_classes - 1 , n_features) self.components = eigenvectors[:, :self.n_components] return self def transform (self, X ): """投影到判别空间""" return X @ self.components def fit_transform (self, X, y ): """拟合并转换""" self.fit(X, y) return self.transform(X)
t-SNE 实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 from scipy.spatial.distance import pdist, squareformclass TSNE : """t 分布随机邻域嵌入""" def __init__ (self, n_components=2 , perplexity=30.0 , learning_rate=200.0 , n_iter=1000 , random_state=42 ): """ 参数: n_components: 低维维度 perplexity: 困惑度 learning_rate: 学习率 n_iter: 迭代次数 random_state: 随机种子 """ self.n_components = n_components self.perplexity = perplexity self.learning_rate = learning_rate self.n_iter = n_iter self.random_state = random_state def _compute_pairwise_affinities (self, X ): """计算高维空间的概率分布""" N = X.shape[0 ] distances = squareform(pdist(X, 'sqeuclidean' )) P = np.zeros((N, N)) target_perplexity = self.perplexity for i in range (N): beta_min, beta_max = -np.inf, np.inf beta = 1.0 for _ in range (50 ): numerator = np.exp(-distances[i] * beta) numerator[i] = 0 sum_P = np.sum (numerator) if sum_P == 0 : P_i = np.zeros(N) else : P_i = numerator / sum_P H = -np.sum (P_i * np.log2(P_i + 1e-12 )) perplexity = 2 ** H perplexity_diff = perplexity - target_perplexity if abs (perplexity_diff) < 1e-5 : break if perplexity_diff > 0 : beta_min = beta beta = (beta + beta_max) / 2 if beta_max != np.inf else beta * 2 else : beta_max = beta beta = (beta + beta_min) / 2 if beta_min != -np.inf else beta / 2 P[i] = P_i P = (P + P.T) / (2 * N) P = np.maximum(P, 1e-12 ) return P def _compute_low_dim_affinities (self, Y ): """计算低维空间的概率分布( t 分布)""" distances = squareform(pdist(Y, 'sqeuclidean' )) Q = 1 / (1 + distances) np.fill_diagonal(Q, 0 ) Q = Q / np.sum (Q) Q = np.maximum(Q, 1e-12 ) return Q def _gradient (self, P, Q, Y ): """计算梯度""" N = Y.shape[0 ] PQ_diff = P - Q grad = np.zeros_like(Y) for i in range (N): diff = Y[i] - Y A = PQ_diff[i] / (1 + np.sum (diff**2 , axis=1 )) grad[i] = 4 * np.sum (A[:, np.newaxis] * diff, axis=0 ) return grad def fit_transform (self, X ): """拟合并转换""" np.random.seed(self.random_state) N = X.shape[0 ] print ("Computing pairwise affinities..." ) P = self._compute_pairwise_affinities(X) P *= 4 Y = np.random.randn(N, self.n_components) * 0.0001 momentum = np.zeros_like(Y) alpha = 0.5 for iteration in range (self.n_iter): Q = self._compute_low_dim_affinities(Y) grad = self._gradient(P, Q, Y) momentum = alpha * momentum - self.learning_rate * grad Y += momentum if iteration == 100 : P /= 4 if (iteration + 1 ) % 100 == 0 : C = np.sum (P * np.log(P / Q)) print (f"Iteration {iteration+1 } /{self.n_iter} , KL divergence: {C:.4 f} " ) return Y
可视化示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 def visualization_example (): """降维可视化示例""" from sklearn.datasets import load_digits digits = load_digits() X = digits.data y = digits.target pca = PCA(n_components=2 ) X_pca = pca.fit_transform(X) lda = LDA(n_components=2 ) X_lda = lda.fit_transform(X, y) tsne = TSNE(n_components=2 , perplexity=30 , n_iter=500 ) X_tsne = tsne.fit_transform(X) fig, axes = plt.subplots(1 , 3 , figsize=(15 , 5 )) for ax, X_proj, title in zip (axes, [X_pca, X_lda, X_tsne], ['PCA' , 'LDA' , 't-SNE' ]): scatter = ax.scatter(X_proj[:, 0 ], X_proj[:, 1 ], c=y, cmap='tab10' , s=10 ) ax.set_title(title) ax.set_xlabel('Component 1' ) ax.set_ylabel('Component 2' ) plt.colorbar(scatter, ax=axes.ravel().tolist()) plt.tight_layout() plt.savefig('dimensionality_reduction.png' , dpi=300 ) plt.show()
深入问答
Q1: PCA
的两种视角(最大方差/最小重构误差)为什么等价?
A:数学上,两者导出相同的特征值方程。直觉上: -
方差大的方向包含更多信息 - 重构误差小意味着投影损失的信息少
这两者本质是同一件事:保留数据的主要变化方向。证明关键在于:总 方 差 投 影 方 差 重 构 误 差
最大化投影方差等价于最小化重构误差。
Q2: PCA 对数据尺度敏感吗?
A:非常敏感!如果特征单位不同(如身高 cm vs 体重
kg),方差大的特征会主导主成分。解决方案: -
标准化 :归一化 :
Q3:核 PCA 比线性 PCA 慢多少?
A:复杂度对比: - 线性 PCA:
Q4: LDA 为什么最多降到 C-1 维?
A:类间散度矩阵
这些向量满足约束
Q5: t-SNE 的困惑度如何选择?
A:困惑度控制每个点的有效邻居数。经验法则: - 小数据集(<1000):
Perp = 5-30 - 中等数据集( 1000-10000): Perp = 30-50 - 大数据集: Perp
= 50-100
困惑度太小:局部结构过于强调,全局结构丢失
困惑度太大:全局结构压倒局部结构
Q6:为什么 t-SNE 用 t 分布而不是高斯分布?
A:解决"拥挤问题"(Crowding
Problem)。高维空间的中等距离点投影到低维时没有足够空间。 t
分布的长尾特性允许: - 近邻点在低维仍然靠近 - 远点有更多空间分散
数学上,t 分布
Q7: t-SNE 适合用于聚类吗?
A:不太适合 。 t-SNE 的问题: 1.
不保距离 :只保持局部概率分布,不保持全局距离 2.
随机性 :不同随机初始化给出不同结果 3.
不可解释 :低维坐标没有明确含义
建议:先用 t-SNE 可视化,再用 K-means 等算法在原始空间聚类。
Q8: PCA vs Autoencoder 有什么关系?
A:线性自编码器(单隐层,线性激活)等价于 PCA!证明:
自编码器最小化重构误差:
最优解张成的空间与 PCA 主成分空间相同
但非线性自编码器(如 VAE)比核 PCA
更强大,可以学习复杂的非线性流形。
Q9:如何评估降维质量?
A:几种方法:
方差解释比例 ( PCA):
重构误差 :
下游任务性能 :降维后的分类/聚类准确率
可视化合理性 :聚类是否清晰分离
Q10:降维会丢失信息吗?
A:一定会丢失!降维是有损压缩。关键问题是:丢失的是噪声还是信号? -
PCA 假设:方差小的方向是噪声 - LDA 假设:与类别无关的方向是噪声
实践中,降维通常提升泛化性能(正则化效果),因为去除了噪声和过拟合。
Q11: UMAP vs t-SNE 有什么区别?
A: UMAP( Uniform Manifold Approximation and Projection)是 t-SNE
的改进: - 速度 : UMAP 快 10-100 倍 -
保持全局结构 : UMAP 比 t-SNE 更好地保持簇间距离 -
理论基础 : UMAP 基于黎曼几何和拓扑理论
实践中, UMAP 逐渐替代 t-SNE 成为首选可视化工具。
Q12:如何处理新样本的降维?
A:不同方法的"外推"能力: - PCA :核 PCA :LDA :类似 PCA,支持外推 -
t-SNE :不支持!需要重新训练或用参数化 t-SNE
✏️ 练习题与解答
练习 1:PCA降维
题目 :数据协方差矩阵特征值解答 :
练习 2:中心化必要性
题目 :PCA前为什么要中心化数据?
解答 :协方差矩阵定义需要零均值。不中心化会让第一主成分指向均值方向而非方差最大方向。
练习 3:t-SNE vs PCA
题目 :t-SNE和PCA区别?
解答 :PCA线性、全局、保留方差。t-SNE非线性、局部、保留邻域结构,适合可视化但慢。
练习 4:核PCA
题目 :核PCA如何处理非线性数据?
解答 :通过核函数
练习 5:PCA白化
题目 :什么是PCA白化? 解答 :
参考文献
[1] Pearson, K. (1901). On lines and planes of closest fit to systems
of points in space. Philosophical Magazine , 2(11), 559-572.
[2] Hotelling, H. (1933). Analysis of a complex of statistical
variables into principal components. Journal of Educational
Psychology , 24(6), 417-441.
[3] Fisher, R. A. (1936). The use of multiple measurements in
taxonomic problems. Annals of Eugenics , 7(2), 179-188.
[4] Sch ö lkopf, B., Smola, A., & M ü ller, K. R. (1998).
Nonlinear component analysis as a kernel eigenvalue problem. Neural
Computation , 10(5), 1299-1319.
[5] Van der Maaten, L., & Hinton, G. (2008). Visualizing data
using t-SNE. Journal of Machine Learning Research , 9(11),
2579-2605.
[6] Tenenbaum, J. B., De Silva, V., & Langford, J. C. (2000). A
global geometric framework for nonlinear dimensionality reduction.
Science , 290(5500), 2319-2323.
[7] Roweis, S. T., & Saul, L. K. (2000). Nonlinear dimensionality
reduction by locally linear embedding. Science , 290(5500),
2323-2326.
[8] McInnes, L., Healy, J., & Melville, J. (2018). UMAP: Uniform
manifold approximation and projection for dimension reduction. arXiv
preprint arXiv:1802.03426 .
[9] Jolliffe, I. T. (2002). Principal Component Analysis
(2nd ed.). Springer.
[10] Hastie, T., Tibshirani, R., & Friedman, J. (2009). The
Elements of Statistical Learning (2nd ed.). Springer. (Chapter 14:
Unsupervised Learning)