支持向量机(SVM)是现代机器学习最优雅的算法之一——它将几何直觉、凸优化理论和核方法完美融合,通过寻找最大间隔超平面实现高效分类。从线性可分到非线性映射,从硬间隔到软间隔,从原始形式到对偶问题,
SVM 的数学推导展现了机器学习理论的深度与美感。本章将系统推导 SVM
的完整理论框架,包括拉格朗日对偶、 KKT 条件、 SMO
算法、核函数构造与理论保证。
线性可分支持向量机
几何直觉:最大间隔分类器
考虑二分类问题:
决策函数为
函数间隔 :样本
函数间隔为正表示分类正确,且值越大表示越自信。
几何间隔 :样本
推导 :超平面
这是高等代数中点到超平面距离的标准公式。加上标签
最大间隔优化问题
硬间隔 SVM 的目标是找到间隔最大的分离超平面:
等价地,可固定函数间隔
这是一个凸二次规划 问题( Convex Quadratic
Programming, QP)。
支持向量 :满足支持向量 (Support Vectors,
SVs),它们位于间隔边界上,决定了超平面的位置。其余样本(
对偶问题推导
使用拉格朗日乘数法,引入非负乘子
原始问题 :
对偶问题 :
步骤 1:对
步骤 2:代入得对偶目标函数
对偶问题 :
等价地,写成最小化形式:
KKT 条件
由于原始问题是凸优化且满足 Slater 条件,强对偶性成立。最优解
原始可行性 :对偶可行性 :互补松弛 :拉格朗日平稳 :
关键洞察 :互补松弛条件表明: - 若
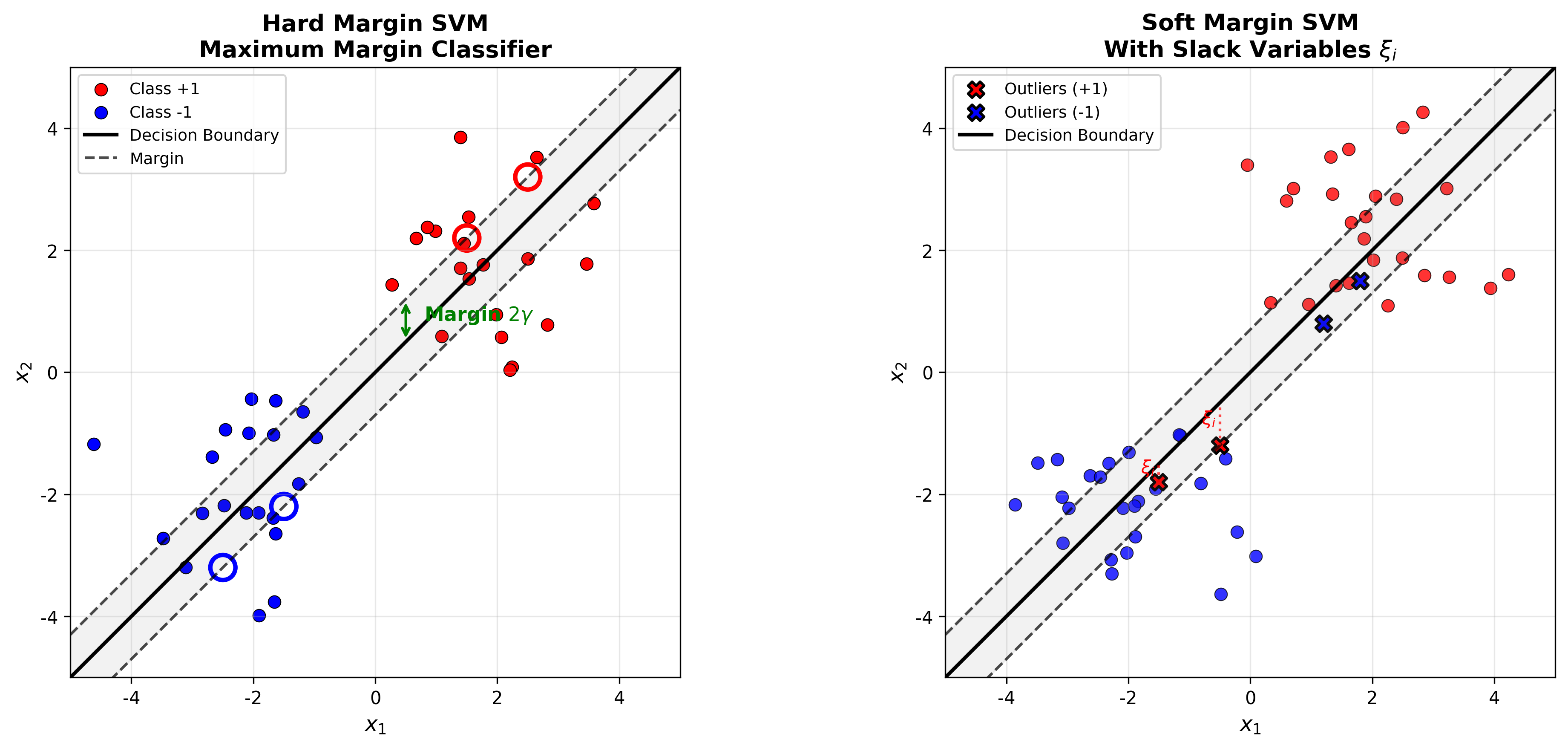
下图展示了硬间隔 SVM
的几何原理——找到使间隔最大化的分离超平面,以及支持向量的位置:
SVM Margin Geometry
因此,决策函数只依赖于支持向量:
求解偏置项
对于任意支持向量
实践中,为数值稳定性,对所有支持向量求平均:
软间隔支持向量机
松弛变量与惩罚参数
现实数据往往不是线性可分的。软间隔
SVM 允许部分样本违反间隔约束,引入松弛变量
优化问题 :
其中惩罚参数 : -
对偶问题
拉格朗日函数为:
对
由于软间隔对偶问题 :
与硬间隔的唯一区别是增加了上界约束
KKT 条件与支持向量分类
软间隔 SVM 的 KKT 条件:
支持向量分为两类: - 边界支持向量 :非边界支持向量 :
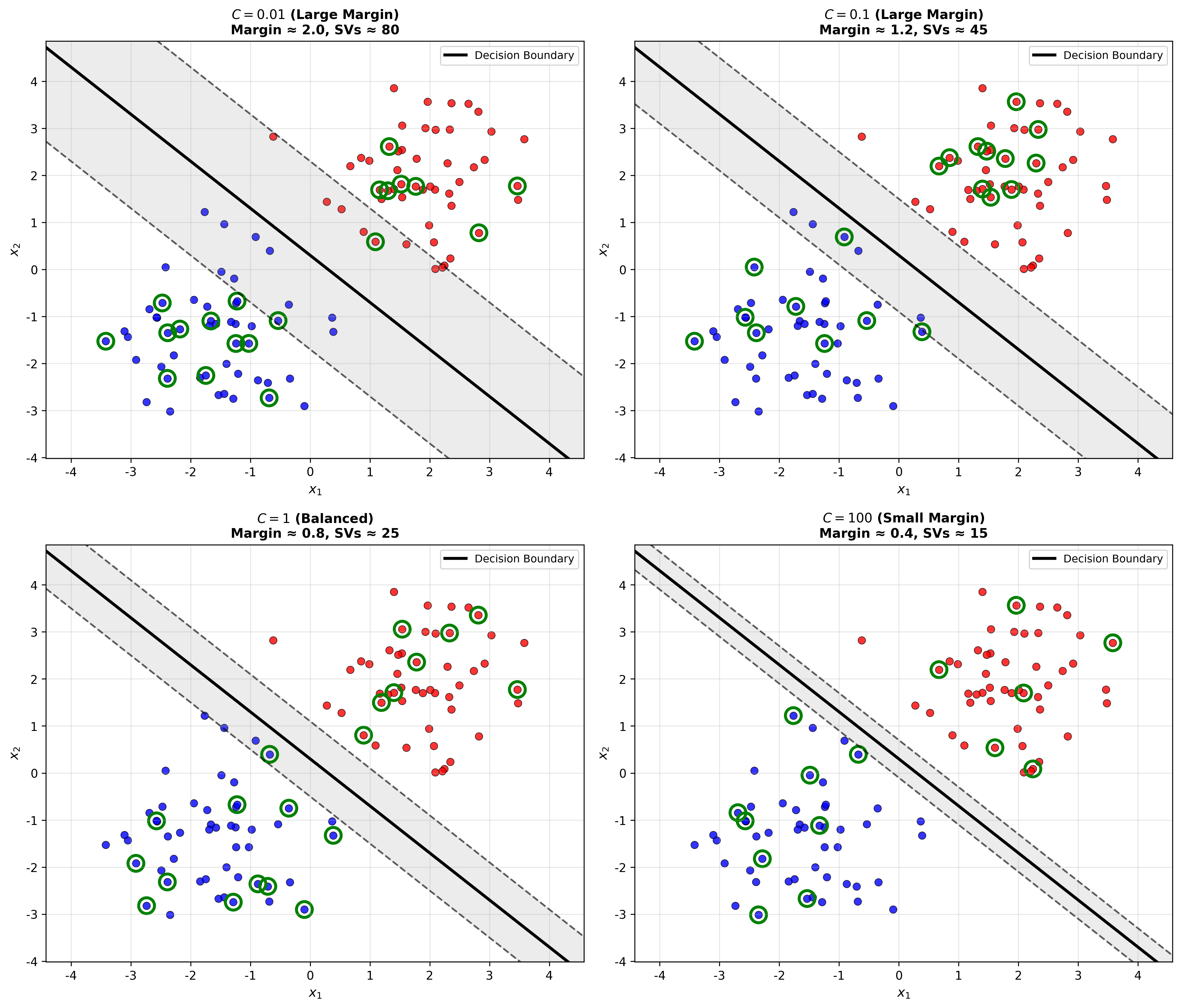
下图展示了不同
Soft Margin SVM with Different
C
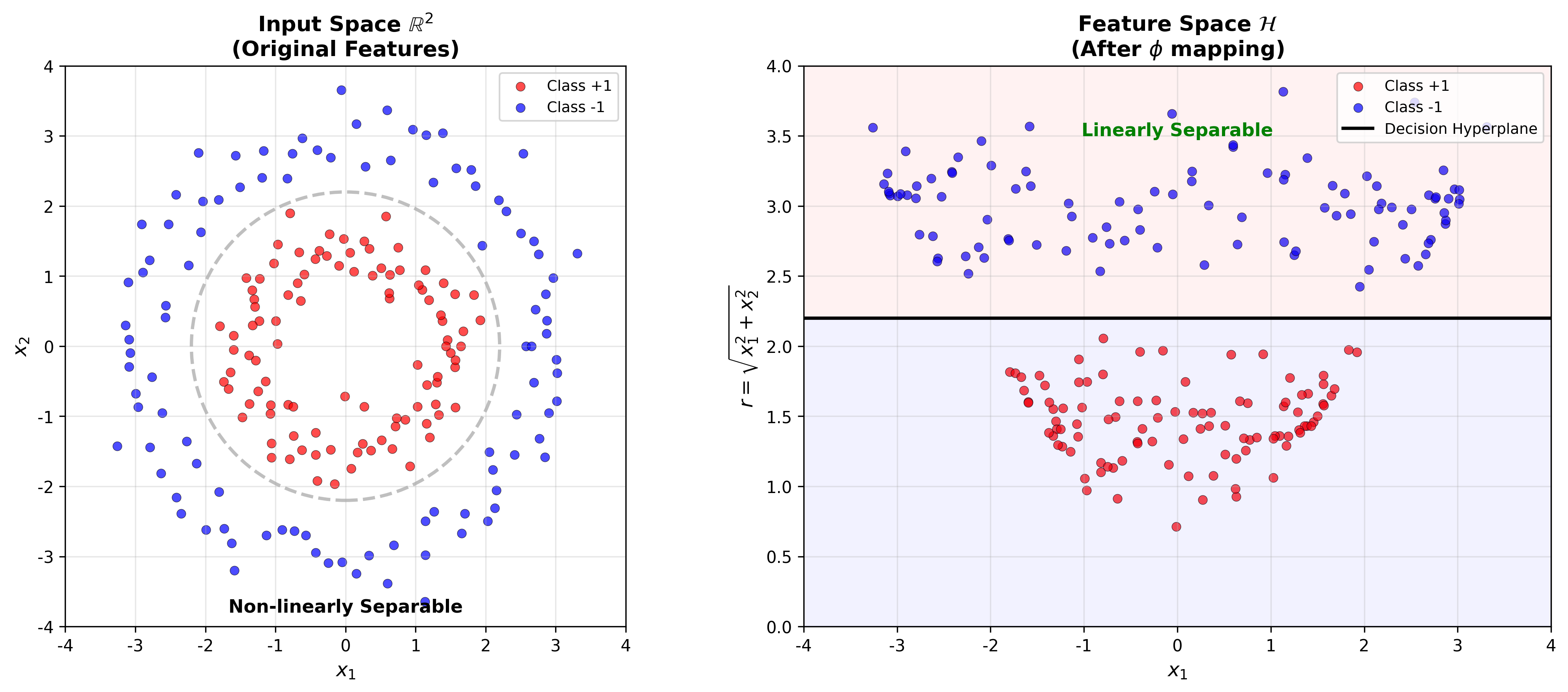
核方法与非线性 SVM
特征映射与核函数
对于非线性问题,将输入空间映射到高维特征空间:
在特征空间中进行线性分类:
对偶问题变为:
核函数 定义为:
核技巧 (Kernel Trick):无需显式计算
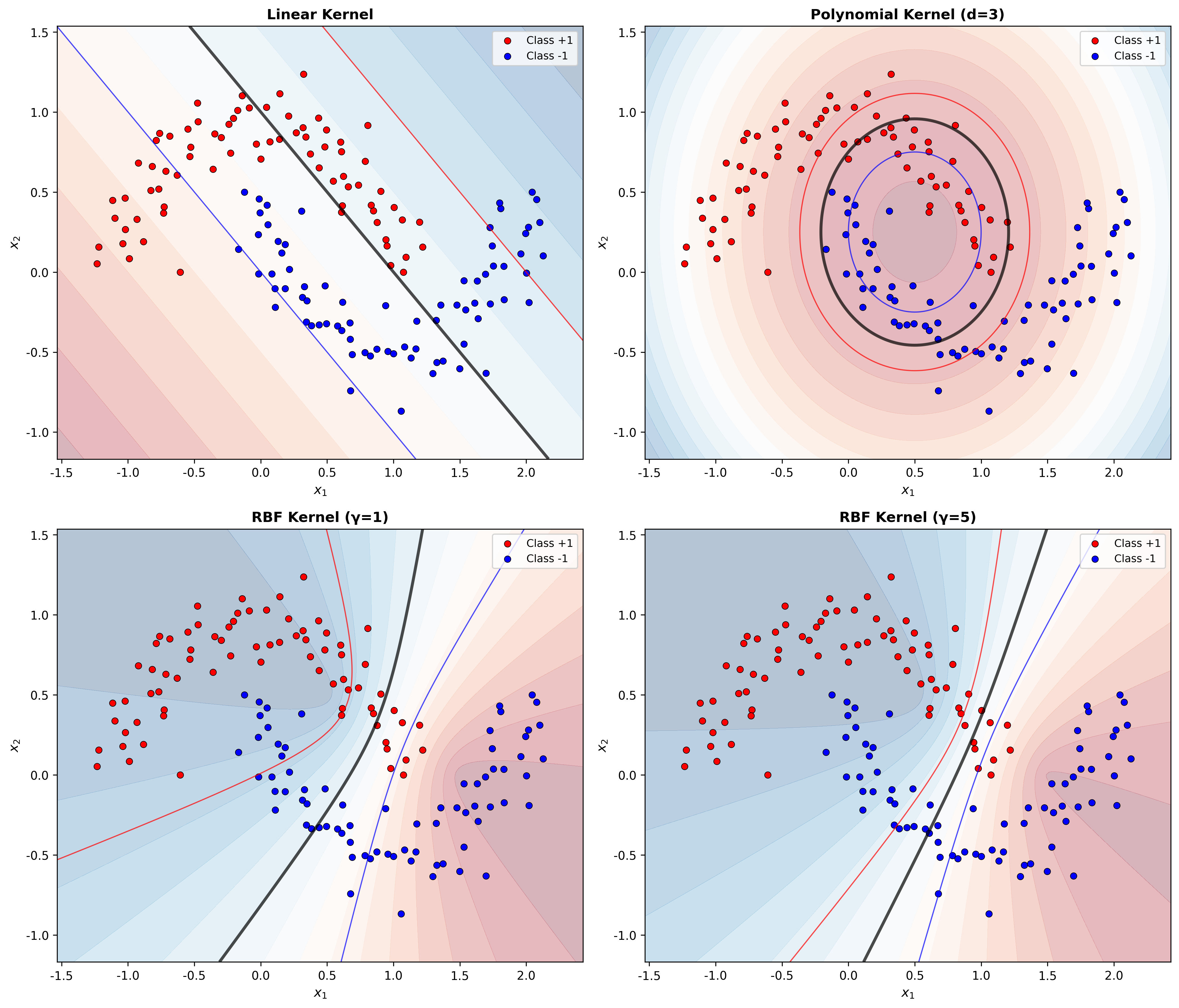
常用核函数
1. 线性核 :
2. 多项式核 :
其中
3. 高斯核(RBF 核) :
其中
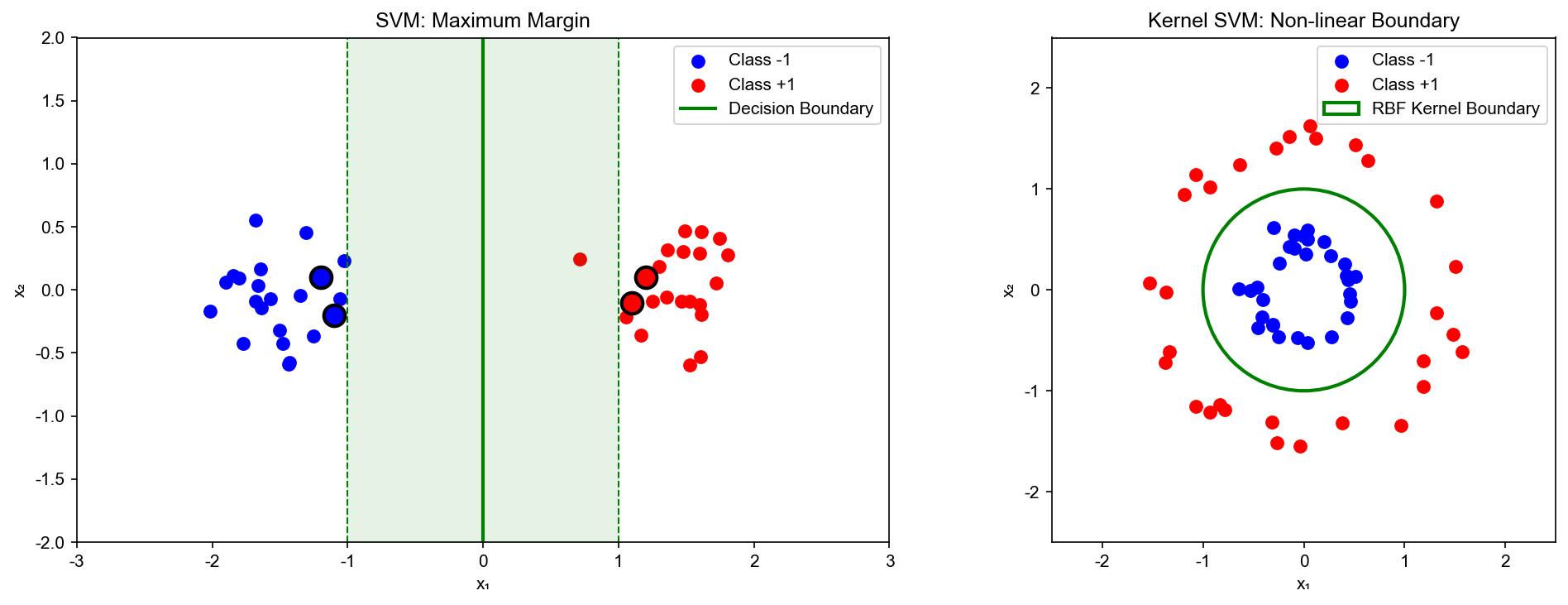
下图展示了 SVM
的核心思想:左图展示最大间隔原理,决策边界与支持向量之间的间隔最大化;右图展示软间隔如何通过引入松弛变量
Maximum Margin Illustration
下图展示了 SVM
的核心思想:左图展示最大间隔原理,决策边界与支持向量之间的间隔最大化;右图展示
RBF
核如何将非线性可分的数据(同心圆)通过核技巧映射到高维空间实现线性分离:
下图直观展示了核映射的原理——将输入空间中非线性可分的数据映射到特征空间后变为线性可分:
Kernel Transformation
下图对比了不同核函数在同一数据集上的效果:
Kernel Comparison
Figure 1
4. Sigmoid 核 :
(注:Sigmoid 核仅在特定参数下为正定核)
Mercer 定理与正定核
Mercer 定理 :对称函数
即对任意
核函数的性质 :
闭性 :若函数组合 :核外推 :
RBF 核的特征空间
RBF
核对应的特征映射维度是无限维 。证明使用泰勒展开:
每个
下图通过动画展示了不同核函数(线性核、多项式核、RBF
核)在相同数据集上的决策边界差异:
Kernel Comparison Animation
算法 :在每个节点,使用线性分类器(如感知机、SVM)找到分裂超平面。
下图展示了参数
C Parameter Effect
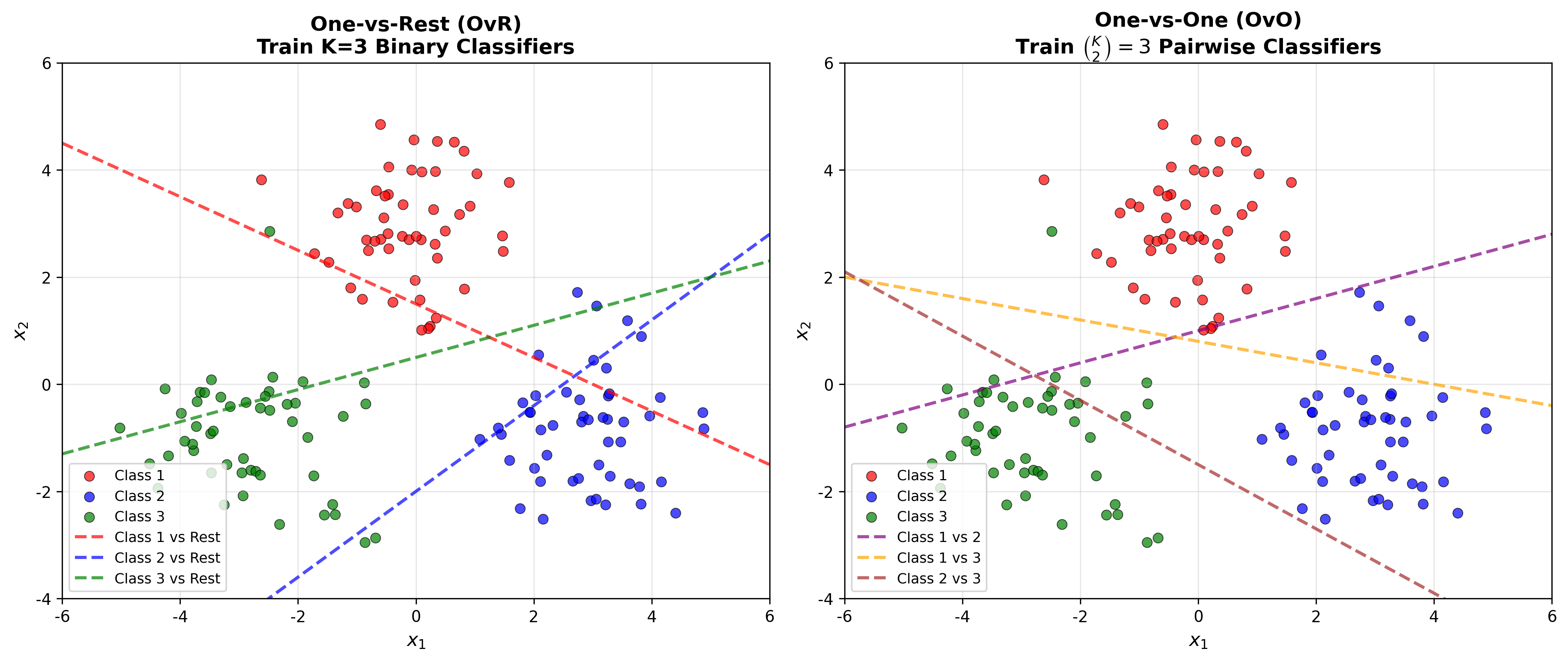
下图展示了两种主要的多分类 SVM 策略:
Multiclass Strategies
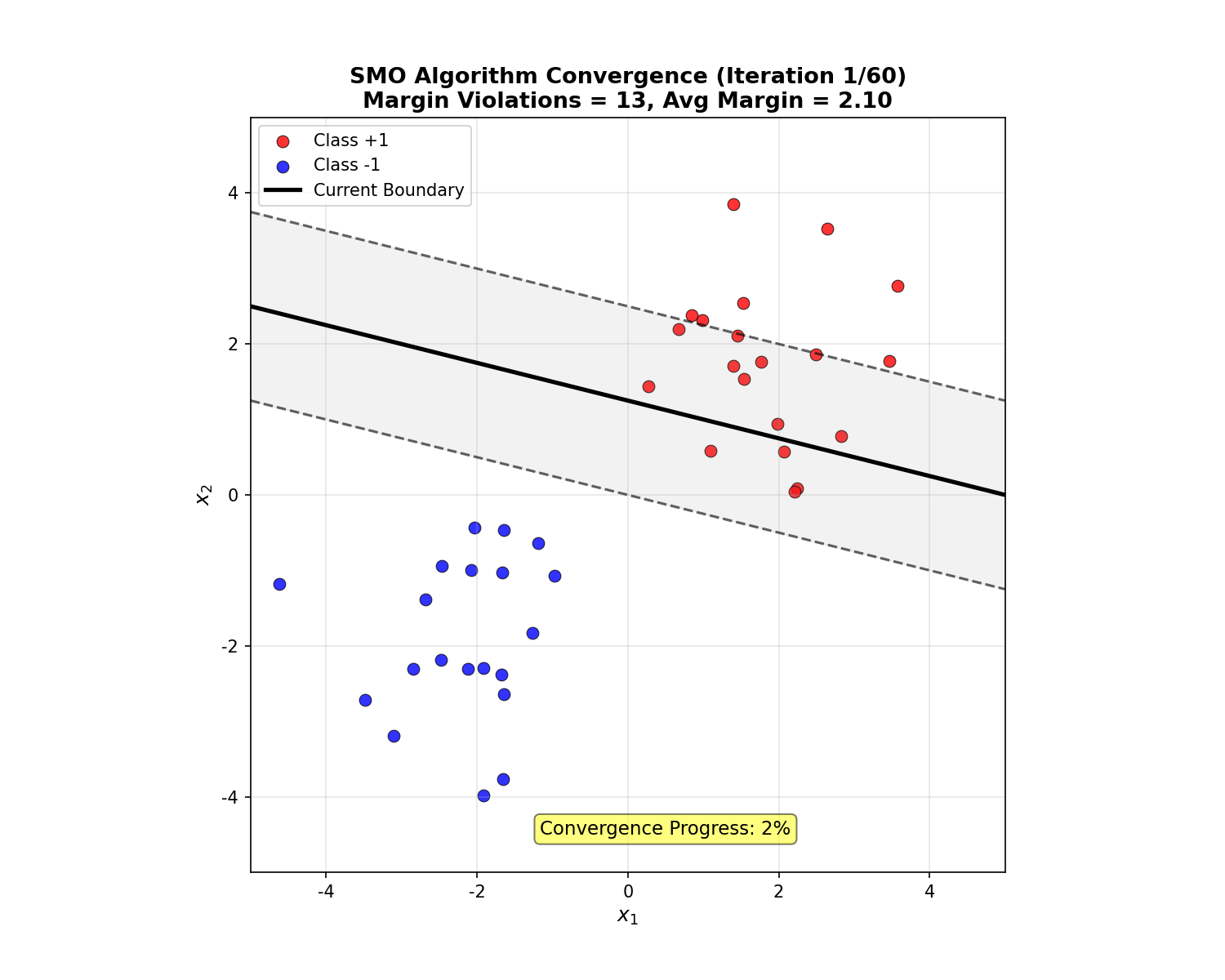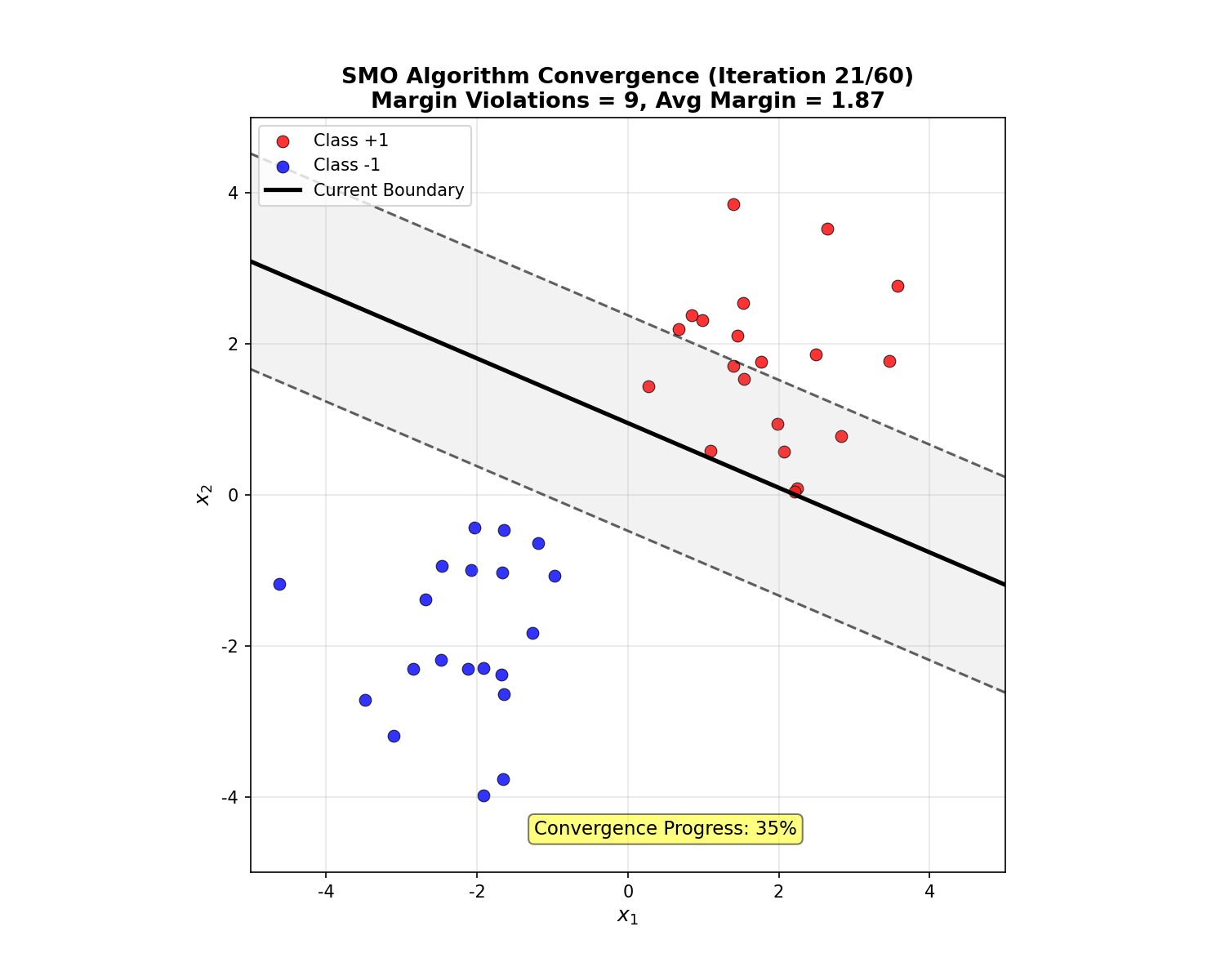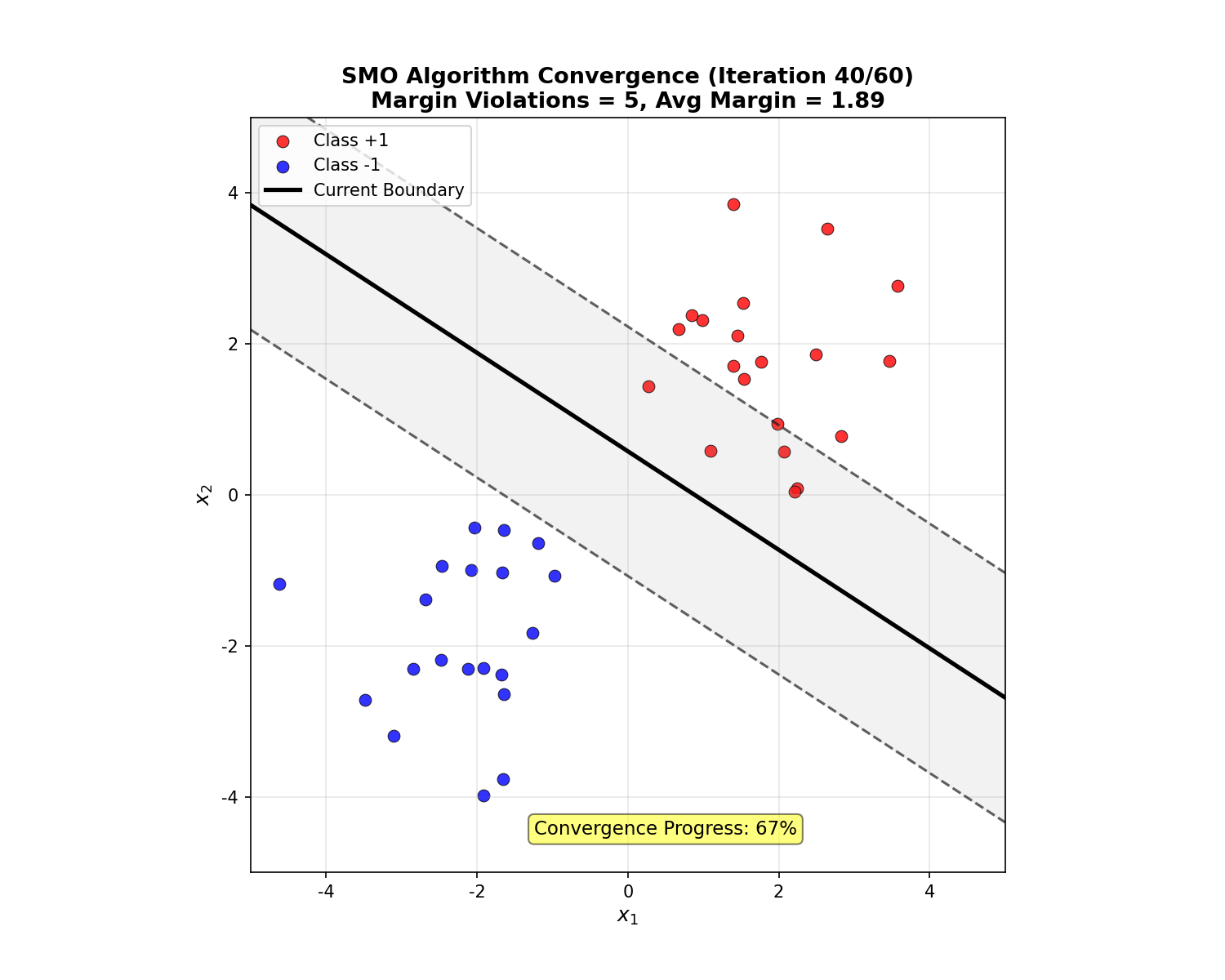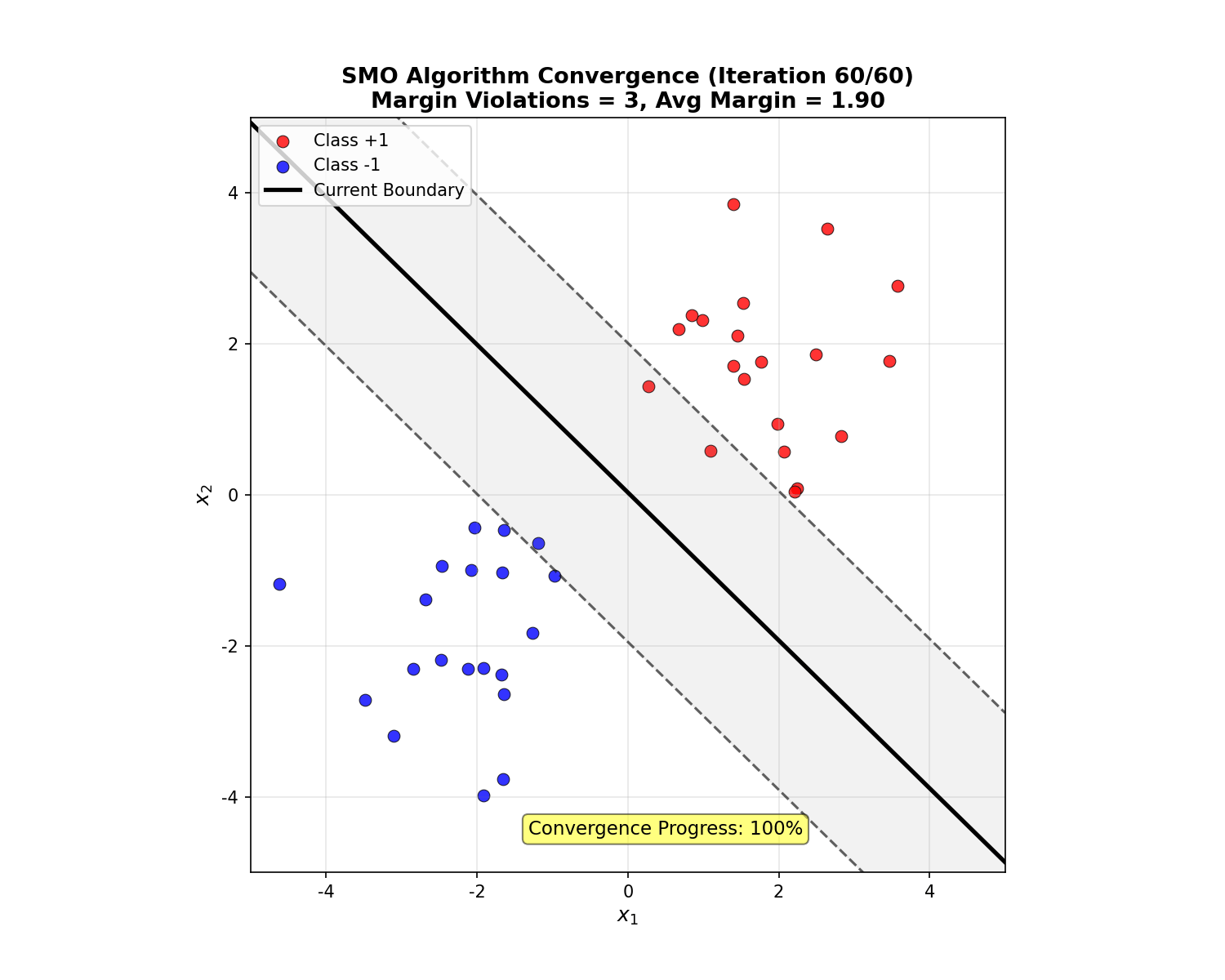
下面的动画展示了 SMO 算法的迭代收敛过程:
SMO Convergence Animation
SMO 算法
坐标上升与块坐标下降
求解对偶问题
坐标上升法 :每次优化一个变量,固定其余。但由于等式约束
SMO 算法 (Sequential Minimal Optimization, Platt
1998):每次选择两个变量
SMO 的两变量子问题
假设选定
常 数
消元 :由
(利用
代入目标函数,变为关于
无约束最优解 :
其中: -
裁剪 :确保
其中
更新 :
启发式选择策略
第一个变量 :选择违反 KKT 条件最严重的样本
第二个变量 :选择使
SVM 的统计学习理论
VC 维与泛化误差界
对于超平面分类器,VC 维为
间隔理论 :设数据集在半径
间隔越大,VC 维越小,泛化能力越强。
下图展示了 SVM 的 Hinge 损失与逻辑回归的交叉熵损失的对比:
Loss Function Comparison
结构风险最小化
SVM 实现了结构风险最小化 (Structural Risk
Minimization, SRM):
经 验 风 险 复 杂 度 惩 罚
对于软间隔 SVM,目标函数可改写为:
其中Hinge 损失 。
多分类 SVM
One-vs-Rest (OvR)
训练
其中
One-vs-One (OvO)
训练
DAGSVM 与纠错输出编码
DAGSVM :使用有向无环图组织 OvO
分类器,预测复杂度从
纠错输出编码 (ECOC):为每个类别分配二进制码字,训练多个二分类器对应码字的每一位。预测时选择汉明距离最小的类别。
完整实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 import numpy as npclass SVM : def __init__ (self, C=1.0 , kernel='linear' , gamma=0.1 , degree=3 , coef0=0 , tol=1e-3 , max_iter=1000 ): self.C = C self.kernel_type = kernel self.gamma = gamma self.degree = degree self.coef0 = coef0 self.tol = tol self.max_iter = max_iter def kernel (self, X1, X2 ): """计算核矩阵""" if self.kernel_type == 'linear' : return X1 @ X2.T elif self.kernel_type == 'poly' : return (self.gamma * X1 @ X2.T + self.coef0) ** self.degree elif self.kernel_type == 'rbf' : X1_norm = np.sum (X1 ** 2 , axis=1 ).reshape(-1 , 1 ) X2_norm = np.sum (X2 ** 2 , axis=1 ).reshape(1 , -1 ) K = X1_norm + X2_norm - 2 * X1 @ X2.T return np.exp(-self.gamma * K) elif self.kernel_type == 'sigmoid' : return np.tanh(self.gamma * X1 @ X2.T + self.coef0) def fit (self, X, y ): """SMO 算法训练 SVM""" N, d = X.shape self.X = X self.y = y self.alpha = np.zeros(N) self.b = 0 self.K = self.kernel(X, X) self.errors = self._decision_function(X) - y num_changed = 0 examine_all = True iter_count = 0 while (num_changed > 0 or examine_all) and iter_count < self.max_iter: num_changed = 0 if examine_all: for i in range (N): num_changed += self._examine_example(i) else : non_bound_indices = np.where((self.alpha > 0 ) & (self.alpha < self.C))[0 ] for i in non_bound_indices: num_changed += self._examine_example(i) if examine_all: examine_all = False elif num_changed == 0 : examine_all = True iter_count += 1 sv_indices = np.where(self.alpha > 1e-5 )[0 ] self.support_vectors_ = X[sv_indices] self.support_labels_ = y[sv_indices] self.support_alpha_ = self.alpha[sv_indices] return self def _decision_function (self, X ): """计算决策函数值""" K = self.kernel(self.X, X) return (self.alpha * self.y) @ K + self.b def _examine_example (self, i2 ): """检查并优化第 i2 个样本""" y2 = self.y[i2] alpha2 = self.alpha[i2] E2 = self.errors[i2] r2 = E2 * y2 if (r2 < -self.tol and alpha2 < self.C) or (r2 > self.tol and alpha2 > 0 ): non_bound = np.where((self.alpha > 0 ) & (self.alpha < self.C))[0 ] if len (non_bound) > 1 : i1 = np.argmax(np.abs (self.errors - E2)) if self._take_step(i1, i2): return 1 for i1 in np.roll(non_bound, np.random.randint(len (non_bound))): if self._take_step(i1, i2): return 1 for i1 in np.roll(range (len (self.y)), np.random.randint(len (self.y))): if self._take_step(i1, i2): return 1 return 0 def _take_step (self, i1, i2 ): """优化 alpha[i1]和 alpha[i2]""" if i1 == i2: return False alpha1, alpha2 = self.alpha[i1], self.alpha[i2] y1, y2 = self.y[i1], self.y[i2] E1, E2 = self.errors[i1], self.errors[i2] s = y1 * y2 if y1 != y2: L = max (0 , alpha2 - alpha1) H = min (self.C, self.C + alpha2 - alpha1) else : L = max (0 , alpha1 + alpha2 - self.C) H = min (self.C, alpha1 + alpha2) if L == H: return False k11 = self.K[i1, i1] k12 = self.K[i1, i2] k22 = self.K[i2, i2] eta = k11 + k22 - 2 * k12 if eta > 0 : alpha2_new = alpha2 + y2 * (E1 - E2) / eta alpha2_new = np.clip(alpha2_new, L, H) else : return False if abs (alpha2_new - alpha2) < 1e-5 : return False alpha1_new = alpha1 + s * (alpha2 - alpha2_new) b1 = E1 + y1 * (alpha1_new - alpha1) * k11 + y2 * (alpha2_new - alpha2) * k12 + self.b b2 = E2 + y1 * (alpha1_new - alpha1) * k12 + y2 * (alpha2_new - alpha2) * k22 + self.b if 0 < alpha1_new < self.C: b_new = b1 elif 0 < alpha2_new < self.C: b_new = b2 else : b_new = (b1 + b2) / 2 delta_b = b_new - self.b delta_alpha1 = alpha1_new - alpha1 delta_alpha2 = alpha2_new - alpha2 self.errors += y1 * delta_alpha1 * self.K[:, i1] + y2 * delta_alpha2 * self.K[:, i2] + delta_b self.errors[i1] = 0 self.errors[i2] = 0 self.alpha[i1] = alpha1_new self.alpha[i2] = alpha2_new self.b = b_new return True def predict (self, X ): """预测""" decision = self._decision_function(X) return np.sign(decision) def score (self, X, y ): """计算准确率""" return np.mean(self.predict(X) == y) if __name__ == '__main__' : from sklearn.datasets import make_classification, make_moons from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt X, y = make_classification(n_samples=100 , n_features=2 , n_redundant=0 , n_informative=2 , n_clusters_per_class=1 , random_state=42 ) y = 2 * y - 1 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2 , random_state=42 ) svm_linear = SVM(C=1.0 , kernel='linear' ) svm_linear.fit(X_train, y_train) print (f"线性核准确率: {svm_linear.score(X_test, y_test):.4 f} " ) X, y = make_moons(n_samples=100 , noise=0.1 , random_state=42 ) y = 2 * y - 1 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2 , random_state=42 ) svm_rbf = SVM(C=1.0 , kernel='rbf' , gamma=1.0 ) svm_rbf.fit(X_train, y_train) print (f"RBF 核准确率: {svm_rbf.score(X_test, y_test):.4 f} " )
Q&A 精选
Q1:为什么 SVM 要最大化间隔?
A:几何直觉上,间隔越大,分类器对噪声越鲁棒。统计学习理论表明,间隔
Q2:对偶问题比原始问题有什么优势?
A:1) 对偶问题只依赖于样本内积
Q3:为什么只有支持向量影响决策边界?
A:由 KKT 互补松弛条件,非支持向量满足
Q4:软间隔的参数
A:通过交叉验证。
Q5:RBF 核的参数
A:
Q6:为什么 SVM 对特征缩放敏感?
A:SVM 通过欧氏距离计算间隔(
Q7: SVM 能处理多标签分类吗?
A:标准 SVM
是二分类器。对于多标签(每个样本属于多个类别),可训练
Q8: SMO 算法为什么高效?
A:SMO 避免了求解大规模 QP 问题(复杂度
Q9: SVM 与逻辑回归的区别?
A: | 维度 | SVM | 逻辑回归 | |------|-----|----------| | 损失 |
Hinge Loss | Cross-Entropy | | 输出 | 决策值(距离) | 概率 | | 稀疏性 |
支持向量(稀疏) | 所有样本参与 | | 核方法 | 天然支持 | 需修改 | |
多分类 | OvR/OvO | Softmax |
SVM 适合硬分类与非线性边界,逻辑回归适合概率预测与大规模数据。
Q10:如何可视化 SVM 的决策边界?
A:对于 2D 数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def plot_svm_boundary (svm, X, y ): x_min, x_max = X[:, 0 ].min () - 1 , X[:, 0 ].max () + 1 y_min, y_max = X[:, 1 ].min () - 1 , X[:, 1 ].max () + 1 xx, yy = np.meshgrid(np.linspace(x_min, x_max, 200 ), np.linspace(y_min, y_max, 200 )) Z = svm._decision_function(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) plt.contourf(xx, yy, Z, levels=[-1 , 0 , 1 ], alpha=0.3 , colors=['blue' , 'white' , 'red' ]) plt.contour(xx, yy, Z, levels=[-1 , 0 , 1 ], linewidths=[1 , 2 , 1 ], colors='k' ) plt.scatter(X[:, 0 ], X[:, 1 ], c=y, edgecolors='k' , cmap='bwr' ) plt.scatter(svm.support_vectors_[:, 0 ], svm.support_vectors_[:, 1 ], s=200 , facecolors='none' , edgecolors='k' , linewidths=2 ) plt.show()
Q11:SVM 能做回归吗?
A:可以。Support Vector Regression (SVR) 引入
只惩罚误差超过
Q12:SVM 的时间复杂度是多少?
A: - 训练 :SMO 算法平均预测 :
对于大规模数据(
✏️ 练习题与解答
练习 1:几何间隔与函数间隔
题目 :设超平面为
解答 :
函数间隔:
几何间隔:
练习 2:KKT 条件验证
题目 :在软间隔 SVM 中,若某样本
解答 :
KKT 条件要求:
但题目给出违反了 KKT
条件 。正确情况应该是边界支持向量。
练习 3:核函数验证
题目 :证明
解答 :
对于
构造特征映射:
验证:
练习
4:软间隔目标函数的等价形式
题目 :证明软间隔 SVM 等价于最小化 Hinge Loss
加正则项:
解答 :
原始问题中,约束
为最小化目标,最优的
练习 5:VC 维与间隔的关系
题目 :数据集在半径
解答 :
间隔越大,VC
维越小,泛化能力越强。这解释了为什么最大化间隔能提升泛化性能。
参考文献
Cortes, C., & Vapnik, V. (1995). Support-vector
networks. Machine Learning , 20(3), 273-297.Vapnik, V. N. (1998). Statistical Learning
Theory . Wiley.Platt, J. C. (1998). Sequential minimal
optimization: A fast algorithm for training support vector machines.
Technical Report MSR-TR-98-14, Microsoft Research.Sch ö lkopf, B., & Smola, A. J. (2002).
Learning with Kernels . MIT Press.Cristianini, N., & Shawe-Taylor, J. (2000).
An Introduction to Support Vector Machines . Cambridge
University Press.Burges, C. J. C. (1998). A tutorial on support
vector machines for pattern recognition. Data Mining and Knowledge
Discovery , 2(2), 121-167.Hastie, T., Tibshirani, R., & Friedman, J.
(2009). The Elements of Statistical Learning (2nd ed.).
Springer. [Chapter 12: Support Vector Machines]
支持向量机以其坚实的理论基础、优雅的数学形式和卓越的实战性能,成为机器学习的里程碑算法。从间隔最大化到核技巧,从对偶理论到
SMO 算法, SVM 完美诠释了理论与实践的统一。理解 SVM
不仅是掌握经典算法的需要,更是通往深度学习(许多现代损失函数借鉴 Hinge
Loss)和核方法高级主题的必经之路。