在 Google 的 PageRank
算法中,网页排名问题被转化为一个巨大的特征值问题:找到转移矩阵的主特征向量。这个简洁的数学表述背后,隐藏着线性代数的深刻结构。线性代数不仅是机器学习的语言,更是理解数据几何结构的钥匙。
机器学习本质上是在高维空间中寻找最优的线性或非线性变换。从最简单的线性回归(求解),到复杂的深度神经网络(链式矩阵乘法),再到主成分分析(特征值分解),线性代数无处不在。本章从第一性原理出发,严格推导机器学习所需的所有线性代数工具。
向量空间与线性变换
向量空间的公理化定义
什么是"空间"?停车场的类比
想象一个停车场: - 里面可以停各种车:轿车、SUV、卡车 -
但必须遵守规则:比如不能停飞机、不能停船 -
满足规则的车,都可以进这个"停车空间"
向量空间也一样: - 是一个"向量的集合" -
必须遵守某些规则(8条公理) - 满足规则的向量,都属于这个"空间"
严格的数学定义
定义 1(向量空间):设是一个非空集合(向量的集合),是一个数域(通常是实数或复数)。如果在上定义了两种运算:
- 向量加法:(两个向量能相加,结果还在空间里)
- 标量乘法:(向量乘以数字,结果还在空间里)
满足以下 8 条公理(规则),则称为上的向量空间:
加法公理:
- 交换律:,
- 结合律:,
- 零元素:,使得,
- 逆元素:,,使得
标量乘法公理:
- 分配律 1:,
- 分配律 2:,
- 结合律:,
- 单位元:,
常见的向量空间例子:
| 空间 |
元素 |
维数 |
应用 |
|
维实向量 |
|
机器学习特征向量 |
|
维复向量 |
|
量子计算,信号处理 |
|
实矩阵 |
|
数据矩阵,权重矩阵 |
|
上连续函数 |
|
函数逼近 |
|
次数的多项式 |
|
多项式回归 |
线性无关与基
定义 2(线性组合):向量可以表示为向量组的线性组合,如果存在标量使得:
定义 3(线性无关):向量组线性无关,如果:
否则称为线性相关。
定理 1(线性相关的等价条件):向量组线性相关,当且仅当其中某个向量可以表示为其他向量的线性组合。
证明:设线性相关,则存在不全为零的使得。不失一般性,设,则:
设,则,且系数不全为零,故线性相关。证毕。
定义 4(基与维数):向量空间的一组基是一个线性无关的向量组,使得中的任意向量都可以唯一表示为这些基向量的线性组合。基向量的个数称为向量空间的维数,记作。
标准基例子:的标准基:
任意可唯一表示为。
线性变换与矩阵
定义 5(线性变换):设是两个向量空间。映射称为线性变换(或线性映射),如果:
- 加法性:,
- 齐次性:,
定理 2(线性变换的矩阵表示):设和分别是维和维向量空间,选定基和。对于线性变换,存在唯一的矩阵,使得对任意:
其中和是向量在对应基下的坐标表示。
证明:
设,则:
由线性性。现在,,可以表示为的基的线性组合:
因此:
这恰好是矩阵-向量乘法的第个分量,其中。证毕。
矩阵的第列就是在的基下的坐标。这是矩阵表示的几何意义。
四个基本子空间
对于矩阵,有四个基本子空间刻画其结构:
定义 6(四个基本子空间):
- 列空间(Column Space):
- 零空间(Null Space):
- 维数:(由秩-零化度定理)
- 几何意义:被映射到零的所有向量
- 行空间(Row Space):
- 左零空间(Left Null Space):
定理 3(基本子空间的正交性):
- (零空间与行空间正交)
- (左零空间与列空间正交)
证明第 1 条:
设,即。对于任意,存在使得。计算内积:
因此,即。证毕。
基本子空间的维数关系:
这两个等式表明和分别被分解为两个正交的子空间。
内积空间与范数
内积的定义与性质
定义 7(内积):设是实向量空间。内积是一个映射,满足:
- 对称性:
- 线性性:
- 正定性:,且
常见内积:
- 标准内积(欧几里得内积):对于,
- 加权内积:给定正定对角矩阵,
- 函数空间的内积:对于,
- 矩阵的 Frobenius 内积:对于,
范数的定义与性质
定义 8(范数):向量空间上的范数是一个映射,满足:
- 正定性:,且
- 齐次性:,
- 三角不等式:,
常见向量范数:
- 范数:对于,,
特例: - 范数(曼哈顿距离): - 范数(欧几里得范数): -
范数(最大范数):
- 内积诱导的范数:对于内积空间,
定理 4(Cauchy-Schwarz
不等式):对于内积空间中的任意,
等号成立当且仅当和线性相关。
证明:
对于任意,考虑:
这是关于的二次函数,且恒非负。因此判别式:
即。等号成立当且仅当存在使得,即(线性相关)。证毕。
Cauchy-Schwarz 不等式的推论:
三角不等式:
证明:
两边开方即得三角不等式。
- 余弦定理:
其中是和的夹角。由 Cauchy-Schwarz 不等式,。
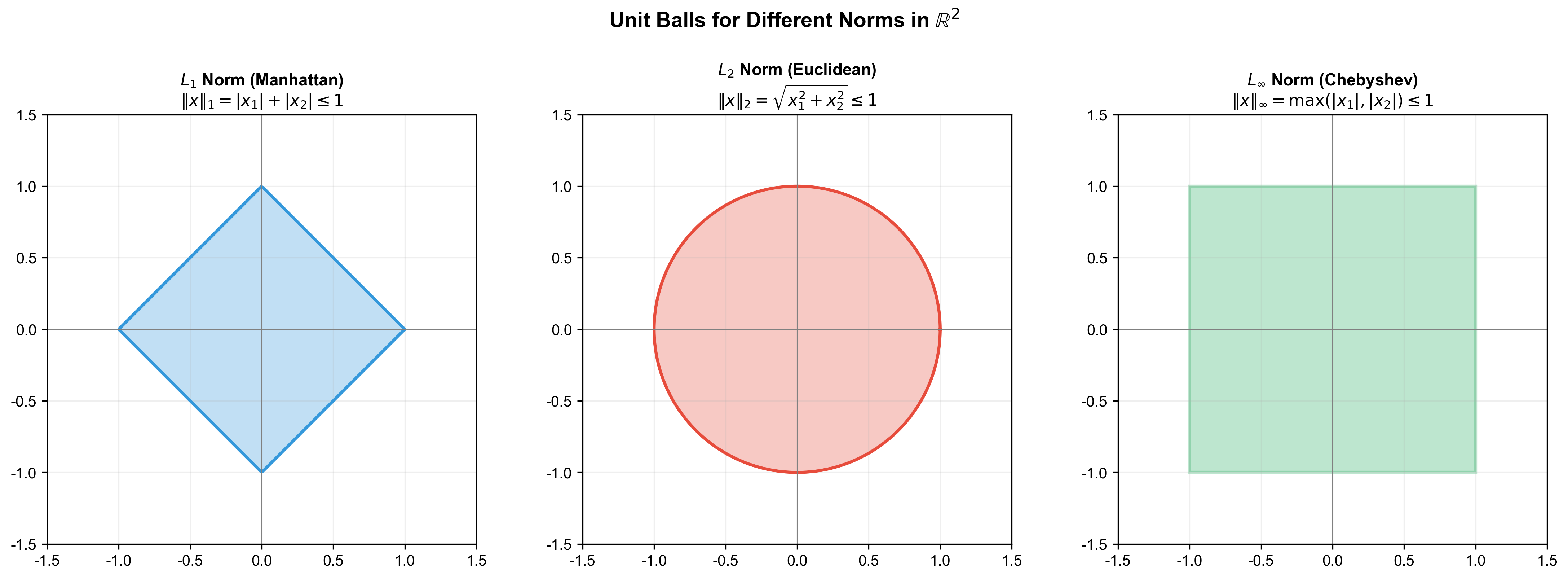
下图直观展示了空间中不同范数的单位球:范数的单位球是菱形,范数的单位球是圆形,范数的单位球是正方形。这些几何形状直接决定了对应正则化方法(Lasso、Ridge)的行为特征:
 Matrix Norms
Matrix Norms
常见矩阵范数
定义 9(矩阵范数):矩阵范数是定义在矩阵空间上的范数。
常见矩阵范数:
- Frobenius 范数:
- 诱导范数(算子范数):由向量范数诱导,
特例: - 谱范数(2-范数):(最大奇异值)
- 1-范数:(列和的最大值) - -范数:(行和的最大值)
- 核范数(迹范数):
其中是的奇异值。
定理 5(矩阵范数的性质):
- 次乘性:(Frobenius 范数不满足,但满足)
- 诱导范数的次乘性:
- 与向量范数的相容性:
特征值与特征向量
特征值问题的定义
定义 10(特征值与特征向量):设。如果存在非零向量和标量使得:
则称为的特征值,为对应的特征向量。
特征值的计算:
特征值满足特征方程:
这是关于的次多项式方程,称为特征多项式:
定理 6(特征值的性质):
1.(特征值之和等于迹) 2.(特征值之积等于行列式) 3.可逆所有特征值非零 4.的特征值是 5. 相似矩阵有相同的特征值
证明第 1,2 条:
特征多项式的首项系数是,次高项系数是,常数项是。
根据 Vieta 定理,多项式展开后:
-的系数: -
常数项:
对比系数即得和。证毕。
对称矩阵的谱定理
定理 7(对称矩阵的谱定理):设是对称矩阵,则:
1.的所有特征值都是实数 2.
对应不同特征值的特征向量正交 3.可以正交对角化,即存在正交矩阵和对角矩阵使得:
其中,的列是的标准正交特征向量。
证明:
第 1 步:特征值是实数
设,。计算:
因此,即。
第 2 步:不同特征值的特征向量正交
设,,其中。计算:
因此。由于,得。
第 3 步:正交对角化
由于是实对称矩阵,在复数域上必有个特征值(计重数)。由第 1
步,这些特征值都是实数。对于重特征值,其特征空间内可以选取正交基(Gram-Schmidt
正交化)。
因此可以找到个标准正交的特征向量,构成正交矩阵。则:
两边右乘(利用),得。证毕。
谱分解的几何意义:
这表明可以分解为个秩 1
矩阵的加权和,每个矩阵是沿特征向量方向的投影,权重是特征值。
正定矩阵
定义 11(正定矩阵):对称矩阵称为正定矩阵,如果对所有非零向量,
类似地,定义半正定()、负定()、半负定()矩阵。
定理 8(正定矩阵的等价条件):以下条件等价:
1.是正定矩阵 2.的所有特征值都是正数 3.的所有顺序主子式都是正数 4.
存在可逆矩阵使得 5.的 Cholesky 分解存在:,其中是下三角矩阵
证明:设,。则:
因此。由谱定理,,其中,。对于任意,令(因为可逆):
因为至少有一个且所有。证毕。
正定矩阵的性质:
- 正定矩阵一定可逆
- 正定矩阵的逆也是正定的
- 两个正定矩阵的和是正定的
- 正定矩阵的主对角元都是正数
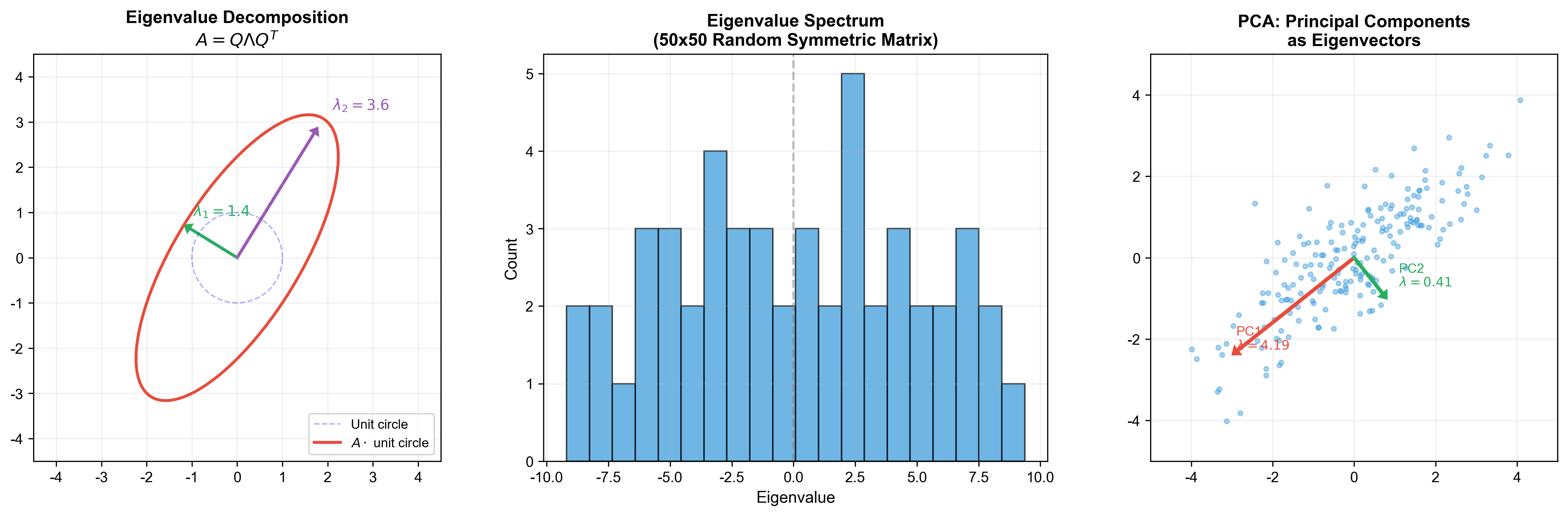
下图展示了特征值分解的几何意义:矩阵将单位圆变换为椭圆,椭圆的主轴方向即为特征向量,主轴长度即为特征值。右图则展示了特征向量即为数据的主方向(PCA
的核心思想):
 Eigenvalue Visualization
Eigenvalue Visualization
奇异值分解(SVD)
SVD 的定理与几何意义
定理 9(奇异值分解):设,秩为。则存在正交矩阵和,以及对角矩阵,使得:
其中的对角元称为的奇异值。
完整形式:
简化形式(经济型 SVD):
其中,,。
证明思路:
第 1 步:特征值分解的启发
考虑和:
-是对称半正定矩阵 -是对称半正定矩阵
由谱定理,它们可以正交对角化。
第 2 步:右奇异向量(来自)的特征值分解:
其中的列是的标准正交特征向量,,。
定义为奇异值(按降序排列)。
第 3 步:左奇异向量的构造
对于(其中),定义:
验证的正交性:
对于,用
Gram-Schmidt 正交化扩展为的标准正交基。
第 4 步:验证
对于:
对于:
(因为,即意味着)
因此:
两边右乘得。证毕。
SVD 的几何意义:
任意线性变换可以分解为三步:
- 旋转(或反射):将的标准正交基旋转到的特征向量基
- 缩放:沿个方向缩放,缩放因子是奇异值
- 旋转(或反射):将结果旋转到的标准正交基
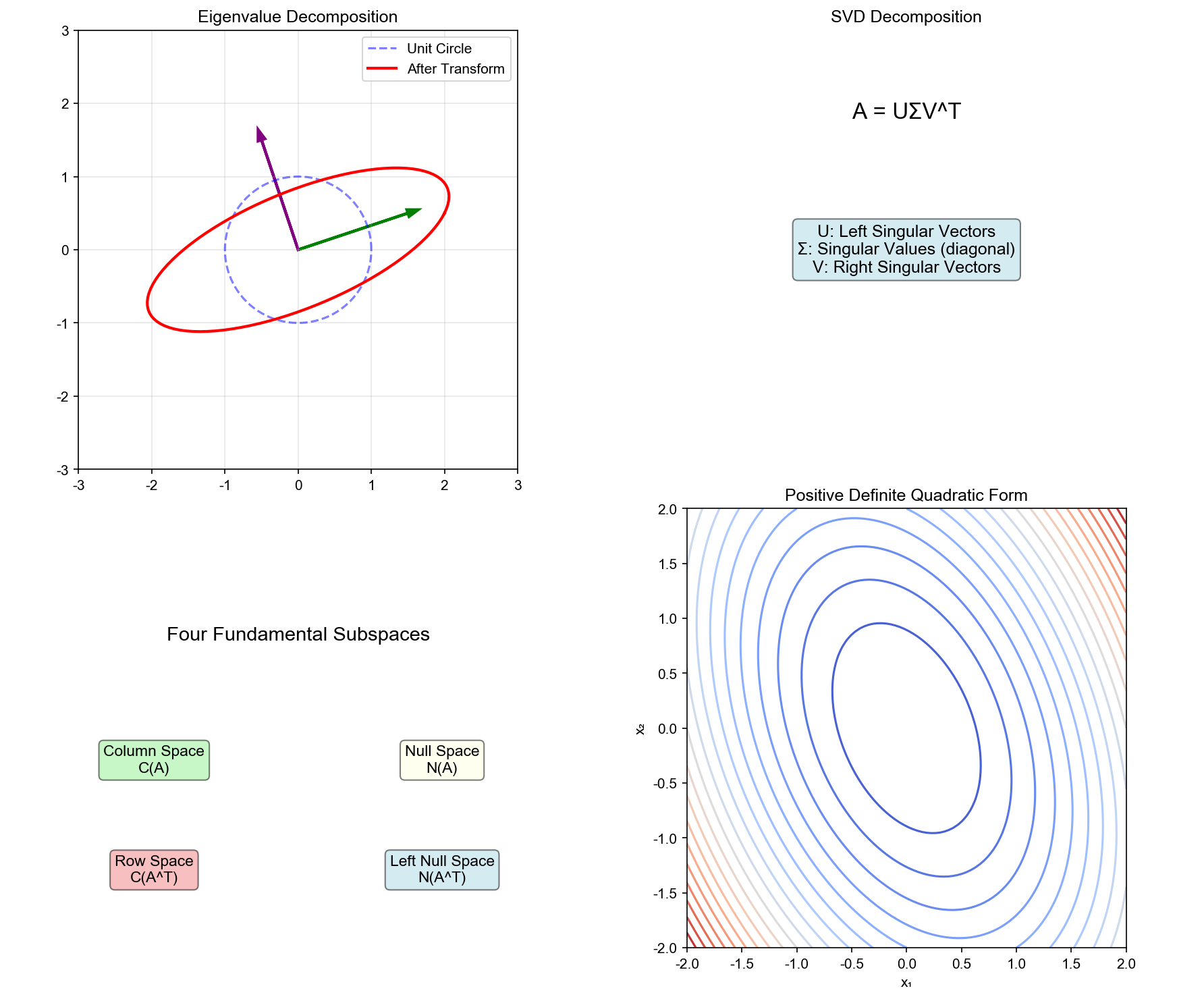
下图展示了线性代数的核心几何概念:左图展示矩阵变换如何将单位圆变换为椭圆,特征向量指示主方向;中图展示
SVD 分解后的奇异值大小;右图展示二次型在不同方向上的函数值变化:
 Linear Algebra Core Concepts
Linear Algebra Core Concepts
SVD 的应用
1. 低秩逼近
定理 10(Eckart-Young 定理):设是的 SVD,是秩逼近。则是在所有秩的矩阵中,Frobenius 范数和谱范数意义下的最佳逼近:
证明思路(谱范数):
设是任意秩的矩阵。则。考虑和:
但它们都是的子空间,所以必有非零交点。存在,。
由于,,。则:
但这只能证明。更精细的论证(利用极小极大原理)可以证明,且达到此下界。
应用:主成分分析(PCA)
给定数据矩阵(中心化后),对做
SVD:
取前个主成分:
这是的最佳秩逼近,即在保留最多方差的意义下,将数据从维降到维。
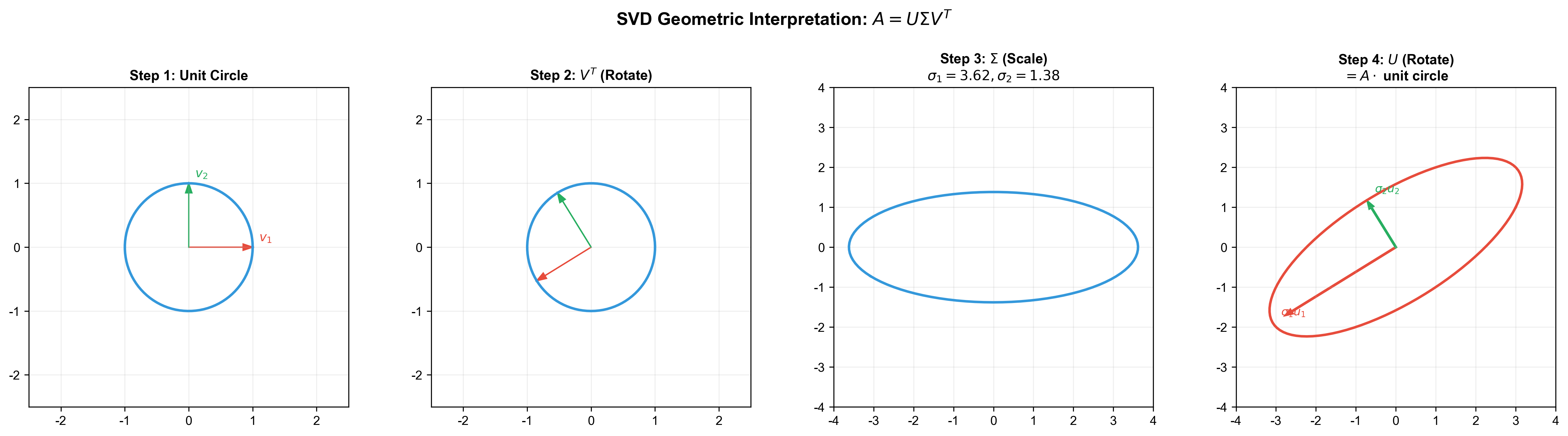
下图展示了 SVD 分解的几何意义:任意矩阵将单位圆通过旋转和缩放变换为椭圆,奇异值决定了椭圆各轴的长度:
 SVD Visualization
SVD Visualization
下面的动画直观展示了 SVD 低秩逼近的过程——随着保留的奇异值个数逐渐增加,图像的近似质量不断提升,这正是低秩逼近理论(Eckart-Young
定理)的实际体现:
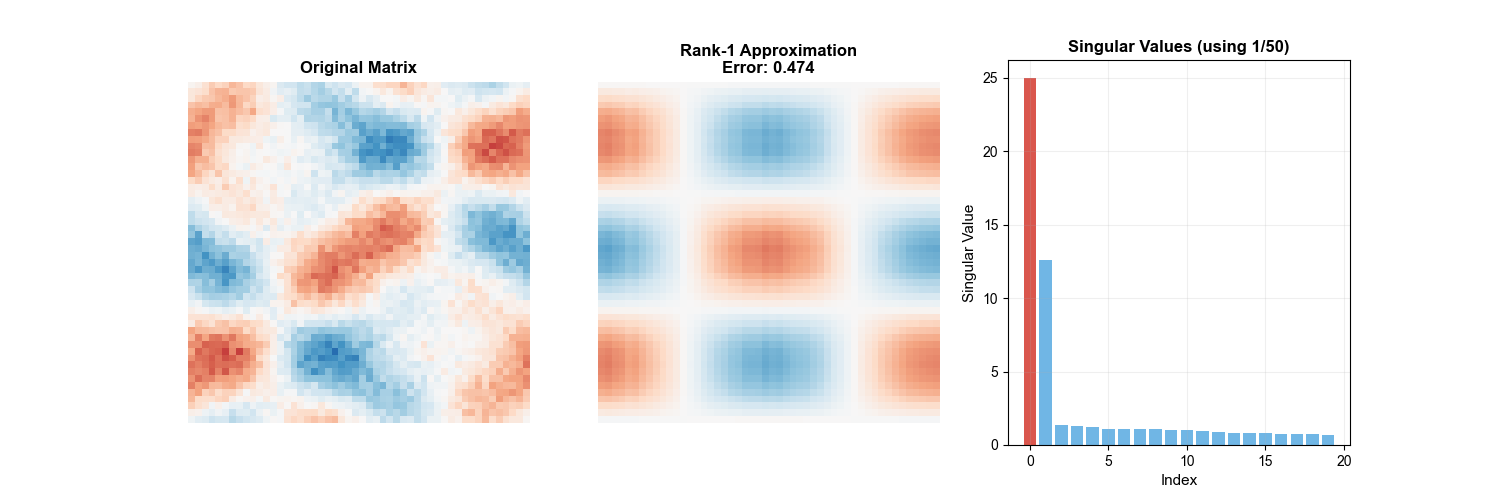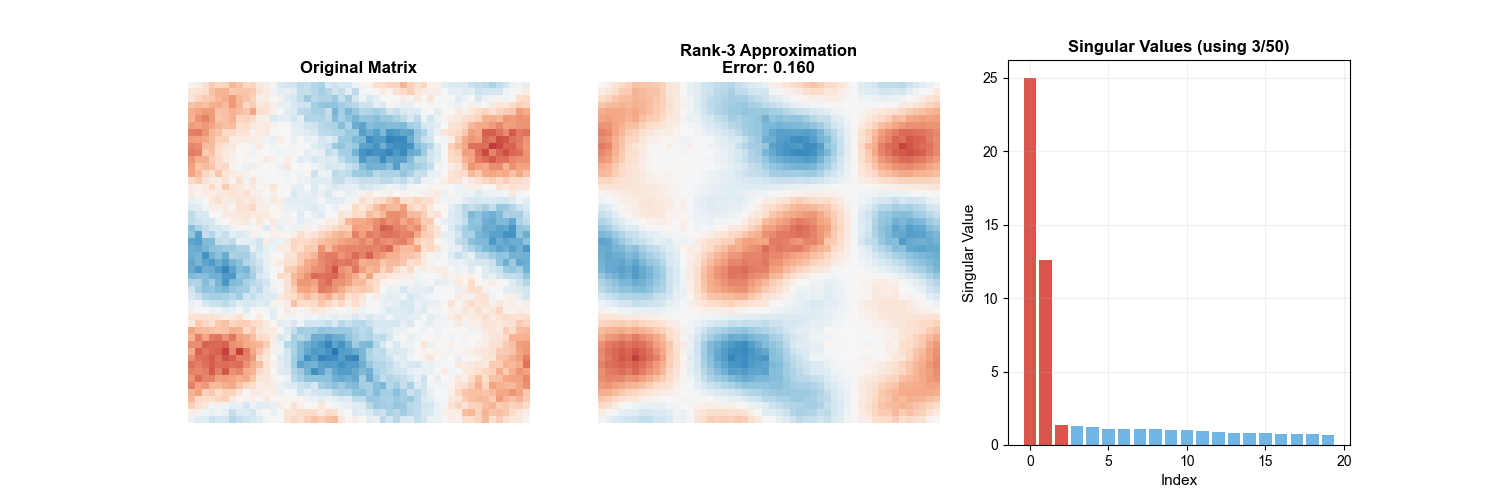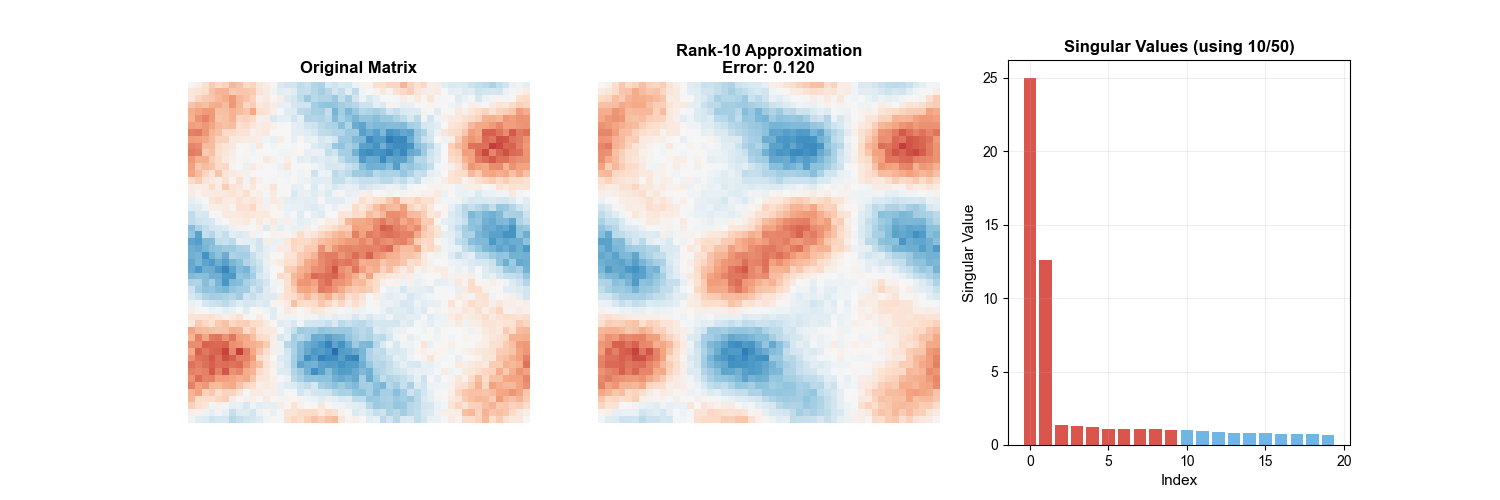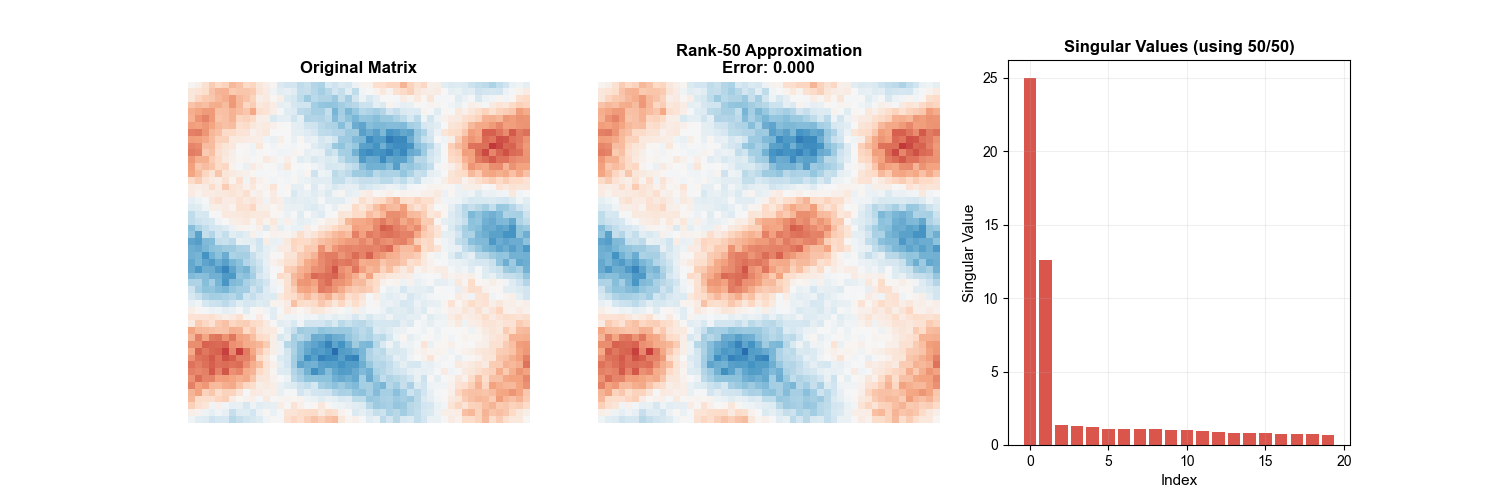 SVD Truncation Animation
SVD Truncation Animation
2. 伪逆矩阵
定义 12(Moore-Penrose 伪逆):矩阵的伪逆是唯一满足以下四个性质的矩阵:
1. 2. 3. 4.
定理 11(SVD 计算伪逆):设是的 SVD,则:
其中定义为:
即。
验证:
验证满足四个性质。以第 1 条为例:
因为(前个对角元是 1)。其余性质类似验证。
最小二乘问题的解:
对于不相容方程组,最小二乘解是:
这是所有使最小的解中,范数最小的一个(最小范数最小二乘解)。
3. 条件数
定义 13(条件数):矩阵的条件数定义为:
条件数度量了矩阵的"病态程度"。越大,线性方程组对的扰动越敏感。
定理 12(扰动界):设,,则:
这表明相对误差被条件数放大。
矩阵求导
矩阵求导在机器学习的优化问题中无处不在。本节从第一性原理推导常用的矩阵求导公式。
矩阵求导的记号
标量对向量求导:
设,则对向量的导数定义为:
这称为梯度向量,记作或。
标量对矩阵求导:
设,则对矩阵的导数定义为:
向量对向量求导:
设,,则Jacobi 矩阵定义为:
注意:矩阵求导的记号约定在不同文献中可能不同(分子布局
vs
分母布局)。本文采用分子布局,即导数的形状与分子(被求导函数)的形状一致。
基本求导公式
1. 线性函数
公式 1:,则:
证明:
因此:
即。
2. 二次型
公式 2:(其中),则:
特别地,如果是对称矩阵,则:
证明:
对求偏导:
因此。当时,得。证毕。
3. 矩阵乘法
公式 3:(其中,,),则:
证明:
对求偏导:
因此。证毕。
4. 矩阵的迹
公式 4:(其中,),则:
特别地,如果对称,则:
证明:
利用迹的循环性质:
利用公式 3:
(这里用到的推广)
实际上,直接计算:
因此。证毕。
5. 行列式与逆矩阵
公式 5:(其中可逆),则:
证明:
利用矩阵求导的链式法则和:
对于行列式的微分,有公式(Jacobi 公式):
因此:
根据微分与导数的关系,得:
证毕。
公式 6:,则:
其中是第元素为 1,其余为 0 的矩阵。
链式法则与反向传播
定理 13(标量函数的链式法则):设,,则复合函数的导数为:
其中是 Jacobi 矩阵。
证明:
由多元函数的链式法则:
写成矩阵形式:
证毕。
反向传播的例子:
考虑神经网络的一层:
其中,,,是激活函数(逐元素作用)。
设损失函数是。要计算。
令,则:
但这里涉及矩阵对矩阵求导,需要更仔细的处理。实际上:
注意到, 所以(Kronecker delta)。
因此:
其中是第个神经元的"误差信号"。
写成矩阵形式:
其中。
矩阵分解的数值计算
QR 分解
定理 14(QR 分解):设()列满秩,则存在正交矩阵和上三角矩阵使得:
Gram-Schmidt 正交化算法:
给定线性无关的向量组, 构造标准正交向量组:
则:
写成矩阵形式:
其中,()。
QR 分解的应用:
求解最小二乘问题:的解为(利用)。
计算特征值: QR 迭代算法
重复以下步骤:
在一定条件下,收敛到上三角矩阵,对角元是特征值。
Cholesky 分解
定理 15(Cholesky 分解):设是正定矩阵,则存在唯一的下三角矩阵$L $
算法:
递推计算的元素:
计算复杂度:(比 LU 分解快一倍)
应用:
- 求解线性方程组:
- 判断矩阵正定性:如果 Cholesky 分解成功(所有都是正数),则正定。
代码实现:矩阵分解与应用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
| import numpy as np
import matplotlib.pyplot as plt
from scipy.linalg import svd, qr, cholesky
import time
np.random.seed(42)
def demonstrate_svd():
"""
演示 SVD 分解及其应用:低秩逼近
"""
print("="*60)
print("1. 奇异值分解(SVD)与低秩逼近")
print("="*60)
m, n = 100, 80
rank_true = 10
U_true = np.random.randn(m, rank_true)
S_true = np.diag(np.linspace(10, 1, rank_true))
V_true = np.random.randn(n, rank_true)
A_true = U_true @ S_true @ V_true.T
noise_level = 0.5
A_noisy = A_true + noise_level * np.random.randn(m, n)
U, s, Vt = svd(A_noisy, full_matrices=False)
print(f"原始矩阵形状: {A_noisy.shape}")
print(f"奇异值前 10 个: {s[:10]}")
print(f"奇异值后 10 个: {s[-10:]}")
ranks = [1, 5, 10, 20, 40]
errors_fro = []
errors_spec = []
for k in ranks:
A_k = U[:, :k] @ np.diag(s[:k]) @ Vt[:k, :]
error_fro = np.linalg.norm(A_noisy - A_k, 'fro')
error_spec = np.linalg.norm(A_noisy - A_k, 2)
errors_fro.append(error_fro)
errors_spec.append(error_spec)
print(f"秩{k}逼近: Frobenius 误差={error_fro:.2f}, 谱误差={error_spec:.2f}")
print("\n 理论预测(Eckart-Young 定理):")
for i, k in enumerate(ranks):
theory_fro = np.sqrt(np.sum(s[k:]**2))
theory_spec = s[k] if k < len(s) else 0
print(f"秩{k}: 理论 Fro 误差={theory_fro:.2f}, 理论谱误差={theory_spec:.2f}")
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.semilogy(np.arange(1, len(s)+1), s, 'o-')
plt.xlabel('奇异值索引')
plt.ylabel('奇异值 (对数尺度)')
plt.title('SVD 奇异值谱')
plt.grid(True, alpha=0.3)
plt.subplot(1, 2, 2)
plt.plot(ranks, errors_fro, 'o-', label='Frobenius 误差')
plt.plot(ranks, errors_spec, 's-', label='谱误差')
plt.xlabel('逼近秩')
plt.ylabel('逼近误差')
plt.title('低秩逼近误差')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('svd_demo.png', dpi=150)
plt.close()
print("\n 图像已保存为 svd_demo.png\n")
def demonstrate_qr():
"""
演示 QR 分解及其在最小二乘中的应用
"""
print("="*60)
print("2. QR 分解与最小二乘问题")
print("="*60)
m, n = 100, 10
A = np.random.randn(m, n)
x_true = np.random.randn(n)
b = A @ x_true + 0.1 * np.random.randn(m)
start = time.time()
x_normal = np.linalg.solve(A.T @ A, A.T @ b)
time_normal = time.time() - start
start = time.time()
Q, R = qr(A, mode='economic')
x_qr = np.linalg.solve(R, Q.T @ b)
time_qr = time.time() - start
start = time.time()
x_svd = np.linalg.lstsq(A, b, rcond=None)[0]
time_svd = time.time() - start
print(f"真实解 x_true: {x_true[:5]}...")
print(f"正规方程解: {x_normal[:5]}... (用时{time_normal*1000:.2f}ms)")
print(f"QR 分解解: {x_qr[:5]}... (用时{time_qr*1000:.2f}ms)")
print(f"SVD 伪逆解: {x_svd[:5]}... (用时{time_svd*1000:.2f}ms)")
print(f"\n 残差范数:")
print(f"正规方程: {np.linalg.norm(A @ x_normal - b):.6f}")
print(f"QR 分解: {np.linalg.norm(A @ x_qr - b):.6f}")
print(f"SVD 伪逆: {np.linalg.norm(A @ x_svd - b):.6f}")
kappa = np.linalg.cond(A)
kappa_ata = np.linalg.cond(A.T @ A)
print(f"\n 条件数 κ(A) = {kappa:.2f}")
print(f"条件数 κ(A^T A) = {kappa_ata:.2f} ≈ κ(A)^2")
print("结论: QR 分解数值稳定性更好(不涉及 A^T A)\n")
def demonstrate_cholesky():
"""
演示 Cholesky 分解
"""
print("="*60)
print("3. Cholesky 分解(正定矩阵)")
print("="*60)
n = 50
B = np.random.randn(n, n)
A = B.T @ B + np.eye(n)
start = time.time()
L = cholesky(A, lower=True)
time_chol = time.time() - start
error = np.linalg.norm(A - L @ L.T, 'fro')
print(f"Cholesky 分解用时: {time_chol*1000:.2f}ms")
print(f"重构误差 ||A - LL^T||_F = {error:.2e}")
b = np.random.randn(n)
start = time.time()
x_inv = np.linalg.solve(A, b)
time_inv = time.time() - start
start = time.time()
y = np.linalg.solve(L, b)
x_chol = np.linalg.solve(L.T, y)
time_chol_solve = time.time() - start
print(f"\n 求解 Ax = b:")
print(f"直接求解用时: {time_inv*1000:.2f}ms")
print(f"Cholesky 求解用时: {time_chol_solve*1000:.2f}ms")
print(f"解的误差: {np.linalg.norm(x_inv - x_chol):.2e}")
print("结论: Cholesky 分解更快(复杂度 O(n^3/3) vs O(n^3))\n")
def demonstrate_matrix_calculus():
"""
演示矩阵求导在机器学习中的应用
"""
print("="*60)
print("4. 矩阵求导:线性回归的梯度计算")
print("="*60)
n, d = 100, 5
X = np.random.randn(n, d)
w_true = np.random.randn(d)
y = X @ w_true + 0.1 * np.random.randn(n)
def loss(w):
return 0.5 / n * np.sum((X @ w - y)**2)
def gradient_analytic(w):
return 1/n * X.T @ (X @ w - y)
def gradient_numeric(w, eps=1e-7):
grad = np.zeros_like(w)
for i in range(len(w)):
w_plus = w.copy()
w_plus[i] += eps
w_minus = w.copy()
w_minus[i] -= eps
grad[i] = (loss(w_plus) - loss(w_minus)) / (2 * eps)
return grad
w_test = np.random.randn(d)
grad_ana = gradient_analytic(w_test)
grad_num = gradient_numeric(w_test)
print(f"解析梯度: {grad_ana}")
print(f"数值梯度: {grad_num}")
print(f"误差: {np.linalg.norm(grad_ana - grad_num):.2e}")
print("结论: 解析梯度与数值梯度一致\n")
w = np.zeros(d)
lr = 0.1
losses = []
for epoch in range(100):
grad = gradient_analytic(w)
w = w - lr * grad
losses.append(loss(w))
print(f"真实权重: {w_true}")
print(f"学习的权重: {w}")
print(f"初始损失: {losses[0]:.4f}")
print(f"最终损失: {losses[-1]:.4f}")
w_analytic = np.linalg.solve(X.T @ X, X.T @ y)
print(f"解析解: {w_analytic}")
print(f"梯度下降解与解析解误差: {np.linalg.norm(w - w_analytic):.2e}\n")
if __name__ == "__main__":
print("╔" + "="*58 + "╗")
print("║" + " "*10 + "线性代数与矩阵论实验" + " "*26 + "║")
print("╚" + "="*58 + "╝")
print()
demonstrate_svd()
demonstrate_qr()
demonstrate_cholesky()
demonstrate_matrix_calculus()
print("="*60)
print("所有实验完成!")
print("="*60)
|
代码解读:
- SVD 演示:
- 验证 Eckart-Young 定理:秩逼近的误差等于第个奇异值起的平方和
- 显示奇异值谱:真实信号的奇异值快速衰减,噪声的奇异值平坦
- QR 分解演示:
- 对比三种求解最小二乘的方法:正规方程、 QR 分解、 SVD 伪逆
- 展示 QR 分解的数值稳定性优势(不需要计算, 条件数不会平方)
- Cholesky 分解演示:
- 验证的准确性
- 展示 Cholesky 分解在求解正定线性方程组中的速度优势
- 矩阵求导演示:
- 验证线性回归梯度的解析公式与数值梯度一致
- 实现梯度下降并与解析解对比
❓ Q&A:线性代数常见疑问
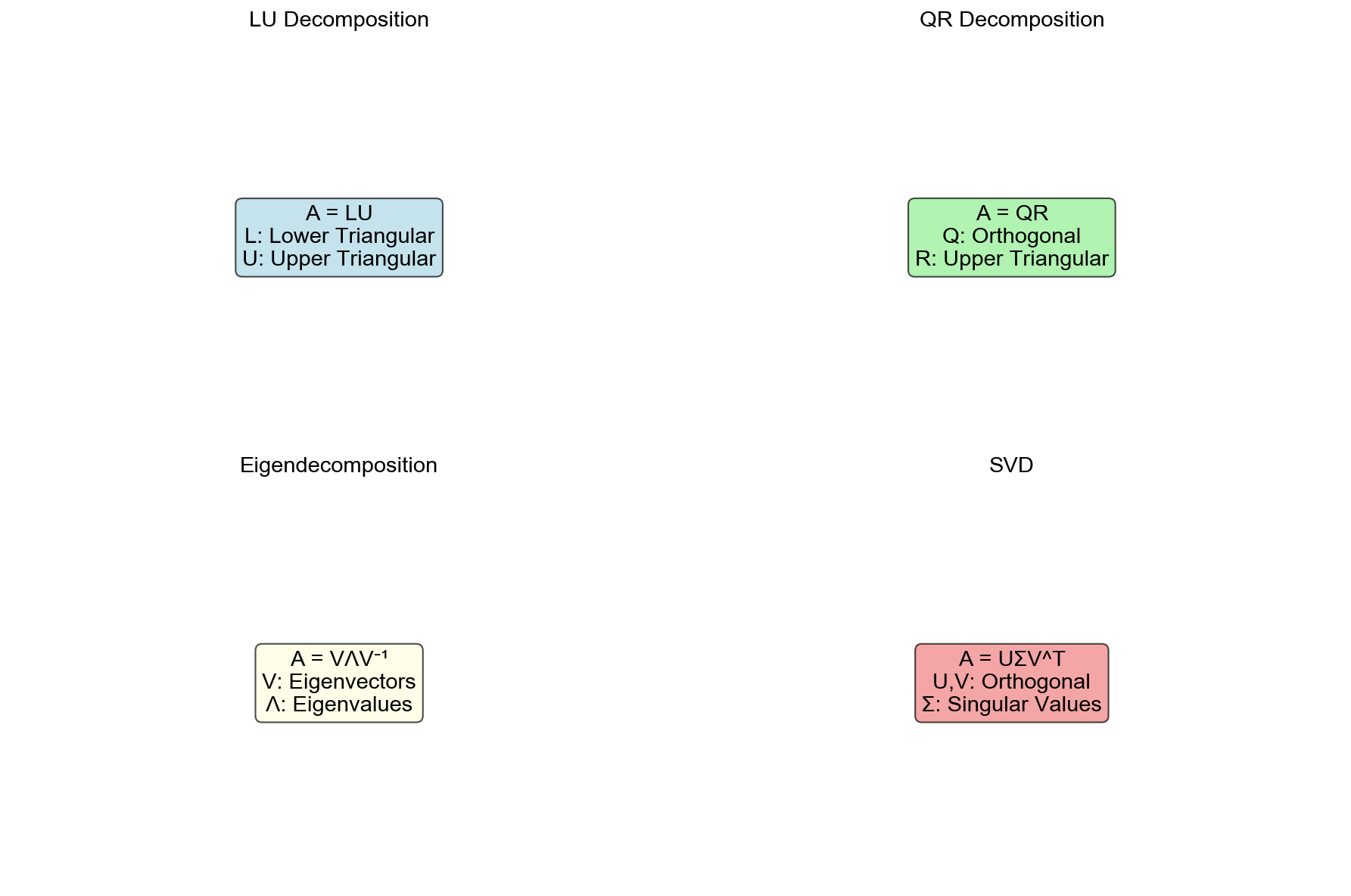
Q1:为什么 SVD
总是存在,而特征值分解不一定存在?
核心区别:
| 性质 |
特征值分解 |
奇异值分解 |
| 适用矩阵 |
方阵 |
任意矩阵 |
| 分解形式 |
|
|
| 左右向量 |
相同() |
不同(,) |
| 存在性 |
仅对可对角化矩阵 |
总是存在 |
| 值的性质 |
特征值可能是复数 |
奇异值总是非负实数 |
为什么 SVD 总是存在?
SVD 的构造不依赖于的结构,而是基于和:
-是对称半正定矩阵 -是对称半正定矩阵
对称矩阵的谱定理保证它们可以正交对角化,因此 SVD 总是存在。
特征值分解何时不存在?
非对称方阵可能不可对角化。例如:
特征值:(重特征值)
特征向量:只有 1 个线性无关的特征向量,无法构成的基。
因此不可对角化,特征值分解不存在(只存在
Jordan 标准形)。
实际应用:
- SVD 适用于任意数据矩阵,因此在
PCA、推荐系统、图像压缩中广泛使用
- 特征值分解用于对称矩阵(协方差矩阵、图拉普拉斯矩阵)或需要迭代求解的问题
下图对比了不同矩阵分解方法:原始矩阵、特征值分解重构、 SVD
低秩逼近以及奇异值能量分布曲线,直观展示了 SVD
如何通过保留主要奇异值实现数据压缩:
 Matrix Decomposition
Comparison
Matrix Decomposition
Comparison
Q2:什么时候应该使用
QR 分解而不是正规方程求解最小二乘?
正规方程的数值稳定性问题:
正规方程需要计算,这会导致条件数平方:
数值例子:
设的条件数(中等病态)。则:
-的相对误差可能被放大倍 -的相对误差可能被放大倍
在有限精度算术(如双精度浮点数,相对精度)下:
- 使用正规方程:有效数字损失约 6 位,结果可能只有 10 位有效数字
- 使用 QR 分解:有效数字损失约 3 位,结果有 13 位有效数字
实际例子:
考虑矩阵:
在双精度下,项会被舍入,导致几乎奇异,无法准确求解。
但 QR 分解直接作用于,不涉及,数值稳定。
建议:
- ✅ 对于的病态问题,使用 QR 分解或 SVD
- ✅ 对于的瘦高矩阵,QR
分解更高效
- ⚠️ 仅当条件数很小()且不太大时,使用正规方程
Q3:如何理解矩阵的秩?为什么秩很重要?
秩的多个等价定义:
列空间维数:
行空间维数:
线性无关列数:
最大线性无关列向量组的大小
非零奇异值个数:
几何意义:
秩是矩阵作为线性变换的"有效维数":
-意味着将维空间映射到维空间的一个维子空间 - 维数"损失" =(零空间维数)
为什么秩重要?
可逆性: -可逆
方程可解性: -有解
自由度:
数据降维:
实际应用:
| 领域 |
秩的含义 |
| 机器学习 |
特征的有效维数 |
| 推荐系统 |
用户-物品交互矩阵的潜在因子数 |
| 图像压缩 |
图像矩阵的低秩逼近 |
| 控制理论 |
系统的可控性/可观性 |
数值计算中的秩:
由于浮点误差,数值秩定义为:
其中是阈值(如)。
Q4:内积和范数有什么关系?为什么需要不同的范数?
内积诱导范数:
对于内积空间,内积自然诱导一个范数:
例如,标准内积 u, v = u^T vL
_2。
范数不一定来自内积:范数 |v|1 = |v_i|L
不能由任何内积诱导。
判断范数是否来自内积:平行四边形法则
范数由内积诱导满足平行四边形法则:
范数满足此法则,和不满足。
不同范数的应用:
| 范数 |
几何意义 |
应用 |
|
曼哈顿距离,菱形等值线 |
稀疏正则化(Lasso) |
|
欧几里得距离,圆形等值线 |
岭回归,支持向量机 |
|
切比雪夫距离,方形等值线 |
鲁棒优化,极小极大问题 |
|
非零元个数(非范数) |
特征选择,压缩感知 |
为什么能产生稀疏解?
范数的等值线在坐标轴上有尖角。当优化问题的约束集(如)与目标函数的等值线相交时,交点倾向于在坐标轴上(某些分量为
0),从而产生稀疏解。
图示:
1
2
3
4
5
6
7
8
9
10
| L1 约束(菱形) L2 约束(圆形)
w2 w2
| |
/|\ / \
/ | \ / \
/ | \ | |
----+----w1 -------w1
\ | / | |
\ | / \ /
\|/ \ /
|
L1 约束的尖角更容易触碰坐标轴(稀疏解)。
Q5:正定矩阵在机器学习中为什么如此重要?
正定矩阵的核心性质:
对称正定矩阵满足:
- 所有特征值
- 对所有,
- 可以写成(如 Cholesky
分解)
在优化中的作用:
定理:函数是凸函数 半正定
证明:Hessian 矩阵。函数凸 Hessian 半正定。
严格凸函数(唯一最优解):正定 严格凸唯一全局最小值。
实际应用:
- 线性回归的正规方程:
是半正定的。如果列满秩,正定,方程有唯一解。
核矩阵: 核函数对应的 Gram 矩阵必须正定(Mercer 定理)。
协方差矩阵:
数据的协方差矩阵总是半正定的。
二阶优化: 牛顿法、共轭梯度法依赖 Hessian
矩阵正定性。
负定矩阵的意义:
函数(正定)是凹函数,用于最大化问题。
判定正定性:
- 特征值:所有特征值
- Sylvester 准则:所有顺序主子式
- Cholesky 分解:尝试分解,成功则正定
- 数值方法:计算最小特征值
Q6:矩阵求导中的"分子布局"和"分母布局"有什么区别?
两种布局约定:
| 布局 |
规则 |
形状 |
常用领域 |
| 分子布局 |
导数形状与分子一致 |
与形状相同 |
统计学,机器学习 |
| 分母布局 |
导数形状与分母一致 |
与形状相同(转置) |
物理学,工程学 |
例子:
设,, Jacobi 矩阵:
标量对向量求导:
设。
重要公式的对比:
本文的约定:
本章采用分子布局,理由:
- 与向量/矩阵的自然形状一致
- 在机器学习文献中更常见
- 梯度是列向量,便于梯度下降
实践建议:
- ✅ 阅读论文时,先确认作者的布局约定
- ✅ 自己的代码/推导中保持一致
- ✅ 使用自动微分库(如 PyTorch, JAX)避免手工推导
Q7:如何快速判断一个矩阵是否可逆?
理论判据:
矩阵可逆以下任一条件成立:
- (零空间只有零向量)
- 所有特征值非零
- 行向量(或列向量)线性无关
- 可以通过行变换化为单位矩阵
数值判据(实际计算):
由于浮点误差,使用:
- 条件数:
- 最小奇异值:
- LU 分解: 尝试 LU
分解,如果遇到零主元(或极小主元),矩阵奇异
快速检查(无需全部计算):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| def is_invertible_quick(A, tol=1e-10):
"""
快速判断矩阵是否数值可逆
"""
if A.shape[0] <= 10:
return abs(np.linalg.det(A)) > tol
kappa = np.linalg.cond(A)
return kappa < 1 / tol
try:
x = np.linalg.solve(A, np.ones(A.shape[0]))
residual = np.linalg.norm(A @ x - np.ones(A.shape[0]))
return residual < tol
except np.linalg.LinAlgError:
return False
|
特殊矩阵的可逆性:
| 矩阵类型 |
可逆条件 |
| 对角矩阵 |
所有对角元非零 |
| 三角矩阵 |
所有对角元非零 |
| 正交矩阵 |
总是可逆() |
| 对称正定 |
总是可逆 |
| 幂等矩阵() |
仅当时可逆 |
Q8:SVD
和 PCA 有什么关系?为什么 PCA 用协方差矩阵的特征值分解?
PCA 的两种等价推导:
方法 1:最大方差(协方差矩阵特征值分解)
给定中心化数据矩阵(每列均值为 0)。
目标:找到方向,,使得数据在此方向上的方差最大。
方差:
其中是协方差矩阵。
优化问题:
由 Lagrange 乘数法,最优解满足:
即是的特征向量,是特征值。最大方差对应最大特征值。
方法 2:最小重构误差(数据矩阵 SVD)
目标:找到秩矩阵使得最小。
由 Eckart-Young 定理,最优解是的秩 SVD 逼近:
其中是前个右奇异向量,恰好是(协方差矩阵的倍)的前个特征向量。
两种方法的等价性:
即:
- 的右奇异向量的特征向量(PCA
的主成分方向)
- 的奇异值的平方的特征值(解释方差)
实际计算的选择:
| 方法 |
公式 |
适用场景 |
| 协方差矩阵特征值分解 |
|
(样本多,特征少) |
| 数据矩阵 SVD |
|
(高维数据,如图像) |
为什么高维时 SVD 更好?
- 协方差矩阵:,需要时间
- 数据矩阵 SVD:,经济型 SVD 只需时间
当(如图像像素数,样本数),SVD 快得多。
Q9:为什么说"秩 1
矩阵是矩阵的原子"?
秩 1 矩阵的定义:
矩阵是秩 1 矩阵,如果。
等价条件:可以写成两个向量的外积:
为什么称为"原子"?
任意矩阵都可以分解为秩 1 矩阵的和。这类似于:
- 向量可以分解为基向量的线性组合
- 函数可以分解为傅里叶级数(正弦/余弦函数的和)
SVD 的秩 1 分解:
每一项是秩 1
矩阵,是个秩 1 矩阵的加权和。
秩 1 矩阵的性质:
- 简单结构:完全由两个向量决定
- 低存储:存储矩阵需要个数,秩 1
矩阵只需个数
- 快速乘法:,先算内积(),再缩放(),总共,远小于
应用:
低秩矩阵补全(推荐系统):
用户-物品评分矩阵可以近似为秩矩阵(很小):
神经网络压缩:
权重矩阵用秩逼近,参数从减少到。
快速矩阵乘法:
如果,则,计算量从降到。
Q10:Gram
矩阵()和 Gram-Schmidt
正交化有什么关系?
Gram 矩阵的定义:
给定矩阵, Gram 矩阵定义为:
元素为:
即列向量之间的内积。
Gram 矩阵的性质:
- 对称:
- 半正定:
- 秩:
- 可逆性:可逆 列满秩
Gram-Schmidt 正交化:
目标:将转化为标准正交基。
过程:
关系:
Gram-Schmidt 正交化本质上是在"去掉在前个向量张成的子空间上的投影",这等价于:
- 计算投影:
- 计算正交分量:
- 归一化
Gram 矩阵的 Cholesky 分解:
如果列满秩,则正定,可以 Cholesky 分解:
其中是下三角矩阵。实际上,的列正比于 Gram-Schmidt
过程的中间向量(未归一化)。
数值稳定性:
经典 Gram-Schmidt(CGS)数值不稳定:后续向量可能不正交。
修改的 Gram-Schmidt(MGS)更稳定:每次只对一个向量正交化。
QR 分解与 Gram-Schmidt 的关系:
QR 分解可以通过
Gram-Schmidt 得到:
-$Q R r_{ij} = q_i^T
x_j$
这正是 Gram 矩阵的 Cholesky 分解!
🎓 总结:线性代数核心要点
记忆公式:
四个基本子空间:
SVD 分解:
谱定理(对称矩阵):
矩阵求导:
记忆口诀:
SVD 分解万能钥匙(任意矩阵可分解)
对称矩阵特征值实(谱定理保证正交)
正定矩阵优化好(凸函数唯一解)
QR 分解数值稳(最小二乘首选)
实战 Checklist:
✏️ 练习题与解答
练习 1:特征值与特征向量
题目:设矩阵,求的所有特征值和特征向量,并验证可以对角化。
解答:
特征方程:
解得,。
对:,即,得。
对:,即,得。
验证对角化:,,则。
可以验证,因此可通过正交对角化分解。这正是谱定理在对称矩阵上的体现。
练习 2:SVD 与低秩逼近
题目:设矩阵,求的 SVD
分解,并给出秩 1 的最佳逼近矩阵。
解答:
首先计算。
的特征值:,解得,。
奇异值:,。
右奇异向量由的特征向量构成(单位化),左奇异向量。
秩 1 最佳逼近:。由 Eckart-Young 定理,逼近误差为。
练习 3:矩阵求导
题目:设,其中是对称矩阵。求和,并说明当正定时的最小值。
解答:
梯度:
(因为对称,)
Hessian 矩阵:
当正定时,正定,因此是严格凸函数。令:
最小值为:
练习 4:正定矩阵与 Cholesky
分解
题目:证明对称正定矩阵一定存在唯一的 Cholesky 分解,其中是对角元为正的下三角矩阵。对验证之。
解答:
存在性证明(归纳法,对矩阵阶数):
:,(正定),取。
设阶时成立。将阶正定矩阵分块:
令,其中(因为正定矩阵主对角元为正),,。
由正定性,仍然正定(Schur 补),由归纳假设,存在。
唯一性:若,则,左边是下三角,右边是上三角,因此(对角矩阵)。由于和的对角元都为正,,即。
验证:。
,,。
练习 5:条件数与数值稳定性
题目:矩阵,计算其 2-范数条件数,并说明为什么用求解线性方程组时会面临数值稳定性问题。
解答:
的特征值:。
由于对称正定,奇异值等于特征值,所以:
条件数约为,属于病态矩阵。这意味着:
- 右端向量的微小扰动会导致解产生倍放大的变化:
- 在浮点运算中,即使本身没有误差,舍入误差也可能被放大约倍,导致解的有效数字损失约 4 位
- 实际应用中应考虑使用正则化(如 Tikhonov 正则化:)来改善数值稳定性
📚 参考文献
Strang, G. (2006). Linear Algebra and Its
Applications (4th ed.). Cengage Learning.
Golub, G. H., & Van Loan, C. F. (2013). Matrix
Computations (4th ed.). Johns Hopkins University
Press.
Horn, R. A., & Johnson, C. R. (2012). Matrix
Analysis (2nd ed.). Cambridge University Press.
Trefethen, L. N., & Bau III, D. (1997). Numerical
Linear Algebra. SIAM.
Axler, S. (2015). Linear Algebra Done Right (3rd
ed.). Springer.
Petersen, K. B., & Pedersen, M. S. (2012). The Matrix
Cookbook. Technical University of Denmark.
Eckart, C., & Young, G. (1936). The approximation of
one matrix by another of lower rank. Psychometrika,
1(3), 211-218.
Meyer, C. D. (2000). Matrix Analysis and Applied Linear
Algebra. SIAM.
Boyd, S., & Vandenberghe, L. (2004). Convex
Optimization. Cambridge University Press.
Magnus, J. R., & Neudecker, H. (2019). Matrix
Differential Calculus with Applications in Statistics and
Econometrics (3rd ed.). Wiley.
下一章预告:第 3
章将深入探讨概率论与统计推断,包括常见分布、最大似然估计、贝叶斯估计等,为概率模型打下基础。