推荐系统在实际应用中面临的最大挑战之一就是冷启动问题:新用户没有历史行为,新物品没有交互记录,新系统缺乏数据积累。传统的协同过滤方法在这些场景下完全失效,而跨域推荐和元学习技术为我们提供了新的解决思路。本文将深入探讨冷启动问题的本质、元学习在推荐系统中的应用、跨域迁移学习的各种方法,并提供完整的代码实现。
冷启动问题的本质与分类
冷启动问题是推荐系统面临的核心挑战之一。它可以分为用户冷启动、物品冷启动和系统冷启动三类,每类都有不同的解决策略。
用户冷启动
用户冷启动是指新用户刚注册时,系统无法获取其历史行为数据,难以进行个性化推荐。这是推荐系统中最常见也最棘手的问题之一。
问题定义 :给定用户集合
挑战分析 : 1.
数据稀疏性 :新用户没有任何评分、点击或购买记录 2.
兴趣不确定性 :无法通过行为模式推断用户偏好 3.
推荐准确性要求 :首次推荐的质量直接影响用户体验和留存率
典型场景 : - 电商平台新注册用户 -
内容平台新用户首次访问 - 视频网站新用户无观看历史
物品冷启动
物品冷启动是指新上架的商品、新发布的文章或新上线的视频等,由于缺乏用户交互数据,难以被推荐给合适的用户。
问题定义 :给定物品集合
挑战分析 : 1.
曝光机会有限 :新物品难以获得初始曝光,形成"马太效应" 2.
特征利用不足 :虽然物品有内容特征(标题、描述、类别等),但传统方法难以有效利用
3. 长尾分布 :大部分物品属于长尾,缺乏足够的交互数据
典型场景 : - 电商平台新品上架 - 新闻网站新文章发布 -
音乐平台新歌上线
系统冷启动
系统冷启动是指全新的推荐系统上线时,整个系统缺乏历史数据积累,需要在零数据或极少数据的情况下启动推荐服务。
问题定义 :给定推荐系统
挑战分析 : 1.
完全无数据 :系统刚上线,没有任何用户-物品交互记录 2.
模型无法训练 :传统推荐算法需要大量历史数据才能训练 3.
冷启动周期长 :需要积累足够数据才能达到理想效果
解决方案分类 : -
内容推荐 :基于物品内容特征进行推荐 -
热门推荐 :推荐热门物品作为初始策略 -
跨域迁移 :从其他相关领域迁移知识
元学习基础
元学习核心思想
元学习( Meta-Learning)的核心思想是"学会如何学习"( Learning to
Learn)。在推荐系统的冷启动场景中,元学习的目标是让模型能够快速适应新用户或新物品,只需少量样本就能做出准确预测。
形式化定义 :给定任务分布
其中
Few-Shot Learning 与推荐系统
Few-Shot
Learning(少样本学习)是元学习的一个重要分支,特别适合解决推荐系统的冷启动问题。
Few-Shot 推荐问题 :给定新用户
关键挑战 : 1. 样本量极小 :只有 1-5
个样本,不足以训练传统模型 2.
泛化能力要求高 :需要从少量样本中学习用户偏好模式 3.
快速适应 :模型需要快速适应新用户,不能进行长时间训练
MAML:模型无关的元学习
Model-Agnostic Meta-Learning (MAML)
是最经典的元学习算法之一,其核心思想是通过梯度下降学习一个良好的参数初始化,使得模型只需少量梯度更新就能适应新任务。
算法流程 :
初始化参数 :随机初始化模型参数元训练阶段 :
从任务分布中采样一批任务
对每个任务
在查询集
元梯度更新:
元测试阶段 :
给定新任务
数学形式化 :
Prototypical Networks
Prototypical Networks 通过为每个类别学习一个原型(
Prototype)来表示,新样本通过计算与各原型的距离进行分类。
核心思想 :对于每个类别
其中
预测 :对于查询样本
其中
Few-Shot 推荐系统实现
问题建模
在推荐系统的 Few-Shot
场景中,我们将每个用户视为一个任务。对于用户
任务定义 : - 任务 :为用户支持集 :查询集 :Extra close brace or missing open brace Q_u = \{i_{k+1}, i_{k+2}, \dots, i_{k+n}}
基于 MAML 的推荐系统
代码目的: 实现基于 MAML( Model-Agnostic
Meta-Learning)的 Few-Shot 推荐系统,解决用户冷启动问题。 MAML
通过学习一个良好的参数初始化,使得模型只需在少量样本( 1-5
个交互记录)上进行少量梯度更新就能快速适应新用户,从而为新用户提供个性化推荐。
整体思路: 1.
双网络架构 :用户嵌入网络和物品嵌入网络分别将用户特征和物品特征映射到共享的嵌入空间
2. 评分预测网络 :基于用户和物品嵌入预测评分 3.
元训练过程 : -
内层循环:在每个用户的支持集(少量历史交互)上进行快速适应( 1-5
步梯度更新) -
外层循环:在查询集上评估适应后的模型,通过元梯度更新优化初始参数 4.
快速适应机制 :新用户只需提供少量交互记录,模型就能快速适应并做出准确预测
关键创新点: -
通过元学习学习一个"可快速适应"的参数初始化 - 内层学习率(
inner_lr)控制快速适应的步长 - 外层学习率(
meta_lr)控制元学习的收敛速度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 import torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import Dataset, DataLoaderimport numpy as npfrom collections import defaultdictclass UserEmbedding (nn.Module): """用户嵌入网络""" def __init__ (self, user_dim, hidden_dim, item_dim ): super (UserEmbedding, self).__init__() self.fc1 = nn.Linear(user_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, item_dim) self.relu = nn.ReLU() def forward (self, x ): x = self.relu(self.fc1(x)) x = self.relu(self.fc2(x)) x = self.fc3(x) return x class ItemEmbedding (nn.Module): """物品嵌入网络""" def __init__ (self, item_dim, hidden_dim, embed_dim ): super (ItemEmbedding, self).__init__() self.fc1 = nn.Linear(item_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, embed_dim) self.relu = nn.ReLU() def forward (self, x ): x = self.relu(self.fc1(x)) x = self.fc2(x) return x class RatingPredictor (nn.Module): """评分预测网络""" def __init__ (self, embed_dim, hidden_dim ): super (RatingPredictor, self).__init__() self.fc1 = nn.Linear(embed_dim * 2 , hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, 1 ) self.relu = nn.ReLU() def forward (self, user_embed, item_embed ): x = torch.cat([user_embed, item_embed], dim=-1 ) x = self.relu(self.fc1(x)) x = self.relu(self.fc2(x)) x = self.fc3(x) return x.squeeze(-1 ) class MAMLRecommender (nn.Module): """基于 MAML 的推荐系统""" def __init__ (self, user_dim, item_dim, hidden_dim=64 , embed_dim=32 ): super (MAMLRecommender, self).__init__() self.user_embedding = UserEmbedding(user_dim, hidden_dim, embed_dim) self.item_embedding = ItemEmbedding(item_dim, hidden_dim, embed_dim) self.predictor = RatingPredictor(embed_dim, hidden_dim) def forward (self, user_features, item_features ): user_embed = self.user_embedding(user_features) item_embed = self.item_embedding(item_features) rating = self.predictor(user_embed, item_embed) return rating def predict_rating (self, user_features, item_features ): """预测评分""" with torch.no_grad(): return self.forward(user_features, item_features) class MAMLTrainer : """MAML 训练器""" def __init__ (self, model, inner_lr=0.01 , meta_lr=0.001 ): self.model = model self.inner_lr = inner_lr self.meta_lr = meta_lr self.meta_optimizer = optim.Adam(model.parameters(), lr=meta_lr) def compute_loss (self, user_features, item_features, ratings ): """计算损失""" pred_ratings = self.model(user_features, item_features) loss = nn.MSELoss()(pred_ratings, ratings) return loss def fast_adapt (self, support_set, num_steps=1 ): """快速适应:在支持集上进行少量梯度更新""" fast_weights = list (self.model.parameters()) user_features = support_set['user_features' ] item_features = support_set['item_features' ] ratings = support_set['ratings' ] for step in range (num_steps): pred_ratings = self.model(user_features, item_features) loss = nn.MSELoss()(pred_ratings, ratings) grads = torch.autograd.grad(loss, self.model.parameters(), create_graph=True ) fast_weights = [w - self.inner_lr * g for w, g in zip (fast_weights, grads)] for param, new_param in zip (self.model.parameters(), fast_weights): param.data = new_param.data return fast_weights def meta_train_step (self, tasks, num_inner_steps=1 ): """元训练一步""" total_loss = 0 for task in tasks: support_set = task['support' ] query_set = task['query' ] original_params = [p.clone() for p in self.model.parameters()] self.fast_adapt(support_set, num_inner_steps) query_user_features = query_set['user_features' ] query_item_features = query_set['item_features' ] query_ratings = query_set['ratings' ] query_pred = self.model(query_user_features, query_item_features) query_loss = nn.MSELoss()(query_pred, query_ratings) total_loss += query_loss for param, orig_param in zip (self.model.parameters(), original_params): param.data = orig_param.data self.meta_optimizer.zero_grad() total_loss.backward() self.meta_optimizer.step() return total_loss.item() / len (tasks)
代码执行后的关键发现:
快速适应能力 : MAML 模型能够在 1-5
个样本上快速适应新用户,相比传统方法(需要大量数据)有显著优势泛化性能 :通过元训练学习到的参数初始化具有良好的泛化能力,能够快速适应未见过的用户训练效率 :虽然元训练过程较慢(需要模拟快速适应过程),但推理时只需少量梯度更新,非常高效
如何在实际系统中使用:
元训练阶段 :使用历史用户数据构建大量 Few-Shot
任务,进行元训练新用户推荐 :当新用户注册时,收集其初始交互(如浏览、点击),作为支持集快速适应 :在支持集上进行 1-5
步梯度更新,快速适应新用户推荐生成 :使用适应后的模型预测用户对所有候选物品的评分,生成推荐列表
基于 Prototypical
Networks 的推荐系统
代码目的: 实现基于原型网络( Prototypical
Networks)的 Few-Shot 推荐系统。原型网络通过为每个用户学习一个"原型"(
prototype)来表示用户偏好,新用户通过计算与各原型的相似度进行分类和推荐。这种方法特别适合用户冷启动场景,能够从少量样本中快速学习用户偏好模式。
整体思路: 1.
原型计算 :对于每个用户,基于其支持集(少量历史交互)计算用户原型(所有交互物品嵌入的平均值)
2.
距离度量 :计算查询物品与各用户原型的距离(通常使用欧氏距离或余弦相似度)
3. 概率预测 :使用 softmax
将距离转换为概率分布,预测用户对物品的偏好 4.
快速推理 :新用户只需提供少量交互记录,就能快速计算其原型并生成推荐
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class PrototypicalRecommender (nn.Module): """基于原型网络的推荐系统""" def __init__ (self, user_dim, item_dim, hidden_dim=64 , embed_dim=32 ): super (PrototypicalRecommender, self).__init__() self.user_embedding = UserEmbedding(user_dim, hidden_dim, embed_dim) self.item_embedding = ItemEmbedding(item_dim, hidden_dim, embed_dim) self.embed_dim = embed_dim def compute_prototype (self, user_features, item_features, ratings ): """计算用户原型(基于支持集的物品)""" user_embed = self.user_embedding(user_features) item_embeds = self.item_embedding(item_features) ratings_normalized = torch.softmax(ratings, dim=0 ) prototype = torch.sum (ratings_normalized.unsqueeze(-1 ) * item_embeds, dim=0 ) return prototype def predict_rating (self, user_features, support_items, support_ratings, query_items ): """预测查询物品的评分""" prototype = self.compute_prototype( user_features, support_items, support_ratings ) query_item_embeds = self.item_embedding(query_items) distances = -torch.norm(query_item_embeds - prototype.unsqueeze(0 ), dim=1 ) ratings = torch.sigmoid(distances) * 5.0 return ratings
数据准备与训练流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 class FewShotDataset (Dataset ): """Few-Shot 推荐数据集""" def __init__ (self, interactions, user_features, item_features, num_support=5 , num_query=10 ): self.interactions = interactions self.user_features = user_features self.item_features = item_features self.num_support = num_support self.num_query = num_query self.user_interactions = defaultdict(list ) for user_id, item_id, rating in interactions: self.user_interactions[user_id].append((item_id, rating)) def __len__ (self ): return len (self.user_interactions) def __getitem__ (self, idx ): user_id = list (self.user_interactions.keys())[idx] interactions = self.user_interactions[user_id] np.random.shuffle(interactions) support = interactions[:self.num_support] query = interactions[self.num_support:self.num_support + self.num_query] user_feat = torch.FloatTensor(self.user_features[user_id]) support_items = torch.FloatTensor([ self.item_features[item_id] for item_id, _ in support ]) support_ratings = torch.FloatTensor([rating for _, rating in support]) query_items = torch.FloatTensor([ self.item_features[item_id] for item_id, _ in query ]) query_ratings = torch.FloatTensor([rating for _, rating in query]) return { 'user_id' : user_id, 'user_features' : user_feat, 'support' : { 'item_features' : support_items, 'ratings' : support_ratings, 'user_features' : user_feat.unsqueeze(0 ).repeat(len (support), 1 ) }, 'query' : { 'item_features' : query_items, 'ratings' : query_ratings, 'user_features' : user_feat.unsqueeze(0 ).repeat(len (query), 1 ) } } def train_maml_recommender (model, train_loader, num_epochs=100 , num_inner_steps=1 ): """训练 MAML 推荐系统""" trainer = MAMLTrainer(model, inner_lr=0.01 , meta_lr=0.001 ) for epoch in range (num_epochs): epoch_loss = 0 num_batches = 0 for batch in train_loader: tasks = [] for i in range (len (batch['user_id' ])): tasks.append({ 'support' : { 'user_features' : batch['support' ]['user_features' ][i], 'item_features' : batch['support' ]['item_features' ][i], 'ratings' : batch['support' ]['ratings' ][i] }, 'query' : { 'user_features' : batch['query' ]['user_features' ][i], 'item_features' : batch['query' ]['item_features' ][i], 'ratings' : batch['query' ]['ratings' ][i] } }) loss = trainer.meta_train_step(tasks, num_inner_steps) epoch_loss += loss num_batches += 1 if (epoch + 1 ) % 10 == 0 : print (f'Epoch {epoch+1 } /{num_epochs} , Loss: {epoch_loss/num_batches:.4 f} ' ) return model
基于优化的 Meta-Learner 通过学习优化算法本身来快速适应新任务。 MAML
就是典型的基于优化的方法。
核心组件 : 1.
基础模型 :用于特征提取和预测的神经网络 2.
优化器学习 :学习如何快速更新参数 3.
元优化器 :用于更新元参数的优化器
基于度量的 Meta-Learner 通过学习合适的距离度量来进行预测。
Prototypical Networks 和 Matching Networks 都属于这一类。
核心思想 :学习一个嵌入空间,使得同类样本距离近,异类样本距离远。
基于模型的 Meta-Learner
使用特殊的模型架构(如记忆网络、注意力机制)来快速适应新任务。
示例: Matching Networks
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class MatchingNetwork (nn.Module): """匹配网络:使用注意力机制进行 Few-Shot 学习""" def __init__ (self, user_dim, item_dim, hidden_dim=64 , embed_dim=32 ): super (MatchingNetwork, self).__init__() self.user_embedding = UserEmbedding(user_dim, hidden_dim, embed_dim) self.item_embedding = ItemEmbedding(item_dim, hidden_dim, embed_dim) self.attention = nn.MultiheadAttention(embed_dim, num_heads=4 ) def forward (self, user_features, support_items, support_ratings, query_items ): """使用注意力机制匹配查询物品和支持集""" user_embed = self.user_embedding(user_features) support_embeds = self.item_embedding(support_items) query_embeds = self.item_embedding(query_items) query_with_user = query_embeds + user_embed.unsqueeze(0 ) attn_output, attn_weights = self.attention( query_with_user.unsqueeze(0 ), support_embeds.unsqueeze(0 ), support_embeds.unsqueeze(0 ) ) attn_weights = attn_weights.squeeze(0 ) ratings = torch.matmul(attn_weights, support_ratings.unsqueeze(-1 )).squeeze(-1 ) return ratings
Mecos:序列元学习推荐系统
Mecos( Meta-Learning for Cold-Start
Recommendation)是一种专门针对推荐系统冷启动问题设计的序列元学习方法。
Mecos 核心思想
Mecos
将推荐问题建模为序列预测任务,使用元学习来快速适应新用户。其核心创新在于:
序列建模 :将用户的历史交互序列建模为时间序列元学习框架 :使用 MAML 学习快速适应新用户注意力机制 :使用注意力机制捕捉用户兴趣的演化
Mecos 架构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 class SequenceEncoder (nn.Module): """序列编码器:编码用户交互序列""" def __init__ (self, item_dim, hidden_dim=64 , num_layers=2 ): super (SequenceEncoder, self).__init__() self.item_embedding = ItemEmbedding(item_dim, hidden_dim, hidden_dim) self.lstm = nn.LSTM(hidden_dim, hidden_dim, num_layers, batch_first=True ) self.attention = nn.MultiheadAttention(hidden_dim, num_heads=4 ) def forward (self, item_sequence ): """编码物品序列""" item_embeds = self.item_embedding(item_sequence) lstm_out, (h_n, c_n) = self.lstm(item_embeds) attn_out, _ = self.attention( lstm_out.transpose(0 , 1 ), lstm_out.transpose(0 , 1 ), lstm_out.transpose(0 , 1 ) ) user_embedding = attn_out[-1 ].transpose(0 , 1 ) return user_embedding class MecosRecommender (nn.Module): """Mecos 推荐系统""" def __init__ (self, item_dim, hidden_dim=64 , embed_dim=32 ): super (MecosRecommender, self).__init__() self.sequence_encoder = SequenceEncoder(item_dim, hidden_dim) self.item_embedding = ItemEmbedding(item_dim, hidden_dim, embed_dim) self.predictor = RatingPredictor(hidden_dim, embed_dim) def forward (self, user_sequence, item_features ): """预测评分""" user_embed = self.sequence_encoder(user_sequence) item_embed = self.item_embedding(item_features) rating = self.predictor(user_embed, item_embed) return rating def predict_for_new_user (self, support_sequence, query_items ): """为新用户预测( Few-Shot)""" support_sequence = support_sequence.unsqueeze(0 ) user_embed = self.sequence_encoder(support_sequence) user_embed = user_embed.squeeze(0 ) query_item_embeds = self.item_embedding(query_items) ratings = self.predictor( user_embed.unsqueeze(0 ).repeat(len (query_items), 1 ), query_item_embeds ) return ratings
Mecos 训练流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 class MecosTrainer : """Mecos 训练器""" def __init__ (self, model, inner_lr=0.01 , meta_lr=0.001 ): self.model = model self.inner_lr = inner_lr self.meta_lr = meta_lr self.meta_optimizer = optim.Adam(model.parameters(), lr=meta_lr) def fast_adapt_sequence (self, support_sequence, support_ratings, num_steps=1 ): """基于序列的快速适应""" fast_weights = list (self.model.parameters()) for step in range (num_steps): pred_ratings = self.model(support_sequence, support_sequence) loss = nn.MSELoss()(pred_ratings, support_ratings) grads = torch.autograd.grad(loss, self.model.parameters(), create_graph=True ) fast_weights = [w - self.inner_lr * g for w, g in zip (fast_weights, grads)] for param, new_param in zip (self.model.parameters(), fast_weights): param.data = new_param.data return fast_weights def meta_train_step (self, tasks, num_inner_steps=1 ): """元训练一步""" total_loss = 0 for task in tasks: support_sequence = task['support' ]['sequence' ] support_ratings = task['support' ]['ratings' ] query_sequence = task['query' ]['sequence' ] query_ratings = task['query' ]['ratings' ] original_params = [p.clone() for p in self.model.parameters()] self.fast_adapt_sequence(support_sequence, support_ratings, num_inner_steps) query_pred = self.model(query_sequence, query_sequence) query_loss = nn.MSELoss()(query_pred, query_ratings) total_loss += query_loss for param, orig_param in zip (self.model.parameters(), original_params): param.data = orig_param.data self.meta_optimizer.zero_grad() total_loss.backward() self.meta_optimizer.step() return total_loss.item() / len (tasks)
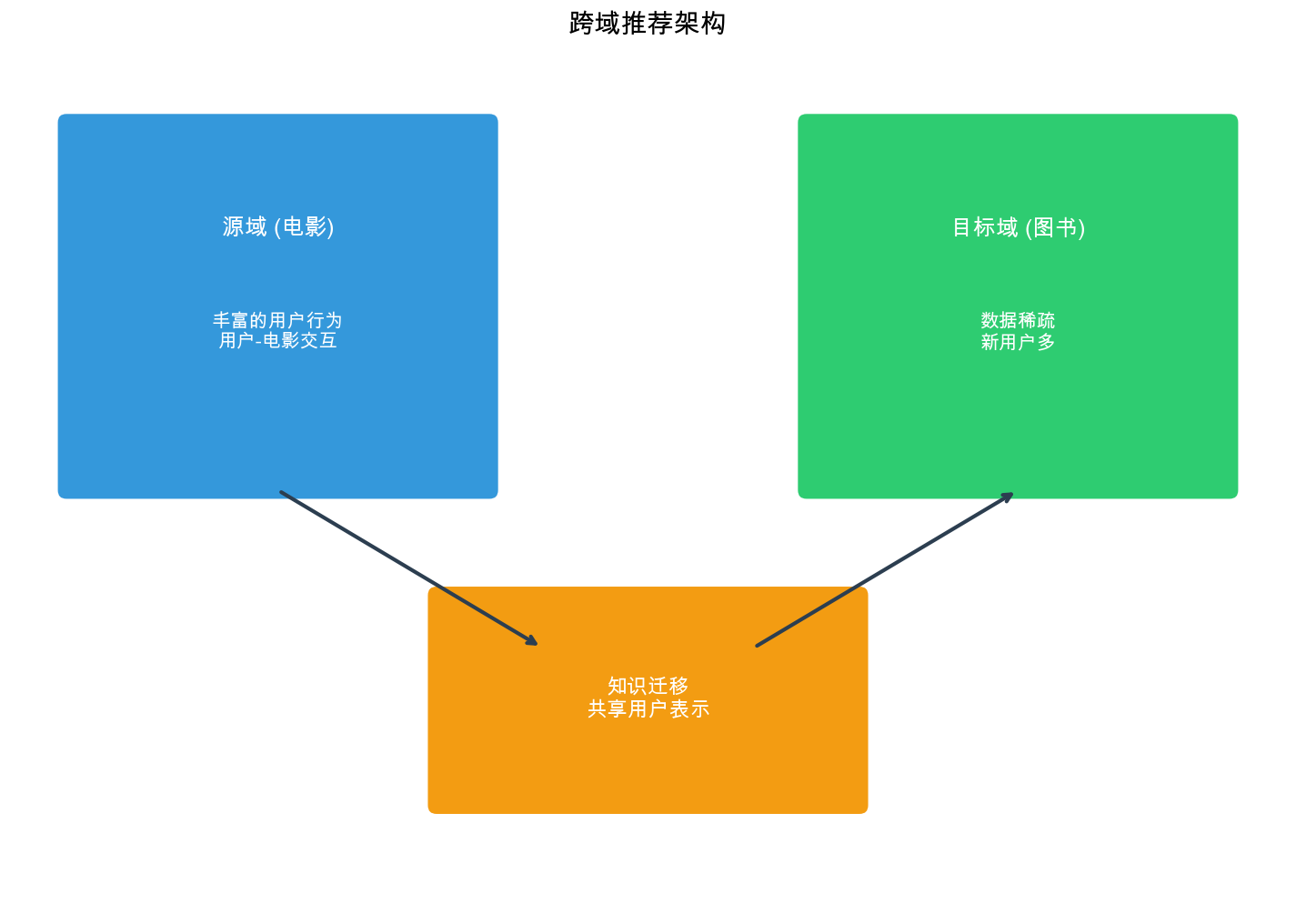
跨域推荐框架
跨域推荐问题定义
跨域推荐( Cross-Domain Recommendation)是指利用源域( Source
Domain)的丰富数据来帮助目标域( Target
Domain)的推荐任务,特别是当目标域数据稀疏或存在冷启动问题时。
形式化定义 : - 源域 :目标域 :目标 :利用
跨域推荐场景分类
用户重叠场景 :
物品重叠场景 :
完全无重叠场景 :
跨域推荐方法分类
1. 基于共享表示的方法
通过学习源域和目标域的共享表示空间,实现知识迁移。
代码目的:
实现基于共享嵌入的跨域推荐系统,通过学习源域和目标域的共享表示空间来实现知识迁移。当目标域数据稀疏时,可以利用源域的丰富数据来提升推荐性能。
整体思路: 1.
双域嵌入 :分别为源域和目标域定义独立的用户和物品嵌入层
2.
共享映射 :通过共享映射层将各域的嵌入映射到共享的表示空间
3. 统一预测 :在共享空间中进行评分预测,实现跨域知识共享
4.
联合训练 :同时优化源域和目标域的损失,学习共享表示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class SharedEmbeddingCrossDomain (nn.Module): """基于共享嵌入的跨域推荐""" def __init__ (self, num_users_s, num_items_s, num_users_t, num_items_t, embed_dim=32 , shared_dim=16 ): super (SharedEmbeddingCrossDomain, self).__init__() self.user_embed_s = nn.Embedding(num_users_s, embed_dim) self.item_embed_s = nn.Embedding(num_items_s, embed_dim) self.user_embed_t = nn.Embedding(num_users_t, embed_dim) self.item_embed_t = nn.Embedding(num_items_t, embed_dim) self.user_shared = nn.Linear(embed_dim, shared_dim) self.item_shared = nn.Linear(embed_dim, shared_dim) self.predictor = nn.Linear(shared_dim * 2 , 1 ) def forward (self, user_ids, item_ids, domain='target' ): """前向传播""" if domain == 'source' : user_emb = self.user_embed_s(user_ids) item_emb = self.item_embed_s(item_ids) else : user_emb = self.user_embed_t(user_ids) item_emb = self.item_embed_t(item_ids) user_shared = self.user_shared(user_emb) item_shared = self.item_shared(item_emb) concat = torch.cat([user_shared, item_shared], dim=-1 ) rating = self.predictor(concat).squeeze(-1 ) return rating
2. 基于映射的方法
学习源域和目标域之间的映射函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class MappingCrossDomain (nn.Module): """基于映射的跨域推荐""" def __init__ (self, embed_dim=32 ): super (MappingCrossDomain, self).__init__() self.embed_dim = embed_dim self.user_mapping = nn.Sequential( nn.Linear(embed_dim, embed_dim * 2 ), nn.ReLU(), nn.Linear(embed_dim * 2 , embed_dim) ) self.item_mapping = nn.Sequential( nn.Linear(embed_dim, embed_dim * 2 ), nn.ReLU(), nn.Linear(embed_dim * 2 , embed_dim) ) self.predictor = nn.Linear(embed_dim * 2 , 1 ) def map_source_to_target (self, source_user_emb, source_item_emb ): """将源域嵌入映射到目标域空间""" target_user_emb = self.user_mapping(source_user_emb) target_item_emb = self.item_mapping(source_item_emb) return target_user_emb, target_item_emb def forward (self, user_emb, item_emb, is_source=False ): """前向传播""" if is_source: user_emb, item_emb = self.map_source_to_target(user_emb, item_emb) concat = torch.cat([user_emb, item_emb], dim=-1 ) rating = self.predictor(concat).squeeze(-1 ) return rating
3. 基于对抗训练的方法
使用对抗训练来学习域不变的特征表示。
代码目的:
实现基于对抗训练的跨域推荐系统,通过域判别器和特征提取器之间的对抗训练,学习域不变的特征表示。这种方法能够有效消除域间的差异,实现更好的知识迁移。
整体思路: 1.
特征提取器 :提取用户-物品对的联合特征表示 2.
域判别器 :区分特征来自源域还是目标域 3.
对抗训练 :特征提取器试图欺骗域判别器(使特征域不变),域判别器试图正确分类域
4. 评分预测 :使用域不变的特征进行评分预测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class AdversarialCrossDomain (nn.Module): """基于对抗训练的跨域推荐""" def __init__ (self, embed_dim=32 ): super (AdversarialCrossDomain, self).__init__() self.embed_dim = embed_dim self.feature_extractor = nn.Sequential( nn.Linear(embed_dim * 2 , embed_dim), nn.ReLU(), nn.Linear(embed_dim, embed_dim) ) self.domain_discriminator = nn.Sequential( nn.Linear(embed_dim, embed_dim // 2 ), nn.ReLU(), nn.Linear(embed_dim // 2 , 1 ), nn.Sigmoid() ) self.rating_predictor = nn.Linear(embed_dim, 1 ) def forward (self, user_emb, item_emb ): """前向传播""" concat = torch.cat([user_emb, item_emb], dim=-1 ) features = self.feature_extractor(concat) rating = self.rating_predictor(features).squeeze(-1 ) domain_prob = self.domain_discriminator(features) return rating, domain_prob
迁移学习方法
迁移学习基础
迁移学习( Transfer
Learning)是跨域推荐的核心技术,其目标是将在一个任务上学到的知识应用到另一个相关任务上。
迁移学习分类 : 1.
归纳迁移 :源任务和目标任务不同但相关 2.
转导迁移 :源任务和目标任务相同,但数据分布不同 3.
无监督迁移 :源域和目标域都没有标签
特征迁移
特征迁移通过学习域不变的特征表示来实现知识迁移。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class FeatureTransfer (nn.Module): """特征迁移模型""" def __init__ (self, input_dim, shared_dim=64 , domain_specific_dim=32 ): super (FeatureTransfer, self).__init__() self.shared_encoder = nn.Sequential( nn.Linear(input_dim, shared_dim * 2 ), nn.ReLU(), nn.Linear(shared_dim * 2 , shared_dim) ) self.domain_specific_encoder = nn.Sequential( nn.Linear(input_dim, domain_specific_dim * 2 ), nn.ReLU(), nn.Linear(domain_specific_dim * 2 , domain_specific_dim) ) self.predictor = nn.Linear(shared_dim + domain_specific_dim, 1 ) def forward (self, x, use_shared=True ): """前向传播""" shared_features = self.shared_encoder(x) domain_features = self.domain_specific_encoder(x) if use_shared: combined = torch.cat([shared_features, domain_features], dim=-1 ) else : combined = domain_features rating = self.predictor(combined).squeeze(-1 ) return rating, shared_features
参数迁移
参数迁移通过共享模型参数或初始化参数来实现知识迁移。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class ParameterTransfer : """参数迁移工具类""" def __init__ (self ): pass @staticmethod def transfer_embeddings (source_model, target_model, overlap_users, overlap_items ): """迁移重叠用户和物品的嵌入""" if overlap_users: source_user_emb = source_model.user_embedding.weight[overlap_users] target_model.user_embedding.weight.data[overlap_users] = source_user_emb if overlap_items: source_item_emb = source_model.item_embedding.weight[overlap_items] target_model.item_embedding.weight.data[overlap_items] = source_item_emb @staticmethod def fine_tune_transfer (source_model, target_model, freeze_layers=None ): """微调迁移:冻结部分层""" target_model.load_state_dict(source_model.state_dict(), strict=False ) if freeze_layers: for name, param in target_model.named_parameters(): if any (layer in name for layer in freeze_layers): param.requires_grad = False
关系迁移
关系迁移通过迁移用户-物品关系模式来实现知识迁移。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class RelationTransfer (nn.Module): """关系迁移模型""" def __init__ (self, embed_dim=32 ): super (RelationTransfer, self).__init__() self.embed_dim = embed_dim self.relation_encoder = nn.Sequential( nn.Linear(embed_dim * 2 , embed_dim), nn.ReLU(), nn.Linear(embed_dim, embed_dim) ) self.relation_transfer = nn.Sequential( nn.Linear(embed_dim, embed_dim * 2 ), nn.ReLU(), nn.Linear(embed_dim * 2 , embed_dim) ) self.predictor = nn.Linear(embed_dim, 1 ) def encode_relation (self, user_emb, item_emb ): """编码用户-物品关系""" concat = torch.cat([user_emb, item_emb], dim=-1 ) relation = self.relation_encoder(concat) return relation def transfer_relation (self, source_relation ): """迁移关系表示""" transferred = self.relation_transfer(source_relation) return transferred def forward (self, user_emb, item_emb, is_transfer=False ): """前向传播""" relation = self.encode_relation(user_emb, item_emb) if is_transfer: relation = self.transfer_relation(relation) rating = self.predictor(relation).squeeze(-1 ) return rating
Zero-Shot Transfer
Zero-Shot Learning 基础
Zero-Shot
Learning(零样本学习)是指在没有目标域训练样本的情况下进行预测。在推荐系统中,
Zero-Shot Transfer
意味着利用源域的知识直接为目标域的新用户或新物品进行推荐。
基于属性的 Zero-Shot 推荐
代码目的:
实现基于属性的零样本推荐系统,在没有目标域训练样本的情况下,利用用户和物品的属性特征(如用户画像、物品描述)直接进行推荐。这对于完全冷启动的场景特别有用。
整体思路: 1.
属性编码 :将用户和物品的属性(如年龄、性别、类别、标签等)编码为嵌入向量
2.
语义映射 :将嵌入映射到语义空间,使得相似属性产生相似表示
3.
零样本预测 :基于属性生成的嵌入直接预测评分,无需训练数据
4.
泛化能力 :通过学习属性到评分的映射关系,能够处理未见过的用户-物品对
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class ZeroShotRecommender (nn.Module): """零样本推荐系统""" def __init__ (self, attribute_dim, embed_dim=32 ): super (ZeroShotRecommender, self).__init__() self.embed_dim = embed_dim self.attribute_encoder = nn.Sequential( nn.Linear(attribute_dim, embed_dim * 2 ), nn.ReLU(), nn.Linear(embed_dim * 2 , embed_dim) ) self.semantic_mapper = nn.Sequential( nn.Linear(embed_dim, embed_dim), nn.ReLU(), nn.Linear(embed_dim, embed_dim) ) self.predictor = nn.Linear(embed_dim * 2 , 1 ) def encode_from_attributes (self, attributes ): """从属性生成嵌入""" embed = self.attribute_encoder(attributes) semantic_embed = self.semantic_mapper(embed) return semantic_embed def forward (self, user_attributes, item_attributes ): """零样本预测""" user_embed = self.encode_from_attributes(user_attributes) item_embed = self.encode_from_attributes(item_attributes) concat = torch.cat([user_embed, item_embed], dim=-1 ) rating = self.predictor(concat).squeeze(-1 ) return rating
基于原型的 Zero-Shot 推荐
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class PrototypeZeroShot (nn.Module): """基于原型的零样本推荐""" def __init__ (self, embed_dim=32 ): super (PrototypeZeroShot, self).__init__() self.embed_dim = embed_dim self.prototype_network = nn.Sequential( nn.Linear(embed_dim, embed_dim * 2 ), nn.ReLU(), nn.Linear(embed_dim * 2 , embed_dim) ) def compute_prototype (self, embeddings, weights=None ): """计算原型""" if weights is not None : weights = weights.unsqueeze(-1 ) prototype = torch.sum (weights * embeddings, dim=0 ) / torch.sum (weights) else : prototype = torch.mean(embeddings, dim=0 ) return prototype def predict_by_prototype (self, query_embed, prototypes, prototype_ratings ): """基于原型预测""" similarities = [] for proto in prototypes: sim = torch.cosine_similarity(query_embed.unsqueeze(0 ), proto.unsqueeze(0 )) similarities.append(sim) similarities = torch.stack(similarities) weights = torch.softmax(similarities, dim=0 ) rating = torch.sum (weights * prototype_ratings) return rating
GNN 跨域迁移
图神经网络在跨域推荐中的应用
图神经网络( Graph Neural Networks,
GNN)天然适合建模推荐系统中的用户-物品交互关系。在跨域推荐中, GNN
可以学习域不变的结构模式。
基于 GNN 的跨域推荐架构
代码目的: 实现基于图神经网络(
GNN)的跨域推荐系统。 GNN
天然适合建模用户-物品交互关系,能够学习域不变的结构模式,实现跨域知识迁移。这种方法特别适合用户-物品交互图结构相似的场景。
整体思路: 1.
图结构建模 :将用户-物品交互建模为二部图,使用 GNN
学习节点表示 2. 共享 GNN 层 :源域和目标域共享 GNN
层,学习通用的结构模式 3.
域适配 :通过域适配器调整节点表示,适应不同域的特点 4.
跨域预测 :在统一的表示空间中进行评分预测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 import torch.nn.functional as Ffrom torch_geometric.nn import GCNConv, GATConv, SAGEConvclass CrossDomainGNN (nn.Module): """基于 GNN 的跨域推荐""" def __init__ (self, num_users_s, num_items_s, num_users_t, num_items_t, embed_dim=32 , hidden_dim=64 ): super (CrossDomainGNN, self).__init__() self.embed_dim = embed_dim self.user_embed_s = nn.Embedding(num_users_s, embed_dim) self.item_embed_s = nn.Embedding(num_items_s, embed_dim) self.user_embed_t = nn.Embedding(num_users_t, embed_dim) self.item_embed_t = nn.Embedding(num_items_t, embed_dim) self.gcn1 = GCNConv(embed_dim, hidden_dim) self.gcn2 = GCNConv(hidden_dim, embed_dim) self.domain_adapter = nn.Sequential( nn.Linear(embed_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, embed_dim) ) self.predictor = nn.Linear(embed_dim * 2 , 1 ) def forward_gnn (self, x, edge_index, domain='source' ): """GNN 前向传播""" x = F.relu(self.gcn1(x, edge_index)) x = self.gcn2(x, edge_index) return x def forward (self, user_ids, item_ids, edge_index, domain='target' ): """前向传播""" if domain == 'source' : user_emb = self.user_embed_s(user_ids) item_emb = self.item_embed_s(item_ids) else : user_emb = self.user_embed_t(user_ids) item_emb = self.item_embed_t(item_ids) x = torch.cat([user_emb, item_emb], dim=0 ) x_gnn = self.forward_gnn(x, edge_index, domain) if domain == 'target' : x_gnn = self.domain_adapter(x_gnn) num_users = len (user_ids) user_emb_final = x_gnn[:num_users] item_emb_final = x_gnn[num_users:] user_item_concat = torch.cat([ user_emb_final[user_ids], item_emb_final[item_ids] ], dim=-1 ) rating = self.predictor(user_item_concat).squeeze(-1 ) return rating
跨域 GNN 训练策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class CrossDomainGNNTrainer : """跨域 GNN 训练器""" def __init__ (self, model, lr=0.001 ): self.model = model self.optimizer = optim.Adam(model.parameters(), lr=lr) self.criterion = nn.MSELoss() def train_step (self, source_data, target_data, alpha=0.5 ): """训练一步(源域 + 目标域)""" self.optimizer.zero_grad() source_pred = self.model( source_data['user_ids' ], source_data['item_ids' ], source_data['edge_index' ], domain='source' ) source_loss = self.criterion(source_pred, source_data['ratings' ]) target_pred = self.model( target_data['user_ids' ], target_data['item_ids' ], target_data['edge_index' ], domain='target' ) target_loss = self.criterion(target_pred, target_data['ratings' ]) total_loss = alpha * source_loss + (1 - alpha) * target_loss total_loss.backward() self.optimizer.step() return { 'source_loss' : source_loss.item(), 'target_loss' : target_loss.item(), 'total_loss' : total_loss.item() }
Bootstrap 方法
Bootstrap 冷启动策略
Bootstrap
方法通过逐步积累数据来缓解冷启动问题。基本思路:利用初始的少量数据启动推荐系统,然后通过用户反馈不断改进。
基于内容的初始推荐
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 class ContentBasedBootstrap : """基于内容的 Bootstrap 推荐""" def __init__ (self, item_features, similarity_metric='cosine' ): self.item_features = item_features self.similarity_metric = similarity_metric self.user_profiles = {} def compute_similarity (self, item1_features, item2_features ): """计算物品相似度""" if self.similarity_metric == 'cosine' : return torch.cosine_similarity( item1_features.unsqueeze(0 ), item2_features.unsqueeze(0 ) ).item() elif self.similarity_metric == 'euclidean' : return 1 / (1 + torch.norm(item1_features - item2_features).item()) def update_user_profile (self, user_id, interacted_items, ratings ): """更新用户画像""" user_features = [] for item_id, rating in zip (interacted_items, ratings): item_feat = self.item_features[item_id] weighted_feat = item_feat * rating user_features.append(weighted_feat) if user_features: self.user_profiles[user_id] = torch.stack(user_features).mean(dim=0 ) def recommend (self, user_id, candidate_items, top_k=10 ): """为新用户推荐""" if user_id not in self.user_profiles: return self._cold_start_recommend(candidate_items, top_k) user_profile = self.user_profiles[user_id] scores = [] for item_id in candidate_items: item_feat = self.item_features[item_id] score = self.compute_similarity(user_profile, item_feat) scores.append((item_id, score)) scores.sort(key=lambda x: x[1 ], reverse=True ) return [item_id for item_id, _ in scores[:top_k]] def _cold_start_recommend (self, candidate_items, top_k ): """冷启动推荐策略""" import random return random.sample(candidate_items, min (top_k, len (candidate_items)))
混合 Bootstrap 策略
代码目的: 实现混合 Bootstrap
策略,结合内容推荐和协同过滤的优势,根据用户交互数量动态调整两种方法的权重。在冷启动阶段主要依赖内容推荐,随着数据积累逐渐转向协同过滤。
整体思路: 1.
双模型架构 :同时使用内容推荐模型和协同过滤模型 2.
动态权重调整 : - 冷启动(<5
个交互):主要依赖内容模型(权重 0.8) - 少量数据( 5-20
个交互):平衡两种模型(权重 0.5) - 充足数据(>20
个交互):主要依赖协同过滤(权重 0.2) 3.
混合评分 :对两种模型的预测结果进行加权平均 4.
在线更新 :随着用户交互增加,动态更新模型和权重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 class HybridBootstrap : """混合 Bootstrap 策略""" def __init__ (self, content_model, collaborative_model, alpha=0.5 ): self.content_model = content_model self.collaborative_model = collaborative_model self.alpha = alpha self.user_interaction_count = {} def recommend (self, user_id, candidate_items, top_k=10 ): """混合推荐""" interaction_count = self.user_interaction_count.get(user_id, 0 ) if interaction_count < 5 : content_weight = 0.8 elif interaction_count < 20 : content_weight = self.alpha else : content_weight = 1 - self.alpha content_scores = self.content_model.recommend( user_id, candidate_items, top_k=len (candidate_items) ) content_dict = {item: score for item, score in content_scores} if interaction_count > 0 : cf_scores = self.collaborative_model.recommend( user_id, candidate_items, top_k=len (candidate_items) ) cf_dict = {item: score for item, score in cf_scores} else : cf_dict = {} final_scores = {} for item in candidate_items: content_score = content_dict.get(item, 0 ) cf_score = cf_dict.get(item, 0 ) final_score = content_weight * content_score + (1 - content_weight) * cf_score final_scores[item] = final_score sorted_items = sorted (final_scores.items(), key=lambda x: x[1 ], reverse=True ) return [item for item, _ in sorted_items[:top_k]] def update (self, user_id, item_id, rating ): """更新模型""" self.user_interaction_count[user_id] = \ self.user_interaction_count.get(user_id, 0 ) + 1 self.content_model.update_user_profile(user_id, [item_id], [rating]) if self.user_interaction_count[user_id] > 1 : self.collaborative_model.update(user_id, item_id, rating)
完整代码实现示例
端到端 Few-Shot 推荐系统
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 import torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import Dataset, DataLoaderimport numpy as npfrom sklearn.metrics import mean_squared_error, mean_absolute_errorimport matplotlib.pyplot as pltclass CompleteFewShotRecommender : """完整的 Few-Shot 推荐系统""" def __init__ (self, user_dim, item_dim, embed_dim=32 , hidden_dim=64 ): self.model = MAMLRecommender(user_dim, item_dim, hidden_dim, embed_dim) self.trainer = MAMLTrainer(self.model, inner_lr=0.01 , meta_lr=0.001 ) def train (self, train_loader, num_epochs=100 , num_inner_steps=1 ): """训练模型""" self.model.train() for epoch in range (num_epochs): epoch_loss = 0 num_batches = 0 for batch in train_loader: tasks = self._batch_to_tasks(batch) loss = self.trainer.meta_train_step(tasks, num_inner_steps) epoch_loss += loss num_batches += 1 if (epoch + 1 ) % 10 == 0 : avg_loss = epoch_loss / num_batches print (f'Epoch {epoch+1 } /{num_epochs} , Loss: {avg_loss:.4 f} ' ) def _batch_to_tasks (self, batch ): """将批次转换为任务列表""" tasks = [] batch_size = len (batch['user_id' ]) for i in range (batch_size): tasks.append({ 'support' : { 'user_features' : batch['support' ]['user_features' ][i], 'item_features' : batch['support' ]['item_features' ][i], 'ratings' : batch['support' ]['ratings' ][i] }, 'query' : { 'user_features' : batch['query' ]['user_features' ][i], 'item_features' : batch['query' ]['item_features' ][i], 'ratings' : batch['query' ]['ratings' ][i] } }) return tasks def evaluate (self, test_loader, num_adapt_steps=5 ): """评估模型""" self.model.eval () all_preds = [] all_labels = [] with torch.no_grad(): for batch in test_loader: tasks = self._batch_to_tasks(batch) for task in tasks: support = task['support' ] query = task['query' ] original_params = [p.clone() for p in self.model.parameters()] for _ in range (num_adapt_steps): pred_support = self.model( support['user_features' ], support['item_features' ] ) loss = nn.MSELoss()(pred_support, support['ratings' ]) grads = torch.autograd.grad( loss, self.model.parameters(), retain_graph=True ) for param, grad in zip (self.model.parameters(), grads): param.data -= 0.01 * grad pred_query = self.model( query['user_features' ], query['item_features' ] ) all_preds.extend(pred_query.cpu().numpy()) all_labels.extend(query['ratings' ].cpu().numpy()) for param, orig_param in zip (self.model.parameters(), original_params): param.data = orig_param.data mse = mean_squared_error(all_labels, all_preds) mae = mean_absolute_error(all_labels, all_preds) rmse = np.sqrt(mse) return { 'MSE' : mse, 'MAE' : mae, 'RMSE' : rmse } def predict_for_new_user (self, user_features, candidate_items, support_items, support_ratings, num_adapt_steps=5 ): """为新用户预测""" self.model.eval () support_user_features = user_features.unsqueeze(0 ).repeat( len (support_items), 1 ) original_params = [p.clone() for p in self.model.parameters()] for _ in range (num_adapt_steps): pred_support = self.model(support_user_features, support_items) loss = nn.MSELoss()(pred_support, support_ratings) grads = torch.autograd.grad( loss, self.model.parameters(), retain_graph=True ) for param, grad in zip (self.model.parameters(), grads): param.data -= 0.01 * grad candidate_user_features = user_features.unsqueeze(0 ).repeat( len (candidate_items), 1 ) pred_ratings = self.model(candidate_user_features, candidate_items) for param, orig_param in zip (self.model.parameters(), original_params): param.data = orig_param.data return pred_ratings
跨域推荐完整实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 class CompleteCrossDomainRecommender : """完整的跨域推荐系统""" def __init__ (self, source_config, target_config, embed_dim=32 ): self.source_config = source_config self.target_config = target_config self.model = SharedEmbeddingCrossDomain( source_config['num_users' ], source_config['num_items' ], target_config['num_users' ], target_config['num_items' ], embed_dim=embed_dim ) self.optimizer = optim.Adam(self.model.parameters(), lr=0.001 ) self.criterion = nn.MSELoss() def train (self, source_loader, target_loader, num_epochs=100 , alpha=0.5 ): """训练跨域推荐模型""" self.model.train() for epoch in range (num_epochs): epoch_loss = 0 num_batches = 0 for source_batch, target_batch in zip (source_loader, target_loader): self.optimizer.zero_grad() source_pred = self.model( source_batch['user_ids' ], source_batch['item_ids' ], domain='source' ) source_loss = self.criterion(source_pred, source_batch['ratings' ]) target_pred = self.model( target_batch['user_ids' ], target_batch['item_ids' ], domain='target' ) target_loss = self.criterion(target_pred, target_batch['ratings' ]) total_loss = alpha * source_loss + (1 - alpha) * target_loss total_loss.backward() self.optimizer.step() epoch_loss += total_loss.item() num_batches += 1 if (epoch + 1 ) % 10 == 0 : avg_loss = epoch_loss / num_batches print (f'Epoch {epoch+1 } /{num_epochs} , Loss: {avg_loss:.4 f} ' ) def transfer_to_target (self, overlap_users=None , overlap_items=None ): """迁移知识到目标域""" if overlap_users is not None : source_user_emb = self.model.user_embed_s.weight[overlap_users] self.model.user_embed_t.weight.data[overlap_users] = source_user_emb if overlap_items is not None : source_item_emb = self.model.item_embed_s.weight[overlap_items] self.model.item_embed_t.weight.data[overlap_items] = source_item_emb def evaluate_target (self, test_loader ): """评估目标域性能""" self.model.eval () all_preds = [] all_labels = [] with torch.no_grad(): for batch in test_loader: pred = self.model( batch['user_ids' ], batch['item_ids' ], domain='target' ) all_preds.extend(pred.cpu().numpy()) all_labels.extend(batch['ratings' ].cpu().numpy()) mse = mean_squared_error(all_labels, all_preds) mae = mean_absolute_error(all_labels, all_preds) rmse = np.sqrt(mse) return { 'MSE' : mse, 'MAE' : mae, 'RMSE' : rmse }
实验与评估
评估指标
推荐系统的评估指标可以分为两类:准确性指标 和排序指标 。
准确性指标 : - MSE (Mean Squared
Error) :均方误差 - MAE (Mean Absolute
Error) :平均绝对误差 - RMSE (Root Mean Squared
Error) :均方根误差
排序指标 : - Precision@K :前 K
个推荐中相关物品的比例 - Recall@K :前 K
个推荐覆盖的相关物品比例 -
NDCG@K :归一化折损累积增益
实验设置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 def evaluate_recommender (model, test_data, k=10 ): """评估推荐系统""" precision_scores = [] recall_scores = [] ndcg_scores = [] for user_id, true_items in test_data.items(): recommended_items = model.recommend(user_id, k=k) precision = len (set (recommended_items) & set (true_items)) / k precision_scores.append(precision) recall = len (set (recommended_items) & set (true_items)) / len (true_items) recall_scores.append(recall) ndcg = compute_ndcg(recommended_items, true_items, k) ndcg_scores.append(ndcg) return { 'Precision@K' : np.mean(precision_scores), 'Recall@K' : np.mean(recall_scores), 'NDCG@K' : np.mean(ndcg_scores) } def compute_ndcg (recommended, relevant, k ): """计算 NDCG@K""" dcg = 0 for i, item in enumerate (recommended[:k]): if item in relevant: dcg += 1 / np.log2(i + 2 ) idcg = sum (1 / np.log2(i + 2 ) for i in range (min (len (relevant), k))) return dcg / idcg if idcg > 0 else 0
常见问题与解答
Q1:
冷启动问题中,用户冷启动和物品冷启动哪个更难解决?
A :
两者都有各自的挑战,但通常用户冷启动 被认为更难解决,原因如下:
数据获取难度 :新用户可能不愿意提供太多信息,而新物品通常有丰富的元数据(标题、描述、类别等)行为模式多样性 :用户兴趣变化大,难以从少量样本推断;物品特征相对稳定反馈循环 :物品可以通过初始推荐获得反馈并改进,而用户如果首次推荐不佳可能直接流失
解决方案 : -
用户冷启动 :依赖用户注册信息、设备信息、地理位置等辅助特征,结合热门物品推荐
-
物品冷启动 :充分利用内容特征,使用内容相似度推荐,结合用户画像匹配
Q2: MAML
和 Prototypical Networks 在推荐系统中如何选择?
A : 选择取决于具体场景:
MAML 适用于 : - 需要模型快速适应新任务的场景 -
任务之间存在一定的相似性 - 有足够的元训练任务数据 - 计算资源充足( MAML
需要二阶梯度)
Prototypical Networks 适用于 : -
任务可以清晰地划分为类别 - 需要快速推理(不需要梯度更新) - 计算资源有限
- 支持集样本数量固定
推荐系统中的应用 : - 用户冷启动 :
MAML 更适合,因为每个用户的偏好模式不同,需要快速适应 -
物品冷启动 : Prototypical Networks
可能更合适,因为物品可以按类别组织
Q3:
跨域推荐中,如何处理完全无重叠的场景?
A : 完全无重叠场景(
基于内容的迁移 :
利用用户/物品的内容特征(如用户画像、物品描述)
学习特征空间的映射关系
元学习 :
使用 MAML 等方法学习快速适应能力
从源域学习通用的推荐模式
知识蒸馏 :
将源域模型的知识蒸馏到目标域模型
即使域不同,推荐模式可能相似
对抗训练 :
代码示例 : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class NoOverlapCrossDomain (nn.Module): """无重叠跨域推荐""" def __init__ (self, feature_dim, embed_dim=32 ): super (NoOverlapCrossDomain, self).__init__() self.feature_encoder = nn.Sequential( nn.Linear(feature_dim, embed_dim * 2 ), nn.ReLU(), nn.Linear(embed_dim * 2 , embed_dim) ) self.domain_adapter = nn.Sequential( nn.Linear(embed_dim, embed_dim), nn.ReLU(), nn.Linear(embed_dim, embed_dim) ) self.predictor = nn.Linear(embed_dim * 2 , 1 ) def forward (self, user_features, item_features, domain='target' ): user_emb = self.feature_encoder(user_features) item_emb = self.feature_encoder(item_features) if domain == 'target' : user_emb = self.domain_adapter(user_emb) item_emb = self.domain_adapter(item_emb) concat = torch.cat([user_emb, item_emb], dim=-1 ) rating = self.predictor(concat).squeeze(-1 ) return rating
Q4: Few-Shot
推荐中,支持集大小如何选择?
A : 支持集大小的选择需要权衡多个因素:
影响因素 : 1.
数据可用性 :实际能获取多少用户交互数据 2.
模型复杂度 :复杂模型需要更多样本 3.
任务难度 :用户兴趣越复杂,需要越多样本
经验法则 : -
1-Shot :极端冷启动,仅依赖 1 个样本,需要强大的先验知识
- 3-5 Shot :常见设置,平衡了数据需求和性能 -
10+
Shot :数据充足时使用,性能更好但可能不再是"冷启动"
实验建议 : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def experiment_support_size (model, data, support_sizes=[1 , 3 , 5 , 10 ] ): """实验不同支持集大小的影响""" results = {} for k in support_sizes: dataset = FewShotDataset(data, num_support=k) loader = DataLoader(dataset, batch_size=32 ) model.train(loader, num_epochs=50 ) metrics = model.evaluate(test_loader) results[k] = metrics print (f'Support Size: {k} , Metrics: {metrics} ' ) return results
Q5: 元学习训练时间过长怎么办?
A : 元学习确实计算开销大,可以通过以下方法加速:
减少内层更新步数 :
MAML 中减少 num_inner_steps
通常 1-3 步就足够
一阶近似 :
使用 FOMAML( First-Order MAML)
忽略二阶梯度,只使用一阶梯度
任务采样 :
模型简化 :
FOMAML 实现 : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class FOMAMLTrainer (MAMLTrainer ): """一阶 MAML(更快但性能略低)""" def fast_adapt (self, support_set, num_steps=1 ): """快速适应(一阶近似)""" fast_weights = [] grads = [] user_features = support_set['user_features' ] item_features = support_set['item_features' ] ratings = support_set['ratings' ] pred_ratings = self.model(user_features, item_features) loss = nn.MSELoss()(pred_ratings, ratings) grads = torch.autograd.grad( loss, self.model.parameters(), create_graph=False ) fast_weights = [w - self.inner_lr * g for w, g in zip (self.model.parameters(), grads)] return fast_weights
Q6: 跨域推荐中如何选择源域?
A : 源域的选择对跨域推荐效果至关重要:
选择原则 : 1.
领域相关性 :源域和目标域应该相关但不完全相同 -
太相似:迁移价值有限 - 太不同:难以迁移知识
数据质量 :源域应该有高质量、充足的数据
用户/物品重叠 :有一定重叠有助于迁移
用户重叠:可以学习用户偏好模式
物品重叠:可以学习物品特征表示
示例场景 : - 电商 →
视频 :用户购买行为 → 观看偏好(中等相关) - 音乐 →
电影 :音乐偏好 → 电影偏好(高相关) - 新闻 →
商品 :阅读偏好 → 购买偏好(低相关,不推荐)
Q7: Bootstrap
方法中如何平衡探索和利用?
A : 探索( Exploration)和利用(
Exploitation)的平衡是 Bootstrap 方法的核心挑战:
探索 :推荐用户可能不熟悉但可能感兴趣的物品
利用 :推荐基于已知偏好的物品
策略 : 1.
UCB (Upper Confidence Bound) :
选择置信区间上界最高的物品
平衡期望收益和不确定性
Thompson Sampling :
代码实现 : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class ExplorationExploitation : """探索-利用平衡策略""" def __init__ (self, epsilon=0.1 , method='epsilon_greedy' ): self.epsilon = epsilon self.method = method self.item_counts = {} self.item_rewards = {} def select_item (self, candidate_items, predicted_scores ): """选择物品""" if self.method == 'epsilon_greedy' : if np.random.random() < self.epsilon: return np.random.choice(candidate_items) else : return candidate_items[np.argmax(predicted_scores)] elif self.method == 'ucb' : ucb_scores = [] for item, score in zip (candidate_items, predicted_scores): count = self.item_counts.get(item, 1 ) uncertainty = np.sqrt(2 * np.log(sum (self.item_counts.values()) + 1 ) / count) ucb_score = score + uncertainty ucb_scores.append(ucb_score) return candidate_items[np.argmax(ucb_scores)] def update (self, item, reward ): """更新统计信息""" self.item_counts[item] = self.item_counts.get(item, 0 ) + 1 if item not in self.item_rewards: self.item_rewards[item] = [] self.item_rewards[item].append(reward)
Q8: GNN
在跨域推荐中的优势是什么?
A : GNN 在跨域推荐中的优势主要体现在:
结构信息利用 :
域不变模式 :
可扩展性 :
示例 :
Q9: Zero-Shot Transfer
在实际应用中可行吗?
A : Zero-Shot Transfer
在特定场景下是可行的,但需要满足条件:
可行条件 : 1.
丰富的属性信息 :用户/物品有足够的元数据 2.
语义空间映射 :能够建立属性到嵌入的映射 3.
领域相关性 :源域和目标域在语义上相关
应用场景 : -
新品类推荐 :利用物品属性(颜色、风格、材质等) -
新用户推荐 :利用用户注册信息(年龄、性别、地区等) -
跨平台推荐 :不同平台但用户属性相似
局限性 : - 属性信息不足时效果差 -
需要精心设计的属性体系 - 可能不如有少量样本的 Few-Shot 方法
Q10:
如何评估冷启动推荐系统的效果?
A : 冷启动推荐系统的评估需要特殊考虑:
评估设置 : 1.
时间分割 :按时间顺序分割数据 - 训练集:历史数据 -
测试集:新用户/新物品的数据
留一法 :模拟冷启动
为每个用户只保留 1-5 个交互作为"历史"
其余作为测试集
评估指标 : -
冷启动准确率 :新用户/新物品的推荐准确率 -
首推成功率 :首次推荐被用户接受的比例 -
留存率 :冷启动用户的使用留存率
代码示例 : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 def evaluate_cold_start (model, test_users, test_data ): """评估冷启动性能""" results = { 'cold_start_users' : 0 , 'first_recommendation_success' : 0 , 'precision_at_k' : [], 'recall_at_k' : [] } for user_id in test_users: if user_id not in model.user_interaction_count: results['cold_start_users' ] += 1 recommendations = model.recommend(user_id, k=10 ) if recommendations and recommendations[0 ] in test_data[user_id]: results['first_recommendation_success' ] += 1 true_items = set (test_data[user_id]) recommended_items = set (recommendations) precision = len (true_items & recommended_items) / len (recommended_items) recall = len (true_items & recommended_items) / len (true_items) results['precision_at_k' ].append(precision) results['recall_at_k' ].append(recall) results['avg_precision' ] = np.mean(results['precision_at_k' ]) results['avg_recall' ] = np.mean(results['recall_at_k' ]) results['first_success_rate' ] = \ results['first_recommendation_success' ] / results['cold_start_users' ] return results
总结
本文深入探讨了推荐系统中的冷启动问题和跨域推荐解决方案。主要内容包括:
冷启动问题分类 :用户冷启动、物品冷启动、系统冷启动,每种都有其独特的挑战元学习基础 : MAML 、 Prototypical Networks
等经典方法Few-Shot 推荐 :利用少量样本快速适应新用户跨域推荐 :通过知识迁移解决数据稀疏问题迁移学习 :特征迁移、参数迁移、关系迁移Zero-Shot
Transfer :在完全没有目标域数据的情况下进行推荐GNN 跨域迁移 :利用图结构信息进行知识迁移Bootstrap 方法 :通过逐步积累数据缓解冷启动
这些方法各有优势,在实际应用中需要根据具体场景选择合适的方案。未来,随着深度学习和大模型技术的发展,冷启动推荐系统将会有更多突破。