朴素贝叶斯(Naive Bayes)是最简单也最优雅的概率分类器——它基于贝叶斯定理和条件独立假设,将复杂的联合概率分解为简单的条件概率乘积,从而实现高效的分类学习。尽管"朴素"假设在现实中往往不成立,朴素贝叶斯却在文本分类、垃圾邮件过滤、情感分析等任务中展现出惊人的效果。本章将系统推导朴素贝叶斯的理论基础、参数估计方法、平滑技术与性能分析。
贝叶斯决策论基础
贝叶斯定理与后验概率
贝叶斯定理是概率论的核心公式,描述了如何通过观测数据更新先验信念:
其中: -
推导:由条件概率定义和全概率公式:
整理即得贝叶斯定理。
贝叶斯最优分类器
对于分类任务,贝叶斯决策论给出最优决策规则:选择后验概率最大的类别:
由于分母
这就是最大后验概率( Maximum A Posteriori, MAP)准则。
理论保证:贝叶斯最优分类器最小化分类错误率:
这是任何分类器能达到的最小误差( Bayes Error)。
判别模型与生成模型
判别模型( Discriminative Model):直接学习
生成模型( Generative Model):学习联合分布
朴素贝叶斯是典型的生成模型。
朴素贝叶斯分类器
条件独立假设
对于高维特征
朴素贝叶斯假设( Naive Bayes
Assumption):在给定类别
直觉解释:类别是"原因",特征是"结果"。假设各个"结果"在原因确定后独立发生。
朴素贝叶斯分类规则
结合贝叶斯定理和条件独立假设:
分类器:
为避免数值下溢,实践中使用对数概率:
下图展示了贝叶斯定理的直观理解——如何从先验概率和似然函数得到后验概率,以及条件独立假设的可视化:
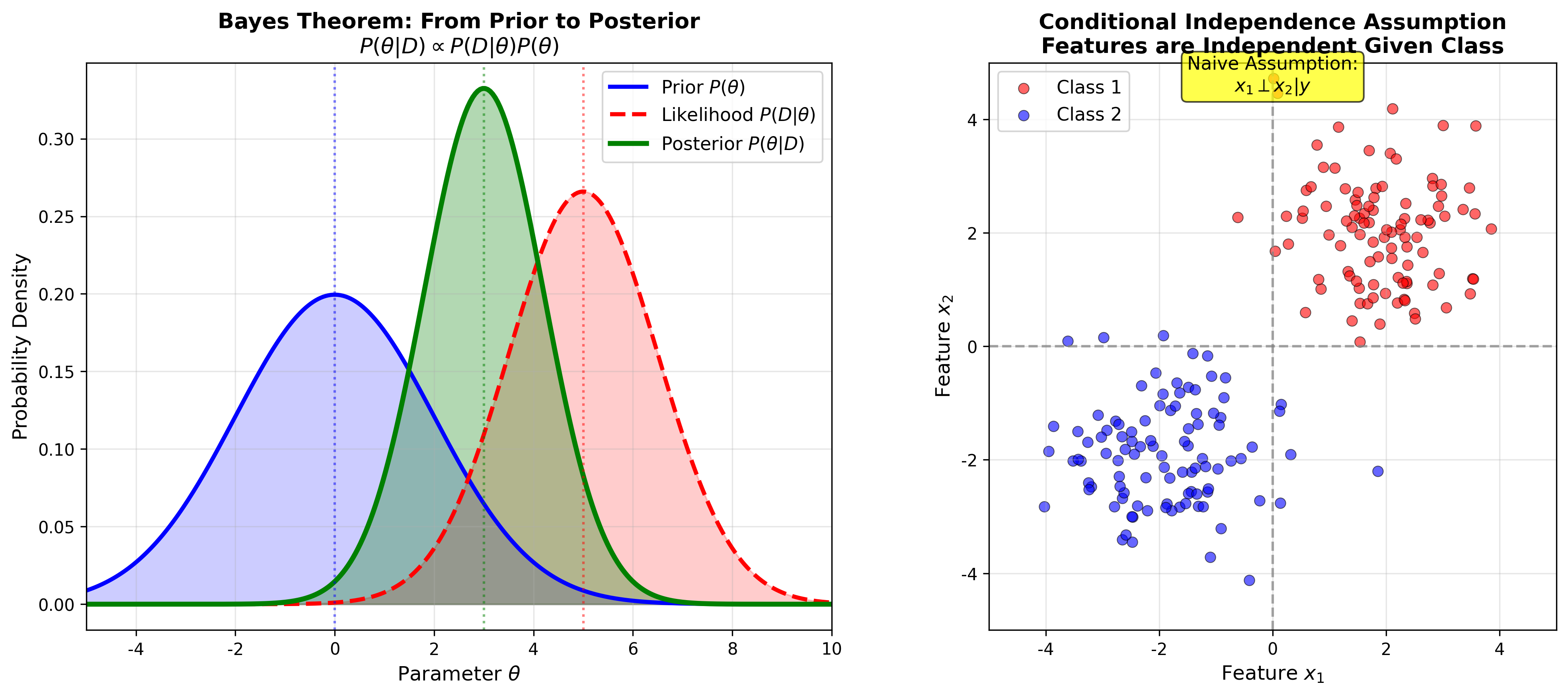
下图对比了真实的特征相关分布(左图)与朴素贝叶斯的条件独立假设(右图)。尽管朴素假设很强,但在实践中朴素贝叶斯往往表现出色,因为分类任务只需要正确的相对概率排序,而不需要精确的概率值:

参数估计:极大似然法
给定训练集
- 先验概率:
- 类条件概率:
先验概率估计:
其中
类条件概率估计:根据特征类型不同:
离散特征
对于取值集合
即:类别
连续特征
假设类条件概率服从高斯分布:
参数估计:
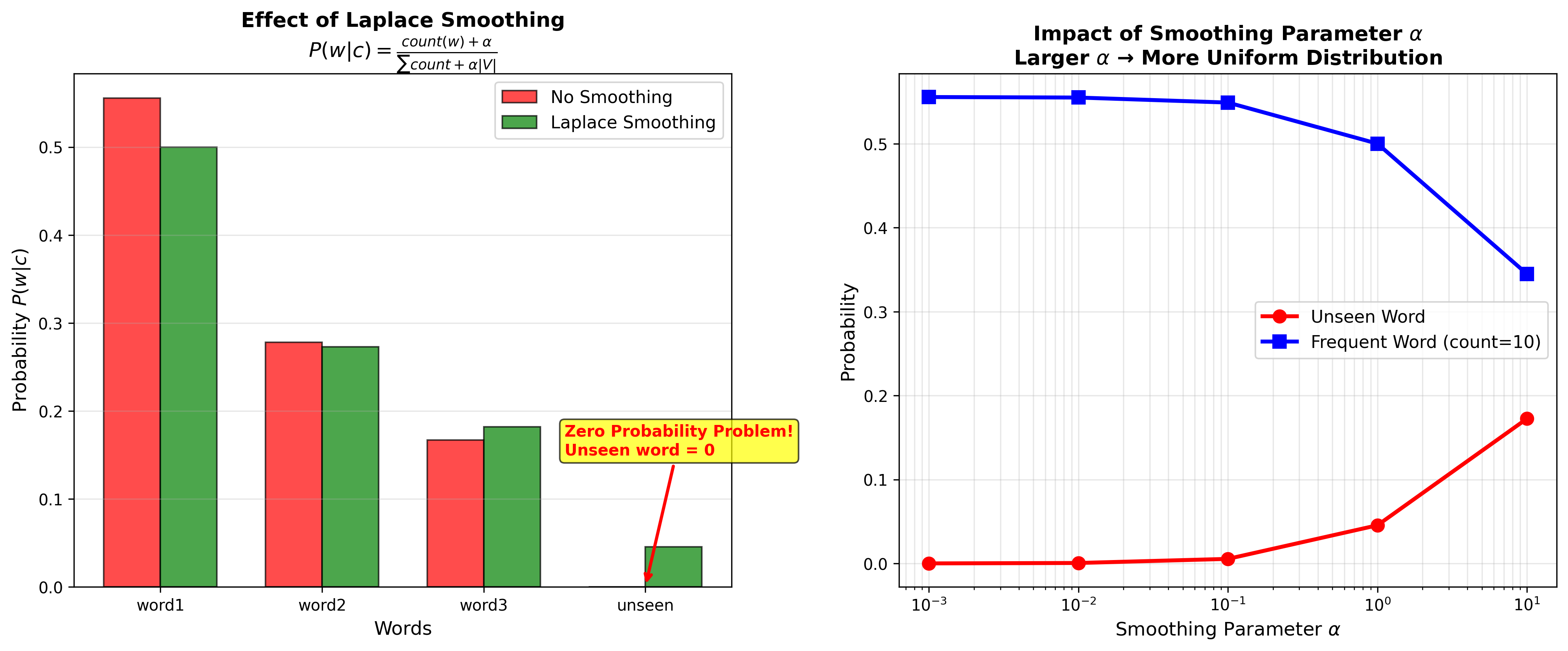
拉普拉斯平滑
零概率问题:若训练集中某个类别
拉普拉斯平滑( Laplace
Smoothing):为每个计数加上伪计数
其中
先验概率平滑:
其中
贝叶斯解释:拉普拉斯平滑等价于在多项分布上引入
Dirichlet 先验
朴素贝叶斯的三种模型
多项式朴素贝叶斯( Multinomial NB)
适用于离散计数特征,如文本数据的词频。
模型:假设特征
其中
下图展示了文本分类中朴素贝叶斯的应用——从词频统计到分类决策的完整流程:
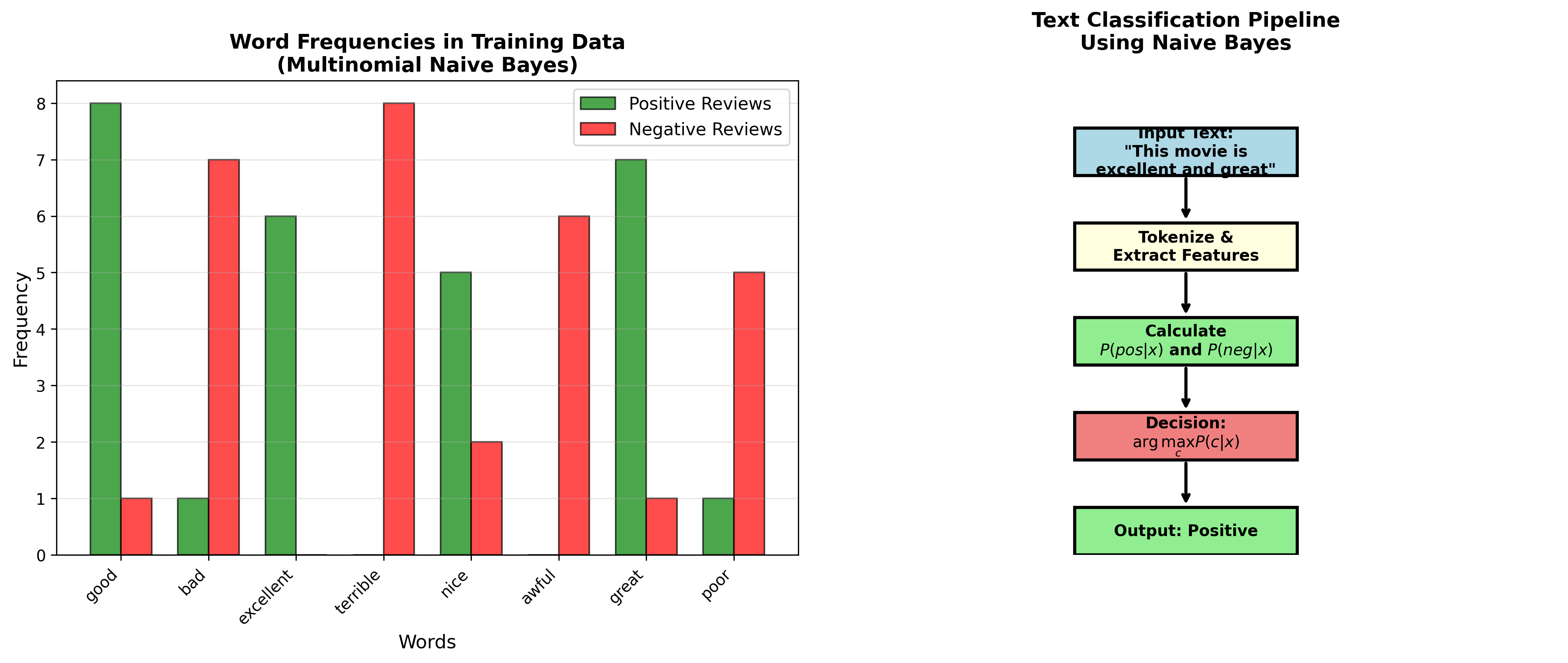
下图展示了拉普拉斯平滑的效果——如何解决零概率问题:
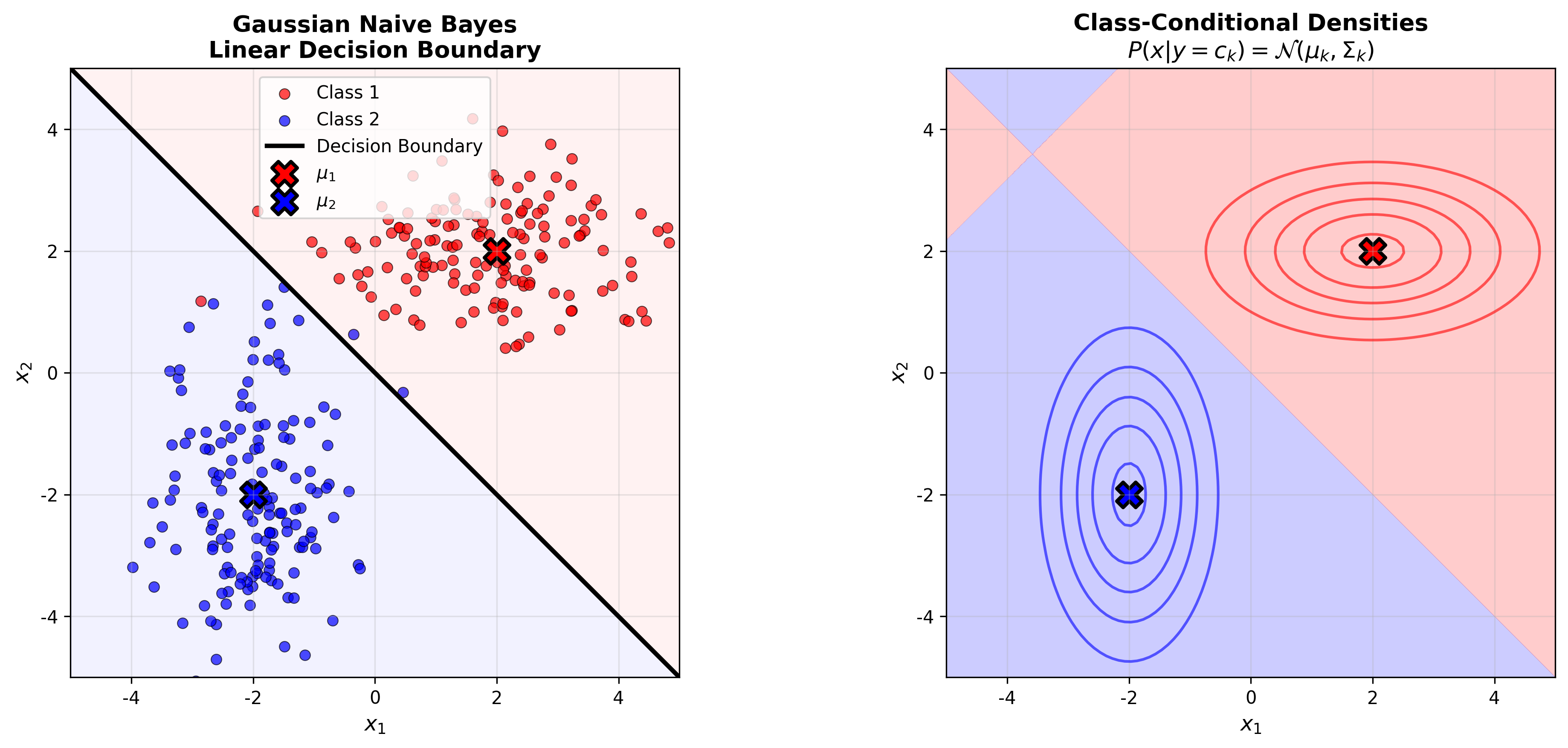
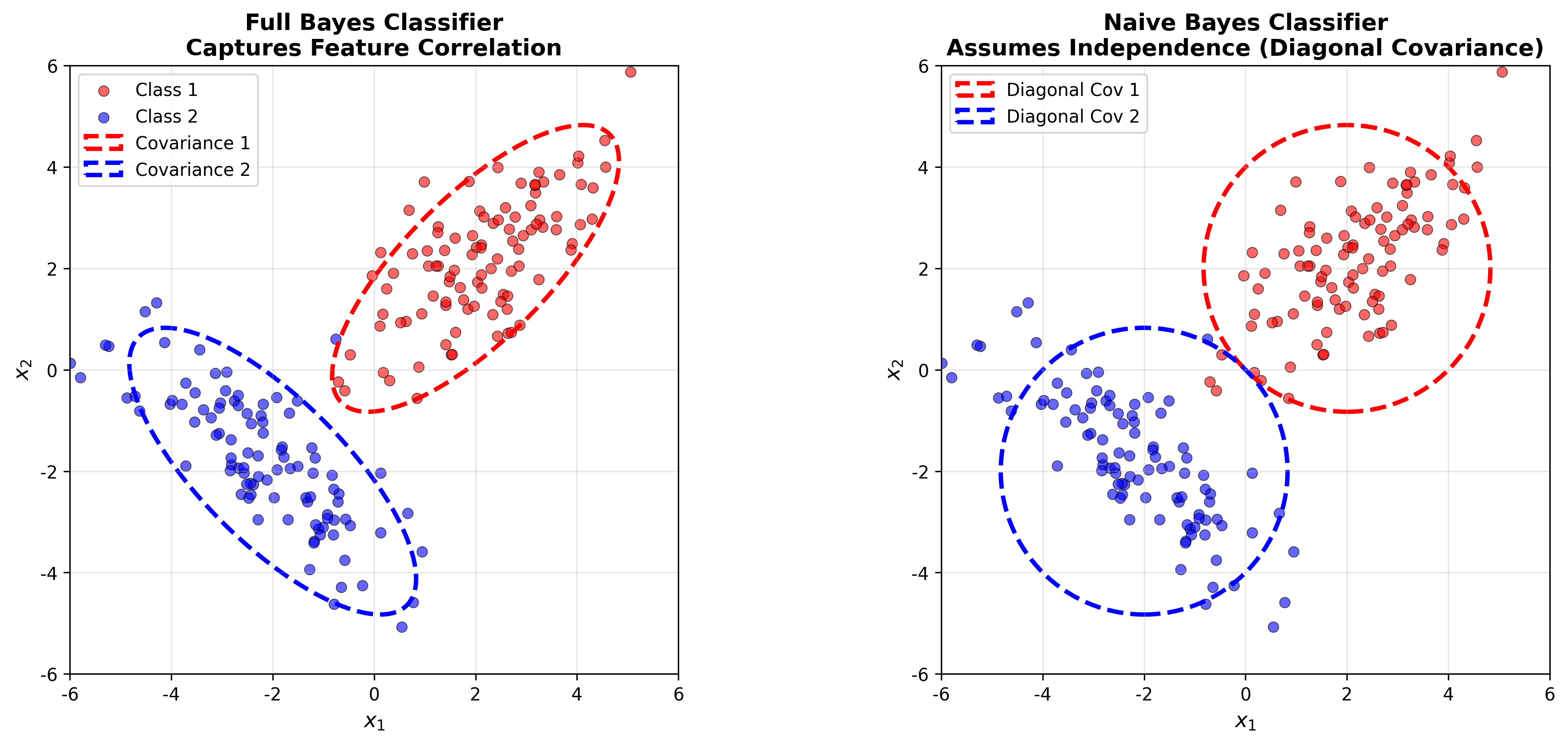
下图对比了朴素贝叶斯与完整贝叶斯分类器的差异——朴素贝叶斯假设特征独立(对角协方差),而完整贝叶斯捕获特征相关性:
参数估计:
即:类别
拉普拉斯平滑:
伯努利朴素贝叶斯( Bernoulli NB)
适用于二值特征,如文档中词的有无。
模型:
其中
参数估计:
与多项式 NB 的区别: - 多项式 NB 考虑词频(出现几次) - 伯努利 NB 只考虑词的存在(出现与否)
对于短文本,伯努利 NB 可能更好;对于长文本,多项式 NB 通常更优。
高斯朴素贝叶斯( Gaussian NB)
适用于连续特征,假设类条件概率为高斯分布(见前文)。
应用场景:传感器数据、生物医学特征等。
参数估计:极大似然估计得到均值_{jk}
文本分类实例
垃圾邮件过滤
问题:给定邮件文本,判断是否为垃圾邮件(二分类)。
特征表示:Bag-of-Words(词袋模型)
- 词汇表:
- 文档表示:
, 是词 的出现次数
训练: 1. 计算先验概率:
预测:
示例: - 训练集: 1000 封邮件( 600 垃圾, 400 正常) - 词汇表:{"free", "money", "meeting", "schedule", ...} - 测试邮件:"free money now"
若垃圾邮件中"free"和"money"出现频率远高于正常邮件,则分类为垃圾。
完整实现
1 | import numpy as np |
理论分析与性能
条件独立假设的影响
假设不成立时的表现:尽管现实中特征往往相关,朴素贝叶斯仍可能表现良好。原因: 1. 决策鲁棒性:分类只需后验概率的相对大小,不需要精确值 2. 参数估计稳定:独立假设大幅减少参数量,降低方差 3. 偏差-方差权衡:增加偏差,但显著降低方差
理论分析( Domingos & Pazzani,
1997):即使条件独立假设错误,朴素贝叶斯仍可达到最优分类(零-一损失下),只要:
即后验概率的排序正确,无需绝对值准确。
样本复杂度
优势:参数量为
样本复杂度:在 PAC 学习框架下,朴素贝叶斯只需
属性重要性与特征选择
互信息:特征
特征选择:保留互信息最大的前
Q&A 精选
Q1:为什么称为"朴素"贝叶斯?
A:"朴素"指条件独立假设——假设各特征在给定类别下相互独立。这一假设在现实中往往不成立(如"北京"和"大学"在文档中高度相关),但大幅简化计算,使得模型简单高效。
Q2:朴素贝叶斯与逻辑回归的关系?
A:在二分类、高斯假设下,朴素贝叶斯等价于逻辑回归的特殊情况:
其中权重
Q3:拉普拉斯平滑的本质是什么?
A:从贝叶斯观点,拉普拉斯平滑是引入均匀 Dirichlet 先验(, , )
Q4:如何处理连续特征的非高斯分布?
A: 1. 核密度估计:用非参数方法估计
Q5:朴素贝叶斯能输出概率吗?
A:能,但概率值往往不准确(过于极端)。原因:条件独立假设导致对数概率累加,放大偏差。若需要准确概率,考虑概率校准( Platt Scaling 、 Isotonic Regression)。
Q6:多项式 NB 与伯努利 NB 如何选择?
A: - 文档长度长:多项式 NB(词频信息丰富) - 文档长度短:伯努利 NB(有无比频率更重要) - 稀疏数据:伯努利 NB(避免零概率)
实践中,交叉验证选择。
Q7:朴素贝叶斯能处理缺失值吗?
A:能,且很自然:预测时忽略缺失特征,只计算已观测特征的对数概率:
Q8:朴素贝叶斯的时间复杂度?
A: - 训练:
远快于 SVM 、神经网络,适合大规模文本分类。
Q9:如何可视化朴素贝叶斯的决策边界?
A:对于 2D 连续特征:
1 | def plot_nb_boundary(nb, X, y): |
Q10:朴素贝叶斯的优缺点总结?
A: 优点: - 简单高效,易于实现 - 小样本表现良好 - 自然处理多分类 - 可解释性强 - 支持在线学习
缺点: - 条件独立假设往往不成立 - 对特征相关性敏感 - 概率估计不准确 - 无法学习特征交互
✏️ 练习题与解答
练习 1:后验概率计算
题目:某疾病检测,患病率
解答:
由贝叶斯定理:
计算边缘概率:
因此:
尽管测试准确率很高,但由于患病率很低(先验概率小),阳性预测值仍然较低。这是贝叶斯推理的经典案例。
练习 2:拉普拉斯平滑
题目:文本分类中,正类有100个词,其中"good"出现15次,"bad"出现0次。负类有80个词,"good"出现2次,"bad"出现10次。词汇表大小
解答:
正类中"good"的概率:
正类中"bad"的概率:
没有平滑时,
练习 3:朴素假设的影响
题目:设二维特征
解答:
真实分布中
影响: - 朴素贝叶斯的决策边界会与真实最优边界偏离 - 对于位于协方差椭圆长轴方向的样本,朴素贝叶斯可能低估其概率 - 但在实践中,只要各类的相关性结构相似,朴素贝叶斯仍可能得到正确的相对排序
这解释了为什么朴素贝叶斯在特征相关的情况下仍常表现良好——分类只需正确的排序,不需要精确的概率值。
练习 4:高斯朴素贝叶斯的决策边界
题目:证明高斯朴素贝叶斯的决策边界是线性的。
解答:
对于二分类,决策边界为
取对数:
代入高斯密度:
展开并整理,得到
练习 5:多项式 vs 伯努利朴素贝叶斯
题目:文档"good good
bad",用多项式NB和伯努利NB表示。设正类先验
解答:
多项式NB(考虑词频):
伯努利NB(只考虑有无):
简化(假设其他词概率可忽略):
多项式NB对重复出现的词("good"出现2次)更敏感,适合词频特征。伯努利NB只关心词是否出现,适合二值特征。
参考文献
- Domingos, P., & Pazzani, M. (1997). On the optimality of the simple Bayesian classifier under zero-one loss. Machine Learning, 29(2-3), 103-130.
- McCallum, A., & Nigam, K. (1998). A comparison of event models for naive Bayes text classification. AAAI Workshop on Learning for Text Categorization.
- Rish, I. (2001). An empirical study of the naive Bayes classifier. IJCAI Workshop on Empirical Methods in AI.
- Zhang, H. (2004). The optimality of naive Bayes. FLAIRS Conference.
- Manning, C. D., Raghavan, P., & Sch ü tze, H. (2008). Introduction to Information Retrieval. Cambridge University Press. [Chapter 13: Text Classification]
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer. [Section 8.2: Naive Bayes]
- Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT Press. [Chapter 3: Generative Models for Discrete Data]
朴素贝叶斯以其极简的形式和出人意料的效果,成为机器学习入门的经典算法。从垃圾邮件过滤到情感分析,从医疗诊断到推荐系统,朴素贝叶斯在无数实际应用中证明了"大道至简"的智慧。理解朴素贝叶斯不仅是掌握概率分类的起点,更是通往贝叶斯网络、隐马尔可夫模型等高级概率图模型的基础。
- 本文标题:机器学习数学推导(九)朴素贝叶斯
- 本文作者:Chen Kai
- 创建时间:2021-10-12 09:15:00
- 本文链接:https://www.chenk.top/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%95%B0%E5%AD%A6%E6%8E%A8%E5%AF%BC%EF%BC%88%E4%B9%9D%EF%BC%89%E6%9C%B4%E7%B4%A0%E8%B4%9D%E5%8F%B6%E6%96%AF/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!