集成学习(Ensemble
Learning)是机器学习最强大的武器之一——通过组合多个弱学习器,构建出性能卓越的强学习器。从
Kaggle
竞赛到工业应用,集成方法几乎无处不在。为什么"三个臭皮匠赛过诸葛亮"?背后的数学机制是什么?偏差-方差分解揭示了集成降低方差的本质,Boosting
通过加性模型逐步降低偏差,随机森林用随机化策略增加多样性,梯度提升则在函数空间进行优化——这些方法共同构成了集成学习的理论基石。
集成学习的理论基础
为什么集成有效?
考虑回归问题,真实函数
平方误差分解 :
假设各模型误差独立同分布,
偏 差 方 差
关键洞察 :集成不改变偏差,但将方差减少到
条件 : 1. 基学习器误差独立(通过随机化实现) 2.
基学习器不能太弱(偏差不能太大)
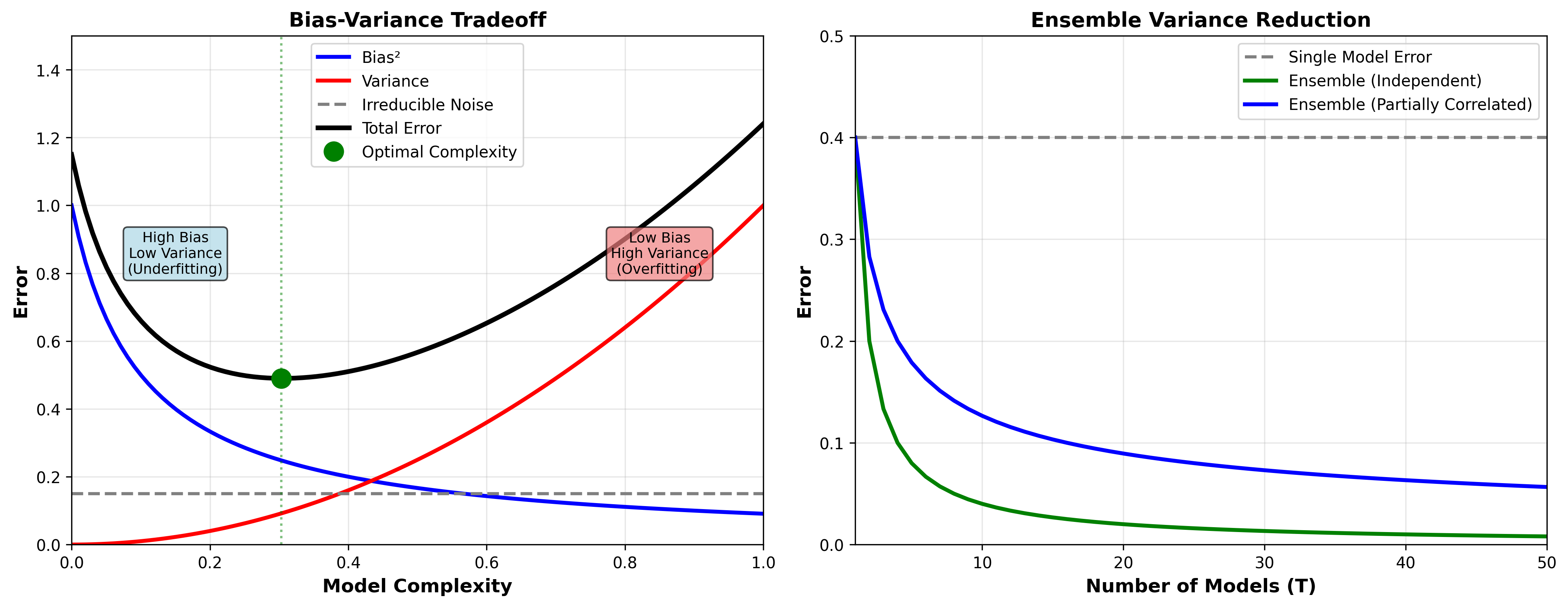
偏差-方差分解
对于平方损失,泛化误差可分解为:
偏 差 方 差 噪 声
其中:
偏差 (
Bias):模型的平均预测与真实值的差距,衡量欠拟合方差 (
Variance):模型在不同训练集上的预测波动,衡量过拟合噪声 ( Noise):数据本身的不可约误差
偏差-方差困境 : - 复杂模型:低偏差,高方差 -
简单模型:高偏差,低方差
集成策略 : -
Bagging :降低方差(用于高方差模型,如决策树) -
Boosting :降低偏差(从弱学习器逐步提升)
下图展示了偏差-方差权衡以及集成方法如何降低误差:
Bias-Variance Tradeoff
多样性与准确性
对于分类问题(二分类),集成误差上界:
若各分类器独立,错误率
示例 :
结论 :独立且稍好于随机的分类器,集成后可接近完美。
多样性度量 :
不一致度 (Disagreement):
其中预 测 为 且 分 类 器 预 测 为
Q 统计量 :
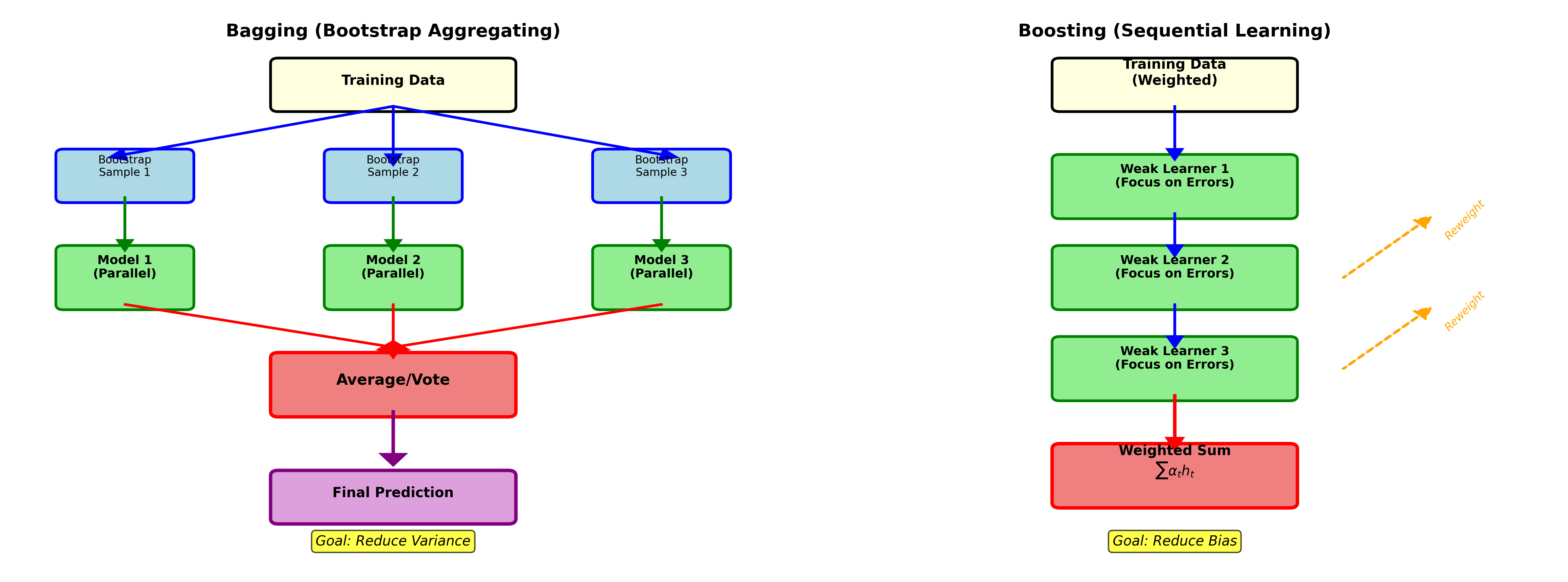
Bagging 与随机森林
Bootstrap Aggregating
(Bagging)
算法 ( Breiman, 1996):
Bootstrap 采样 :从训练集个 子 集 训练基学习器 :在 _t上 训 练 集成预测 :
Bootstrap 采样性质 :
样本被选中的概率:Out-of-Bag, OOB )
OOB 误差估计 :对每个样本
OOB 误差是泛化误差的无偏估计,无需额外验证集。
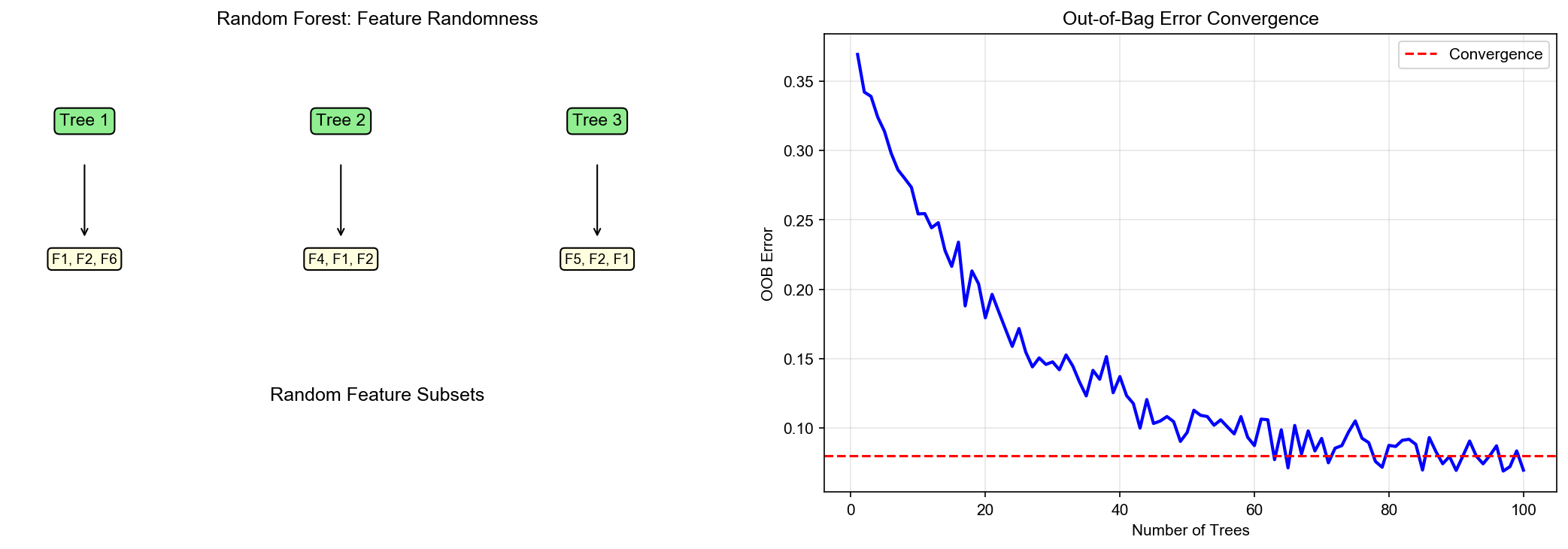
随机森林( Random Forest)
Figure 2
创新 ( Breiman, 2001):在 Bagging
基础上,引入随机特征选择 :
Bootstrap 采样 :同 Bagging随机特征子集 :每次分裂节点时,从完全生长 :决策树不剪枝,生长到纯节点或最小样本数
随机化的双重机制 : - 样本随机 :
Bootstrap(减少样本方差) -
特征随机 :随机特征选择(减少特征相关性,增加多样性)
理论分析 :泛化误差上界(Breiman, 2001)
其中: -
降低误差的方法 : 1. **增加降低 :增加随机性(减少
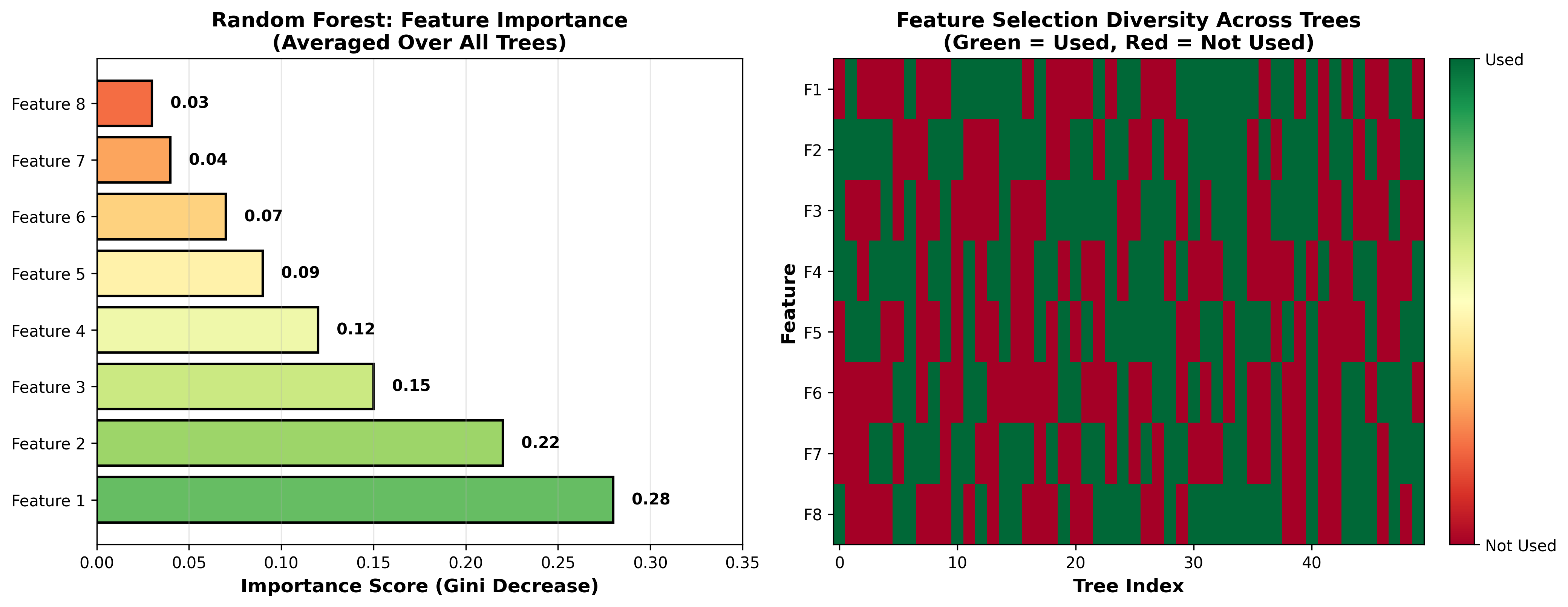
特征重要性
基于不纯度减少 :特征
基于 OOB 排列 :随机打乱特征
排列重要性更准确(不受特征相关性影响),但计算慢。
下图展示了随机森林的特征重要性分析和树之间的特征选择多样性:
Random Forest Feature
Importance
Bagging vs Boosting
下图对比了 Bagging 和 Boosting 两种核心集成策略的工作流程:
Bagging vs Boosting
Boosting 算法族
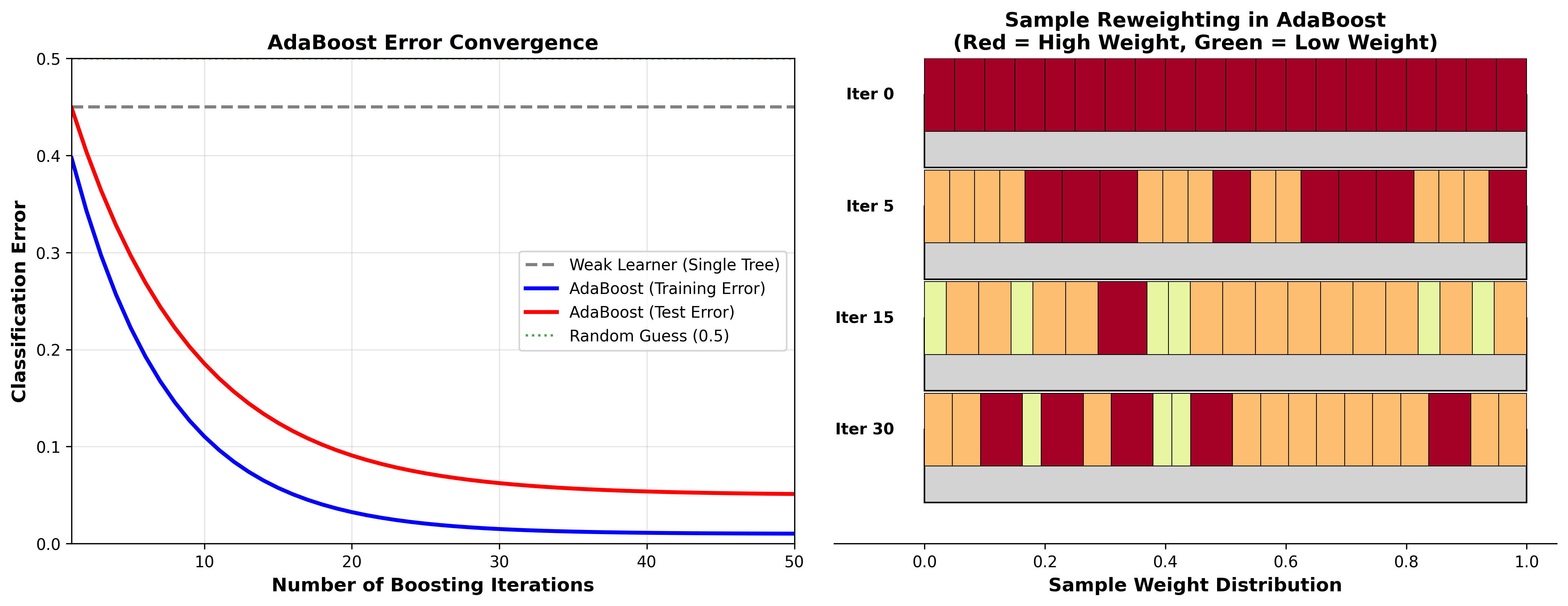
AdaBoost:自适应增强
Figure 3
核心思想 :迭代训练弱学习器,每轮增加错分样本的权重,最终加权组合。
下图展示了 AdaBoost 的训练误差收敛过程和样本权重演化:
AdaBoost Convergence
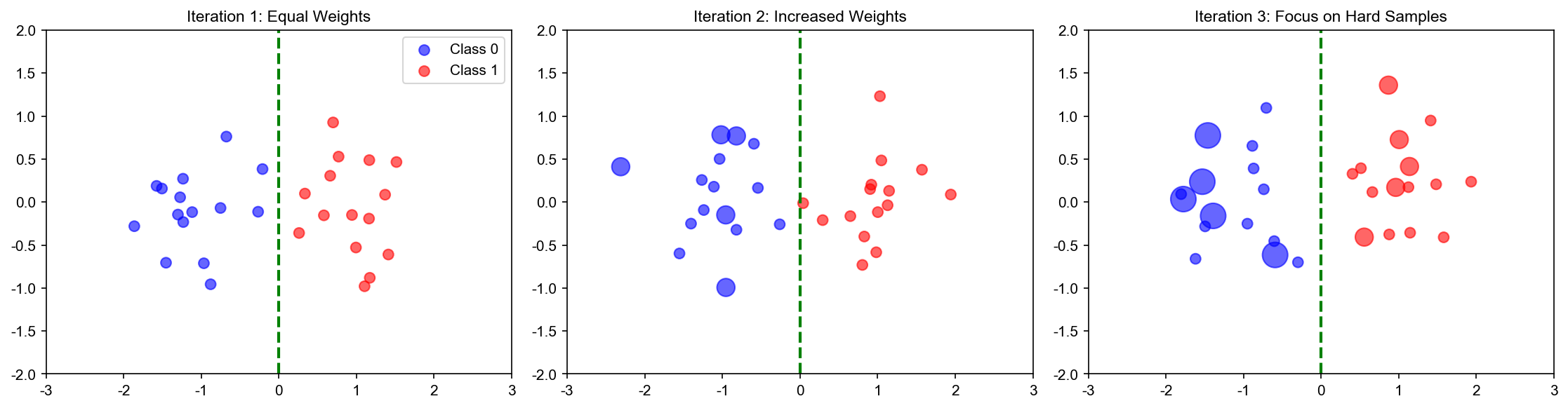
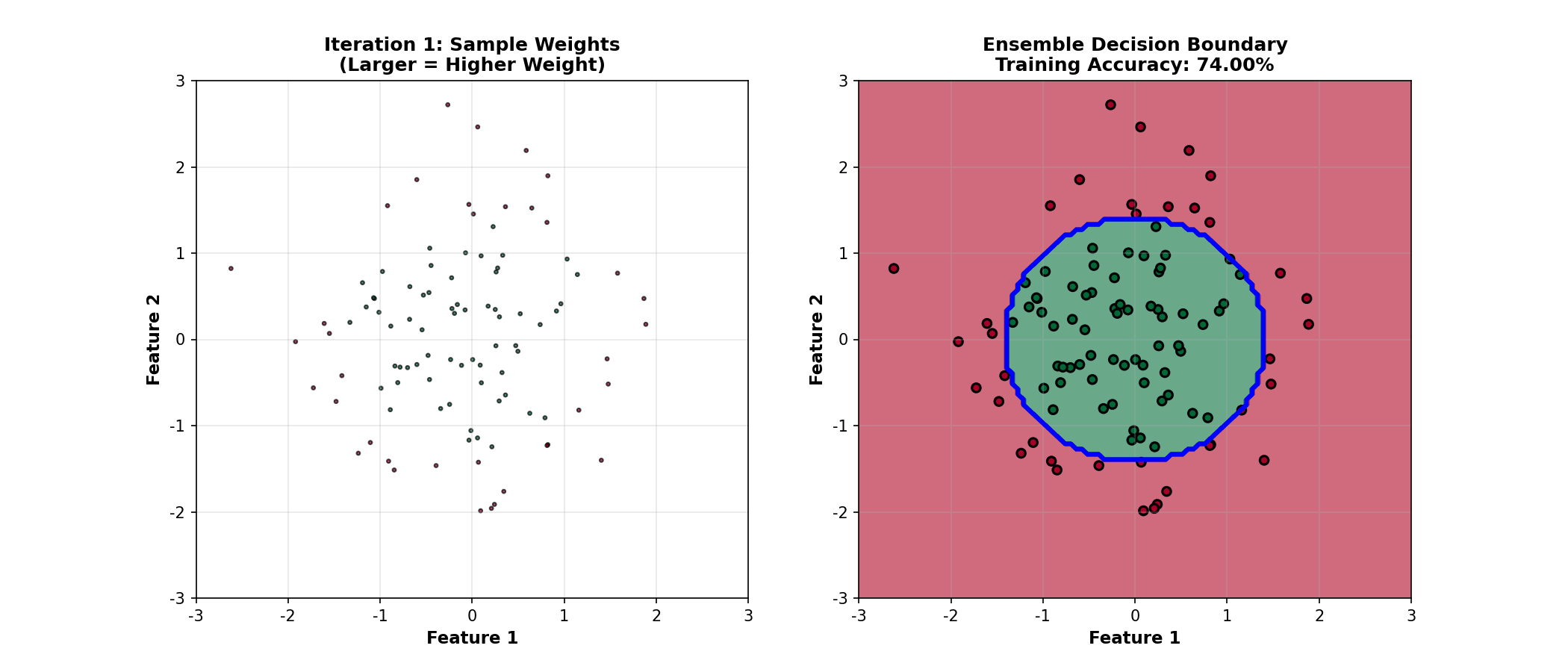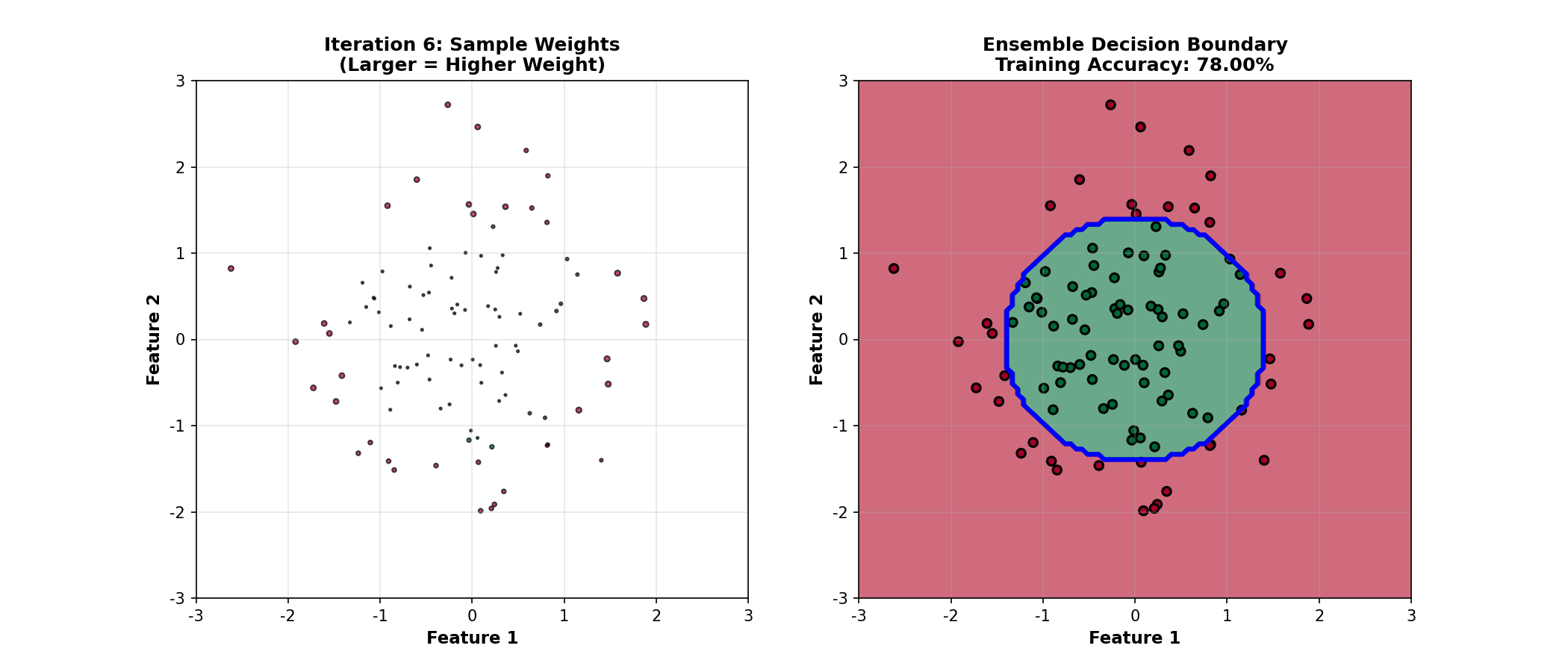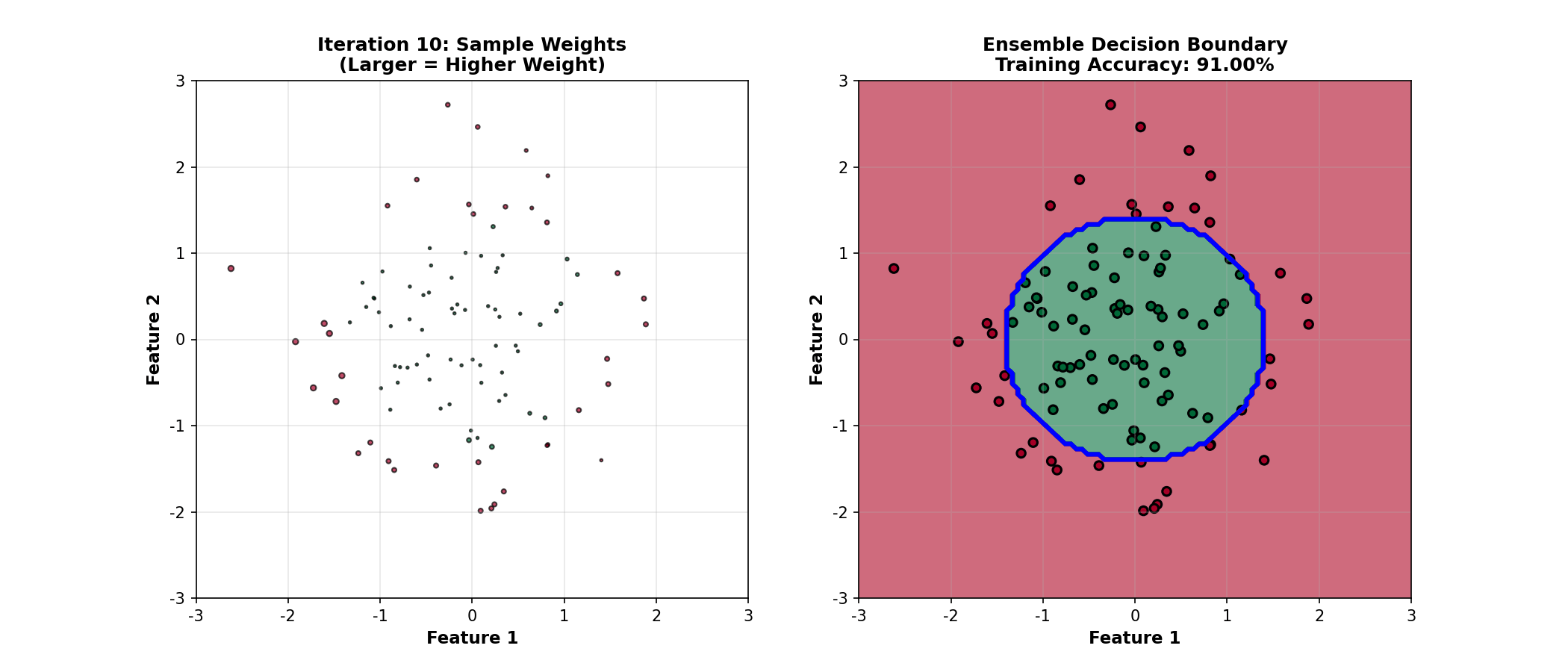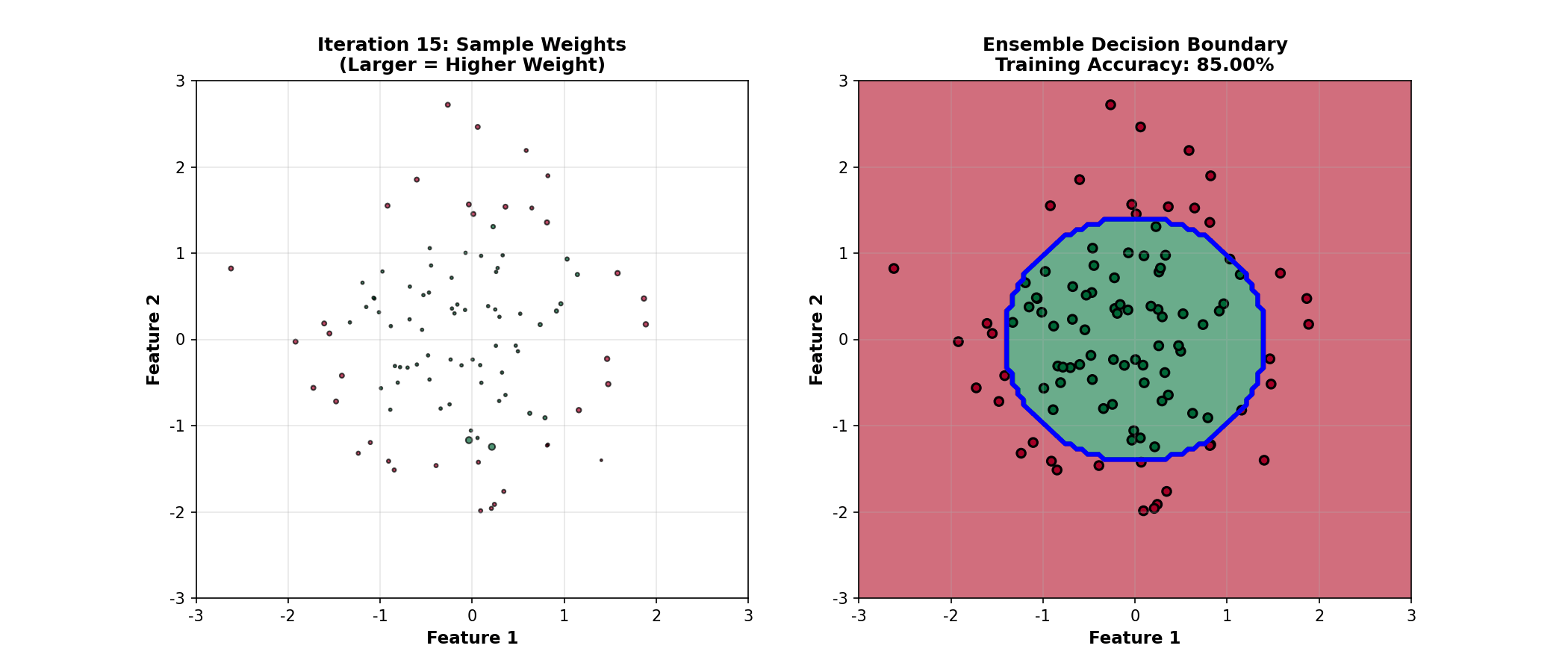
下面的动画演示了 Boosting
如何通过迭代重加权样本,逐步改进决策边界:
Boosting Animation
算法 (Freund & Schapire, 1997):
输入 :训练集
初始化 :
循环 (
训练基学习器 :
计算加权错误率 :
计算基学习器权重 :
更新样本权重 :
其中
最终模型 :
AdaBoost 的理论保证
训练误差上界 :
推导 :
若每轮
结论 :训练误差以指数速度下降!
泛化误差界 ( Schapire et al., 1998):
泛化能力随
指数损失与加性模型
AdaBoost
等价于最小化指数损失 的加性模型 :
前向分步算法 ( Forward Stagewise Additive
Modeling):
每轮优化:
令
这正是 AdaBoost 的更新公式!
洞察 : AdaBoost
是在函数空间上进行坐标下降 ,每轮添加一个新的基函数。
梯度提升决策树( GBDT)
梯度提升框架
思想 :将 Boosting 视为梯度下降的函数空间优化。
目标 :最小化损失函数
其中
梯度提升算法 ( Friedman, 2001):
初始化 :
循环 (
计算负梯度 (伪残差):
拟合基学习器 :
线搜索 :
更新模型 :
最终模型 :
不同损失函数
平方损失(回归)
梯度提升退化为拟合残差,类似传统回归。
绝对值损失(鲁棒回归)
对异常值鲁棒。
Logistic 损失(二分类)
输出对数几率:
GBDT with Regression Trees
基学习器 :回归树( CART)
叶节点优化 :对于叶节点区域
示例 (平方损失):
更新 :
其中
正则化与收缩
学习率收缩 :
小学习率
子采样 ( Stochastic Gradient
Boosting):每轮随机采样
树的复杂度惩罚 :限制树深度(如
完整实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 import numpy as npfrom collections import Counterclass DecisionStump : """决策树桩(单层决策树)""" def __init__ (self ): self.feature_idx = None self.threshold = None self.left_value = None self.right_value = None def fit (self, X, y, weights ): N, d = X.shape best_error = float ('inf' ) for j in range (d): thresholds = np.unique(X[:, j]) for threshold in thresholds: left_mask = X[:, j] <= threshold right_mask = ~left_mask if np.sum (left_mask) == 0 or np.sum (right_mask) == 0 : continue left_value = np.sign(np.sum (weights[left_mask] * y[left_mask])) right_value = np.sign(np.sum (weights[right_mask] * y[right_mask])) pred = np.where(left_mask, left_value, right_value) error = np.sum (weights[pred != y]) if error < best_error: best_error = error self.feature_idx = j self.threshold = threshold self.left_value = left_value self.right_value = right_value return self def predict (self, X ): left_mask = X[:, self.feature_idx] <= self.threshold return np.where(left_mask, self.left_value, self.right_value) class AdaBoost : """AdaBoost 分类器""" def __init__ (self, n_estimators=50 ): self.n_estimators = n_estimators self.estimators = [] self.alphas = [] def fit (self, X, y ): N = X.shape[0 ] weights = np.ones(N) / N for t in range (self.n_estimators): stump = DecisionStump() stump.fit(X, y, weights) pred = stump.predict(X) epsilon = np.sum (weights[pred != y]) epsilon = np.clip(epsilon, 1e-10 , 1 - 1e-10 ) alpha = 0.5 * np.log((1 - epsilon) / epsilon) weights *= np.exp(-alpha * y * pred) weights /= np.sum (weights) self.estimators.append(stump) self.alphas.append(alpha) return self def predict (self, X ): predictions = np.array([alpha * estimator.predict(X) for alpha, estimator in zip (self.alphas, self.estimators)]) return np.sign(np.sum (predictions, axis=0 )) def score (self, X, y ): return np.mean(self.predict(X) == y) class GradientBoostingRegressor : """梯度提升回归树""" def __init__ (self, n_estimators=100 , learning_rate=0.1 , max_depth=3 ): self.n_estimators = n_estimators self.learning_rate = learning_rate self.max_depth = max_depth self.trees = [] self.init_prediction = None def fit (self, X, y ): self.init_prediction = np.mean(y) F = np.full(len (y), self.init_prediction) for t in range (self.n_estimators): residuals = y - F tree = self._build_tree(X, residuals, depth=0 ) self.trees.append(tree) F += self.learning_rate * self._predict_tree(tree, X) return self def _build_tree (self, X, y, depth ): """递归构建回归树""" N = len (y) if depth >= self.max_depth or N < 2 : return {'value' : np.mean(y)} best_mse = float ('inf' ) best_split = None for j in range (X.shape[1 ]): thresholds = np.unique(X[:, j]) for threshold in thresholds: left_mask = X[:, j] <= threshold right_mask = ~left_mask if np.sum (left_mask) < 1 or np.sum (right_mask) < 1 : continue mse = np.var(y[left_mask]) * np.sum (left_mask) + np.var(y[right_mask]) * np.sum (right_mask) if mse < best_mse: best_mse = mse best_split = (j, threshold, left_mask, right_mask) if best_split is None : return {'value' : np.mean(y)} j, threshold, left_mask, right_mask = best_split return { 'feature' : j, 'threshold' : threshold, 'left' : self._build_tree(X[left_mask], y[left_mask], depth + 1 ), 'right' : self._build_tree(X[right_mask], y[right_mask], depth + 1 ) } def _predict_tree (self, tree, X ): """单棵树预测""" if 'value' in tree: return np.full(len (X), tree['value' ]) left_mask = X[:, tree['feature' ]] <= tree['threshold' ] predictions = np.zeros(len (X)) predictions[left_mask] = self._predict_tree(tree['left' ], X[left_mask]) predictions[~left_mask] = self._predict_tree(tree['right' ], X[~left_mask]) return predictions def predict (self, X ): F = np.full(len (X), self.init_prediction) for tree in self.trees: F += self.learning_rate * self._predict_tree(tree, X) return F def score (self, X, y ): pred = self.predict(X) return 1 - np.sum ((y - pred) ** 2 ) / np.sum ((y - np.mean(y)) ** 2 ) if __name__ == '__main__' : from sklearn.datasets import make_classification, make_regression from sklearn.model_selection import train_test_split print ("=== AdaBoost ===" ) X, y = make_classification(n_samples=500 , n_features=10 , random_state=42 ) y = 2 * y - 1 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3 , random_state=42 ) ada = AdaBoost(n_estimators=50 ) ada.fit(X_train, y_train) print (f"测试准确率: {ada.score(X_test, y_test):.4 f} " ) print ("\n=== GBDT Regression ===" ) X, y = make_regression(n_samples=500 , n_features=10 , noise=10 , random_state=42 ) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3 , random_state=42 ) gbdt = GradientBoostingRegressor(n_estimators=100 , learning_rate=0.1 , max_depth=3 ) gbdt.fit(X_train, y_train) print (f"测试 R ²: {gbdt.score(X_test, y_test):.4 f} " )
Q&A 精选
Q1:为什么 Boosting 比 Bagging 强?
A: Bagging 并行训练,降低方差; Boosting
串行训练,既降低偏差又降低方差。关键区别: -
Bagging :独立训练,适合高方差模型(如深树) -
Boosting :自适应训练,从简单模型逐步学习复杂模式
但 Boosting 更易过拟合、对噪声敏感。
Q2: AdaBoost 为什么指数权重更新?
A:指数更新
Q3: GBDT 的学习率为什么重要?
A:学习率控 制 每 棵 树 的 贡 献 。 小 shrinkage
正则化 防止单棵树过拟合。
Q4:随机森林的特征数
A:经验法则: - 分类 :回归 :
Q5: Boosting 能并行化吗?
A:标准 Boosting 串行(每轮依赖前一轮)。但有并行变种: -
并行 Bagging + Boosting :先 Bagging,每个子集 Boosting
- 数据并行 :单轮内,样本分割到多机(如 XGBoost
的分布式) - 特征并行 :寻找最优分裂时,特征并行搜索
Q6:为什么 GBDT 用决策树而非其他模型?
A:决策树天然支持: - 非线性 :自动学习特征交互 -
分段常数 :每个叶节点独立优化 -
高效分裂 :基于阈值的快速搜索
理论上可用任意模型(如线性模型),但树最实用。
Q7:集成学习能防止过拟合吗?
A:取决于方法: -
Bagging/RF :几乎不会过拟合(树越多越好) -
Boosting :会过拟合(训练误差→ 0,测试误差可能上升)
防止 Boosting 过拟合: - 早停(监控验证集) - 学习率收缩 - 子采样 -
树复杂度限制
Q8: XGBoost 与 GBDT 的区别?
A: XGBoost 是 GBDT 的高效实现,增加: -
二阶泰勒展开 :利用 Hessian 信息(更精确) -
正则化 :叶节点数和叶权重的列采样 :类似随机森林的特征随机 -
并行与分布式 :系统优化(非算法层面)
Q9:如何可视化决策树集成?
A:单棵树可视化(用 graphviz):
1 2 3 4 from sklearn.tree import export_graphvizexport_graphviz(rf.estimators_[0 ], out_file='tree.dot' , feature_names=feature_names, filled=True )
集成整体:特征重要性柱状图
1 2 3 4 importances = rf.feature_importances_ plt.barh(range (len (importances)), importances) plt.yticks(range (len (importances)), feature_names) plt.show()
✏️ 练习题与解答
练习 1:偏差-方差分解计算
题目 :有3个独立的回归模型,每个模型的偏差平方为
解答 :
单个模型的 MSE :
集成模型的 MSE (假设误差独立):
集成使误差降低了
练习 2:多数投票误差概率
题目 :有21个独立的二分类器,每个错误率为
解答 :
多数投票出错当且仅当超过一半(
使用二项分布累积概率函数(或编程计算):
集成将错误率从
练习 3:AdaBoost 权重更新
题目 :AdaBoost 第
解答 :
(1) 分类器权重 :
(2) 样本权重更新 (归一化前):
因为
正确分类的样本权重降低,错误分类样本权重会增加(
练习 4:随机森林 vs
单棵决策树
题目 :随机森林使用100棵深度为10的决策树,每棵树在
Bootstrap 样本上训练,每次分裂随机选择
解答 :
单棵深决策树 : -
在完整训练集上生长,能记住所有训练样本的特征组合 -
方差极高,泛化误差大
随机森林的降方差机制 :
Bootstrap
采样 :每棵树看到不同的训练子集(约63.2%原始样本),减少树之间的相关性特征随机选择 :每次分裂只考虑平均效应 :100棵树的预测平均后,单棵树的过拟合噪声被抵消
根据方差减少公式,如果树之间独立,方差降为
练习 5:GBDT vs AdaBoost
题目 :GBDT 和 AdaBoost 都是 Boosting 方法,但 GBDT
使用梯度下降拟合残差,AdaBoost
使用指数损失加权样本。比较两者的优劣。
解答 :
特性 AdaBoost GBDT
损失函数 指数损失(固定)
任意可微损失(灵活)
基学习器 通常决策桩(弱分类器)
决策树(CART)
更新方式 样本重加权
拟合负梯度(残差)
对噪声 敏感(指数损失对离群点惩罚大)
较鲁棒(可用 Huber 等损失)
回归任务 不适用
直接适用
可解释性 较好(权重明确)
较好(树结构)
优劣总结 : -
AdaBoost :简单高效,适合二分类,但对噪声敏感 -
GBDT :更通用(回归+分类),损失函数灵活,工业应用广泛(XGBoost/LightGBM
的基础)
在实践中,GBDT
及其变种(XGBoost、LightGBM、CatBoost)因灵活性和性能优势,成为主流选择。
参考文献
A: 1. 神经网络集成 :集成多个深度模型( Snapshot
Ensemble 、 Cyclical LR) 2. 自动集成 : AutoML
自动选择集成策略 3.
异构集成 :混合树模型、线性模型、神经网络 4.
隐私保护集成 :联邦学习中的安全聚合
参考文献
Breiman, L. (1996). Bagging predictors. Machine
Learning , 24(2), 123-140.Breiman, L. (2001). Random forests. Machine
Learning , 45(1), 5-32.Freund, Y., & Schapire, R. E. (1997). A
decision-theoretic generalization of on-line learning and an application
to boosting. Journal of Computer and System Sciences , 55(1),
119-139.Friedman, J. H. (2001). Greedy function
approximation: A gradient boosting machine. Annals of
Statistics , 29(5), 1189-1232.Friedman, J. H. (2002). Stochastic gradient
boosting. Computational Statistics & Data Analysis , 38(4),
367-378.Schapire, R. E., Freund, Y., Bartlett, P., & Lee, W.
S. (1998). Boosting the margin: A new explanation for the
effectiveness of voting methods. Annals of Statistics , 26(5),
1651-1686.Hastie, T., Tibshirani, R., & Friedman, J.
(2009). The Elements of Statistical Learning (2nd ed.).
Springer. [Chapter 10: Boosting and Additive Trees]
集成学习以"众人拾柴火焰高"的智慧,将简单模型组合成强大系统。从
Bagging 的并行聚合到 Boosting 的串行提升,从随机森林的随机化策略到 GBDT
的梯度优化,集成方法展现了机器学习的工程美学。理解集成学习,不仅是掌握实战利器,更是领悟"整体大于部分之和"的系统思维——这一思想贯穿现代机器学习的方方面面,从深度学习的
Dropout 到强化学习的 Actor-Critic,无不体现集成的精髓。