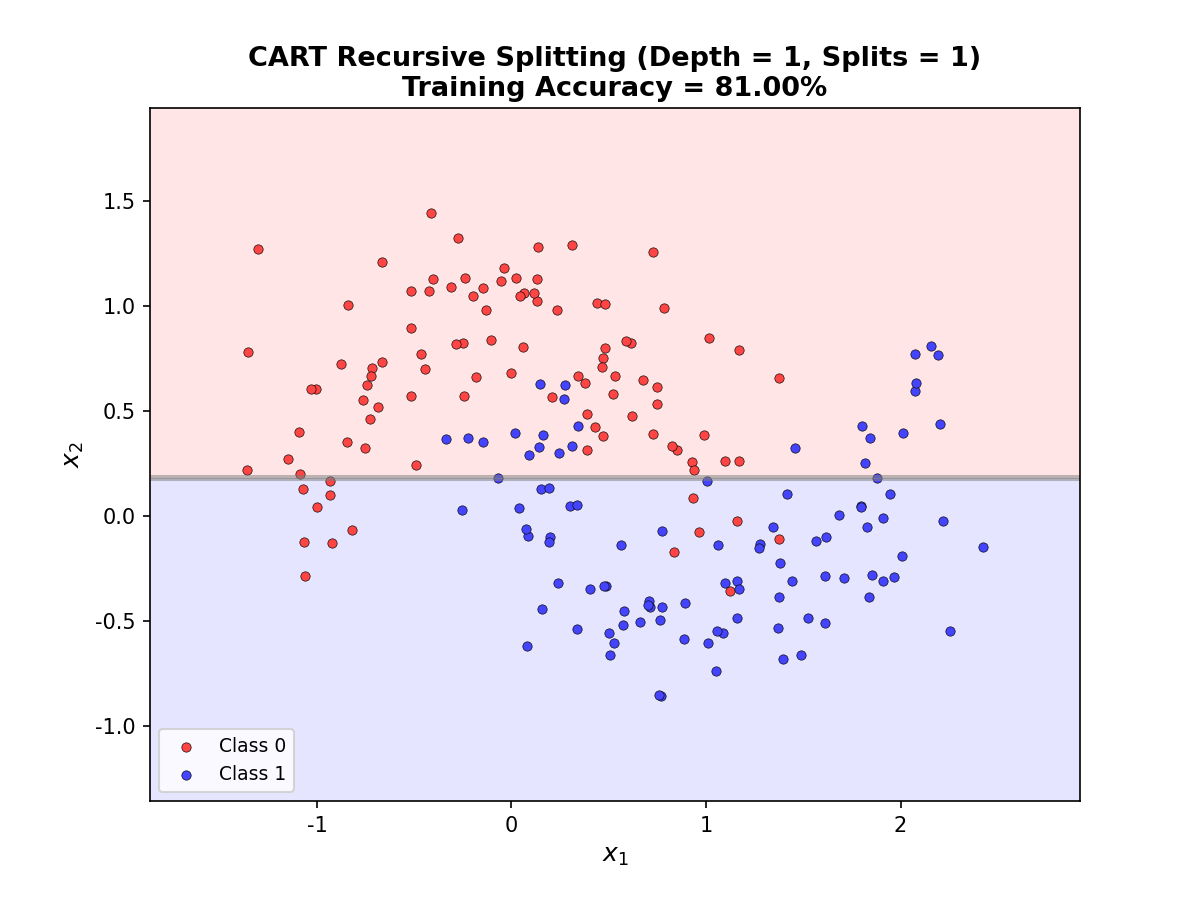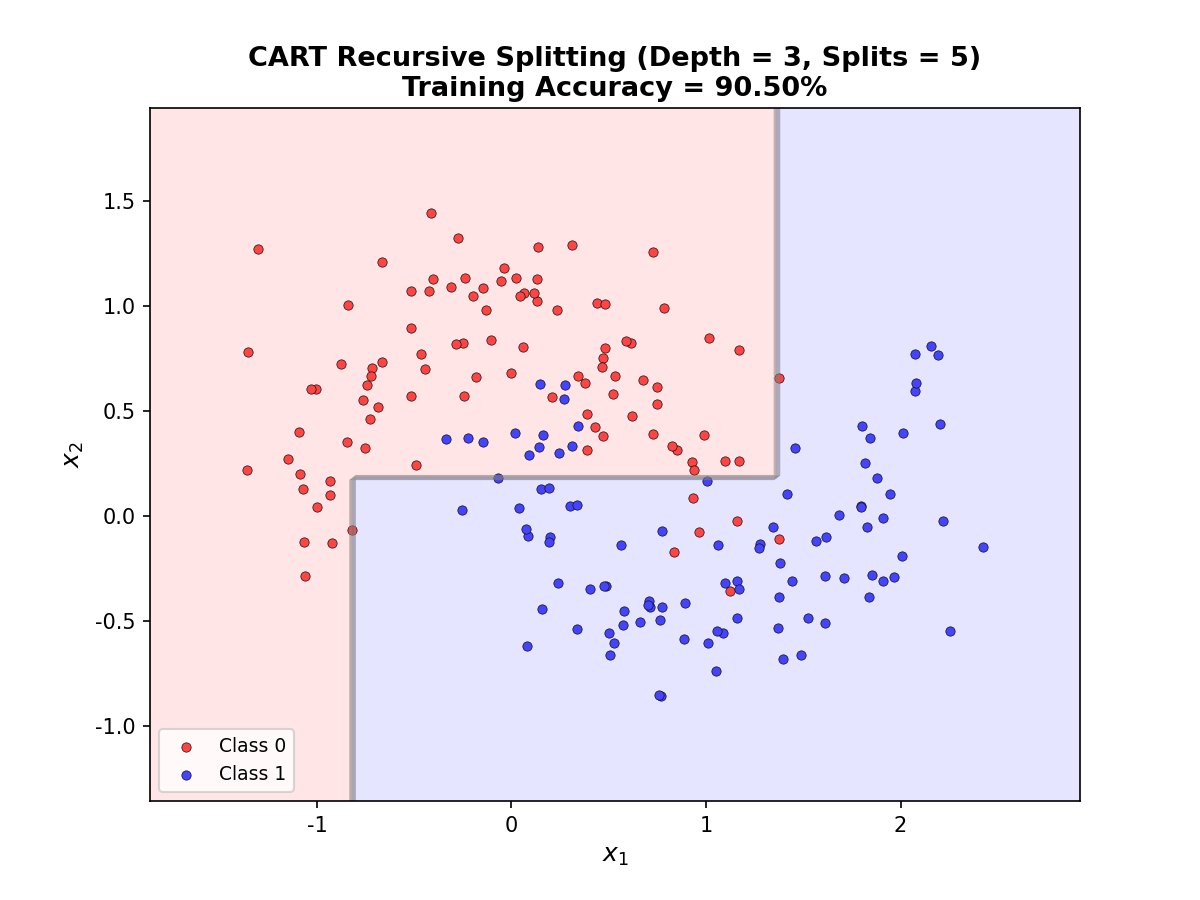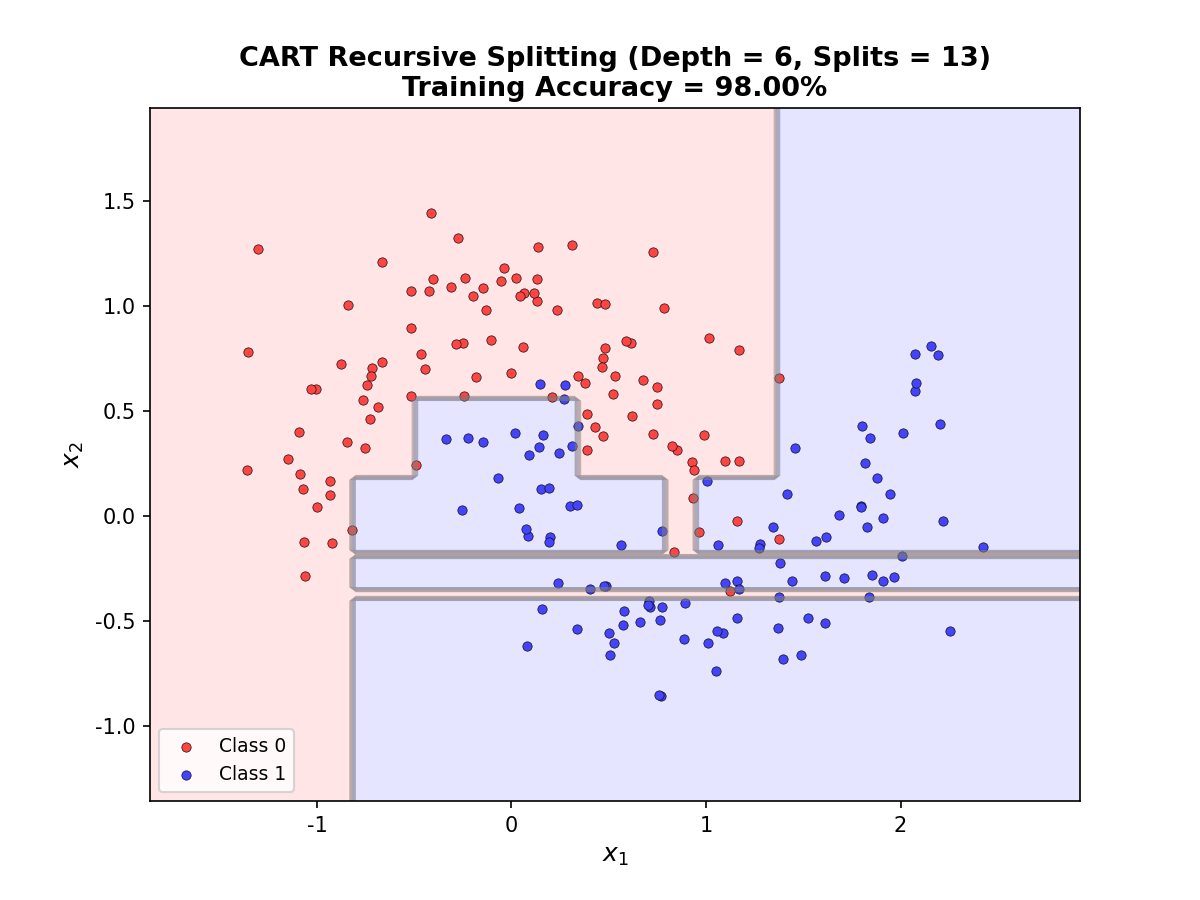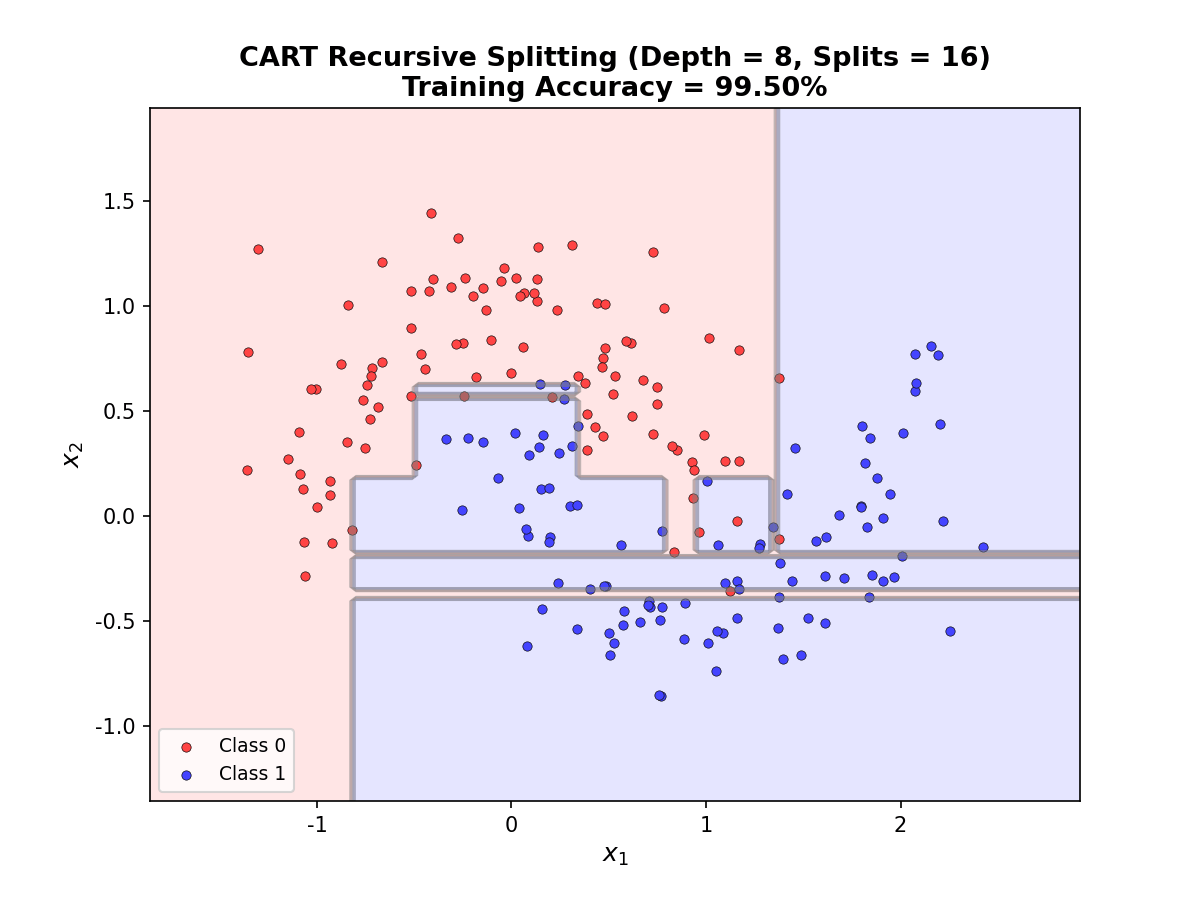
决策树是最直观的机器学习模型之一——像人类决策过程一样,通过一系列"是否"问题逐步缩小答案范围。但其背后隐藏着深刻的信息论与概率论基础:如何选择最优分裂点?如何避免过拟合?如何处理连续特征与缺失值?本章将系统推导决策树的数学原理,从熵的定义到
ID3 、 C4.5 、 CART
算法的细节,从剪枝理论到随机森林的集成思想,全面揭示树模型的内在逻辑。
决策树基础
模型表示与决策过程
决策树是一种层次化分类/回归模型 ,由节点和边构成:
根节点 :包含所有样本内部节点 :表示特征测试(如分支 :表示测试结果叶节点 :表示预测结果(类别或数值)
预测过程 :对于样本
数学表示 :决策树可视为特征空间的递归划分 :
𝟙
其中
决策树的优势与局限
优势 : 1.
可解释性强 :决策路径清晰,类似人类思维 2.
无需归一化 :对特征尺度不敏感 3.
处理非线性 :能捕获复杂交互关系 4.
混合数据 :同时处理数值型和类别型特征
局限 : 1.
过拟合倾向 :深树可完美拟合训练集 2.
不稳定 :数据微小变化可能导致树结构大变 3.
贪心策略 :局部最优不保证全局最优 4.
难以捕获线性关系 :对线性可分问题可能表现不佳
信息论基础
信息熵:不确定性的度量
对于离散随机变量熵 (Entropy)定义为:
其中
物理意义 :熵衡量随机变量的不确定性 或混乱程度 。熵越大,不确定性越高。
性质 1:非负性
当且仅当
性质 2:最大值
对于
证明 :拉格朗日乘数法最大化
性质 3:凹性
条件熵与信息增益
条件熵
信息增益 (Information Gain)定义为知道
性质 : -
数据挖掘解释 :选择特征
信息增益率
问题 :信息增益倾向于选择取值多的特征(极端情况:样本
ID 作为特征,信息增益最大但无泛化能力)。
解决方案 :引入信息增益率 (Gain
Ratio):
其中
作用 :惩罚取值过多的特征。若
分裂准则
基尼系数
基尼系数 (Gini
Index)是另一种衡量数据纯度的指标:
其中
物理意义 :从数据集中随机抽取两个样本,类别不一致的概率。
性质 : -
基尼增益 :特征
选择使
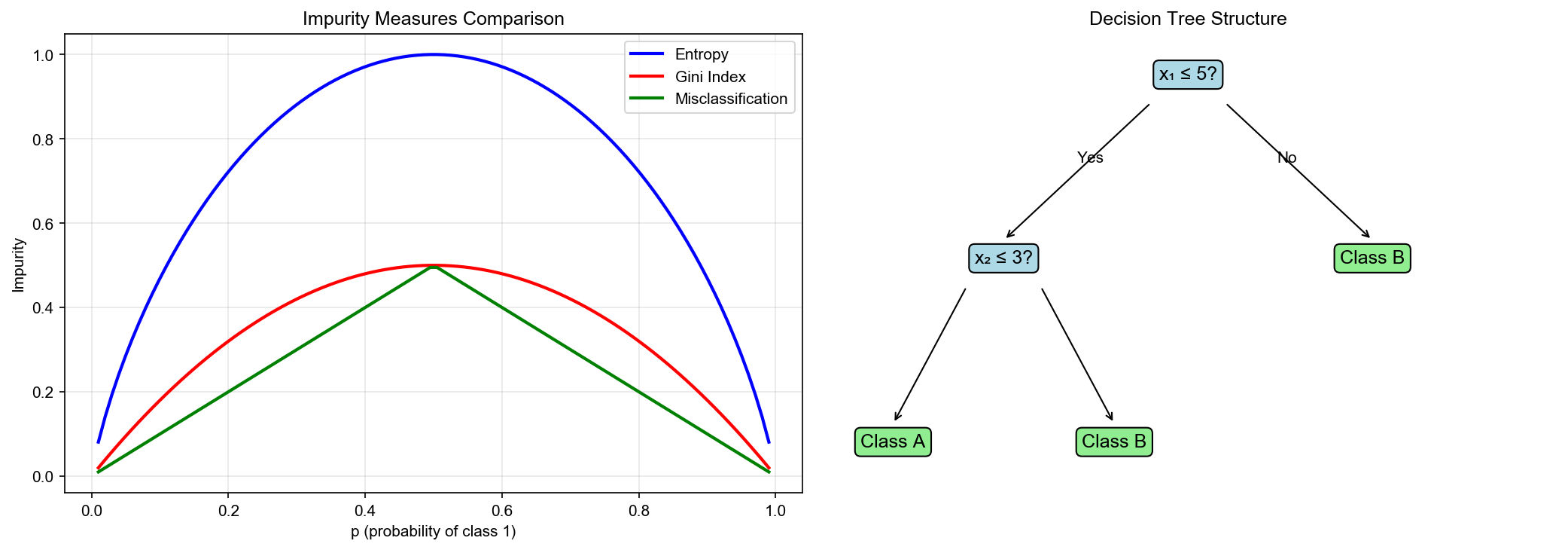
下图对比了不同分裂准则(熵、基尼指数、分类误差)的曲线形态,以及决策树的典型结构示意:
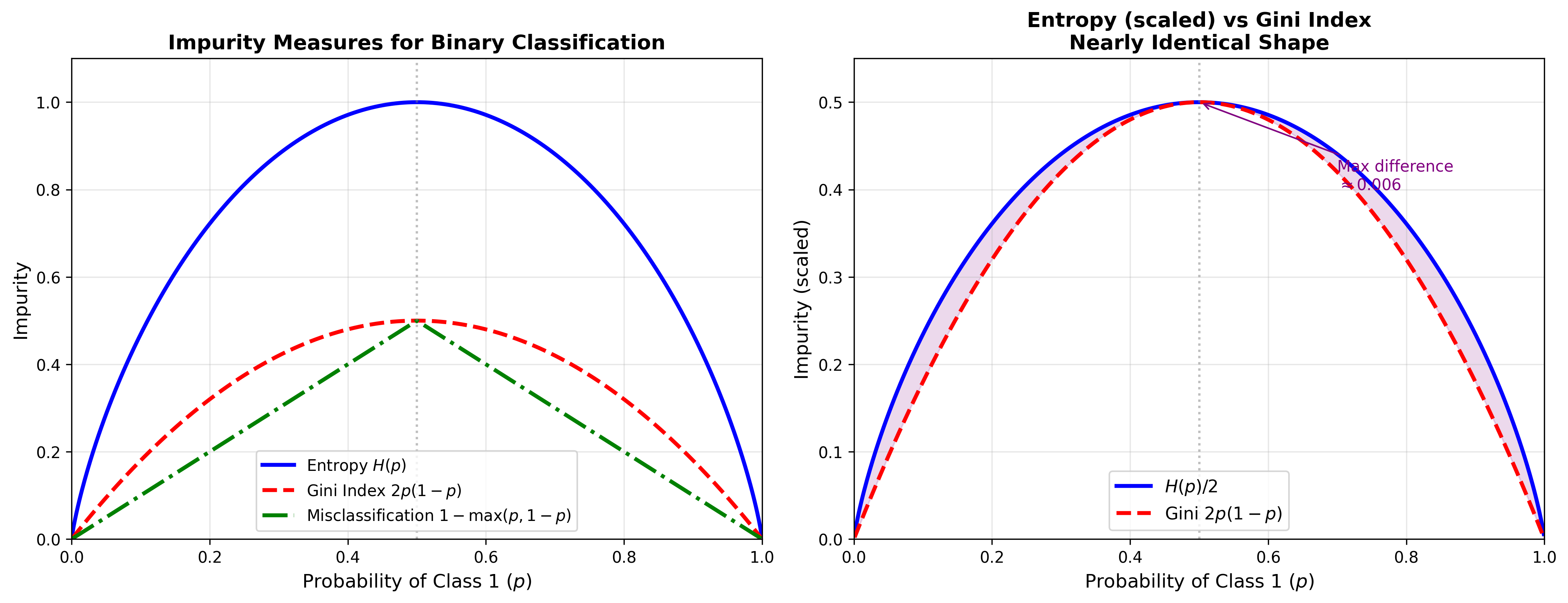
熵与基尼系数的关系
对于二分类(
泰勒展开 :在
两者形状类似,但基尼系数计算更简单(无对数运算),CART
算法采用基尼系数。
下图直观展示了熵和基尼系数随正类概率变化的曲线对比,二者在
Entropy vs Gini Index
均方误差准则(回归树)
对于回归任务,目标是最小化叶节点的预测误差。若叶节点
(即区域内目标值的平均)
分裂准则 :选择特征
其中
最优预测值 :给定分裂,最优
决策树算法
ID3 算法
ID3 ( Iterative Dichotomiser 3)由 Quinlan 于 1986
年提出,使用信息增益作为分裂准则。
算法流程 :
终止条件 :若当前节点
所有样本属于同一类别
特征集为空,或所有样本在所有特征上取值相同(多数表决)
节点样本数小于阈值
特征选择 :计算每个特征
分裂 :按特征
递归 :对每个子集
示例 :
假设数据集
计算 :
C4.5 算法
C4.5 是 ID3 的改进版,主要改进:
信息增益率 :用连续特征处理 :将连续特征离散化(见下节)缺失值处理 :允许特征值缺失(见下节)剪枝 :引入后剪枝策略
信息增益率的使用细节 :
直接用
CART 算法
CART ( Classification and Regression
Tree)是最广泛使用的决策树算法,由 Breiman 等人于 1984 年提出。
特点 : -
二叉树 :每次分裂产生两个子节点( ID3/C4.5
可产生多个子节点) -
基尼系数 (分类)或均方误差(回归)作为分裂准则 -
代价复杂度剪枝 ( Cost-Complexity Pruning)
分类树的分裂 :
对于特征
选择
回归树的分裂 :
其中
连续特征与缺失值处理
连续特征的离散化
对于连续特征二分法 :
将特征值排序:
考虑所有可能的切分点:
对每个切分点
选择最优的
复杂度 :对于
优化 :预排序特征值,避免重复排序,降至
缺失值处理
面对缺失值, C4.5 采用以下策略:
策略 1:分裂时的处理
计算信息增益时,只使用非缺失样本 :
其中
策略 2:样本划分时的处理
对于特征按比例分配 到各个子节点:
其中
策略 3:预测时的处理
若测试样本在特征方法 1 :沿所有分支,以权重方法 2 :选择样本数最多的分支
剪枝策略
为什么需要剪枝
完全生长的决策树(直到叶节点只有一个样本或同类样本)会严重过拟合 :训练误差为
0,但测试误差高。
过拟合的原因 : - 树过深,捕获训练数据的噪声 -
叶节点样本数过少,统计不可靠
解决方案 :剪枝(
Pruning),通过简化树结构提高泛化能力。
预剪枝( Pre-Pruning)
在构建过程中,提前停止分裂。常见停止条件:
节点样本数阈值 :深度限制 :深度达到信息增益阈值 :叶节点样本数阈值 :分裂后子节点样本数
优点 :计算高效,避免构建过深的树
缺点 :可能过早停止,导致欠拟合(某些看似无效的分裂后续可能有用)
后剪枝( Post-Pruning)
先构建完整的树,再自底向上剪枝。
基本思想 :对于内部节点剪枝前 :剪枝后 :
若剪枝后性能不降低(或提升),则剪枝。
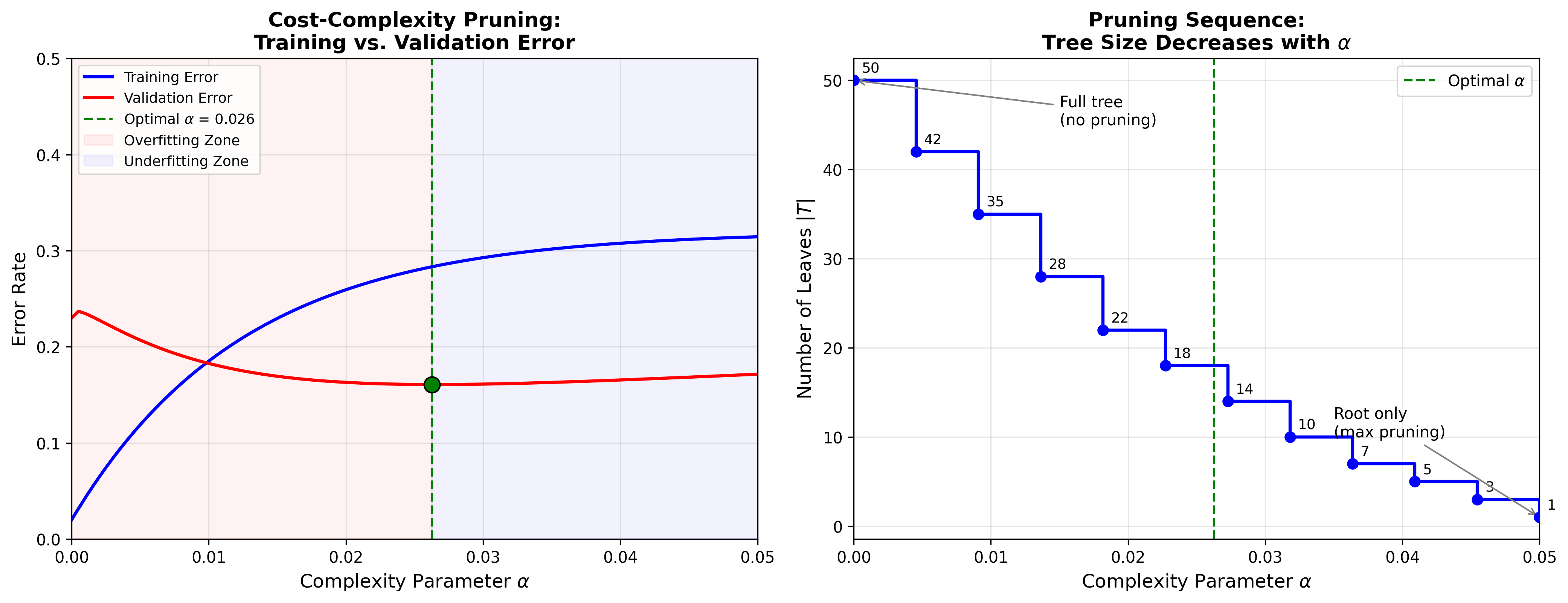
代价复杂度剪枝( CART 剪枝) :
引入树的复杂度惩罚。定义树代价复杂度 :
其中: -
物理意义 :
剪枝过程 :
生成剪枝序列 :从完整树
对于每个内部节点
其中
交叉验证选择最优 :在验证集上评估序列中每棵树,选择验证误差最小的
下图展示了不同复杂度参数
Cost-Complexity Pruning
数学推导 :
剪枝后,节点
剪枝前(保留子树
当
解得:
这是使剪枝与不剪枝等价的临界
决策树的数学性质
VC 维与泛化误差
决策树的VC 维 (Vapnik-Chervonenkis
Dimension)取决于树的复杂度。对于深度为
其中
泛化误差界 :根据统计学习理论,以高概率:
其中
决策树的不稳定性
决策树对训练数据高度敏感。定量分析:
定理 :若特征
示例 :假设
缓解方法 :集成学习(如随机森林)通过平均多棵树的预测降低方差。
下图通过动画展示了 CART
算法逐步分裂特征空间的过程,每一步选择最优分裂点将区域一分为二:
CART Splitting Animation
特征交互的表示
决策树天然捕获特征交互 。若某个分支路径为:
这表示
表达能力 :深度为
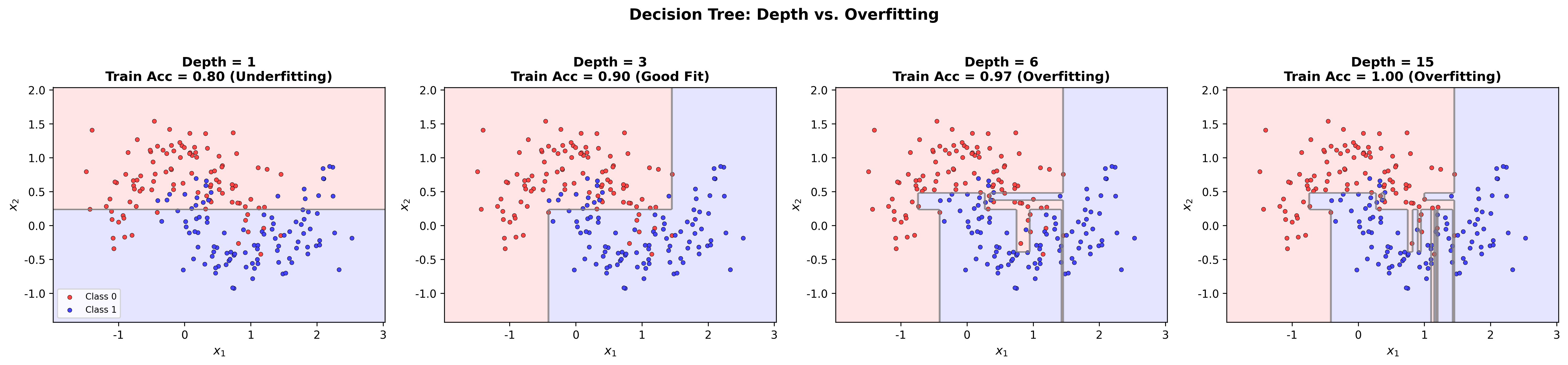
下图展示了决策树从浅到深的拟合过程——随着深度增加,决策边界越来越复杂,从欠拟合逐步过渡到过拟合:
Decision Tree Depth vs
Overfitting
实现与优化
完整的 CART 实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 import numpy as npclass Node : def __init__ (self, feature=None , threshold=None , left=None , right=None , value=None ): self.feature = feature self.threshold = threshold self.left = left self.right = right self.value = value class DecisionTreeClassifier : def __init__ (self, max_depth=None , min_samples_split=2 , min_samples_leaf=1 , criterion='gini' ): self.max_depth = max_depth self.min_samples_split = min_samples_split self.min_samples_leaf = min_samples_leaf self.criterion = criterion self.root = None def gini (self, y ): """计算基尼系数""" _, counts = np.unique(y, return_counts=True ) probs = counts / len (y) return 1 - np.sum (probs ** 2 ) def entropy (self, y ): """计算熵""" _, counts = np.unique(y, return_counts=True ) probs = counts / len (y) return -np.sum (probs * np.log2(probs + 1e-10 )) def split_criterion (self, y ): """根据准则选择评估函数""" if self.criterion == 'gini' : return self.gini(y) elif self.criterion == 'entropy' : return self.entropy(y) def best_split (self, X, y ): """寻找最优分裂""" n_samples, n_features = X.shape if n_samples < self.min_samples_split: return None , None parent_impurity = self.split_criterion(y) best_gain = 0 best_feature = None best_threshold = None for feature in range (n_features): thresholds = np.unique(X[:, feature]) for threshold in thresholds: left_mask = X[:, feature] <= threshold right_mask = ~left_mask if np.sum (left_mask) < self.min_samples_leaf or \ np.sum (right_mask) < self.min_samples_leaf: continue n_left, n_right = np.sum (left_mask), np.sum (right_mask) left_impurity = self.split_criterion(y[left_mask]) right_impurity = self.split_criterion(y[right_mask]) weighted_impurity = (n_left * left_impurity + n_right * right_impurity) / n_samples gain = parent_impurity - weighted_impurity if gain > best_gain: best_gain = gain best_feature = feature best_threshold = threshold return best_feature, best_threshold def build_tree (self, X, y, depth=0 ): """递归构建决策树""" n_samples, n_features = X.shape n_classes = len (np.unique(y)) if n_classes == 1 or \ (self.max_depth is not None and depth >= self.max_depth): leaf_value = np.argmax(np.bincount(y)) return Node(value=leaf_value) feature, threshold = self.best_split(X, y) if feature is None : leaf_value = np.argmax(np.bincount(y)) return Node(value=leaf_value) left_mask = X[:, feature] <= threshold right_mask = ~left_mask left_subtree = self.build_tree(X[left_mask], y[left_mask], depth + 1 ) right_subtree = self.build_tree(X[right_mask], y[right_mask], depth + 1 ) return Node(feature=feature, threshold=threshold, left=left_subtree, right=right_subtree) def fit (self, X, y ): """训练模型""" self.root = self.build_tree(X, y) return self def predict_sample (self, x, node ): """预测单个样本""" if node.value is not None : return node.value if x[node.feature] <= node.threshold: return self.predict_sample(x, node.left) else : return self.predict_sample(x, node.right) def predict (self, X ): """预测多个样本""" return np.array([self.predict_sample(x, self.root) for x in X]) class DecisionTreeRegressor : def __init__ (self, max_depth=None , min_samples_split=2 , min_samples_leaf=1 ): self.max_depth = max_depth self.min_samples_split = min_samples_split self.min_samples_leaf = min_samples_leaf self.root = None def mse (self, y ): """计算均方误差""" if len (y) == 0 : return 0 return np.var(y) * len (y) def best_split (self, X, y ): """寻找最优分裂(最小化 MSE)""" n_samples, n_features = X.shape if n_samples < self.min_samples_split: return None , None parent_mse = self.mse(y) best_gain = 0 best_feature = None best_threshold = None for feature in range (n_features): thresholds = np.unique(X[:, feature]) for threshold in thresholds: left_mask = X[:, feature] <= threshold right_mask = ~left_mask if np.sum (left_mask) < self.min_samples_leaf or \ np.sum (right_mask) < self.min_samples_leaf: continue left_mse = self.mse(y[left_mask]) right_mse = self.mse(y[right_mask]) gain = parent_mse - (left_mse + right_mse) if gain > best_gain: best_gain = gain best_feature = feature best_threshold = threshold return best_feature, best_threshold def build_tree (self, X, y, depth=0 ): """递归构建回归树""" n_samples = X.shape[0 ] if (self.max_depth is not None and depth >= self.max_depth) or \ n_samples < self.min_samples_split: leaf_value = np.mean(y) return Node(value=leaf_value) feature, threshold = self.best_split(X, y) if feature is None : leaf_value = np.mean(y) return Node(value=leaf_value) left_mask = X[:, feature] <= threshold right_mask = ~left_mask left_subtree = self.build_tree(X[left_mask], y[left_mask], depth + 1 ) right_subtree = self.build_tree(X[right_mask], y[right_mask], depth + 1 ) return Node(feature=feature, threshold=threshold, left=left_subtree, right=right_subtree) def fit (self, X, y ): """训练模型""" self.root = self.build_tree(X, y) return self def predict_sample (self, x, node ): """预测单个样本""" if node.value is not None : return node.value if x[node.feature] <= node.threshold: return self.predict_sample(x, node.left) else : return self.predict_sample(x, node.right) def predict (self, X ): """预测多个样本""" return np.array([self.predict_sample(x, self.root) for x in X]) if __name__ == '__main__' : from sklearn.datasets import load_iris, load_boston from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, mean_squared_error iris = load_iris() X, y = iris.data, iris.target X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2 , random_state=42 ) clf = DecisionTreeClassifier(max_depth=3 , criterion='gini' ) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print (f"分类准确率: {accuracy_score(y_test, y_pred):.4 f} " ) boston = load_boston() X, y = boston.data, boston.target X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2 , random_state=42 ) reg = DecisionTreeRegressor(max_depth=5 ) reg.fit(X_train, y_train) y_pred = reg.predict(X_test) print (f"回归 MSE: {mean_squared_error(y_test, y_pred):.4 f} " )
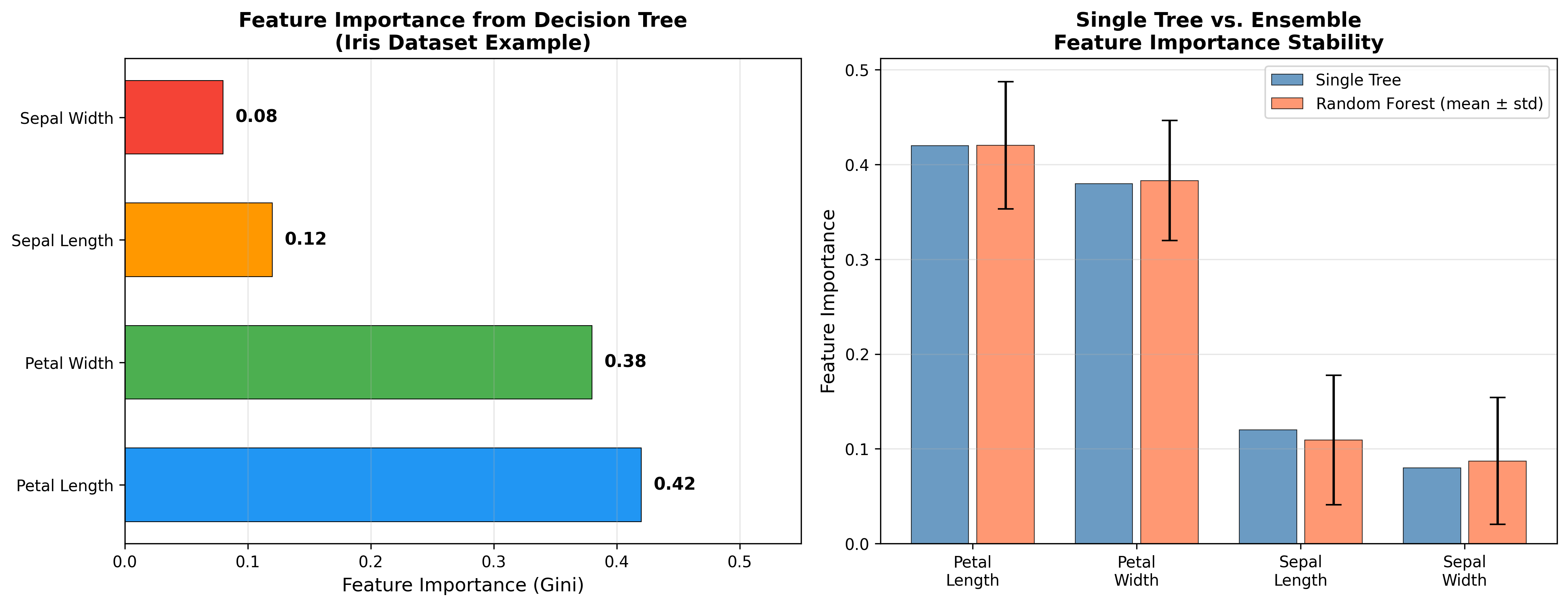
特征重要性
决策树提供了一种自然的特征重要性 度量:
即所有使用特征
下图展示了 Iris 数据集上决策树训练后各特征的重要性排序:
Feature Importance
实现 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def feature_importance (self, node, X, total_samples ): """递归计算特征重要性""" if node.value is not None : return np.zeros(X.shape[1 ]) importance = np.zeros(X.shape[1 ]) left_mask = X[:, node.feature] <= node.threshold right_mask = ~left_mask n_samples = len (X) n_left = np.sum (left_mask) n_right = np.sum (right_mask) parent_impurity = self.split_criterion(y) left_impurity = self.split_criterion(y[left_mask]) right_impurity = self.split_criterion(y[right_mask]) importance[node.feature] = (n_samples / total_samples) * ( parent_impurity - (n_left / n_samples) * left_impurity - (n_right / n_samples) * right_impurity ) importance += self.feature_importance(node.left, X[left_mask], total_samples) importance += self.feature_importance(node.right, X[right_mask], total_samples) return importance
多变量决策树
标准决策树使用单变量分裂 (如多变量决策树 (Multivariate
Decision Tree)使用线性组合 作为分裂准则:
优点 :能以更少的节点表示斜向边界
缺点 : - 寻找最优
算法 :在每个节点,使用线性分类器(如感知机、SVM)找到分裂超平面。
Q&A 精选
Q1:决策树为什么能处理非线性问题?
A:决策树通过递归分割特征空间,将其划分为多个矩形区域,每个区域对应一个叶节点的预测值。虽然单次分裂是线性的(
Q2:信息增益为什么倾向于选择取值多的特征?
A:极端情况:若特征是样本 ID(每个样本唯一值),则按 ID
分裂后每个子集只有一个样本,
Q3:基尼系数和熵哪个更好?
A:两者在理论上等价(都是凹函数,形状相似),但实践中略有差异: -
基尼系数 :计算更快(无对数), CART 采用 -
熵 :更符合信息论解释, ID3/C4.5 采用
实验表明性能差异不大。选择主要基于计算效率和实现偏好。
Q4:如何处理类别型特征?
A:对于无序类别(如颜色:红、绿、蓝): - 方法 1 :
One-Hot 编码,转为多个二元特征 - 方法
2 :直接使用多路分裂( ID3 方式),每个类别值一个分支 -
方法 3 :二元分裂(CART
方式),将类别分为两个子集(需遍历
对于有序类别(如等级:低、中、高),可视为连续特征处理。
Q5:决策树能处理多输出任务吗?
A:可以。对于多输出回归(如同时预测身高和体重),叶节点存储目标向量的均值:
对于多标签分类,叶节点存储各标签的概率分布。
Q6:预剪枝和后剪枝哪个更好?
A: -
预剪枝 :快速,但可能过早停止(某些看似无效的分裂后续可能有用)
- 后剪枝 :更准确(基于完整树的信息),但计算成本高
实践中,预剪枝用于快速原型,后剪枝用于精细调优。 Scikit-learn
的决策树主要使用预剪枝。
Q7:决策树为什么对特征尺度不敏感?
A:决策树的分裂条件是
Q8:如何可视化决策树?
A:使用 Graphviz 或 matplotlib:
1 2 3 4 5 6 7 8 9 from sklearn.tree import export_graphvizimport graphvizdot_data = export_graphviz(clf, out_file=None , feature_names=iris.feature_names, class_names=iris.target_names, filled=True , rounded=True ) graph = graphviz.Source(dot_data) graph.render("decision_tree" )
或使用 plot_tree:
1 2 3 4 5 6 7 from sklearn.tree import plot_treeimport matplotlib.pyplot as pltplt.figure(figsize=(20 , 10 )) plot_tree(clf, feature_names=iris.feature_names, class_names=iris.target_names, filled=True ) plt.show()
Q9:决策树能做特征选择吗?
A:可以。通过特征重要性排序,选择最重要的
1 2 3 4 5 importances = clf.feature_importances_ indices = np.argsort(importances)[::-1 ] print ("特征排名:" )for i in range (X.shape[1 ]): print (f"{i+1 } . 特征 {indices[i]} ({importances[indices[i]]:.4 f} )" )
但注意:决策树的特征重要性可能不稳定(数据微小变化导致不同排序)。可结合随机森林获得更稳定的重要性。
Q10:决策树能并行化吗?
A:单棵树的训练难以并行化(每个节点的分裂依赖父节点)。但可并行化:
1. 特征搜索 :并行计算每个特征的最优分裂点 2.
样本采样 :随机森林中,并行训练多棵树 3.
预测 :并行预测多个样本
现代实现(如 XGBoost 、 LightGBM)使用高度优化的并行算法。
Q11:决策树的最优深度如何选择?
A:通过交叉验证:
1 2 3 4 5 6 7 from sklearn.model_selection import GridSearchCVparam_grid = {'max_depth' : [3 , 5 , 7 , 9 , 11 , None ]} clf = DecisionTreeClassifier() grid_search = GridSearchCV(clf, param_grid, cv=5 , scoring='accuracy' ) grid_search.fit(X_train, y_train) print (f"最优深度: {grid_search.best_params_['max_depth' ]} " )
一般来说,深度
Q12:决策树能处理高维数据吗?
A:理论上可以,但高维数据存在维度灾难 : -
特征多,搜索最优分裂点计算量大(
解决方案: - 特征选择 :降低维度 -
正则化 :限制树深度、叶节点样本数 -
集成方法 :随机森林通过特征采样缓解维度问题
决策树的变体与扩展
代价敏感决策树
在不平衡数据或不同错误代价不同的场景(如医疗诊断,漏诊代价高于误诊),引入代价矩阵
将 真 实 类 别 预 测 为 的 代 价
修改分裂准则,最小化期望代价:
模糊决策树
允许样本部分属于 多个分支(隶属度
增量决策树
在线学习场景中,数据逐步到来。增量决策树(如 Hoeffding Tree)利用
Hoeffding 不等式,判断何时有足够样本进行可靠分裂。
✏️ 练习题与解答
练习 1:信息增益计算
题目 :数据集
解答 :
父节点的熵:
各子节点的熵:
条件熵:
信息增益:
特征
信息增益率:
练习 2:基尼系数与熵的近似
题目 :证明对于二分类问题,当使用自然对数时,
解答 :
令
熵的泰勒展开 (以自然对数为底):
在
基尼系数 :
对比两者:
因此
练习 3:代价复杂度剪枝
题目 :一棵决策树有子树
解答 :
临界
当
因为应该剪枝 。
直觉上,
练习 4:缺失值的信息增益修正
题目 :数据集
解答 :
非缺失样本比例:
修正后的信息增益:
缺失值越多,
练习
5:多变量决策树的决策边界
题目 :标准决策树(单变量分裂)在二维空间中分割出一个"阶梯状"的决策边界。说明为什么需要至少多少次分裂才能近似表示直线
解答 :
标准决策树 :每次分裂产生平行于坐标轴的边界(
设斜线经过
精确地说,在
多变量决策树 :使用线性组合只需 1 次分裂 即可精确表示
这正是多变量决策树的优势:用更紧凑的树结构表示斜向决策边界。代价是寻找最优
参考文献
Quinlan, J. R. (1986). Induction of decision trees.
Machine Learning , 1(1), 81-106.Quinlan, J. R. (1993). C4.5: Programs for
Machine Learning . Morgan Kaufmann.Breiman, L., Friedman, J., Stone, C. J., & Olshen, R.
A. (1984). Classification and Regression Trees .
Wadsworth.Hastie, T., Tibshirani, R., & Friedman, J.
(2009). The Elements of Statistical Learning (2nd ed.).
Springer. [Chapter 9: Additive Models, Trees, and Related Methods]Mitchell, T. M. (1997). Machine Learning .
McGraw-Hill. [Chapter 3: Decision Tree Learning]Rokach, L., & Maimon, O. (2008). Data
Mining with Decision Trees: Theory and Applications . World
Scientific.Breiman, L. (2001). Random forests. Machine
Learning , 45(1), 5-32.Loh, W. Y. (2011). Classification and regression
trees. Wiley Interdisciplinary Reviews: Data Mining and Knowledge
Discovery , 1(1), 14-23.
决策树以其直观的结构和强大的表达能力,成为机器学习的重要工具。从信息熵到基尼系数,从
ID3 到
CART,本章系统推导了决策树的理论基础与算法细节。理解决策树不仅是掌握经典算法的需要,更是理解集成学习(随机森林、
GBDT 、 XGBoost)的前提——这些现代算法的核心都是决策树的组合与优化。