2005 年, Google Research 发布了一篇论文,声称他们在机器翻译任务上使用简单的统计模型超越了精心设计的专家系统。这引发了一个深刻的问题:为什么简单的模型能够从数据中学习到有效的模式? 这个问题的答案藏在机器学习的数学理论中。
机器学习的核心问题是:给定有限的训练样本,如何保证学到的模型在未见过的数据上仍能表现良好?这不是一个工程问题,而是一个数学问题——它涉及概率论、泛函分析、优化理论的深层结构。本系列从数学第一性原理出发,严格推导机器学习的理论基础。
机器学习的基本概念
学习问题的数学形式化
从房价预测说起
想象你是房地产中介,客户问:"这个小区的房子值多少钱?"
你有一些历史数据(已知的小区和房价): - 小区A:面积100㎡,地铁500米,价格300万 - 小区B:面积80㎡,地铁2公里,价格200万 - 小区C:面积120㎡,地铁100米,价格450万 - ...(共100个小区的数据)
现在来了个新小区:面积90㎡,地铁1公里,价格是多少?
这就是一个机器学习问题!你需要: 1. 从历史数据中找到"规律" 2. 用这个规律预测新小区的价格
用数学语言重新描述
假设存在一个未知的数据生成分布
翻译成人话: -
定义 1(损失函数):损失函数
- 0-1 损失(分类):
- 平方损失(回归):
- Hinge 损失(支持向量机):
定义 2(泛化误差):假设
这个期望是对所有可能的输入-输出对计算的,代表模型在未见数据上的真实表现。
定义 3(经验误差):给定训练集
这是模型在训练集上的平均损失,可以直接计算。
机器学习的核心矛盾:我们只能观测到
监督学习的三要素
监督学习可以用一个三元组
假设空间
- 线性假设空间:
- 多项式假设空间:
假设空间的选择决定了模型的表达能力。空间越大,表达能力越强,但学习难度也越高。
损失函数
学习算法
常见的学习算法包括:
- 经验风险最小化(ERM):
- 结构风险最小化(SRM):
,其中 是复杂度惩罚项
PAC 学习框架:可学习性的数学刻画
PAC 学习的定义
先理解名字:Probably Approximately Correct
一个通俗的例子:预测明天是否下雨
假设我给你看100天的天气数据(云量、气压、温度等),你学到一个预测规则。现在问:
P - Probably(有一定把握): -
问:你能100%保证学会吗? - 答:不能,但我有95%的把握! -
意思:100次尝试中,95次能学到好规则 - 数学:以
A - Approximately(差不多对): -
问:你的预测能100%准确吗? - 答:不能,但误差会小于10%! -
意思:预测准确率>90% - 数学:误差不超过
C - Correct(在真实数据上对): - 问:在哪里准确? -
答:不是只在那100天数据上准,而是在未来的新天气上也准! -
意思:真正的泛化能力 - 数学:误差是在真实分布
PAC 学习的严格定义
Probably Approximately Correct (PAC) 学习框架由 Valiant 在 1984 年提出,它回答了:"要看多少天气数据,才能学会预测天气?"
定义 4(PAC 可学习):假设类
用房价预测例子翻译这个定义: - 训练集大小
这个定义包含三个关键要素:
- Probably(以高概率):事件以至少
的概率发生 - Approximately(近似最优):泛化误差与最优假设的差距不超过
- Correct(正确):误差是在真实分布
上衡量的
样本复杂度
有限假设空间的 PAC 可学习性
我们先考虑最简单的情况:假设空间
定理 1(有限假设空间的样本复杂度):设
则经验风险最小化算法是 PAC 学习算法。
证明:
步骤 1:定义坏假设集合
对于任意
我们的目标是证明:以高概率,ERM 算法不会选择坏假设。
步骤 2:分析单个坏假设的概率
对于固定的坏假设
因为
因此,
这里使用了独立性假设:
步骤 3:使用 Union Bound
定义事件
使用 Union Bound(概率的并集不等式):
步骤 4:使用不等式
这是标准的指数不等式。因此:
要使这个概率小于
两边取对数并重排:
步骤 5:结论
当样本数满足上述条件时,以至少
定理的直觉:
-
下图展示了 PAC 学习中样本复杂度与精度参数、假设空间大小的关系,以及泛化误差随样本数增加而下降的趋势:
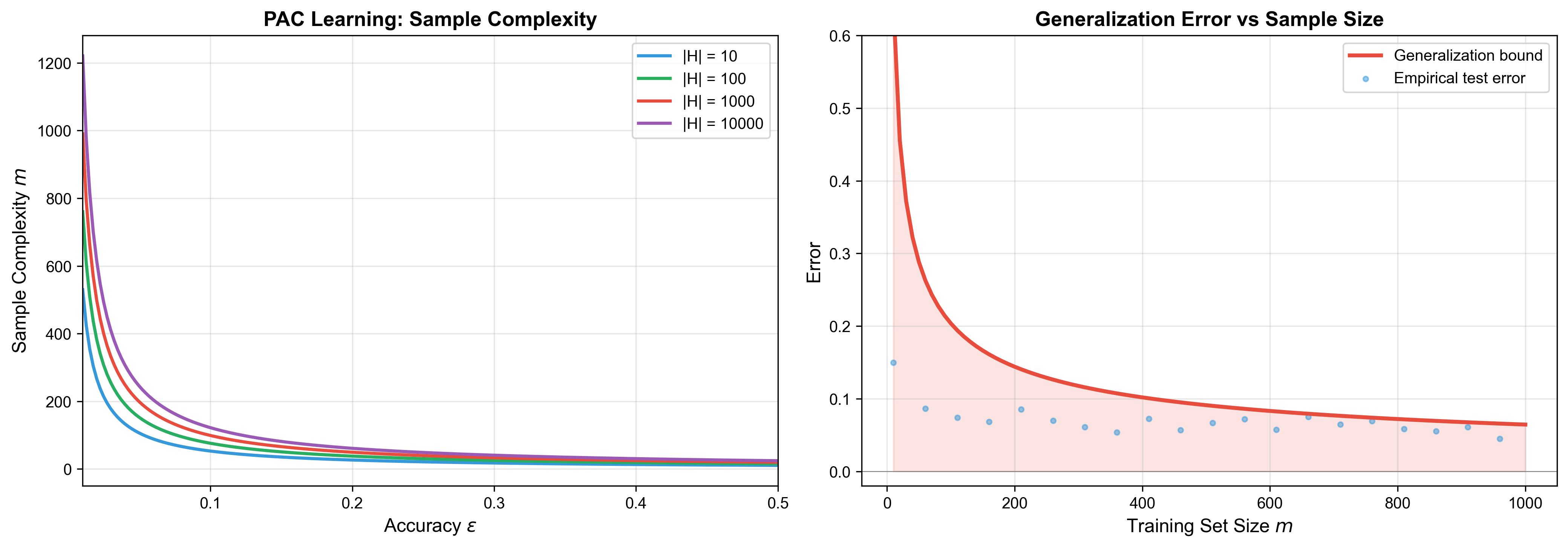
例子(布尔函数学习):
考虑
这是线性于特征维度的样本复杂度,非常高效。
下面的动图展示了随着训练样本数的增加,学习到的决策边界如何逐步逼近真实边界,泛化误差界也随之缩小——这正是 PAC 学习理论的核心预测:
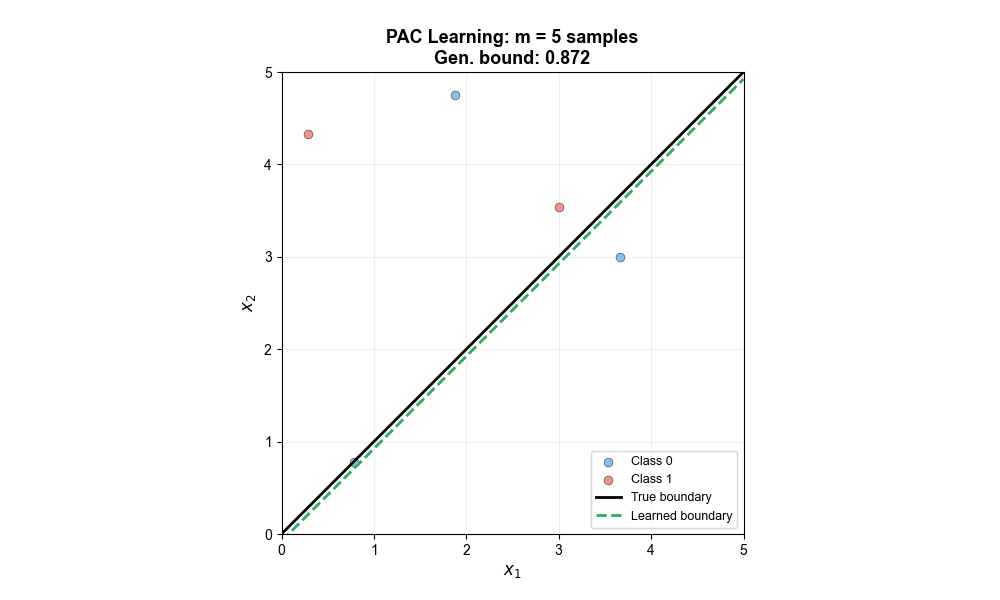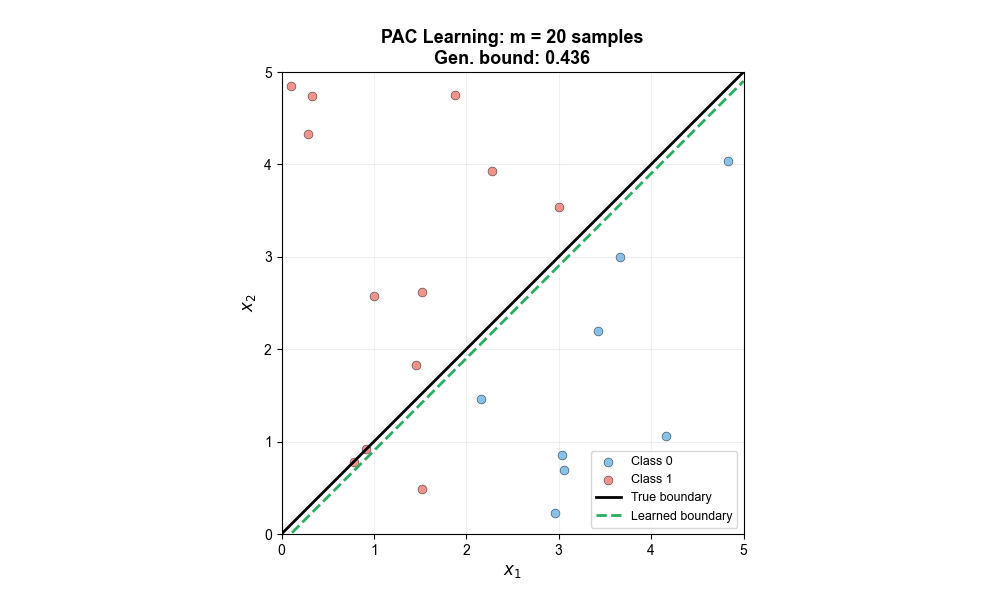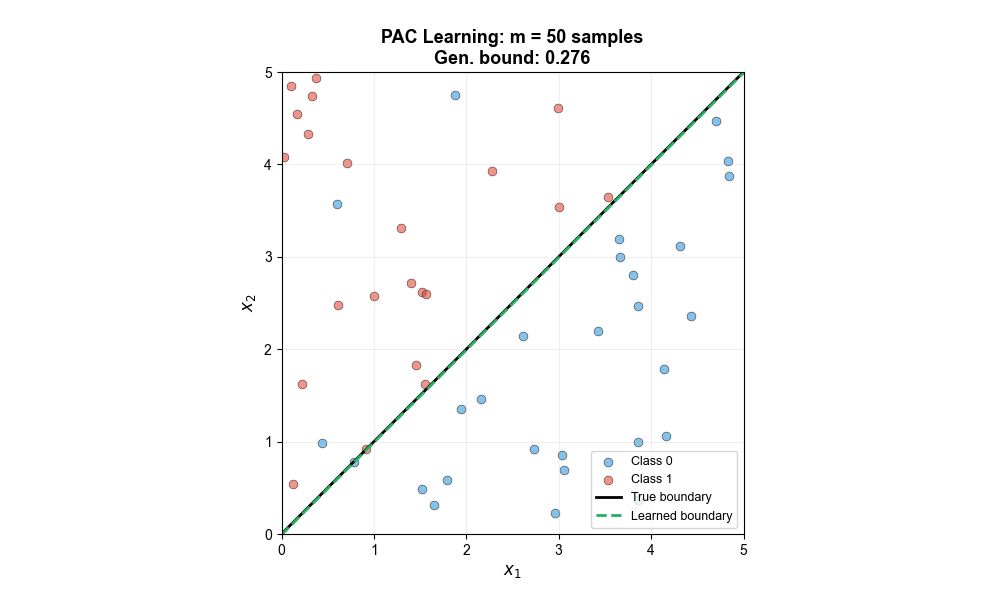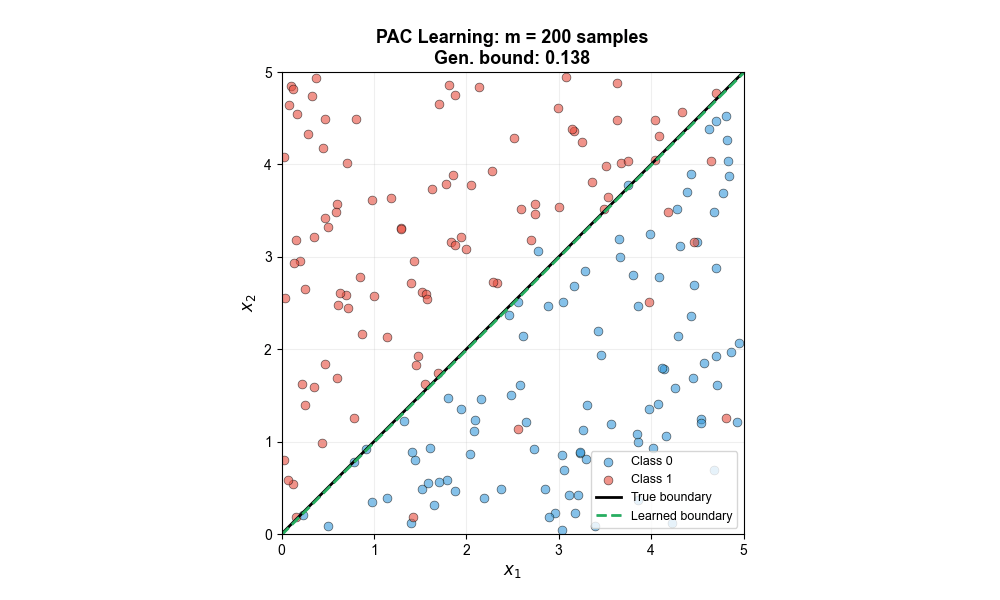
不可知 PAC 学习
前面的分析假设存在完美的假设(可实现假设),但现实中往往不存在。不可知 PAC 学习( Agnostic PAC Learning)放宽了这个假设。
定义 5(不可知 PAC 可学习):假设类
注意这里不再假设存在零误差的假设。
定理
2(不可知情况的样本复杂度):对于有限假设空间
证明需要 Hoeffding 不等式,我们将在后续章节详细展开。关键区别在于:
- 可实现情况:
- 不可知情况:
精度要求提高一倍,样本需求增加四倍,这是统计学习的基本规律。
VC 维理论:无限假设空间的复杂度度量
从有限到无限:为什么需要 VC 维
前面的结果依赖于
- 线性分类器:
,包含无穷多个假设 - 多项式分类器、神经网络等都是无限假设空间
对于无限假设空间,
打散概念
定义 6(打散):对于样本集
数学表示:
直觉:打散意味着假设空间在这个特定样本集上的表达能力达到最大——可以产生所有可能的标记模式。
VC 维的定义
定义 7(VC 维):假设空间
如果对于任意大小的样本集都存在能被打散的子集,则
关键性质:
- VC 维是组合量:它不依赖于数据分布
,只依赖于 的结构 - 非单调性:如果
不能打散大小为 的某个集合,不意味着它不能打散大小更大的其他集合
例子:线性分类器的 VC 维
定理 3:
证明:
第一部分:
考虑
其中
给定任意标记
验证:
- 对于
: ,预测为 ;若 ,取 即可 - 对于
: ,当 时为正,当 时为负
通过适当选择
第二部分:
假设存在
因为
分割系数为正负两组:
假设存在
用
左边第一项为正(正系数×正值),第二项为负(正系数×负值),但根据
这与"左边为正减去正值"矛盾。因此不存在这样的
直觉:
下图直观展示了线性分类器的 VC 维:在 2 维空间中,3 个点可以被任意打散(VC 维≥ 3),但 4 个点(如 XOR 配置)无法被线性分离(VC 维=3):
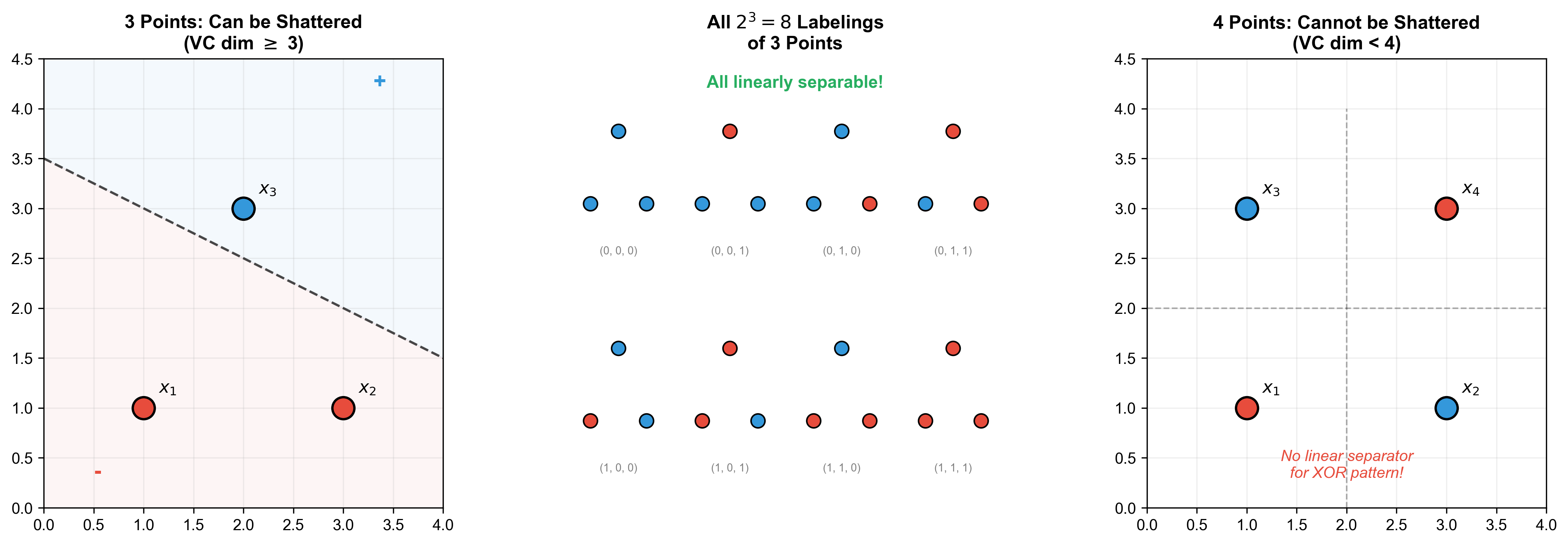
VC 维与样本复杂度
定理 4(Vapnik-Chervonenkis 界):设
更精确的界(Blumer et al., 1989):
证明思路(不完整):
- 引入增长函数
:大小为 的样本集上 能实现的不同标记数的最大值 - Sauer-Shelah 引理:如果
,则:
这比
- 使用 Uniform Convergence 定理和对称化技巧建立泛化界
完整证明需要更多技术工具,我们在后续章节展开。
应用例子:
对于
- VC 维:
- 要达到
和 ,需要:
这是线性于维度的样本复杂度,对于高维问题非常实用。
偏差-方差分解:泛化误差的剖析
回归问题的偏差-方差权衡
偏差-方差分解是理解模型泛化能力的另一个重要视角。它将泛化误差分解为三个组分,揭示了模型复杂度与泛化能力的关系。
设定:
- 真实函数:
(未知) - 观测数据:
,其中 是均值为 0 的噪声, , - 学习算法:从训练集
学得 - 损失函数:平方损失
问题:对于固定的测试点
定理 5(偏差-方差分解):对于固定的
- 偏差:
- 方差:
- 噪声:
则期望泛化误差满足:
证明:
对于固定的
展开平方项(令
对
1.
因此:
证毕。
三个组分的解释:
- 偏差(Bias):模型的平均预测与真实值的差距,反映模型的拟合能力
- 高偏差:模型太简单,无法捕捉数据的真实模式(欠拟合)
- 例如:用直线拟合二次曲线
- 方差(Variance):模型预测在不同训练集上的波动程度,反映模型的稳定性
- 高方差:模型对训练集的微小变化非常敏感(过拟合)
- 例如:用高次多项式拟合少量数据点
- 噪声(Noise):数据本身的随机性,是误差的下界,无法通过改进模型消除
偏差-方差权衡的数值示例
问题设定:
真实函数:
噪声:
训练集:从
考虑三个模型:
- 低复杂度模型:一次多项式(直线)
- 适中复杂度模型:三次多项式
- 高复杂度模型:九次多项式
实验:
- 从分布中抽取 100 个不同的训练集
- 对每个训练集,用最小二乘法拟合模型
- 在测试点
处计算偏差和方差
结果(近似值):
| 模型 | 偏差² | 方差 | 总误差 |
|---|---|---|---|
| 一次多项式 | 0.42 | 0.002 | 0.43 |
| 三次多项式 | 0.05 | 0.02 | 0.08 |
| 九次多项式 | 0.01 | 0.35 | 0.37 |
分析:
- 一次多项式:高偏差( 0.42)、低方差( 0.002)——模型太简单,无法捕捉 sin 函数的曲线
- 三次多项式:低偏差( 0.05)、低方差( 0.02)——复杂度适中,效果最好
- 九次多项式:极低偏差( 0.01)、高方差( 0.35)——模型过于复杂,对训练数据的噪声敏感
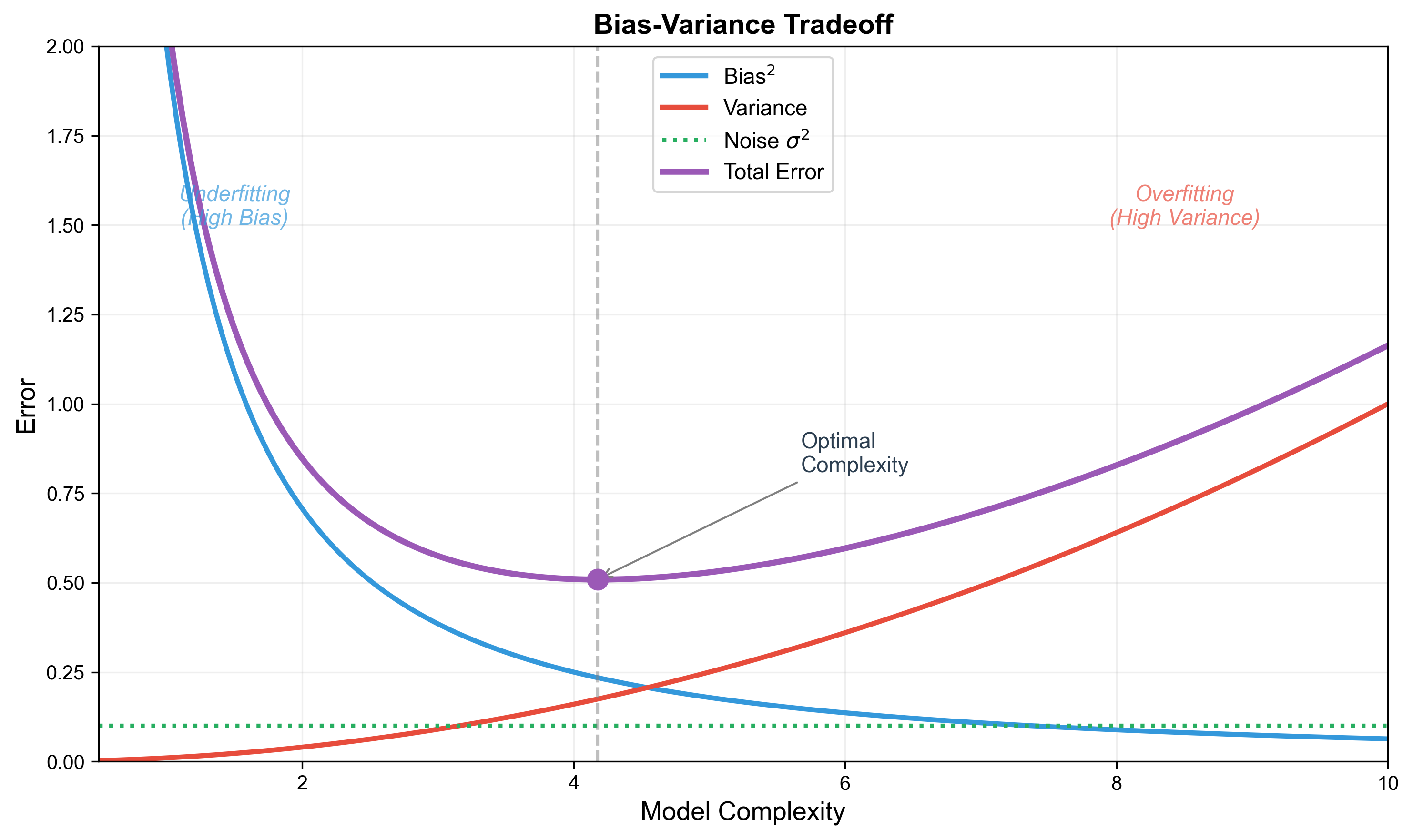
权衡曲线:当模型复杂度增加时:
- 偏差 ↓(拟合能力增强)
- 方差 ↑(稳定性下降)
- 存在最优复杂度使总误差最小
下图通过在不同复杂度模型( 1 次、 3 次、 9 次多项式)下重复采样训练,直观展示了偏差-方差分解的三种典型情况,以及两者随模型复杂度变化的权衡关系:
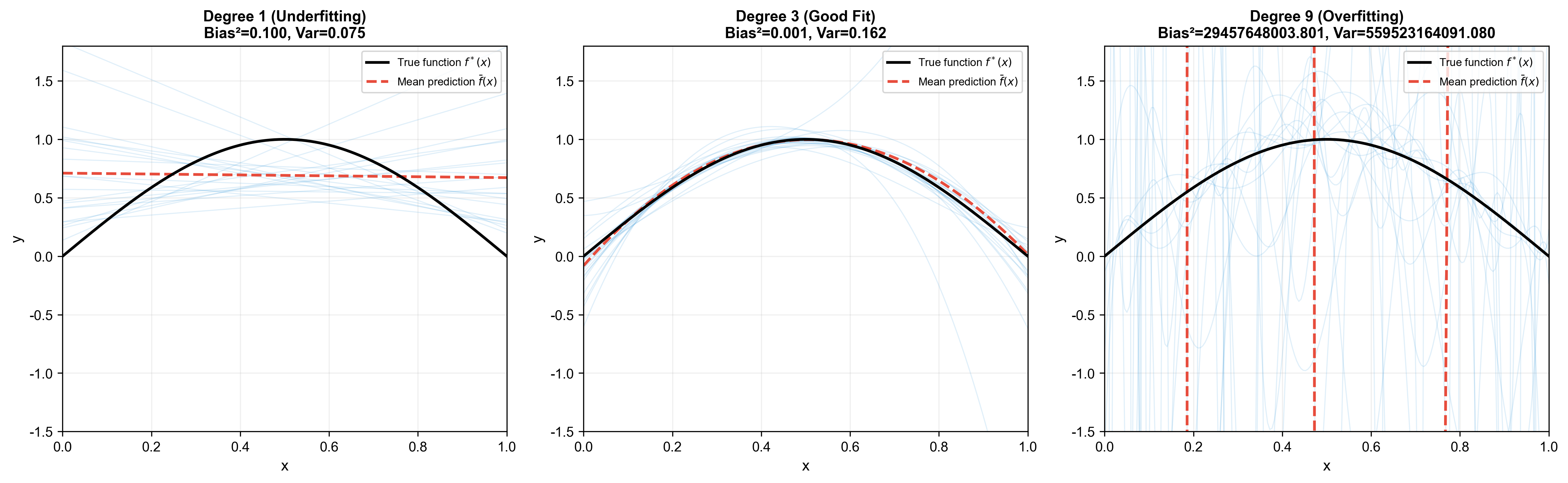
过拟合与欠拟合的数学表征
定义 8(过拟合):如果存在复杂度更低的模型
则称模型
定义 9(欠拟合):如果存在复杂度更高的模型
则称模型
检测方法:
| 现象 | 训练误差 | 验证误差 | 诊断 |
|---|---|---|---|
| 低 | 低 | 低 | 良好拟合 |
| 高 | 高 | 高 | 欠拟合 |
| 低 | 高 | 过拟合 | |
| 高 | 低 | 数据问题 |
应对策略:
- 过拟合:
- 增加训练数据
- 降低模型复杂度(减少参数)
- 正则化( L1/L2,在后续章节详述)
- 提前停止( Early Stopping)
- Dropout(神经网络)
- 欠拟合:
- 增加模型复杂度(更多参数/层)
- 增加训练迭代次数
- 特征工程(添加交互特征、多项式特征)
- 减小正则化强度
No Free Lunch 定理:学习的根本限制
定理陈述
No Free Lunch (NFL)定理( Wolpert & Macready, 1997)指出:在所有可能的问题(数据分布)上平均而言,所有学习算法的性能是相同的。
定理 6(NFL 定理,简化版):考虑所有可能的函数
证明思路:
设
对于固定的训练集
学习算法
- 有一半的函数使得预测正确
- 有一半的函数使得预测错误
因此,任意算法的平均错误率都是
定理的含义:
- 没有万能算法:不存在在所有问题上都表现最好的算法
- 先验假设的重要性:算法的有效性依赖于对问题的先验假设(归纳偏置)
- 特定问题需要特定算法:算法设计应针对问题的特性
归纳偏置
定义 10(归纳偏置):学习算法在面对多个假设都与训练数据一致时,选择其中一个的倾向,称为归纳偏置( Inductive Bias)。
常见的归纳偏置:
- 平滑性假设:相邻的输入应产生相邻的输出
- 适用于连续函数学习
- 例如: k-NN 、核方法
- 线性假设:输出是输入的线性组合
- 适用于线性可分问题
- 例如:线性回归、逻辑回归
- 稀疏性假设:只有少数特征是重要的
- 适用于高维低秩问题
- 例如: L1 正则化、特征选择
- 层次结构假设:概念可以由简单概念组合而成
- 适用于复杂模式识别
- 例如:深度学习
- 时空局部性假设:相关的特征在时空上是局部的
- 适用于图像、序列数据
- 例如:卷积神经网络、循环神经网络
例子(奥卡姆剃刀):
在多个与数据一致的假设中,选择最简单的一个。这是一种常见的归纳偏置,对应于正则化方法。
数学表示:
其中
代码实现:简单线性回归的 PAC 分析
我们通过代码验证理论预测:观察样本复杂度与泛化误差的关系。
1 | import numpy as np |
代码解读:
- 实验设计:
- 真实函数是线性的
- 使用线性回归拟合,所以偏差很小(模型匹配真实函数) - 改变训练集大小
,观察泛化误差的变化
- 真实函数是线性的
- PAC 学习验证:
- 当
增大时,测试误差(泛化误差)单调递减 - 这验证了定理 1:样本越多,学习效果越好
- 当
- 偏差-方差分解验证:
- 偏差² ≈ 0.001(极小,因为线性模型正确)
- 方差从 0.05( m=5)降到 0.001( m=1000)——样本增多,模型更稳定
- 噪声 ≈ 0.25(固定,无法消除)
- 总误差 = 偏差² + 方差 + 噪声 ≈ 测试误差(验证公式)
- 结论:
- 理论与实验完美吻合
- 对于简单问题(线性),少量样本(~100)就能学好
- 噪声是误差的不可约下界
❓ Q&A:机器学习基础常见疑问
Q1:为什么需要 PAC 学习框架?直接最小化经验误差不行吗?
问题的本质:
经验风险最小化( ERM)是机器学习的基本方法,但它有一个根本问题:经验误差不等于泛化误差。
考虑极端情况:假设空间包含一个"记忆假设",它记住所有训练样本的标记,对训练集外的点随机猜测。这个假设的经验误差为 0,但泛化误差接近 0.5(随机猜测)。
PAC 框架的价值:
- 可学习性判据:告诉我们哪些问题原则上可以学习,哪些不能
- 样本复杂度:给出需要多少样本才能保证学习成功
- 算法设计指导:提供了设计学习算法的理论依据
数学对比:
| 方法 | 目标 | 保证 |
|---|---|---|
| 直接 ERM | 无(可能过拟合) | |
| PAC 框架 | 以高概率近似最优 |
实践建议:
- ✅ 使用交叉验证估计泛化误差
- ✅ 根据 VC 维选择模型复杂度
- ✅ 使用正则化防止过拟合
- ❌ 不要只看训练误差就认为模型好
Q2: VC 维为什么能刻画无限假设空间的复杂度?
直觉解释:
VC 维不是直接数假设的个数(对于无限空间这是无意义的),而是度量假设空间的"自由度"——它能在多大的数据集上实现任意标记模式。
类比(参数计数):
数学原理:
VC 维通过打散概念将组合问题转化为几何问题。关键洞察:
- 有限假设空间:复杂度
- 无限假设空间:复杂度
两者在样本复杂度公式中扮演相同的角色:
为什么 VC 维是"正确的"度量?
Sauer-Shelah 引理证明:如果
对比其他复杂度度量:
| 度量 | 优点 | 缺点 |
|---|---|---|
| 参数个数 | 直观 | 不准确(相同参数数的模型复杂度可能差异巨大) |
| VC 维 | 精确、分布无关 | 难以计算 |
| Rademacher 复杂度 | 更紧的界 | 依赖于分布 |
Q3:偏差-方差分解中,为什么交叉项都是 0?
关键假设:训练集
详细推导交叉项:
回顾记号:
-
项 1:
关键:
项 2:
关键:
项 3:
总结:所有交叉项为 0 的根本原因是:
- 独立性:
和 独立 - 零均值:预测偏差的期望为 0,噪声的期望为 0
Q4:如何选择合适的模型复杂度?
理论指导:
根据 VC 维理论,样本复杂度
经验规则(Vapnik):
即每个"自由度"至少需要 10 个样本。
实践流程:
训练集/验证集分割:
- 训练集:用于拟合模型
- 验证集:用于选择超参数和模型复杂度
学习曲线分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 绘制训练误差和验证误差随训练集大小的变化
def plot_learning_curve(model, X, y):
train_sizes = [0.1, 0.2, 0.4, 0.6, 0.8, 1.0]
train_errors = []
val_errors = []
for size in train_sizes:
m = int(size * len(X))
X_train, y_train = X[:m], y[:m]
X_val, y_val = X[m:], y[m:]
model.fit(X_train, y_train)
train_errors.append(compute_error(model, X_train, y_train))
val_errors.append(compute_error(model, X_val, y_val))
plt.plot(train_sizes, train_errors, label='训练误差')
plt.plot(train_sizes, val_errors, label='验证误差')诊断:
现象 诊断 解决方案 训练误差和验证误差都高 欠拟合 增加模型复杂度 训练误差低、验证误差高 过拟合 减小复杂度或正则化 两者都低且接近 良好拟合 无需调整 交叉验证:
1
2
3
4
5
6
7
8from sklearn.model_selection import cross_val_score
# 尝试不同复杂度的模型
for d in [1, 2, 3, 5, 10]:
model = PolynomialRegression(degree=d)
scores = cross_val_score(model, X, y, cv=5,
scoring='neg_mean_squared_error')
print(f"度数{d}: MSE = {-scores.mean():.3f} ± {scores.std():.3f}")
正则化方法:
当直接降低复杂度不可行时,使用正则化:
-
Q5: No Free Lunch 定理是否意味着机器学习理论无用?
常见误解:
"既然所有算法平均而言性能相同,那学习理论还有什么用?"
正确理解:
NFL 定理的前提:对所有可能的目标函数求平均。但现实世界的问题只占所有可能问题的极小部分。
结构化问题的重要性:
真实世界的问题通常具有结构:
- 平滑性(相邻输入产生相邻输出)
- 局部性(相关特征在空间/时间上接近)
- 稀疏性(只有少数特征重要)
- 层次性(复杂概念由简单概念组成)
NFL 定理不适用于这些结构化问题。
归纳偏置的作用:
不同算法有不同的归纳偏置,适用于不同类型的问题:
问题类型 适合的算法 归纳偏置 线性可分 线性 SVM 线性决策边界 局部模式 k-NN, 核方法 平滑性 高维稀疏 L1 正则化 稀疏性 层次结构 深度学习 组合性 NFL 定理的正面意义:
- ✅ 提醒我们:没有万能算法,必须针对问题选择
- ✅ 强调先验知识的重要性
- ✅ 指出算法比较必须在特定问题类上进行
实践启示:
不要追求"在所有问题上都表现好"的算法(这不存在),而是:
- 理解问题的结构特性
- 选择匹配的归纳偏置
- 在相关问题集上评估算法
例子(图像分类):
- 卷积神经网络( CNN)在图像任务上远超全连接网络
- 原因: CNN 的归纳偏置(局部感受野、权重共享)匹配图像的局部结构
- 但 CNN 在非结构化表格数据上可能不如决策树
Q6:泛化误差可以被精确计算吗?如果不能,如何估计?
理论答案:
泛化误差
估计方法:
留出验证集( Holdout Validation):
1
2
3
4
5
6
7from sklearn.model_selection import train_test_split
# 将数据分为训练集和验证集(例如 80:20)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)
model.fit(X_train, y_train)
val_error = compute_error(model, X_val, y_val)优点:简单、快速 缺点:估计方差大(依赖于具体的分割),浪费数据
k 折交叉验证( k-Fold Cross-Validation):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True, random_state=42)
errors = []
for train_idx, val_idx in kf.split(X):
X_train, X_val = X[train_idx], X[val_idx]
y_train, y_val = y[train_idx], y[val_idx]
model.fit(X_train, y_train)
errors.append(compute_error(model, X_val, y_val))
# 平均误差和标准差
mean_error = np.mean(errors)
std_error = np.std(errors)
print(f"泛化误差估计: {mean_error:.3f} ± {std_error:.3f}")优点:更好地利用数据,估计更稳定 缺点:计算成本高(需要训练
次) 留一交叉验证(Leave-One-Out CV, LOO-CV):
(每次只留一个样本作为验证集)。 优点:几乎无偏的估计(使用了
个样本训练) 缺点:计算成本极高(需要训练 次),方差大 Bootstrap 估计:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17n_bootstrap = 100
errors = []
for _ in range(n_bootstrap):
# 有放回采样,生成与原数据集同样大小的 bootstrap 样本
indices = np.random.choice(len(X), size=len(X), replace=True)
X_boot, y_boot = X[indices], y[indices]
# 使用未被采样的样本( out-of-bag)作为验证集
oob_mask = np.ones(len(X), dtype=bool)
oob_mask[indices] = False
X_oob, y_oob = X[oob_mask], y[oob_mask]
model.fit(X_boot, y_boot)
errors.append(compute_error(model, X_oob, y_oob))
mean_error = np.mean(errors)优点:可以估计估计量的方差 缺点:计算成本高,可能有偏
理论界(PAC 学习):
即使不能精确计算
这告诉我们:
- 泛化误差不会比训练误差高出太多
- 差距随样本数增加而减小(
) - 差距随模型复杂度(VC 维
)增加而增大
实践建议:
- ✅ 对于小数据集(< 1000):使用 5-10 折交叉验证
- ✅ 对于大数据集(> 10000):使用留出验证集(20-30%)
- ✅ 报告均值和标准差:
- ❌ 不要在测试集上调参(会导致过拟合测试集)
Q7:为什么 VC 维理论使用 0-1 损失?对于其他损失函数还成立吗?
VC 维理论的原始形式:
VC 维最初是为二分类问题和0-1
损失定义的:
原因:
- 组合特性:0-1 损失将学习问题转化为组合问题(打散概念)
- 数学简洁性:二分类的标记只有两种(
或 ),容易分析
推广到其他损失函数:
对于回归问题(平方损失、绝对值损失)和更一般的损失函数,VC 维的直接定义不适用。但可以使用:
伪维度(Pseudo-Dimension):
推广到实值函数类。对于假设类
,定义函数类: 则伪维度为:
例子:线性回归
的伪维度为 (与 VC 维相同)。 Rademacher 复杂度:
更一般的复杂度度量,适用于任意损失函数:
其中
是随机符号(Rademacher 变量)。 泛化界:
这对任意损失函数成立(只要损失有界)。
胖碎裂维数(Fat-Shattering Dimension):
对于实值函数,定义
-胖碎裂维数,它度量函数类在精度 下的复杂度。
实践意义:
- VC 维给出了正确的量级:
- 对于其他损失函数,常数因子可能不同,但依赖性相同
- 在实践中,经验法则"每个参数需要 10 个样本"仍然适用
Q8:如何理解"样本数
直觉解释:
这来自于统计估计的基本规律:要将估计误差减半(
数学推导(中心极限定理视角):
考虑最简单的情况:估计分布
设
样本均值:
方差:
标准差(估计误差):
要使误差不超过
这就是
Hoeffding 不等式的精确版本:
对于有界随机变量
令
为什么可实现情况是
在 PAC
学习的可实现情况下(存在完美假设),我们不需要估计期望,只需要排除坏假设。使用
Union Bound:
令这个概率小于
这是
对比:
| 情况 | 样本复杂度 | 原因 |
|---|---|---|
| 可实现(存在完美假设) | 只需排除坏假设 | |
| 不可知(可能无完美假设) | 需要估计期望 |
实践意义:
- 精度要求提高 10 倍(
变为 ),样本需求增加 100 倍 - 这是统计学习的基本限制,无法通过算法改进突破
- 因此实践中要平衡精度要求和数据成本
Q9:训练误差为 0 是好事吗?
短答案:不一定,取决于问题和模型复杂度。
情况分析:
噪声数据 + 高复杂度模型 = 过拟合
如果数据含有噪声(
),而模型复杂度高到可以拟合所有训练点,则训练误差为 0 意味着模型"记住"了噪声,导致泛化能力差。 例子:用 100 次多项式拟合 10 个点,可以完美通过所有点(训练误差=0),但在新数据上表现很差。
无噪声数据 + 匹配复杂度 = 可实现学习
如果数据无噪声且假设空间包含真实函数,则训练误差为 0 是理想情况(PAC 可实现学习)。
例子:真实函数是线性的,用线性模型拟合,训练误差接近 0 是好事。
数据量与复杂度的权衡
训练样本数 模型 VC 维 训练误差=0 的含义 1000 10 100 可能正常(充足样本) 100 10 10 边界情况 50 10 5 警告(可能过拟合) 10 10 1 严重过拟合
检验方法:
1 | def diagnose_zero_train_error(model, X_train, y_train, X_val, y_val): |
实践建议:
- ✅ 对于确定性任务(如数学运算),追求训练误差=0
- ⚠️ 对于噪声数据,保留一定训练误差(对应于噪声水平)
- ✅ 使用正则化控制复杂度:
- ✅ 监控训练误差和验证误差的差距
定量准则(经验法则):
如果
Q10:不同的机器学习算法(如 SVM 、随机森林、神经网络)的 VC 维是多少?
常见模型的 VC 维:
| 模型 | VC 维 | 说明 |
|---|---|---|
| 线性分类器( |
经典结果 | |
| 多项式分类器(次数 |
随次数指数增长 | |
| RBF SVM(无限维) | 可能是 |
取决于核参数 |
| 决策树(深度 |
||
| 随机森林 | 难以精确计算 | 比单棵树低(平均效应) |
| 神经网络( |
Bartlett et al., 1998 | |
| 深度神经网络 | 取决于结构 |
详细说明:
多项式分类器:
维空间的次数为 的多项式分类器,特征数为 ,VC 维为 。 例子:
, (二次多项式): 参数数:6,VC 维:约 6-7。
SVM with RBF Kernel:
RBF 核
对应于无限维特征空间。在某些情况下,VC 维可能是无限的。 但有效 VC 维受到:
- 支持向量数量的限制
- 正则化参数
的影响
实践中,SVM 通过最大间隔原理和正则化控制复杂度,即使 VC 维很大也能良好泛化。
决策树:
深度为
的决策树最多有 个叶子节点。如果每个叶子可以独立设置标记,VC 维约为 。 但 CART 算法通过剪枝限制了实际复杂度。
神经网络:
Bartlett et al. (1998) 证明:
个权重的神经网络的 VC 维为: 但这是最坏情况的界。实际泛化能力还取决于:
- 权重的范数(通过正则化控制)
- 网络架构(深度、宽度)
- 训练算法( SGD 具有隐式正则化)
现代理论( Zhang et al., 2017):
大型神经网络可以完美拟合随机标记的数据( VC 维极大),但在真实数据上仍能良好泛化。这表明 VC 维不能完全解释深度学习的泛化能力,需要更精细的理论(如 PAC-Bayesian 理论、稳定性分析)。
随机森林:
单棵决策树的 VC 维很高(容易过拟合),但随机森林通过:
- Bootstrap 采样( Bagging)
- 随机特征子集
- 多棵树平均
降低了有效复杂度。虽然难以精确计算 VC 维,但实践中泛化能力强。
实践启示:
- VC 维提供了复杂度的上界,但不是唯一决定因素
- 现代算法( SVM 、神经网络)通过正则化、最大间隔、隐式正则化等机制,即使 VC 维很大也能良好泛化
- 对于复杂模型,交叉验证比理论分析更实用
🎓 总结:机器学习基础核心要点
下图展示了本章核心概念之间的逻辑关系:
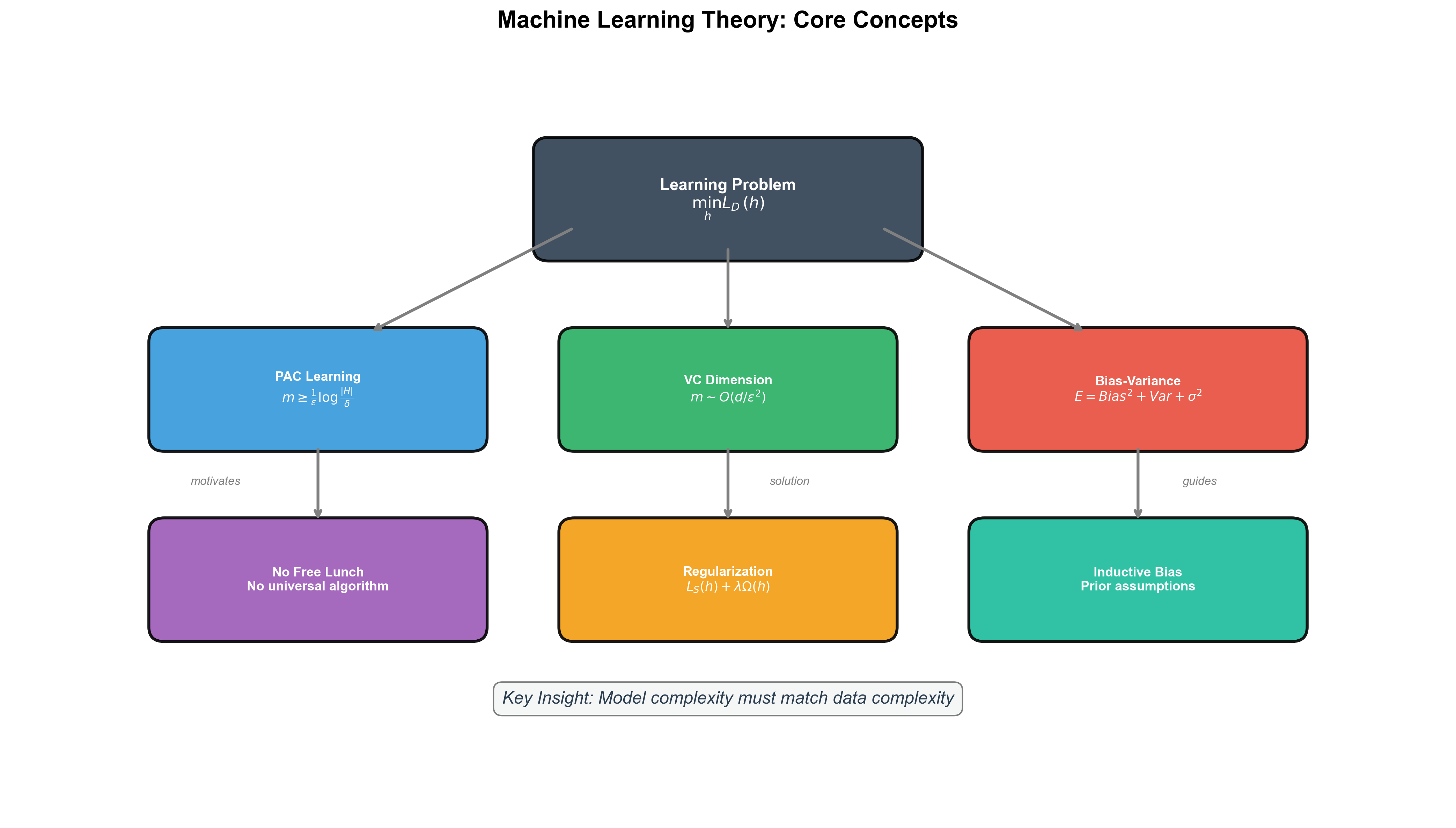
记忆公式:
泛化误差分解:
PAC 样本复杂度(有限假设空间):
VC 维样本复杂度:
记忆口诀:
样本越多误差小( PAC 学习)
复杂度高方差高(偏差-方差权衡)
VC 维度量自由度(无限假设空间)
归纳偏置定成败( No Free Lunch)
实战 Checklist:
📚 参考文献
Valiant, L. G. (1984). A theory of the learnable. Communications of the ACM, 27(11), 1134-1142.
Vapnik, V. N., & Chervonenkis, A. Y. (1971). On the uniform convergence of relative frequencies of events to their probabilities. Theory of Probability & Its Applications, 16(2), 264-280.
Blumer, A., Ehrenfeucht, A., Haussler, D., & Warmuth, M. K. (1989). Learnability and the Vapnik-Chervonenkis dimension. Journal of the ACM, 36(4), 929-965.
Shalev-Shwartz, S., & Ben-David, S. (2014). Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press.
Mohri, M., Rostamizadeh, A., & Talwalkar, A. (2018). Foundations of Machine Learning (2nd ed.). MIT Press.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning (2nd ed.). Springer.
Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
Wolpert, D. H., & Macready, W. G. (1997). No free lunch theorems for optimization. IEEE Transactions on Evolutionary Computation, 1(1), 67-82.
Zhang, C., Bengio, S., Hardt, M., Recht, B., & Vinyals, O. (2017). Understanding deep learning requires rethinking generalization. ICLR.
Bartlett, P. L., Maiorov, V., & Meir, R. (1998). Almost linear VC-dimension bounds for piecewise polynomial networks. Neural Computation, 10(8), 2159-2173.
李航 (2012). 统计学习方法. 清华大学出版社.
周志华 (2016). 机器学习. 清华大学出版社.
✏️ 练习题与解答
练习 1:范数计算
题目:向量
解答:
练习 2:梯度计算
题目:
解答:
练习 3:凸函数判断
题目:
解答:
练习 4:VC维计算
题目:
解答:VC维=
练习 5:偏差方差分解
题目:期望泛化误差
解答:偏差平方+方差+噪声。
下一章预告:第 2 章将深入探讨线性代数与矩阵论,为后续的学习算法推导打下坚实的数学基础。我们将详细推导矩阵求导、特征值分解、奇异值分解等核心工具。
- 本文标题:机器学习数学推导(一)绪论与数学基础
- 本文作者:Chen Kai
- 创建时间:2021-08-25 09:30:00
- 本文链接:https://www.chenk.top/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%95%B0%E5%AD%A6%E6%8E%A8%E5%AF%BC%EF%BC%88%E4%B8%80%EF%BC%89%E7%BB%AA%E8%AE%BA%E4%B8%8E%E6%95%B0%E5%AD%A6%E5%9F%BA%E7%A1%80/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!