1886 年, Francis Galton 研究父母身高与子女身高的关系时,发现了一个奇特现象:极端身高的父母,其子女身高往往更接近平均值。他创造了"regression toward the mean"(向均值回归)这个术语,这就是"回归"一词的由来。但线性回归的真正力量不在于统计描述,而在于它是几乎所有机器学习算法的数学基础——从神经网络到支持向量机,都可以看作线性回归的推广。
线性回归的本质是在数据空间中寻找最优的超平面。这个看似简单的问题,背后隐藏着线性代数、概率论、优化理论的深刻联系。本章从多个角度完整推导线性回归的数学理论。
线性回归的基本形式
问题定义
预测房价的例子
场景:你是房产中介,要预测房价
历史数据: | 面积(㎡) | 距地铁(km) | 楼层 | 房价(万) | |---------|-----------|------|---------| | 100 | 0.5 | 10 | 300 | | 80 | 2.0 | 5 | 200 | | 120 | 0.2 | 15 | 450 |
直觉发现: - 面积越大 → 房价越高(正相关) - 距地铁越远 → 房价越低(负相关) - 楼层影响较小
线性回归的假设:房价和这些因素是"线性关系"(直线关系)
关键问题:如何找到最好的系数(3, -50, 2, 50)?
数学形式化
给定训练数据集
-
目标:找到参数向量
能够最好地拟合训练数据。
具体例子:
记号简化:为了统一表示,我们将偏置吸收到权重向量中。定义增广特征向量:
则模型简化为:
后续为简洁起见,我们省略波浪号,直接写为
矩阵形式
将所有训练样本组织成矩阵形式:
设计矩阵(Design Matrix):
输出向量:
预测向量:
我们的目标是找到最优的
最小二乘法:代数推导
损失函数
使用平方损失( L2 损失)衡量预测误差:
这里系数
目标:
梯度推导
计算损失函数关于
展开:
对
因此:
正规方程
令梯度为零:
这就是著名的正规方程( Normal Equation)。
定理 1(最小二乘解):如果
证明:
- 一阶必要条件:
给出 - 二阶充分条件:计算 Hessian 矩阵:
对于任意非零向量
如果
- 正定 Hessian + 零梯度 = 全局最小值。证毕。
矩阵
- 充要条件:
列满秩,即 - 等价条件: 正定 - 实际意义:
- 样本数
(样本数至少要多于特征数) - 特征之间线性无关(无完全共线性)
- 样本数
Moore-Penrose 伪逆
当
其中
性质:
- 当
可逆时, (退化为普通逆) - 是所有满足 的解中范数最小的解:
计算方法:通过奇异值分解( SVD)。设
其中 ^+
几何解释:投影视角
列空间与投影
线性回归的几何本质是正交投影。
定义:
-
定理 2(正交投影定理):
这正是正规方程!
证明:
对于任意
使用毕达哥拉斯定理(当两向量正交时):
令
因此:
等号成立当且仅当
投影矩阵
定义:投影矩阵
性质:
幂等性:
(投影两次等于投影一次) 对称性:
作用:
是 在列空间的投影
残差投影矩阵:
满足:
性质:
-
几何直觉
在
-
类比( 2 维平面投影):
想象在 3 维空间中,一个点
下图直观展示了最小二乘法的几何本质——通过正交投影将真实向量
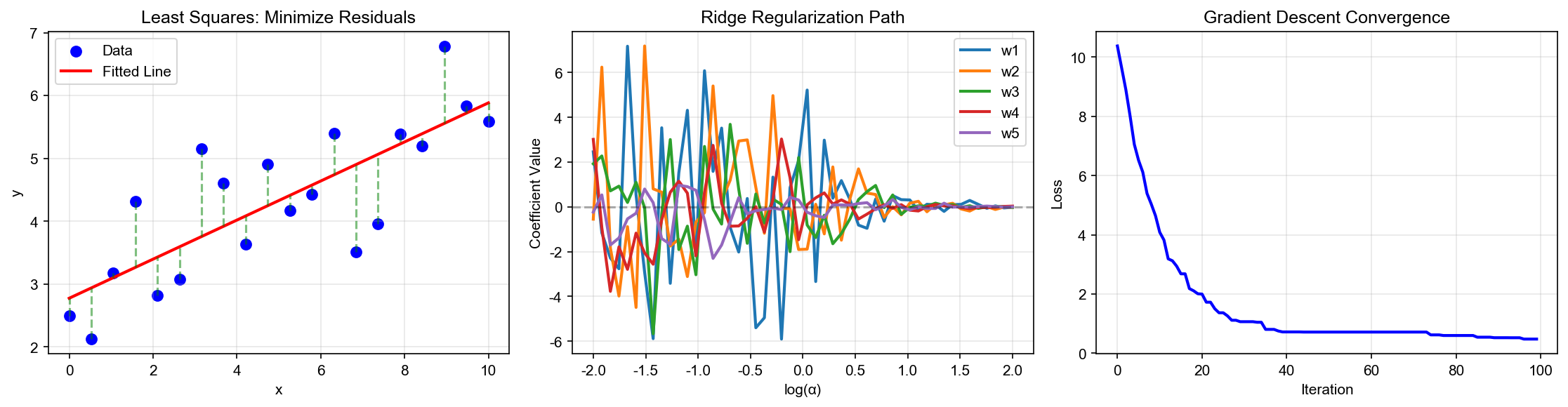
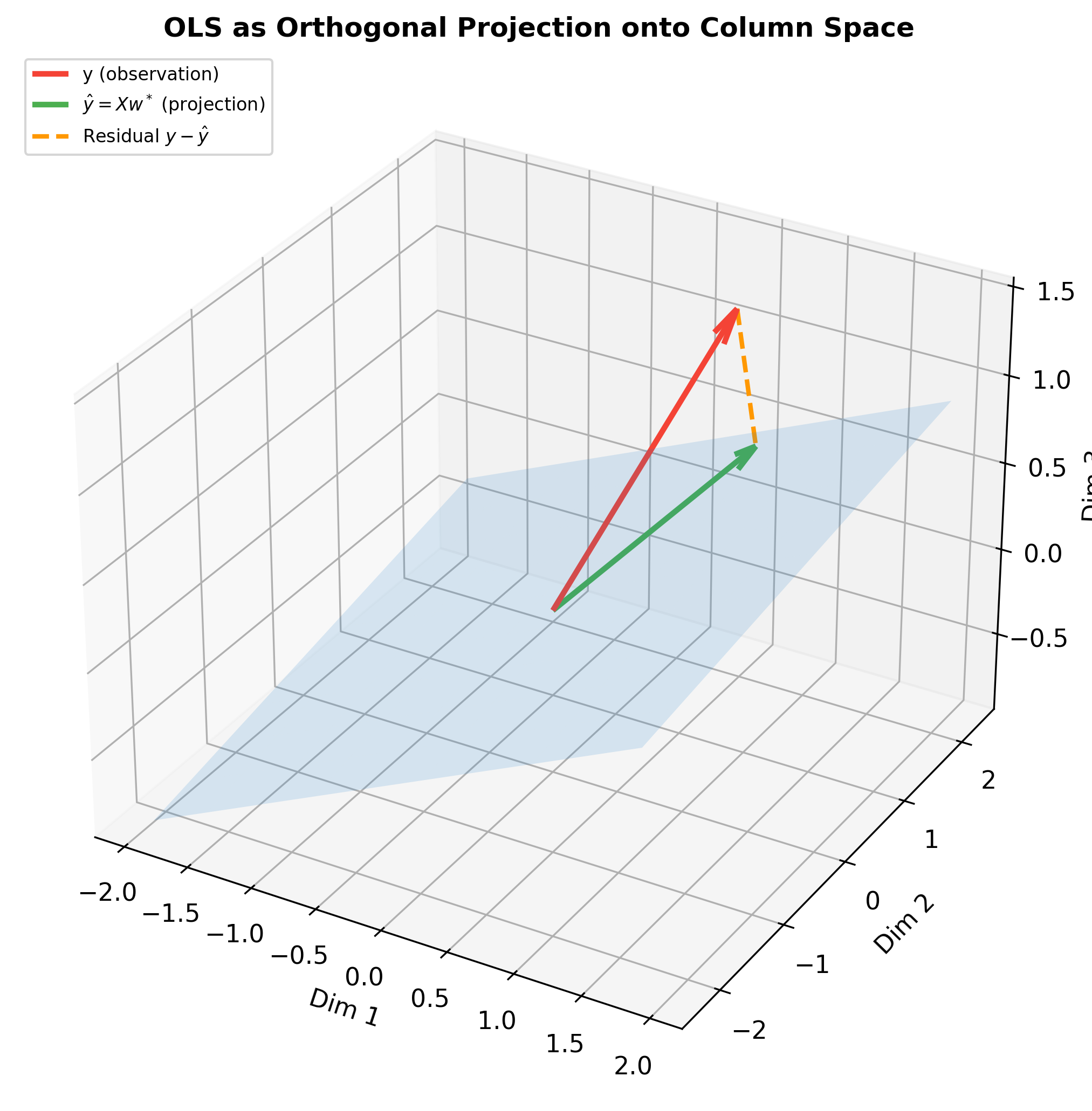
下图展示了 OLS 作为正交投影的三维视角——观测向量
概率视角:最大似然估计
线性高斯模型
假设数据生成过程为:
其中
等价形式:
即给定
似然函数
给定训练数据
对数似然
取对数(单调变换不改变最大值点):
最大似然估计
关于
最大化
这正是最小二乘目标!
定理 3:在线性高斯模型下,最大似然估计等价于最小二乘估计:
关于
固定
解得:
即噪声方差的最大似然估计是残差平方和的均值。
贝叶斯视角
引入参数的先验分布
高斯先验:假设
最大化后验概率(MAP)等价于最小化:
这正是岭回归( Ridge
Regression)的目标函数!正则化项 = ^2/
正则化: Ridge 回归与 Lasso
Ridge 回归( L2 正则化)
目标函数:
其中
梯度:
令梯度为零:
解析解:
关键观察:
- 添加
保证了 的可逆性(即使 不可逆) - 当
,退化为普通最小二乘 - 当
, (极端正则化)
矩阵视角:Ridge 回归通过添加对角项"稳定"了矩阵
Lasso 回归( L1 正则化)
目标函数:
其中
特点:
- 无解析解( L1 范数不可微)
- 需要迭代算法求解(如坐标下降、近端梯度)
- 稀疏性:部分参数会被精确压缩到 0,实现特征选择
几何解释:
在约束形式下:
L1 约束球是菱形(在高维中是超菱形),其尖角更容易与等高线相交于坐标轴上,导致稀疏解。
Elastic Net
结合 L1 和 L2:
优点:
- 保留 L1 的稀疏性
- 保留 L2 的稳定性(对共线特征友好)
正则化的效果
偏差-方差权衡:
- 无正则化(
):低偏差、高方差(过拟合) - 强正则化(
大):高偏差、低方差(欠拟合) - 最优
:通过交叉验证选择
岭迹图(Ridge Trace):
绘制
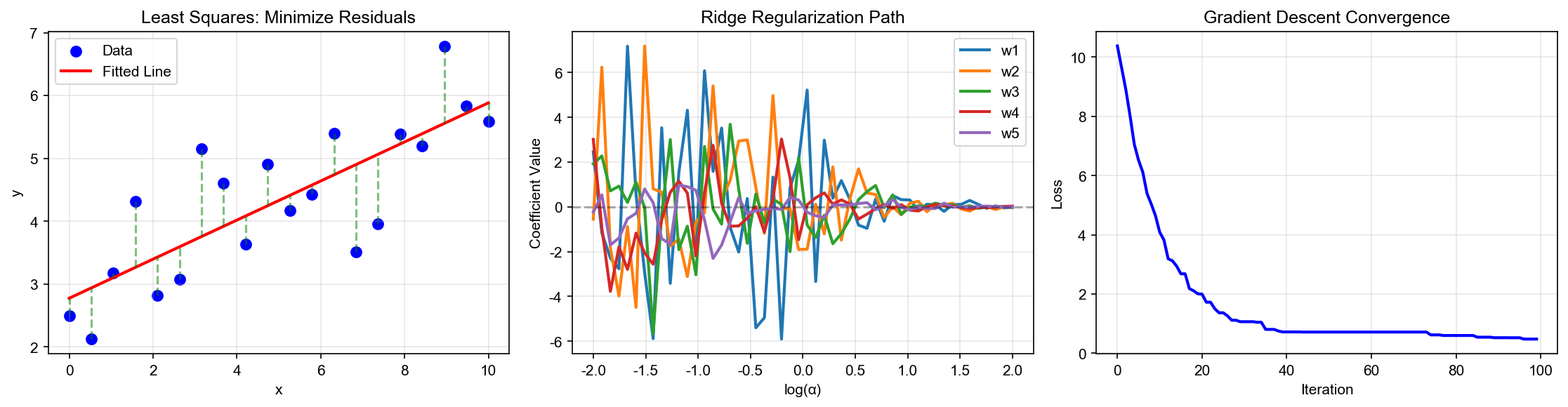
下图对比了 Ridge 和 Lasso 正则化的效果—— Ridge 使系数逐渐收缩但不为零,而 Lasso 可以将系数精确压缩到 0,实现特征选择的稀疏性:
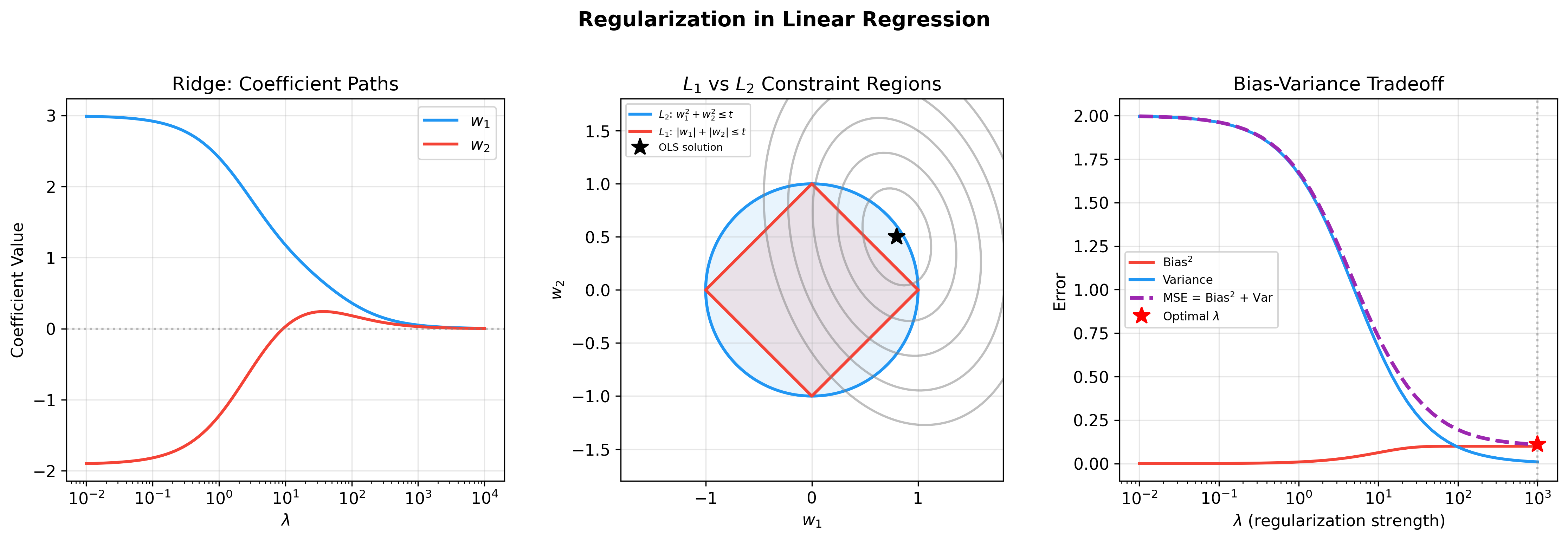
下图详细对比了 Ridge(L2)和 Lasso(L1)正则化的效果——左图展示 Ridge
系数随
梯度下降算法
批量梯度下降( BGD)
当数据量大时,直接计算
算法:
- 初始化
- 重复直到收敛:
其中
完整形式:
计算复杂度:每次迭代
随机梯度下降( SGD)
每次只使用一个样本更新参数。
算法:
- 初始化
- 对于
: - 随机选择样本
- 更新:
- 随机选择样本
优点:
- 每次迭代快(
) - 适合大规模数据
- 有逃离局部最小值的能力(对于非凸问题)
缺点:
- 收敛不稳定(高方差)
- 需要精心调整学习率
小批量梯度下降( Mini-batch GD)
折中方案:每次使用
其中
典型选择:
收敛性分析
定理 4(BGD 收敛性):对于学习率
其中
证明思路:
- 损失函数是强凸的( Hessian 正定)
- 梯度 Lipschitz 连续
- 应用强凸函数的收敛定理
实践建议:
- 学习率:
(保守选择) - 自适应学习率:Adam、RMSprop 等
- 学习率衰减:
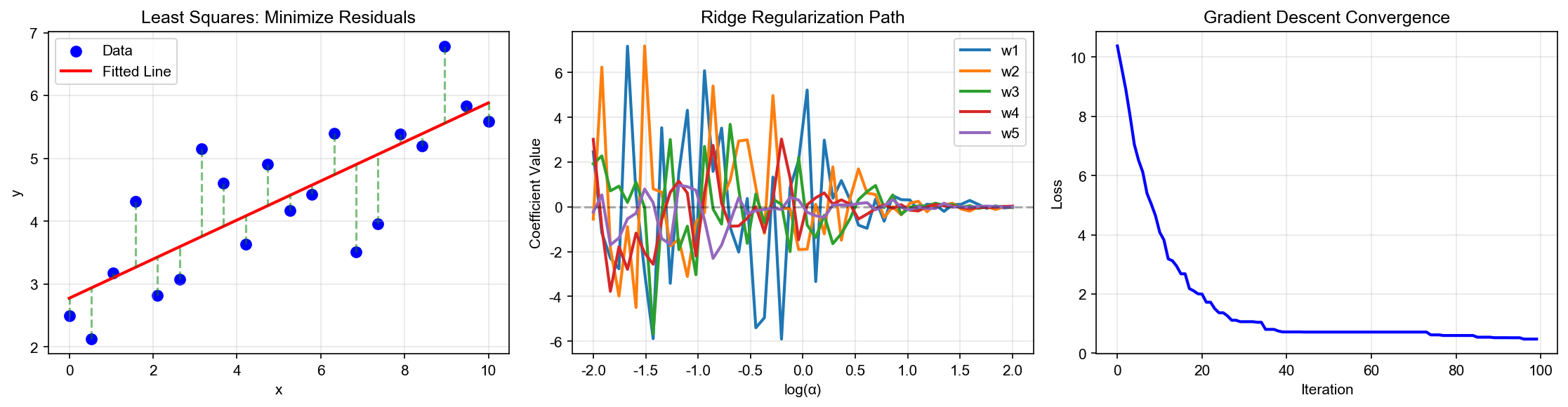
下图展示了不同学习率下梯度下降的收敛轨迹:学习率太小收敛慢,太大可能震荡,适中的学习率能快速稳定收敛到最优点:
下面的动画展示了梯度下降拟合线性回归模型的完整过程——左图展示数据点与当前拟合直线,右图展示损失函数随迭代下降的曲线:
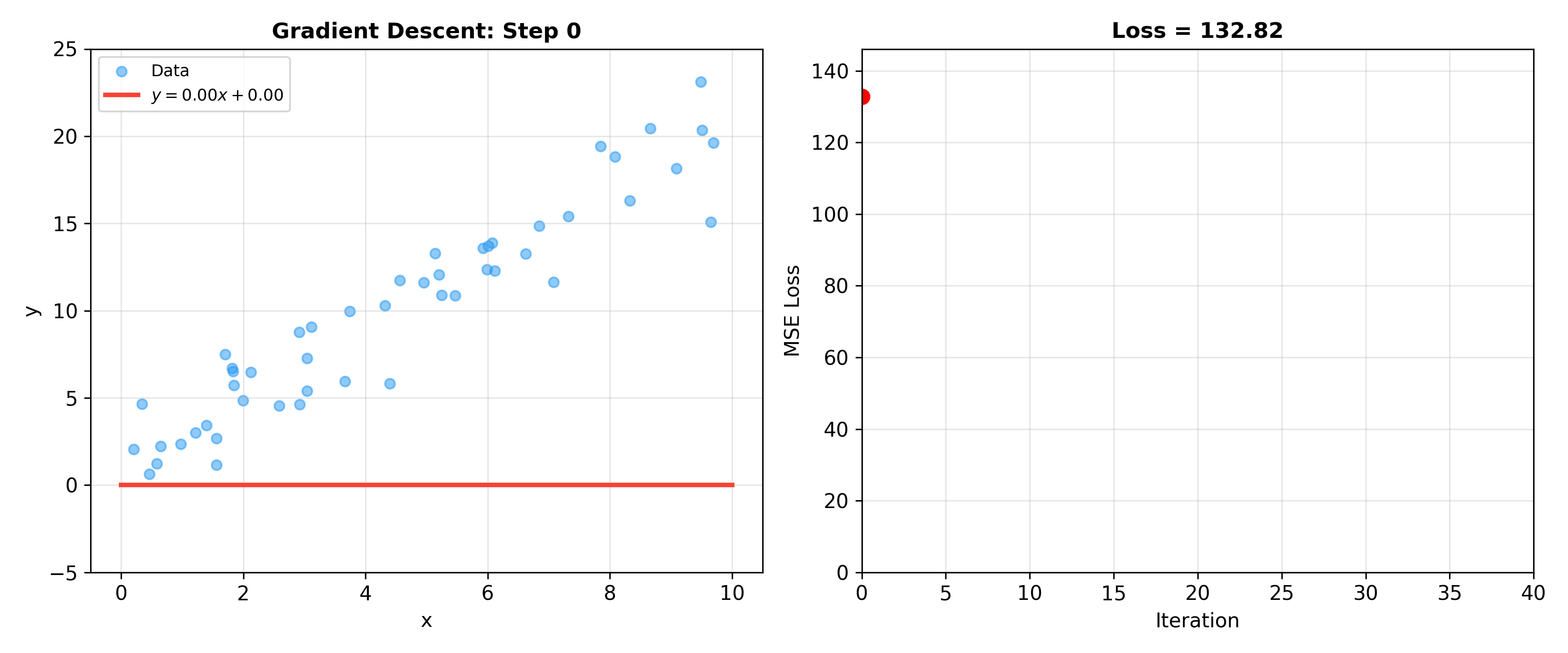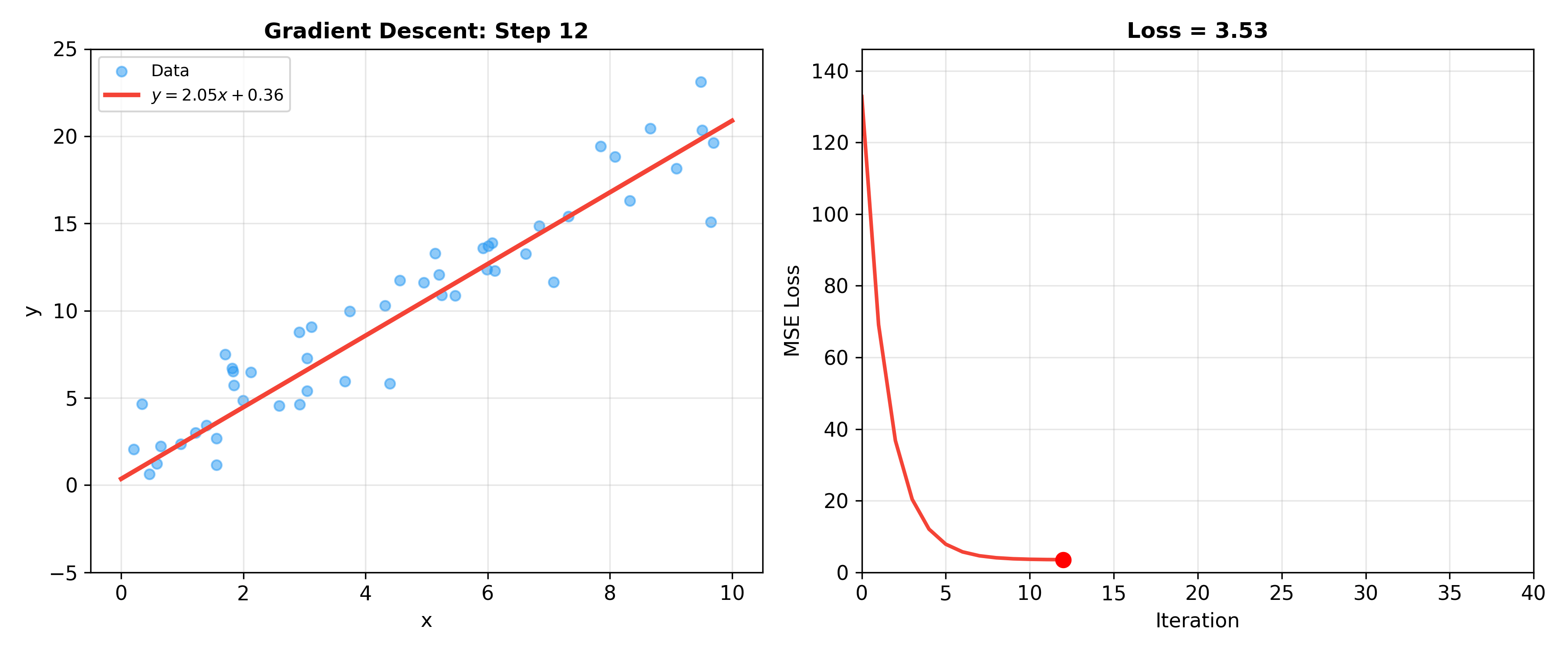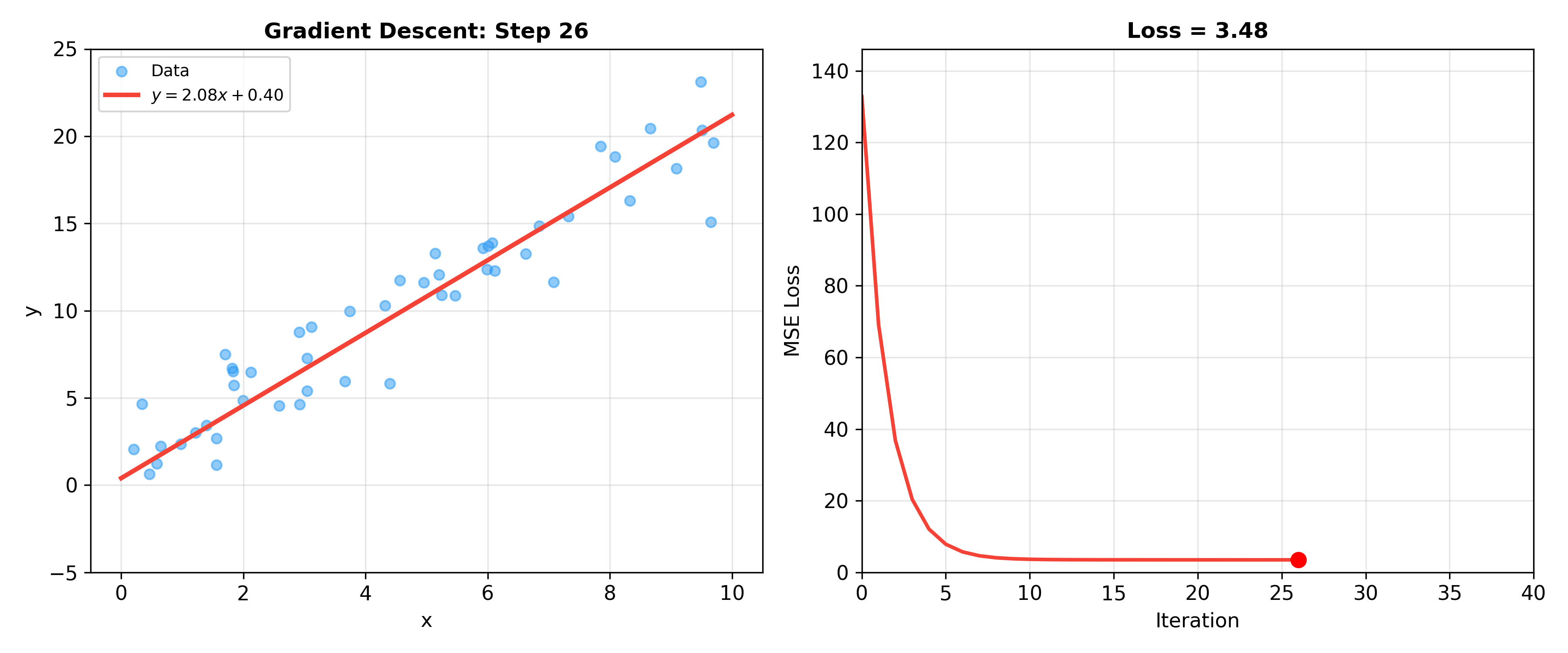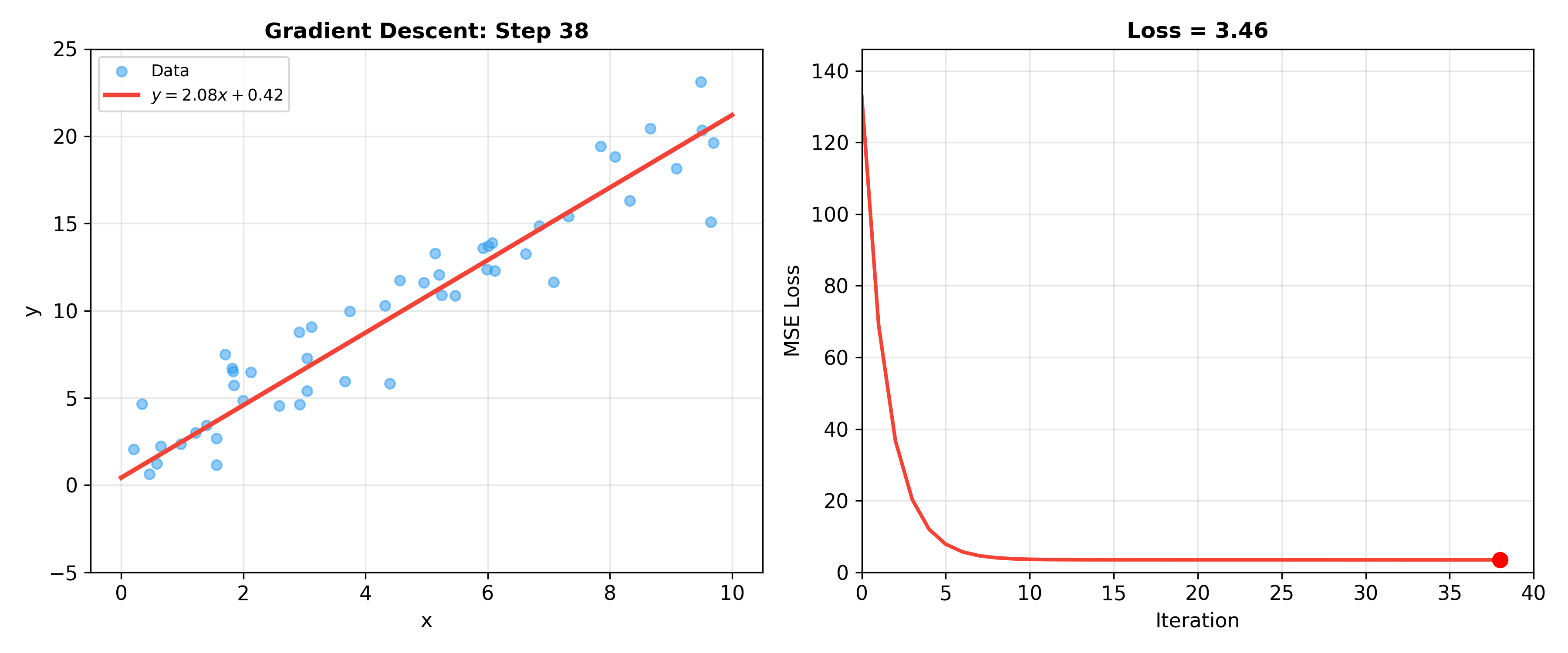
模型评估与选择
评价指标
均方误差(MSE):
均方根误差(RMSE):
平均绝对误差(MAE):
决定系数(R²):
其中
解释:
-
调整 R²
考虑模型复杂度的惩罚:
优点:添加无用特征时,
下图展示了线性回归模型的四种经典残差诊断图——通过残差 vs 拟合值、Q-Q 图、Scale-Location 图和残差分布直方图来检验模型假设是否成立:
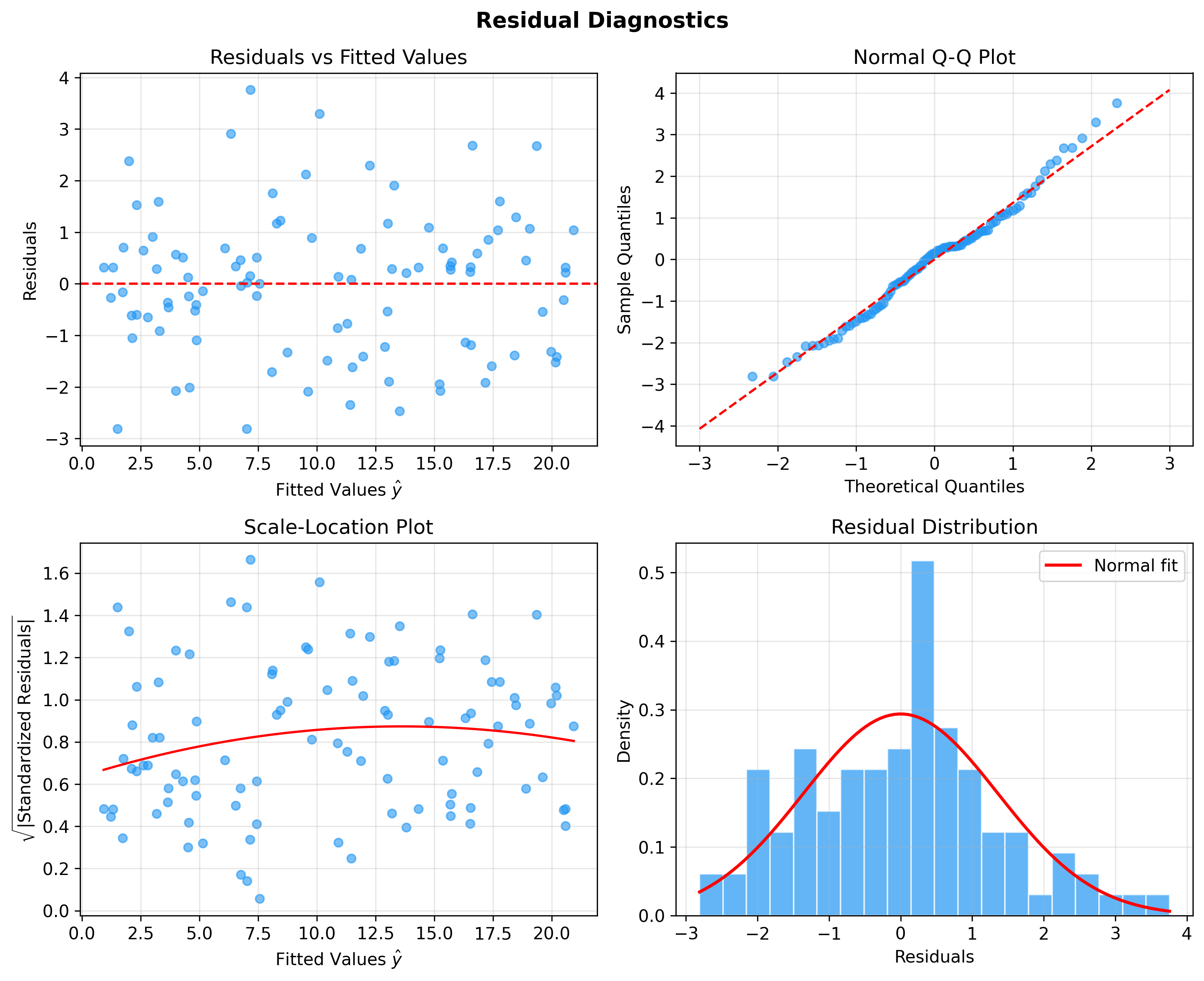
交叉验证
k 折交叉验证:
- 将数据分为
份 - 对于
: - 使用除第
份外的数据训练 - 在第
份上测试
- 使用除第
- 平均
个测试误差
Python 实现:
1 | from sklearn.model_selection import cross_val_score |
完整代码实现
1 | import numpy as np |
代码输出示例:
1 | ====================================================================== |
❓ Q&A:线性回归核心问题
Q1:为什么使用平方损失而不是绝对值损失?
数学原因:
- 可微性:
处处可微,便于优化 - 解析解:平方损失导致二次优化问题,有闭式解
- 统计意义:在高斯噪声假设下,平方损失对应最大似然估计
绝对值损失( L1 损失):
- 优点:对异常值鲁棒( outliers 影响小)
- 缺点:在 0 点不可微,无解析解,需要线性规划求解
对比:
| 损失函数 | 可微性 | 解析解 | 异常值鲁棒性 | 对应噪声分布 |
|---|---|---|---|---|
| 平方( L2) | 处处可微 | 有 | 弱 | 高斯分布 |
| 绝对值( L1) | 0 点不可微 | 无 | 强 | 拉普拉斯分布 |
| Huber | 处处可微 | 无 | 中等 | 混合分布 |
Huber 损失(折中方案):
在
Q2:正规方程 vs 梯度下降,什么时候用哪个?
决策树:
1 | 数据规模? |
详细对比:
| 维度 | 正规方程 | 梯度下降 |
|---|---|---|
| 时间复杂度 | ||
| 空间复杂度 | ||
| 收敛性 | 一步到位 | 需要多次迭代 |
| 超参数 | 无 | 学习率、迭代次数 |
| 特征数量 | 任意大 | |
| 可逆性要求 | 无 | |
| 正则化 | 容易加入 | 容易加入 |
| 在线学习 | 不支持 | 支持( SGD) |
实践建议:
- 默认选择:
用正规方程,否则用梯度下降 - 大数据:必须用 SGD 或 Mini-batch GD
- 实时更新:必须用 SGD(支持在线学习)
Q3:为什么 Ridge 回归的解总是存在?
核心原因:添加
定理:对于任意
证明:
对于任意非零向量
因为
因此
直觉:
可能奇异(例如特征共线) - 添加
相当于在对角线上加上一个"安全垫" - 即使某些特征完全相关,
保证了矩阵的正定性
几何意义:
在特征空间中,
Q4:如何选择正则化参数
方法 1:交叉验证(推荐)
1 | from sklearn.linear_model import RidgeCV |
方法 2:网格搜索
1 | from sklearn.model_selection import GridSearchCV |
方法 3:理论指导
根据偏差-方差权衡:
其中
实践经验:
- 起点:
(在标准化数据上) - 范围:
(对数刻度搜索) - 精细调整:在最优值附近缩小范围
- 早停:如果验证误差连续增加,停止搜索
L-曲线方法:
绘制 |w|
Q5:特征标准化为什么重要?
问题:不同特征量纲不同会导致:
- 梯度下降收敛慢:参数空间呈椭球形,梯度方向不指向最优点
- 正则化不公平:
惩罚大量纲特征的权重更多
示例:
假设两个特征:
:面积(范围 0-1000 平方米) :房间数(范围 1-10)
权重
标准化方法:
Z-score 标准化(推荐):
其中
Min-Max 标准化:
效果对比:
| 方法 | 均值 | 标准差/范围 | 异常值敏感性 |
|---|---|---|---|
| 原始数据 | 任意 | 任意 | - |
| Z-score | 0 | 1 | 中等 |
| Min-Max | - | [0,1] | 高 |
代码:
1 | from sklearn.preprocessing import StandardScaler |
注意:标准化后,权重的解释会改变。要恢复原始尺度的权重:
Q6:多重共线性如何影响线性回归?
定义:多重共线性( Multicollinearity)指特征之间高度线性相关。
检测方法:
方差膨胀因子(VIF):
其中
判断标准:
:无共线性 :中等共线性 :严重共线性
影响:
- 数值不稳定:
接近奇异,计算 误差大 - 参数方差大:权重估计的标准误增大,置信区间变宽
- 参数不可解释:权重符号可能与预期相反
示例:
假设
- 真实模型:
(参数不稳定)
解决方法:
- 删除冗余特征:通过 VIF 识别并删除
- PCA 降维:将相关特征转化为正交主成分
- Ridge 回归:
惩罚缓解共线性 - 收集更多数据:增大样本量减小估计方差
Python 检测 VIF:
1 | from statsmodels.stats.outliers_influence import variance_inflation_factor |
Q7:线性回归的假设是什么?违反假设怎么办?
经典线性回归的四大假设:
假设 1:线性关系
检验:残差图(Residual Plot)应无明显模式。
违反时:
- 添加多项式特征:
- 特征变换:
- 使用非线性模型:决策树、神经网络
假设 2:独立性
检验: Durbin-Watson 检验统计量:
违反时(常见于时间序列):
- 使用自回归模型( AR, ARIMA)
- 添加滞后项作为特征
假设 3:同方差性
(_i) =
检验:残差图中,残差的散布应随
违反时(异方差性):
- 加权最小二乘( WLS):给不同样本不同权重
- 稳健标准误( Robust Standard Errors)
- 对数变换目标变量
假设 4:正态性
检验:
- QQ 图( Quantile-Quantile Plot)
- Shapiro-Wilk 检验
违反时:
- 对目标变量变换( Box-Cox 变换)
- 使用非参数方法或广义线性模型
诊断代码:
1 | import matplotlib.pyplot as plt |
Q8:如何处理分类特征?
问题:线性回归要求输入是数值型,但很多特征是分类的(如"颜色":红、绿、蓝)。
错误做法:直接编码为整数(红=1, 绿=2, 蓝=3)。
问题:引入了虚假的顺序关系(模型会认为蓝比红"大"2 倍)。
正确方法:
独热编码( One-Hot Encoding):
将
示例:
| 原始 | 红 | 绿 | 蓝 |
|---|---|---|---|
| 红 | 1 | 0 | 0 |
| 绿 | 0 | 1 | 0 |
| 蓝 | 0 | 0 | 1 |
代码:
1 | from sklearn.preprocessing import OneHotEncoder |
注意:
- 多重共线性:
个独热列完全线性相关(和为 1)。解决:删除一列( drop='first')或使用 Ridge 回归。 - 高基数特征:如果类别数
很大(如邮政编码),考虑: - 目标编码( Target Encoding)
- 嵌入( Embedding)
Q9:线性回归能处理非线性关系吗?
答案:能,通过特征工程。
关键洞察:线性回归中的"线性"指的是参数线性,而非特征线性。
这仍是关于
方法 1:多项式特征
1 | from sklearn.preprocessing import PolynomialFeatures |
方法 2:交互特征
1 | from sklearn.preprocessing import PolynomialFeatures |
方法 3:自定义变换
1 | import numpy as np |
注意:
- 过拟合风险:特征数量快速增长(
个特征的 次多项式有 项) - 正则化必要性:使用 Ridge 或 Lasso 控制复杂度
- 可解释性下降:高次项难以解释
示例:拟合正弦曲线
1 | # 生成数据 |
Q10:如何解释线性回归的系数?
基本解释:
对于模型
注意事项:
标准化影响:如果特征标准化了,权重大小不能直接比较重要性。
共线性影响:多重共线性会导致权重不稳定。
因果关系:相关≠因果。权重只表示统计关联,不能推断因果关系。
标准化系数( Standardized Coefficients):
在标准化数据上拟合模型,得到的系数可以比较相对重要性:
解释:
显著性检验:
使用 t 检验判断
其中
Python 实现:
1 | import statsmodels.api as sm |
置信区间:
95%置信区间:
如果区间不包含 0,则参数显著。
🎓 总结与展望
核心要点:
三种视角:代数(正规方程)、几何(投影)、概率( MLE)殊途同归
最小二乘解:
正则化: Ridge( L2)保证可逆, Lasso( L1)实现稀疏
优化算法:小数据用正规方程,大数据用梯度下降
模型诊断:检查线性性、独立性、同方差性、正态性
实战要点:
- 特征标准化
- 处理共线性
- 选择正则化参数
- 交叉验证评估
下一章预告:第 6 章将探讨逻辑回归与分类问题,将线性模型推广到离散输出空间。我们将推导 sigmoid 函数的来源、交叉熵损失的数学基础,以及决策边界的几何意义。
✏️ 练习题与解答
练习 1:正规方程推导
题目:从矩阵微积分出发,推导最小二乘法的正规方程
解答:
损失函数:
展开:
对
令
当
练习 2:Ridge 回归的贝叶斯解释
题目:证明 Ridge 回归等价于在权重上施加高斯先验
解答:
似然:
先验:
MAP 估计最大化后验(等价于最小化负对数后验):
对比 Ridge 回归:
因此
练习 3:投影矩阵性质
题目:证明投影矩阵
解答:
对称性:
(因为
幂等性:
几何意义:
练习 4:MLE 与 OLS 的等价性
题目:在线性高斯模型
解答:
对数似然:
对
对
注意
练习 5:多重共线性分析
题目:设
解答:
OLS 估计的方差-协方差矩阵:
当
具体来看,VIF(方差膨胀因子)
Ridge 回归的方差:
添加
📚 参考文献
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning (2nd ed.). Springer.
Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT Press.
Shalev-Shwartz, S., & Ben-David, S. (2014). Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press.
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An Introduction to Statistical Learning. Springer.
Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B, 58(1), 267-288.
Hoerl, A. E., & Kennard, R. W. (1970). Ridge regression: Biased estimation for nonorthogonal problems. Technometrics, 12(1), 55-67.
Zou, H., & Hastie, T. (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B, 67(2), 301-320.
Huber, P. J. (1964). Robust estimation of a location parameter. The Annals of Mathematical Statistics, 35(1), 73-101.
李航 (2012). 统计学习方法. 清华大学出版社.
周志华 (2016). 机器学习. 清华大学出版社.
- 本文标题:机器学习数学推导(五)线性回归
- 本文作者:Chen Kai
- 创建时间:2021-09-18 09:00:00
- 本文链接:https://www.chenk.top/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%95%B0%E5%AD%A6%E6%8E%A8%E5%AF%BC%EF%BC%88%E4%BA%94%EF%BC%89%E7%BA%BF%E6%80%A7%E5%9B%9E%E5%BD%92/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!