从线性回归到逻辑回归的跨越,标志着机器学习从回归任务到分类任务的重要转变。逻辑回归虽然名为"回归",实则是分类算法的基石,通过引入
Sigmoid
函数建立起线性模型与概率预测的桥梁。本章将深入推导逻辑回归的数学本质:从似然函数的构造到梯度计算的细节,从二分类到多分类的推广,从优化算法到正则化技术,全面揭示分类问题的概率建模思想。
从线性模型到概率分类
线性分类的局限性
回顾线性回归,我们建立了输入与连续输出的线性映射:
但分类任务的标签是离散的(如Extra close brace or missing open brace y \in \{0,1\\}
输出不受约束 :概率解释缺失 :线性模型无法给出"样本属于某类的概率"
逻辑回归通过引入链接函数 ( link
function)解决这一矛盾:将线性模型的输出映射到
Sigmoid 函数:从实数到概率
Sigmoid 函数定义为:
它具有优雅的数学性质:
性质 1:值域约束
对任意
性质 2:对称性
证明 :
性质 3:导数的自我表示
证明 :
这一性质是梯度计算简洁性的关键。
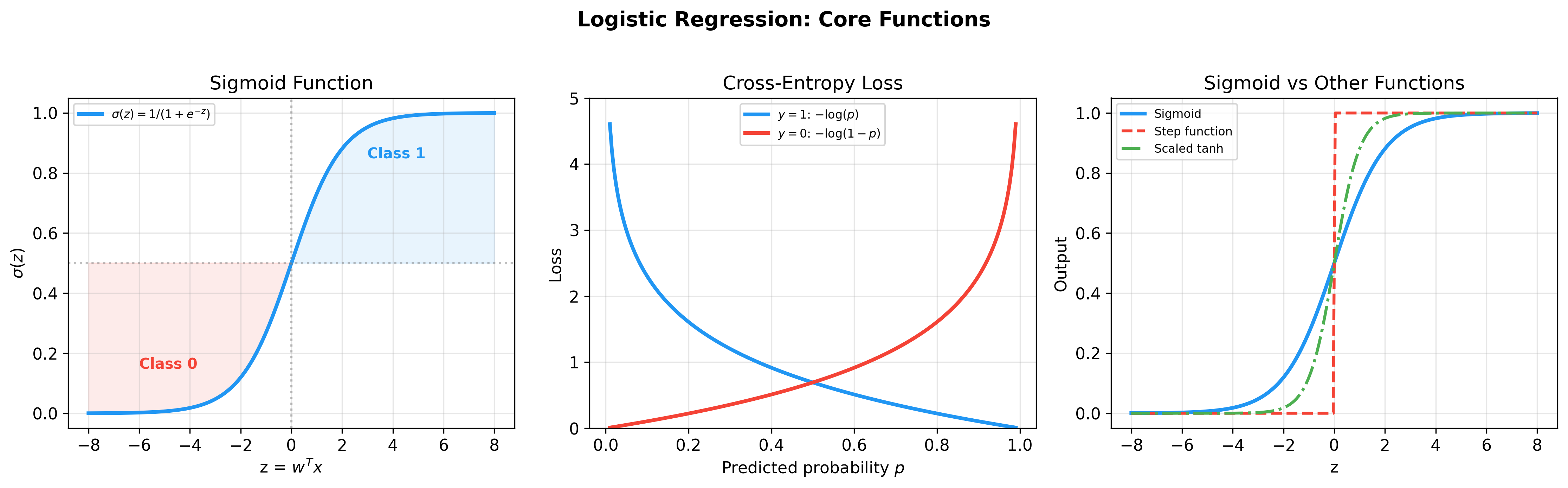
下图全面展示了 Sigmoid
函数的核心性质——函数曲线与导数、对称性、与其他激活函数的对比,以及梯度消失问题:
Sigmoid Function Properties
下图更详细地展示了 Sigmoid
函数、交叉熵损失函数以及与阶跃函数的对比——交叉熵损失对错误预测施加严厉的惩罚(趋向无穷),这使得优化更加高效:
Sigmoid and Loss Functions
逻辑回归模型定义
对于二分类任务(Extra close brace or missing open brace y \in \{0,1\\}
相应地:
统一表示 :利用指数形式,两个概率可合并为:
当
最大似然估计与损失函数
似然函数的构造
给定训练集
代入逻辑回归模型:
对数似然与交叉熵
取对数得对数似然:
最大化对数似然等价于最小化负对数似然:
其中二元交叉熵损失 (Binary
Cross-Entropy Loss)。
信息论解释 :交叉熵衡量真实分布
在二分类中,真实分布
与均方误差的对比
如果用均方误差(MSE)作为损失:
计算梯度:
注意到多了一项梯度消失 ,即使预测错误也几乎不更新。
而交叉熵损失的梯度为(下节推导):
不含
梯度推导与优化算法
梯度的精确计算
对单个样本的损失:
其中
第一步 :
第二步 :利用 Sigmoid 导数性质
第三步 :
合并 :
总梯度为:
其中
Hessian 矩阵与二阶方法
对于牛顿法等二阶优化,需要计算 Hessian 矩阵:
对单样本梯度
总 Hessian 为:
其中
正定性分析 :对任意
因为严格凸 的,存在唯一全局最优解。
梯度下降与随机优化
批量梯度下降 (BGD):
随机梯度下降 (SGD):每次随机选一个样本
小批量梯度下降 (Mini-batch GD):每次选批量大小
多分类推广:Softmax 回归
从二分类到多分类
对于
使用 Softmax 函数将得分归一化为概率:
其中
归一化验证 :
交叉熵损失与 One-Hot 编码
引入 One-Hot 编码:若真实类别为
其中
化简 :由于每个样本只有一个
这是多分类的负对数似然 (Negative
Log-Likelihood,NLL)。
Softmax 梯度推导
对单样本损失
第一项 :
𝟙
第二项 :
合并 :
𝟙
进一步关于
总梯度为:
矩阵形式:
其中
下图展示了 Softmax
函数的温度参数效应、交叉熵损失函数的形态、多分类概率分布以及 L2
正则化对权重的衰减作用:
Softmax and Cross Entropy
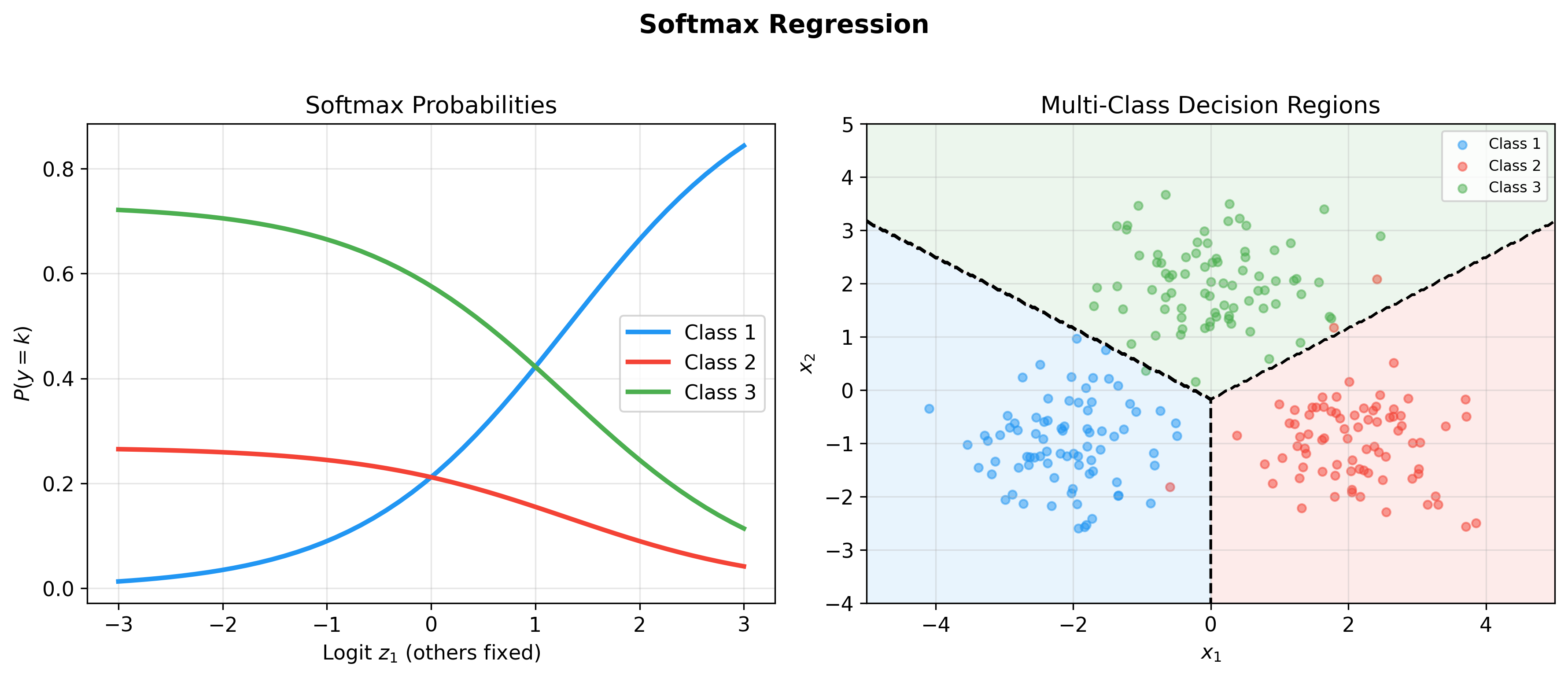
下图展示了 Softmax 回归的概率分布和多类别决策区域——左图展示当一个
logit 变化时各类概率如何"竞争",右图展示三类数据的决策区域分割:
Softmax Visualization
正则化技术
L2 正则化(岭逻辑回归)
添加 L2 惩罚项:
梯度变为:
更新公式:
权重衰减 (weight
decay)效果。
L1 正则化( Lasso 逻辑回归)
添加 L1 惩罚:
其中
稀疏性 : L1 正则化倾向于产生稀疏解(许多权重恰好为
0),实现特征选择 。
弹性网络( Elastic Net)
结合 L1 和 L2:
兼具稀疏性与稳定性。
决策边界与几何解释
二分类决策边界
逻辑回归的决策规则:
由于
这是特征空间中的超平面 。
点到边界的距离 :对于样本
距离越大,分类越自信。
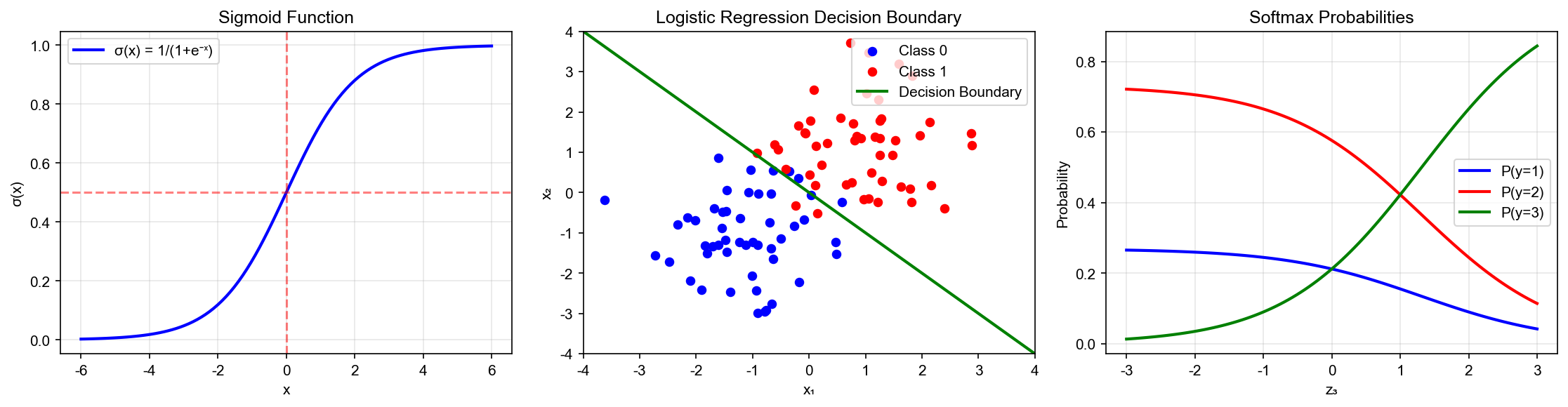
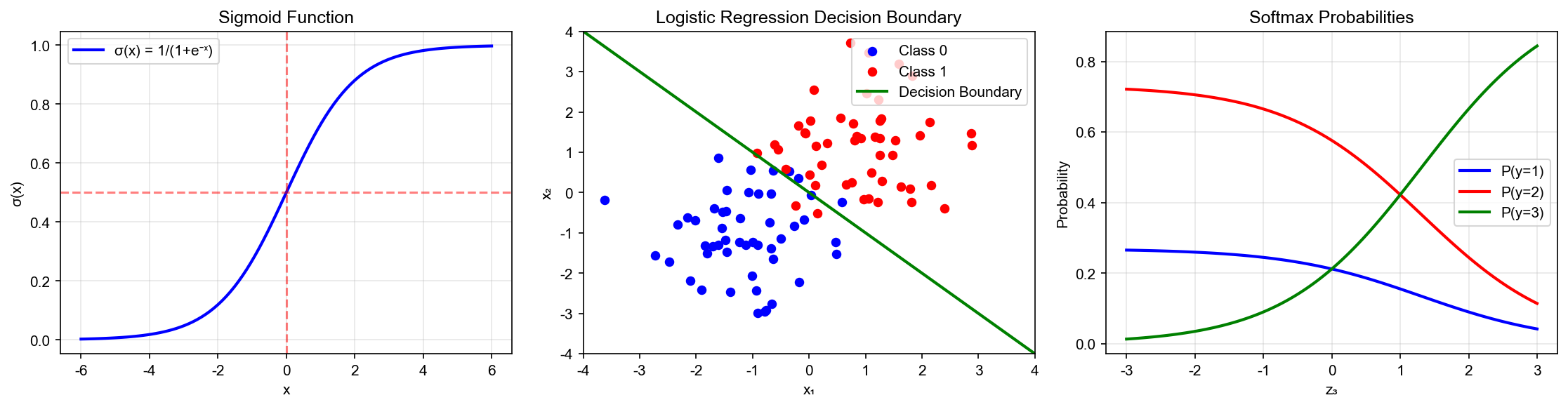
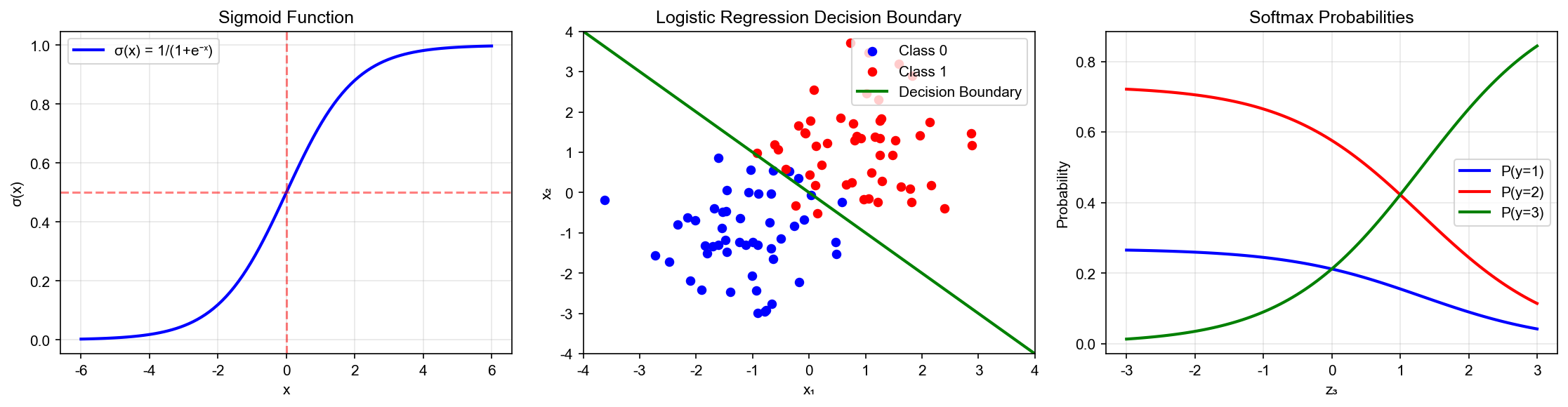
下图展示了逻辑回归的决策边界:左图显示二分类中概率等高线和线性决策边界;右图展示多分类
Softmax 如何将特征空间划分为不同区域:
Decision Boundary
Visualization
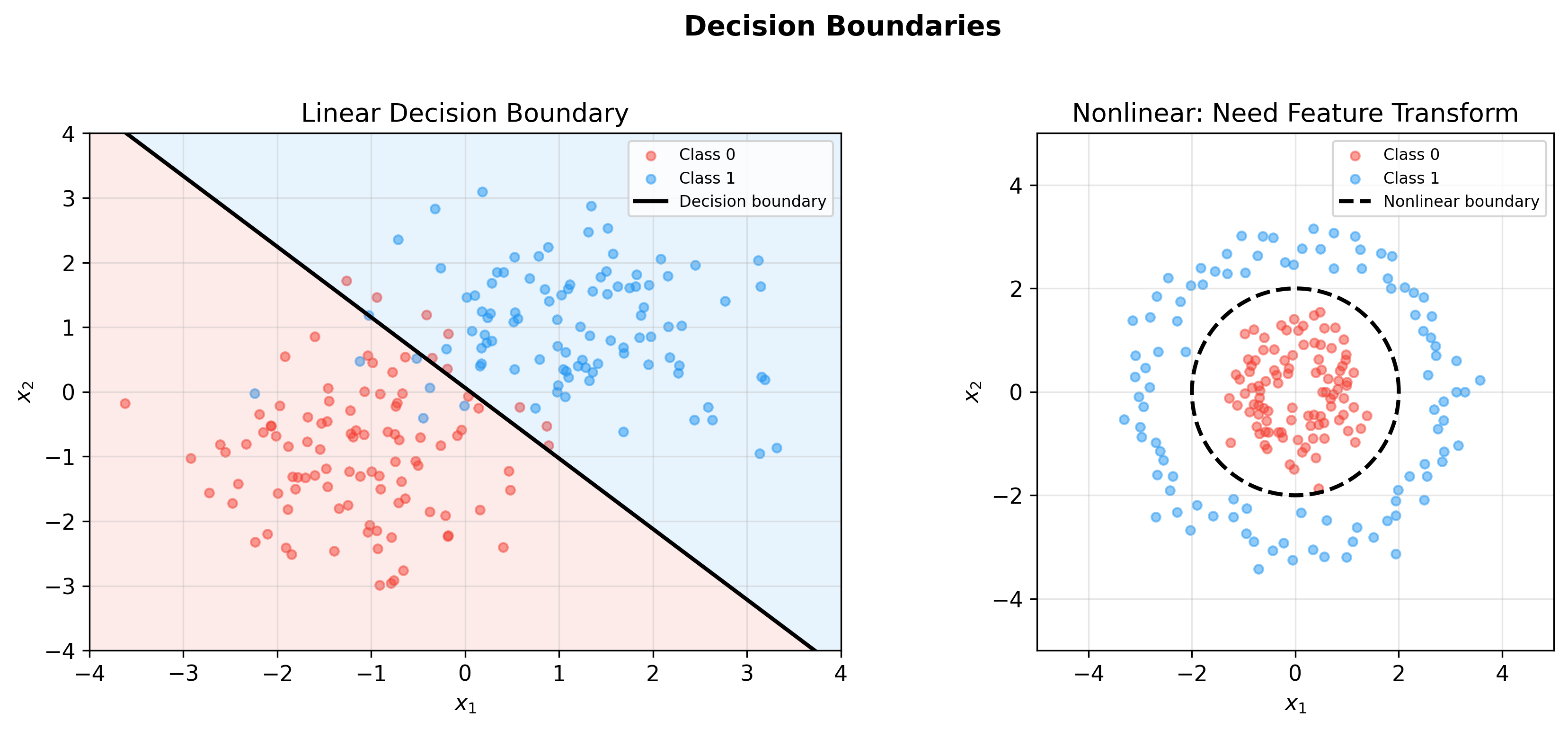
下图展示了线性决策边界(左)和非线性决策边界的需求(右)——当数据不是线性可分时,需要特征变换或核方法来构造更复杂的分类面:
Decision Boundaries
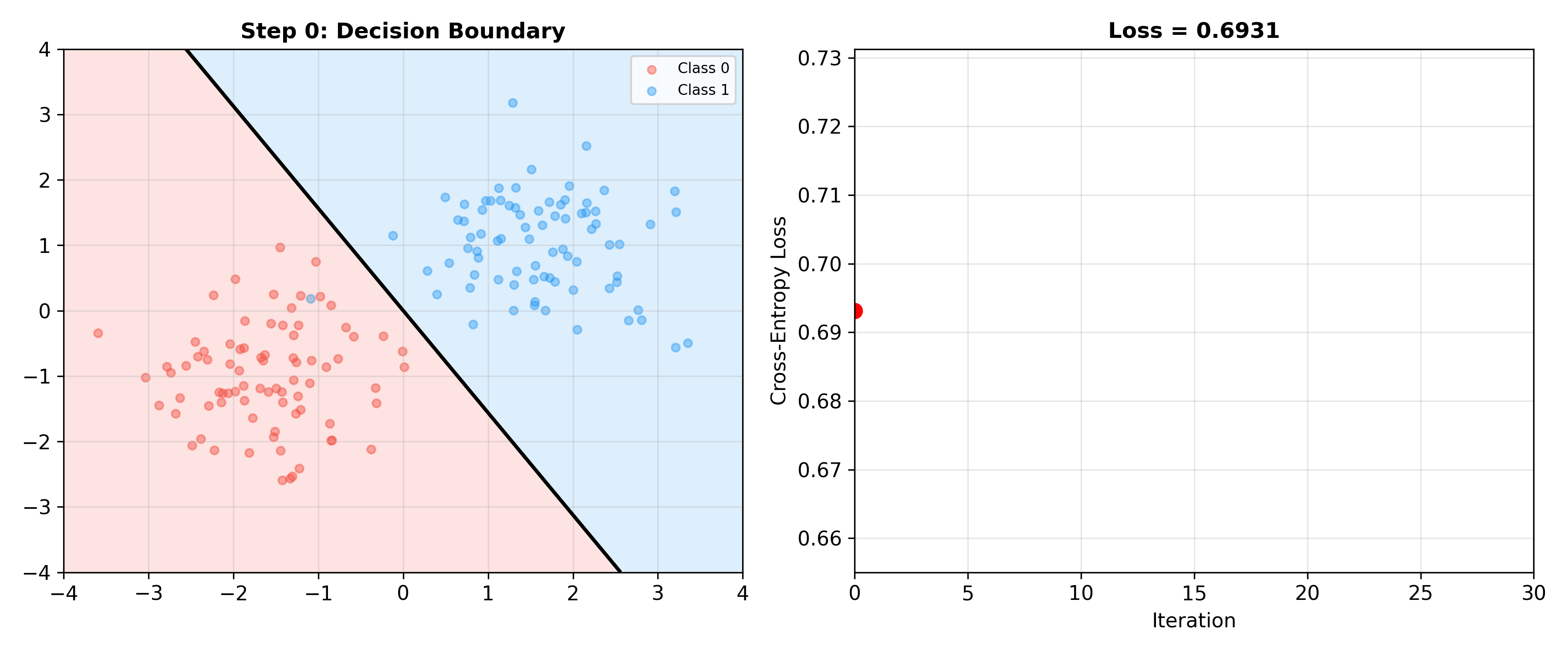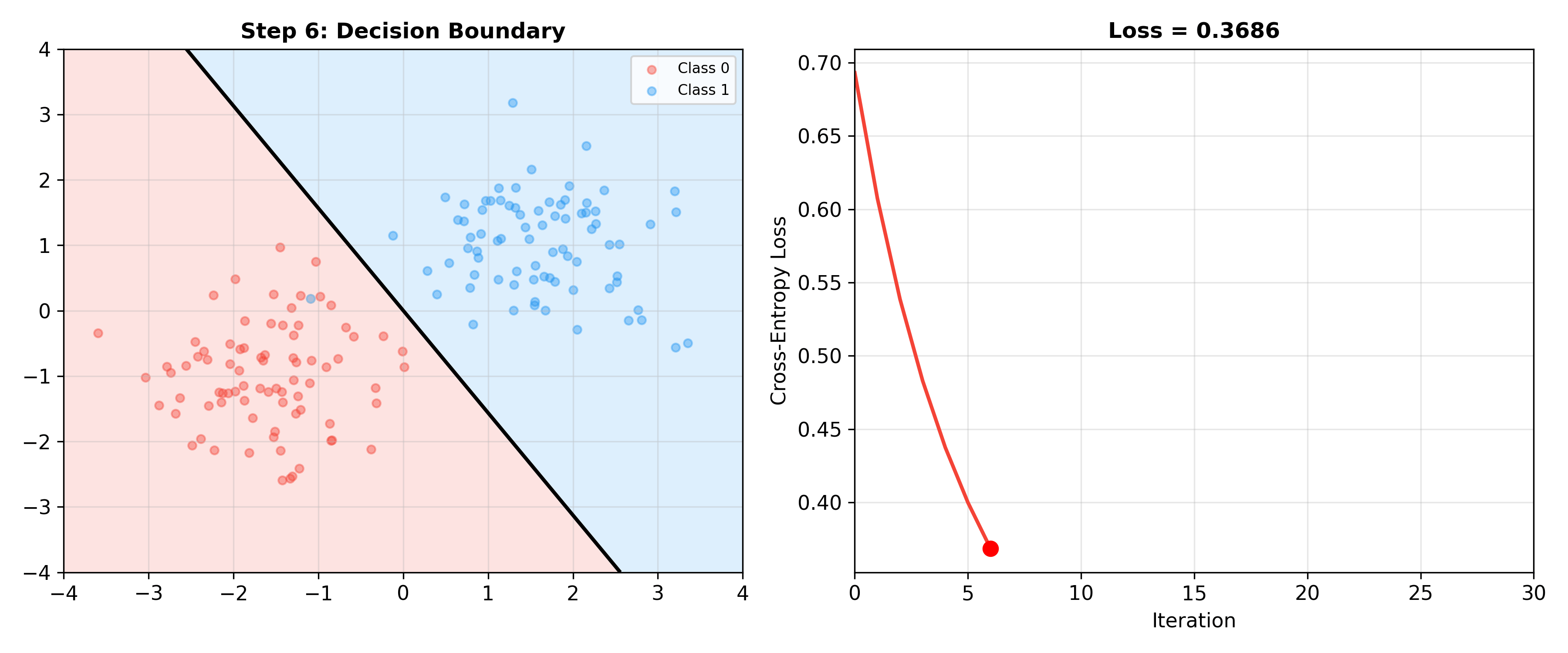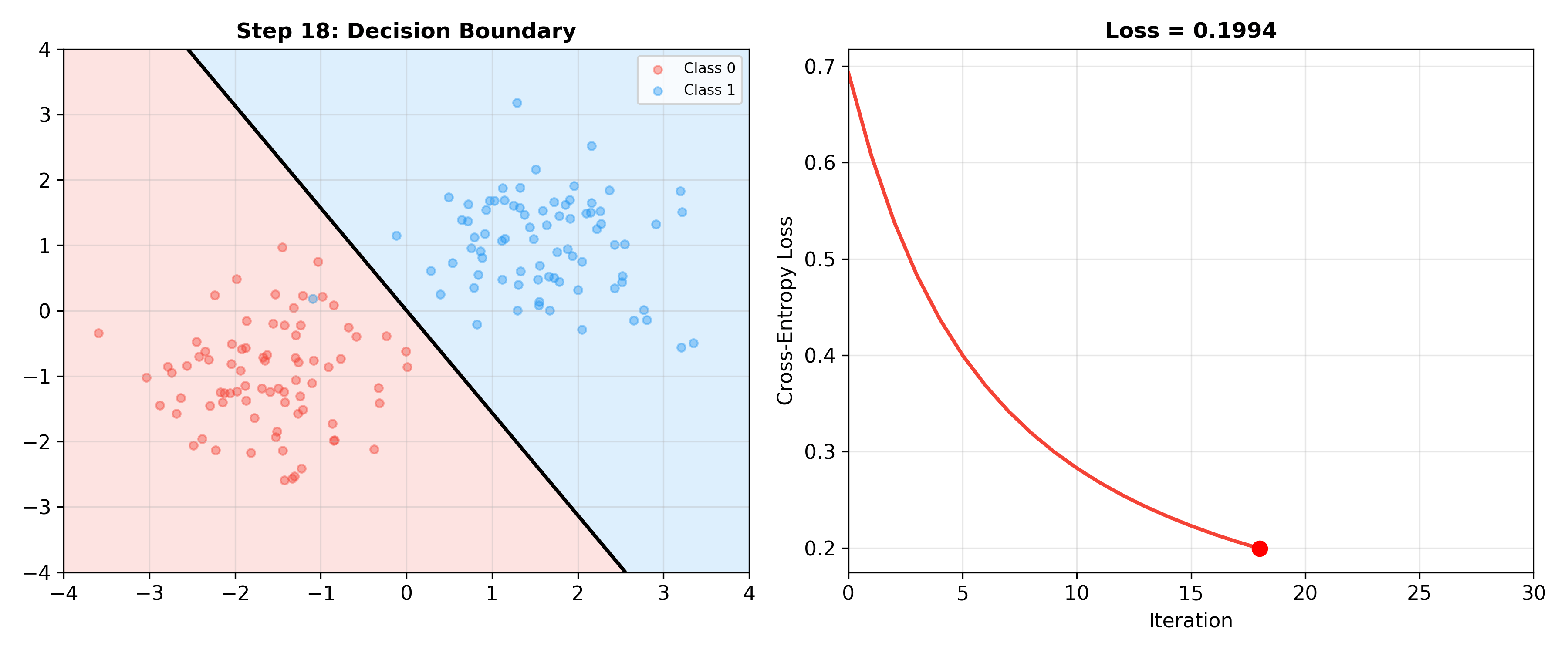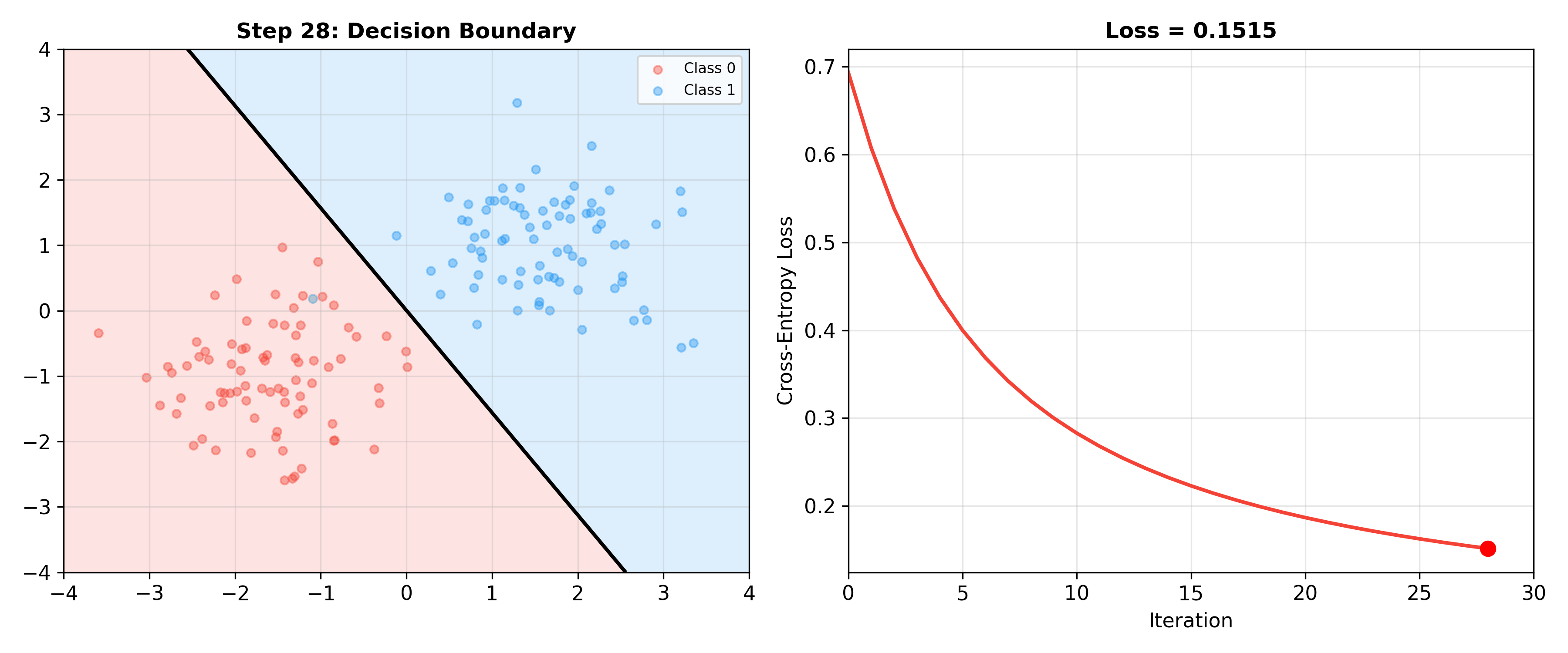
下面的动画展示了逻辑回归训练过程中决策边界如何逐步调整——随着梯度下降迭代,决策边界逐渐找到最优位置,交叉熵损失持续下降:
Logistic Regression Training
多分类决策区域
在
特征空间被划分为
模型评估与诊断
混淆矩阵与性能指标
对于二分类,定义:
TP ( True Positive):真实为正,预测为正FP ( False Positive):真实为负,预测为正TN ( True Negative):真实为负,预测为负FN ( False Negative):真实为正,预测为负
准确率 (Accuracy):
精确率 (Precision):
召回率 ( Recall):
F1 分数 :
ROC 曲线与 AUC
改变决策阈值(
真正例率 ( TPR):$ - 假正例率 (
FPR):$
ROC 曲线 :以 FPR 为横轴、 TPR 为纵轴的曲线。
AUC ( Area Under Curve): ROC
曲线下面积,度量排序能力。 AUC=1 表示完美分类器, AUC=0.5
表示随机猜测。
概率解释 : AUC
等于随机选取一对正负样本,正样本得分高于负样本的概率。
实现细节与数值稳定性
Sigmoid 函数的数值溢出
当
1 2 3 4 5 6 def stable_sigmoid (z ): if z >= 0 : return 1 / (1 + np.exp(-z)) else : exp_z = np.exp(z) return exp_z / (1 + exp_z)
Softmax 的数值稳定性
直接计算
取
1 2 3 4 def stable_softmax (z ): z_max = np.max (z, axis=-1 , keepdims=True ) exp_z = np.exp(z - z_max) return exp_z / np.sum (exp_z, axis=-1 , keepdims=True )
完整训练代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 import numpy as npclass LogisticRegression : def __init__ (self, learning_rate=0.01 , n_iterations=1000 , regularization='l2' , lambda_reg=0.01 ): self.lr = learning_rate self.n_iter = n_iterations self.reg = regularization self.lambda_reg = lambda_reg self.w = None def sigmoid (self, z ): return np.where(z >= 0 , 1 / (1 + np.exp(-z)), np.exp(z) / (1 + np.exp(z))) def fit (self, X, y ): N, d = X.shape self.w = np.zeros(d) for _ in range (self.n_iter): z = X @ self.w y_hat = self.sigmoid(z) grad = X.T @ (y_hat - y) / N if self.reg == 'l2' : grad += self.lambda_reg * self.w elif self.reg == 'l1' : grad += self.lambda_reg * np.sign(self.w) self.w -= self.lr * grad def predict_proba (self, X ): return self.sigmoid(X @ self.w) def predict (self, X, threshold=0.5 ): return (self.predict_proba(X) >= threshold).astype(int ) if __name__ == '__main__' : from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, roc_auc_score X, y = make_classification(n_samples=1000 , n_features=20 , n_informative=15 , n_redundant=5 , random_state=42 ) X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2 , random_state=42 ) model = LogisticRegression(learning_rate=0.1 , n_iterations=1000 , regularization='l2' , lambda_reg=0.01 ) model.fit(X_train, y_train) y_pred = model.predict(X_test) y_prob = model.predict_proba(X_test) print (f"准确率: {accuracy_score(y_test, y_pred):.4 f} " ) print (f"AUC: {roc_auc_score(y_test, y_prob):.4 f} " )
多分类实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 class SoftmaxRegression : def __init__ (self, learning_rate=0.01 , n_iterations=1000 , lambda_reg=0.01 ): self.lr = learning_rate self.n_iter = n_iterations self.lambda_reg = lambda_reg self.W = None def softmax (self, Z ): """稳定的 Softmax 计算""" Z_max = np.max (Z, axis=1 , keepdims=True ) exp_Z = np.exp(Z - Z_max) return exp_Z / np.sum (exp_Z, axis=1 , keepdims=True ) def fit (self, X, y ): N, d = X.shape K = len (np.unique(y)) self.W = np.zeros((d, K)) Y_one_hot = np.zeros((N, K)) Y_one_hot[np.arange(N), y] = 1 for _ in range (self.n_iter): Z = X @ self.W Y_hat = self.softmax(Z) grad = X.T @ (Y_hat - Y_one_hot) / N grad += self.lambda_reg * self.W self.W -= self.lr * grad def predict_proba (self, X ): Z = X @ self.W return self.softmax(Z) def predict (self, X ): return np.argmax(self.predict_proba(X), axis=1 ) if __name__ == '__main__' : from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score X, y = make_classification(n_samples=1000 , n_features=20 , n_informative=15 , n_redundant=5 , n_classes=5 , random_state=42 ) X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2 , random_state=42 ) model = SoftmaxRegression(learning_rate=0.1 , n_iterations=1000 , lambda_reg=0.01 ) model.fit(X_train, y_train) y_pred = model.predict(X_test) print (f"准确率: {accuracy_score(y_test, y_pred):.4 f} " )
与其他分类器的联系
与感知机的关系
感知机更新规则:
其中
与线性判别分析( LDA)的关系
LDA
假设每类数据服从高斯分布,且协方差矩阵相同。在此假设下,后验概率为:
形式与逻辑回归相同。区别: -
LDA :生成式模型,估计逻辑回归 :判别式模型,直接估计
与神经网络的关系
逻辑回归可视为单层神经网络 :
输 入 线 性 变 换 激 活
Softmax
回归是单层多类神经网络 ,是深度学习的基石。
进阶主题
类别不平衡问题
当正负样本比例严重失衡(如
1. 调整决策阈值 :根据业务需求调整
2. 重采样 : - 上采样少数类( SMOTE 等) -
下采样多数类
3. 损失加权 :
其中
在线学习与流式数据
对于流式到达的数据,使用随机梯度下降 逐个更新:
适合大规模或实时场景。
多标签分类
每个样本可属于多个类别(如文本标注)。对每个标签
损失为各标签交叉熵之和:
Q&A 精选
Q1:为什么叫"逻辑回归"而不是"逻辑分类"?
A:历史原因。逻辑回归最早用于回归问题的概率建模,通过 Logistic
函数(即
Sigmoid)将线性模型输出映射到概率。后来发现其更适合分类任务,但名称保留至今。
Q2:逻辑回归与线性回归的本质区别是什么?
A:核心区别在于输出空间与损失函数 : -
线性回归:Extra close brace or missing open brace y \in \{0,1\\}
两者都是广义线性模型 (
GLM)的特例,只是链接函数和假设分布不同。
Q3:为什么交叉熵比 MSE 更适合分类?
A:MSE 的梯度含有
Q4:逻辑回归能拟合非线性边界吗?
A:原始逻辑回归是线性分类器,决策边界为超平面。但可通过: -
特征工程 :添加多项式特征(如核方法 :隐式映射到高维空间 -
神经网络 :多层逻辑回归堆叠
实现非线性分类。
Q5: Softmax 与多个独立 Sigmoid 的区别?
A: - Softmax :各类别概率归一化,互斥多分类 (单标签) - 多
Sigmoid :各标签独立,概率和可多标签分类
例如新闻分类(单类别)用 Softmax,标签推荐(多标签)用多
Sigmoid。
Q6:正则化参数
A:通过交叉验证 网格搜索:
候选值:
对每个
选择验证误差最小的
一般
Q7:逻辑回归为什么是凸优化问题?
A: Hessian 矩阵的 对 角 元 素
这是逻辑回归的重要优势。
Q8:逻辑回归能处理缺失值吗?
A:标准逻辑回归不直接支持。常见处理方法: -
删除 :删除含缺失值的样本(损失信息) -
填充 :用均值/中位数/众数填充 -
指示变量 :为缺失特征添加二元指示器 -
模型预测 :用其他特征预测缺失值
或使用支持缺失值的算法(如 XGBoost)。
Q9:为什么需要特征标准化?
A:不同特征量纲不同(如年龄[0,100]vs 收入[0,1e6]),导致: 1.
梯度数值范围差异大,需要极小学习率 2. 某些特征主导权重更新 3.
正则化不公平(惩罚大量纲特征)
标准化(
Q10:逻辑回归与 SVM 的区别?
A: | 维度 | 逻辑回归 | SVM | |------|----------|-----| | 损失 |
交叉熵 | Hinge Loss | | 输出 | 概率 | 决策值 | | 支持向量 | 所有样本参与
| 仅边界样本 | | 核技巧 | 不直接支持 | 天然支持 | | 凸性 | 严格凸 | 凸
|
逻辑回归适合概率预测, SVM 适合硬分类与非线性边界。
Q11:如何解释逻辑回归的系数?
A:权重
-
几率比 :
Q12:逻辑回归的时间复杂度是多少?
A: - 单次迭代 :总训练 :预测 :
对于大规模数据,使用随机梯度下降(
SGD)或小批量梯度下降,单次迭代降至
实验与案例
案例 1:垃圾邮件分类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import numpy as npfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import classification_reportemails = [ "Win a free iPhone now!" , "Meeting at 3pm tomorrow" , "You have won$1,000,000!" , "Project deadline reminder" , ] labels = [1 , 0 , 1 , 0 , ...] vectorizer = TfidfVectorizer(max_features=1000 ) X = vectorizer.fit_transform(emails).toarray() X_train, X_test, y_train, y_test = train_test_split( X, labels, test_size=0.2 , random_state=42 ) model = LogisticRegression(learning_rate=0.1 , n_iterations=1000 , regularization='l2' , lambda_reg=0.1 ) model.fit(X_train, y_train) y_pred = model.predict(X_test) print (classification_report(y_test, y_pred))feature_names = vectorizer.get_feature_names_out() top_indices = np.argsort(np.abs (model.w))[-10 :] print ("最相关词语:" , feature_names[top_indices])
案例 2:医疗诊断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from sklearn.datasets import load_breast_cancerfrom sklearn.preprocessing import StandardScalerfrom sklearn.metrics import roc_curve, aucimport matplotlib.pyplot as pltdata = load_breast_cancer() X, y = data.data, data.target scaler = StandardScaler() X = scaler.fit_transform(X) X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2 , random_state=42 ) lambdas = [0 , 0.01 , 0.1 , 1.0 ] for lam in lambdas: model = LogisticRegression(learning_rate=0.1 , n_iterations=1000 , regularization='l2' , lambda_reg=lam) model.fit(X_train, y_train) y_prob = model.predict_proba(X_test) fpr, tpr, _ = roc_curve(y_test, y_prob) roc_auc = auc(fpr, tpr) plt.plot(fpr, tpr, label=f'λ={lam} (AUC={roc_auc:.3 f} )' ) plt.plot([0 ,1 ], [0 ,1 ], 'k--' , label='Random' ) plt.xlabel('False Positive Rate' ) plt.ylabel('True Positive Rate' ) plt.title('ROC Curves with Different Regularizations' ) plt.legend() plt.show()
✏️ 练习题与解答
练习 1:Sigmoid 函数性质
题目 :证明 Sigmoid 函数
解答 :
导数 :
对称性 :
这个性质非常重要——它意味着
练习 2:交叉熵损失推导
题目 :从最大似然估计出发,推导二分类逻辑回归的交叉熵损失函数。
解答 :
设
对数似然:
最大化对数似然等价于最小化负对数似然,即交叉熵损失:
练习 3:Softmax 梯度
题目 :推导 Softmax 回归中,损失函数对 logit
解答 :
Softmax:
首先求
当
当
因此:
这个优美的结果(
练习 4:正则化的贝叶斯解释
题目 :说明 L2
正则化逻辑回归对应于什么样的先验分布?L1 正则化呢?
解答 :
L2 正则化 :
对应高斯先验
L1 正则化 :
对应拉普拉斯先验
拉普拉斯先验在零处有尖峰,这就是 L1 能产生稀疏解的原因——MAP
估计倾向于将小系数精确设为零。
练习 5:决策边界的几何意义
题目 :证明逻辑回归的决策边界
解答 :
这是一个法向量为
点
参考文献
Bishop, C. M. (2006). Pattern Recognition and
Machine Learning . Springer. [Chapter 4: Linear Models for
Classification]Hastie, T., Tibshirani, R., & Friedman, J.
(2009). The Elements of Statistical Learning (2nd ed.).
Springer. [Chapter 4: Linear Methods for Classification]Murphy, K. P. (2012). Machine Learning: A
Probabilistic Perspective . MIT Press. [Chapter 8: Logistic
Regression]Goodfellow, I., Bengio, Y., & Courville, A.
(2016). Deep Learning . MIT Press. [Chapter 5: Machine Learning
Basics]Ng, A. Y., & Jordan, M. I. (2002). On
discriminative vs. generative classifiers: A comparison of logistic
regression and naive Bayes. Advances in Neural Information
Processing Systems , 14.Hosmer, D. W., Lemeshow, S., & Sturdivant, R.
X. (2013). Applied Logistic Regression (3rd ed.).
Wiley.Wright, R. E. (1995). Logistic regression. In
Reading and Understanding Multivariate Statistics (pp.
217-244). American Psychological Association.
逻辑回归以其简洁的数学形式、清晰的概率解释和高效的优化算法,成为分类任务的基准模型。从
Sigmoid 到
Softmax,从梯度下降到正则化,本章完整推导了逻辑回归的理论框架。理解逻辑回归不仅是掌握经典机器学习的基础,更是深入神经网络与深度学习的必经之路——毕竟,深度神经网络的每一层都蕴含着逻辑回归的影子。