推荐系统在数据稀疏性和冷启动问题上一直面临巨大挑战。传统的监督学习方法严重依赖大量标注数据,而在推荐场景中,用户-物品交互数据往往存在严重的类别不平衡和长尾分布问题。对比学习( Contrastive Learning)和自监督学习( Self-Supervised Learning)的兴起为这些问题提供了新的解决思路。
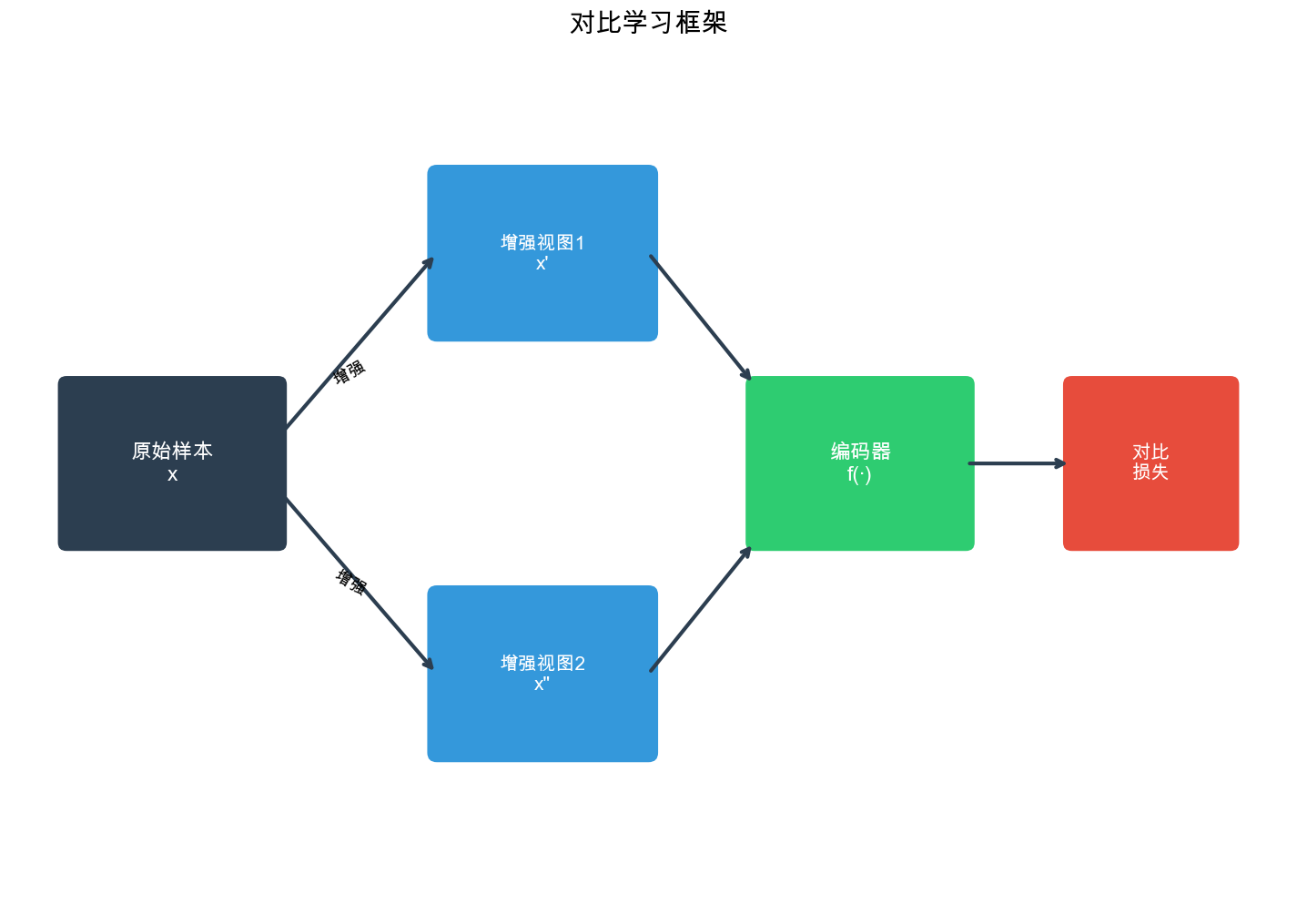
对比学习的核心思想是通过学习区分相似样本和不相似样本来学习有效的表示,而无需显式的标签。在推荐系统中,可以将同一用户的不同行为视图视为正样本对,将不同用户的行为视为负样本对,从而学习到更好的用户和物品表示。自监督学习则通过设计巧妙的预训练任务,从数据本身挖掘监督信号,显著提升了模型在数据稀疏场景下的表现。
本文将深入探讨对比学习和自监督学习在推荐系统中的应用,涵盖从理论基础到最新实践的完整路径。我们将详细解析 SimCLR 、 SGL 、 XSimGCL 等经典框架,探讨图数据增强策略、序列推荐中的对比学习应用,以及如何利用这些技术解决长尾物品推荐问题。文章将包含丰富的代码实现和实际案例,帮助读者深入理解这些前沿技术的设计思想和实现细节。
自监督学习基础
什么是自监督学习
自监督学习( Self-Supervised Learning)是一种无需人工标注数据就能学习数据表示的方法。它通过设计预测任务,从数据本身生成监督信号,从而学习到有用的特征表示。
在推荐系统中,自监督学习的基本思路:利用数据的内在结构来构造监督信号。例如,可以预测用户的下一个交互物品,或者预测图中被遮挡的边,这些任务都不需要额外的标注数据。
自监督学习与监督学习的区别
监督学习: - 需要大量标注数据(如用户对物品的显式评分) - 标注成本高,数据获取困难 - 容易过拟合到标注数据的分布
自监督学习: - 无需人工标注,利用数据本身的结构 - 可以充分利用大量无标注数据 - 学习到的表示更具泛化能力
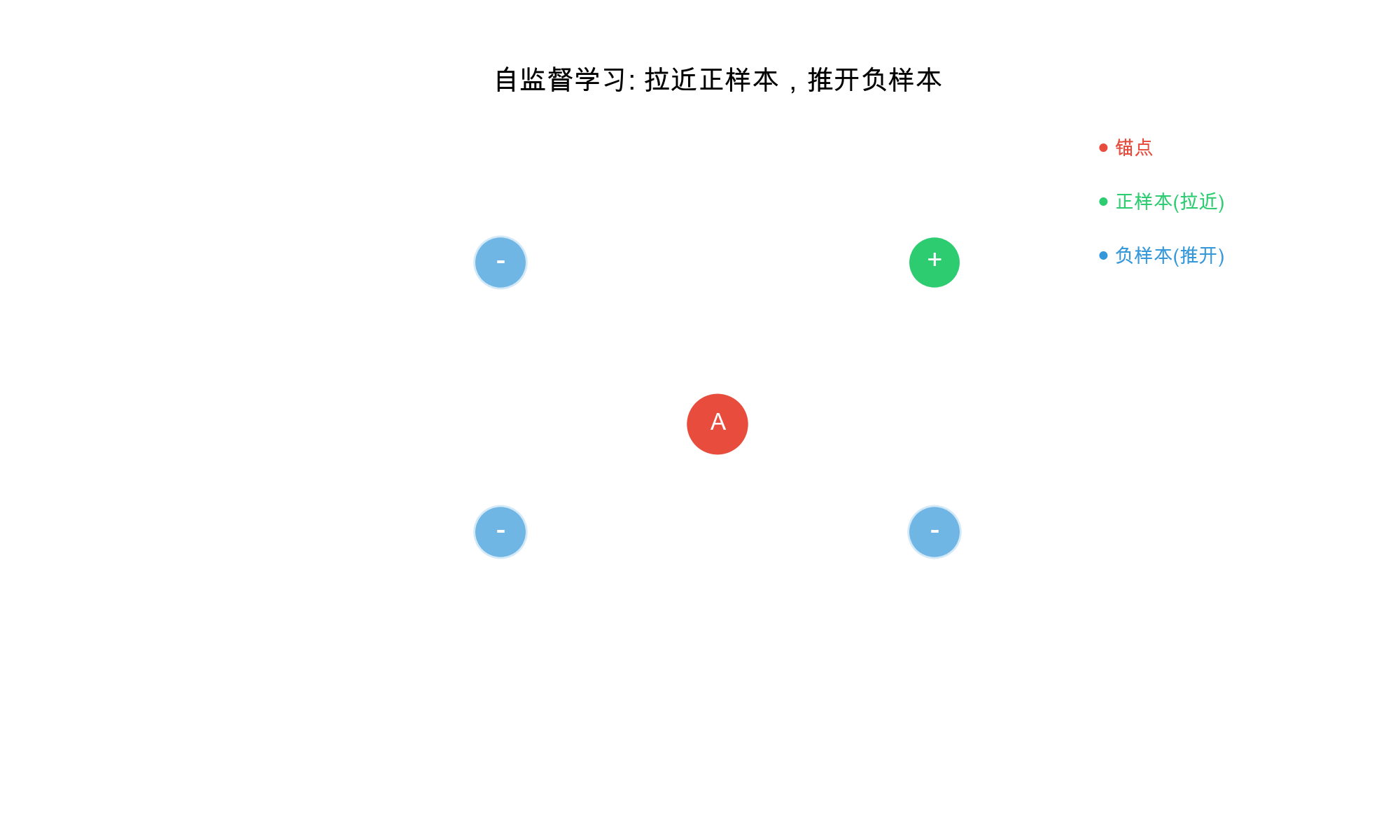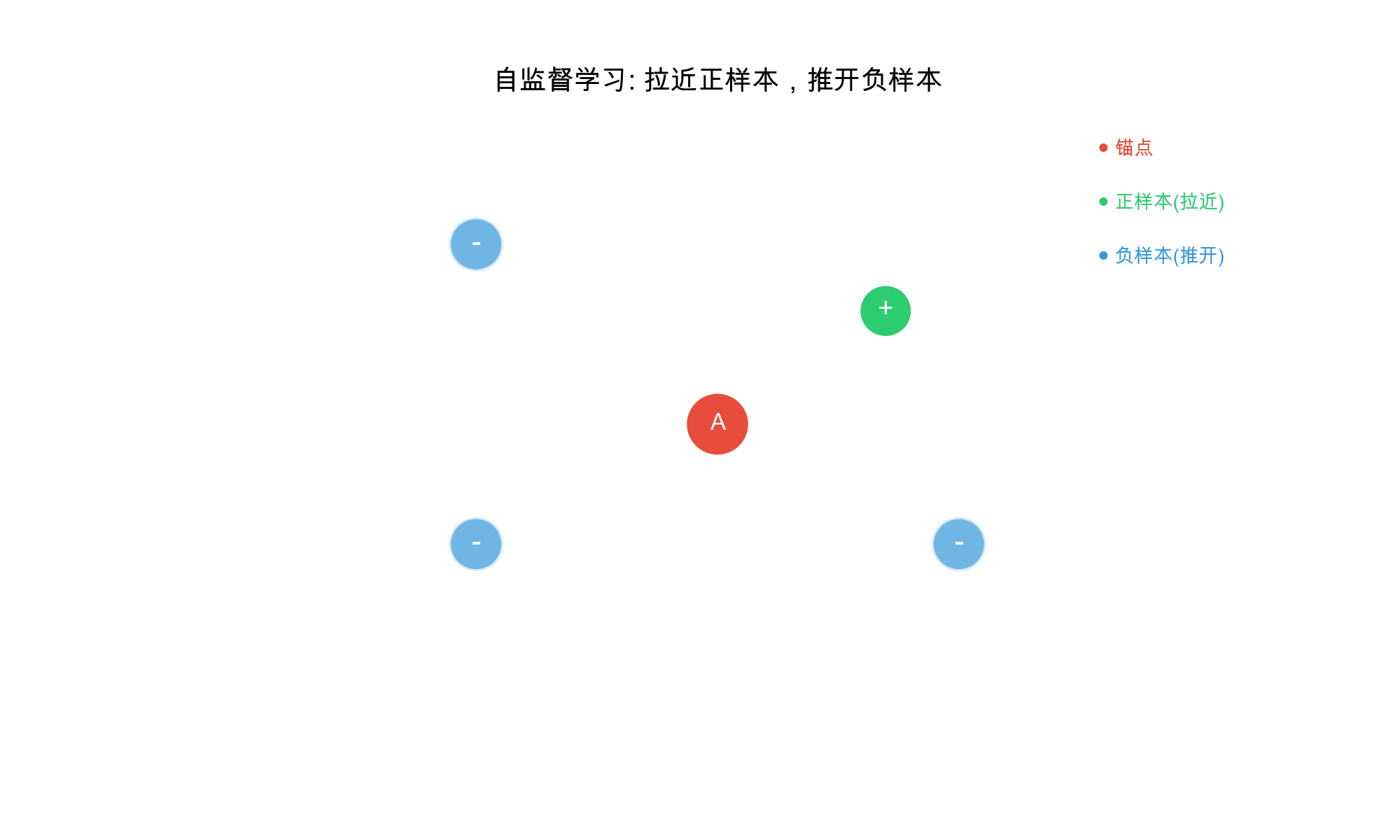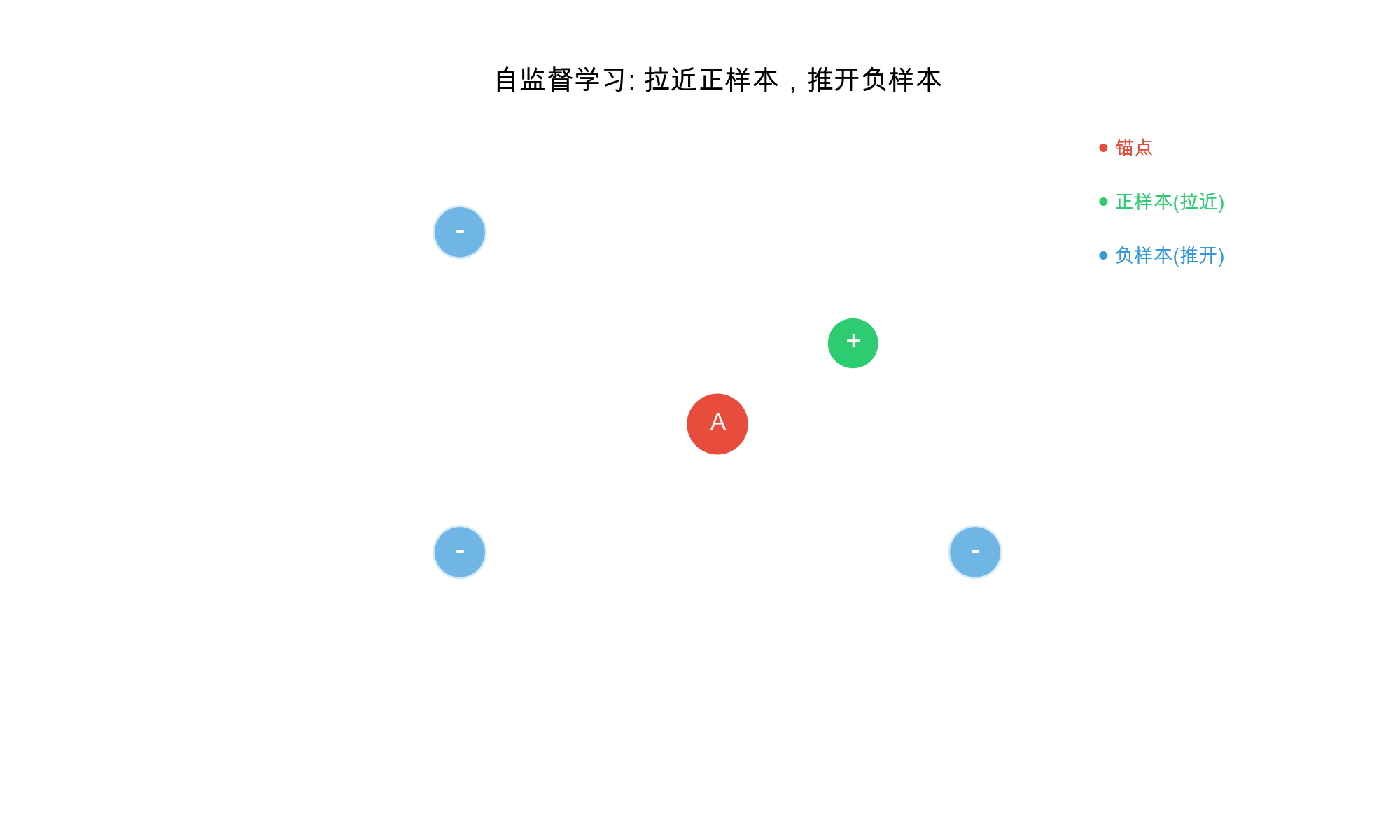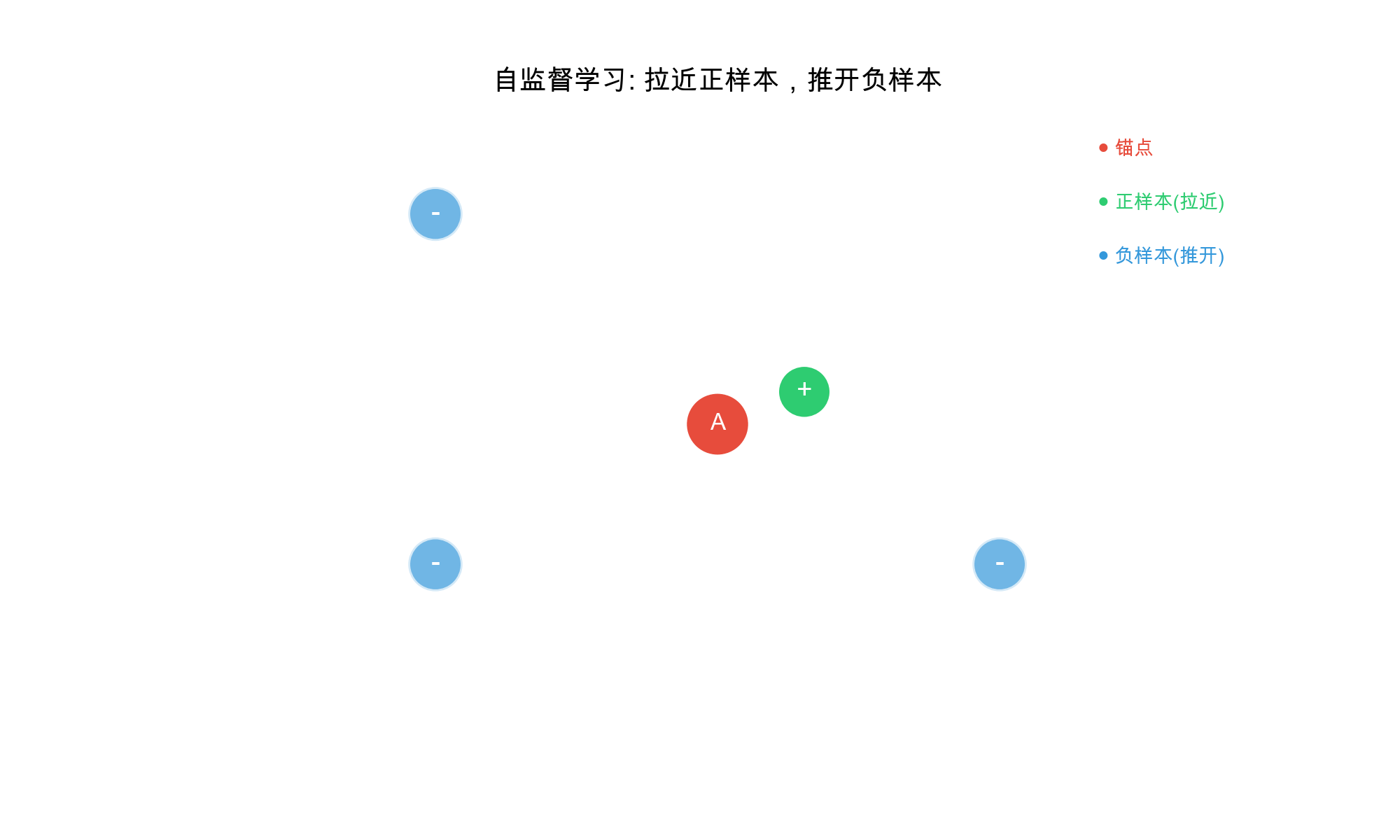
自监督学习的核心组件
自监督学习通常包含三个核心组件:
- 数据增强( Data Augmentation):通过变换原始数据生成不同的视图
- 编码器( Encoder):将增强后的数据映射到表示空间
- 对比目标( Contrastive Objective):通过对比不同视图学习表示
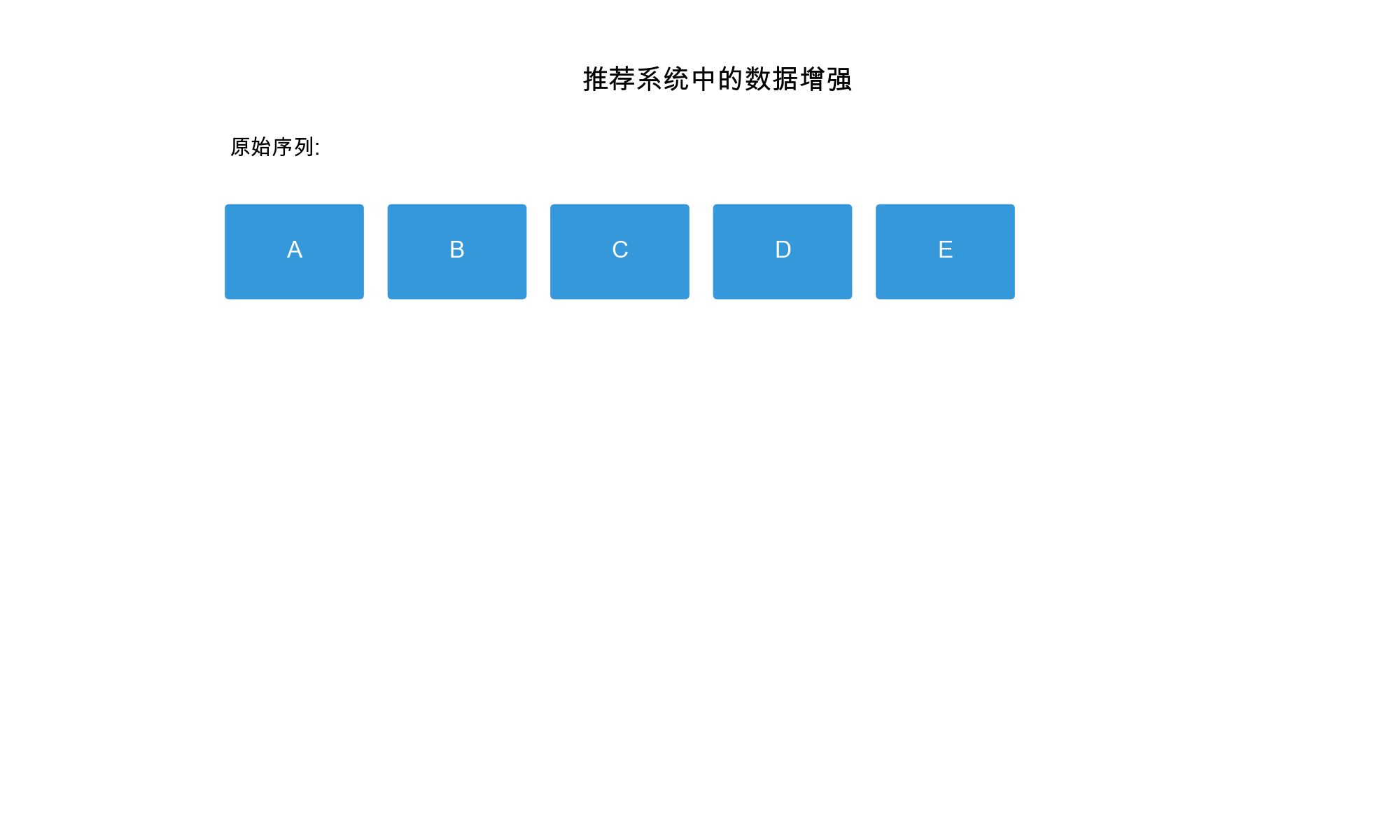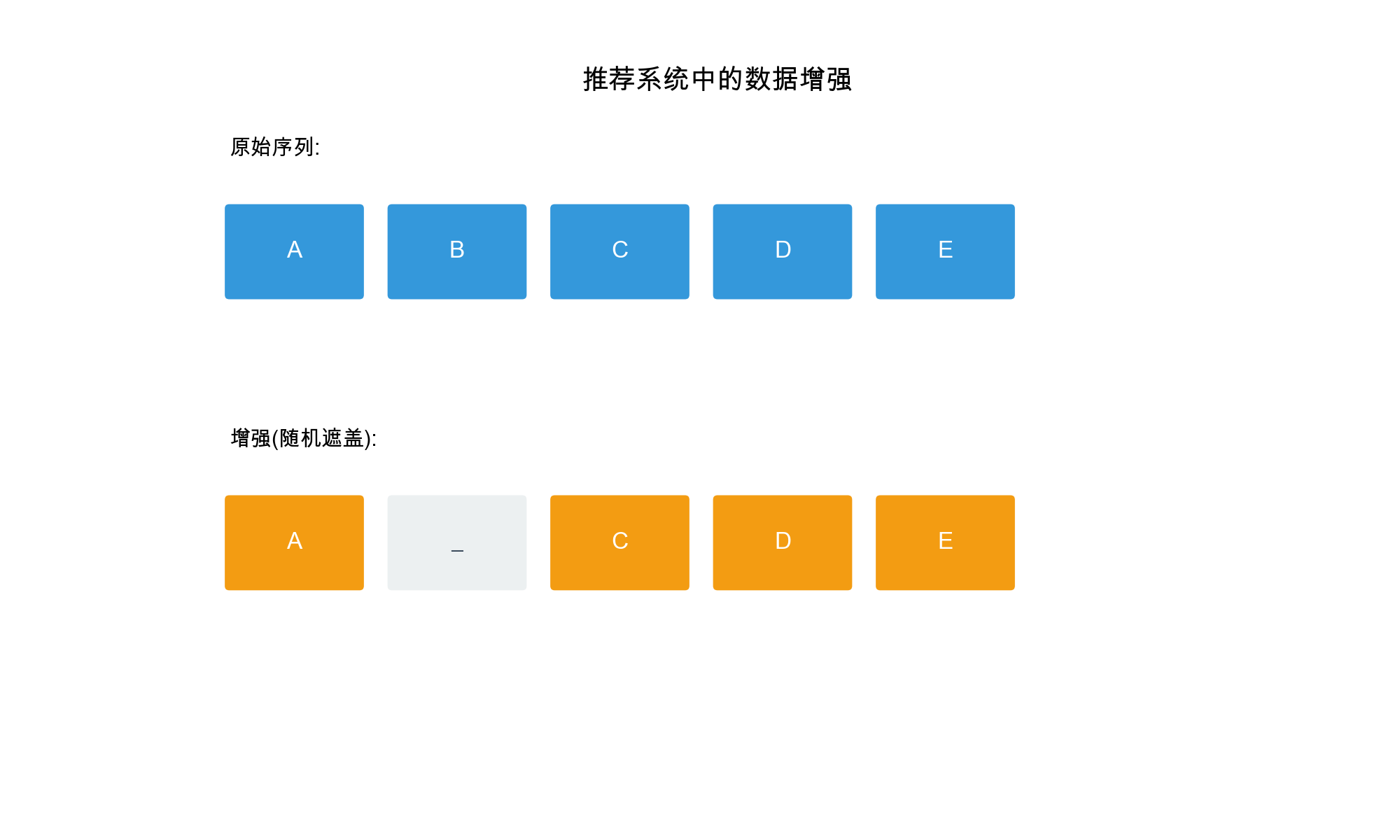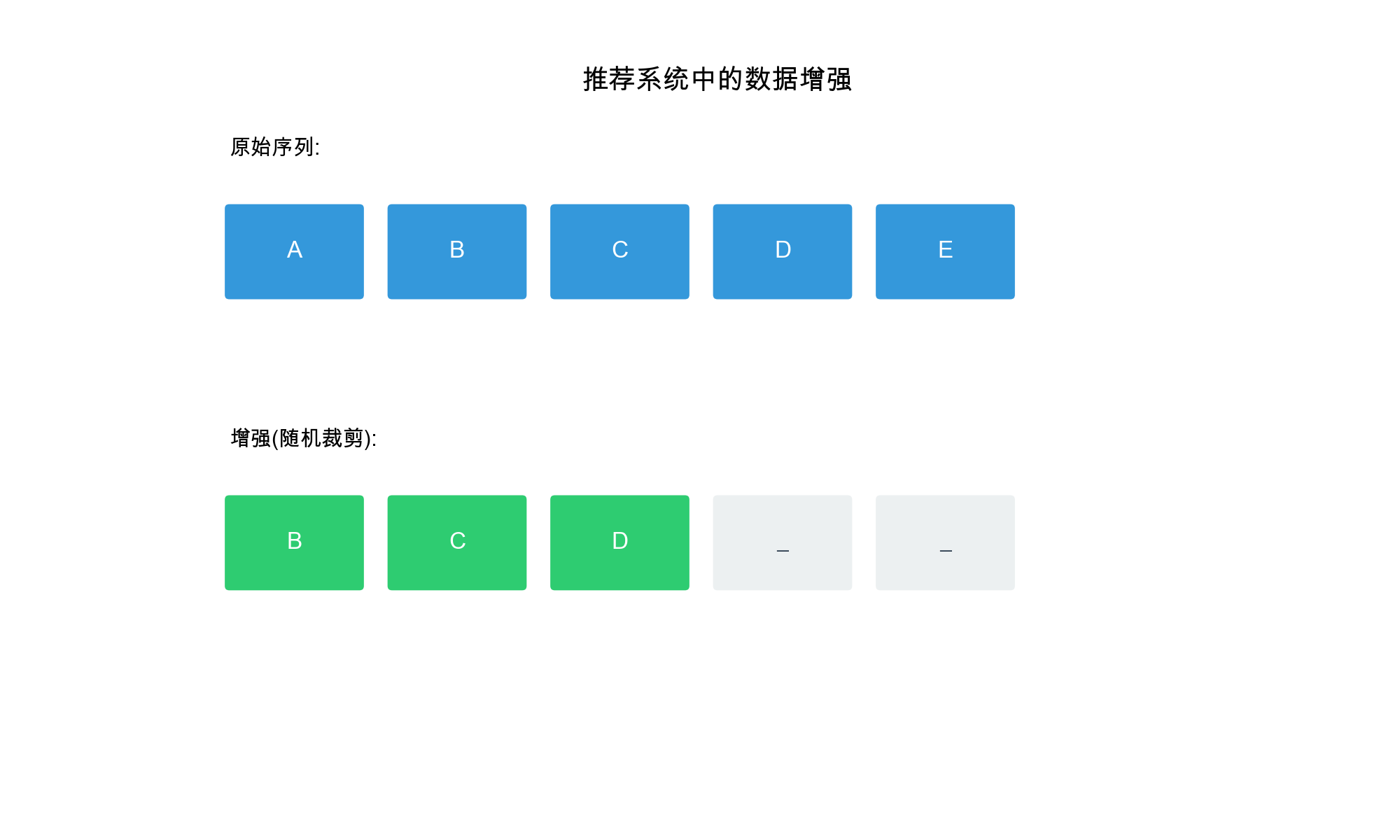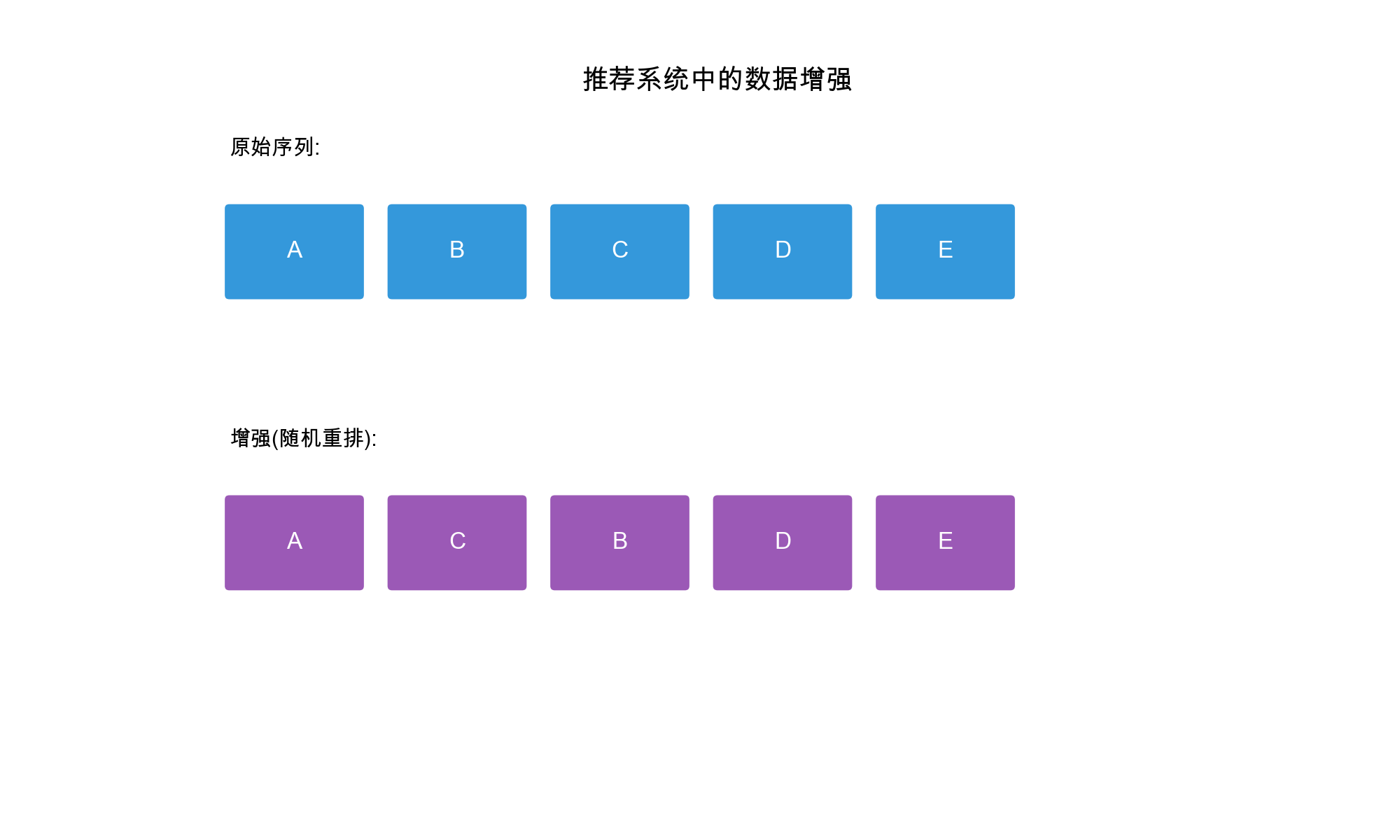
推荐系统中的自监督信号
在推荐系统中,可以利用以下自监督信号:
1. 序列顺序信号 - 用户行为序列的时间顺序 - 相邻交互之间的关联性
2. 图结构信号 - 用户-物品二部图的结构 - 邻居节点的相似性
3. 多视图信号 - 同一用户的不同行为子序列 - 同一物品的不同用户交互
SimCLR 框架详解
SimCLR 的核心思想
SimCLR( Simple Framework for Contrastive Learning of Visual Representations)是 Google 在 2020 年提出的对比学习框架。虽然最初用于计算机视觉,但其核心思想可以很好地迁移到推荐系统。
SimCLR 的核心流程可以概括为:
- 数据增强:对每个样本应用随机增强,生成两个不同的视图
- 编码:使用编码器将增强后的样本映射到表示空间
- 投影:通过投影头将表示映射到对比学习空间
- 对比损失:最大化同一样本不同视图之间的相似度,最小化不同样本之间的相似度
SimCLR 的数学形式化
给定一个样本
其中
编码器
投影头
对比损失函数( InfoNCE):
符号说明:
-
-
- 通常取值 0.05-0.2 - 较小的
-
-
-
- 排除自己(不能和自己对比)
直觉理解: InfoNCE 损失在做什么?
核心思想: "正样本应该相似,负样本应该不同"
1. 分子( Numerator):正样本对的相似度
2. 分母( Denominator):正样本对 +
所有负样本对的相似度
3. 整体损失: Softmax + 负对数
类比:多分类问题
可以把 InfoNCE 理解为一个"从
- 类别数:
(每个样本的视图都是一个"类别") - 正确类别:第
个样本( 的另一个视图) - 目标:最大化正确类别的概率
具体例子(推荐系统):
假设我们有 3 个用户的行为数据,批次大小
- 用户 1 的两个视图:
(删除了不同的交互历史) - 用户 2 的两个视图:
- 用户 3 的两个视图:
对于 ,计算与所有视图的相似度:
| 对比对象 | 关系 | 相似度期望 |
|---|---|---|
| 正样本(同一用户) | 高 (如 0.9) | |
| 负样本(用户 2) | 低 (如 0.1) | |
| 负样本(用户 3) | 低 (如 0.1) |
损失计算(假设
简化:
如果正样本相似度低(如 0.2):
损失很大,模型会更新参数使正样本更相似!
为什么需要负样本?
如果只有正样本约束:
- 所有样本的表示变成相同的向量(如全为 0 或全为 1)
- 因为这样所有正样本对的相似度都是 1(最大)
- 但模型完全没有区分能力!
负样本的作用:
- 防止坍缩:强制不同样本的表示要不同
- 提升区分能力:学会区分相似和不相似的样本
- 学习有意义的表示:正负样本的对比让模型学到数据的本质特征
负样本数量的影响:
- 太少(如只有 2 个负样本):模型容易坍缩,学不到好的表示
- 太多(如 10000 个负样本):计算开销大,但效果通常更好
- SimCLR 的发现:批次大小从 256 增加到 4096,性能显著提升
- 实际应用:可以使用 Memory Bank 或 Momentum Encoder 来增加负样本数量,不增加计算
SimCLR 在推荐系统中的实现
SimCLR 框架的核心是对比学习:通过最大化同一样本不同增强视图之间的相似度,最小化不同样本之间的相似度,学习有效的表示。在推荐系统中,可以将同一用户的不同行为子序列视为正样本对,将不同用户的行为视为负样本对。
SimCLR 的关键组件: 1. 编码器( Encoder):学习用户/物品的表示,这是最终要使用的特征 2. 投影头( Projection Head):将表示映射到对比学习空间,训练完成后可以丢弃 3. 对比损失( InfoNCE Loss):通过对比正负样本对学习表示
下面我们实现一个适用于推荐系统的 SimCLR 框架。这个实现展示了如何将对比学习应用到推荐场景,学习更好的用户和物品表示。
1 | import torch |
SimCLR 的关键设计要点
1. 数据增强的重要性 - SimCLR 发现数据增强是成功的关键 - 在推荐系统中,可以通过特征丢弃、噪声添加、子序列采样等方式进行增强
2. 投影头的作用 - 投影头将表示映射到对比学习空间 - 训练完成后可以丢弃投影头,只使用编码器的输出
3. 温度参数的影响 - 较小的温度参数(如 0.07)会产生更尖锐的分布 - 有助于模型学习更细粒度的特征
4. 大批次训练 - SimCLR 需要大批次(如 4096)才能获得足够的负样本 - 在资源受限时可以使用内存库( Memory Bank)或动量编码器
SGL:自监督图对比学习
SGL 框架概述
SGL( Self-supervised Graph Learning)是华为在 2021 年提出的用于推荐系统的自监督图对比学习框架。它将对比学习的思想应用到用户-物品二部图上,通过图数据增强和对比学习来提升推荐性能。
SGL 的核心创新在于: 1. 图数据增强策略:设计了节点丢弃、边丢弃、子图采样等增强方法 2. 多视图对比学习:从同一图的不同增强视图学习一致表示 3. 联合训练:将对比学习损失与推荐任务损失联合优化
SGL 的图数据增强策略
SGL 提出了三种图数据增强策略:
1. 节点丢弃( Node Dropout)
随机丢弃图中的部分节点及其连接的边:
2. 边丢弃( Edge Dropout)
随机丢弃图中的部分边:
3. 随机游走( Random Walk)
通过随机游走采样子图:
SGL 的模型架构
SGL 使用图神经网络(如 LightGCN)作为编码器:
其中
SGL 的完整实现
1 | import torch |
SGL 的优势与局限
优势: 1. 有效利用图结构信息 2. 通过对比学习提升表示质量 3. 在稀疏数据上表现优异
局限: 1. 计算开销较大(需要多次前向传播) 2. 增强策略的选择需要调优 3. 对超参数(如温度参数、增强率)敏感
RecDCL:推荐系统中的数据增强对比学习
RecDCL 框架介绍
RecDCL( Recommendation with Data Augmentation Contrastive Learning)专注于推荐系统中的数据增强策略设计。与 SGL 不同, RecDCL 更关注如何设计有效的数据增强方法来提升对比学习效果。
RecDCL 的数据增强策略
RecDCL 提出了多种针对推荐系统的数据增强方法:
1. 特征掩码( Feature Masking)
随机掩码部分特征维度:
2. 特征噪声( Feature Noise) 添加高斯噪声:
3. 序列裁剪( Sequence Cropping)
对用户行为序列进行随机裁剪:
4. 序列重排( Sequence Reordering)
随机重排序列中的部分元素:
RecDCL 的实现
1 | import torch |
RCL:对比推荐学习
RCL 框架概述
RCL( Recommendation Contrastive Learning)是一个专门为推荐系统设计的对比学习框架。它通过设计合适的正负样本对构造策略,学习更好的用户和物品表示。
RCL 的正负样本构造
RCL 的核心在于如何构造正负样本对:
正样本对: 1. 同一用户的不同行为视图 2. 同一物品的不同用户交互 3. 用户-物品交互对
负样本对: 1. 不同用户的行为 2. 不同物品的特征 3. 未交互的用户-物品对
RCL 的损失函数设计
RCL 使用改进的对比损失函数:
其中: -
RCL 的完整实现
1 | import torch |
图数据增强策略详解
图数据增强的重要性
在推荐系统中,用户-物品交互可以表示为二部图。图数据增强是图对比学习的关键,它通过生成图的不同视图来构造正样本对。
常见的图数据增强方法
1. 节点级增强
节点丢弃是最直接的增强方法:
1 | def node_dropout_augmentation(edge_index, num_nodes, drop_rate=0.1): |
2. 边级增强
边丢弃保留所有节点,但随机删除部分边:
1 | def edge_dropout_augmentation(edge_index, drop_rate=0.1): |
3. 子图采样
通过随机游走或 BFS 采样子图:
1 | def random_walk_subgraph(edge_index, start_nodes, walk_length=10): |
4. 特征增强
对节点特征进行增强:
1 | def feature_augmentation(node_features, method='dropout', drop_rate=0.1): |
增强策略的组合使用
在实际应用中,可以组合多种增强策略:
1 | class CombinedGraphAugmentation: |
XSimGCL:极简设计的对比学习
XSimGCL 的设计理念
XSimGCL( eXtreme Simple Graph Contrastive Learning)是 2022 年提出的极简图对比学习框架。基本思路:最简单的设计往往最有效。
XSimGCL 的主要创新: 1. 去除了复杂的图数据增强:直接使用原始图结构 2. 简化了对比学习目标:使用更直接的对比损失 3. 减少了计算开销:只需要一次前向传播
XSimGCL 的架构
XSimGCL 使用 LightGCN 作为编码器,但去除了数据增强步骤:
关键创新在于:使用不同层的表示作为不同的视图,而不是通过数据增强生成视图。
XSimGCL 的实现
1 | import torch |
XSimGCL 的优势
- 计算效率高:不需要多次前向传播
- 实现简单:代码量少,易于理解和实现
- 效果优异:在多个数据集上达到或超过 SGL 的效果
- 超参数少:减少了需要调优的超参数
序列推荐中的对比学习
序列推荐的特殊性
序列推荐需要考虑用户行为的时间顺序,这与图推荐有所不同。在序列推荐中,对比学习可以通过以下方式应用:
- 序列增强:对用户行为序列进行增强
- 时间对比:利用时间信息构造正负样本
- 上下文对比:利用序列上下文信息
序列数据增强策略
1. 序列裁剪( Crop)
1 | def sequence_crop(sequence, crop_ratio=0.8): |
2. 序列掩码( Mask)
1 | def sequence_mask(sequence, mask_ratio=0.2): |
3. 序列重排( Reorder)
1 | def sequence_reorder(sequence, reorder_ratio=0.2): |
序列对比学习模型
1 | import torch |
长尾物品推荐
长尾问题的挑战
推荐系统中的长尾问题是指:少数热门物品占据了大部分交互,而大量长尾物品只有很少的交互。这导致:
- 数据稀疏:长尾物品的交互数据极少
- 表示学习困难:难以学习到有效的物品表示
- 推荐偏差:模型倾向于推荐热门物品
对比学习如何解决长尾问题
对比学习通过以下方式帮助解决长尾问题:
- 数据增强:为长尾物品生成更多训练样本
- 表示学习:学习更好的物品表示,即使数据稀疏
- 负样本挖掘:通过对比学习更好地区分相似物品
长尾物品推荐的对比学习框架
1 | import torch |
完整代码实现示例
端到端的推荐系统对比学习框架
下面我们提供一个完整的、可以直接运行的推荐系统对比学习框架:
1 | import torch |
常见问题与解答( Q&A)
Q1: 对比学习和传统推荐方法的主要区别是什么?
A: 对比学习与传统推荐方法的主要区别在于:
- 监督信号来源:
- 传统方法:依赖显式反馈(评分)或隐式反馈(点击)
- 对比学习:从数据本身的结构中挖掘监督信号
- 数据利用:
- 传统方法:主要利用用户-物品交互矩阵
- 对比学习:通过数据增强生成更多训练样本
- 表示学习:
- 传统方法:通过预测任务学习表示
- 对比学习:通过对比相似和不相似样本学习表示
- 稀疏数据处理:
- 传统方法:在稀疏数据上表现较差
- 对比学习:通过对比学习更好地处理稀疏数据
Q2: SimCLR 中的温度参数有什么作用?
A: 温度参数
- 控制分布的尖锐程度:
- 较小的
(如 0.07)会产生更尖锐的分布,模型更关注困难负样本 - 较大的
(如 1.0)会产生更平滑的分布,模型对所有样本的关注更均匀
- 较小的
- 影响学习难度:
- 较小的
增加学习难度,可能提升模型性能 - 但过小的
可能导致训练不稳定
- 较小的
- 实际应用:
- 在推荐系统中,通常使用 0.1-0.2 的温度参数
- 需要通过实验找到最适合的值
Q3: SGL 和 XSimGCL 的主要区别是什么?
A: 主要区别如下:
- 数据增强:
- SGL:使用图数据增强(节点丢弃、边丢弃等)生成不同视图
- XSimGCL:不使用数据增强,直接使用不同层的表示作为不同视图
- 计算开销:
- SGL:需要多次前向传播(每个视图一次)
- XSimGCL:只需要一次前向传播
- 实现复杂度:
- SGL:需要实现图数据增强策略
- XSimGCL:实现更简单,代码量更少
- 性能:
- 两者在大多数数据集上性能相近
- XSimGCL 在某些场景下可能略优于 SGL
Q4: 如何选择合适的数据增强策略?
A: 选择数据增强策略需要考虑:
- 数据类型:
- 图数据:使用节点丢弃、边丢弃、子图采样
- 序列数据:使用序列裁剪、掩码、重排
- 特征数据:使用特征掩码、噪声添加
- 增强强度:
- 过强的增强可能破坏数据语义
- 过弱的增强可能无法提供足够的多样性
- 通常使用 10%-20% 的增强率
- 任务特性:
- 推荐任务:需要保持用户-物品关系的语义
- 可以组合多种增强策略
- 实验验证:
- 通过消融实验找到最佳组合
- 在不同数据集上验证策略的有效性
Q5: 对比学习如何解决冷启动问题?
A: 对比学习通过以下方式帮助解决冷启动问题:
- 数据增强:
- 为新用户/物品生成多个视图
- 即使交互数据少,也能学习到有效表示
- 表示学习:
- 学习到更具泛化能力的表示
- 相似用户/物品的表示更接近
- 迁移学习:
- 可以先用大量数据预训练
- 再在冷启动场景下微调
- 负样本挖掘:
- 通过对比学习更好地利用负样本信息
- 帮助模型学习到更细粒度的特征
Q6: 对比学习的计算开销大吗?
A: 对比学习的计算开销取决于具体实现:
- SimCLR:
- 需要大批次(如 4096)才能获得足够负样本
- 计算开销较大,但可以通过梯度累积缓解
- SGL:
- 需要多次前向传播(每个视图一次)
- 计算开销是传统方法的 2-3 倍
- XSimGCL:
- 只需要一次前向传播
- 计算开销与传统方法相近
- 优化策略:
- 使用内存库( Memory Bank)减少计算
- 使用动量编码器
- 减少增强视图的数量
Q7: 如何评估对比学习模型的效果?
A: 评估对比学习模型可以使用以下指标:
- 推荐任务指标:
- Hit Rate @ K
- NDCG @ K
- Recall @ K
- Precision @ K
- 表示学习指标:
- 表示的可分离性
- 相似样本的表示距离
- t-SNE 可视化
- 对比学习特定指标:
- 对比损失的收敛情况
- 正样本对的相似度
- 负样本对的相似度
- 实际业务指标:
- CTR(点击率)
- 转化率
- 用户满意度
Q8: 对比学习中的负样本采样策略有哪些?
A: 常见的负样本采样策略:
- 随机采样:
- 最简单的方法
- 从所有未交互物品中随机采样
- 困难负样本挖掘:
- 选择与正样本相似但未交互的物品
- 提升模型的学习难度
- 流行度加权采样:
- 根据物品流行度加权采样
- 平衡热门和长尾物品
- 对抗性负样本:
- 使用对抗网络生成负样本
- 提升模型的鲁棒性
- 批次内负样本:
- 使用同一批次内的其他样本作为负样本
- SimCLR 使用的方法
Q9: 对比学习可以与其他推荐技术结合吗?
A: 可以,对比学习可以与多种技术结合:
- 注意力机制:
- 在对比学习中引入注意力
- 关注重要的特征维度
- 图神经网络:
- SGL 就是结合了 GNN 和对比学习
- 利用图结构信息
- 序列模型:
- 结合 Transformer 和对比学习
- 用于序列推荐
- 多任务学习:
- 同时优化推荐任务和对比学习任务
- 提升模型的泛化能力
- 元学习:
- 结合元学习和对比学习
- 快速适应新场景
Q10: 对比学习在工业界的应用情况如何?
A: 对比学习在工业界的应用:
- 应用场景:
- 电商推荐(淘宝、京东等)
- 视频推荐( YouTube 、抖音等)
- 音乐推荐( Spotify 、网易云音乐等)
- 实际效果:
- 在稀疏数据场景下显著提升效果
- 特别是在冷启动和长尾物品推荐上
- 挑战:
- 计算开销需要优化
- 超参数调优复杂
- 需要大量实验验证
- 未来方向:
- 更高效的数据增强策略
- 更好的负样本采样方法
- 与其他技术的深度融合
总结
本文深入探讨了对比学习和自监督学习在推荐系统中的应用。我们从自监督学习的基础开始,详细介绍了 SimCLR 、 SGL 、 RecDCL 、 RCL 、 XSimGCL 等经典框架,探讨了图数据增强策略、序列推荐中的对比学习应用,以及如何利用这些技术解决长尾物品推荐问题。
对比学习为推荐系统带来了新的思路和方法,特别是在处理数据稀疏性、冷启动和长尾问题方面表现出色。通过合理设计数据增强策略、对比损失函数和训练流程,可以学习到更好的用户和物品表示,从而提升推荐效果。
随着研究的深入和技术的成熟,对比学习在推荐系统中的应用将会越来越广泛。希望本文能够帮助读者深入理解这些前沿技术,并在实际项目中应用它们。
- 本文标题:推荐系统(十一)—— 对比学习与自监督学习
- 本文作者:Chen Kai
- 创建时间:2024-06-21 10:00:00
- 本文链接:https://www.chenk.top/%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%EF%BC%88%E5%8D%81%E4%B8%80%EF%BC%89%E2%80%94%E2%80%94-%E5%AF%B9%E6%AF%94%E5%AD%A6%E4%B9%A0%E4%B8%8E%E8%87%AA%E7%9B%91%E7%9D%A3%E5%AD%A6%E4%B9%A0/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!