推荐系统从实验室走向生产环境,面临的是完全不同的挑战。单机训练、离线评估的模型在真实流量面前往往不堪一击。工业级推荐系统需要处理每秒百万级的请求、毫秒级的响应延迟、实时特征更新、
A/B
测试分流、模型热更新、异常监控等复杂问题。本文将深入探讨工业推荐系统的完整架构设计,从召回、粗排、精排到重排序的每一层,结合阿里巴巴
EasyRec 、字节跳动 LONGER 等业界最佳实践,提供可落地的工程方案。
工业推荐系统全景
系统架构概览
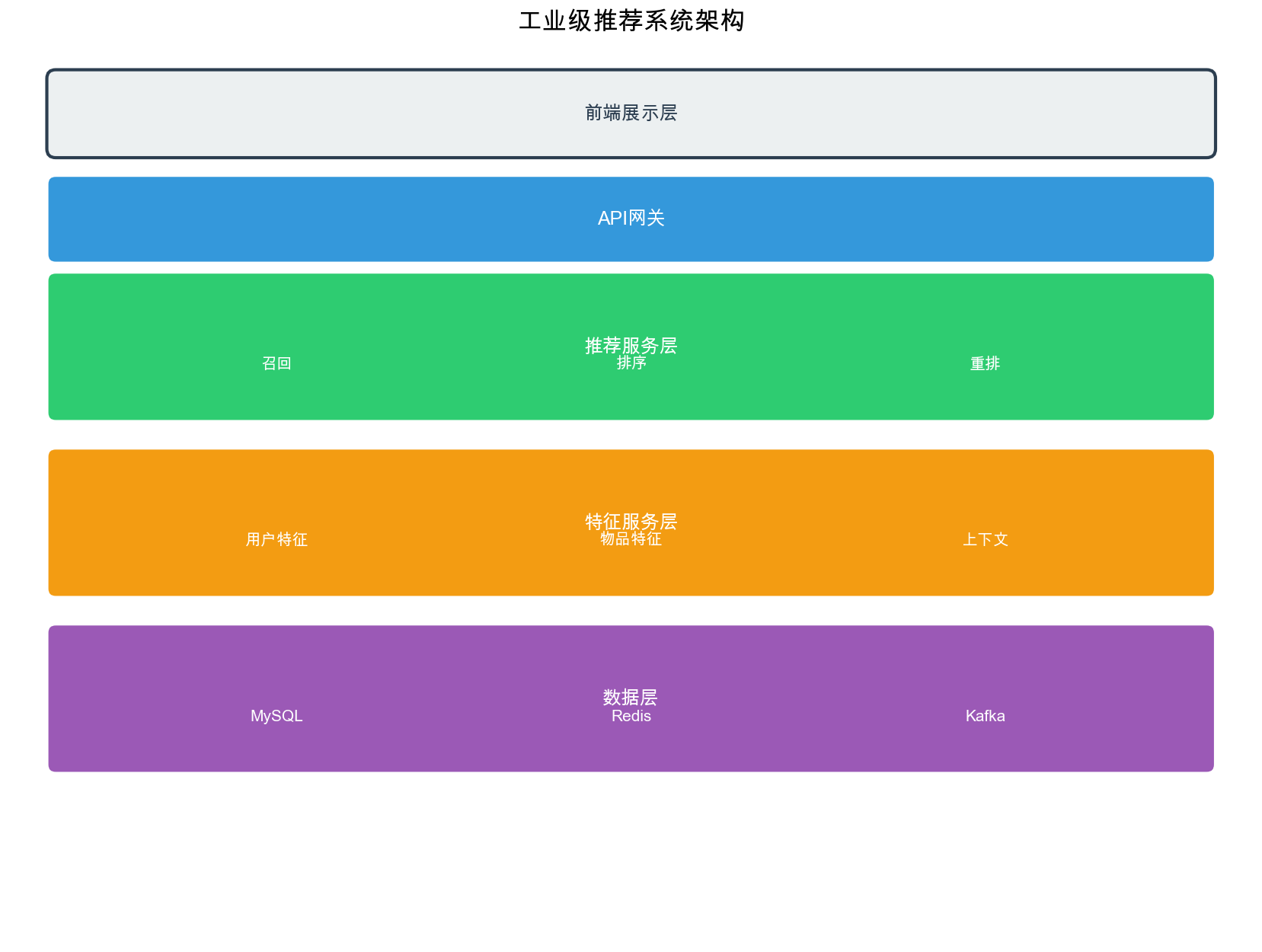
工业级推荐系统通常采用分层漏斗架构,从海量候选集中逐步筛选出最相关的物品。典型的架构包含以下层次:
- 召回层(
Recall):从百万级候选集中快速召回数千个相关物品
- 粗排层( Coarse
Ranking):对召回结果进行初步排序,筛选出数百个候选
- 精排层( Fine
Ranking):使用复杂模型对候选进行精确打分
- 重排序层(
Re-ranking):考虑多样性、新颖性、业务规则等因素进行最终调整
代码目的:
实现工业级推荐系统的主流程,展示分层漏斗架构的完整实现。工业级推荐系统通过多阶段逐步筛选,在保证推荐质量的同时满足毫秒级响应要求。
整体思路: 1.
召回层:从百万级候选集中快速召回数千个相关物品,使用多种召回策略(协同过滤、内容、热门等)
2.
粗排层:使用轻量级模型快速筛选到数百个候选,平衡准确性和效率
3.
精排层:使用复杂模型精确打分,考虑用户特征、物品特征、上下文等
4.
重排序层:考虑多样性、新颖性、业务规则等因素进行最终调整
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| class IndustrialRecommendationSystem:
"""工业级推荐系统主流程"""
def __init__(self):
self.recall_engine = MultiChannelRecall()
self.coarse_ranker = CoarseRanker()
self.fine_ranker = FineRanker()
self.re_ranker = ReRanker()
self.feature_service = FeatureService()
def recommend(self, user_id, context=None):
"""推荐主流程"""
recall_items = self.recall_engine.recall(user_id, top_k=5000)
coarse_items = self.coarse_ranker.rank(
recall_items, user_id, top_k=500
)
fine_items = self.fine_ranker.rank(
coarse_items, user_id, context, top_k=100
)
final_items = self.re_ranker.re_rank(
fine_items, user_id, top_k=20
)
return final_items
|
性能指标与 SLA
工业系统需要明确的性能指标:
- QPS(每秒查询数):通常需要支持 10K+ QPS
- P99 延迟:召回层 < 50ms,粗排 < 20ms,精排
< 100ms
- 可用性: 99.9%+ 可用性,故障自动降级
- 吞吐量:支持峰值流量 3-5 倍扩容
代码目的:
实现性能监控系统,实时监控推荐系统各阶段的延迟指标,确保满足 SLA
要求。工业级系统需要持续监控 P99 延迟、 QPS
等关键指标,及时发现性能问题。
整体思路: 1.
延迟记录:记录召回、粗排、精排、总延迟等各阶段的耗时 2.
P99 监控:计算 P99 延迟,及时发现性能瓶颈 3.
告警机制:当延迟超过阈值时触发告警,支持自动降级
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| class PerformanceMonitor:
"""性能监控"""
def __init__(self):
self.metrics = {
'recall_latency': [],
'coarse_latency': [],
'fine_latency': [],
'total_latency': []
}
def record_latency(self, stage, latency_ms):
"""记录延迟"""
self.metrics[f'{stage}_latency'].append(latency_ms)
if stage == 'total':
p99 = np.percentile(self.metrics['total_latency'], 99)
if p99 > 200:
self.alert(f'P99 latency exceeds threshold: {p99}ms')
|
召回层设计:多路召回策略
召回层是推荐系统的第一道防线,需要在极短时间内从百万级候选集中找出数千个相关物品。单一召回策略往往无法覆盖所有场景,因此工业系统普遍采用多路召回策略。
协同过滤召回
协同过滤( Collaborative
Filtering)是最经典的召回方法,包括用户协同过滤(
UserCF)和物品协同过滤( ItemCF)。
用户协同过滤( UserCF)
UserCF 基于"相似用户喜欢相似物品"的假设:
其中表示用户交互过的物品集合。
代码目的: 实现用户协同过滤(
UserCF)召回算法,基于"相似用户喜欢相似物品"的假设,从百万级候选集中快速召回相关物品。
UserCF 是工业级推荐系统中最常用的召回策略之一。
整体思路: 1.
相似度计算:使用余弦相似度计算用户之间的相似度 2.
相似用户查找:找到与目标用户最相似的 top-k 个用户 3.
物品推荐:基于相似用户的历史行为,计算物品推荐分数 4.
去重排序:去除用户已交互的物品,按分数排序返回
top-n
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| class UserCFRecall:
"""用户协同过滤召回"""
def __init__(self, user_item_matrix, top_k=100):
self.user_item_matrix = user_item_matrix
self.top_k = top_k
self.user_similarity = None
def compute_user_similarity(self):
"""计算用户相似度矩阵"""
from sklearn.metrics.pairwise import cosine_similarity
self.user_similarity = cosine_similarity(
self.user_item_matrix
)
return self.user_similarity
def recall(self, user_id, top_n=500):
"""召回 top_n 个物品"""
if self.user_similarity is None:
self.compute_user_similarity()
similar_users = np.argsort(
self.user_similarity[user_id]
)[-self.top_k-1:-1][::-1]
scores = {}
user_items = set(self.user_item_matrix[user_id].nonzero()[1])
for similar_user in similar_users:
similarity = self.user_similarity[user_id, similar_user]
similar_user_items = self.user_item_matrix[similar_user].nonzero()[1]
for item_id in similar_user_items:
if item_id not in user_items:
scores[item_id] = scores.get(item_id, 0) + similarity
top_items = sorted(scores.items(), key=lambda x: x[1], reverse=True)
return [item_id for item_id, score in top_items[:top_n]]
|
物品协同过滤( ItemCF)
ItemCF 基于"喜欢物品 A 的用户也喜欢物品
B"的假设,通常效果更好且更稳定:
其中表示喜欢物品的用户集合。
代码目的: 实现物品协同过滤(
ItemCF)召回算法,基于"喜欢物品 A 的用户也喜欢物品 B"的假设进行召回。
ItemCF 通常比 UserCF
效果更好且更稳定,是工业级推荐系统的核心召回策略。
整体思路: 1.
物品相似度计算:转置用户-物品矩阵,计算物品之间的余弦相似度
2. 历史物品扩展:基于用户历史交互的物品,找到相似物品
3.
加权评分:考虑用户对历史物品的偏好强度,加权计算推荐分数
4. 排序返回:按分数排序,返回 top-n 个物品
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| class ItemCFRecall:
"""物品协同过滤召回"""
def __init__(self, user_item_matrix, top_k=100):
self.user_item_matrix = user_item_matrix
self.top_k = top_k
self.item_similarity = None
def compute_item_similarity(self):
"""计算物品相似度矩阵"""
item_user_matrix = self.user_item_matrix.T
from sklearn.metrics.pairwise import cosine_similarity
self.item_similarity = cosine_similarity(item_user_matrix)
return self.item_similarity
def recall(self, user_id, top_n=500):
"""基于用户历史行为召回"""
user_items = self.user_item_matrix[user_id].nonzero()[1]
if len(user_items) == 0:
return []
scores = {}
for item_id in user_items:
similar_items = np.argsort(
self.item_similarity[item_id]
)[-self.top_k-1:-1][::-1]
for similar_item in similar_items:
if similar_item not in user_items:
similarity = self.item_similarity[item_id, similar_item]
user_preference = self.user_item_matrix[user_id, item_id]
scores[similar_item] = scores.get(
similar_item, 0
) + similarity * user_preference
top_items = sorted(scores.items(), key=lambda x: x[1], reverse=True)
return [item_id for item_id, score in top_items[:top_n]]
|
内容召回
内容召回基于物品的文本、图像、类别等特征,计算用户与物品的内容相似度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| class ContentBasedRecall:
"""基于内容的召回"""
def __init__(self, item_features, user_profile):
"""
item_features: dict{item_id: feature_vector}
user_profile: dict{user_id: feature_vector}
"""
self.item_features = item_features
self.user_profile = user_profile
def recall(self, user_id, top_n=500):
"""基于内容相似度召回"""
if user_id not in self.user_profile:
return []
user_vector = self.user_profile[user_id]
scores = {}
for item_id, item_vector in self.item_features.items():
similarity = cosine_similarity(
user_vector.reshape(1, -1),
item_vector.reshape(1, -1)
)[0][0]
scores[item_id] = similarity
top_items = sorted(scores.items(), key=lambda x: x[1], reverse=True)
return [item_id for item_id, score in top_items[:top_n]]
|
热门召回
热门召回保证系统的覆盖度和新鲜度,避免过度个性化导致的"信息茧房"。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| class PopularRecall:
"""热门物品召回"""
def __init__(self, time_window_hours=24):
self.time_window_hours = time_window_hours
self.popular_items = []
def update_popular_items(self, click_logs):
"""更新热门物品列表"""
import pandas as pd
from datetime import datetime, timedelta
cutoff_time = datetime.now() - timedelta(
hours=self.time_window_hours
)
recent_clicks = click_logs[
click_logs['timestamp'] >= cutoff_time
]
item_counts = recent_clicks.groupby('item_id').size()
item_scores = {}
for item_id, count in item_counts.items():
latest_time = recent_clicks[
recent_clicks['item_id'] == item_id
]['timestamp'].max()
hours_ago = (datetime.now() - latest_time).total_seconds() / 3600
decay = np.exp(-hours_ago / self.time_window_hours)
item_scores[item_id] = count * decay
self.popular_items = sorted(
item_scores.items(), key=lambda x: x[1], reverse=True
)
def recall(self, user_id, top_n=200):
"""召回热门物品"""
return [item_id for item_id, score in self.popular_items[:top_n]]
|
实时召回
实时召回基于用户最近的交互行为,捕捉用户的即时兴趣变化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| class RealTimeRecall:
"""实时召回"""
def __init__(self, redis_client, time_window_minutes=30):
self.redis = redis_client
self.time_window_minutes = time_window_minutes
def record_user_action(self, user_id, item_id, action_type='click'):
"""记录用户行为"""
import time
key = f"realtime:user:{user_id}"
timestamp = time.time()
self.redis.zadd(
key,
{f"{item_id}:{action_type}": timestamp}
)
cutoff_time = timestamp - self.time_window_minutes * 60
self.redis.zremrangebyscore(key, 0, cutoff_time)
def recall(self, user_id, top_n=200):
"""基于实时行为召回"""
import time
key = f"realtime:user:{user_id}"
cutoff_time = time.time() - self.time_window_minutes * 60
recent_actions = self.redis.zrangebyscore(
key, cutoff_time, time.time(), withscores=True
)
if not recent_actions:
return []
recent_items = set()
for action_data, timestamp in recent_actions:
item_id = action_data.split(':')[0]
recent_items.add(int(item_id))
return list(recent_items)[:top_n]
|
多路召回融合
多路召回的结果需要融合,常见策略包括:
- 加权融合:不同召回通道设置不同权重
- 去重合并:相同物品取最高分
- 多样性保证:确保各通道都有一定比例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| class MultiChannelRecall:
"""多路召回融合"""
def __init__(self):
self.recall_channels = {
'itemcf': ItemCFRecall(...),
'content': ContentBasedRecall(...),
'popular': PopularRecall(...),
'realtime': RealTimeRecall(...)
}
self.weights = {
'itemcf': 0.4,
'content': 0.2,
'popular': 0.2,
'realtime': 0.2
}
self.recall_sizes = {
'itemcf': 2000,
'content': 1000,
'popular': 1000,
'realtime': 1000
}
def recall(self, user_id, top_k=5000):
"""多路召回并融合"""
all_items = {}
for channel_name, recaller in self.recall_channels.items():
items = recaller.recall(
user_id,
top_n=self.recall_sizes[channel_name]
)
if items:
max_score = len(items)
for rank, item_id in enumerate(items):
normalized_score = (max_score - rank) / max_score
weighted_score = normalized_score * self.weights[channel_name]
if item_id not in all_items:
all_items[item_id] = 0
all_items[item_id] += weighted_score
sorted_items = sorted(
all_items.items(),
key=lambda x: x[1],
reverse=True
)
return [item_id for item_id, score in sorted_items[:top_k]]
|
粗排与精排
粗排层设计
粗排层需要在召回和精排之间做平衡:既要保证效果,又要控制计算成本。粗排通常使用轻量级模型,如双塔模型、浅层神经网络。
双塔模型粗排
双塔模型将用户和物品分别编码为向量,通过向量内积计算匹配分数:
其中和分别是用户塔和物品塔的编码函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| import torch
import torch.nn as nn
class CoarseRankerDualTower(nn.Module):
"""双塔模型粗排"""
def __init__(self, user_feature_dim, item_feature_dim, embedding_dim=128):
super().__init__()
self.user_tower = nn.Sequential(
nn.Linear(user_feature_dim, 256),
nn.ReLU(),
nn.Linear(256, embedding_dim)
)
self.item_tower = nn.Sequential(
nn.Linear(item_feature_dim, 256),
nn.ReLU(),
nn.Linear(256, embedding_dim)
)
def forward(self, user_features, item_features):
"""前向传播"""
user_emb = self.user_tower(user_features)
item_emb = self.item_tower(item_features)
user_emb = nn.functional.normalize(user_emb, p=2, dim=1)
item_emb = nn.functional.normalize(item_emb, p=2, dim=1)
score = torch.sum(user_emb * item_emb, dim=1)
return score
def rank(self, user_features, item_features_list, top_k=500):
"""批量排序"""
self.eval()
with torch.no_grad():
user_emb = self.user_tower(user_features)
user_emb = nn.functional.normalize(user_emb, p=2, dim=1)
scores = []
batch_size = 1000
for i in range(0, len(item_features_list), batch_size):
batch_items = item_features_list[i:i+batch_size]
item_batch = torch.stack(batch_items)
item_emb = self.item_tower(item_batch)
item_emb = nn.functional.normalize(item_emb, p=2, dim=1)
batch_scores = torch.matmul(user_emb, item_emb.T)
scores.extend(batch_scores.cpu().numpy().tolist()[0])
top_indices = np.argsort(scores)[-top_k:][::-1]
return top_indices
|
粗排优化技巧
- 特征缓存:物品特征可以离线计算并缓存
- 批量计算:使用 GPU 批量计算提高吞吐
- 模型量化:使用 INT8 量化减少内存和计算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| class OptimizedCoarseRanker:
"""优化的粗排器"""
def __init__(self, model, item_feature_cache):
self.model = model
self.item_feature_cache = item_feature_cache
def rank(self, user_id, item_ids, top_k=500):
"""优化的排序流程"""
user_features = self.get_user_features(user_id)
item_features = [
self.item_feature_cache[item_id]
for item_id in item_ids
]
scores = self.model.batch_score(
user_features,
item_features
)
top_indices = np.argsort(scores)[-top_k:][::-1]
return [item_ids[i] for i in top_indices]
|
精排层设计
精排层使用复杂模型进行精确打分,常见模型包括
Wide&Deep 、 DeepFM 、 DCN 、 xDeepFM 等。
DeepFM 精排模型
DeepFM 结合了因子分解机( FM)和深度神经网络:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
| class DeepFM(nn.Module):
"""DeepFM 模型"""
def __init__(self, field_dims, embed_dim=16, mlp_dims=[128, 64]):
super().__init__()
self.field_dims = field_dims
self.embed_dim = embed_dim
self.linear = FeaturesLinear(field_dims)
self.fm = FactorizationMachine(reduce_sum=True)
self.embedding = FeaturesEmbedding(field_dims, embed_dim)
input_dim = len(field_dims) * embed_dim
self.mlp = MultiLayerPerceptron(input_dim, mlp_dims, dropout=0.2)
def forward(self, x):
"""
x: (batch_size, num_fields)
"""
linear_score = self.linear(x)
x_emb = self.embedding(x)
fm_score = self.fm(x_emb)
deep_input = x_emb.view(x_emb.size(0), -1)
deep_score = self.mlp(deep_input)
score = linear_score + fm_score + deep_score
return torch.sigmoid(score)
class FactorizationMachine(nn.Module):
"""因子分解机"""
def __init__(self, reduce_sum=True):
super().__init__()
self.reduce_sum = reduce_sum
def forward(self, x):
"""
x: (batch_size, num_fields, embed_dim)
"""
square_of_sum = torch.sum(x, dim=1) ** 2
sum_of_square = torch.sum(x ** 2, dim=1)
ix = square_of_sum - sum_of_square
if self.reduce_sum:
ix = torch.sum(ix, dim=1, keepdim=True)
return 0.5 * ix
class MultiLayerPerceptron(nn.Module):
"""多层感知机"""
def __init__(self, input_dim, hidden_dims, dropout=0.0):
super().__init__()
layers = []
dims = [input_dim] + hidden_dims
for i in range(len(dims) - 1):
layers.append(nn.Linear(dims[i], dims[i+1]))
layers.append(nn.ReLU())
if dropout > 0:
layers.append(nn.Dropout(dropout))
self.mlp = nn.Sequential(*layers)
def forward(self, x):
return self.mlp(x)
|
特征工程
精排模型的效果很大程度上依赖于特征质量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| class FeatureEngineering:
"""特征工程"""
def __init__(self):
self.feature_encoders = {}
self.statistics = {}
def create_user_features(self, user_id, user_profile, behavior_history):
"""构建用户特征"""
features = {}
features['user_id'] = user_id
features['age'] = user_profile.get('age', 0)
features['gender'] = user_profile.get('gender', 0)
features['click_count_7d'] = self.count_recent_actions(
behavior_history, days=7, action='click'
)
features['purchase_count_30d'] = self.count_recent_actions(
behavior_history, days=30, action='purchase'
)
features['recent_item_ids'] = self.get_recent_items(
behavior_history, top_k=10
)
features['age_gender'] = f"{features['age']}_{features['gender']}"
return features
def create_item_features(self, item_id, item_info):
"""构建物品特征"""
features = {}
features['item_id'] = item_id
features['category'] = item_info.get('category', '')
features['price'] = item_info.get('price', 0.0)
features['click_count_24h'] = item_info.get('click_count_24h', 0)
features['ctr_7d'] = item_info.get('ctr_7d', 0.0)
return features
def create_context_features(self, context):
"""构建上下文特征"""
features = {}
import datetime
now = datetime.datetime.now()
features['hour'] = now.hour
features['day_of_week'] = now.weekday()
features['is_weekend'] = 1 if now.weekday() >= 5 else 0
features['device_type'] = context.get('device_type', 'unknown')
features['platform'] = context.get('platform', 'unknown')
return features
def create_interaction_features(self, user_features, item_features):
"""构建交互特征"""
features = {}
features['user_item_category_match'] = (
1 if user_features.get('preferred_category') ==
item_features.get('category') else 0
)
user_price_range = user_features.get('price_range', [0, 1000])
item_price = item_features.get('price', 0)
features['price_match'] = (
1 if user_price_range[0] <= item_price <= user_price_range[1]
else 0
)
return features
|
重排序策略
重排序层在精排结果基础上,考虑多样性、新颖性、业务规则等因素进行最终调整。
多样性重排序
多样性保证推荐结果的丰富程度,避免结果过于相似:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| class DiversityReRanker:
"""多样性重排序"""
def __init__(self, item_similarity_matrix, lambda_diversity=0.5):
self.item_similarity = item_similarity_matrix
self.lambda_diversity = lambda_diversity
def re_rank(self, ranked_items, scores, top_k=20):
"""MMR (Maximal Marginal Relevance) 重排序"""
selected = []
remaining = list(range(len(ranked_items)))
if remaining:
selected.append(remaining.pop(0))
while len(selected) < top_k and remaining:
best_idx = None
best_score = -float('inf')
for idx in remaining:
relevance = scores[idx]
max_sim = 0
for sel_idx in selected:
sim = self.item_similarity[
ranked_items[idx],
ranked_items[sel_idx]
]
max_sim = max(max_sim, sim)
mmr_score = (
self.lambda_diversity * relevance -
(1 - self.lambda_diversity) * max_sim
)
if mmr_score > best_score:
best_score = mmr_score
best_idx = idx
if best_idx is not None:
selected.append(best_idx)
remaining.remove(best_idx)
return [ranked_items[i] for i in selected]
|
新颖性重排序
新颖性保证推荐结果的新鲜度,避免重复推荐用户已经看过的内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| class NoveltyReRanker:
"""新颖性重排序"""
def __init__(self, user_history, novelty_weight=0.3):
self.user_history = user_history
self.novelty_weight = novelty_weight
def re_rank(self, ranked_items, scores, top_k=20):
"""基于新颖性重排序"""
novelty_scores = []
for item_id in ranked_items:
is_novel = 1 if item_id not in self.user_history else 0
if item_id in self.user_history:
last_interaction_time = self.user_history[item_id]
hours_ago = (
time.time() - last_interaction_time
) / 3600
novelty = np.exp(-hours_ago / 720)
else:
novelty = 1.0
novelty_scores.append(novelty)
combined_scores = [
(1 - self.novelty_weight) * score +
self.novelty_weight * novelty
for score, novelty in zip(scores, novelty_scores)
]
sorted_indices = np.argsort(combined_scores)[::-1]
return [ranked_items[i] for i in sorted_indices[:top_k]]
|
业务规则重排序
业务规则重排序考虑运营需求,如新品扶持、品类平衡等:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| class BusinessRuleReRanker:
"""业务规则重排序"""
def __init__(self, rules):
"""
rules: dict, 例如 {
'new_item_boost': 1.2, # 新品加权
'category_balance': True, # 品类平衡
'max_items_per_category': 5 # 每个品类最多推荐数
}
"""
self.rules = rules
def re_rank(self, ranked_items, item_metadata, top_k=20):
"""应用业务规则"""
result = []
category_count = {}
for item_id in ranked_items:
if len(result) >= top_k:
break
item_info = item_metadata[item_id]
category = item_info.get('category', 'other')
if self.rules.get('category_balance', False):
max_per_category = self.rules.get(
'max_items_per_category',
float('inf')
)
if category_count.get(category, 0) >= max_per_category:
continue
if self.rules.get('new_item_boost', 1.0) > 1.0:
is_new = item_info.get('is_new', False)
if is_new and len(result) < top_k:
result.append(item_id)
category_count[category] = category_count.get(category, 0) + 1
continue
result.append(item_id)
category_count[category] = category_count.get(category, 0) + 1
return result
|
EasyRec 框架实践
EasyRec
是阿里巴巴开源的推荐算法框架,提供了完整的推荐系统解决方案。
EasyRec 架构
EasyRec
采用配置化的方式构建推荐模型,支持多种模型结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
easyrec_config = {
"model_config": {
"model_class": "MultiTower",
"feature_groups": [
{
"group_name": "user",
"features": [
{"feature_name": "user_id", "feature_type": "id_feature"},
{"feature_name": "age", "feature_type": "raw_feature"},
{"feature_name": "gender", "feature_type": "id_feature"}
]
},
{
"group_name": "item",
"features": [
{"feature_name": "item_id", "feature_type": "id_feature"},
{"feature_name": "category", "feature_type": "id_feature"},
{"feature_name": "price", "feature_type": "raw_feature"}
]
},
{
"group_name": "context",
"features": [
{"feature_name": "hour", "feature_type": "id_feature"},
{"feature_name": "device", "feature_type": "id_feature"}
]
}
],
"wide_and_deep": {
"dnn": {
"hidden_units": [512, 256, 128],
"dropout_rate": 0.2
}
}
},
"data_config": {
"input_fields": ["user_id", "item_id", "label"],
"label_fields": ["label"]
}
}
|
EasyRec 使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| from easy_rec.python import easy_rec_predictor
class EasyRecRecommender:
"""基于 EasyRec 的推荐器"""
def __init__(self, model_path, config_path):
self.predictor = easy_rec_predictor.EasyRecPredictor(
model_path=model_path,
config_path=config_path
)
def predict(self, user_features, item_features, context_features):
"""预测用户对物品的偏好"""
inputs = {
'user_id': user_features['user_id'],
'item_id': item_features['item_id'],
'age': user_features['age'],
'gender': user_features['gender'],
'category': item_features['category'],
'price': item_features['price'],
'hour': context_features['hour'],
'device': context_features['device']
}
predictions = self.predictor.predict(inputs)
return predictions['probs']
def batch_predict(self, user_id, item_ids, context):
"""批量预测"""
user_features = self.get_user_features(user_id)
context_features = self.get_context_features(context)
scores = []
for item_id in item_ids:
item_features = self.get_item_features(item_id)
score = self.predict(user_features, item_features, context_features)
scores.append(score[0])
return scores
|
EasyRec 特征工程
EasyRec 提供了丰富的特征工程能力:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
feature_config = {
"features": [
{
"feature_name": "user_id",
"feature_type": "id_feature",
"embedding_dim": 64,
"hash_bucket_size": 1000000
},
{
"feature_name": "item_id",
"feature_type": "id_feature",
"embedding_dim": 64,
"hash_bucket_size": 500000
},
{
"feature_name": "age",
"feature_type": "raw_feature",
"normalizer": "log"
},
{
"feature_name": "price",
"feature_type": "raw_feature",
"normalizer": "min_max",
"boundaries": [0, 1000]
},
{
"feature_name": "user_item_cross",
"feature_type": "sequence_feature",
"sequence_combiner": "mean"
}
]
}
|
LONGER 长序列建模
LONGER
是字节跳动提出的长序列推荐模型,能够处理用户的长历史行为序列(数千到数万条)。
长序列挑战
传统序列模型(如 GRU 、 LSTM)难以处理超长序列: 1.
计算复杂度:的注意力机制 2.
内存限制:无法将整个序列加载到内存 3.
噪声干扰:长序列中包含大量噪声
LONGER 架构
LONGER 采用分段检索 + 局部建模的策略:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
| class LONGERModel(nn.Module):
"""LONGER 长序列模型"""
def __init__(self, item_embed_dim=64, hidden_dim=128, num_segments=10):
super().__init__()
self.item_embed_dim = item_embed_dim
self.hidden_dim = hidden_dim
self.num_segments = num_segments
self.item_embedding = nn.Embedding(
num_items, item_embed_dim
)
self.segment_retriever = SegmentRetriever(
item_embed_dim, hidden_dim
)
self.local_encoder = LocalSequenceEncoder(
item_embed_dim, hidden_dim
)
self.fusion_layer = nn.Sequential(
nn.Linear(hidden_dim * 2, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1)
)
def forward(self, user_history, candidate_item):
"""
user_history: (batch_size, seq_len) 用户历史序列
candidate_item: (batch_size,) 候选物品
"""
batch_size = user_history.size(0)
seq_len = user_history.size(1)
history_emb = self.item_embedding(user_history)
candidate_emb = self.item_embedding(candidate_item)
segment_size = seq_len // self.num_segments
segments = []
for i in range(self.num_segments):
start_idx = i * segment_size
end_idx = min((i + 1) * segment_size, seq_len)
segment = history_emb[:, start_idx:end_idx, :]
segments.append(segment)
segment_scores = []
for segment in segments:
segment_repr = segment.mean(dim=1)
score = torch.sum(segment_repr * candidate_emb, dim=1)
segment_scores.append(score)
segment_scores = torch.stack(segment_scores, dim=1)
top_k = min(3, self.num_segments)
top_k_scores, top_k_indices = torch.topk(
segment_scores, k=top_k, dim=1
)
selected_segments = []
for i in range(batch_size):
selected_indices = top_k_indices[i]
selected_segment_embs = []
for idx in selected_indices:
seg_idx = idx.item()
seg_emb = segments[seg_idx][i]
selected_segment_embs.append(seg_emb)
selected_segment = torch.cat(selected_segment_embs, dim=0)
selected_segments.append(selected_segment)
max_len = max(seg.size(0) for seg in selected_segments)
padded_segments = []
for seg in selected_segments:
pad_len = max_len - seg.size(0)
if pad_len > 0:
pad = torch.zeros(pad_len, self.item_embed_dim).to(seg.device)
seg = torch.cat([seg, pad], dim=0)
padded_segments.append(seg)
selected_history = torch.stack(padded_segments, dim=0)
local_repr = self.local_encoder(selected_history)
global_repr = history_emb.mean(dim=1)
global_repr = nn.functional.linear(
global_repr,
self.item_embedding.weight[candidate_item]
)
fused_repr = torch.cat([local_repr, global_repr], dim=1)
score = self.fusion_layer(fused_repr)
return torch.sigmoid(score)
class LocalSequenceEncoder(nn.Module):
"""局部序列编码器"""
def __init__(self, input_dim, hidden_dim):
super().__init__()
self.transformer = nn.TransformerEncoder(
nn.TransformerEncoderLayer(
d_model=input_dim,
nhead=8,
dim_feedforward=hidden_dim,
dropout=0.1
),
num_layers=2
)
self.output_proj = nn.Linear(input_dim, hidden_dim)
def forward(self, x):
"""
x: (batch_size, seq_len, input_dim)
"""
x = x.transpose(0, 1)
encoded = self.transformer(x)
encoded = encoded.transpose(0, 1)
output = encoded[:, -1, :]
output = self.output_proj(output)
return output
|
LONGER 优化技巧
- 增量更新:只对新行为进行编码,避免重复计算
- 缓存机制:缓存片段表示,减少计算量
- 采样策略:对超长序列进行智能采样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| class OptimizedLONGER:
"""优化的 LONGER 实现"""
def __init__(self, model, cache_size=10000):
self.model = model
self.segment_cache = {}
self.cache_size = cache_size
def encode_with_cache(self, user_history):
"""带缓存的编码"""
cache_key = self._generate_cache_key(user_history)
if cache_key in self.segment_cache:
return self.segment_cache[cache_key]
representation = self.model.encode(user_history)
if len(self.segment_cache) >= self.cache_size:
oldest_key = next(iter(self.segment_cache))
del self.segment_cache[oldest_key]
self.segment_cache[cache_key] = representation
return representation
def incremental_update(self, old_history, new_actions):
"""增量更新"""
new_segment = self.model.encode_segment(new_actions)
old_repr = self.encode_with_cache(old_history)
updated_repr = self._fuse_representations(old_repr, new_segment)
return updated_repr
|
特征工程自动化
特征工程是推荐系统的关键环节,自动化特征工程可以大幅提升效率。
自动特征生成
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
| class AutoFeatureGenerator:
"""自动特征生成器"""
def __init__(self):
self.feature_templates = []
self._init_templates()
def _init_templates(self):
"""初始化特征模板"""
self.feature_templates.extend([
'count_{field}_{window}',
'avg_{field}_{window}',
'max_{field}_{window}',
'min_{field}_{window}',
])
self.feature_templates.extend([
'{field1}_{field2}_cross',
'{field1}_div_{field2}',
'{field1}_mul_{field2}',
])
self.feature_templates.extend([
'last_{n}_{field}',
'first_{n}_{field}',
])
def generate_features(self, data, target_field='label'):
"""自动生成特征"""
generated_features = {}
for template in self.feature_templates:
if 'count' in template or 'avg' in template:
features = self._generate_stat_features(
data, template
)
generated_features.update(features)
cross_features = self._generate_cross_features(data)
generated_features.update(cross_features)
seq_features = self._generate_sequence_features(data)
generated_features.update(seq_features)
return generated_features
def _generate_stat_features(self, data, template):
"""生成统计特征"""
features = {}
if 'count' in template:
stat_type = 'count'
elif 'avg' in template:
stat_type = 'avg'
elif 'max' in template:
stat_type = 'max'
elif 'min' in template:
stat_type = 'min'
windows = ['1h', '24h', '7d', '30d']
for window in windows:
feature_name = template.format(
field='*', window=window
)
features[feature_name] = self._compute_stat(
data, stat_type, window
)
return features
def _generate_cross_features(self, data):
"""生成交叉特征"""
features = {}
important_fields = ['user_id', 'item_id', 'category', 'price']
for i, field1 in enumerate(important_fields):
for field2 in important_fields[i+1:]:
cross_name = f'{field1}_{field2}_cross'
features[cross_name] = self._compute_cross(
data, field1, field2
)
return features
def _generate_sequence_features(self, data):
"""生成序列特征"""
features = {}
for n in [1, 3, 5, 10]:
feature_name = f'last_{n}_items'
features[feature_name] = self._get_last_n_items(data, n)
return features
|
特征选择
自动特征选择可以去除冗余特征,提升模型效果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| class AutoFeatureSelector:
"""自动特征选择"""
def __init__(self, method='mutual_info'):
self.method = method
self.selected_features = []
def select_features(self, X, y, top_k=100):
"""选择 top_k 个特征"""
if self.method == 'mutual_info':
scores = self._mutual_info_score(X, y)
elif self.method == 'chi2':
scores = self._chi2_score(X, y)
elif self.method == 'f_score':
scores = self._f_score(X, y)
else:
raise ValueError(f"Unknown method: {self.method}")
top_indices = np.argsort(scores)[-top_k:][::-1]
self.selected_features = top_indices
return self.selected_features
def _mutual_info_score(self, X, y):
"""互信息分数"""
from sklearn.feature_selection import mutual_info_classif
scores = mutual_info_classif(X, y, random_state=42)
return scores
def _chi2_score(self, X, y):
"""卡方分数"""
from sklearn.feature_selection import chi2
scores, _ = chi2(X, y)
return scores
def _f_score(self, X, y):
"""F 分数"""
from sklearn.feature_selection import f_classif
scores, _ = f_classif(X, y)
return scores
def transform(self, X):
"""转换数据,只保留选中的特征"""
return X[:, self.selected_features]
|
A/B 测试方法论
A/B
测试是评估推荐系统改进效果的标准方法。通过对比实验组和对照组的真实指标差异,我们可以科学地验证新策略的效果。

A/B 测试框架
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
| class ABTestFramework:
"""A/B 测试框架"""
def __init__(self, redis_client):
self.redis = redis_client
self.experiments = {}
def create_experiment(self, exp_name, variants, traffic_split):
"""
创建实验
variants: ['control', 'treatment']
traffic_split: {'control': 0.5, 'treatment': 0.5}
"""
self.experiments[exp_name] = {
'variants': variants,
'traffic_split': traffic_split,
'start_time': time.time(),
'metrics': {v: [] for v in variants}
}
def assign_variant(self, user_id, exp_name):
"""分配用户到实验组"""
if exp_name not in self.experiments:
return 'control'
exp = self.experiments[exp_name]
hash_value = hash(f"{user_id}_{exp_name}") % 100
cumulative = 0
for variant, split in exp['traffic_split'].items():
cumulative += split * 100
if hash_value < cumulative:
return variant
return 'control'
def record_event(self, user_id, exp_name, event_type, value=1):
"""记录事件"""
variant = self.assign_variant(user_id, exp_name)
key = f"abtest:{exp_name}:{variant}:{event_type}"
self.redis.incrby(key, value)
def get_metrics(self, exp_name):
"""获取实验指标"""
if exp_name not in self.experiments:
return None
exp = self.experiments[exp_name]
metrics = {}
for variant in exp['variants']:
variant_metrics = {}
clicks = int(self.redis.get(
f"abtest:{exp_name}:{variant}:click"
) or 0)
impressions = int(self.redis.get(
f"abtest:{exp_name}:{variant}:impression"
) or 0)
conversions = int(self.redis.get(
f"abtest:{exp_name}:{variant}:conversion"
) or 0)
variant_metrics['ctr'] = clicks / impressions if impressions > 0 else 0
variant_metrics['cvr'] = conversions / clicks if clicks > 0 else 0
variant_metrics['clicks'] = clicks
variant_metrics['impressions'] = impressions
metrics[variant] = variant_metrics
return metrics
def statistical_significance_test(self, exp_name):
"""统计显著性检验"""
metrics = self.get_metrics(exp_name)
if not metrics:
return None
from scipy import stats
control_clicks = metrics['control']['clicks']
control_impressions = metrics['control']['impressions']
treatment_clicks = metrics['treatment']['clicks']
treatment_impressions = metrics['treatment']['impressions']
control_ctr = control_clicks / control_impressions
treatment_ctr = treatment_clicks / treatment_impressions
p1 = control_ctr
p2 = treatment_ctr
n1 = control_impressions
n2 = treatment_impressions
p_pooled = (control_clicks + treatment_clicks) / (n1 + n2)
se = np.sqrt(p_pooled * (1 - p_pooled) * (1/n1 + 1/n2))
z_score = (p2 - p1) / se
p_value = 2 * (1 - stats.norm.cdf(abs(z_score)))
return {
'control_ctr': control_ctr,
'treatment_ctr': treatment_ctr,
'lift': (treatment_ctr - control_ctr) / control_ctr,
'p_value': p_value,
'significant': p_value < 0.05
}
|
A/B 测试最佳实践
- 样本量计算:确保有足够的样本量检测到显著差异
- 分层实验:支持多个实验并行运行
- 灰度发布:逐步扩大流量,降低风险
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| class SampleSizeCalculator:
"""样本量计算器"""
@staticmethod
def calculate_sample_size(
baseline_ctr,
min_detectable_lift,
power=0.8,
alpha=0.05
):
"""
计算所需样本量
baseline_ctr: 基线 CTR
min_detectable_lift: 最小可检测的提升比例
"""
from scipy import stats
p1 = baseline_ctr
p2 = baseline_ctr * (1 + min_detectable_lift)
z_alpha = stats.norm.ppf(1 - alpha/2)
z_beta = stats.norm.ppf(power)
p_bar = (p1 + p2) / 2
n = (
(z_alpha * np.sqrt(2 * p_bar * (1 - p_bar)) +
z_beta * np.sqrt(p1 * (1 - p1) + p2 * (1 - p2))) ** 2
) / ((p2 - p1) ** 2)
return int(np.ceil(n))
|
性能优化技巧
模型推理优化
- 模型量化: INT8 量化减少模型大小和推理时间
- 模型剪枝:去除冗余参数
- 批量推理:提高 GPU 利用率
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| class ModelOptimizer:
"""模型优化器"""
def quantize_model(self, model, calibration_data):
"""模型量化"""
import torch.quantization as quantization
model.qconfig = quantization.get_default_qconfig('fbgemm')
quantization.prepare(model, inplace=True)
with torch.no_grad():
for batch in calibration_data:
model(batch)
quantized_model = quantization.convert(model, inplace=False)
return quantized_model
def prune_model(self, model, pruning_rate=0.2):
"""模型剪枝"""
import torch.nn.utils.prune as prune
for module in model.modules():
if isinstance(module, nn.Linear):
prune.l1_unstructured(module, name='weight', amount=pruning_rate)
prune.remove(module, 'weight')
return model
def optimize_for_inference(self, model):
"""推理优化"""
model.eval()
traced_model = torch.jit.trace(model, example_inputs)
optimized_model = torch.jit.optimize_for_inference(traced_model)
return optimized_model
|
缓存策略
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| class CacheStrategy:
"""缓存策略"""
def __init__(self, redis_client, ttl=3600):
self.redis = redis_client
self.ttl = ttl
def get_user_embedding(self, user_id):
"""获取用户嵌入(带缓存)"""
cache_key = f"user_emb:{user_id}"
cached = self.redis.get(cache_key)
if cached:
return pickle.loads(cached)
embedding = self.compute_user_embedding(user_id)
self.redis.setex(
cache_key,
self.ttl,
pickle.dumps(embedding)
)
return embedding
def get_item_embeddings_batch(self, item_ids):
"""批量获取物品嵌入"""
cache_keys = [f"item_emb:{item_id}" for item_id in item_ids]
cached_values = self.redis.mget(cache_keys)
missing_indices = [
i for i, val in enumerate(cached_values) if val is None
]
missing_item_ids = [item_ids[i] for i in missing_indices]
if missing_item_ids:
new_embeddings = self.compute_item_embeddings_batch(missing_item_ids)
pipe = self.redis.pipeline()
for item_id, emb in zip(missing_item_ids, new_embeddings):
cache_key = f"item_emb:{item_id}"
pipe.setex(cache_key, self.ttl, pickle.dumps(emb))
pipe.execute()
embeddings = []
for i, item_id in enumerate(item_ids):
if cached_values[i]:
embeddings.append(pickle.loads(cached_values[i]))
else:
idx = missing_indices.index(i)
embeddings.append(new_embeddings[idx])
return embeddings
|
异步处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| import asyncio
from concurrent.futures import ThreadPoolExecutor
class AsyncRecommendationService:
"""异步推荐服务"""
def __init__(self, max_workers=10):
self.executor = ThreadPoolExecutor(max_workers=max_workers)
async def recommend_async(self, user_id, context):
"""异步推荐"""
loop = asyncio.get_event_loop()
recall_tasks = [
loop.run_in_executor(
self.executor,
self.recall_channel,
channel,
user_id
)
for channel in ['itemcf', 'content', 'popular', 'realtime']
]
recall_results = await asyncio.gather(*recall_tasks)
all_items = []
for result in recall_results:
all_items.extend(result)
unique_items = list(set(all_items))
coarse_items = await loop.run_in_executor(
self.executor,
self.coarse_rank,
unique_items,
user_id
)
fine_items = await loop.run_in_executor(
self.executor,
self.fine_rank,
coarse_items,
user_id,
context
)
return fine_items
|
模型部署与监控
模型服务化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| from flask import Flask, request, jsonify
import torch
app = Flask(__name__)
class ModelServer:
"""模型服务"""
def __init__(self, model_path):
self.model = torch.load(model_path)
self.model.eval()
self.feature_service = FeatureService()
def predict(self, user_id, item_ids, context):
"""预测接口"""
user_features = self.feature_service.get_user_features(user_id)
item_features_list = self.feature_service.get_item_features_batch(item_ids)
context_features = self.feature_service.get_context_features(context)
scores = []
with torch.no_grad():
for item_features in item_features_list:
input_features = self._combine_features(
user_features,
item_features,
context_features
)
score = self.model(input_features)
scores.append(score.item())
return scores
model_server = ModelServer('model.pth')
@app.route('/recommend', methods=['POST'])
def recommend():
"""推荐接口"""
data = request.json
user_id = data['user_id']
item_ids = data.get('item_ids', [])
context = data.get('context', {})
if not item_ids:
item_ids = recall(user_id, top_k=100)
scores = model_server.predict(user_id, item_ids, context)
ranked_items = [
{'item_id': item_id, 'score': score}
for item_id, score in zip(item_ids, scores)
]
ranked_items.sort(key=lambda x: x['score'], reverse=True)
return jsonify({
'user_id': user_id,
'recommendations': ranked_items[:20]
})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)
|
监控系统
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| class ModelMonitor:
"""模型监控"""
def __init__(self):
self.metrics = {
'latency': [],
'qps': [],
'error_rate': [],
'prediction_distribution': []
}
self.alert_thresholds = {
'latency_p99': 200,
'error_rate': 0.01,
'qps_drop': 0.2
}
def record_prediction(self, latency_ms, score, error=None):
"""记录预测"""
self.metrics['latency'].append(latency_ms)
self.metrics['prediction_distribution'].append(score)
if error:
self.metrics['error_rate'].append(1)
else:
self.metrics['error_rate'].append(0)
self._check_alerts()
def _check_alerts(self):
"""检查告警条件"""
if len(self.metrics['latency']) < 100:
return
p99_latency = np.percentile(self.metrics['latency'][-1000:], 99)
if p99_latency > self.alert_thresholds['latency_p99']:
self.send_alert(f'P99 latency exceeds threshold: {p99_latency}ms')
recent_error_rate = np.mean(self.metrics['error_rate'][-1000:])
if recent_error_rate > self.alert_thresholds['error_rate']:
self.send_alert(f'Error rate exceeds threshold: {recent_error_rate}')
recent_scores = self.metrics['prediction_distribution'][-1000:]
mean_score = np.mean(recent_scores)
std_score = np.std(recent_scores)
if abs(mean_score - 0.5) > 0.3:
self.send_alert(
f'Prediction distribution abnormal: mean={mean_score}, std={std_score}'
)
def send_alert(self, message):
"""发送告警"""
print(f"ALERT: {message}")
|
模型热更新
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
| class HotModelUpdater:
"""模型热更新"""
def __init__(self, model_path, check_interval=300):
self.model_path = model_path
self.check_interval = check_interval
self.current_model = None
self.model_version = None
self.load_model()
def load_model(self):
"""加载模型"""
self.current_model = torch.load(self.model_path)
self.model_version = self._get_model_version()
def _get_model_version(self):
"""获取模型版本"""
import os
mtime = os.path.getmtime(self.model_path)
return mtime
def check_and_update(self):
"""检查并更新模型"""
new_version = self._get_model_version()
if new_version != self.model_version:
print(f"New model detected: {new_version}")
self._update_model()
def _update_model(self):
"""更新模型"""
try:
new_model = torch.load(self.model_path)
if self._validate_model(new_model):
self.current_model = new_model
self.model_version = self._get_model_version()
print(f"Model updated successfully to version {self.model_version}")
else:
print("New model validation failed, keeping current model")
except Exception as e:
print(f"Error updating model: {e}")
def _validate_model(self, model):
"""验证模型"""
try:
dummy_input = torch.randn(1, 100)
with torch.no_grad():
_ = model(dummy_input)
return True
except:
return False
def start_background_update(self):
"""后台更新线程"""
import threading
def update_loop():
while True:
time.sleep(self.check_interval)
self.check_and_update()
thread = threading.Thread(target=update_loop, daemon=True)
thread.start()
|
完整项目实战
项目结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| recommendation_system/
├── config/
│ ├── model_config.yaml
│ └── feature_config.yaml
├── src/
│ ├── recall/
│ │ ├── itemcf.py
│ │ ├── content.py
│ │ └── multi_channel.py
│ ├── rank/
│ │ ├── coarse_ranker.py
│ │ ├── fine_ranker.py
│ │ └── re_ranker.py
│ ├── feature/
│ │ ├── feature_engineering.py
│ │ └── feature_service.py
│ ├── model/
│ │ ├── deepfm.py
│ │ └── longer.py
│ ├── service/
│ │ ├── recommendation_service.py
│ │ └── model_server.py
│ └── utils/
│ ├── cache.py
│ └── monitor.py
├── tests/
├── scripts/
│ ├── train.py
│ └── deploy.py
└── requirements.txt
|
完整推荐服务实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
| class CompleteRecommendationService:
"""完整的推荐服务"""
def __init__(self, config):
self.config = config
self.recall_engine = MultiChannelRecall(config.recall_config)
self.coarse_ranker = CoarseRankerDualTower(config.coarse_ranker_config)
self.fine_ranker = DeepFM(config.fine_ranker_config)
self.re_ranker = DiversityReRanker(config.re_ranker_config)
self.feature_service = FeatureService(config.feature_config)
self.cache = CacheStrategy(config.cache_config)
self.monitor = ModelMonitor()
self.ab_test = ABTestFramework(config.ab_test_config)
def recommend(self, user_id, context=None, top_k=20):
"""完整推荐流程"""
start_time = time.time()
try:
exp_name = self.config.get('experiment_name', 'default')
variant = self.ab_test.assign_variant(user_id, exp_name)
recall_start = time.time()
recall_items = self.recall_engine.recall(
user_id,
top_k=self.config.recall_top_k
)
recall_latency = (time.time() - recall_start) * 1000
coarse_start = time.time()
coarse_items = self.coarse_ranker.rank(
recall_items,
user_id,
top_k=self.config.coarse_top_k
)
coarse_latency = (time.time() - coarse_start) * 1000
fine_start = time.time()
fine_items = self.fine_ranker.rank(
coarse_items,
user_id,
context,
top_k=self.config.fine_top_k
)
fine_latency = (time.time() - fine_start) * 1000
re_rank_start = time.time()
final_items = self.re_ranker.re_rank(
fine_items,
user_id,
top_k=top_k
)
re_rank_latency = (time.time() - re_rank_start) * 1000
total_latency = (time.time() - start_time) * 1000
self.monitor.record_prediction(total_latency, fine_items[0]['score'])
self.ab_test.record_event(user_id, exp_name, 'impression')
return {
'user_id': user_id,
'recommendations': final_items,
'metrics': {
'recall_latency_ms': recall_latency,
'coarse_latency_ms': coarse_latency,
'fine_latency_ms': fine_latency,
're_rank_latency_ms': re_rank_latency,
'total_latency_ms': total_latency
}
}
except Exception as e:
self.monitor.record_prediction(
(time.time() - start_time) * 1000,
0,
error=e
)
raise
|
常见问题 Q&A
Q1: 召回层应该召回多少物品?
A: 召回数量需要在效果和效率之间平衡。通常: -
召回数量: 5000-10000 个物品 -
考虑因素: - 候选集大小:百万级候选集需要更多召回 -
精排模型复杂度:复杂模型可以处理更多候选 -
延迟要求:召回更多会增加延迟
经验值: - 候选集 < 100 万:召回 3000-5000 -
候选集 100 万-1000 万:召回 5000-10000 - 候选集 > 1000 万:召回
10000+
Q2: 如何选择粗排模型?
A: 粗排模型选择原则:
- 轻量级:推理速度快, P99 延迟 < 20ms
- 效果保证:与精排的相关性高( Spearman 相关系数 >
0.7)
- 可扩展:支持批量推理, GPU 利用率高
推荐方案: -
双塔模型:最常用,效果好且速度快 -
浅层神经网络: 2-3 层,速度快但效果略差 -
线性模型:最快但效果一般
Q3: 特征工程中哪些特征最重要?
A: 重要特征排序(经验值):
- 用户-物品交互特征:最重要
- 用户历史点击/购买该物品的次数
- 用户对该物品类别的偏好
- 用户统计特征:
- 用户活跃度( 7 天/30 天点击量)
- 用户偏好类别分布
- 物品统计特征:
- 物品 CTR(点击率)
- 物品热度( 24 小时点击量)
- 上下文特征:
- 交叉特征:
- 用户类别 × 物品类别
- 用户价格偏好 × 物品价格
Q4: 如何处理冷启动问题?
A: 冷启动分为用户冷启动和物品冷启动:
用户冷启动: 1.
利用注册信息:年龄、性别、地域等 2.
热门推荐:推荐热门物品 3.
内容推荐:基于用户填写的兴趣标签 4.
探索策略:增加探索比例,快速收集用户行为
物品冷启动: 1.
内容特征:文本、图像、类别等 2.
相似物品:找到内容相似的热门物品 3.
流量扶持:新品加权,增加曝光机会
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| class ColdStartHandler:
"""冷启动处理"""
def recommend_for_new_user(self, user_profile):
"""新用户推荐"""
if user_profile.get('interests'):
items = self.content_based_recommend(
user_profile['interests']
)
if items:
return items
return self.popular_recommend(top_k=20)
def recommend_new_item(self, item_content_features):
"""新物品推荐"""
similar_items = self.find_similar_items(
item_content_features,
top_k=100
)
target_users = self.get_users_like_items(similar_items)
return target_users
|
Q5: 如何平衡准确性和多样性?
A: 多样性-准确性权衡:
- MMR 算法:在重排序层使用,可调节参数
- 类别多样性:限制每个类别的推荐数量
- 时间多样性:避免重复推荐最近看过的内容
参数调优: -:偏向准确性 -:平衡 -:偏向多样性
Q6: 模型训练数据如何构建?
A: 训练数据构建要点:
- 负样本采样:
- 随机负采样:简单但可能引入噪声
- 曝光未点击:更真实,推荐使用
- 困难负样本:提升模型区分能力
- 时间窗口:
- 使用最近 30-90 天的数据
- 避免使用太旧的数据(用户兴趣会变化)
- 样本平衡:
- 正负样本比例 1:1 到 1:4
- 不同用户/物品的样本数量尽量平衡
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| class TrainingDataBuilder:
"""训练数据构建"""
def build_training_data(self, click_logs, impressions, negative_ratio=4):
"""构建训练数据"""
positive_samples = []
negative_samples = []
for _, row in click_logs.iterrows():
positive_samples.append({
'user_id': row['user_id'],
'item_id': row['item_id'],
'label': 1,
'timestamp': row['timestamp']
})
for _, row in impressions.iterrows():
if row['clicked'] == 0:
negative_samples.append({
'user_id': row['user_id'],
'item_id': row['item_id'],
'label': 0,
'timestamp': row['timestamp']
})
if len(negative_samples) > len(positive_samples) * negative_ratio:
negative_samples = random.sample(
negative_samples,
len(positive_samples) * negative_ratio
)
training_data = positive_samples + negative_samples
random.shuffle(training_data)
return training_data
|
Q7: 如何评估推荐系统效果?
A: 推荐系统评估指标:
离线指标: 1. 准确率指标: -
Precision@K:前 K 个推荐中相关的比例 - Recall@K:覆盖了多少相关物品 -
NDCG@K:考虑位置的排序质量
- 覆盖率:
- 新颖性:
在线指标: 1.
CTR(点击率):最重要的业务指标 2.
CVR(转化率):购买/下载等转化行为 3.
停留时长:用户对推荐内容的参与度 4.
GMV(成交总额):电商场景的核心指标
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| class RecommendationEvaluator:
"""推荐系统评估器"""
def evaluate_offline(self, recommendations, ground_truth):
"""离线评估"""
metrics = {}
for k in [5, 10, 20]:
precision = self.precision_at_k(
recommendations, ground_truth, k
)
metrics[f'precision@{k}'] = precision
for k in [5, 10, 20]:
recall = self.recall_at_k(
recommendations, ground_truth, k
)
metrics[f'recall@{k}'] = recall
for k in [5, 10, 20]:
ndcg = self.ndcg_at_k(
recommendations, ground_truth, k
)
metrics[f'ndcg@{k}'] = ndcg
return metrics
def precision_at_k(self, recommendations, ground_truth, k):
"""Precision@K"""
top_k = recommendations[:k]
relevant = set(ground_truth)
hits = sum(1 for item in top_k if item in relevant)
return hits / k
def recall_at_k(self, recommendations, ground_truth, k):
"""Recall@K"""
top_k = recommendations[:k]
relevant = set(ground_truth)
hits = sum(1 for item in top_k if item in relevant)
return hits / len(relevant) if relevant else 0
def ndcg_at_k(self, recommendations, ground_truth, k):
"""NDCG@K"""
from sklearn.metrics import ndcg_score
y_true = [1 if item in ground_truth else 0
for item in recommendations[:k]]
y_score = list(range(k, 0, -1))
if sum(y_true) == 0:
return 0
return ndcg_score([y_true], [y_score], k=k)
|
Q8: 如何处理数据稀疏性问题?
A: 数据稀疏性处理:
- 矩阵分解: SVD 、 NMF 等降维方法
- 深度学习: Embedding 层学习稠密表示
- 迁移学习:利用其他域的数据
- 内容特征:补充协同过滤的不足
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| class SparseDataHandler:
"""稀疏数据处理"""
def __init__(self, user_item_matrix):
self.user_item_matrix = user_item_matrix
self.sparsity = self._calculate_sparsity()
def _calculate_sparsity(self):
"""计算稀疏度"""
total = self.user_item_matrix.size
non_zero = self.user_item_matrix.nnz
return 1 - (non_zero / total)
def handle_sparsity(self, method='embedding'):
"""处理稀疏性"""
if method == 'embedding':
return self._learn_embeddings()
elif method == 'matrix_factorization':
return self._matrix_factorization()
elif method == 'content_boost':
return self._content_boost()
def _learn_embeddings(self):
"""学习 Embedding"""
from gensim.models import Word2Vec
sequences = []
for user_id in range(self.user_item_matrix.shape[0]):
items = self.user_item_matrix[user_id].nonzero()[1].tolist()
sequences.append([str(item) for item in items])
model = Word2Vec(sequences, vector_size=64, window=5, min_count=1)
return model
|
Q9: 推荐系统如何应对流量峰值?
A: 流量峰值应对策略:
- 水平扩容:
- 缓存策略:
- 降级策略:
- 流量过大时简化模型(如只用召回+粗排)
- 返回缓存结果
- 限流:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| class TrafficPeakHandler:
"""流量峰值处理"""
def __init__(self, max_qps=10000):
self.max_qps = max_qps
self.current_qps = 0
self.cache = {}
def recommend_with_fallback(self, user_id, context):
"""带降级的推荐"""
if self.current_qps > self.max_qps:
if user_id in self.cache:
return self.cache[user_id]
else:
return self.simple_recommend(user_id)
try:
result = self.full_recommend(user_id, context)
self.cache[user_id] = result
return result
except Exception as e:
return self.simple_recommend(user_id)
def simple_recommend(self, user_id):
"""简化推荐(只用召回)"""
return self.recall_engine.recall(user_id, top_k=20)
|
Q10: 如何实现实时推荐?
A: 实时推荐实现:
- 实时特征:
- 使用 Kafka/Flink 处理实时数据流
- Redis 存储实时特征
- 实时召回:
- 基于用户最近行为快速召回
- 向量检索(如 Faiss)加速
- 模型更新:
- 增量学习:只训练新数据
- 在线学习:流式更新模型参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| class RealTimeRecommendation:
"""实时推荐"""
def __init__(self, kafka_consumer, redis_client):
self.kafka_consumer = kafka_consumer
self.redis = redis_client
self.user_recent_actions = {}
def process_real_time_events(self):
"""处理实时事件流"""
for message in self.kafka_consumer:
event = json.loads(message.value)
user_id = event['user_id']
item_id = event['item_id']
action_type = event['action_type']
timestamp = event['timestamp']
self.update_user_actions(user_id, item_id, action_type, timestamp)
if action_type in ['click', 'purchase']:
self.update_recommendations(user_id)
def update_user_actions(self, user_id, item_id, action_type, timestamp):
"""更新用户行为"""
key = f"realtime:user:{user_id}"
self.redis.zadd(key, {f"{item_id}:{action_type}": timestamp})
cutoff = timestamp - 3600
self.redis.zremrangebyscore(key, 0, cutoff)
def update_recommendations(self, user_id):
"""更新推荐结果"""
recent_items = self.get_recent_items(user_id, minutes=30)
realtime_items = self.realtime_recall(user_id, recent_items)
cache_key = f"recommendations:{user_id}"
self.redis.setex(cache_key, 300, json.dumps(realtime_items))
|
总结
工业级推荐系统是一个复杂的系统工程,涉及召回、排序、重排序多个层次,需要综合考虑效果、性能、可维护性等多个方面。本文从架构设计、模型选择、特征工程、
A/B 测试、性能优化、部署监控等角度全面介绍了工业推荐系统的最佳实践。
关键要点:
- 分层架构:召回-粗排-精排-重排序的漏斗设计,平衡效果和效率
- 多路召回:协同过滤、内容、热门、实时等多通道融合
- 特征工程:自动化特征生成和选择,提升模型效果
- A/B 测试:科学评估模型改进,确保线上效果
- 性能优化:模型量化、缓存、异步处理等技巧
- 监控告警:实时监控系统健康,及时发现问题
推荐系统的优化是一个持续迭代的过程,需要不断根据业务反馈调整策略和模型。希望本文能为构建工业级推荐系统提供有价值的参考。