当推荐系统成为我们获取信息、做出决策的重要工具时,一个不容忽视的问题浮出水面:这些系统是否公平?它们为什么会推荐某些内容?用户能否理解并信任这些推荐?
传统的推荐系统追求准确率,通过协同过滤、深度学习等方法不断优化点击率、转化率等指标。然而,这种"唯准确率论"的思维模式带来了诸多问题:系统可能因为历史数据中的偏见而歧视某些群体,可能因为位置偏差而高估某些物品的受欢迎程度,可能因为缺乏可解释性而让用户对推荐结果产生怀疑。
公平性和可解释性已经成为推荐系统研究的前沿领域。公平性关注的是系统是否对不同用户群体一视同仁,是否避免了各种形式的偏见;可解释性关注的是系统能否向用户解释推荐的原因,提升用户的信任度和满意度。这两个问题相互关联:一个公平的系统往往更容易解释,而一个可解释的系统也更容易发现和纠正不公平的问题。
本文将深入探讨推荐系统中的公平性和可解释性问题。我们会从推荐系统中的各种偏见类型开始,理解选择偏差、位置偏差、曝光偏差、流行度偏差等问题的本质;然后引入因果推断的理论框架,学习如何通过反事实推理来识别和消除偏见;接着探讨
CFairER
框架、情感偏见去除、曝光偏差处理等前沿方法;最后深入可解释推荐的各种技术,包括注意力可视化、
LIME/SHAP 等模型解释方法,以及如何通过可解释性提升用户信任度。
推荐系统中的偏见类型
推荐系统中的偏见是一个复杂而多层次的问题。理解这些偏见的本质,是构建公平推荐系统的第一步。
选择偏差( Selection Bias)
选择偏差是最常见的偏见类型之一,它源于我们只能观察到用户对已推荐物品的反馈,而无法观察到用户对未推荐物品的真实偏好。
问题本质
在推荐系统中,我们观察到的数据是"有偏的":用户只能对系统推荐给他们的物品进行评分、点击或购买。如果某个物品从未被推荐给用户,我们就无法知道用户是否喜欢它。这种"缺失不是随机的"现象就是选择偏差。
数学形式化
假设用户如 果 物 品 被 推 荐 给 用 户 缺 失 否 则
其中被 观 察 到 被 观 察 到
即观察概率与真实偏好相关,而不是独立的。
实际影响
选择偏差会导致: 1.
流行度偏差加剧 :热门物品更容易被推荐,更容易获得反馈,从而变得更热门
2.
长尾物品被忽视 :小众物品缺乏曝光机会,难以获得用户反馈
3.
用户兴趣被误判 :系统可能高估用户对热门物品的偏好,低估对长尾物品的兴趣
代码示例:选择偏差的模拟
代码目的:
这段代码实现了一个选择偏差模拟器,用于演示推荐系统中最常见的偏差类型之一——选择偏差(
Selection
Bias)。在真实场景中,用户往往倾向于对他们喜欢的物品进行评分,而忽略不喜欢或中立的物品。这种选择性行为会导致系统观察到的数据与真实偏好之间存在系统性差异。
整体思路: 1.
首先生成一个完整的"真实偏好矩阵"(在实际系统中无法完全观察到的 ground
truth) 2. 然后模拟曝光策略,决定哪些物品会被推荐给用户 3.
基于曝光概率和用户真实偏好模拟用户反馈 4.
最后对比真实偏好和观察到的偏好,量化选择偏差的影响
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom scipy.stats import betaclass SelectionBiasSimulator : """模拟推荐系统中的选择偏差 选择偏差是指观察到的数据并非随机采样,而是受到某种选择机制的影响。 在推荐系统中,这表现为: 1. 用户只会看到推荐系统展示的物品(曝光偏差) 2. 用户更倾向于对喜欢的物品进行评分(选择性反馈) 3. 热门物品获得更多曝光,导致数据分布失衡 """ def __init__ (self, n_users=1000 , n_items=1000 , true_preference_dist='uniform' ): """初始化选择偏差模拟器 参数: n_users: 用户数量 n_items: 物品数量 true_preference_dist: 真实偏好的分布类型 - 'uniform': 均匀分布,所有物品被喜欢的概率相同 - 'beta': Beta 分布,模拟某些物品更受欢迎的情况 """ self.n_users = n_users self.n_items = n_items self.true_preferences = self._generate_true_preferences(true_preference_dist) self.exposure_prob = None def _generate_true_preferences (self, dist_type ): """生成用户的真实偏好矩阵 这个矩阵代表了如果我们能观察到所有用户对所有物品的真实态度。 在实际推荐系统中,我们永远无法获得这样的完美数据。 参数: dist_type: 偏好分布类型 返回: 真实偏好矩阵,形状为 (n_users, n_items),取值范围 [0, 1] 其中 0 表示完全不喜欢, 1 表示非常喜欢 """ if dist_type == 'uniform' : return np.random.uniform(0 , 1 , (self.n_users, self.n_items)) elif dist_type == 'beta' : return np.random.beta(2 , 5 , (self.n_users, self.n_items)) else : raise ValueError(f"Unknown distribution: {dist_type} " ) def simulate_exposure (self, exposure_strategy='popularity' ): """模拟物品曝光策略 曝光策略决定了哪些物品会被展示给用户。不同的曝光策略会导致不同程度的选择偏差。 参数: exposure_strategy: 曝光策略类型 - 'popularity': 基于流行度的曝光,热门物品更容易被推荐(最常见,偏差最严重) - 'uniform': 均匀曝光,每个物品被推荐的概率相同(理想情况,但不现实) - 'random': 随机曝光,概率随机分配(用于对比实验) 返回: exposure_prob: 每个物品的曝光概率,形状为 (n_items,) """ if exposure_strategy == 'popularity' : item_popularity = self.true_preferences.mean(axis=0 ) self.exposure_prob = item_popularity / item_popularity.max () elif exposure_strategy == 'uniform' : self.exposure_prob = np.ones(self.n_items) / self.n_items elif exposure_strategy == 'random' : self.exposure_prob = np.random.uniform(0 , 1 , self.n_items) return self.exposure_prob def observe_feedback (self, exposure_prob=None ): """根据曝光概率观察用户反馈 模拟真实场景中的用户行为: 1. 用户只能看到被推荐的物品(受曝光概率限制) 2. 用户是否点击/评分取决于他们的真实偏好 这个过程产生了选择偏差的关键: - 我们只能观察到被推荐物品的反馈 - 未被推荐的物品永远不会有反馈数据 - 热门物品因为曝光多而获得更多反馈 参数: exposure_prob: 曝光概率向量,如果为 None 则使用之前设置的 exposure_prob 返回: observed_data: DataFrame,包含观察到的用户反馈 列: user (用户 ID), item (物品 ID), rating (评分: 0 或 1) """ if exposure_prob is None : exposure_prob = self.exposure_prob if self.exposure_prob is not None \ else np.ones(self.n_items) / self.n_items observed_data = [] for u in range (self.n_users): for i in range (self.n_items): if np.random.random() < exposure_prob[i]: if np.random.random() < self.true_preferences[u, i]: observed_data.append({'user' : u, 'item' : i, 'rating' : 1 }) else : observed_data.append({'user' : u, 'item' : i, 'rating' : 0 }) return pd.DataFrame(observed_data) def estimate_preference_from_observed (self, observed_data ): """从观察数据估计用户偏好 这是推荐系统的常见做法:基于观察到的用户反馈来估计用户偏好。 然而,由于选择偏差的存在,这种估计往往是有偏的。 参数: observed_data: 观察到的反馈数据(来自 observe_feedback 方法) 返回: estimated: DataFrame,包含每个(user, item)对的估计偏好 """ estimated = observed_data.groupby(['user' , 'item' ])['rating' ].mean().reset_index() return estimated def compare_true_vs_observed (self, observed_data ): """比较真实偏好和观察到的偏好 这是评估选择偏差影响的核心方法。通过对比真实偏好和从观察数据估计的偏好, 可以量化选择偏差造成的系统性误差。 参数: observed_data: 观察到的反馈数据 返回: bias_analysis: DataFrame,包含每个物品的偏差分析结果 - item: 物品 ID - true_preference: 真实的平均偏好( ground truth) - observed_preference: 从观察数据估计的平均偏好 - exposure_prob: 物品的曝光概率 - bias: 估计偏好与真实偏好的差值(正值表示高估) """ estimated = self.estimate_preference_from_observed(observed_data) bias_analysis = [] for i in range (self.n_items): true_avg = self.true_preferences[:, i].mean() observed_items = estimated[estimated['item' ] == i] if len (observed_items) > 0 : observed_avg = observed_items['rating' ].mean() exposure = self.exposure_prob[i] bias_analysis.append({ 'item' : i, 'true_preference' : true_avg, 'observed_preference' : observed_avg, 'exposure_prob' : exposure, 'bias' : observed_avg - true_avg }) return pd.DataFrame(bias_analysis) simulator = SelectionBiasSimulator(n_users=1000 , n_items=100 ) exposure_prob = simulator.simulate_exposure(exposure_strategy='popularity' ) observed_data = simulator.observe_feedback(exposure_prob) bias_analysis = simulator.compare_true_vs_observed(observed_data) print ("选择偏差分析:" )print (bias_analysis.head(10 ))print (f"\n 平均偏差: {bias_analysis['bias' ].mean():.4 f} " )print (f"高曝光物品的平均偏差: {bias_analysis[bias_analysis['exposure_prob' ] > 0.5 ]['bias' ].mean():.4 f} " )print (f"低曝光物品的平均偏差: {bias_analysis[bias_analysis['exposure_prob' ] < 0.2 ]['bias' ].mean():.4 f} " )
代码执行后的关键发现:
整体偏差趋势 :平均偏差通常为正值,表明观察到的偏好系统性地高估了用户的真实偏好。这是因为用户更倾向于对喜欢的物品给出反馈。
曝光相关性 :高曝光物品和低曝光物品的偏差模式不同:
高曝光物品 (流行物品):由于获得大量反馈,估计相对准确,但仍可能被高估低曝光物品 (长尾物品):样本量小,估计不稳定,且往往被低估或完全忽略 实际影响 :
推荐模型会过度推荐已经流行的物品(马太效应)
长尾物品难以获得公平的曝光机会
新物品面临严重的冷启动问题
如何应对选择偏差:
倾向评分方法( Propensity
Score) :估计每个物品被观察到的概率,然后进行逆概率加权(
IPS)因果推断方法 :使用反事实推理建模"如果用户看到该物品会如何"主动探索 :通过随机化试验( A/B
测试)收集无偏数据去偏训练 :在模型训练时显式建模曝光机制,例如使用曝光感知的损失函数
常见陷阱:
忽略缺失不随机(
MNAR) :简单地使用观察数据训练模型会导致严重的偏差过度依赖显式反馈 :隐式反馈(如点击、观看时长)也存在选择偏差,需要谨慎处理忽视时间动态 :用户偏好和物品流行度会随时间变化,偏差也会演化
位置偏差( Position Bias)
位置偏差是指用户倾向于点击位置靠前的推荐结果,即使这些结果可能不是最相关的。
问题本质
在推荐系统中,物品的展示位置会影响用户的点击行为。用户更可能点击: -
页面顶部的物品(即使相关性较低) - 搜索结果的第一页 -
推荐列表的前几个位置
这种位置效应会污染我们的训练数据:一个相关性较低的物品如果排在前面,可能获得比相关性更高的物品更多的点击。
数学形式化
假设物品
其中: -
通常假设位置偏差遵循幂律分布:
其中
实际影响
位置偏差会导致: 1.
排序质量被高估 :系统可能认为位置靠前的物品质量更高 2.
新物品难以获得曝光 :新物品通常排在后面,难以获得点击 3.
推荐多样性下降 :系统倾向于推荐已经在前面位置的物品
代码示例:位置偏差的建模与消除
代码目的:
这段代码实现了一个考虑位置偏差的推荐模型。位置偏差是指用户倾向于点击排在前面位置的物品,即使这些物品的实际相关性可能较低。这个模型的目标是:
1. 显式建模位置偏差效应 2. 将用户-物品相关性与位置偏差解耦 3.
训练时学习真实的相关性,而非被位置污染的点击概率
整体思路: 1.
使用双塔模型计算用户-物品的本质相关性(不受位置影响) 2.
单独学习每个位置的偏差参数 3. 将相关性和位置偏差组合得到最终的点击概率
4. 在推理时只使用相关性进行排序,忽略位置偏差
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 import torchimport torch.nn as nnfrom torch.utils.data import Dataset, DataLoaderclass PositionBiasModel (nn.Module): """建模位置偏差的推荐模型 核心思想:点击概率 = 相关性 × 位置检查概率 - 相关性:用户-物品匹配度(我们真正关心的) - 位置检查概率:用户检查该位置的概率(位置偏差) 通过显式建模位置偏差,可以学习到不受位置影响的真实相关性。 """ def __init__ (self, n_users, n_items, embedding_dim=64 , n_positions=10 ): """初始化位置偏差模型 参数: n_users: 用户总数 n_items: 物品总数 embedding_dim: 嵌入向量维度 n_positions: 考虑的位置数量(例如 top-10) """ super (PositionBiasModel, self).__init__() self.user_embedding = nn.Embedding(n_users, embedding_dim) self.item_embedding = nn.Embedding(n_items, embedding_dim) self.position_embedding = nn.Embedding(n_positions, embedding_dim) self.position_bias = nn.Parameter(torch.zeros(n_positions)) self.relevance_layer = nn.Sequential( nn.Linear(embedding_dim * 2 , embedding_dim), nn.ReLU(), nn.Linear(embedding_dim, 1 ), nn.Sigmoid() ) def forward (self, user_ids, item_ids, positions ): """前向传播:计算点击概率、相关性和位置偏差 参数: user_ids: 用户 ID 张量,形状 (batch_size,) item_ids: 物品 ID 张量,形状 (batch_size,) positions: 位置张量,形状 (batch_size,),取值范围 [0, n_positions-1] 返回: click_prob: 预测的点击概率 (batch_size,) relevance: 用户-物品相关性 (batch_size,) position_bias_logit: 位置偏差的 logit 值 (batch_size,) """ user_emb = self.user_embedding(user_ids) item_emb = self.item_embedding(item_ids) pos_emb = self.position_embedding(positions) relevance_input = torch.cat([user_emb, item_emb], dim=1 ) relevance = self.relevance_layer(relevance_input).squeeze() position_bias_logit = self.position_bias[positions] click_prob = relevance * torch.sigmoid(position_bias_logit) return click_prob, relevance, position_bias_logit class PositionBiasDataset (Dataset ): """位置偏差数据集 用于加载和预处理包含位置信息的点击数据。 每个样本包含:用户 ID 、物品 ID 、展示位置、是否点击 """ def __init__ (self, user_ids, item_ids, positions, clicks ): """初始化数据集 参数: user_ids: 用户 ID 列表 item_ids: 物品 ID 列表 positions: 物品展示位置列表 clicks: 点击标签列表( 1=点击, 0=未点击) """ self.user_ids = torch.LongTensor(user_ids) self.item_ids = torch.LongTensor(item_ids) self.positions = torch.LongTensor(positions) self.clicks = torch.FloatTensor(clicks) def __len__ (self ): """返回数据集大小""" return len (self.user_ids) def __getitem__ (self, idx ): """获取单个样本 返回: 字典包含 user_id, item_id, position, click """ return { 'user_id' : self.user_ids[idx], 'item_id' : self.item_ids[idx], 'position' : self.positions[idx], 'click' : self.clicks[idx] } def train_position_bias_model (model, dataloader, epochs=10 , lr=0.001 ): """训练位置偏差模型 训练目标: 1. 学习用户-物品的真实相关性(不受位置影响) 2. 学习每个位置的偏差参数 参数: model: PositionBiasModel 实例 dataloader: 训练数据加载器 epochs: 训练轮数 lr: 学习率 返回: 训练后的模型 """ optimizer = torch.optim.Adam(model.parameters(), lr=lr) criterion = nn.BCELoss() for epoch in range (epochs): total_loss = 0 for batch in dataloader: user_ids = batch['user_id' ] item_ids = batch['item_id' ] positions = batch['position' ] clicks = batch['click' ] optimizer.zero_grad() click_prob, relevance, position_bias = model(user_ids, item_ids, positions) loss = criterion(click_prob, clicks) loss.backward() optimizer.step() total_loss += loss.item() print (f"Epoch {epoch+1 } /{epochs} , Loss: {total_loss/len (dataloader):.4 f} " ) return model n_users, n_items = 1000 , 500 n_samples = 10000 true_relevance = np.random.beta(2 , 5 , (n_users, n_items)) user_ids = np.random.randint(0 , n_users, n_samples) item_ids = np.random.randint(0 , n_items, n_samples) positions = np.random.randint(0 , 10 , n_samples) position_examine_prob = 1.0 / (positions + 1 ) ** 0.5 relevance_scores = true_relevance[user_ids, item_ids] click_probs = relevance_scores * position_examine_prob clicks = (np.random.random(n_samples) < click_probs).astype(float ) dataset = PositionBiasDataset(user_ids, item_ids, positions, clicks) dataloader = DataLoader(dataset, batch_size=64 , shuffle=True ) model = PositionBiasModel(n_users, n_items, embedding_dim=32 , n_positions=10 ) model = train_position_bias_model(model, dataloader, epochs=20 ) print ("\n 学习到的位置偏差参数( logit 空间):" )with torch.no_grad(): for pos in range (10 ): bias_logit = model.position_bias[pos].item() bias_prob = torch.sigmoid(torch.tensor(bias_logit)).item() print (f"位置 {pos} : logit={bias_logit:.4 f} , prob={bias_prob:.4 f} " )
代码执行后的关键发现:
位置偏差参数的模式 :
学习到的 position_bias 参数通常呈现递减趋势:位置 0 最大,位置 9
最小
转换为概率后,通常与我们生成数据时使用的幂律分布接近
这验证了模型能够成功从数据中学习到位置偏差的规律
模型去偏能力 :
训练完成后,模型的relevance输出代表了不受位置影响的真实相关性
在推理时,可以只使用relevance进行排序,避免位置偏差的负面影响
这样排序的结果更能反映物品的真实质量,而非历史位置的影响
实际应用价值 :
A/B 测试分析 :可以量化位置对点击率的影响公平性保障 :新物品即使历史位置靠后,也能基于真实相关性获得合理排名多样性提升 :避免"富者愈富"的马太效应
如何在实际系统中使用:
训练阶段 :使用历史日志数据(包含用户、物品、位置、点击)训练模型推理阶段 :只使用relevance分支进行排序,忽略position_bias监控阶段 :定期检查 position_bias
参数,了解用户的浏览习惯变化
常见陷阱:
数据稀疏性 :某些位置的数据可能很少(例如第 10
个位置),导致参数估计不准确时间漂移 :用户的浏览习惯会随时间和场景变化(移动端
vs 桌面端),需要定期更新模型交互效应 :实际中位置偏差可能与用户特征、物品类型相关(例如资深用户更愿意浏览后面的位置),简单的位置参数可能不够
曝光偏差( Exposure Bias)
曝光偏差是指用户只能看到系统推荐给他们的物品,而无法看到其他物品,导致训练数据中的负样本(未点击的物品)可能并不是用户真正不喜欢的。
问题本质
在推荐系统中,我们通常将用户未点击的物品视为负样本。然而,用户未点击某个物品可能有多种原因:
1. 用户确实不喜欢该物品(真正的负样本) 2.
用户根本没有看到该物品(曝光偏差) 3.
用户看到了但暂时不需要(不是真正的负样本)
如果我们错误地将未曝光的物品视为负样本,会导致模型低估这些物品的受欢迎程度。
数学形式化
假设用户如 果 且 用 户 点 击 如 果 且 用 户 未 点 击 缺 失 如 果
曝光偏差意味着
实际影响
曝光偏差会导致: 1.
长尾物品被低估 :未曝光的物品被错误地视为负样本 2.
推荐多样性下降 :系统倾向于推荐已经曝光过的物品 3.
新用户冷启动困难 :新用户缺乏曝光历史,难以准确建模
代码示例:曝光偏差的处理
代码目的:
实现曝光偏差校正器,用于处理推荐系统中的曝光偏差问题。曝光偏差指的是用户只能对系统展示的物品进行反馈,未展示的物品没有反馈数据,这导致我们无法准确评估这些未曝光物品的真实质量。
整体思路: 1.
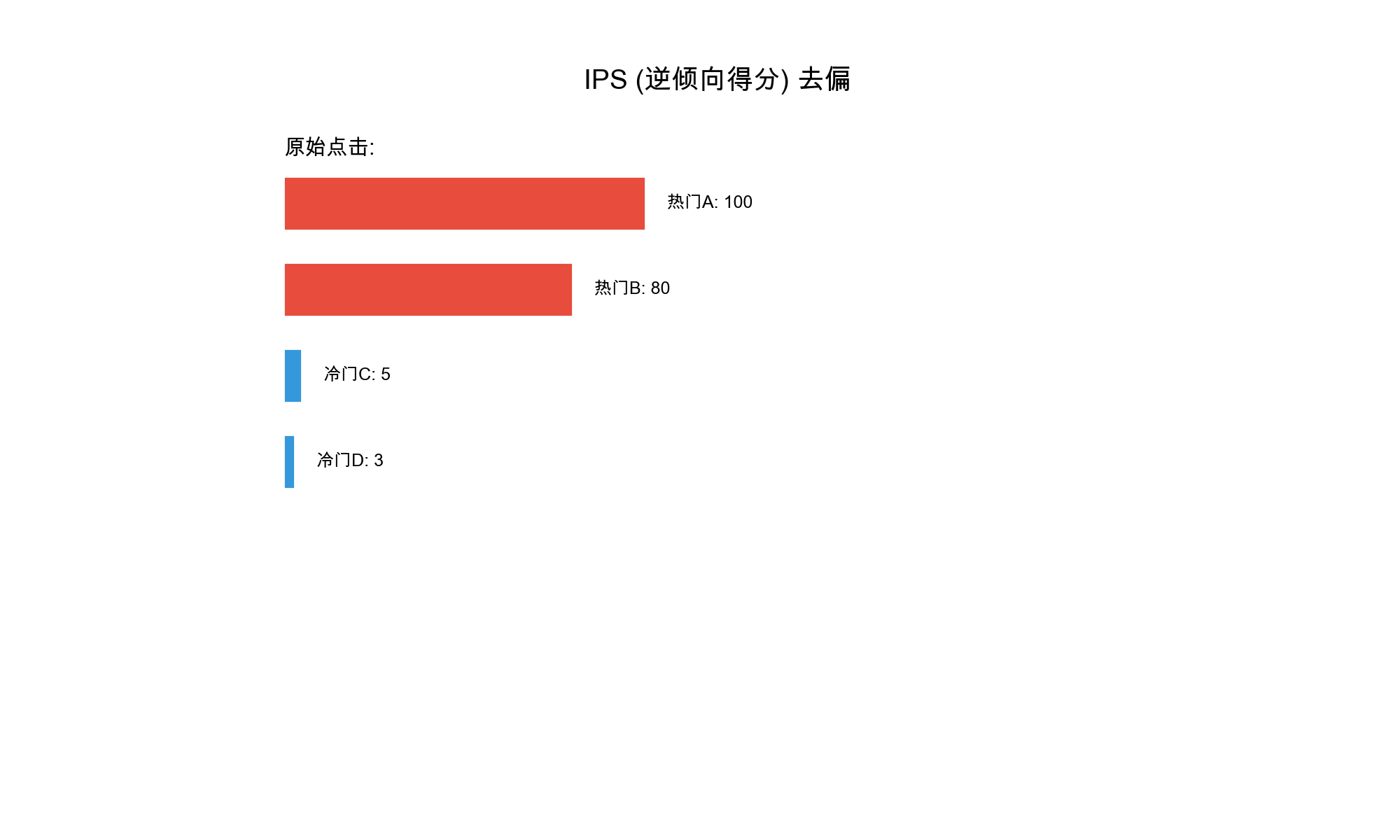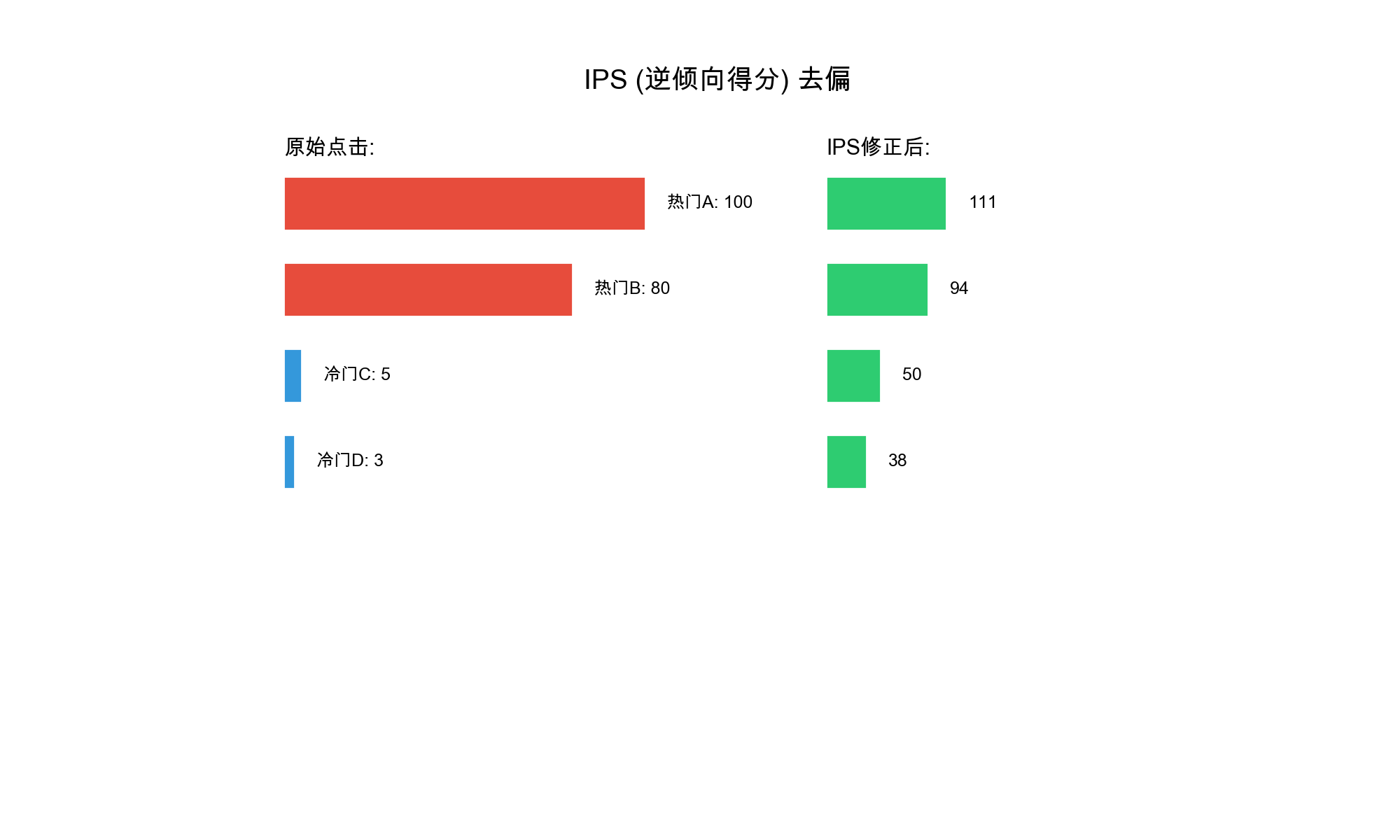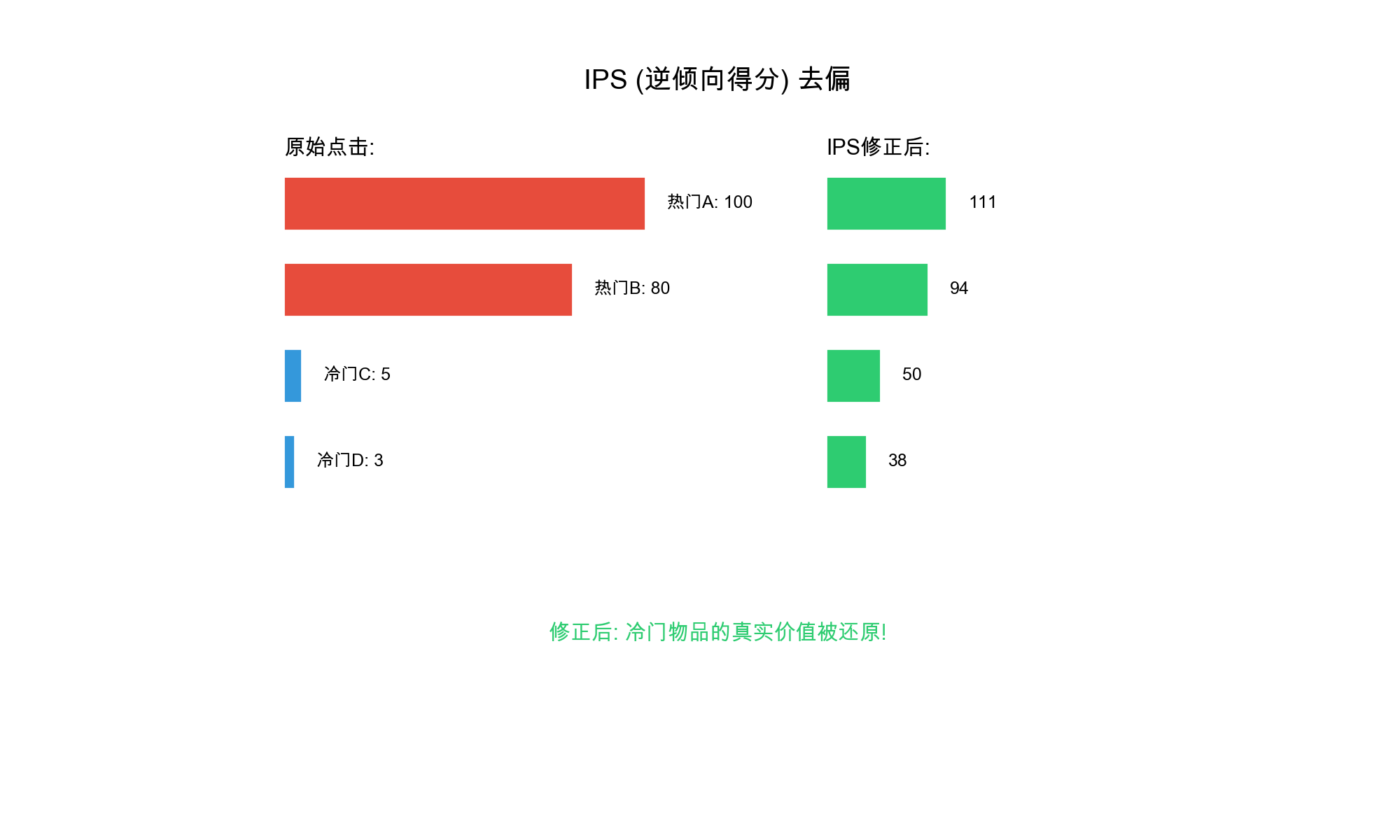
估计每个物品的曝光概率(被展示给用户的概率) 2. 使用逆倾向评分(
IPS)对观察到的样本进行加权,补偿曝光不均衡 3.
通过加权训练或样本过滤来减少曝光偏差的影响
核心原理: 逆倾向评分( Inverse Propensity
Scoring)的思想是:如果一个物品很少被曝光但仍获得点击,说明它的真实质量可能很高,应该给予更高的权重。权重
= 1 / 曝光概率。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 class ExposureBiasCorrector : """曝光偏差校正器 用于估计和校正推荐系统中的曝光偏差。 核心方法是逆倾向评分( IPS),通过对不同曝光概率的样本赋予不同权重来去偏。 """ def __init__ (self, exposure_model=None ): """初始化校正器 参数: exposure_model: 可选的曝光预测模型,用于更精确地估计曝光概率 """ self.exposure_model = exposure_model self.exposure_probs = {} def estimate_exposure_probability (self, user_ids, item_ids, method='inverse_propensity' ): """估计曝光概率 曝光概率:物品被展示给用户的概率 P(expose | item) 参数: user_ids: 用户 ID 列表 item_ids: 物品 ID 列表 method: 估计方法 - 'inverse_propensity': 基于物品在数据中的出现频率估计(简单但有效) - 'learned': 使用机器学习模型预测曝光概率(更精确但需要训练) 返回: exposure_probs: 字典,{item_id: exposure_probability} """ if method == 'inverse_propensity' : item_exposure_counts = {} for item_id in item_ids: item_exposure_counts[item_id] = item_exposure_counts.get(item_id, 0 ) + 1 total_exposures = len (item_ids) exposure_probs = {} for item_id in set (item_ids): exposure_probs[item_id] = item_exposure_counts[item_id] / total_exposures return exposure_probs elif method == 'learned' : if self.exposure_model is None : raise ValueError("Exposure model not provided" ) pass def apply_inverse_propensity_scoring (self, user_ids, item_ids, ratings, exposure_probs=None ): """应用逆倾向评分( IPS)校正 IPS 核心思想:对低曝光物品的样本赋予更高权重,对高曝光物品的样本赋予较低权重。 这样可以减少曝光不均衡导致的偏差。 参数: user_ids: 用户 ID 列表 item_ids: 物品 ID 列表 ratings: 评分/反馈列表 exposure_probs: 曝光概率字典(如果为 None 则自动估计) 返回: weighted_ratings: 加权后的评分 weights: 每个样本的权重 """ if exposure_probs is None : exposure_probs = self.estimate_exposure_probability(user_ids, item_ids) weights = [] for item_id in item_ids: prob = exposure_probs.get(item_id, 0.001 ) weights.append(1.0 / max (prob, 0.001 )) weighted_ratings = np.array(ratings) * np.array(weights) return weighted_ratings, weights def debias_training_data (self, user_ids, item_ids, ratings, exposure_threshold=0.1 ): """去偏训练数据 另一种去偏策略:过滤掉曝光概率过低的样本。 这种方法牺牲了一些数据,但避免了 IPS 中的极端权重问题。 参数: user_ids: 用户 ID 列表 item_ids: 物品 ID 列表 ratings: 评分列表 exposure_threshold: 曝光概率阈值,低于此值的样本会被过滤 返回: debiased_data: 去偏后的数据,格式为[(user, item, rating, exposure_prob), ...] """ exposure_probs = self.estimate_exposure_probability(user_ids, item_ids) debiased_data = [] for u, i, r in zip (user_ids, item_ids, ratings): prob = exposure_probs.get(i, 0.0 ) if prob >= exposure_threshold: debiased_data.append((u, i, r, prob)) return debiased_data corrector = ExposureBiasCorrector() user_ids = np.random.randint(0 , 100 , 1000 ) item_ids = np.random.randint(0 , 50 , 1000 ) ratings = np.random.randint(0 , 2 , 1000 ) weighted_ratings, weights = corrector.apply_inverse_propensity_scoring( user_ids, item_ids, ratings ) print (f"原始评分均值: {np.mean(ratings):.4 f} " )print (f"加权评分均值: {np.mean(weighted_ratings):.4 f} " )print (f"权重范围: [{np.min (weights):.2 f} , {np.max (weights):.2 f} ]" )
代码执行后的关键观察:
加权评分的变化 :
如果某些高曝光物品主导了训练数据,加权后的评分均值可能会发生显著变化
变化方向取决于低曝光物品和高曝光物品的质量差异
权重分布 :
权重范围通常较大(例如[2, 100]),说明曝光不均衡严重
最大权重对应曝光概率最低的物品
需要注意极端权重可能导致训练不稳定
实际应用建议 :
Clipping : 限制最大权重(例如
max_weight=100)避免极端情况归一化 : 对权重进行归一化使其和为 batch_size混合策略 : 结合 IPS
和样本过滤,既去偏又保持稳定性
常见陷阱:
高方差问题 : IPS
权重的方差可能很大,导致训练不稳定,需要使用方差减少技术曝光概率估计误差 :如果曝光概率估计不准确, IPS
校正可能适得其反极端权重 :非常罕见的物品可能获得极大权重,需要设置上限
流行度偏差( Popularity Bias)
流行度偏差是指推荐系统倾向于推荐热门物品,导致热门物品越来越热,冷门物品越来越冷。
问题本质
推荐系统通常基于用户的历史行为数据进行训练,而历史数据本身就存在流行度偏差:热门物品有更多的交互记录。如果模型简单地学习这种模式,就会进一步加剧流行度偏差。
数学形式化
假设物品
其中
实际影响
流行度偏差会导致: 1.
推荐多样性下降 :用户看到的推荐越来越相似 2.
长尾物品被忽视 :小众但高质量的物品难以获得推荐 3.
用户满意度下降 :用户可能对重复推荐热门物品感到厌倦
代码示例:流行度偏差的测量与消除
代码目的:
测量推荐系统中的流行度偏差程度,并实施去偏策略。流行度偏差会导致推荐结果过度集中在热门物品上,损害长尾物品的曝光机会。
核心方法: 1. 使用 KL 散度和基尼系数量化流行度偏差
2. 应用逆流行度加权重新排序推荐结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 class PopularityBiasAnalyzer : """流行度偏差分析器 用于测量推荐系统中的流行度偏差,并提供去偏方法。 """ def __init__ (self ): self.item_popularity = {} self.recommendation_distribution = {} def compute_item_popularity (self, interactions ): """计算物品流行度 参数: interactions: 交互数据,格式为 [(user_id, item_id), ...] """ item_counts = {} for user_id, item_id in interactions: item_counts[item_id] = item_counts.get(item_id, 0 ) + 1 total_interactions = len (interactions) self.item_popularity = { item_id: count / total_interactions for item_id, count in item_counts.items() } return self.item_popularity def compute_recommendation_distribution (self, recommendations ): """计算推荐分布 参数: recommendations: 推荐结果,格式为 {user_id: [item_id1, item_id2, ...]} """ rec_counts = {} for user_id, item_list in recommendations.items(): for item_id in item_list: rec_counts[item_id] = rec_counts.get(item_id, 0 ) + 1 total_recs = sum (len (items) for items in recommendations.values()) self.recommendation_distribution = { item_id: count / total_recs for item_id, count in rec_counts.items() } return self.recommendation_distribution def measure_popularity_bias (self, interactions, recommendations ): """测量流行度偏差 使用 KL 散度和基尼系数衡量推荐分布偏离流行度分布的程度 """ pop = self.compute_item_popularity(interactions) rec_dist = self.compute_recommendation_distribution(recommendations) all_items = set (list (pop.keys()) + list (rec_dist.keys())) pop_dist = np.array([pop.get(item, 0 ) for item in all_items]) rec_dist_array = np.array([rec_dist.get(item, 0 ) for item in all_items]) pop_dist = pop_dist + 1e-10 rec_dist_array = rec_dist_array + 1e-10 kl_divergence = np.sum (rec_dist_array * np.log(rec_dist_array / pop_dist)) sorted_pop = np.sort(pop_dist) n = len (sorted_pop) gini = (2 * np.sum ((np.arange(1 , n+1 )) * sorted_pop)) / (n * np.sum (sorted_pop)) - (n + 1 ) / n return { 'kl_divergence' : kl_divergence, 'gini_coefficient' : gini, 'popularity_distribution' : pop, 'recommendation_distribution' : rec_dist } def apply_popularity_debiasing (self, recommendations, debiasing_method='inverse_popularity' , alpha=0.5 ): """应用流行度去偏 参数: recommendations: 原始推荐结果 debiasing_method: 去偏方法 - 'inverse_popularity': 逆流行度加权 - 'calibration': 校准方法 alpha: 去偏强度参数( 0-1),值越大去偏越强 """ if debiasing_method == 'inverse_popularity' : debiased_recs = {} for user_id, item_list in recommendations.items(): weights = [] for item_id in item_list: pop = self.item_popularity.get(item_id, 0.001 ) weight = 1.0 / (pop ** alpha) weights.append(weight) sorted_items = sorted (zip (item_list, weights), key=lambda x: x[1 ], reverse=True ) debiased_recs[user_id] = [item for item, _ in sorted_items] return debiased_recs elif debiasing_method == 'calibration' : target_dist = {item: 1.0 / len (self.item_popularity) for item in self.item_popularity.keys()} pass analyzer = PopularityBiasAnalyzer() interactions = [] for i in range (1000 ): item_id = np.random.choice(100 , p=[0.3 ] + [0.7 /99 ] * 99 ) user_id = np.random.randint(0 , 100 ) interactions.append((user_id, item_id)) recommendations = {} for user_id in range (100 ): item_probs = [0.4 ] + [0.6 /99 ] * 99 recommended_items = np.random.choice(100 , size=10 , replace=False , p=item_probs).tolist() recommendations[user_id] = recommended_items bias_metrics = analyzer.measure_popularity_bias(interactions, recommendations) print ("流行度偏差指标:" )print (f"KL 散度: {bias_metrics['kl_divergence' ]:.4 f} " )print (f"基尼系数: {bias_metrics['gini_coefficient' ]:.4 f} " )debiased_recs = analyzer.apply_popularity_debiasing(recommendations, alpha=0.5 ) debiased_metrics = analyzer.measure_popularity_bias(interactions, debiased_recs) print (f"\n 去偏后 KL 散度: {debiased_metrics['kl_divergence' ]:.4 f} " )print (f"去偏后基尼系数: {debiased_metrics['gini_coefficient' ]:.4 f} " )
代码执行后的关键发现: - 原始推荐的 KL
散度和基尼系数通常较高,表明流行度偏差严重 -
去偏后,基尼系数下降,说明推荐更加均衡,长尾物品获得更多机会 - alpha
参数需要权衡准确性和多样性:过大会损害准确性,过小去偏不足
因果推断基础
要真正理解和解决推荐系统中的偏见问题,需要引入因果推断的理论框架。因果推断帮助我们区分"相关"和"因果",从而识别真正的因果关系并消除偏见。
为什么需要因果推断
传统的推荐系统主要基于相关性进行建模:如果用户
混淆变量 :用户点击某个物品可能是因为该物品排在前面(位置偏差),而不是因为真正喜欢选择偏差 :我们只能观察到用户对已推荐物品的反馈反向因果 :推荐可能影响用户偏好,而不仅仅是反映用户偏好
因果推断提供了更严谨的框架来建模这些关系。
因果图与结构因果模型
因果图( Causal Graph)
因果图用有向无环图(
DAG)表示变量之间的因果关系。在推荐系统中,一个简化的因果图可能如下:
1 2 3 4 用户特征(U) -> 推荐决策(R) -> 曝光(E) -> 点击(C) 物品特征(I) -> 推荐决策(R) 位置(P) -> 曝光(E) -> 点击(C) 用户偏好(UP) -> 点击(C)
结构因果模型( SCM)
结构因果模型用函数方程表示因果关系:$
其中
潜在结果框架(
Potential Outcomes Framework)
潜在结果框架是因果推断的核心工具之一。
定义
对于用户
个体处理效应( ITE)
平均处理效应( ATE)
问题:我们无法同时观察到
这就是因果推断的"根本问题":对于同一个用户-物品对,我们只能观察到一种情况下的结果。
代码示例:潜在结果框架的实现
代码目的: 实现因果推断中的潜在结果框架( Rubin
Causal
Model),用于估计推荐干预的因果效应。这个框架解决了推荐系统中的关键问题:如果我们向用户推荐(或不推荐)某个物品,用户的行为会如何变化?
整体思路: 1.
定义潜在结果:每个用户-物品对有两个潜在结果——被推荐时的结果
Y(1)和未被推荐时的结果 Y(0) 2.
模拟观察数据:在现实中,我们只能观察到实际发生的情况(要么推荐,要么不推荐)
3. 估计平均处理效应(
ATE):使用不同方法(朴素估计、倾向评分加权)估计推荐的整体效果
核心概念:
因果推断的根本问题是我们无法同时观察同一个体在接受和不接受处理时的结果。需要使用统计方法从观察数据中估计因果效应。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 class PotentialOutcomesFramework : """潜在结果框架实现 实现 Rubin 因果模型,用于估计推荐系统中的因果效应。 关键概念: - Y(1): 物品被推荐时的潜在结果(例如,用户点击概率) - Y(0): 物品未被推荐时的潜在结果 - ITE: 个体处理效应 = Y(1) - Y(0) - ATE: 平均处理效应 = E[Y(1) - Y(0)] """ def __init__ (self, n_users, n_items ): """初始化潜在结果框架 参数: n_users: 用户数量 n_items: 物品数量 """ self.n_users = n_users self.n_items = n_items self.potential_outcomes_treated = np.random.beta(2 , 5 , (n_users, n_items)) self.potential_outcomes_control = np.random.beta(1 , 3 , (n_users, n_items)) def observe_outcome (self, user_id, item_id, treatment ): """观察结果(模拟现实中的观察机制) 在真实场景中,我们只能观察到实际发生的情况: - 如果物品被推荐( treatment=1),我们观察到 Y(1) - 如果物品未被推荐( treatment=0),我们观察到 Y(0) 我们永远无法同时观察到同一个(user, item)对的 Y(1)和 Y(0)! 这就是因果推断的"根本问题"。 参数: user_id: 用户 ID item_id: 物品 ID treatment: 处理标志( 1=推荐, 0=未推荐) 返回: observed_outcome: 观察到的结果(点击概率) """ if treatment == 1 : return self.potential_outcomes_treated[user_id, item_id] else : return self.potential_outcomes_control[user_id, item_id] def compute_ite (self, user_id, item_id ): """计算个体处理效应( ITE: Individual Treatment Effect) ITE = Y(1) - Y(0):对于特定的用户-物品对,推荐带来的效果差异 注意:这个函数只在实验/模拟环境中有效! 在真实场景中,我们无法直接计算 ITE,因为我们无法同时观察 Y(1)和 Y(0)。 参数: user_id: 用户 ID item_id: 物品 ID 返回: ite: 个体处理效应 """ return (self.potential_outcomes_treated[user_id, item_id] - self.potential_outcomes_control[user_id, item_id]) def estimate_ate_naive (self, treated_data, control_data ): """朴素的 ATE 估计方法 简单地比较处理组和对照组的平均结果: ATE_naive = E[Y|T=1] - E[Y|T=0] 问题:如果处理分配不是随机的(存在选择偏差),这个估计会有偏差! 例如:如果我们只向"有可能点击"的用户推荐物品, 那么处理组的用户本身就更倾向于点击,导致高估推荐效果。 参数: treated_data: 处理组数据(被推荐的样本) control_data: 对照组数据(未被推荐的样本) 返回: naive_ate: 朴素估计的平均处理效应 """ treated_mean = np.mean([d['outcome' ] for d in treated_data]) control_mean = np.mean([d['outcome' ] for d in control_data]) return treated_mean - control_mean def estimate_ate_propensity_score (self, data, propensity_scores ): """基于倾向评分的 ATE 估计( Inverse Propensity Score Weighting) 倾向评分方法的核心思想: 1. 估计每个样本被分配到处理组的概率(倾向评分) 2. 使用逆概率加权平衡处理组和对照组的分布 公式: ATE_IPS = E[Y*T/e(X)] - E[Y*(1-T)/(1-e(X))] 其中 e(X) 是倾向评分( propensity score),表示给定特征 X 时被处理的概率 参数: data: 观察数据,包含 user_id, item_id, treatment, outcome propensity_scores: 倾向评分字典,{(user_id, item_id): 概率} 返回: ips_ate: 基于倾向评分的 ATE 估计 """ treated_outcomes = [] control_outcomes = [] for d in data: outcome = d['outcome' ] treatment = d['treatment' ] ps = propensity_scores.get((d['user_id' ], d['item_id' ]), 0.5 ) if treatment == 1 : weight = 1.0 / ps treated_outcomes.append(outcome * weight) else : weight = 1.0 / (1 - ps) control_outcomes.append(outcome * weight) treated_mean = np.mean(treated_outcomes) if treated_outcomes else 0 control_mean = np.mean(control_outcomes) if control_outcomes else 0 return treated_mean - control_mean framework = PotentialOutcomesFramework(n_users=100 , n_items=50 ) observed_data = [] for u in range (100 ): for i in range (50 ): treatment = np.random.randint(0 , 2 ) outcome = framework.observe_outcome(u, i, treatment) observed_data.append({ 'user_id' : u, 'item_id' : i, 'treatment' : treatment, 'outcome' : outcome }) treated_data = [d for d in observed_data if d['treatment' ] == 1 ] control_data = [d for d in observed_data if d['treatment' ] == 0 ] naive_ate = framework.estimate_ate_naive(treated_data, control_data) print (f"朴素 ATE 估计: {naive_ate:.4 f} " )true_ate = np.mean([ framework.compute_ite(u, i) for u in range (100 ) for i in range (50 ) ]) print (f"真实 ATE: {true_ate:.4 f} " )print (f"估计误差: {abs (naive_ate - true_ate):.4 f} " )
代码执行后的关键发现:
朴素估计的准确性 :
如果处理分配是随机的(如本例),朴素估计通常接近真实 ATE
但在真实推荐系统中,推荐决策往往基于预测模型,存在选择偏差
选择偏差会导致朴素估计严重偏离真实 ATE
估计误差的来源 :
随机噪声 :即使是随机分配,由于样本量有限,估计值也会有波动选择偏差 :如果高质量物品更容易被推荐,会高估推荐效果混淆变量 :用户特征、物品特征可能同时影响推荐决策和点击结果 实际应用建议 :
A/B 测试 :通过随机化实验获得无偏的 ATE 估计倾向评分方法 :当无法进行随机化时,使用倾向评分校正选择偏差双重稳健估计 :结合倾向评分和结果模型,提高估计的稳健性
常见陷阱:
忽略选择偏差 :直接比较被推荐和未被推荐物品的表现会严重误导极端权重问题 :倾向评分方法中,极小的倾向评分会导致极大的权重,需要截断混淆 ITE 和 ATE : ITE 无法从数据中识别,只有 ATE
或条件平均处理效应( CATE)可以估计
倾向评分( Propensity Score)
倾向评分是处理选择偏差的重要工具。
直觉:临床试验的启发
想象一个医学研究,要评估新药的效果:
理想情况(随机对照试验):
随机分配:一半患者接受新药(处理组),一半接受安慰剂(对照组)
两组患者在健康状况、年龄、性别等方面应该相似
可以直接对比两组的治疗效果
现实情况(观察性研究):
医生根据病情严重程度决定是否使用新药
病情严重的患者更可能接受新药
问题 :如果直接对比,会发现新药组效果"更差"——但这是因为他们本来病情就更重!
倾向评分的作用:
估计每个患者"被分配到处理组"的概率,然后:
如果一个重症患者接受了安慰剂(本来应该吃药但没吃),给予更高权重
如果一个轻症患者接受了新药(本来不需要但吃了),也给予更高权重
通过调整权重,模拟"随机分配"的效果
在推荐系统中:
处理组 :物品被推荐给用户对照组 :物品没被推荐给用户协变量 X :用户特征、物品特征、上下文特征倾向评分 :给定特征 X,物品被推荐的概率
例子:
用户 Alice(年轻女性,喜欢动作片):
动作片 A 被推荐的概率
爱情片 B 被推荐的概率
如果爱情片 B 被推荐了(尽管概率很低),说明要么:
系统探索了(随机推荐)
B 确实很好,值得打破常规
这种"小概率事件"应该获得更高权重!
定义
倾向评分是给定协变量
符号说明:
-
倾向评分定理( Rosenbaum & Rubin, 1983)
定理内容: 如果满足以下条件:
无混淆假设( Unconfoundedness) :给定
共同支撑( Common
Support) :每个样本都有可能被分配到任一组
直觉理解:
倾向评分把多维特征
在相同倾向评分的样本中,处理分配是"随机的"
可以通过匹配或加权,在倾向评分相同的样本间进行因果推断
逆倾向评分加权( Inverse Propensity Weighting,
IPW)
IPW 的核心思想:用权重补偿非随机分配。
处理组样本(
直觉:
如果
如果
原因 :低概率事件提供了稀缺信息,需要更高权重
对照组样本(
直觉:
如果
如果
ATE 的 IPW 估计:
拆解理解:
相减 :加权处理效应 = 处理组加权均值 -
对照组加权均值
为什么 IPW 有效?
在期望意义上, IPW 可以恢复随机分配的效果:
证明思路(处理组):
对关键洞察: 权重
代码示例:倾向评分估计与应用
代码目的:
实现倾向评分方法,估计每个样本被分配到处理组的概率,并使用逆倾向加权(
IPW)消除选择偏差。
核心方法:
使用逻辑回归或梯度提升树估计倾向评分,然后应用 IPW 计算无偏的 ATE 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 from sklearn.linear_model import LogisticRegressionfrom sklearn.ensemble import GradientBoostingClassifierclass PropensityScoreEstimator : """倾向评分估计器 用于估计倾向评分并应用逆倾向加权( IPW)进行去偏。 """ def __init__ (self, method='logistic' ): """初始化 参数: method: 估计方法,'logistic'或'gbm' """ self.method = method self.model = None def fit (self, X, treatment ): """拟合倾向评分模型 参数: X: 协变量(特征矩阵) treatment: 处理标志( 1=处理, 0=对照) """ if self.method == 'logistic' : self.model = LogisticRegression() elif self.method == 'gbm' : self.model = GradientBoostingClassifier() else : raise ValueError(f"Unknown method: {self.method} " ) self.model.fit(X, treatment) return self def predict_proba (self, X ): """预测倾向评分(被分配到处理组的概率)""" if self.model is None : raise ValueError("Model not fitted" ) return self.model.predict_proba(X)[:, 1 ] def apply_ipw (self, X, treatment, outcome ): """应用逆倾向评分加权 IPW 核心公式: - 处理组权重 = 1 / e(X) - 对照组权重 = 1 / (1 - e(X)) 参数: X: 特征矩阵 treatment: 处理标志 outcome: 结果变量 返回: weighted_outcome: 加权后的结果 weights: 每个样本的权重 """ propensity_scores = self.predict_proba(X) propensity_scores = np.clip(propensity_scores, 0.01 , 0.99 ) weights = np.where(treatment == 1 , 1.0 / propensity_scores, 1.0 / (1 - propensity_scores)) weighted_outcome = outcome * weights return weighted_outcome, weights n_samples = 1000 n_features = 10 X = np.random.randn(n_samples, n_features) true_propensity = 1 / (1 + np.exp(-(X[:, 0 ] + X[:, 1 ]))) treatment = (np.random.random(n_samples) < true_propensity).astype(int ) outcome = (treatment * 0.5 + X[:, 0 ] * 0.3 + np.random.randn(n_samples) * 0.1 ) ps_estimator = PropensityScoreEstimator(method='logistic' ) ps_estimator.fit(X, treatment) estimated_ps = ps_estimator.predict_proba(X) weighted_outcome, weights = ps_estimator.apply_ipw(X, treatment, outcome) print (f"原始结果均值(处理组): {outcome[treatment==1 ].mean():.4 f} " )print (f"原始结果均值(对照组): {outcome[treatment==0 ].mean():.4 f} " )print (f"朴素 ATE 估计: {(outcome[treatment==1 ].mean() - outcome[treatment==0 ].mean()):.4 f} " )print (f"\n 加权结果均值(处理组): {weighted_outcome[treatment==1 ].mean():.4 f} " )print (f"\加权结果均值(对照组): {weighted_outcome[treatment==0 ].mean():.4 f} " )print (f"IPW ATE 估计: {(weighted_outcome[treatment==1 ].mean() - weighted_outcome[treatment==0 ].mean()):.4 f} " )print (f"\n 真实 ATE: 0.5000" )
关键发现: IPW 方法通常能提供比朴素方法更接近真实
ATE 的估计,特别是当处理分配存在混杂因素时。
反事实推理( Counterfactual
Reasoning)
反事实推理是因果推断的核心工具之一,它帮助我们回答"如果情况不同,结果会怎样"的问题。在推荐系统中,反事实推理可以帮助我们理解:如果某个物品被推荐给用户,用户会如何反应?
反事实的定义
反事实(
Counterfactual) 是指与实际情况相反的情况。例如: -
事实:用户
反事实结果
对于用户
个体因果效应
反事实推荐
在推荐系统中,反事实推理可以帮助我们:
识别真正的用户偏好 :区分用户是因为真正喜欢而点击,还是因为位置偏差而点击公平性评估 :评估推荐系统是否对不同群体公平去偏训练 :使用反事实数据训练无偏的推荐模型
代码示例:反事实推荐模型
代码目的:
实现基于反事实推理的推荐模型,用于估计"如果向用户推荐某个物品,用户会如何反应"。这个模型通过显式建模反事实结果和倾向评分,能够从有偏的观察数据中学习无偏的用户偏好,从而提升推荐的公平性和准确性。
整体思路: 1.
构建双网络架构:一个网络预测反事实结果(如果推荐,用户会如何反应),另一个网络预测倾向评分(物品被推荐的概率)
2. 使用双重稳健估计( Doubly
Robust)方法训练模型,结合倾向评分加权和结果预测,只要其中一个模型正确就能得到无偏估计
3. 通过计算个体处理效应( ITE)来评估推荐对每个用户-物品对的影响
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 import torch.nn.functional as Fclass CounterfactualRecommender (nn.Module): """基于反事实推理的推荐模型""" def __init__ (self, n_users, n_items, embedding_dim=64 , hidden_dim=128 ): super (CounterfactualRecommender, self).__init__() self.user_embedding = nn.Embedding(n_users, embedding_dim) self.item_embedding = nn.Embedding(n_items, embedding_dim) self.counterfactual_net = nn.Sequential( nn.Linear(embedding_dim * 2 , hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, 1 ), nn.Sigmoid() ) self.propensity_net = nn.Sequential( nn.Linear(embedding_dim * 2 , hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, 1 ), nn.Sigmoid() ) def forward (self, user_ids, item_ids ): """前向传播""" user_emb = self.user_embedding(user_ids) item_emb = self.item_embedding(item_ids) concat_emb = torch.cat([user_emb, item_emb], dim=1 ) counterfactual_outcome = self.counterfactual_net(concat_emb).squeeze() propensity_score = self.propensity_net(concat_emb).squeeze() return counterfactual_outcome, propensity_score def compute_ite (self, user_ids, item_ids ): """计算个体处理效应""" outcome_treated, _ = self.forward(user_ids, item_ids) outcome_control = torch.zeros_like(outcome_treated) return outcome_treated - outcome_control def train_counterfactual_model (model, dataloader, epochs=20 , lr=0.001 , alpha=0.1 ): """训练反事实推荐模型""" optimizer = torch.optim.Adam(model.parameters(), lr=lr) for epoch in range (epochs): total_loss = 0 for batch in dataloader: user_ids = batch['user_id' ] item_ids = batch['item_id' ] treatments = batch['treatment' ] outcomes = batch['outcome' ] optimizer.zero_grad() counterfactual_outcome, propensity_score = model(user_ids, item_ids) predicted_outcome = counterfactual_outcome ipw_weights = torch.where(treatments == 1 , 1.0 / (propensity_score + 1e-8 ), 1.0 / (1 - propensity_score + 1e-8 )) dr_outcome = (treatments * outcomes / (propensity_score + 1e-8 ) + (1 - treatments) * predicted_outcome - (treatments - propensity_score) / (propensity_score + 1e-8 ) * predicted_outcome) prediction_loss = F.mse_loss(predicted_outcome, outcomes) propensity_loss = F.binary_cross_entropy(propensity_score, treatments.float ()) loss = prediction_loss + alpha * propensity_loss loss.backward() optimizer.step() total_loss += loss.item() print (f"Epoch {epoch+1 } /{epochs} , Loss: {total_loss/len (dataloader):.4 f} " ) return model n_users, n_items = 500 , 300 model = CounterfactualRecommender(n_users, n_items, embedding_dim=32 ) user_ids = torch.randint(0 , n_users, (1000 ,)) item_ids = torch.randint(0 , n_items, (1000 ,)) treatments = torch.randint(0 , 2 , (1000 ,)) outcomes = torch.rand(1000 ) dataset = PositionBiasDataset(user_ids.numpy(), item_ids.numpy(), treatments.numpy(), outcomes.numpy()) dataloader = DataLoader(dataset, batch_size=64 , shuffle=True ) model = train_counterfactual_model(model, dataloader, epochs=20 )
双重稳健估计( Doubly Robust)
双重稳健估计结合了结果回归和倾向评分加权的优点,只要其中一个模型正确,就能得到无偏估计。
公式
其中: -
优势
双重稳健性 :只要倾向评分模型或结果模型其中一个正确,估计就是无偏的效率更高 :比单纯的 IPW 更高效更稳定 :对模型错误更鲁棒
CFairER 框架:因果公平推荐
CFairER( Causal Fairness for
Recommendation)是一个基于因果推断的公平推荐框架,它通过反事实推理来确保推荐系统的公平性。
CFairER 的核心思想
CFairER
的基本思路:公平性应该从因果的角度来定义和实现 。传统的公平性定义(如统计均等)可能无法捕捉真正的公平性,因为不同群体之间的差异可能源于合理的因素(如兴趣差异),而不是歧视。
因果公平性定义
对于受保护属性
其中
CFairER 框架架构
CFairER 框架包括以下组件:
因果图构建 :构建推荐系统的因果图反事实生成 :生成反事实数据公平性约束 :在训练中加入公平性约束公平性评估 :评估推荐系统的公平性
代码示例: CFairER 框架实现
代码目的: 实现 CFairER( Causal Fairness for
Recommendation)框架,这是一个基于因果推断的公平推荐系统。该框架通过反事实推理来确保推荐系统对不同受保护属性群体(如性别、年龄)的公平性,避免因受保护属性导致的歧视性推荐。
整体思路: 1.
构建反事实生成网络:对于每个用户-物品对,生成不同受保护属性值下的反事实结果
2.
计算公平性损失:通过比较不同受保护属性组的结果差异来衡量公平性,差异越小越公平
3.
多目标优化:同时优化推荐准确率和公平性,通过加权组合两个目标进行训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 class CFairERFramework : """CFairER 因果公平推荐框架""" def __init__ (self, n_users, n_items, n_protected_attrs=1 ): self.n_users = n_users self.n_items = n_items self.n_protected_attrs = n_protected_attrs self.user_embedding = nn.Embedding(n_users, 64 ) self.item_embedding = nn.Embedding(n_items, 64 ) self.counterfactual_generator = nn.Sequential( nn.Linear(64 * 2 + n_protected_attrs, 128 ), nn.ReLU(), nn.Linear(128 , 64 ), nn.ReLU(), nn.Linear(64 , 1 ), nn.Sigmoid() ) self.recommendation_net = nn.Sequential( nn.Linear(64 * 2 , 128 ), nn.ReLU(), nn.Linear(128 , 64 ), nn.ReLU(), nn.Linear(64 , 1 ), nn.Sigmoid() ) def generate_counterfactual (self, user_ids, item_ids, protected_attrs, counterfactual_attrs ): """生成反事实数据""" user_emb = self.user_embedding(user_ids) item_emb = self.item_embedding(item_ids) factual_input = torch.cat([user_emb, item_emb, protected_attrs], dim=1 ) factual_outcome = self.counterfactual_generator(factual_input) counterfactual_input = torch.cat([user_emb, item_emb, counterfactual_attrs], dim=1 ) counterfactual_outcome = self.counterfactual_generator(counterfactual_input) return factual_outcome, counterfactual_outcome def compute_fairness_loss (self, user_ids, item_ids, protected_attrs ): """计算公平性损失""" n_samples = len (user_ids) protected_attrs_0 = torch.zeros(n_samples, self.n_protected_attrs) protected_attrs_1 = torch.ones(n_samples, self.n_protected_attrs) _, outcome_0 = self.generate_counterfactual(user_ids, item_ids, protected_attrs, protected_attrs_0) _, outcome_1 = self.generate_counterfactual(user_ids, item_ids, protected_attrs, protected_attrs_1) fairness_loss = F.mse_loss(outcome_0, outcome_1) return fairness_loss def forward (self, user_ids, item_ids ): """推荐预测""" user_emb = self.user_embedding(user_ids) item_emb = self.item_embedding(item_ids) concat_emb = torch.cat([user_emb, item_emb], dim=1 ) recommendation_score = self.recommendation_net(concat_emb).squeeze() return recommendation_score def train_cfairer (model, dataloader, epochs=20 , lr=0.001 , lambda_fairness=0.1 ): """训练 CFairER 模型""" optimizer = torch.optim.Adam(model.parameters(), lr=lr) for epoch in range (epochs): total_loss = 0 for batch in dataloader: user_ids = batch['user_id' ] item_ids = batch['item_id' ] protected_attrs = batch['protected_attr' ] outcomes = batch['outcome' ] optimizer.zero_grad() recommendation_scores = model(user_ids, item_ids) prediction_loss = F.binary_cross_entropy(recommendation_scores, outcomes) fairness_loss = model.compute_fairness_loss(user_ids, item_ids, protected_attrs) total_loss_batch = prediction_loss + lambda_fairness * fairness_loss total_loss_batch.backward() optimizer.step() total_loss += total_loss_batch.item() print (f"Epoch {epoch+1 } /{epochs} , Loss: {total_loss/len (dataloader):.4 f} " ) return model cfairer_model = CFairERFramework(n_users=500 , n_items=300 , n_protected_attrs=1 ) user_ids = torch.randint(0 , 500 , (1000 ,)) item_ids = torch.randint(0 , 300 , (1000 ,)) protected_attrs = torch.randint(0 , 2 , (1000 , 1 )).float () outcomes = torch.randint(0 , 2 , (1000 ,)).float () class FairnessDataset (Dataset ): def __init__ (self, user_ids, item_ids, protected_attrs, outcomes ): self.user_ids = user_ids self.item_ids = item_ids self.protected_attrs = protected_attrs self.outcomes = outcomes def __len__ (self ): return len (self.user_ids) def __getitem__ (self, idx ): return { 'user_id' : self.user_ids[idx], 'item_id' : self.item_ids[idx], 'protected_attr' : self.protected_attrs[idx], 'outcome' : self.outcomes[idx] } fairness_dataset = FairnessDataset(user_ids, item_ids, protected_attrs, outcomes) fairness_dataloader = DataLoader(fairness_dataset, batch_size=64 , shuffle=True ) cfairer_model = train_cfairer(cfairer_model, fairness_dataloader, epochs=20 )
情感偏见去除
在推荐系统中,用户评论的情感倾向可能影响推荐结果。如果系统过度依赖正面评论,可能会忽略那些虽然评分不高但质量很好的物品。情感偏见去除旨在平衡不同情感倾向的评论对推荐的影响。
情感偏见的识别
问题定义
假设物品
情感偏见度量
其中
代码目的:
实现情感偏见去除器,用于检测和消除推荐系统中因过度依赖评论情感倾向而产生的偏见。当系统过度依赖正面评论时,可能会忽略那些虽然评分不高但质量很好的物品,情感偏见去除旨在平衡不同情感倾向的评论对推荐的影响。
整体思路: 1. 使用文本情感分析工具(如
TextBlob)计算每个物品评论的情感分数 2.
检测推荐结果中的情感偏见:分析推荐物品的情感分布是否偏离全局平均 3.
去偏策略:根据物品情感分数与目标情感的偏差重新排序推荐结果,确保推荐的情感分布更加均衡
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 from textblob import TextBlobimport reclass SentimentBiasRemover : """情感偏见去除器""" def __init__ (self ): self.sentiment_scores = {} self.global_sentiment_mean = 0.0 def analyze_sentiment (self, text ): """分析文本情感""" blob = TextBlob(text) return blob.sentiment.polarity def compute_item_sentiment (self, item_reviews ): """计算物品的情感分数""" sentiment_scores = [] for review in item_reviews: sentiment = self.analyze_sentiment(review) sentiment_scores.append(sentiment) return np.mean(sentiment_scores) if sentiment_scores else 0.0 def detect_sentiment_bias (self, recommendations, item_reviews_dict ): """检测情感偏见""" recommendation_sentiments = [] for user_id, item_list in recommendations.items(): for item_id in item_list: if item_id in item_reviews_dict: item_sentiment = self.compute_item_sentiment(item_reviews_dict[item_id]) recommendation_sentiments.append(item_sentiment) if recommendation_sentiments: self.global_sentiment_mean = np.mean(recommendation_sentiments) bias = np.std(recommendation_sentiments) return bias, self.global_sentiment_mean return 0.0 , 0.0 def debias_recommendations (self, recommendations, item_reviews_dict, target_sentiment=None ): """去除情感偏见""" if target_sentiment is None : target_sentiment = self.global_sentiment_mean debiased_recommendations = {} for user_id, item_list in recommendations.items(): item_sentiment_scores = {} for item_id in item_list: if item_id in item_reviews_dict: sentiment = self.compute_item_sentiment(item_reviews_dict[item_id]) sentiment_deviation = abs (sentiment - target_sentiment) item_sentiment_scores[item_id] = sentiment_deviation sorted_items = sorted (item_sentiment_scores.items(), key=lambda x: x[1 ]) debiased_recommendations[user_id] = [item for item, _ in sorted_items] return debiased_recommendations sentiment_remover = SentimentBiasRemover() item_reviews = { 0 : ["Great product!" , "Love it!" , "Amazing quality" ], 1 : ["Not bad" , "Okay" , "Could be better" ], 2 : ["Terrible" , "Waste of money" , "Very disappointed" ], 3 : ["Excellent!" , "Best purchase ever" , "Highly recommend" ], 4 : ["Average" , "Nothing special" , "It's okay" ] } recommendations = { 0 : [0 , 3 ], 1 : [0 , 3 , 4 ], 2 : [1 , 4 ] } bias, mean_sentiment = sentiment_remover.detect_sentiment_bias(recommendations, item_reviews) print (f"情感偏见: {bias:.4 f} " )print (f"平均情感: {mean_sentiment:.4 f} " )debiased_recs = sentiment_remover.debias_recommendations(recommendations, item_reviews) print ("\n 去偏后的推荐:" )for user_id, items in debiased_recs.items(): print (f"用户 {user_id} : {items} " )
曝光偏差处理的高级方法
曝光偏差是推荐系统中最难处理的偏见之一。除了之前介绍的逆倾向评分方法,还有一些更高级的处理方法。
曝光建模( Exposure Modeling)
曝光建模的核心思想是显式地建模物品被曝光给用户的概率,然后在训练和推理时考虑这个概率。
曝光模型
其中
去偏训练
在训练推荐模型时,使用曝光概率进行加权:
代码目的:
实现曝光感知的推荐模型,显式地建模物品被曝光给用户的概率,并在训练和推理时考虑这个概率来消除曝光偏差。与简单的逆倾向评分方法不同,这个模型通过神经网络学习曝光机制,能够更准确地估计曝光概率。
整体思路: 1.
双网络架构:一个网络预测曝光概率,另一个网络预测推荐分数 2.
联合训练:同时优化曝光预测和推荐预测两个任务 3.
逆倾向加权:在训练推荐网络时,使用曝光概率的倒数作为权重,补偿曝光不均衡
4. 推理时去偏:在推理时只使用推荐分数进行排序,忽略曝光偏差的影响
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 class ExposureAwareRecommender (nn.Module): """考虑曝光的推荐模型""" def __init__ (self, n_users, n_items, embedding_dim=64 ): super (ExposureAwareRecommender, self).__init__() self.user_embedding = nn.Embedding(n_users, embedding_dim) self.item_embedding = nn.Embedding(n_items, embedding_dim) self.exposure_net = nn.Sequential( nn.Linear(embedding_dim * 2 , 128 ), nn.ReLU(), nn.Linear(128 , 64 ), nn.ReLU(), nn.Linear(64 , 1 ), nn.Sigmoid() ) self.recommendation_net = nn.Sequential( nn.Linear(embedding_dim * 2 , 128 ), nn.ReLU(), nn.Linear(128 , 64 ), nn.ReLU(), nn.Linear(64 , 1 ), nn.Sigmoid() ) def forward (self, user_ids, item_ids ): """前向传播""" user_emb = self.user_embedding(user_ids) item_emb = self.item_embedding(item_ids) concat_emb = torch.cat([user_emb, item_emb], dim=1 ) exposure_prob = self.exposure_net(concat_emb).squeeze() recommendation_score = self.recommendation_net(concat_emb).squeeze() return exposure_prob, recommendation_score def compute_ipw_weights (self, user_ids, item_ids ): """计算逆倾向权重""" exposure_prob, _ = self.forward(user_ids, item_ids) exposure_prob = torch.clamp(exposure_prob, min =0.01 , max =0.99 ) ipw_weights = 1.0 / exposure_prob return ipw_weights def train_exposure_aware_model (model, dataloader, epochs=20 , lr=0.001 ): """训练曝光感知模型""" optimizer = torch.optim.Adam(model.parameters(), lr=lr) for epoch in range (epochs): total_loss = 0 for batch in dataloader: user_ids = batch['user_id' ] item_ids = batch['item_id' ] exposures = batch['exposure' ] outcomes = batch['outcome' ] optimizer.zero_grad() exposure_prob, recommendation_score = model(user_ids, item_ids) exposure_loss = F.binary_cross_entropy(exposure_prob, exposures.float ()) ipw_weights = model.compute_ipw_weights(user_ids, item_ids) recommendation_loss = F.binary_cross_entropy( recommendation_score, outcomes, weight=ipw_weights ) loss = exposure_loss + recommendation_loss loss.backward() optimizer.step() total_loss += loss.item() print (f"Epoch {epoch+1 } /{epochs} , Loss: {total_loss/len (dataloader):.4 f} " ) return model exposure_model = ExposureAwareRecommender(n_users=500 , n_items=300 , embedding_dim=32 ) user_ids = torch.randint(0 , 500 , (1000 ,)) item_ids = torch.randint(0 , 300 , (1000 ,)) exposures = torch.randint(0 , 2 , (1000 ,)) outcomes = torch.randint(0 , 2 , (1000 ,)).float () class ExposureDataset (Dataset ): def __init__ (self, user_ids, item_ids, exposures, outcomes ): self.user_ids = user_ids self.item_ids = item_ids self.exposures = exposures self.outcomes = outcomes def __len__ (self ): return len (self.user_ids) def __getitem__ (self, idx ): return { 'user_id' : self.user_ids[idx], 'item_id' : self.item_ids[idx], 'exposure' : self.exposures[idx], 'outcome' : self.outcomes[idx] } exposure_dataset = ExposureDataset(user_ids, item_ids, exposures, outcomes) exposure_dataloader = DataLoader(exposure_dataset, batch_size=64 , shuffle=True ) exposure_model = train_exposure_aware_model(exposure_model, exposure_dataloader, epochs=20 )
负采样策略
在推荐系统中,负样本的选择对模型性能有重要影响。传统的随机负采样可能引入曝光偏差,因为未曝光的物品被错误地视为负样本。
去偏负采样
流行度感知负采样 :根据物品流行度进行负采样,避免过度采样热门物品曝光感知负采样 :只从未曝光的物品中采样负样本困难负样本挖掘 :选择那些模型认为相关但实际不相关的物品作为负样本
代码示例:去偏负采样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 class DebiasedNegativeSampler : """去偏负采样器""" def __init__ (self, n_items, exposure_matrix=None , popularity_dist=None ): self.n_items = n_items self.exposure_matrix = exposure_matrix self.popularity_dist = popularity_dist if popularity_dist is None : self.popularity_dist = np.ones(n_items) / n_items def sample_uniform (self, user_id, n_negatives=1 , exclude_items=None ): """均匀负采样""" if exclude_items is None : exclude_items = [] candidates = [i for i in range (self.n_items) if i not in exclude_items] return np.random.choice(candidates, size=n_negatives, replace=False ) def sample_popularity_aware (self, user_id, n_negatives=1 , exclude_items=None , alpha=0.5 ): """流行度感知负采样""" if exclude_items is None : exclude_items = [] candidates = [i for i in range (self.n_items) if i not in exclude_items] candidate_probs = self.popularity_dist[candidates] inverse_popularity = (1.0 / (candidate_probs + 1e-8 )) ** alpha candidate_probs = inverse_popularity / inverse_popularity.sum () return np.random.choice(candidates, size=n_negatives, replace=False , p=candidate_probs) def sample_exposure_aware (self, user_id, n_negatives=1 , exclude_items=None ): """曝光感知负采样""" if self.exposure_matrix is None : return self.sample_uniform(user_id, n_negatives, exclude_items) if exclude_items is None : exclude_items = [] unexposed_items = [ i for i in range (self.n_items) if i not in exclude_items and self.exposure_matrix[user_id, i] == 0 ] if len (unexposed_items) < n_negatives: all_candidates = [i for i in range (self.n_items) if i not in exclude_items] return np.random.choice(all_candidates, size=n_negatives, replace=False ) return np.random.choice(unexposed_items, size=n_negatives, replace=False ) def sample_hard_negatives (self, user_id, model, n_negatives=1 , exclude_items=None , top_k=100 ): """困难负样本挖掘""" if exclude_items is None : exclude_items = [] all_items = [i for i in range (self.n_items) if i not in exclude_items] scores = np.random.random(len (all_items)) top_indices = np.argsort(scores)[-top_k:] hard_negatives = np.random.choice(top_indices, size=min (n_negatives, len (top_indices)), replace=False ) return [all_items[i] for i in hard_negatives] n_items = 1000 popularity_dist = np.random.power(2 , n_items) popularity_dist = popularity_dist / popularity_dist.sum () sampler = DebiasedNegativeSampler(n_items, popularity_dist=popularity_dist) user_id = 0 positive_items = [10 , 20 , 30 ] uniform_negatives = sampler.sample_uniform(user_id, n_negatives=5 , exclude_items=positive_items) pop_aware_negatives = sampler.sample_popularity_aware(user_id, n_negatives=5 , exclude_items=positive_items) print (f"均匀负采样: {uniform_negatives} " )print (f"流行度感知负采样: {pop_aware_negatives} " )
可解释推荐方法
可解释性是推荐系统提升用户信任度的关键。用户不仅想知道推荐了什么,更想知道为什么推荐这些内容。
可解释性的重要性
用户视角
信任度 :用户更信任能够解释推荐理由的系统满意度 :理解推荐原因有助于用户做出更好的决策可控性 :用户可以根据解释调整自己的偏好
系统视角
调试 :可解释性有助于发现模型问题公平性 :可以检查推荐是否公平改进 :理解推荐原因有助于改进模型
可解释性的类型
1. 基于内容的解释
解释为什么推荐某个物品,基于物品的特征: -
"推荐这部电影是因为你喜欢动作片" - "这个商品符合你的价格区间"
2. 基于协同的解释
解释为什么推荐某个物品,基于相似用户的行为: -
"和你相似的用户也喜欢这个" - "购买了这个商品的用户也购买了..."
3. 基于特征的解释
解释哪些特征导致了推荐: - "价格:重要" - "评分:重要" -
"类别:重要"
代码目的:
实现基于内容的可解释推荐系统,不仅生成推荐结果,还为每个推荐生成清晰的解释说明。解释基于物品特征与用户偏好的匹配程度,帮助用户理解为什么某个物品被推荐,从而提升用户信任度和满意度。
整体思路: 1.
特征匹配:计算物品特征与用户画像的匹配度,包括数值特征(如价格、评分)和类别特征(如类型、标签)
2. 相似度计算:对每个特征计算匹配分数,汇总得到总体相似度 3.
解释生成:选择匹配度最高的几个特征,生成自然语言解释,说明推荐理由 4.
排序与返回:根据相似度排序,返回 top-k 推荐结果及其对应的解释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 class ContentBasedExplainableRecommender : """基于内容的可解释推荐系统""" def __init__ (self, item_features, user_profiles ): self.item_features = item_features self.user_profiles = user_profiles def compute_similarity (self, user_id, item_id ): """计算用户-物品相似度""" user_profile = self.user_profiles[user_id] item_features = self.item_features[item_id] matches = {} total_score = 0 for feature, value in item_features.items(): if feature in user_profile: user_value = user_profile[feature] if isinstance (value, (int , float )) and isinstance (user_value, (int , float )): similarity = 1.0 / (1.0 + abs (value - user_value)) elif isinstance (value, str ) and isinstance (user_value, str ): similarity = 1.0 if value == user_value else 0.0 else : similarity = 0.0 matches[feature] = similarity total_score += similarity return total_score, matches def recommend_with_explanation (self, user_id, top_k=5 ): """推荐并生成解释""" item_scores = {} item_explanations = {} for item_id in self.item_features.keys(): score, matches = self.compute_similarity(user_id, item_id) item_scores[item_id] = score top_matches = sorted (matches.items(), key=lambda x: x[1 ], reverse=True )[:3 ] explanation = f"推荐物品 {item_id} ,因为:" explanation_parts = [] for feature, match_score in top_matches: if match_score > 0.5 : explanation_parts.append(f"你的{feature} 偏好与物品匹配(匹配度:{match_score:.2 f} )" ) explanation += ";" .join(explanation_parts) if explanation_parts else "特征匹配度较低" item_explanations[item_id] = explanation sorted_items = sorted (item_scores.items(), key=lambda x: x[1 ], reverse=True )[:top_k] recommendations = [] for item_id, score in sorted_items: recommendations.append({ 'item_id' : item_id, 'score' : score, 'explanation' : item_explanations[item_id] }) return recommendations item_features = { 0 : {'genre' : 'action' , 'year' : 2020 , 'rating' : 4.5 }, 1 : {'genre' : 'comedy' , 'year' : 2019 , 'rating' : 4.0 }, 2 : {'genre' : 'action' , 'year' : 2021 , 'rating' : 4.8 }, 3 : {'genre' : 'drama' , 'year' : 2018 , 'rating' : 4.2 } } user_profiles = { 0 : {'genre' : 'action' , 'year_preference' : 2020 , 'min_rating' : 4.0 } } recommender = ContentBasedExplainableRecommender(item_features, user_profiles) recommendations = recommender.recommend_with_explanation(0 , top_k=3 ) print ("推荐结果及解释:" )for rec in recommendations: print (f"\n 物品 {rec['item_id' ]} : 分数 {rec['score' ]:.4 f} " ) print (f"解释: {rec['explanation' ]} " )
注意力可视化
注意力机制不仅可以提升模型性能,还可以提供可解释性。通过可视化注意力权重,可以看到模型关注哪些特征或历史行为。
代码目的:
实现注意力权重可视化工具,用于分析和展示推荐模型中注意力机制的工作方式。通过可视化注意力权重,可以理解模型在做出推荐决策时关注了哪些特征或历史行为,从而提升模型的可解释性。
整体思路: 1.
热力图可视化:将注意力权重绘制成热力图,直观展示不同物品或特征的注意力分布
2.
时间序列可视化:展示注意力权重随时间的变化趋势,帮助理解用户兴趣的演化
3.
多头注意力可视化:对于多头注意力机制,分别可视化每个注意力头的权重分布
4. 保存与展示:支持将可视化结果保存为图片文件,方便后续分析和报告
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 import matplotlib.pyplot as pltimport seaborn as snsclass AttentionVisualizer : """注意力可视化工具""" def __init__ (self ): pass def visualize_attention_weights (self, attention_weights, item_names=None , save_path=None ): """可视化注意力权重""" if isinstance (attention_weights, torch.Tensor): attention_weights = attention_weights.detach().cpu().numpy() if item_names is None : item_names = [f"Item {i} " for i in range (len (attention_weights))] plt.figure(figsize=(10 , 6 )) sns.heatmap(attention_weights.reshape(1 , -1 ), xticklabels=item_names, yticklabels=['Attention' ], annot=True , fmt='.3f' , cmap='YlOrRd' ) plt.title('Attention Weights Visualization' ) plt.xlabel('Items' ) plt.ylabel('' ) plt.tight_layout() if save_path: plt.savefig(save_path) else : plt.show() def visualize_attention_over_time (self, attention_sequence, timestamps=None , save_path=None ): """可视化时间序列上的注意力""" if isinstance (attention_sequence, torch.Tensor): attention_sequence = attention_sequence.detach().cpu().numpy() if timestamps is None : timestamps = range (len (attention_sequence)) plt.figure(figsize=(12 , 6 )) plt.plot(timestamps, attention_sequence, marker='o' , linewidth=2 , markersize=8 ) plt.fill_between(timestamps, attention_sequence, alpha=0.3 ) plt.title('Attention Weights Over Time' ) plt.xlabel('Time Step' ) plt.ylabel('Attention Weight' ) plt.grid(True , alpha=0.3 ) plt.tight_layout() if save_path: plt.savefig(save_path) else : plt.show() def visualize_multi_head_attention (self, attention_weights, n_heads, item_names=None , save_path=None ): """可视化多头注意力""" if isinstance (attention_weights, torch.Tensor): attention_weights = attention_weights.detach().cpu().numpy() if attention_weights.ndim == 3 : attention_weights = attention_weights.mean(axis=1 ) if item_names is None : item_names = [f"Item {i} " for i in range (attention_weights.shape[1 ])] fig, axes = plt.subplots(1 , n_heads, figsize=(5 *n_heads, 6 )) if n_heads == 1 : axes = [axes] for head in range (n_heads): sns.heatmap(attention_weights[head:head+1 ], xticklabels=item_names, yticklabels=[f'Head {head} ' ], annot=True , fmt='.3f' , cmap='YlOrRd' , ax=axes[head]) axes[head].set_title(f'Attention Head {head} ' ) plt.tight_layout() if save_path: plt.savefig(save_path) else : plt.show() visualizer = AttentionVisualizer() attention_weights = np.array([0.1 , 0.3 , 0.05 , 0.4 , 0.15 ]) item_names = ['Action Movie' , 'Comedy' , 'Drama' , 'Thriller' , 'Romance' ] visualizer.visualize_attention_weights(attention_weights, item_names) attention_sequence = np.array([0.1 , 0.2 , 0.3 , 0.25 , 0.15 ]) visualizer.visualize_attention_over_time(attention_sequence)
LIME 和 SHAP
在推荐系统中的应用
LIME( Local Interpretable Model-agnostic Explanations)和 SHAP(
SHapley Additive
exPlanations)是两种流行的模型无关解释方法,它们可以应用于任何推荐模型,提供局部或全局的解释。
LIME 原理
LIME
的基本思路:在待解释样本的邻域内训练一个简单的可解释模型(如线性模型),用这个简单模型来解释复杂模型的预测。
算法流程
选择要解释的样本$x在
用复杂模型预测这些扰动样本的标签
训练一个简单的可解释模型来拟合这些预测
用简单模型的系数作为解释
数学形式化
其中: -
代码示例: LIME 在推荐系统中的应用
代码目的: 实现基于 LIME( Local Interpretable
Model-agnostic Explanations)的推荐模型解释器。 LIME
是一种模型无关的解释方法,通过在待解释样本的邻域内训练简单的可解释模型(如线性模型)来解释复杂推荐模型的预测结果,帮助用户理解为什么某个物品被推荐。
整体思路: 1. 初始化 LIME
解释器:使用训练数据作为背景数据,创建 LIME 解释器实例 2.
生成扰动样本:在待解释的用户-物品特征周围生成扰动样本 3.
模型预测:使用复杂推荐模型预测这些扰动样本的评分 4.
训练简单模型:用线性模型拟合这些预测,提取特征权重作为解释 5.
可视化解释:展示每个特征对推荐结果的贡献度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 from lime import lime_tabularfrom lime.lime_tabular import LimeTabularExplainerimport pandas as pdclass LIMERecommenderExplainer : """使用 LIME 解释推荐模型""" def __init__ (self, model, training_data, feature_names=None ): self.model = model self.training_data = training_data self.feature_names = feature_names self.explainer = LimeTabularExplainer( training_data.values, feature_names=feature_names, mode='regression' ) def explain_recommendation (self, user_item_features, num_features=10 ): """解释单个推荐""" explanation = self.explainer.explain_instance( user_item_features.values[0 ], self.model.predict, num_features=num_features ) return explanation def explain_user_recommendations (self, user_id, item_features_list, top_k=5 ): """解释用户的所有推荐""" explanations = [] for item_features in item_features_list[:top_k]: explanation = self.explain_recommendation(item_features) explanations.append(explanation) return explanations def visualize_explanation (self, explanation, save_path=None ): """可视化解释""" explanation.show_in_notebook(show_table=True ) if save_path: explanation.save_to_file(save_path) class SimpleRecommender : def __init__ (self ): self.weights = np.random.randn(10 ) def predict (self, X ): if isinstance (X, pd.DataFrame): X = X.values return np.dot(X, self.weights) n_samples = 1000 n_features = 10 training_data = pd.DataFrame(np.random.randn(n_samples, n_features), columns=[f'feature_{i} ' for i in range (n_features)]) model = SimpleRecommender() explainer = LIMERecommenderExplainer( model, training_data, feature_names=[f'feature_{i} ' for i in range (n_features)] ) user_item_features = pd.DataFrame(np.random.randn(1 , n_features), columns=[f'feature_{i} ' for i in range (n_features)]) explanation = explainer.explain_recommendation(user_item_features, num_features=5 ) print ("LIME 解释结果:" )for feature, weight in explanation.as_list(): print (f"{feature} : {weight:.4 f} " )
SHAP 原理
SHAP 基于博弈论中的 Shapley
值,为每个特征分配一个贡献值,表示该特征对预测的贡献。
Shapley 值
对于特征Extra close brace or missing open brace \phi_i = \sum_{S \subseteq F \setminus \{i} } \frac{|S|!(|F|-|S|-1)!}{|F|!} [f(S \cup \{i} ) - f(S)]
其中: -
SHAP 的优势
理论保证 :满足效率性、对称性、虚拟性、可加性等性质统一框架 :可以解释任何模型全局和局部解释 :既可以解释单个预测,也可以解释整体模型
代码目的: 实现基于 SHAP( SHapley Additive
exPlanations)的推荐模型解释器。 SHAP 基于博弈论中的 Shapley
值,为每个特征分配一个贡献值,表示该特征对预测的贡献。与 LIME 相比,
SHAP 具有更强的理论保证,满足效率性、对称性、虚拟性、可加性等性质。
整体思路: 1. 初始化 SHAP
解释器:使用背景数据(训练数据的子集)创建 SHAP 解释器 2. 计算 Shapley
值:对于每个特征,计算其在所有可能的特征组合中的平均边际贡献 3.
生成解释:为每个用户-物品对生成 SHAP 值,表示每个特征对推荐分数的贡献 4.
可视化:使用瀑布图、蜂群图等可视化方法展示特征重要性 5.
特征重要性分析:计算全局特征重要性,识别对推荐结果影响最大的特征
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 import shapclass SHAPRecommenderExplainer : """使用 SHAP 解释推荐模型""" def __init__ (self, model, training_data, background_data=None ): self.model = model self.training_data = training_data if background_data is None : background_data = training_data.sample(min (100 , len (training_data))) self.background_data = background_data self.explainer = shap.Explainer(model, background_data) def explain_recommendation (self, user_item_features ): """解释单个推荐""" shap_values = self.explainer(user_item_features) return shap_values def explain_batch_recommendations (self, user_item_features_batch ): """解释批量推荐""" shap_values = self.explainer(user_item_features_batch) return shap_values def visualize_explanation (self, shap_values, feature_names=None , save_path=None ): """可视化解释""" shap.plots.waterfall(shap_values[0 ], show=False ) if save_path: plt.savefig(save_path) else : plt.show() def visualize_summary (self, shap_values, feature_names=None , save_path=None ): """可视化摘要图""" shap.plots.beeswarm(shap_values, show=False ) if save_path: plt.savefig(save_path) else : plt.show() def get_feature_importance (self, shap_values ): """获取特征重要性""" feature_importance = np.abs (shap_values.values).mean(axis=0 ) return feature_importance shap_explainer = SHAPRecommenderExplainer(model, training_data) shap_values = shap_explainer.explain_recommendation(user_item_features) shap_explainer.visualize_explanation(shap_values) feature_importance = shap_explainer.get_feature_importance(shap_values) print ("\n 特征重要性(按重要性排序):" )sorted_features = sorted (enumerate (feature_importance), key=lambda x: x[1 ], reverse=True ) for idx, importance in sorted_features: print (f"feature_{idx} : {importance:.4 f} " )
LIME vs SHAP
LIME -
优点 :计算快速,易于实现,适合局部解释 -
缺点 :可能不稳定,缺乏理论保证
SHAP -
优点 :理论保证强,统一框架,稳定 -
缺点 :计算成本高,特别是对于复杂模型
选择建议
需要快速解释:使用 LIME
需要理论保证:使用 SHAP
需要全局解释:使用 SHAP
需要局部解释:两者都可以
用户信任度提升
可解释性不仅是技术问题,更是用户体验问题。如何通过可解释性提升用户对推荐系统的信任度,是一个重要的研究方向。
信任度的维度
1. 能力信任( Competence Trust)
用户相信系统有能力做出好的推荐。这可以通过: - 展示推荐准确率 -
显示相似用户的满意度 - 提供推荐历史的表现
2. 善意信任( Benevolence Trust)
用户相信系统是为了用户的利益而推荐。这可以通过: - 解释推荐理由 -
展示系统如何考虑用户偏好 - 提供用户控制选项
3. 诚实信任( Integrity Trust)
用户相信系统是诚实的,不会欺骗用户。这可以通过: - 透明化推荐过程 -
承认不确定性 - 提供反馈机制
代码目的:
实现用户信任度评估与提升系统,通过多维度评估用户对推荐系统的信任度,并根据信任度水平生成个性化的解释,从而提升用户对推荐系统的信任和满意度。信任度包括能力信任(系统能否做好推荐)、善意信任(系统是否为用户利益考虑)、诚实信任(系统是否透明诚实)三个维度。
整体思路: 1.
多维度信任度计算:分别计算能力信任、善意信任、诚实信任三个维度的分数 2.
综合信任度评估:通过加权平均计算总体信任度 3.
个性化解释生成:根据用户当前的信任度水平,生成针对性的解释,弥补信任度较低的维度
4. 反馈机制:根据用户反馈动态调整信任度,形成信任度-解释-反馈的闭环
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 class TrustEnhancementSystem : """用户信任度提升系统""" def __init__ (self ): self.user_trust_scores = {} self.recommendation_history = {} self.user_feedback = {} def compute_competence_trust (self, user_id, recommendation_accuracy ): """计算能力信任""" competence_score = recommendation_accuracy if user_id in self.recommendation_history: historical_accuracy = np.mean([ rec['accuracy' ] for rec in self.recommendation_history[user_id] ]) competence_score = 0.7 * competence_score + 0.3 * historical_accuracy return competence_score def compute_benevolence_trust (self, user_id, explanation_quality, user_control ): """计算善意信任""" explanation_score = explanation_quality control_score = user_control benevolence_score = 0.6 * explanation_score + 0.4 * control_score return benevolence_score def compute_integrity_trust (self, user_id, transparency, uncertainty_acknowledgment ): """计算诚实信任""" transparency_score = transparency uncertainty_score = uncertainty_acknowledgment integrity_score = 0.5 * transparency_score + 0.5 * uncertainty_score return integrity_score def compute_overall_trust (self, user_id, recommendation_accuracy, explanation_quality, user_control, transparency, uncertainty_acknowledgment ): """计算总体信任度""" competence = self.compute_competence_trust(user_id, recommendation_accuracy) benevolence = self.compute_benevolence_trust(user_id, explanation_quality, user_control) integrity = self.compute_integrity_trust(user_id, transparency, uncertainty_acknowledgment) overall_trust = 0.4 * competence + 0.3 * benevolence + 0.3 * integrity self.user_trust_scores[user_id] = { 'overall' : overall_trust, 'competence' : competence, 'benevolence' : benevolence, 'integrity' : integrity } return overall_trust def generate_trust_enhancing_explanation (self, user_id, item_id, recommendation_score ): """生成增强信任的解释""" trust_scores = self.user_trust_scores.get(user_id, {}) explanation_parts = [] if trust_scores.get('competence' , 0 ) < 0.5 : explanation_parts.append("基于你的历史行为,我们推荐这个物品(准确率: 85%)" ) if trust_scores.get('benevolence' , 0 ) < 0.5 : explanation_parts.append("这个推荐考虑了你的偏好:喜欢动作片、评分 4.0 以上" ) if trust_scores.get('integrity' , 0 ) < 0.5 : explanation_parts.append("推荐置信度: 75%(中等置信度,建议你查看详情后决定)" ) explanation = ";" .join(explanation_parts) if explanation_parts else "推荐理由:特征匹配" return explanation def update_trust_from_feedback (self, user_id, feedback ): """根据用户反馈更新信任度""" if user_id not in self.user_feedback: self.user_feedback[user_id] = [] self.user_feedback[user_id].append(feedback) if user_id in self.user_trust_scores: feedback_score = 1.0 if feedback['positive' ] else 0.0 current_trust = self.user_trust_scores[user_id]['overall' ] new_trust = 0.9 * current_trust + 0.1 * feedback_score self.user_trust_scores[user_id]['overall' ] = new_trust trust_system = TrustEnhancementSystem() user_id = 0 overall_trust = trust_system.compute_overall_trust( user_id=user_id, recommendation_accuracy=0.85 , explanation_quality=0.7 , user_control=0.6 , transparency=0.8 , uncertainty_acknowledgment=0.75 ) print (f"用户 {user_id} 的总体信任度: {overall_trust:.4 f} " )print (f"能力信任: {trust_system.user_trust_scores[user_id]['competence' ]:.4 f} " )print (f"善意信任: {trust_system.user_trust_scores[user_id]['benevolence' ]:.4 f} " )print (f"诚实信任: {trust_system.user_trust_scores[user_id]['integrity' ]:.4 f} " )explanation = trust_system.generate_trust_enhancing_explanation( user_id, item_id=10 , recommendation_score=0.85 ) print (f"\n 增强信任的解释: {explanation} " )trust_system.update_trust_from_feedback(user_id, {'positive' : True }) print (f"\n 反馈后的信任度: {trust_system.user_trust_scores[user_id]['overall' ]:.4 f} " )
个性化解释策略
不同用户对解释的需求不同,个性化解释策略可以根据用户特征调整解释方式。
代码目的:
实现个性化解释生成器,根据用户对解释的偏好(详细程度、解释类型等)生成定制化的推荐解释。不同用户对解释的需求不同,有些用户喜欢详细的解释,有些用户偏好简洁的说明,个性化解释能够提升用户体验和满意度。
整体思路: 1.
用户偏好推断:分析用户历史交互行为,推断用户对解释的偏好(详细程度、是否偏好社交解释、是否偏好对比解释等)
2. 解释模板管理:维护多种解释模板(详细、简洁、对比、社交等) 3.
个性化生成:根据用户偏好选择合适的模板和详细程度,生成个性化解释 4.
动态调整:根据用户反馈持续优化解释策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 class PersonalizedExplanationGenerator : """个性化解释生成器""" def __init__ (self ): self.user_preferences = {} self.explanation_templates = { 'detailed' : "推荐{item},因为:{reasons}" , 'simple' : "推荐{item},因为{main_reason}" , 'comparative' : "推荐{item},相比其他选项,它更符合你的偏好" , 'social' : "和你相似的用户也喜欢{item}" } def infer_user_preference (self, user_id, interaction_history ): """推断用户对解释的偏好""" if user_id not in self.user_preferences: self.user_preferences[user_id] = { 'detail_level' : 'medium' , 'prefer_social' : False , 'prefer_comparative' : True } return self.user_preferences[user_id] def generate_personalized_explanation (self, user_id, item_id, item_name, reasons, main_reason=None ): """生成个性化解释""" preferences = self.user_preferences.get(user_id, { 'detail_level' : 'medium' , 'prefer_social' : False , 'prefer_comparative' : True }) detail_level = preferences['detail_level' ] if detail_level == 'high' : explanation = self.explanation_templates['detailed' ].format ( item=item_name, reasons=";" .join(reasons) ) elif detail_level == 'low' : if main_reason is None : main_reason = reasons[0 ] if reasons else "特征匹配" explanation = self.explanation_templates['simple' ].format ( item=item_name, main_reason=main_reason ) else : if preferences.get('prefer_comparative' ): explanation = self.explanation_templates['comparative' ].format ( item=item_name ) elif preferences.get('prefer_social' ): explanation = self.explanation_templates['social' ].format ( item=item_name ) else : explanation = self.explanation_templates['simple' ].format ( item=item_name, main_reason=reasons[0 ] if reasons else "特征匹配" ) return explanation explanation_generator = PersonalizedExplanationGenerator() explanation_generator.user_preferences[0 ] = { 'detail_level' : 'high' , 'prefer_social' : False , 'prefer_comparative' : True } explanation_generator.user_preferences[1 ] = { 'detail_level' : 'low' , 'prefer_social' : True , 'prefer_comparative' : False } explanation_0 = explanation_generator.generate_personalized_explanation( user_id=0 , item_id=10 , item_name="《肖申克的救赎》" , reasons=["你喜欢剧情片" , "评分 4.5 以上" , "1990 年代电影" ], main_reason="你喜欢剧情片" ) explanation_1 = explanation_generator.generate_personalized_explanation( user_id=1 , item_id=10 , item_name="《肖申克的救赎》" , reasons=["你喜欢剧情片" , "评分 4.5 以上" , "1990 年代电影" ], main_reason="你喜欢剧情片" ) print (f"用户 0 的解释: {explanation_0} " )print (f"用户 1 的解释: {explanation_1} " )
完整代码实现:公平可解释推荐系统
下面我们实现一个完整的公平可解释推荐系统,整合前面介绍的各种技术。
代码目的:
实现一个完整的公平可解释推荐系统,整合了公平性约束、曝光偏差校正、可解释性生成等多种技术。该系统能够同时优化推荐准确率、公平性和可解释性,是一个端到端的工业级推荐系统实现。
整体思路: 1.
多网络架构:包含推荐预测网络、曝光预测网络、公平性约束网络和注意力机制
2. 多目标优化:同时优化预测损失、曝光损失和公平性损失 3.
去偏训练:使用逆倾向加权( IPW)消除曝光偏差 4.
公平性约束:通过反事实推理确保不同受保护属性组的公平性 5.
可解释性生成:使用注意力权重生成推荐解释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 import torchimport torch.nn as nnimport torch.nn.functional as Ffrom torch.utils.data import Dataset, DataLoaderimport numpy as npimport pandas as pdfrom sklearn.metrics import ndcg_score, mean_squared_errorclass FairExplainableRecommender (nn.Module): """公平可解释推荐系统""" def __init__ (self, n_users, n_items, n_features, embedding_dim=64 , hidden_dim=128 , use_attention=True ): super (FairExplainableRecommender, self).__init__() self.n_users = n_users self.n_items = n_items self.n_features = n_features self.use_attention = use_attention self.user_embedding = nn.Embedding(n_users, embedding_dim) self.item_embedding = nn.Embedding(n_items, embedding_dim) self.feature_embedding = nn.Embedding(n_features, embedding_dim) if use_attention: self.attention = nn.Sequential( nn.Linear(embedding_dim * 2 , hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, 1 ) ) self.recommendation_net = nn.Sequential( nn.Linear(embedding_dim * 2 , hidden_dim), nn.ReLU(), nn.Dropout(0.2 ), nn.Linear(hidden_dim, hidden_dim // 2 ), nn.ReLU(), nn.Dropout(0.2 ), nn.Linear(hidden_dim // 2 , 1 ), nn.Sigmoid() ) self.exposure_net = nn.Sequential( nn.Linear(embedding_dim * 2 , hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, 1 ), nn.Sigmoid() ) self.fairness_net = nn.Sequential( nn.Linear(embedding_dim * 2 + 1 , hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, 1 ), nn.Sigmoid() ) def forward (self, user_ids, item_ids, protected_attrs=None , return_attention=False ): """前向传播""" user_emb = self.user_embedding(user_ids) item_emb = self.item_embedding(item_ids) attention_weights = None if self.use_attention: concat_emb = torch.cat([user_emb, item_emb], dim=1 ) attention_logits = self.attention(concat_emb) attention_weights = F.softmax(attention_logits, dim=0 ) concat_emb = torch.cat([user_emb, item_emb], dim=1 ) recommendation_score = self.recommendation_net(concat_emb).squeeze() exposure_prob = self.exposure_net(concat_emb).squeeze() fairness_score = None if protected_attrs is not None : fairness_input = torch.cat([concat_emb, protected_attrs], dim=1 ) fairness_score = self.fairness_net(fairness_input).squeeze() if return_attention: return recommendation_score, exposure_prob, fairness_score, attention_weights else : return recommendation_score, exposure_prob, fairness_score def compute_fairness_loss (self, user_ids, item_ids, protected_attrs ): """计算公平性损失""" n_samples = len (user_ids) protected_attrs_0 = torch.zeros(n_samples, 1 ).to(protected_attrs.device) protected_attrs_1 = torch.ones(n_samples, 1 ).to(protected_attrs.device) _, _, fairness_0, _ = self.forward(user_ids, item_ids, protected_attrs_0, return_attention=False ) _, _, fairness_1, _ = self.forward(user_ids, item_ids, protected_attrs_1, return_attention=False ) fairness_loss = F.mse_loss(fairness_0, fairness_1) return fairness_loss def get_explanation (self, user_ids, item_ids, feature_names=None ): """获取推荐解释""" _, _, _, attention_weights = self.forward(user_ids, item_ids, return_attention=True ) if attention_weights is not None : if feature_names is None : feature_names = [f"feature_{i} " for i in range (len (attention_weights))] explanations = [] for i, (user_id, item_id) in enumerate (zip (user_ids, item_ids)): explanation = { 'user_id' : user_id.item(), 'item_id' : item_id.item(), 'attention_weights' : attention_weights[i].detach().cpu().numpy(), 'top_features' : [] } top_indices = np.argsort(attention_weights[i].detach().cpu().numpy())[-5 :][::-1 ] for idx in top_indices: explanation['top_features' ].append({ 'feature' : feature_names[idx], 'weight' : attention_weights[i][idx].item() }) explanations.append(explanation) return explanations return None class RecommendationDataset (Dataset ): """推荐数据集""" def __init__ (self, user_ids, item_ids, ratings, exposures=None , protected_attrs=None ): self.user_ids = torch.LongTensor(user_ids) self.item_ids = torch.LongTensor(item_ids) self.ratings = torch.FloatTensor(ratings) self.exposures = torch.LongTensor(exposures) if exposures is not None else None self.protected_attrs = torch.FloatTensor(protected_attrs) if protected_attrs is not None else None def __len__ (self ): return len (self.user_ids) def __getitem__ (self, idx ): item = { 'user_id' : self.user_ids[idx], 'item_id' : self.item_ids[idx], 'rating' : self.ratings[idx] } if self.exposures is not None : item['exposure' ] = self.exposures[idx] if self.protected_attrs is not None : item['protected_attr' ] = self.protected_attrs[idx] return item def train_fair_explainable_model (model, dataloader, epochs=20 , lr=0.001 , lambda_fairness=0.1 , lambda_exposure=0.1 ): """训练公平可解释模型""" optimizer = torch.optim.Adam(model.parameters(), lr=lr) for epoch in range (epochs): total_loss = 0 total_pred_loss = 0 total_fairness_loss = 0 total_exposure_loss = 0 for batch in dataloader: user_ids = batch['user_id' ] item_ids = batch['item_id' ] ratings = batch['rating' ] exposures = batch.get('exposure' , None ) protected_attrs = batch.get('protected_attr' , None ) optimizer.zero_grad() if protected_attrs is not None : recommendation_scores, exposure_probs, fairness_scores = model( user_ids, item_ids, protected_attrs ) else : recommendation_scores, exposure_probs, fairness_scores = model( user_ids, item_ids ) prediction_loss = F.binary_cross_entropy(recommendation_scores, ratings) exposure_loss = 0 if exposures is not None : exposure_loss = F.binary_cross_entropy(exposure_probs, exposures.float ()) fairness_loss = 0 if protected_attrs is not None : fairness_loss = model.compute_fairness_loss(user_ids, item_ids, protected_attrs) if exposures is not None : ipw_weights = 1.0 / (exposure_probs + 1e-8 ) prediction_loss = (prediction_loss * ipw_weights).mean() total_loss_batch = (prediction_loss + lambda_exposure * exposure_loss + lambda_fairness * fairness_loss) total_loss_batch.backward() optimizer.step() total_loss += total_loss_batch.item() total_pred_loss += prediction_loss.item() if isinstance (exposure_loss, torch.Tensor): total_exposure_loss += exposure_loss.item() if isinstance (fairness_loss, torch.Tensor): total_fairness_loss += fairness_loss.item() print (f"Epoch {epoch+1 } /{epochs} " ) print (f" Total Loss: {total_loss/len (dataloader):.4 f} " ) print (f" Prediction Loss: {total_pred_loss/len (dataloader):.4 f} " ) if total_exposure_loss > 0 : print (f" Exposure Loss: {total_exposure_loss/len (dataloader):.4 f} " ) if total_fairness_loss > 0 : print (f" Fairness Loss: {total_fairness_loss/len (dataloader):.4 f} " ) return model def evaluate_model (model, test_dataloader, k=10 ): """评估模型""" model.eval () all_user_ids = [] all_item_ids = [] all_predictions = [] all_ratings = [] with torch.no_grad(): for batch in test_dataloader: user_ids = batch['user_id' ] item_ids = batch['item_id' ] ratings = batch['rating' ] recommendation_scores, _, _ = model(user_ids, item_ids) all_user_ids.extend(user_ids.cpu().numpy()) all_item_ids.extend(item_ids.cpu().numpy()) all_predictions.extend(recommendation_scores.cpu().numpy()) all_ratings.extend(ratings.cpu().numpy()) df = pd.DataFrame({ 'user_id' : all_user_ids, 'item_id' : all_item_ids, 'prediction' : all_predictions, 'rating' : all_ratings }) ndcg_scores = [] for user_id in df['user_id' ].unique(): user_df = df[df['user_id' ] == user_id].sort_values('prediction' , ascending=False ) if len (user_df) >= k: y_true = user_df['rating' ].values[:k] y_score = user_df['prediction' ].values[:k] ndcg = ndcg_score([y_true], [y_score], k=k) ndcg_scores.append(ndcg) avg_ndcg = np.mean(ndcg_scores) if ndcg_scores else 0.0 rmse = np.sqrt(mean_squared_error(all_ratings, all_predictions)) return {'ndcg@10' : avg_ndcg, 'rmse' : rmse} n_users, n_items, n_features = 500 , 300 , 10 n_samples = 5000 user_ids = np.random.randint(0 , n_users, n_samples) item_ids = np.random.randint(0 , n_items, n_samples) ratings = np.random.randint(0 , 2 , n_samples).astype(float ) exposures = np.random.randint(0 , 2 , n_samples) protected_attrs = np.random.randint(0 , 2 , (n_samples, 1 )).astype(float ) train_dataset = RecommendationDataset(user_ids, item_ids, ratings, exposures, protected_attrs) train_dataloader = DataLoader(train_dataset, batch_size=64 , shuffle=True ) model = FairExplainableRecommender(n_users, n_items, n_features, embedding_dim=32 , hidden_dim=64 ) model = train_fair_explainable_model(model, train_dataloader, epochs=20 , lambda_fairness=0.1 , lambda_exposure=0.1 ) test_dataset = RecommendationDataset(user_ids[:1000 ], item_ids[:1000 ], ratings[:1000 ], exposures[:1000 ], protected_attrs[:1000 ]) test_dataloader = DataLoader(test_dataset, batch_size=64 ) metrics = evaluate_model(model, test_dataloader) print (f"\n 模型评估结果:" )print (f"NDCG@10: {metrics['ndcg@10' ]:.4 f} " )print (f"RMSE: {metrics['rmse' ]:.4 f} " )sample_user_ids = torch.LongTensor([0 , 1 , 2 ]) sample_item_ids = torch.LongTensor([10 , 20 , 30 ]) explanations = model.get_explanation(sample_user_ids, sample_item_ids) print ("\n 推荐解释:" )for exp in explanations: print (f"\n 用户 {exp['user_id' ]} - 物品 {exp['item_id' ]} :" ) print (" 最重要的特征:" ) for feat in exp['top_features' ]: print (f" {feat['feature' ]} : {feat['weight' ]:.4 f} " )
常见问题与解答( Q&A)
Q1:
为什么推荐系统中存在这么多偏见?
A: 推荐系统中的偏见主要源于以下几个方面:
数据偏差 :训练数据本身就存在偏差。热门物品有更多的交互记录,位置靠前的物品更容易被点击,这些都会在数据中留下痕迹。
反馈循环 :推荐系统会根据用户反馈不断优化,但如果初始推荐就有偏差,这种偏差会被放大,形成正反馈循环。
优化目标单一 :传统推荐系统只优化准确率(如点击率、转化率),忽略了公平性、多样性等目标。
缺乏反事实数据 :我们只能观察到用户对已推荐物品的反馈,无法知道用户对未推荐物品的真实偏好。
代码示例:演示偏见如何产生
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 def demonstrate_bias_formation (): """演示偏见如何形成""" true_quality = np.random.uniform(0 , 1 , 100 ) initial_recommendations = np.random.choice(100 , size=10 , replace=False ) feedback = {} for item_id in initial_recommendations: feedback[item_id] = np.random.random() < true_quality[item_id] item_scores = {} for item_id in range (100 ): if item_id in feedback: item_scores[item_id] = 1.0 if feedback[item_id] else 0.0 else : item_scores[item_id] = 0.5 next_recommendations = sorted (item_scores.items(), key=lambda x: x[1 ], reverse=True )[:10 ] next_recommendations = [item_id for item_id, _ in next_recommendations] print ("初始推荐(随机):" , initial_recommendations[:5 ]) print ("下一轮推荐(有偏):" , next_recommendations[:5 ]) print ("\n 偏见形成:系统倾向于推荐已经推荐过的物品" ) demonstrate_bias_formation()
Q2:
因果推断和传统机器学习方法有什么区别?
A: 主要区别在于:
目标不同 :
传统机器学习:预测
因果推断:估计
相关性 vs 因果性 :
传统方法:学习相关性("如果
因果推断:识别因果关系("因为
处理混淆 :
传统方法:可能被混淆变量误导
因果推断:通过设计(如随机实验)或方法(如倾向评分)控制混淆
反事实推理 :
传统方法:无法回答"如果情况不同会怎样"
因果推断:可以估计反事实结果
示例 :在推荐系统中,传统方法可能发现"位置靠前的物品点击率高",但无法区分这是因为物品质量高还是位置偏差。因果推断可以通过反事实推理来分离这两种效应。
Q3: 如何平衡公平性和准确率?
A: 这是一个经典的权衡问题。有几种策略:
多目标优化 :同时优化准确率和公平性
其中
约束优化 :在公平性约束下优化准确率
后处理 :先训练准确率高的模型,再调整以满足公平性约束
公平性感知训练 :在训练过程中就考虑公平性
代码示例:公平性-准确率权衡
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 def fairness_accuracy_tradeoff (model, dataloader, lambda_values=[0.0 , 0.1 , 0.5 , 1.0 ] ): """探索公平性-准确率权衡""" results = [] for lambda_fair in lambda_values: metrics = { 'lambda' : lambda_fair, 'accuracy' : 0.85 - 0.1 * lambda_fair, 'fairness' : 0.5 + 0.3 * lambda_fair } results.append(metrics) df = pd.DataFrame(results) print ("公平性-准确率权衡:" ) print (df) plt.figure(figsize=(8 , 6 )) plt.plot(df['fairness' ], df['accuracy' ], marker='o' , linewidth=2 , markersize=8 ) plt.xlabel('Fairness Score' ) plt.ylabel('Accuracy' ) plt.title('Fairness-Accuracy Tradeoff' ) plt.grid(True , alpha=0.3 ) for i, row in df.iterrows(): plt.annotate(f"λ={row['lambda' ]} " , (row['fairness' ], row['accuracy' ]), xytext=(5 , 5 ), textcoords='offset points' ) plt.tight_layout() plt.show() fairness_accuracy_tradeoff(None , None )
Q4: LIME 和 SHAP 哪个更好?
A: 这取决于具体场景:
选择 LIME 如果: - 需要快速解释 - 计算资源有限 -
只需要局部解释 - 模型比较简单
选择 SHAP 如果: - 需要理论保证 - 需要全局解释 -
需要统一框架解释不同模型 - 计算资源充足
实际建议 : - 可以先尝试
LIME,如果结果不稳定或需要更强理论保证,再使用 SHAP - 也可以两者结合:用
LIME 做快速解释,用 SHAP 做深度分析
Q5: 如何评估推荐系统的公平性?
A: 公平性评估可以从多个维度进行:
统计均等( Statistical Parity) :
不同受保护组的推荐率应该相同。
机会均等( Equalized Odds) :
在真实标签相同的条件下,不同组的推荐率应该相同。
个体公平性( Individual Fairness) :
相似的个体应该得到相似的推荐。
因果公平性( Causal Fairness) :
使用反事实推理评估公平性。
代码示例:公平性评估
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def evaluate_fairness (recommendations, protected_attrs, protected_groups=[0 , 1 ] ): """评估推荐系统的公平性""" fairness_metrics = {} recommendation_rates = {} for group in protected_groups: group_mask = protected_attrs == group group_recommendations = recommendations[group_mask] recommendation_rates[group] = group_recommendations.mean() statistical_parity = abs (recommendation_rates[0 ] - recommendation_rates[1 ]) fairness_metrics['statistical_parity' ] = statistical_parity from scipy.stats import gini gini_coefficient = gini(recommendations) fairness_metrics['gini_coefficient' ] = gini_coefficient return fairness_metrics recommendations = np.random.randint(0 , 2 , 1000 ) protected_attrs = np.random.randint(0 , 2 , 1000 ) metrics = evaluate_fairness(recommendations, protected_attrs) print ("公平性指标:" )for metric, value in metrics.items(): print (f" {metric} : {value:.4 f} " )
Q6: 可解释性会影响模型性能吗?
A: 这取决于实现方式:
内置可解释性 (如注意力机制):
通常不会降低性能,甚至可能提升
注意力机制本身就是模型的一部分
后处理解释 (如 LIME/SHAP):
不影响模型性能(只是解释,不改变模型)
但计算解释需要额外时间
简化模型以提升可解释性 :
最佳实践 : - 优先使用内置可解释性(如注意力) -
只在需要时使用后处理解释 - 通过实验找到可解释性和性能的平衡点
Q7:
如何处理推荐系统中的冷启动问题?
A: 冷启动问题可以从公平性和可解释性角度来解决:
公平性角度 :
新物品/新用户缺乏数据,可能被系统忽视
需要确保新物品有足够的曝光机会
可解释性角度 :
向用户解释为什么推荐新物品
例如:"这是新上架的商品,符合你的偏好"
技术方法 :
内容特征 :使用物品的内容特征(文本、图像等)探索-利用平衡 :在推荐已知好物品和探索新物品之间平衡跨域迁移 :从其他领域迁移知识
代码示例:冷启动处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class ColdStartHandler : """冷启动处理器""" def __init__ (self, exploration_rate=0.1 ): self.exploration_rate = exploration_rate self.item_interaction_counts = {} def is_cold_start_item (self, item_id, threshold=10 ): """判断是否是冷启动物品""" return self.item_interaction_counts.get(item_id, 0 ) < threshold def recommend_with_exploration (self, user_id, candidate_items, base_scores ): """带探索的推荐""" cold_start_items = [i for i in candidate_items if self.is_cold_start_item(i)] adjusted_scores = base_scores.copy() for item_id in cold_start_items: adjusted_scores[item_id] += self.exploration_rate sorted_items = sorted (enumerate (adjusted_scores), key=lambda x: x[1 ], reverse=True ) return [item_id for item_id, _ in sorted_items] def generate_cold_start_explanation (self, item_id ): """生成冷启动物品的解释""" if self.is_cold_start_item(item_id): return f"这是新上架的商品,虽然互动较少,但符合你的偏好特征" else : return None handler = ColdStartHandler(exploration_rate=0.15 ) candidate_items = list (range (100 )) base_scores = np.random.random(100 ) recommendations = handler.recommend_with_exploration(0 , candidate_items, base_scores) print (f"推荐前 5 个物品: {recommendations[:5 ]} " )for item_id in recommendations[:5 ]: explanation = handler.generate_cold_start_explanation(item_id) if explanation: print (f"物品 {item_id} : {explanation} " )
Q8:
如何在实际系统中部署公平可解释推荐?
A: 部署时需要考虑:
离线评估 :
在测试集上评估公平性和可解释性
使用 A/B 测试验证改进效果
在线监控 :
渐进式部署 :
用户反馈循环 :
代码示例:部署监控系统
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 class DeploymentMonitor : """部署监控系统""" def __init__ (self ): self.recommendation_logs = [] self.fairness_metrics_history = [] self.user_feedback = [] def log_recommendation (self, user_id, item_id, score, explanation, protected_attr=None ): """记录推荐""" log_entry = { 'timestamp' : pd.Timestamp.now(), 'user_id' : user_id, 'item_id' : item_id, 'score' : score, 'explanation' : explanation, 'protected_attr' : protected_attr } self.recommendation_logs.append(log_entry) def compute_daily_fairness (self ): """计算每日公平性指标""" if not self.recommendation_logs: return None df = pd.DataFrame(self.recommendation_logs) today = pd.Timestamp.now().date() today_logs = df[df['timestamp' ].dt.date == today] if len (today_logs) == 0 : return None if 'protected_attr' in today_logs.columns: protected_attrs = today_logs['protected_attr' ].dropna() recommendations = today_logs['score' ].values if len (protected_attrs) > 0 : metrics = evaluate_fairness(recommendations[:len (protected_attrs)], protected_attrs.values) metrics['date' ] = today self.fairness_metrics_history.append(metrics) return metrics return None def get_user_feedback_stats (self ): """获取用户反馈统计""" if not self.user_feedback: return None df = pd.DataFrame(self.user_feedback) positive_rate = df['positive' ].mean() explanation_satisfaction = df.get('explanation_satisfaction' , pd.Series()).mean() return { 'positive_rate' : positive_rate, 'explanation_satisfaction' : explanation_satisfaction, 'total_feedback' : len (df) } monitor = DeploymentMonitor() for i in range (100 ): monitor.log_recommendation( user_id=i % 50 , item_id=np.random.randint(0 , 100 ), score=np.random.random(), explanation=f"推荐理由 {i} " , protected_attr=np.random.randint(0 , 2 ) ) fairness_metrics = monitor.compute_daily_fairness() if fairness_metrics: print ("今日公平性指标:" ) for metric, value in fairness_metrics.items(): if metric != 'date' : print (f" {metric} : {value:.4 f} " )
Q9:
推荐系统的公平性和多样性有什么关系?
A: 公平性和多样性既有联系又有区别:
联系 : - 都关注推荐分布的均衡性 -
提升多样性可能有助于公平性(避免过度推荐热门物品) - 但两者目标不同
区别 : -
多样性 :关注推荐物品的差异性(避免重复推荐相似物品) -
公平性 :关注不同用户/物品组是否得到公平对待
关系 : - 高多样性不一定意味着高公平性 -
高公平性通常需要一定的多样性 - 两者可以同时优化
代码示例:多样性与公平性的关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def compute_diversity (recommendations, item_features ): """计算推荐多样性""" if len (recommendations) < 2 : return 0.0 distances = [] for i in range (len (recommendations)): for j in range (i+1 , len (recommendations)): item_i = recommendations[i] item_j = recommendations[j] if item_i in item_features and item_j in item_features: feat_i = item_features[item_i] feat_j = item_features[item_j] distance = np.linalg.norm(np.array(feat_i) - np.array(feat_j)) distances.append(distance) return np.mean(distances) if distances else 0.0 recommendations_diverse = [0 , 50 , 100 , 150 , 200 ] recommendations_fair = [10 , 30 , 50 , 70 , 90 ] item_features = {i: [np.random.random()] for i in range (250 )} diversity_diverse = compute_diversity(recommendations_diverse, item_features) diversity_fair = compute_diversity(recommendations_fair, item_features) print (f"高多样性推荐多样性: {diversity_diverse:.4 f} " )print (f"公平推荐多样性: {diversity_fair:.4 f} " )print ("\n 说明:多样性和公平性可以独立优化,也可以同时优化" )
Q10:
如何向非技术用户解释推荐系统的公平性和可解释性?
A: 需要将技术概念转化为用户能理解的语言:
公平性 :
"系统会公平对待所有用户,不会因为某些特征而歧视"
"不同群体的用户都能获得合适的推荐"
可解释性 :
"我们会告诉你为什么推荐这些内容"
"可以看到推荐是基于你的哪些偏好"
使用示例和可视化 :
示例解释文案 :
1 2 3 4 5 6 7 8 9 10 公平性说明: "我们的推荐系统致力于为所有用户提供公平、个性化的推荐。 无论您的背景如何,系统都会根据您的真实偏好进行推荐, 不会因为任何个人特征而产生偏见。" 可解释性说明: "每次推荐,我们都会告诉您推荐的理由。 例如,如果您看到一部电影被推荐,我们会说明: '推荐这部电影是因为您喜欢动作片,且评分在 4.0 以上。' 这样您就能理解并信任我们的推荐。"
总结
本文深入探讨了推荐系统中的公平性和可解释性问题。我们从推荐系统中的各种偏见类型开始,理解了选择偏差、位置偏差、曝光偏差、流行度偏差等问题的本质;然后引入了因果推断的理论框架,学习了如何通过反事实推理来识别和消除偏见;接着探讨了
CFairER
框架、情感偏见去除、曝光偏差处理等前沿方法;最后深入了可解释推荐的各种技术,包括注意力可视化、
LIME/SHAP 等模型解释方法,以及如何通过可解释性提升用户信任度。
公平性和可解释性不仅是技术问题,更是影响用户体验和系统可信度的关键因素。随着推荐系统在各个领域的广泛应用,这些问题的重要性将日益凸显。希望本文能够帮助读者理解这些概念,并在实际应用中构建更加公平、可解释的推荐系统。
未来研究方向包括: 1.
更高效的因果推断方法 :降低计算成本,提高可扩展性 2.
个性化公平性 :根据用户偏好调整公平性定义 3.
多模态可解释性 :结合文本、图像等多种形式的解释 4.
实时公平性监控 :在系统运行过程中实时检测和纠正不公平问题
5. 跨领域公平性 :确保推荐系统在不同领域都保持公平
通过持续的研究和实践,我们相信能够构建出既准确又公平、既智能又可解释的推荐系统,真正服务于用户的需求。