正则化(Regularization)是机器学习中控制模型复杂度、防止过拟合的核心技术——当训练数据有限时,模型容易记住噪声而非真实规律。从 L1/L2 正则的数学形式到其贝叶斯先验解释,从 Dropout 的随机失活到早停的隐式正则化,从交叉验证的模型选择到 VC 维的泛化界,正则化理论为平衡欠拟合与过拟合提供了数学保证。L1 正则产生稀疏解,L2 正则等价于高斯先验,Dropout 可视为模型平均,早停相当于自适应的权重衰减,而 VC 维和 PAC 学习则从理论上界定了泛化能力。


过拟合与泛化能力
过拟合的数学刻画
训练误差(经验风险):
泛化误差(期望风险):
泛化差距:
过拟合:
欠拟合:
偏差方差权衡
回归问题的期望泛化误差分解:
假设真实模型
期望泛化误差(对所有可能的
分解推导:
第三项:
进一步分解第一项:
定义 {f}() = _{}[_{}()]$$
第三项:
最终分解:
物理解释:
- 偏差( Bias):模型平均预测与真实值的差距,衡量欠拟合
- 方差( Variance):不同训练集导致的预测波动,衡量过拟合
- 不可约误差:数据本身的噪声
模型复杂度与泛化的权衡
简单模型(低复杂度):
- 高偏差(欠拟合)
- 低方差(稳定)
复杂模型(高复杂度):
- 低偏差(拟合训练数据)
- 高方差(对训练数据敏感,过拟合)
最优复杂度:平衡偏差与方差,最小化总误差

L2 正则化:岭回归
优化形式
目标函数:
其中
线性回归的岭回归:
求解:
闭式解:
正则化的作用:
- 防止
奇异(不可逆) - 收缩权重向 0(权重衰减)
贝叶斯解释
最大后验估计 (MAP):
取对数:
等价于:
假设:
- 似然:
- 先验:
(高斯先验)
推导:
组合:
结论:L2 正则化等价于高斯先验下的 MAP 估计,
权重衰减的梯度下降
梯度更新:
改写为:
物理意义:每次更新前,权重先衰减到
SVD 视角的岭回归
线性回归的 SVD 分解:
无正则化的解:
岭回归的解:
收缩因子:
- 大奇异值
:收缩因子 (保留) - 小奇异值
:收缩因子 (抑制)
直觉:岭回归抑制了对应小奇异值的方向(噪声方向)
L1 正则化: Lasso
优化形式
目标函数:
其中
线性回归的 Lasso:
特点:不可微(在 0 点),需要特殊优化算法
稀疏性诱导
L1 vs L2 的几何直觉:
考虑约束优化形式:
- L2 约束:
(球形) - L1 约束:
(菱形,在坐标轴上有尖角)
等高线与约束的切点:
- L2:切点通常不在坐标轴上,
非稀疏 - L1:切点倾向于在坐标轴上(尖角处),
部分为 0,稀疏!
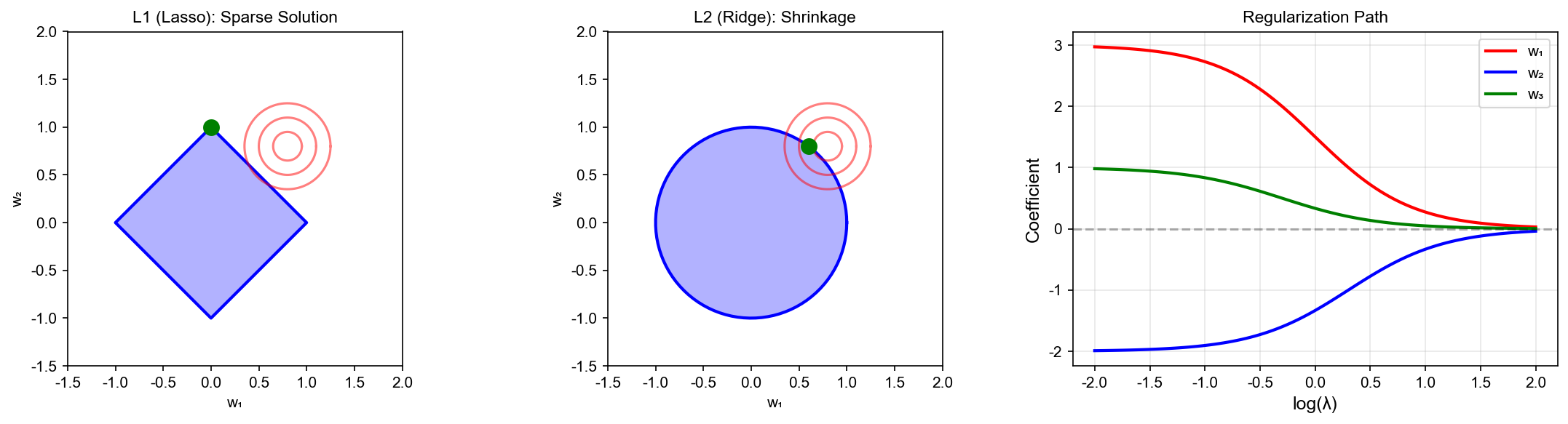
数学分析:
L1 的次梯度:
软阈值算子(Soft-thresholding):
结论: L1 正则化会将小权重直接置为 0,实现特征选择
贝叶斯解释
Laplace 先验:
负对数先验:
结论: L1 正则化等价于 Laplace 先验下的 MAP 估计
LASSO 求解算法
坐标下降法( Coordinate Descent):
对每个坐标
其中
近端梯度下降(Proximal Gradient Descent):
其中近端算子:
Elastic Net: L1 + L2
组合正则化:
优势:
- 保留 L1 的稀疏性
- 避免 L1 在高相关特征时不稳定的问题
- L2 的群组效应:相关特征倾向于同时选择或丢弃
Dropout:随机失活正则化
Dropout 机制
训练时:
每个神经元以概率
$
除以
测试时:
使用所有神经元,不进行 Dropout(或等价地使用期望)
集成学习视角
想法: Dropout 训练了指数级多个子网络
假设网络有
训练:每次 mini-batch 采样一个子网络
测试:近似为所有子网络的平均(权重共享)
类比 Bagging:训练多个模型并平均
正则化效果的数学分析
近似 L2 正则:
考虑线性模型
其中
期望与方差:
最小化方差相当于惩罚
深层网络: Dropout 防止神经元共适应( co-adaptation),强制学习鲁棒特征
Dropout 变体
DropConnect:随机失活权重而非神经元
Spatial Dropout( CNN 专用):对整个特征图 Dropout
Variational Dropout:在 RNN 中对时间步共享掩码
早停与隐式正则化
早停策略
算法:
- 在训练过程中监控验证集误差
- 当验证集误差连续
个 epoch 不下降时停止 - 返回验证集误差最小的模型
效果:防止过拟合,类似于正则化
早停的数学解释
梯度下降的轨迹:
初始化
早停 = 限制迭代次数
对于凸二次损失(如线性回归),可以证明早停与 L2 正则化等价
直觉:
- 训练初期:学习主要模式(低频分量)
- 训练后期:拟合噪声(高频分量)
早停在学到主要模式后停止,避免拟合噪声
早停与 L2 正则的关系
线性回归例子:
损失函数:
梯度下降更新:
可以证明(通过 SVD 分解):
其中
结论:早停相当于自适应的岭回归,
数据增强
数据增强策略
图像:
- 随机裁剪、翻转、旋转
- 颜色抖动、亮度/对比度调整
- Mixup:线性插值两张图片
文本:
- 同义词替换
- 回译(翻译成其他语言再翻译回来)
- 随机插入/删除/交换
数学原理:
数据增强等价于在损失函数中添加关于变换的不变性约束
其中
Mixup 数学分析
Mixup:
其中
正则化效果:
鼓励模型在训练样本之间进行线性插值,平滑决策边界
理论分析: Mixup 等价于在特征空间中添加平滑正则项
模型选择与交叉验证
交叉验证策略
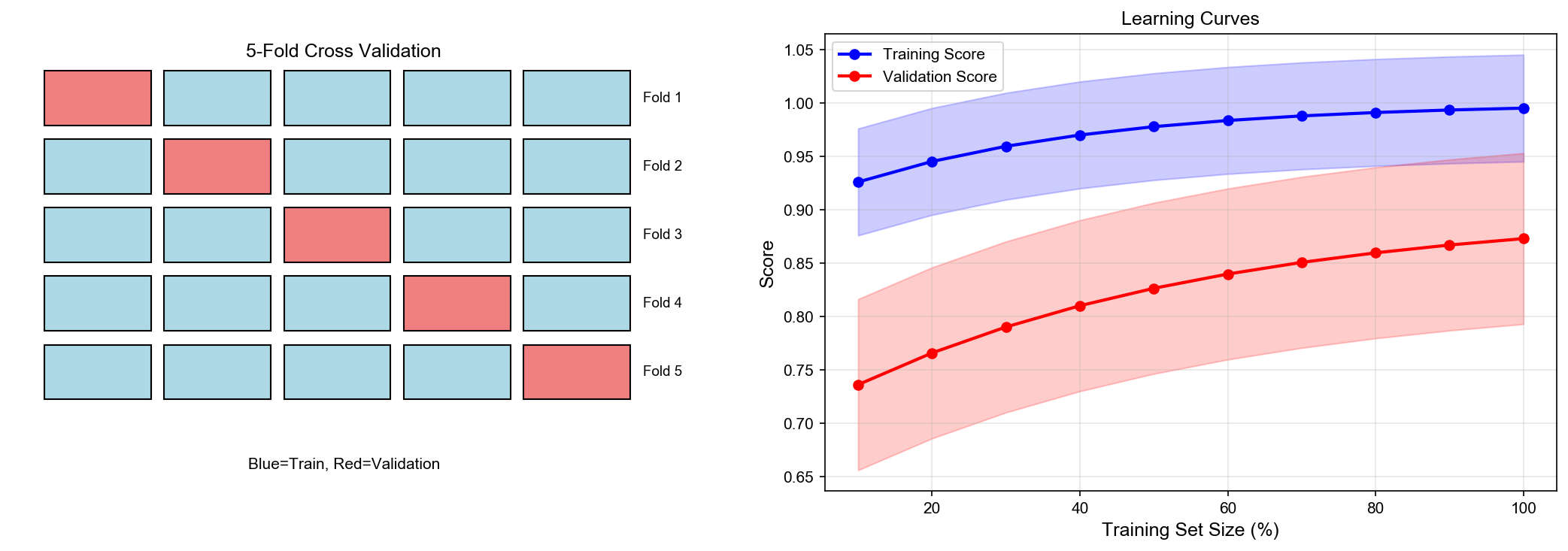
K-fold 交叉验证:
- 将数据分为
折(通常 或 10) - 对每一折
: - 用其余
折训练 - 在第
折验证
- 用其余
- 平均
次验证误差
估计泛化误差:
留一交叉验证 (LOO-CV):
- 无偏估计
- 计算量大
次训练
时间序列交叉验证:
保持时间顺序,只用过去数据训练,未来数据验证
信息准则
AIC (Akaike Information Criterion):
其中
BIC (Bayesian Information Criterion):
原理:平衡拟合度与复杂度
- 第一项:负对数似然(越小越好)
- 第二项:复杂度惩罚(越简单越好)
AIC vs BIC:
- BIC 对复杂度惩罚更重(
当 ) - BIC 倾向于选择更简单的模型
- AIC 渐近最优(预测视角)
- BIC 一致性(
时恢复真实模型)
学习曲线与验证曲线
学习曲线:误差 vs 训练样本数
- 训练误差:单调上升
- 验证误差:单调下降
- 两者收敛:欠拟合
- 两者差距大:过拟合
验证曲线:误差 vs 超参数(如
- 左侧(
小):过拟合 - 右侧(
大):欠拟合 - U 型曲线最低点:最优超参数
泛化理论: VC 维与 PAC 学习
VC 维定义
打散 (Shatter):假设空间
VC 维:
例子:
- 1D 线性分类器: VC 维 = 2
- 2D 线性分类器: VC 维 = 3 -
维线性分类器: VC 维 =
VC 维与泛化界
定理( Vapnik-Chervonenkis):
以概率至少
含义:
- VC 维越大,泛化界越松(需要更多数据)
- 样本数
越大,泛化界越紧
权衡:
- 复杂模型(高 VC 维):训练误差小,泛化界松
- 简单模型(低 VC 维):训练误差大,泛化界紧
PAC 学习框架
PAC(Probably Approximately Correct):
给定:
- 误差阈值
- 置信度
如果存在算法,以概率至少
其中
样本复杂度:
要达到
结论:有限 VC 维
Rademacher 复杂度
定义:衡量假设空间在随机标签上的拟合能力
其中
泛化界:
优势:
- 比 VC 维更精细
- 对数据分布敏感
- 便于分析深度学习(通过范数界)
深度学习的泛化之谜
现象:深度神经网络参数数量
经典理论失效:
- VC 维
(巨大) - Rademacher 复杂度也很高
- 但测试误差仍然很小!
现代解释:
- 隐式正则化: SGD 倾向于收敛到平坦最小值(低 Hessian 特征值)
- 范数约束:实际学到的权重范数远小于理论上界
- 压缩界:基于 PAC-Bayes 、信息论的新界
- 双下降曲线:现代过参数化 regime 的新现象
代码实现:正则化技术
L1/L2 正则化实现
1 | import numpy as np |
Dropout 实现
1 | class DropoutLayer: |
早停实现
1 | class EarlyStopping: |
交叉验证实现
1 | from sklearn.model_selection import KFold |
综合示例
1 | def regularization_comparison(): |
深入问答
Q1: L1 正则为什么产生稀疏解,而 L2 不会?
A:几何和优化两个角度:
几何:约束优化的可行域 - L1:菱形(有尖角),等高线倾向于在尖角处相切 - L2:圆形(光滑),等高线在光滑边界相切
优化:次梯度 - L1 在 0 点次梯度为
Q2:为什么 Dropout 在训练时需要除以(1-p)?
A:保持期望不变!
训练时:
测试时:
如果不缩放,测试时激活值是训练时的
另一种做法( Inverted Dropout):训练时缩放,测试时不变( PyTorch 采用)
Q3:为什么早停类似 L2 正则化?
A:对于凸二次损失,梯度下降的轨迹可用 SVD 分解:
当
Q4: Batch Normalization 算正则化吗?
A: BN 主要是加速训练(稳定梯度),但有副作用的正则化效果:
- 噪声注入: mini-batch 统计量有噪声,类似 Dropout
- 缩放不变性:权重范数不影响输出,隐式正则化
但 BN 的正则化效果比 Dropout 弱,通常需要结合其他正则化方法。
Q5:如何选择正则化强度λ?
A:三种方法:
- 交叉验证:网格搜索
(对数尺度) - 学习曲线:绘制训练/验证误差 vs
,选择 U 型曲线最低点 - 贝叶斯优化:高效搜索超参数空间
实践中,从
Q6:数据增强为什么有效?
A:两个角度:
- 增加有效样本数:
( 是增强倍数) - 引入先验知识:如图像旋转不变性、翻译不变性
数学上,数据增强等价于在损失函数中添加对称性约束(群不变性)。
Q7: VC 维能预测深度学习的泛化吗?
A:不能!深度神经网络的 VC 维巨大(
现代理论: - PAC-Bayes 界:基于权重范数 - 压缩界:基于信息论 - 隐式正则化: SGD 偏好平坦最小值
VC 维对经典机器学习( SVM 、决策树)仍有指导意义。
Q8:过参数化为什么有助于泛化?
A:反直觉的"双下降"现象:
- 欠参数化区域:增加参数降低测试误差
- 插值阈值:参数数 = 样本数,最差泛化
- 过参数化区域:继续增加参数,测试误差再次下降!
解释:过参数化使得优化景观更平滑, SGD 找到的解更鲁棒(最小范数插值)。
Q9:如何诊断模型是否需要正则化?
A:检查学习曲线:
1 | plt.plot(train_loss, label='Train') |
- 训练 loss ≪ 验证 loss:过拟合,增加正则化
- 训练 loss ≈ 验证 loss,但都很高:欠拟合,减少正则化
- 训练 loss 和验证 loss 都低:良好拟合
Q10: Dropout 、 L2 正则、数据增强能同时使用吗?
A:可以!它们作用于不同方面:
- L2 正则:限制权重大小
- Dropout:防止神经元共适应
- 数据增强:引入不变性先验
实践中常见组合: - CNN:数据增强 + L2 正则 + Dropout - Transformer: Dropout + 梯度裁剪 + 标签平滑
注意:过度正则化会导致欠拟合,需要交叉验证调优。
Q11:为什么 ImageNet 预训练模型泛化这么好?
A:三个因素:
- 数据规模:百万级样本学到通用特征(边缘、纹理、物体部件)
- 隐式正则化: SGD + BN + 数据增强
- 迁移学习:低层特征通用,高层特征任务特定
预训练模型相当于强先验,大幅减少目标任务所需样本数。
Q12:学习理论对实践有什么指导?
A:三点启示:
- 样本复杂度:复杂模型需要更多数据,否则过拟合
- 正则化必要性:有限样本下,正则化必不可少
- 模型选择:平衡偏差与方差,选择适当复杂度
但注意:现代深度学习超出传统理论框架,实践中需要经验和实验。
✏️ 练习题与解答
练习 1:L2正则化
题目:损失
练习 2:L1 vs L2
题目:L1和L2正则化区别? 解答:L1产生稀疏解(特征选择),L2产生小权重(平滑)。L1不可微,需次梯度;L2可微,等价权重衰减。
练习 3:Early Stopping
题目:Early Stopping如何防止过拟合? 解答:监控验证集误差,误差不再下降时停止训练,避免过度拟合训练数据。相当于隐式正则化。
练习 4:交叉验证
题目:k折交叉验证如何选超参数? 解答:数据分k份,每次1份做验证、k-1份训练,重复k次取平均。遍历超参数网格,选验证误差最小的。
练习 5:AIC vs BIC
题目:AIC和BIC区别?
解答:AIC=
参考文献
[1] Tikhonov, A. N. (1963). Solution of incorrectly formulated problems and the regularization method. Soviet Mathematics Doklady, 5, 1035-1038.
[2] Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B, 58(1), 267-288.
[3] Zou, H., & Hastie, T. (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B, 67(2), 301-320.
[4] Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(1), 1929-1958.
[5] Vapnik, V. N., & Chervonenkis, A. Y. (1971). On the uniform convergence of relative frequencies of events to their probabilities. Theory of Probability & Its Applications, 16(2), 264-280.
[6] Valiant, L. G. (1984). A theory of the learnable. Communications of the ACM, 27(11), 1134-1142.
[7] Bartlett, P. L., & Mendelson, S. (2002). Rademacher and Gaussian complexities: Risk bounds and structural results. Journal of Machine Learning Research, 3, 463-482.
[8] Zhang, C., Bengio, S., Hardt, M., Recht, B., & Vinyals, O. (2017). Understanding deep learning requires rethinking generalization. ICLR.
[9] Neyshabur, B., Bhojanapalli, S., McAllester, D., & Srebro, N. (2017). Exploring generalization in deep learning. NeurIPS, 5947-5956.
[10] Nakkiran, P., Kaplun, G., Bansal, Y., Yang, T., Barak, B., & Sutskever, I. (2020). Deep double descent: Where bigger models and more data hurt. ICLR.
- 本文标题:机器学习数学推导(二十)正则化与模型选择
- 本文作者:Chen Kai
- 创建时间:2021-12-17 16:00:00
- 本文链接:https://www.chenk.top/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%95%B0%E5%AD%A6%E6%8E%A8%E5%AF%BC%EF%BC%88%E4%BA%8C%E5%8D%81%EF%BC%89%E6%AD%A3%E5%88%99%E5%8C%96%E4%B8%8E%E6%A8%A1%E5%9E%8B%E9%80%89%E6%8B%A9/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!