1912 年, Fisher 提出了最大似然估计(MLE)的思想,彻底改变了统计学。他的核心洞察是:参数的最佳估计应该使观测数据出现的概率最大。这个看似简单的想法,背后隐藏着深刻的数学结构——从概率空间的公理化定义,到统计推断的渐近性质,再到贝叶斯学派与频率学派的哲学分歧。
机器学习的核心是不确定性建模。线性回归假设误差服从高斯分布;逻辑回归假设标签服从伯努利分布;隐马尔可夫模型假设状态转移服从马尔可夫链。所有这些模型都建立在概率论的坚实基础上。本章从 Kolmogorov 公理出发,严格推导统计推断的数学理论。
概率空间与测度论基础
概率空间的公理化定义
定义 1(概率空间):概率空间是一个三元组
- 样本空间
:所有可能结果的集合 - 事件域
: 的子集族,满足 -代数性质: - 若
,则 (对补集封闭) - 若
,则 (对可数并封闭)
- 概率测度
,满足 Kolmogorov 公理: - 非负性:
, - 规范性:
- 可数可加性:若
互不相交,则
- 非负性:
为什么需要
在无限样本空间中,不是所有子集都可测。例如,实数区间
定理 1(概率的基本性质):
- 若
,则 4. (容斥原理)
证明性质 1:
由可数可加性,令
此式成立当且仅当
条件概率与独立性
定义 2(条件概率):设
定理 2(乘法公式):
定理 3(全概率公式):设
证明:
由于
证毕。
定理 4(Bayes 定理):设
其中第二个等式使用了全概率公式。
Bayes 定理的意义:
-
Bayes 定理是贝叶斯统计的核心,它提供了从数据更新信念的数学框架。
定义 3(独立性):事件
等价地,若
定义 4(条件独立):事件
注意:独立不蕴含条件独立,条件独立也不蕴含独立。
反例:考虑抛两枚硬币:
-
显然
随机变量与分布
定义 5(随机变量):随机变量是从样本空间
可测性要求:对任意 Borel 集
定义 6(累积分布函数,CDF):随机变量
CDF 的性质:
- 单调非降:
- 右连续:
- 极限性质:
,
定义 7(概率密度函数,PDF):若存在非负函数
则称
定义 8(概率质量函数,PMF):对离散型随机变量
定义 9(联合分布):随机变量
联合 PDF(若存在):
定义 10(边缘分布):
定义 11(条件分布):
定义 12(随机变量的独立性):随机变量
期望、方差与特征函数
期望的定义与性质
定义 13(期望):随机变量
- 离散型:
- 连续型:
定理 5(期望的线性性):
对任意常数
证明(连续型):
证毕。
定理 6(全期望公式):
证明:
证毕。
方差与协方差
定义 14(方差):
定理 7(方差的性质):
- 若
和 独立,则
证明性质 2:
若
定义 15(协方差):
性质:
(对称性) (双线性) - 若
和 独立,则 (但逆命题不成立)
定义 16(相关系数):
定理 8(Cauchy-Schwarz 不等式):
即
证明:考虑任意
这是关于
证毕。
特征函数
定义 17(特征函数):随机变量
特征函数的性质:
(共轭) - 若
,则 - 若
和 独立,则
定理
9(特征函数唯一性):分布由特征函数唯一决定。即若
定理 10(矩生成性质):若
证明:
对
令
证毕。
常见概率分布
离散分布
1. 伯努利分布(Bernoulli)
定义:
期望与方差:
应用:二元分类、逻辑回归的输出分布。
2. 二项分布(Binomial)
定义:
期望与方差:
推导期望:
设
推导方差:
由方差的独立可加性:
3. 泊松分布(Poisson)
定义:
期望与方差:
推导期望:
泊松定理:当
证明:
当
故
应用:稀有事件计数(如网站访问次数、放射性衰变)。
连续分布
1. 均匀分布(Uniform)
定义:
期望与方差:
2. 指数分布(Exponential)
定义:
期望与方差:
无记忆性:
证明:
证毕。
应用:等待时间、寿命分布、泊松过程的事件间隔。
3. 高斯分布(Gaussian/Normal)
定义:
期望与方差:
标准正态分布:
标准化变换:若
多元高斯分布:
性质:
- 线性变换的不变性:若
,则 - 边缘分布是高斯:若
联合高斯,则 和 的边缘分布也是高斯 - 条件分布是高斯:若
联合高斯,则 和 也是高斯 - 不相关蕴含独立:对高斯随机变量,
为什么高斯分布如此重要?
- 中心极限定理:独立同分布随机变量之和的分布趋向高斯
- 最大熵原理:在给定均值和方差的所有分布中,高斯分布熵最大
- 解析性好:高斯分布的卷积、线性变换仍是高斯
- 广泛出现:自然界中许多现象近似高斯(如测量误差)
4. Gamma 分布
定义:
其中
期望与方差:
特例:
- = 1
- = n/2, = 1/2
5. Beta 分布
定义:
期望与方差:
应用:贝叶斯推断中的共轭先验(伯努利/二项分布的先验)。
分布之间的关系
定理 11(Gamma 函数与 Beta 函数的关系):
定理 12(卡方分布):若
定理 13(t 分布):若
其中
定理 14(F 分布):若
下图展示了机器学习中最常用的 6 种概率分布族:高斯分布、 Beta 分布、伽马分布、二项分布、泊松分布和卡方分布。这些分布构成了概率建模的基础工具箱:
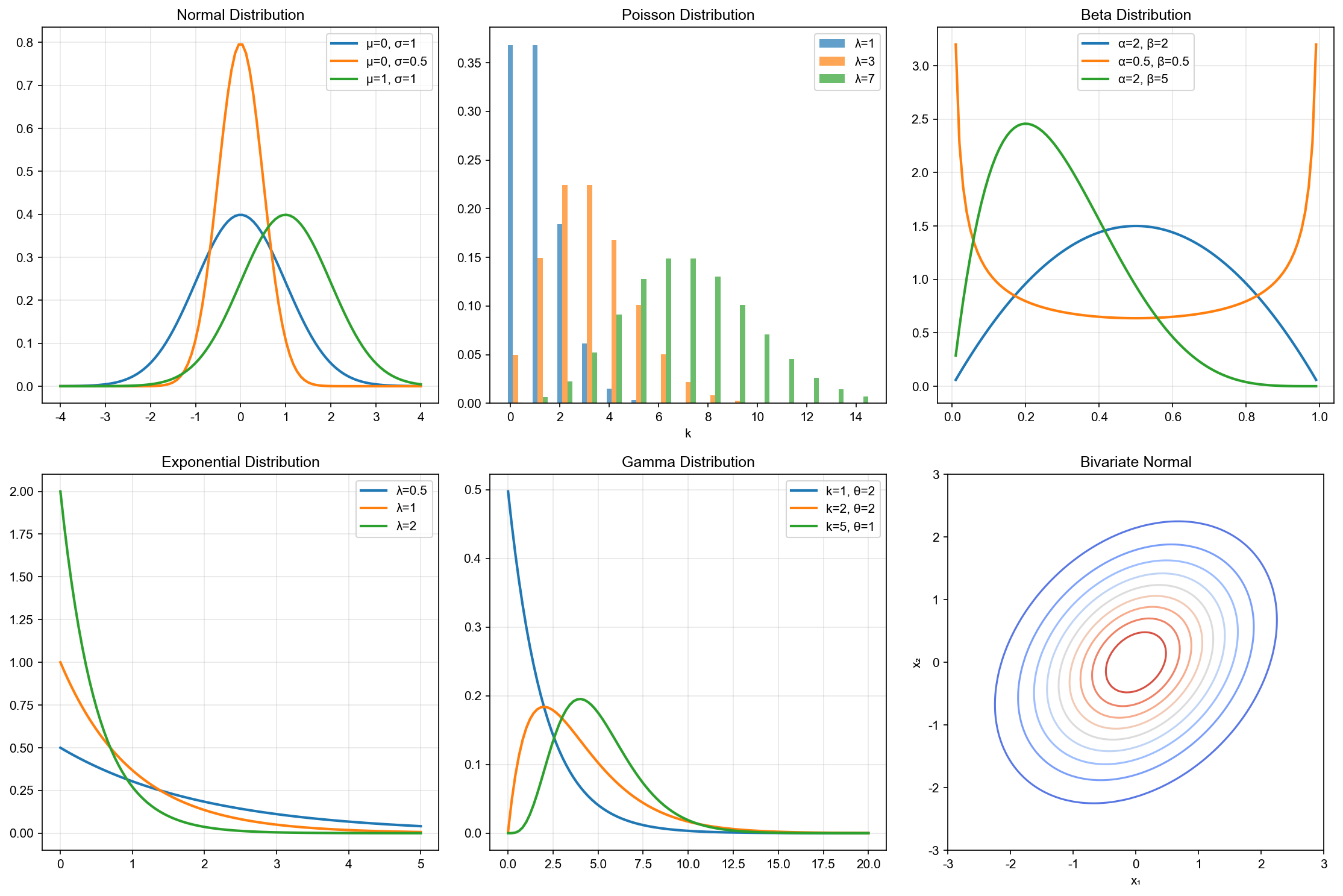
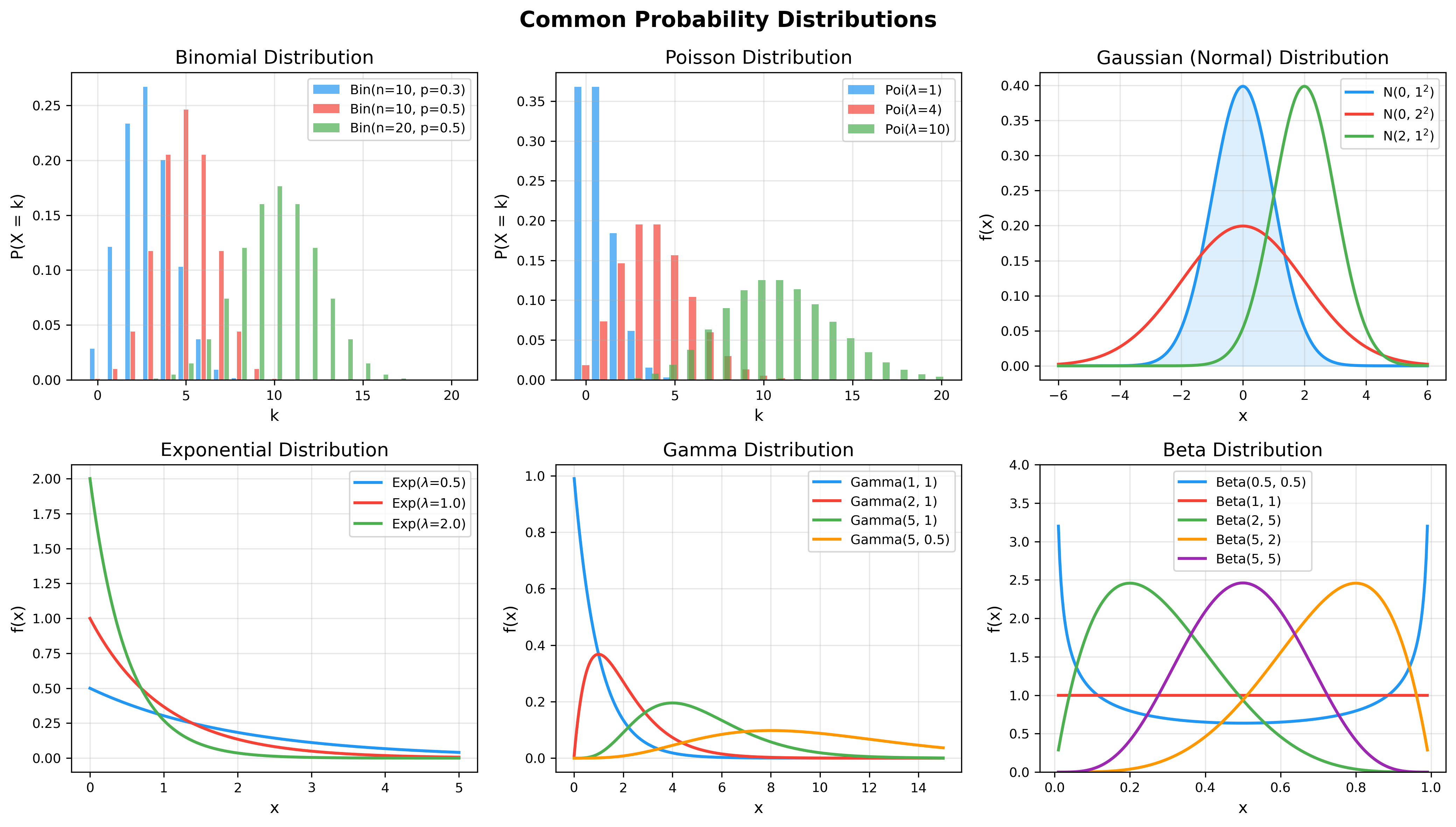
下图更详细地展示了各分布在不同参数下的形状变化——理解参数如何影响分布形态是选择合适模型的关键:
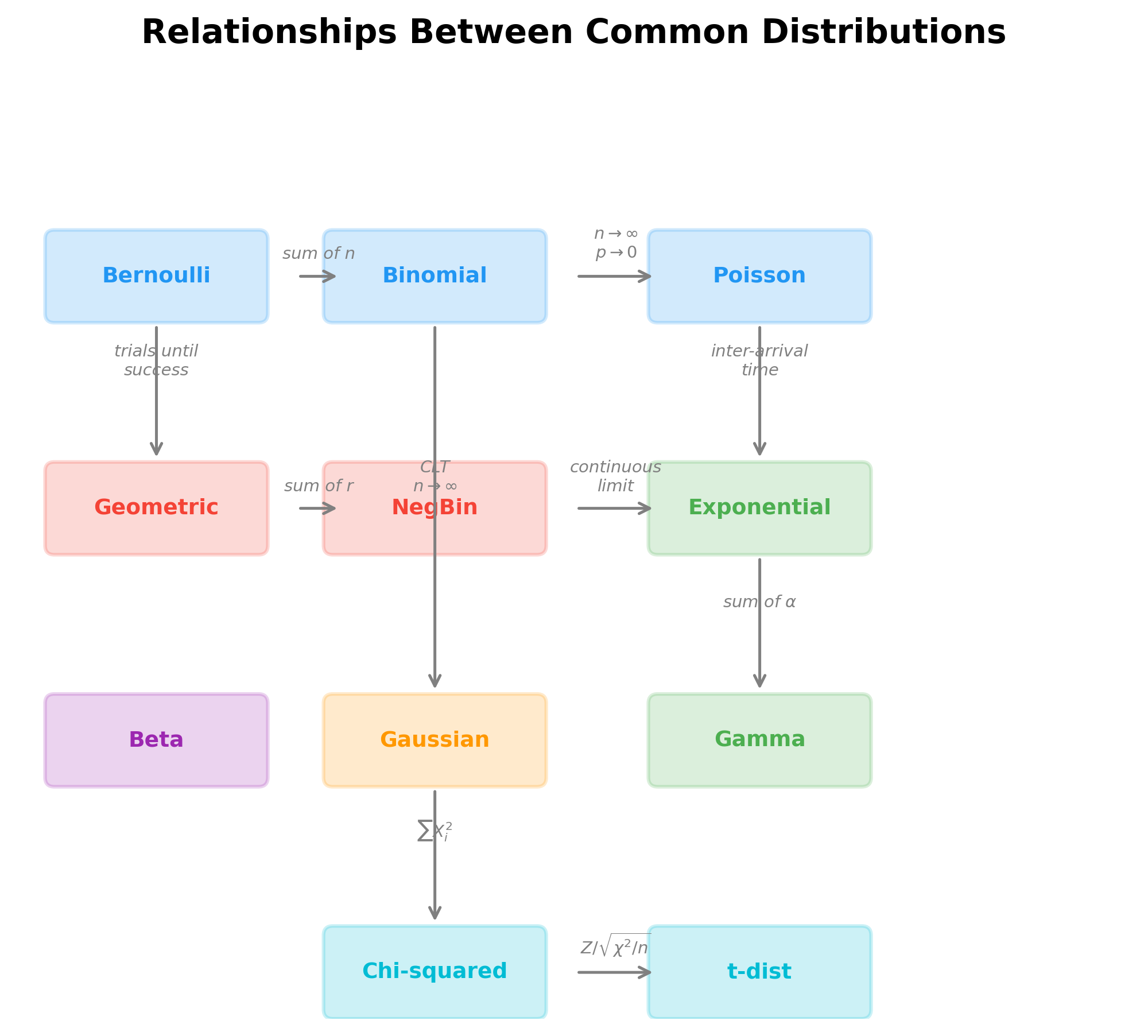
下图展示了概率分布之间的数学关系网络——这些关系揭示了分布论中深层的结构联系:
极限定理
大数定律
定义 18(依概率收敛):随机变量序列 {X_n}
定理 15(Markov 不等式):若
证明:
证毕。
定理 16(Chebyshev 不等式):若
证明:应用 Markov 不等式于
证毕。
定理 17(弱大数定律,WLLN):设
证明:
由 Chebyshev 不等式:
证毕。
定理 18(强大数定律,SLLN):在 WLLN 的条件下:
即
几乎必然收敛 vs 依概率收敛:
- 几乎必然收敛(a.s.):样本轨道收敛
- 依概率收敛(in probability):概率质量集中
几乎必然收敛强于依概率收敛。
中心极限定理
定理 19(中心极限定理,CLT):设
则:
其中
证明思路(利用特征函数):
令
展开
因此:
而
CLT 的意义:
- 解释了为什么正态分布如此普遍:许多现象是大量小随机效应的叠加
- 为统计推断提供理论基础:样本均值的分布近似正态
- 给出近似误差界:
下面的动画直观展示了中心极限定理的魔力——即使原始分布是高度偏斜的指数分布,随着样本量
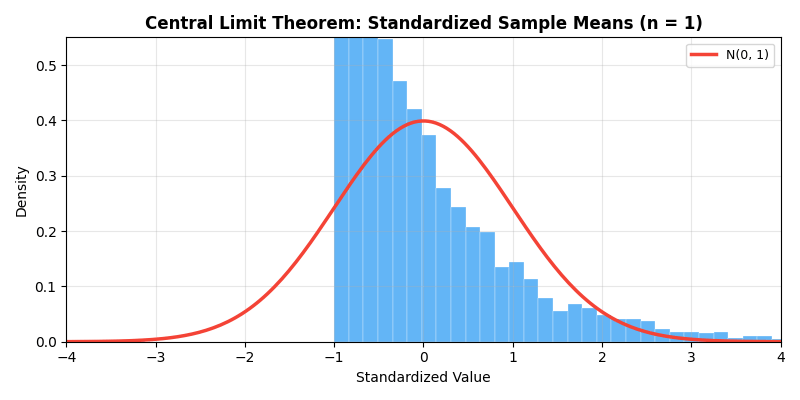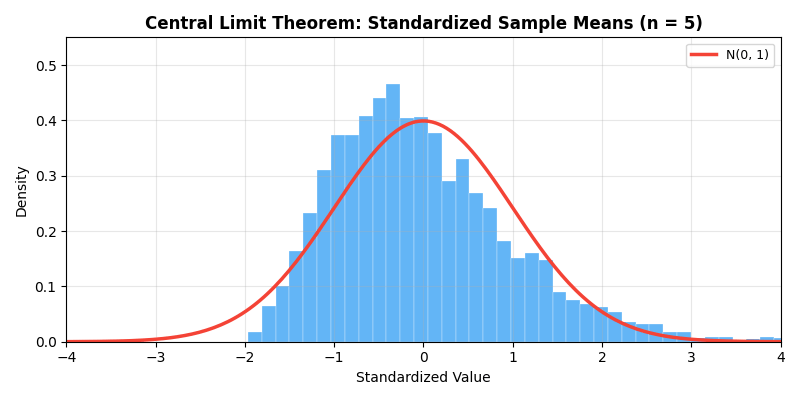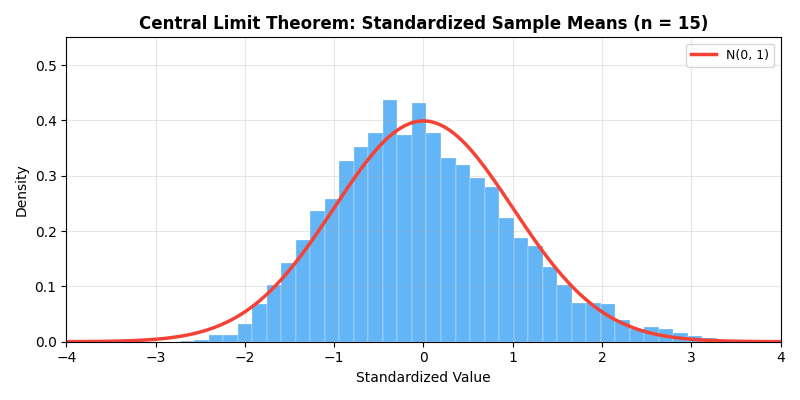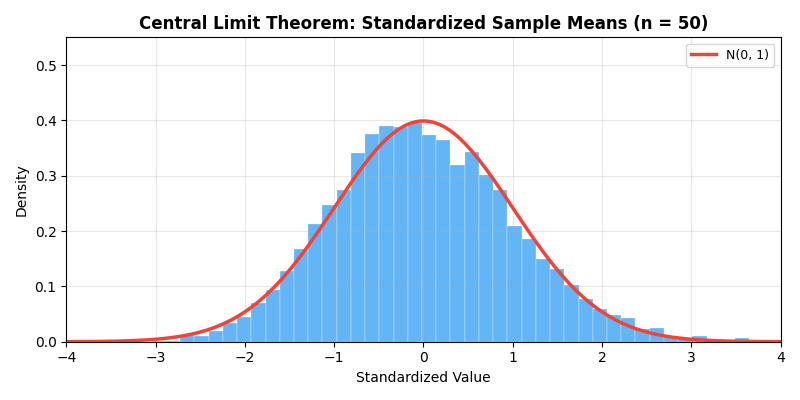
多元中心极限定理:设
参数估计
点估计
定义 19(估计量):设
定义 20(无偏性):若$E [_n] =
例子:
- 样本均值
是总体均值 的无偏估计 - 样本方差
是总体方差 的无偏估计
为什么样本方差除以
证明样本方差的无偏性:
关键步骤:
若除以
定义 21(相合性):若
定义 22(均方误差,MSE):
其中 (_n) = E[_n] -
偏差-方差分解:
- 偏差(bias):估计的系统误差
- 方差(variance):估计的随机性
- 两者的权衡是统计学习的核心
最大似然估计(MLE)
定义 23(似然函数):给定样本
对数似然函数:
定义 24(最大似然估计):MLE 定义为:
例子 1:伯努利分布的 MLE
设
对数似然:
求导:
解得:
例子 2:高斯分布的 MLE
设
对
对
解得:
注意:这是有偏估计!无偏估计应除以
定理 20(MLE 的渐近性质):在正则条件下,MLE 具有以下性质:
- 相合性:
(真实参数) - 渐近正态性:
- 渐近有效性:在所有相合估计中,MLE 的渐近方差达到 Cramér-Rao 下界
其中
贝叶斯估计
贝叶斯范式:将参数
后验分布:由 Bayes 定理:
定义 25(后验均值估计):
定义 26(最大后验估计,MAP):
例子:Beta-Bernoulli 共轭
先验:
似然:
后验:
这是
后验均值:
解释:
- 先验参数
、 可视为"伪观测":先验认为有 个成功, 个失败 - 后验是先验与数据的结合:
个成功, 个失败 - 当
,后验均值 (MLE)
贝叶斯 vs 频率:
| 特性 | 频率学派 | 贝叶斯学派 |
|---|---|---|
| 参数 | 固定但未知 | 随机变量 |
| 推断基础 | 重复抽样 | 条件概率 |
| 先验知识 | 不使用 | 显式建模 |
| 不确定性 | 置信区间 | 可信区间 |
| 计算 | 通常较简单 | 可能需要 MCMC |
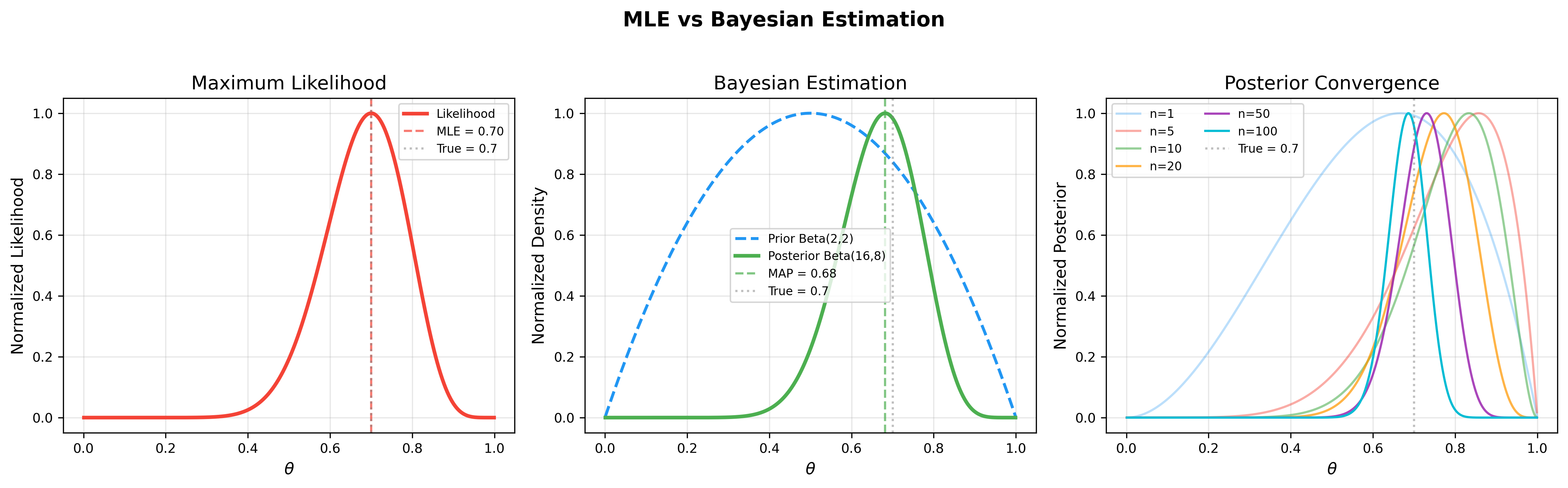
下图对比了最大似然估计( MLE)与最大后验估计( MAP)的差异:左图展示 MLE 仅依赖似然函数寻找使数据概率最大的参数;右图展示 MAP 如何结合先验知识与似然函数得到后验分布,在小样本情况下 MAP 通常更稳定:
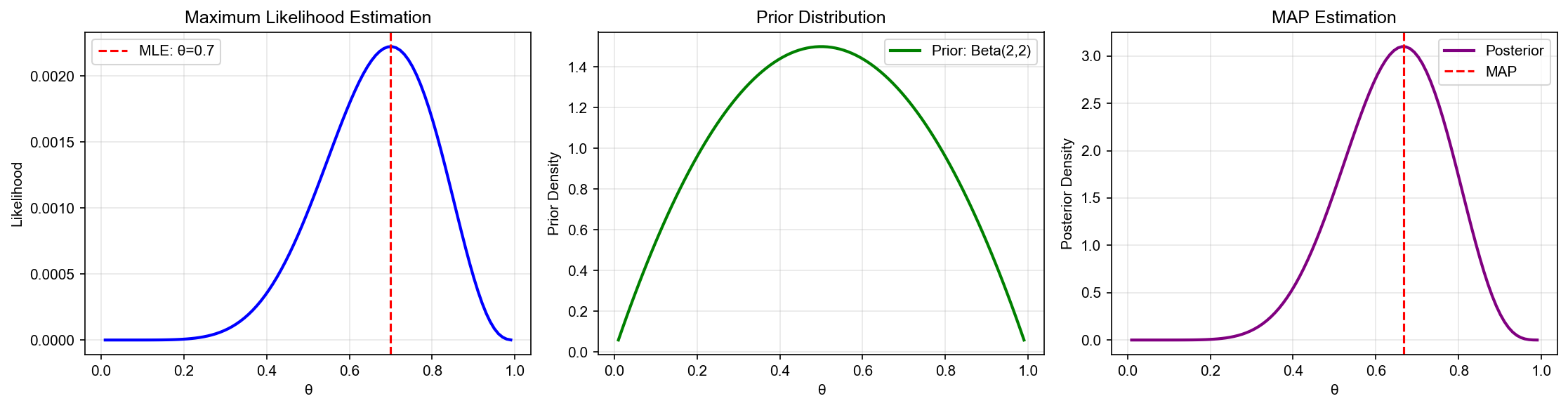
下图进一步展示了贝叶斯估计的核心流程:左图展示似然函数,中图展示先验分布如何与似然函数结合产生后验分布,右图展示随着数据量增大后验分布逐渐集中到真实参数值(后验一致性):
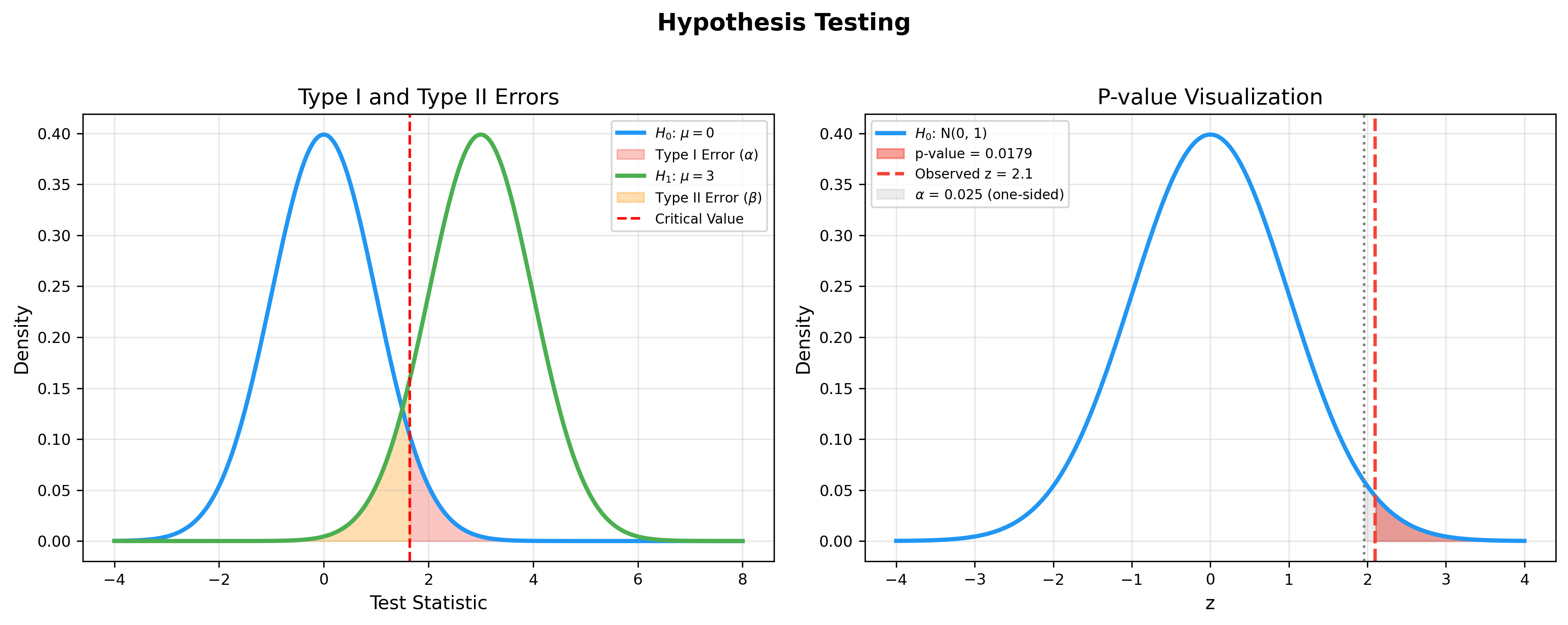
假设检验与置信区间
假设检验
定义 27(统计假设):关于总体分布的陈述。
- 原假设
: 默认假设(通常是"无效应") - 备择假设
: 研究者希望证明的假设
定义 28(检验统计量):基于样本构造的随机变量
定义 29(拒绝域):若
两类错误:
| 真实情况 | 接受 |
拒绝 |
|---|---|---|
| ✓ | 第 I 类错误( |
|
| 第 II 类错误( |
✓(检验力 |
定义 30(显著性水平):
定义 31(p 值):在
决策规则:若 p 值
例子:单样本 t 检验
假设:
在
拒绝域:
下图直观展示了假设检验的核心概念:左图展示了第一类错误(拒绝真实的
置信区间
定义 32(置信区间):随机区间
注意:这是关于随机区间的概率陈述,而非参数的概率陈述(频率观点)。
例子:均值的置信区间
设
因此:
变形得:
是
若
代码实现:分布、估计与检验
1 | import numpy as np |
代码解读:
- 概率分布演示:可视化常见分布的 PDF/PMF,展示其形状特征
- 中心极限定理:从不同分布抽样,展示样本均值的正态化过程
- 最大似然估计:计算高斯分布的 MLE,可视化似然函数,展示估计的收敛性
- 贝叶斯估计:演示 Beta-Bernoulli 共轭,展示先验、数据和后验的关系
- 假设检验:单样本 t 检验,计算 p 值和置信区间,可视化拒绝域
❓ Q&A:概率论常见疑问
Q1:为什么需要
Vitali 集的反例:
在区间
矛盾证明
设
性质:
互不相交(否则存在 使 ,即 ,矛盾于 的构造) 。若 可测,则 可测且 (平移不变性)。由可数可加性:
- 若
, 右边 , 矛盾 - 若
, 右边 , 矛盾
因此
Q2:独立与不相关有什么区别?为什么高斯随机变量中二者等价?
独立 vs 不相关:
| 概念 | 定义 | 蕴含关系 |
|---|---|---|
| 独立 | 独立 |
|
| 不相关 | 不相关 |
反例(不相关但不独立):
设
(奇函数积分) - 因此
,但 完全由 决定,显然不独立!
为什么高斯随机变量中二者等价?
定理:若
证明思路:
联合高斯的 PDF:
其中
当
即
关键:高斯分布的特殊性在于,其 PDF 可以完全因式分解为边缘 PDF 的乘积,当且仅当协方差为 0 。
Q3:为什么样本方差要除以
自由度的直观解释:
样本方差
这意味着给定
数学证明:
展开:
取期望:
因此:
Q4:最大似然估计(MLE)为什么是"好"的估计?
MLE 的三大渐近性质:
相合性:
渐近正态性:
渐近有效性:MLE 达到 Cram é r-Rao 下界(在所有无偏估计中方差最小)
Cramér-Rao 下界:
定理:设
其中
证明思路:
由无偏性:
定义
由 Cauchy-Schwarz 不等式:
整理得:
MLE 达到下界:
在正则条件下,MLE 的渐近方差
Q5:贝叶斯估计与 MLE 有什么区别?何时更优?
哲学差异:
| 特性 | 频率派(MLE) | 贝叶斯派 |
|---|---|---|
| 参数 |
固定但未知 | 随机变量 |
| 数据 |
随机 | 观测到后为固定值 |
| 推断 | ||
| 不确定性 | 估计的抽样分布 | 参数的后验分布 |
MAP vs MLE:
MAP = MLE + 先验正则化。
例子:Ridge 回归 vs MLE
线性回归
MLE:
贝叶斯(高斯先验
这正是 Ridge 回归!正则化参数
何时贝叶斯更优?
- 小样本:先验提供额外信息,减少过拟合
- 高维问题:正则化防止奇异性
- 不确定性量化:后验分布提供完整不确定性描述,而非点估计
- 序贯更新:易于增量学习(后验→下次先验)
何时 MLE 更优?
- 大样本:数据主导,先验影响消失
- 计算简单:无需积分后验
- 客观性:无先验主观性争议
Q6:p 值到底是什么?为什么不能说"参数有 95%概率落在置信区间"?
p 值的正确解释:
p 值 = 在原假设
常见误解:
❌ "p 值是
✅ 正确:p 值是
这两者根本不同!由 Bayes 定理:
p 值只是分子的一部分,不涉及
置信区间的正确解释:
95%置信区间
✅ 如果我们重复实验无数次,95%的区间会包含真实参数。
❌ 参数有 95%概率落在此区间。
为什么第二种说法错误?
频率观点下,参数
图示:
1 | 重复实验 100 次,构造 100 个 95%置信区间: |
每个区间要么包含
贝叶斯可信区间:
贝叶斯派可以说"参数有 95%概率落在可信区间",因为他们将
Q7:中心极限定理为什么如此重要?有什么局限性?
CLT 的重要性:
- 普适性:适用于几乎任何分布(只需有限方差)
- 解释正态分布无处不在:许多现象是大量小随机效应的叠加
- 统计推断的基础:
- 样本均值的置信区间
- t 检验、 ANOVA 等依赖正态近似
- 回归系数的渐近分布
应用例子:
- 测量误差:多个独立误差源的叠加
- 生物特征:身高、智商等受多基因影响
- 金融:资产收益是多因素综合作用
CLT 的局限性:
- 收敛速度:
- 对高度偏斜分布,需要很大的
才能近似正态 - Berry-Esseen 定理给出误差界:
,其中
- 对高度偏斜分布,需要很大的
- 厚尾分布:
- 若
(如 Cauchy 分布),CLT 不适用 - 此时样本均值甚至不收敛到任何分布!
- 若
- 相依性:
- CLT 假设独立同分布
- 对时间序列等相依数据,需要修改版本(如 Lyapunov CLT)
- 多峰分布:
- 若混合多个相距很远的分布,样本均值可能呈现多峰,而非正态
替代方案:
- Bootstrap:无需正态假设,用重抽样估计抽样分布
- Permutation test:精确检验,无需渐近近似
- Robust statistics:对异常值不敏感的估计(如中位数)
Q8:为什么高斯分布如此特殊?
高斯分布的独特性质:
- 再生性:
, 独立,则 - 线性变换不变性:
,则 - 边缘与条件分布均为高斯:
则: -
不相关蕴含独立:仅对高斯成立
最大熵原理:给定均值和方差,高斯分布熵最大
最大熵推导:
目标:在约束
Lagrange 函数:
变分法,对
解得:
确定常数后,得:
这正是高斯分布!
意义:在只知道均值和方差的情况下,高斯分布是最"无偏"的选择(信息熵最大,假设最少)。
Q9:什么是共轭先验?为什么要使用它?
定义:若先验分布 ()
常见共轭对:
| 似然 | 共轭先验 | 后验 |
|---|---|---|
| Bernoulli/Binomial | Beta | Beta |
| Poisson | Gamma | Gamma |
| Gaussian(均值) | Gaussian | Gaussian |
| Gaussian(方差) | Inverse-Gamma | Inverse-Gamma |
| Multinomial | Dirichlet | Dirichlet |
例子:Gaussian-Gaussian 共轭
似然:
先验:
后验:
后验均值是加权平均:
权重 = 精度(方差的倒数)。
为什么使用共轭先验?
- 解析解:后验有闭式形式,无需数值积分
- 可解释性:先验参数有直观含义(如"伪观测")
- 序贯更新:后验作为新的先验,易于增量学习
- 计算效率:对大规模数据尤其重要
局限性:
- 可能不反映真实先验信念
- 分布族选择受限
非共轭先验:使用 MCMC(如 Gibbs 采样、 Metropolis-Hastings)或变分推断。
Q10:偏差-方差分解在统计推断中有何意义?
偏差-方差分解:
几何解释:
1 | θ (真实参数) |
权衡:
- 低偏差,高方差:过拟合(如高次多项式拟合)
- 高偏差,低方差:欠拟合(如线性模型拟合复杂数据)
- 最优:平衡两者
例子:Ridge vs OLS
OLS(普通最小二乘):
- 无偏:
- 方差:
- 当
接近奇异时,方差爆炸!
Ridge:
- 有偏:
- 方差更小:正则化稳定估计
定理(Ridge 的 MSE 优势):存在
特别是当
实践启示:
- 无偏估计不一定最优(可能方差巨大)
- 适度偏差换取方差大幅下降,常能降低 MSE
- 正则化、收缩估计(如 Lasso 、 Ridge)正是基于此思想
🎓 总结:概率论核心要点
记忆公式:
- Bayes 定理:
- 期望的线性性:
- 中心极限定理:
- MLE 的渐近分布:
记忆口诀:
Bayes 更新先验信念(后验∝似然×先验)
大数定律保证收敛(样本均值→总体均值)
中心极限给出正态(和的分布近似正态)
MLE 达到效率下界(Cram é r-Rao 界)
实战 Checklist:
✏️ 练习题与解答
练习 1:条件概率与贝叶斯公式
题目:某疾病的患病率为 0.1%。一种检测方法的灵敏度(真阳性率)为 99%,特异度(真阴性率)为 95%。一个人检测阳性,他实际患病的概率是多少?
解答:
设
由贝叶斯公式:
即使检测阳性,实际患病概率只有约 1.94%。这是"基率谬误"的经典案例——当患病率很低时,即使检测很准确,阳性预测值也可能很低。
练习 2:最大似然估计
题目:设
解答:
似然函数:
其中
要最大化
检查无偏性:
因此
无偏修正:
练习 3:中心极限定理的应用
题目:一台机器生产的螺丝长度服从均值 10mm、标准差
0.2mm 的分布。随机抽取 100 根螺丝,求样本均值在
解答:
设
由中心极限定理,
即样本均值落在
练习 4:贝叶斯估计与共轭先验
题目:投掷一枚可能不均匀的硬币,假设正面概率
解答:
先验:
似然:
由 Beta-Binomial 共轭性,后验为:
后验均值:
对比 MLE:
后验均值(0.643)比 MLE(0.7)更接近 0.5,这是先验
练习 5:假设检验
题目:某工厂声称其产品的平均重量为 500g。随机抽取 25
件产品,测得
解答:
设
检验统计量:
在
临界值:
由于
p 值:
结论:没有足够的统计证据表明产品的平均重量与 500g
有显著差异。但注意:不能拒绝
📚 参考文献
Casella, G., & Berger, R. L. (2002). Statistical Inference (2nd ed.). Duxbury Press.
Wasserman, L. (2004). All of Statistics: A Concise Course in Statistical Inference. Springer.
Murphy, K. P. (2022). Probabilistic Machine Learning: An Introduction. MIT Press.
Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., & Rubin, D. B. (2013). Bayesian Data Analysis (3rd ed.). Chapman and Hall/CRC.
Lehmann, E. L., & Casella, G. (1998). Theory of Point Estimation (2nd ed.). Springer.
van der Vaart, A. W. (1998). Asymptotic Statistics. Cambridge University Press.
Billingsley, P. (2008). Probability and Measure (Anniversary ed.). Wiley.
Durrett, R. (2019). Probability: Theory and Examples (5th ed.). Cambridge University Press.
Ferguson, T. S. (1996). A Course in Large Sample Theory. Chapman and Hall/CRC.
Robert, C. P., & Casella, G. (2004). Monte Carlo Statistical Methods (2nd ed.). Springer.
下一章预告:第 4 章将深入探讨优化理论基础,包括凸优化、梯度下降、牛顿法、拟牛顿法、约束优化等,为机器学习算法的训练提供数学工具。
- 本文标题:机器学习数学推导(三)概率论与统计推断
- 本文作者:Chen Kai
- 创建时间:2021-09-06 10:45:00
- 本文链接:https://www.chenk.top/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%95%B0%E5%AD%A6%E6%8E%A8%E5%AF%BC%EF%BC%88%E4%B8%89%EF%BC%89%E6%A6%82%E7%8E%87%E8%AE%BA%E4%B8%8E%E7%BB%9F%E8%AE%A1%E6%8E%A8%E6%96%AD/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!