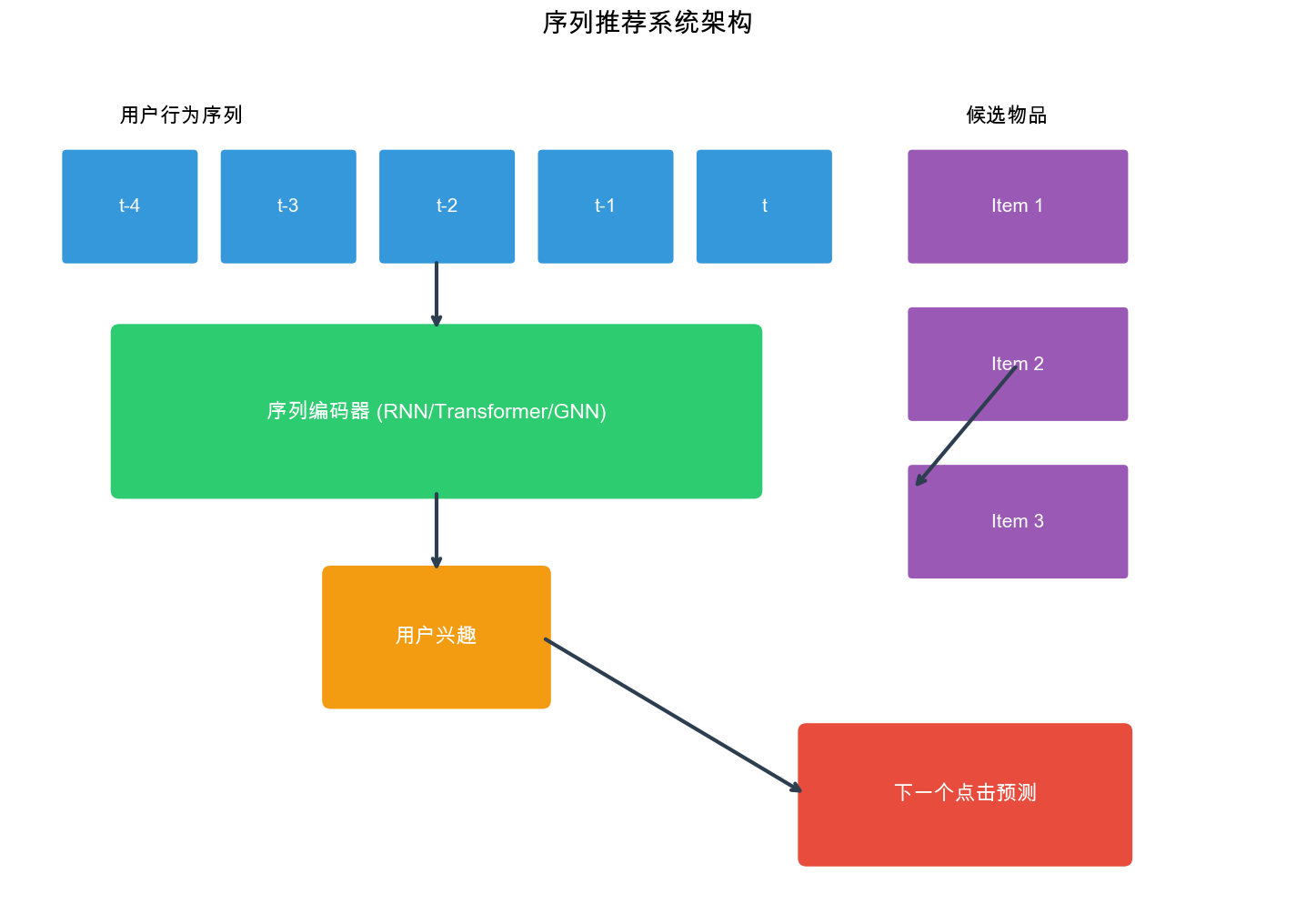
当你打开淘宝,浏览了几个商品后,首页的"猜你喜欢"会立即更新,推荐与你刚才浏览的商品相关的物品。当你听了几首周杰伦的歌,音乐
App
会自动推荐更多相似风格的歌曲。这种"根据用户最近的行为序列来预测下一步兴趣"的推荐方式,就是序列推荐(
Sequential Recommendation)的核心思想。
传统的推荐系统往往将用户的历史行为视为一个无序的集合,忽略了时间顺序和序列模式。但现实中,用户的兴趣会随着时间演变,行为之间存在明显的序列依赖关系。序列推荐正是要捕捉这种动态的、有序的偏好模式,从而做出更精准的预测。
本文将深入探讨序列推荐的各种方法,从经典的马尔可夫链模型,到基于 RNN
、 CNN 、 Transformer
的深度学习方法,再到会话推荐和图神经网络方法。我们会详细讲解每个模型的原理、实现细节,并提供完整的代码示例。
序列推荐问题定义
问题形式化
序列推荐的核心任务是:给定用户的历史交互序列
形式化地,需要学习一个函数
其中
序列推荐 vs 传统推荐
序列推荐与传统推荐方法的关键区别在于:
传统推荐方法 : - 将用户历史行为视为无序集合 -
关注用户和物品的长期静态偏好 - 典型方法:协同过滤、矩阵分解
序列推荐方法 : - 考虑用户行为的时间顺序 -
捕捉短期动态偏好和序列模式 - 能够建模兴趣的演变和转移
序列推荐的应用场景
序列推荐在以下场景中特别有效:
电商推荐 :用户浏览商品序列,推荐下一个可能购买的商品音乐推荐 :根据用户听歌序列,推荐下一首歌曲视频推荐 :根据观看历史,推荐下一个视频新闻推荐 :根据阅读序列,推荐相关新闻会话推荐 :在匿名会话中,根据当前会话内的行为推荐
评估指标
序列推荐的评估指标主要包括:
准确率指标 : - Hit Rate (HR@K) :前
K 个推荐中命中真实物品的比例 -
NDCG@K :归一化折损累积增益 -
MRR :平均倒数排名
多样性指标 : -
Coverage :推荐物品的覆盖率 -
Diversity :推荐列表的多样性
效率指标 : -
训练时间 :模型训练所需时间 -
推理时间 :单次推荐所需时间
马尔可夫链方法
一阶马尔可夫链
最简单的序列推荐方法是使用一阶马尔可夫链( First-Order Markov
Chain),它假设下一个物品的选择只依赖于当前物品,即:
转移矩阵构建 :
对于物品集合
预测方法 :
给定当前物品
高阶马尔可夫链
一阶马尔可夫链的假设过于简单,实际中下一个物品可能依赖于前面多个物品。高阶马尔可夫链(
Higher-Order Markov Chain)考虑前
问题 :高阶马尔可夫链的状态空间会指数级增长。对于
因子分解马尔可夫链( FPMC)
FPMC( Factorizing Personalized Markov
Chains)结合了矩阵分解和马尔可夫链,既考虑个性化,又捕捉序列模式。
模型定义 :
FPMC 将转移概率分解为:
其中: -
优势 : - 通过矩阵分解解决数据稀疏问题 -
同时建模用户偏好和序列模式 - 参数规模远小于高阶马尔可夫链
马尔可夫链方法实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 import numpy as npfrom collections import defaultdictfrom typing import List , Dict , Tuple class MarkovChainRecommender : """一阶马尔可夫链推荐模型""" def __init__ (self ): self.transition_matrix = None self.item_to_idx = {} self.idx_to_item = {} self.n_items = 0 def fit (self, sequences: List [List [int ]] ): """训练模型 Args: sequences: 用户交互序列列表,每个序列是物品 ID 列表 """ all_items = set () for seq in sequences: all_items.update(seq) self.item_to_idx = {item: idx for idx, item in enumerate (sorted (all_items))} self.idx_to_item = {idx: item for item, idx in self.item_to_idx.items()} self.n_items = len (self.item_to_idx) transition_counts = defaultdict(lambda : defaultdict(int )) for seq in sequences: for i in range (len (seq) - 1 ): curr_item = seq[i] next_item = seq[i + 1 ] transition_counts[curr_item][next_item] += 1 self.transition_matrix = np.zeros((self.n_items, self.n_items)) for curr_item, next_items in transition_counts.items(): if curr_item in self.item_to_idx: curr_idx = self.item_to_idx[curr_item] total = sum (next_items.values()) for next_item, count in next_items.items(): if next_item in self.item_to_idx: next_idx = self.item_to_idx[next_item] self.transition_matrix[curr_idx][next_idx] = count / total def predict_next (self, current_item: int , top_k: int = 10 ) -> List [Tuple [int , float ]]: """预测下一个物品 Args: current_item: 当前物品 ID top_k: 返回 Top-K 推荐 Returns: (物品 ID, 概率) 元组列表 """ if current_item not in self.item_to_idx: return [] curr_idx = self.item_to_idx[current_item] probabilities = self.transition_matrix[curr_idx] top_indices = np.argsort(probabilities)[::-1 ][:top_k] recommendations = [ (self.idx_to_item[idx], probabilities[idx]) for idx in top_indices if probabilities[idx] > 0 ] return recommendations def predict_sequence (self, sequence: List [int ], top_k: int = 10 ) -> List [Tuple [int , float ]]: """基于序列预测下一个物品(使用最后一个物品)""" if not sequence: return [] return self.predict_next(sequence[-1 ], top_k) if __name__ == "__main__" : sequences = [ [1 , 2 , 3 , 4 ], [2 , 3 , 5 ], [1 , 3 , 4 , 5 ], [2 , 4 , 3 ], [1 , 2 , 3 ] ] model = MarkovChainRecommender() model.fit(sequences) recommendations = model.predict_next(2 , top_k=5 ) print ("当前物品 2 的推荐:" ) for item, prob in recommendations: print (f" 物品{item} : {prob:.3 f} " )
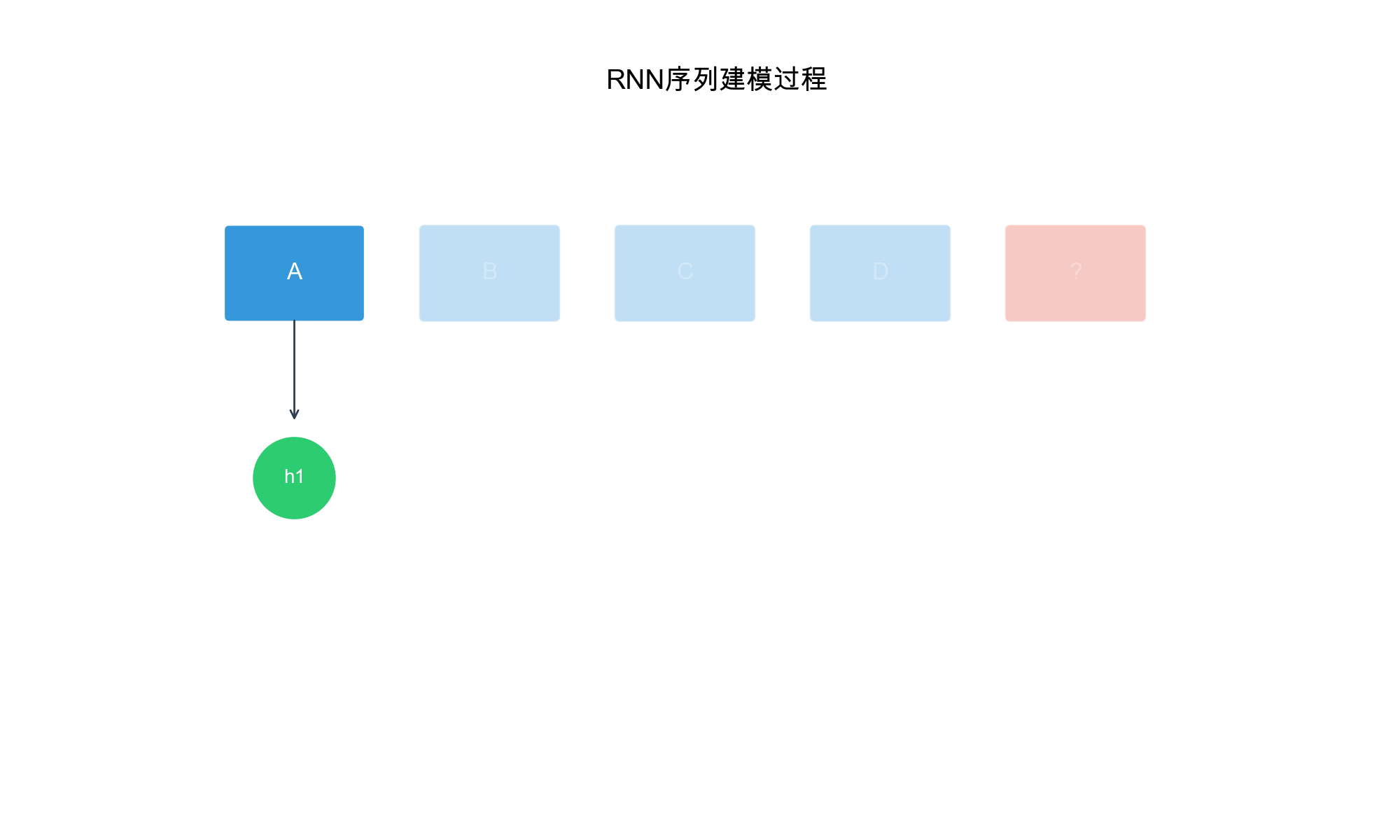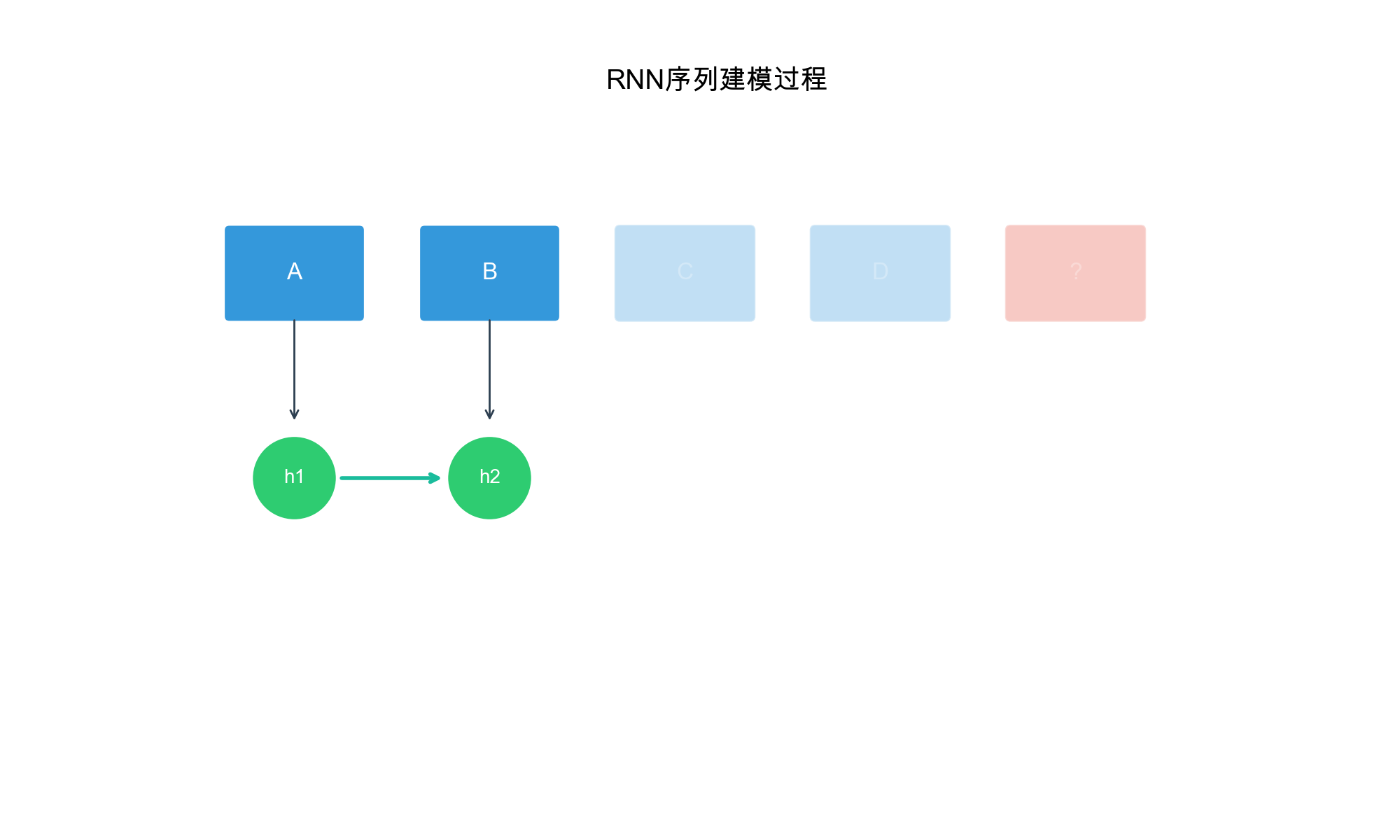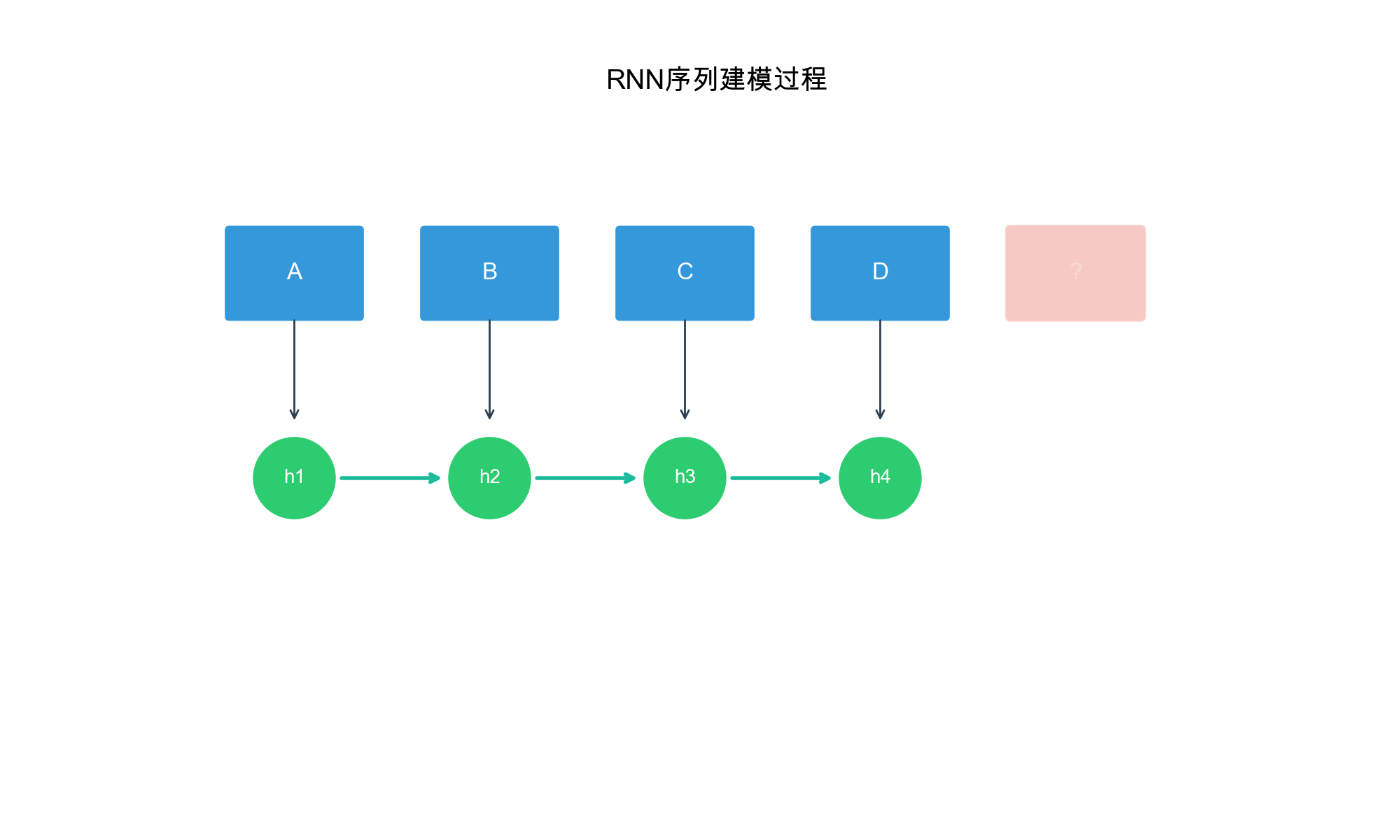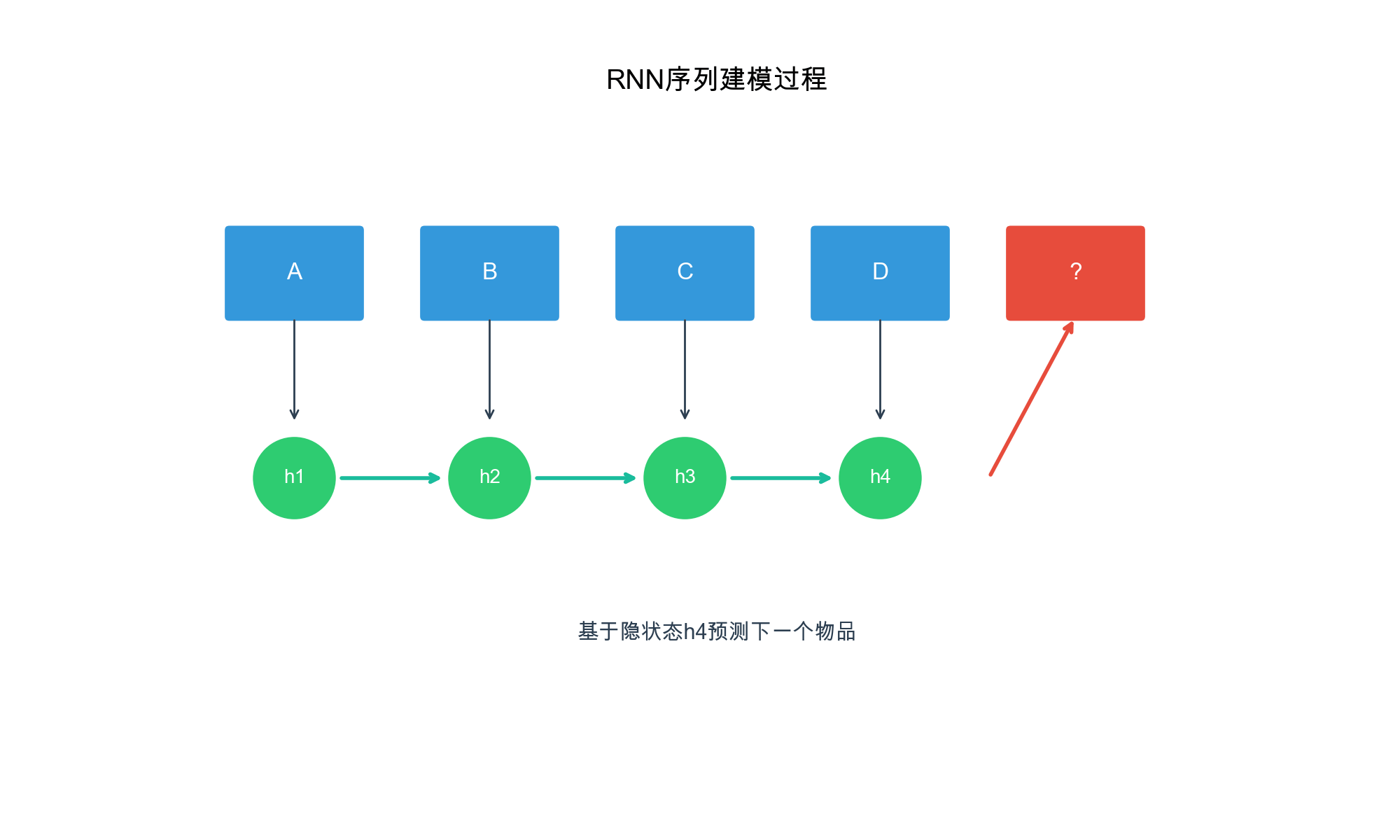
GRU4Rec 详解
模型动机
GRU4Rec( GRU for Recommendation)是第一个将 RNN
应用于序列推荐的深度学习方法。它使用 GRU( Gated Recurrent
Unit)来建模用户行为序列,捕捉长期和短期的依赖关系。
为什么选择 GRU 而不是 LSTM? - GRU
参数更少,训练更快 - 对于序列推荐任务, GRU 的性能与 LSTM 相当 - GRU
更容易收敛
模型架构
GRU4Rec 的基本思路:将用户的历史交互序列作为输入,通过 GRU
编码得到用户当前的状态表示,然后用这个表示预测下一个物品。
输入表示 :
对于序列
GRU 编码 :
其中
预测层 :
使用最后一个隐藏状态
其中
训练策略
Session-parallel mini-batch :
GRU4Rec 使用特殊的批处理策略。每个 batch
包含多个会话,但每个会话的序列长度可能不同。训练时,对于较短的序列,在序列结束后停止更新该会话的隐藏状态。
采样策略 :
由于物品数量巨大,直接计算所有物品的 softmax 成本太高。 GRU4Rec
使用负采样:
正样本 :序列中的下一个物品负样本 :随机采样的其他物品
损失函数使用 BPR( Bayesian Personalized Ranking):
其中
GRU4Rec 完整实现
问题背景
传统的推荐方法(如协同过滤、矩阵分解)将用户历史行为视为无序集合,忽略了时间顺序和序列模式。但在实际应用中,用户的兴趣会随着时间演变,行为之间存在明显的序列依赖关系。例如,用户浏览了"手机"后,更可能浏览"手机壳"而不是"电脑",这种序列模式无法被传统方法捕获。此外,用户的兴趣具有动态性:短期兴趣(如当前浏览的商品类别)和长期兴趣(如历史偏好)都会影响下一步的行为。如何建模这种动态的、有序的偏好模式,是序列推荐的核心挑战。
解决思路
GRU4Rec( GRU for Recommendation)是第一个将 RNN
应用于序列推荐的深度学习方法。它使用 GRU( Gated Recurrent
Unit)来建模用户行为序列,捕捉长期和短期的依赖关系。基本思路:将用户的历史交互序列作为输入,通过
GRU 编码得到用户当前的状态表示,然后用这个表示预测下一个物品。 GRU
的门控机制(更新门和重置门)能够选择性地保留或遗忘历史信息,从而同时建模短期和长期依赖。与
LSTM 相比, GRU
参数更少、训练更快,对于序列推荐任务性能相当且更容易收敛。
设计考虑
在实现 GRU4Rec 时,需要考虑以下几个关键设计:
序列表示 :用户的历史交互序列需要转换为固定长度的输入。对于变长序列,可以使用填充(
padding)或截断( truncation)。通常保留最近 N 个物品(如最近 50
个),既能捕获短期模式又不会引入过多噪声。
Session-parallel mini-batch : GRU4Rec
使用特殊的批处理策略。每个 batch
包含多个会话,但每个会话的序列长度可能不同。训练时,对于较短的序列,在序列结束后停止更新该会话的隐藏状态。这需要仔细处理序列长度和隐藏状态的更新。
负采样策略 :由于物品数量巨大(百万级),直接计算所有物品的
softmax 成本太高。 GRU4Rec
使用负采样:正样本是序列中的下一个物品,负样本是随机采样的其他物品。损失函数使用
BPR( Bayesian Personalized
Ranking),最大化正样本和负样本的得分差距。
Dropout 和正则化 : GRU4Rec 使用 Dropout
防止过拟合,通常在 GRU 层和输出层之间添加 Dropout 。此外,可以使用 L2
正则化约束参数,提升模型泛化能力。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torch.utils.data import Dataset, DataLoaderimport numpy as npfrom typing import List , Tuple class GRU4Rec (nn.Module): """GRU4Rec 模型实现""" def __init__ (self, n_items: int , embedding_dim: int = 128 , hidden_dim: int = 128 , num_layers: int = 1 , dropout: float = 0.25 ): """ Args: n_items: 物品总数 embedding_dim: 物品嵌入维度 hidden_dim: GRU 隐藏层维度 num_layers: GRU 层数 dropout: Dropout 比率 """ super (GRU4Rec, self).__init__() self.n_items = n_items self.embedding_dim = embedding_dim self.hidden_dim = hidden_dim self.item_embedding = nn.Embedding(n_items + 1 , embedding_dim, padding_idx=0 ) self.gru = nn.GRU( embedding_dim, hidden_dim, num_layers, batch_first=True , dropout=dropout if num_layers > 1 else 0 ) self.output_layer = nn.Linear(hidden_dim, n_items + 1 ) self.dropout = nn.Dropout(dropout) self._init_weights() def _init_weights (self ): """初始化模型参数""" nn.init.normal_(self.item_embedding.weight, mean=0 , std=0.01 ) nn.init.xavier_uniform_(self.output_layer.weight) nn.init.zeros_(self.output_layer.bias) def forward (self, item_seqs: torch.Tensor, lengths: torch.Tensor = None ): """ 前向传播 Args: item_seqs: (batch_size, seq_len) 物品序列 lengths: (batch_size,) 每个序列的实际长度 Returns: (batch_size, seq_len, n_items+1) 每个时间步的物品概率分布 """ batch_size, seq_len = item_seqs.size() embedded = self.item_embedding(item_seqs) embedded = self.dropout(embedded) if lengths is not None : embedded = nn.utils.rnn.pack_padded_sequence( embedded, lengths.cpu(), batch_first=True , enforce_sorted=False ) gru_out, hidden = self.gru(embedded) if lengths is not None : gru_out, _ = nn.utils.rnn.pad_packed_sequence( gru_out, batch_first=True ) output = self.output_layer(gru_out) return output def predict (self, item_seq: List [int ], k: int = 10 ) -> List [Tuple [int , float ]]: """预测下一个物品 Args: item_seq: 历史物品序列 k: Top-K 推荐 Returns: (物品 ID, 分数) 列表 """ self.eval () with torch.no_grad(): seq_tensor = torch.LongTensor([item_seq]).to(next (self.parameters()).device) output = self.forward(seq_tensor) last_output = output[0 , -1 , :] probs = F.softmax(last_output, dim=0 ) top_probs, top_indices = torch.topk(probs, k) recommendations = [ (idx.item(), prob.item()) for idx, prob in zip (top_indices, top_probs) if idx.item() > 0 ] return recommendations class SessionDataset (Dataset ): """会话数据集""" def __init__ (self, sequences: List [List [int ]], max_len: int = 50 ): """ Args: sequences: 物品序列列表 max_len: 最大序列长度 """ self.sequences = sequences self.max_len = max_len def __len__ (self ): return len (self.sequences) def __getitem__ (self, idx ): seq = self.sequences[idx] if len (seq) > self.max_len: seq = seq[-self.max_len:] input_seq = [0 ] * (self.max_len - len (seq) + 1 ) + seq[:-1 ] target = seq[-1 ] length = len (seq) return torch.LongTensor(input_seq), torch.LongTensor([target]), length def train_gru4rec (model: GRU4Rec, train_loader: DataLoader, n_epochs: int = 10 , lr: float = 0.001 , device: str = 'cuda' ): """训练 GRU4Rec 模型""" model = model.to(device) optimizer = optim.Adam(model.parameters(), lr=lr) criterion = nn.CrossEntropyLoss(ignore_index=0 ) model.train() for epoch in range (n_epochs): total_loss = 0 for batch_idx, (input_seqs, targets, lengths) in enumerate (train_loader): input_seqs = input_seqs.to(device) targets = targets.squeeze().to(device) lengths = lengths.to(device) optimizer.zero_grad() output = model(input_seqs, lengths) loss = 0 batch_size = input_seqs.size(0 ) for i in range (batch_size): seq_len = lengths[i].item() if seq_len > 0 : pred = output[i, seq_len - 2 , :] loss += criterion(pred.unsqueeze(0 ), targets[i:i+1 ]) loss = loss / batch_size loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0 ) optimizer.step() total_loss += loss.item() print (f"Epoch {epoch+1 } /{n_epochs} , Loss: {total_loss/len (train_loader):.4 f} " ) if __name__ == "__main__" : sequences = [ [1 , 2 , 3 , 4 , 5 ], [2 , 3 , 4 ], [1 , 3 , 5 , 2 ], [4 , 2 , 3 , 1 ], [1 , 2 , 4 , 3 , 5 ] ] max_item_id = max (max (seq) for seq in sequences) n_items = max_item_id dataset = SessionDataset(sequences, max_len=20 ) train_loader = DataLoader(dataset, batch_size=2 , shuffle=True ) model = GRU4Rec(n_items=n_items, embedding_dim=64 , hidden_dim=64 ) device = 'cuda' if torch.cuda.is_available() else 'cpu' train_gru4rec(model, train_loader, n_epochs=5 , device=device) test_seq = [1 , 2 , 3 ] recommendations = model.predict(test_seq, k=5 ) print (f"\n 序列 {test_seq} 的推荐:" ) for item, score in recommendations: print (f" 物品{item} : {score:.4 f} " )
关键点解读
GRU4Rec 的实现包含几个关键组件,每个组件都有其特定的作用:
物品嵌入层 :每个物品通过 Embedding
层映射到稠密向量空间。嵌入维度通常设置为 64-256
维,根据物品数量和计算资源选择。嵌入层的初始化使用小范围的均匀分布,避免初始值过大导致的梯度爆炸问题。
GRU 层设计 : GRU
使用门控机制(更新门和重置门)选择性地保留或遗忘历史信息。更新门控制新信息流入,重置门控制历史信息遗忘。这种设计使得
GRU 能够同时建模短期和长期依赖。代码中使用 batch_first=True
参数,使得输入格式为
(batch_size, seq_len, embedding_dim),更符合推荐系统的使用习惯。
序列长度处理 :对于变长序列,代码使用
pack_padded_sequence 和 pad_packed_sequence
来高效处理。pack_padded_sequence
将填充后的序列打包,避免对填充位置进行计算;pad_packed_sequence
将打包后的序列解包,恢复原始形状。这种处理方式既能处理变长序列,又能提高计算效率。
输出层和预测 :输出层将 GRU
的隐藏状态映射到物品空间,使用线性层和 softmax
得到物品概率分布。预测时,使用最后一个时间步的隐藏状态,通过输出层得到下一个物品的概率分布,然后选择概率最高的
K 个物品作为推荐。
设计权衡
在 GRU4Rec 的实现中,存在多个设计权衡:
序列长度 vs
计算效率 :保留更长的序列能够捕获更多的历史信息,但计算开销也线性增长。通常保留最近
50-100
个物品,既能捕获短期模式又不会引入过多噪声。对于更长的序列,可以使用截断或采样策略。
GRU 层数 vs 模型复杂度 :更多的 GRU
层能够捕获更复杂的序列模式,但参数数量也线性增长,且可能导致梯度消失或过拟合。通常使用
1-3 层 GRU,在效果和效率之间权衡。
负采样数量 vs
训练效果 :更多的负样本能够提升模型对不相似物品的区分能力,但训练时间也线性增长。通常设置
5-20 个负样本,在效果和效率之间权衡。
Dropout 比率 vs 过拟合 :更高的 Dropout
比率能够防止过拟合,但可能降低模型表达能力。通常设置 0.2-0.5 的 Dropout
比率,根据数据规模和模型复杂度调整。
常见问题
如何处理新用户或新物品?
对于新用户,可以使用空序列或随机初始化的序列作为输入。对于新物品,可以使用随机初始化的
Embedding,或者使用物品的内容特征(如类别、标签)通过额外的网络生成初始
Embedding 。
如何提升训练速度? GRU4Rec
的串行计算特性导致训练速度较慢。可以通过以下方式加速:( 1)使用 GPU
并行处理多个 batch;( 2)减少序列长度;( 3)使用更少的 GRU 层;(
4)使用负采样减少计算量。
如何处理长序列? GRU
对长序列的记忆能力有限,通常只能记住最近几十个物品。对于更长的序列,可以使用:(
1)截断策略,只保留最近 N 个物品;( 2)分层
GRU,先对序列分段编码,再对分段编码结果编码;(
3)注意力机制,选择性地关注重要历史物品。
如何平衡准确率和多样性? GRU4Rec
主要优化准确率,可能推荐相似度高的物品导致多样性不足。可以在预测时使用多样性采样策略,或者在损失函数中加入多样性正则项。
使用示例
下面的示例展示了如何使用 GRU4Rec 进行训练和预测:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 sequences = [ [1 , 2 , 3 , 4 , 5 ], [2 , 3 , 4 ], [1 , 3 , 5 , 2 ], ] dataset = SessionDataset(sequences, max_len=20 ) train_loader = DataLoader(dataset, batch_size=32 , shuffle=True ) model = GRU4Rec( n_items=max_item_id, embedding_dim=64 , hidden_dim=64 , num_layers=1 , dropout=0.25 ) train_gru4rec(model, train_loader, n_epochs=10 ) test_seq = [1 , 2 , 3 ] recommendations = model.predict(test_seq, k=10 )
在实际应用中, GRU4Rec 通常用于:(
1)电商推荐,根据用户浏览序列推荐下一个商品;(
2)音乐推荐,根据听歌序列推荐下一首歌曲;(
3)视频推荐,根据观看历史推荐下一个视频。
GRU4Rec 的优缺点
优点 : - 能够捕捉序列中的长期依赖关系 -
参数相对较少,训练效率高 - 对序列长度变化有较好的适应性
缺点 : - RNN 的串行计算特性导致训练和推理速度较慢 -
难以并行化处理 - 对长序列的记忆能力有限
Caser:基于 CNN 的序列推荐
模型动机
Caser( Convolutional Sequence Embedding Recommendation
Model)是第一个将 CNN
应用于序列推荐的模型。它使用卷积操作来捕捉序列中的局部模式和全局模式,突破了
RNN 串行计算的限制。
为什么使用 CNN? - CNN 可以并行计算,训练速度快 -
卷积操作天然适合捕捉局部模式(如"用户看了 A 后经常看 B") -
通过多个卷积核可以捕捉不同长度的模式
模型架构
Caser
的核心思想是将用户的历史序列看作一个"图像",使用卷积操作提取特征。
水平卷积( Horizontal Convolution) :
捕捉序列中的点级模式( point-level
patterns),即单个物品的影响:
其中
垂直卷积( Vertical Convolution) :
捕捉序列级模式( sequence-level
patterns),即整个序列的全局特征:
其中
特征融合 :
将水平卷积和垂直卷积的输出拼接,然后通过全连接层预测:
Caser 完整实现
问题背景
GRU4Rec 等基于 RNN
的方法虽然能够建模序列依赖,但存在串行计算的限制,训练和推理速度较慢。此外,
RNN
对长序列的记忆能力有限,难以捕获不同长度的序列模式。在实际应用中,用户的兴趣模式可能具有不同的时间尺度:短期模式(如"看了手机后看手机壳")和长期模式(如"喜欢科技类产品")。如何同时捕获这些不同尺度的模式,同时提升计算效率,是序列推荐的一个重要挑战。
解决思路
Caser( Convolutional Sequence Embedding Recommendation
Model)是第一个将 CNN
应用于序列推荐的模型。它使用卷积操作来捕捉序列中的局部模式和全局模式,突破了
RNN
串行计算的限制。核心思想是将用户的历史序列看作一个"图像",使用水平卷积(
Horizontal Convolution)捕捉点级模式(单个物品的影响),使用垂直卷积(
Vertical
Convolution)捕捉序列级模式(整个序列的全局特征)。通过多个不同大小的卷积核,
Caser
能够同时捕获不同长度的序列模式,且卷积操作可以并行计算,大幅提升训练速度。
设计考虑
在实现 Caser 时,需要考虑以下几个关键设计:
水平卷积设计 :水平卷积使用不同高度的卷积核(如高度为
1 、 2 、 3)来捕捉不同长度的点级模式。高度为 1
的卷积核捕捉单个物品的影响,高度为 2
的卷积核捕捉相邻两个物品的模式,依此类推。多个卷积核的输出通过最大池化得到固定长度的特征向量。
垂直卷积设计 :垂直卷积对整个序列的嵌入矩阵进行卷积,捕捉序列级的全局特征。垂直卷积核的宽度等于嵌入维度,高度等于序列长度,这样能够捕获整个序列的全局模式。
特征融合 :将水平卷积和垂直卷积的输出拼接,然后通过全连接层预测下一个物品。这种设计能够同时利用局部模式和全局模式,提升预测效果。
序列长度处理 :对于变长序列,可以使用填充或截断。通常保留最近
N 个物品(如最近 50 个),既能捕获短期模式又不会引入过多噪声。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 import torchimport torch.nn as nnimport torch.nn.functional as Ffrom typing import List , Tuple class Caser (nn.Module): """Caser 模型实现""" def __init__ (self, n_items: int , embedding_dim: int = 50 , max_len: int = 50 , num_horizon: int = 16 , num_vertical: int = 8 , dropout: float = 0.5 ): """ Args: n_items: 物品总数 embedding_dim: 物品嵌入维度 max_len: 最大序列长度 num_horizon: 水平卷积核数量 num_vertical: 垂直卷积核数量 dropout: Dropout 比率 """ super (Caser, self).__init__() self.n_items = n_items self.embedding_dim = embedding_dim self.max_len = max_len self.num_horizon = num_horizon self.num_vertical = num_vertical self.item_embedding = nn.Embedding(n_items + 1 , embedding_dim, padding_idx=0 ) self.horizon_convs = nn.ModuleList([ nn.Conv2d(1 , num_horizon, (h, embedding_dim)) for h in [2 , 3 , 4 ] ]) self.vertical_convs = nn.ModuleList([ nn.Conv2d(1 , num_vertical, (max_len, 1 )) ]) horizon_dim = num_horizon * len ([2 , 3 , 4 ]) * (max_len - 2 ) vertical_dim = num_vertical * embedding_dim fc_dim = horizon_dim + vertical_dim self.fc = nn.Linear(fc_dim, n_items + 1 ) self.dropout = nn.Dropout(dropout) self._init_weights() def _init_weights (self ): """初始化模型参数""" nn.init.normal_(self.item_embedding.weight, mean=0 , std=0.01 ) nn.init.xavier_uniform_(self.fc.weight) nn.init.zeros_(self.fc.bias) def forward (self, item_seqs: torch.Tensor ): """ 前向传播 Args: item_seqs: (batch_size, seq_len) 物品序列 Returns: (batch_size, n_items+1) 物品概率分布 """ batch_size, seq_len = item_seqs.size() embedded = self.item_embedding(item_seqs) embedded = embedded.unsqueeze(1 ) horizon_out = [] for conv in self.horizon_convs: h_out = F.relu(conv(embedded)) h_out = h_out.squeeze(-1 ) h_out = F.max_pool1d(h_out, kernel_size=h_out.size(2 )) h_out = h_out.squeeze(-1 ) horizon_out.append(h_out) horizon_out = torch.cat(horizon_out, dim=1 ) vertical_out = [] for conv in self.vertical_convs: v_out = F.relu(conv(embedded)) v_out = v_out.squeeze(2 ) v_out = v_out.view(batch_size, -1 ) vertical_out.append(v_out) vertical_out = torch.cat(vertical_out, dim=1 ) features = torch.cat([horizon_out, vertical_out], dim=1 ) features = self.dropout(features) output = self.fc(features) return output def predict (self, item_seq: List [int ], k: int = 10 ) -> List [Tuple [int , float ]]: """预测下一个物品""" self.eval () with torch.no_grad(): if len (item_seq) > self.max_len: item_seq = item_seq[-self.max_len:] else : item_seq = [0 ] * (self.max_len - len (item_seq)) + item_seq seq_tensor = torch.LongTensor([item_seq]).to(next (self.parameters()).device) output = self.forward(seq_tensor) probs = F.softmax(output[0 ], dim=0 ) top_probs, top_indices = torch.topk(probs, k) recommendations = [ (idx.item(), prob.item()) for idx, prob in zip (top_indices, top_probs) if idx.item() > 0 ] return recommendations if __name__ == "__main__" : sequences = [ [1 , 2 , 3 , 4 , 5 ], [2 , 3 , 4 ], [1 , 3 , 5 , 2 ], ] max_item_id = max (max (seq) for seq in sequences) n_items = max_item_id model = Caser(n_items=n_items, embedding_dim=32 , max_len=10 ) test_seq = [1 , 2 , 3 ] recommendations = model.predict(test_seq, k=5 ) print (f"序列 {test_seq} 的推荐:" ) for item, score in recommendations: print (f" 物品{item} : {score:.4 f} " )
SASRec:基于
Self-Attention 的序列推荐
模型动机
SASRec( Self-Attentive Sequential Recommendation)将 Transformer
架构引入序列推荐。它使用 Self-Attention
机制来捕捉序列中任意位置之间的依赖关系,突破了 RNN 和 CNN 的局限性。
为什么使用 Self-Attention? -
可以并行计算,训练速度快 - 能够直接建模任意距离的依赖关系 -
注意力权重提供了可解释性
模型架构
SASRec 的核心组件包括:
1. 位置嵌入( Positional Embedding) :
由于 Self-Attention 本身不包含位置信息,需要添加位置嵌入:
其中
2. Self-Attention 层 :
其中
3. 前馈网络( Feed-Forward Network) :
4. 层归一化和残差连接 :
5. 预测层 :
使用最后一个位置的表示预测下一个物品:
SASRec 完整实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 import torchimport torch.nn as nnimport torch.nn.functional as Fimport mathfrom typing import List , Tuple class PointWiseFeedForward (nn.Module): """点式前馈网络""" def __init__ (self, hidden_dim: int , dropout: float = 0.2 ): super (PointWiseFeedForward, self).__init__() self.conv1 = nn.Conv1d(hidden_dim, hidden_dim, kernel_size=1 ) self.dropout = nn.Dropout(dropout) self.conv2 = nn.Conv1d(hidden_dim, hidden_dim, kernel_size=1 ) self.relu = nn.ReLU() def forward (self, inputs ): outputs = self.dropout(self.relu(self.conv1(inputs.transpose(-1 , -2 )))) outputs = self.conv2(outputs).transpose(-1 , -2 ) outputs = self.dropout(outputs) return outputs class SASRecBlock (nn.Module): """SASRec Transformer Block""" def __init__ (self, hidden_dim: int , num_heads: int = 1 , dropout: float = 0.2 ): super (SASRecBlock, self).__init__() self.attention = nn.MultiheadAttention( hidden_dim, num_heads, dropout=dropout, batch_first=True ) self.ffn = PointWiseFeedForward(hidden_dim, dropout) self.ln1 = nn.LayerNorm(hidden_dim) self.ln2 = nn.LayerNorm(hidden_dim) self.dropout = nn.Dropout(dropout) def forward (self, inputs, mask=None ): attn_output, _ = self.attention(inputs, inputs, inputs, attn_mask=mask, need_weights=False ) attn_output = self.dropout(attn_output) inputs = self.ln1(inputs + attn_output) ffn_output = self.ffn(inputs) inputs = self.ln2(inputs + ffn_output) return inputs class SASRec (nn.Module): """SASRec 模型实现""" def __init__ (self, n_items: int , hidden_dim: int = 128 , max_len: int = 50 , num_blocks: int = 2 , num_heads: int = 1 , dropout: float = 0.2 ): """ Args: n_items: 物品总数 hidden_dim: 隐藏层维度 max_len: 最大序列长度 num_blocks: Transformer 块数量 num_heads: 注意力头数 dropout: Dropout 比率 """ super (SASRec, self).__init__() self.n_items = n_items self.hidden_dim = hidden_dim self.max_len = max_len self.item_embedding = nn.Embedding(n_items + 1 , hidden_dim, padding_idx=0 ) self.pos_embedding = nn.Embedding(max_len + 1 , hidden_dim, padding_idx=0 ) self.blocks = nn.ModuleList([ SASRecBlock(hidden_dim, num_heads, dropout) for _ in range (num_blocks) ]) self.output_layer = nn.Linear(hidden_dim, n_items + 1 ) self.dropout = nn.Dropout(dropout) self._init_weights() def _init_weights (self ): """初始化模型参数""" nn.init.normal_(self.item_embedding.weight, mean=0 , std=0.01 ) nn.init.normal_(self.pos_embedding.weight, mean=0 , std=0.01 ) nn.init.xavier_uniform_(self.output_layer.weight) nn.init.zeros_(self.output_layer.bias) def forward (self, item_seqs: torch.Tensor ): """ 前向传播 Args: item_seqs: (batch_size, seq_len) 物品序列 Returns: (batch_size, seq_len, n_items+1) 每个位置的物品概率分布 """ batch_size, seq_len = item_seqs.size() positions = torch.arange(seq_len, device=item_seqs.device).unsqueeze(0 ).expand(batch_size, -1 ) positions = positions + 1 positions[item_seqs == 0 ] = 0 item_emb = self.item_embedding(item_seqs) pos_emb = self.pos_embedding(positions) seq_emb = item_emb + pos_emb seq_emb = self.dropout(seq_emb) mask = self._generate_square_subsequent_mask(seq_len).to(item_seqs.device) for block in self.blocks: seq_emb = block(seq_emb, mask) output = self.output_layer(seq_emb) return output def _generate_square_subsequent_mask (self, sz: int ): """生成因果掩码( causal mask)""" mask = torch.triu(torch.ones(sz, sz), diagonal=1 ) mask = mask.masked_fill(mask == 1 , float ('-inf' )) return mask def predict (self, item_seq: List [int ], k: int = 10 ) -> List [Tuple [int , float ]]: """预测下一个物品""" self.eval () with torch.no_grad(): if len (item_seq) > self.max_len: item_seq = item_seq[-self.max_len:] else : item_seq = [0 ] * (self.max_len - len (item_seq)) + item_seq seq_tensor = torch.LongTensor([item_seq]).to(next (self.parameters()).device) output = self.forward(seq_tensor) last_output = output[0 , -1 , :] probs = F.softmax(last_output, dim=0 ) top_probs, top_indices = torch.topk(probs, k) recommendations = [ (idx.item(), prob.item()) for idx, prob in zip (top_indices, top_probs) if idx.item() > 0 ] return recommendations if __name__ == "__main__" : sequences = [ [1 , 2 , 3 , 4 , 5 ], [2 , 3 , 4 ], [1 , 3 , 5 , 2 ], ] max_item_id = max (max (seq) for seq in sequences) n_items = max_item_id model = SASRec(n_items=n_items, hidden_dim=64 , max_len=10 , num_blocks=2 ) test_seq = [1 , 2 , 3 ] recommendations = model.predict(test_seq, k=5 ) print (f"序列 {test_seq} 的推荐:" ) for item, score in recommendations: print (f" 物品{item} : {score:.4 f} " )
BERT4Rec:双向序列推荐
模型动机
BERT4Rec 将 BERT 的双向编码思想引入序列推荐。与 SASRec
的单向预测不同, BERT4Rec 使用双向上下文来学习更好的物品表示。
为什么使用双向编码? -
双向上下文可以提供更丰富的物品表示 - 通过掩码语言模型(
MLM)预训练,可以学习更好的序列模式 -
在推荐任务中,双向信息往往比单向信息更有价值
模型架构
BERT4Rec
的基本思路:随机掩码序列中的一些物品,然后使用双向上下文预测被掩码的物品。
掩码策略 :
对于序列
双向编码 :
使用 Transformer 编码器处理掩码后的序列:
预测被掩码的物品 :
对于位置
BERT4Rec 完整实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 import torchimport torch.nn as nnimport torch.nn.functional as Fimport randomfrom typing import List , Tuple class BERT4RecBlock (nn.Module): """BERT4Rec Transformer Block""" def __init__ (self, hidden_dim: int , num_heads: int = 2 , dropout: float = 0.2 ): super (BERT4RecBlock, self).__init__() self.attention = nn.MultiheadAttention( hidden_dim, num_heads, dropout=dropout, batch_first=True ) self.ffn = nn.Sequential( nn.Linear(hidden_dim, hidden_dim * 4 ), nn.GELU(), nn.Dropout(dropout), nn.Linear(hidden_dim * 4 , hidden_dim), nn.Dropout(dropout) ) self.ln1 = nn.LayerNorm(hidden_dim) self.ln2 = nn.LayerNorm(hidden_dim) def forward (self, inputs ): attn_output, _ = self.attention(inputs, inputs, inputs, need_weights=False ) inputs = self.ln1(inputs + attn_output) ffn_output = self.ffn(inputs) inputs = self.ln2(inputs + ffn_output) return inputs class BERT4Rec (nn.Module): """BERT4Rec 模型实现""" def __init__ (self, n_items: int , hidden_dim: int = 128 , max_len: int = 50 , num_blocks: int = 2 , num_heads: int = 2 , dropout: float = 0.2 , mask_prob: float = 0.15 ): """ Args: n_items: 物品总数 hidden_dim: 隐藏层维度 max_len: 最大序列长度 num_blocks: Transformer 块数量 num_heads: 注意力头数 dropout: Dropout 比率 mask_prob: 掩码概率 """ super (BERT4Rec, self).__init__() self.n_items = n_items self.hidden_dim = hidden_dim self.max_len = max_len self.mask_prob = mask_prob self.item_embedding = nn.Embedding(n_items + 2 , hidden_dim, padding_idx=0 ) self.pos_embedding = nn.Embedding(max_len + 1 , hidden_dim, padding_idx=0 ) self.blocks = nn.ModuleList([ BERT4RecBlock(hidden_dim, num_heads, dropout) for _ in range (num_blocks) ]) self.output_layer = nn.Linear(hidden_dim, n_items + 1 ) self.dropout = nn.Dropout(dropout) self._init_weights() def _init_weights (self ): """初始化模型参数""" nn.init.normal_(self.item_embedding.weight, mean=0 , std=0.02 ) nn.init.normal_(self.pos_embedding.weight, mean=0 , std=0.02 ) nn.init.xavier_uniform_(self.output_layer.weight) nn.init.zeros_(self.output_layer.bias) def forward (self, item_seqs: torch.Tensor, masked_positions: torch.Tensor = None ): """ 前向传播 Args: item_seqs: (batch_size, seq_len) 物品序列(可能包含 mask token) masked_positions: (batch_size, seq_len) 掩码位置标记( 1 表示被掩码) Returns: (batch_size, seq_len, n_items+1) 每个位置的物品概率分布 """ batch_size, seq_len = item_seqs.size() positions = torch.arange(seq_len, device=item_seqs.device).unsqueeze(0 ).expand(batch_size, -1 ) positions = positions + 1 positions[item_seqs == 0 ] = 0 item_emb = self.item_embedding(item_seqs) pos_emb = self.pos_embedding(positions) seq_emb = item_emb + pos_emb seq_emb = self.dropout(seq_emb) for block in self.blocks: seq_emb = block(seq_emb) output = self.output_layer(seq_emb) return output def predict (self, item_seq: List [int ], k: int = 10 ) -> List [Tuple [int , float ]]: """预测下一个物品(在序列末尾添加 mask token)""" self.eval () with torch.no_grad(): if len (item_seq) >= self.max_len: item_seq = item_seq[-(self.max_len-1 ):] item_seq = item_seq + [1 ] if len (item_seq) < self.max_len: item_seq = [0 ] * (self.max_len - len (item_seq)) + item_seq seq_tensor = torch.LongTensor([item_seq]).to(next (self.parameters()).device) output = self.forward(seq_tensor) mask_pos = (seq_tensor == 1 ).nonzero(as_tuple=True )[1 ] if len (mask_pos) > 0 : last_mask_pos = mask_pos[-1 ].item() last_output = output[0 , last_mask_pos, :] else : last_output = output[0 , -1 , :] probs = F.softmax(last_output, dim=0 ) top_probs, top_indices = torch.topk(probs, k) recommendations = [ (idx.item(), prob.item()) for idx, prob in zip (top_indices, top_probs) if idx.item() > 0 ] return recommendations if __name__ == "__main__" : sequences = [ [1 , 2 , 3 , 4 , 5 ], [2 , 3 , 4 ], [1 , 3 , 5 , 2 ], ] max_item_id = max (max (seq) for seq in sequences) n_items = max_item_id model = BERT4Rec(n_items=n_items, hidden_dim=64 , max_len=10 , num_blocks=2 ) test_seq = [1 , 2 , 3 ] recommendations = model.predict(test_seq, k=5 ) print (f"序列 {test_seq} 的推荐:" ) for item, score in recommendations: print (f" 物品{item} : {score:.4 f} " )
模型动机
BST( Behavior Sequence
Transformer)是阿里巴巴提出的模型,专门用于电商推荐场景。它不仅考虑用户的历史行为序列,还融合了用户特征、物品特征等丰富的上下文信息。
BST 的特点 : -
融合多种特征(用户特征、物品特征、上下文特征) - 使用 Transformer
捕捉序列模式 - 专门针对电商场景优化
模型架构
BST 的输入包括:
1. 用户特征 :年龄、性别、城市等 2.
物品特征 :类别、品牌、价格等 3.
行为序列 :用户的历史交互序列 4.
上下文特征 :时间、设备等
特征融合 :
对于序列中的每个物品,将其特征与用户特征、上下文特征拼接:
Transformer 编码 :
预测 :
BST 简化实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 import torchimport torch.nn as nnimport torch.nn.functional as Ffrom typing import List , Tuple , Dict class BST (nn.Module): """BST 简化实现(仅考虑物品序列)""" def __init__ (self, n_items: int , hidden_dim: int = 128 , max_len: int = 50 , num_blocks: int = 2 , num_heads: int = 2 , dropout: float = 0.2 ): super (BST, self).__init__() self.n_items = n_items self.hidden_dim = hidden_dim self.max_len = max_len self.item_embedding = nn.Embedding(n_items + 1 , hidden_dim, padding_idx=0 ) self.pos_embedding = nn.Embedding(max_len + 1 , hidden_dim, padding_idx=0 ) self.blocks = nn.ModuleList([ SASRecBlock(hidden_dim, num_heads, dropout) for _ in range (num_blocks) ]) self.output_layer = nn.Linear(hidden_dim, n_items + 1 ) self.dropout = nn.Dropout(dropout) def forward (self, item_seqs: torch.Tensor ): batch_size, seq_len = item_seqs.size() positions = torch.arange(seq_len, device=item_seqs.device).unsqueeze(0 ).expand(batch_size, -1 ) positions = positions + 1 positions[item_seqs == 0 ] = 0 item_emb = self.item_embedding(item_seqs) pos_emb = self.pos_embedding(positions) seq_emb = item_emb + pos_emb seq_emb = self.dropout(seq_emb) for block in self.blocks: seq_emb = block(seq_emb) output = self.output_layer(seq_emb) return output def predict (self, item_seq: List [int ], k: int = 10 ) -> List [Tuple [int , float ]]: self.eval () with torch.no_grad(): if len (item_seq) > self.max_len: item_seq = item_seq[-self.max_len:] else : item_seq = [0 ] * (self.max_len - len (item_seq)) + item_seq seq_tensor = torch.LongTensor([item_seq]).to(next (self.parameters()).device) output = self.forward(seq_tensor) last_output = output[0 , -1 , :] probs = F.softmax(last_output, dim=0 ) top_probs, top_indices = torch.topk(probs, k) return [ (idx.item(), prob.item()) for idx, prob in zip (top_indices, top_probs) if idx.item() > 0 ]
会话推荐( Session-based
Recommendation)
问题定义
会话推荐是序列推荐的一个特殊场景,主要特点是:
匿名性 :用户可能是匿名访问,没有长期历史记录
短期性 :只关注当前会话内的行为
实时性 :需要快速响应当前会话的变化
形式化定义 :
给定当前会话
会话推荐 vs 序列推荐
特性
序列推荐
会话推荐
用户身份
已知用户
可能匿名
历史数据
长期历史
仅当前会话
时间跨度
数周/数月
几分钟/几小时
应用场景
个性化推荐
实时推荐
会话推荐方法分类
1. 基于相似度的方法 : - Item-KNN:基于物品相似度 -
Session-KNN:基于会话相似度
2. 基于马尔可夫链的方法 : - 一阶/高阶马尔可夫链 -
FPMC
3. 基于深度学习的方法 : - GRU4Rec - NARM( Neural
Attentive Recommendation Machine) - SR-GNN( Session-based Graph Neural
Network)
SR-GNN:会话图神经网络
模型动机
SR-GNN 将会话建模为图结构,使用图神经网络(
GNN)来捕捉会话中物品之间的复杂关系。这是第一个将图神经网络应用于会话推荐的模型。
为什么使用图结构? -
会话中的物品关系不是简单的线性序列 -
图结构可以捕捉物品之间的复杂连接模式 - GNN
能够聚合邻居信息,学习更好的物品表示
模型架构
1. 会话图构建 :
对于会话
2. 图神经网络编码 :
使用门控图神经网络( Gated Graph Neural Network)编码会话图:
其中
3. 会话表示学习 :
使用注意力机制聚合所有节点的表示:
其中
4. 预测 :
其中
SR-GNN 完整实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 import torchimport torch.nn as nnimport torch.nn.functional as Ffrom torch_geometric.data import Data, Batchfrom torch_geometric.nn import MessagePassingfrom typing import List , Tuple , Dict import numpy as npclass SRGNNLayer (MessagePassing ): """SR-GNN 图神经网络层""" def __init__ (self, hidden_dim: int ): super (SRGNNLayer, self).__init__(aggr='add' , flow='target_to_source' ) self.hidden_dim = hidden_dim self.gru = nn.GRUCell(hidden_dim, hidden_dim) self.linear = nn.Linear(hidden_dim, hidden_dim) def forward (self, x, edge_index, edge_attr ): return self.propagate(edge_index, x=x, edge_attr=edge_attr) def message (self, x_j, edge_attr ): return self.linear(x_j) + edge_attr def update (self, aggr_out, x ): return self.gru(aggr_out, x) class SRGNN (nn.Module): """SR-GNN 模型实现""" def __init__ (self, n_items: int , hidden_dim: int = 128 , num_layers: int = 1 , dropout: float = 0.2 ): """ Args: n_items: 物品总数 hidden_dim: 隐藏层维度 num_layers: GNN 层数 dropout: Dropout 比率 """ super (SRGNN, self).__init__() self.n_items = n_items self.hidden_dim = hidden_dim self.item_embedding = nn.Embedding(n_items + 1 , hidden_dim, padding_idx=0 ) self.edge_embedding = nn.Embedding(2 , hidden_dim) self.gnn_layers = nn.ModuleList([ SRGNNLayer(hidden_dim) for _ in range (num_layers) ]) self.attention = nn.Sequential( nn.Linear(hidden_dim, hidden_dim), nn.Tanh(), nn.Linear(hidden_dim, 1 ) ) self.output_layer = nn.Linear(hidden_dim, n_items + 1 ) self.dropout = nn.Dropout(dropout) self._init_weights() def _init_weights (self ): """初始化模型参数""" nn.init.normal_(self.item_embedding.weight, mean=0 , std=0.01 ) nn.init.normal_(self.edge_embedding.weight, mean=0 , std=0.01 ) nn.init.xavier_uniform_(self.output_layer.weight) nn.init.zeros_(self.output_layer.bias) def _build_session_graph (self, session: List [int ] ) -> Data: """构建会话图""" if len (session) == 0 : return None num_nodes = len (session) edge_index = [] edge_attr = [] for i in range (num_nodes - 1 ): edge_index.append([i, i + 1 ]) edge_attr.append(0 ) for i in range (1 , num_nodes): edge_index.append([i, i - 1 ]) edge_attr.append(1 ) if len (edge_index) == 0 : edge_index = [[0 , 0 ]] edge_attr = [0 ] edge_index = torch.LongTensor(edge_index).t().contiguous() edge_attr = torch.LongTensor(edge_attr) x = self.item_embedding(torch.LongTensor(session)) return Data(x=x, edge_index=edge_index, edge_attr=edge_attr) def forward (self, session_graphs: List [Data] ): """ 前向传播 Args: session_graphs: 会话图列表 Returns: (batch_size, n_items+1) 物品概率分布 """ batch_size = len (session_graphs) session_embeddings = [] for graph in session_graphs: if graph is None : session_emb = torch.zeros(self.hidden_dim, device=next (self.parameters()).device) session_embeddings.append(session_emb) continue x = graph.x edge_index = graph.edge_index edge_attr = graph.edge_attr edge_emb = self.edge_embedding(edge_attr) for gnn_layer in self.gnn_layers: x = gnn_layer(x, edge_index, edge_emb) x = self.dropout(x) attn_weights = self.attention(x) attn_weights = F.softmax(attn_weights, dim=0 ) session_emb = torch.sum (attn_weights * x, dim=0 ) session_embeddings.append(session_emb) session_embeddings = torch.stack(session_embeddings) output = self.output_layer(session_embeddings) return output def predict (self, session: List [int ], k: int = 10 ) -> List [Tuple [int , float ]]: """预测下一个物品""" self.eval () with torch.no_grad(): if len (session) == 0 : return [] graph = self._build_session_graph(session) graph = graph.to(next (self.parameters()).device) output = self.forward([graph]) probs = F.softmax(output[0 ], dim=0 ) top_probs, top_indices = torch.topk(probs, k) recommendations = [ (idx.item(), prob.item()) for idx, prob in zip (top_indices, top_probs) if idx.item() > 0 ] return recommendations if __name__ == "__main__" : sessions = [ [1 , 2 , 3 , 4 ], [2 , 3 , 4 ], [1 , 3 , 5 ], ] max_item_id = max (max (sess) for sess in sessions) n_items = max_item_id model = SRGNN(n_items=n_items, hidden_dim=64 , num_layers=2 ) test_session = [1 , 2 , 3 ] recommendations = model.predict(test_session, k=5 ) print (f"会话 {test_session} 的推荐:" ) for item, score in recommendations: print (f" 物品{item} : {score:.4 f} " )
模型对比与选择
性能对比
模型
优势
劣势
适用场景
马尔可夫链
简单、可解释
难以捕捉长期依赖
短期序列、冷启动
GRU4Rec
捕捉序列依赖
训练慢、难以并行
中等长度序列
Caser
并行计算、捕捉局部模式
难以捕捉长期依赖
短序列、实时推荐
SASRec
并行计算、捕捉任意依赖
计算复杂度高
长序列、个性化推荐
BERT4Rec
双向上下文、表示能力强
训练复杂、需要预训练
长序列、高质量数据
SR-GNN
捕捉复杂关系、适合会话
图构建复杂
会话推荐、匿名用户
选择建议
根据序列长度选择 : - 短序列(<10): Caser
、马尔可夫链 - 中等序列( 10-50): GRU4Rec 、 SASRec -
长序列(>50): SASRec 、 BERT4Rec
根据场景选择 : - 实时推荐: Caser 、 SR-GNN -
个性化推荐: SASRec 、 BERT4Rec - 会话推荐: SR-GNN 、 GRU4Rec -
冷启动:马尔可夫链、 Caser
实战代码示例
示例 1:数据预处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import pandas as pdimport numpy as npfrom collections import defaultdictdef preprocess_sequences (df: pd.DataFrame, user_col: str = 'user_id' , item_col: str = 'item_id' , time_col: str = 'timestamp' ): """ 预处理序列数据 Args: df: 包含 user_id, item_id, timestamp 的 DataFrame user_col: 用户列名 item_col: 物品列名 time_col: 时间列名 Returns: 用户序列字典 {user_id: [item_id1, item_id2, ...]} """ df = df.sort_values([user_col, time_col]) user_sequences = defaultdict(list ) for _, row in df.iterrows(): user_sequences[row[user_col]].append(row[item_col]) return dict (user_sequences) data = pd.DataFrame({ 'user_id' : [1 , 1 , 1 , 2 , 2 , 2 ], 'item_id' : [10 , 20 , 30 , 20 , 30 , 40 ], 'timestamp' : [1 , 2 , 3 , 1 , 2 , 3 ] }) sequences = preprocess_sequences(data) print (sequences)
示例 2:序列分割
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 def split_sequences (sequences: dict , test_ratio: float = 0.2 , min_len: int = 2 ): """ 将序列分割为训练集和测试集 Args: sequences: 用户序列字典 test_ratio: 测试集比例 min_len: 最小序列长度 Returns: train_sequences, test_sequences """ train_sequences = [] test_sequences = [] for user_id, seq in sequences.items(): if len (seq) < min_len: continue split_point = max (1 , int (len (seq) * (1 - test_ratio))) train_seq = seq[:split_point] test_seq = seq[split_point:] if len (train_seq) > 0 : train_sequences.append(train_seq) if len (test_seq) > 0 : test_sequences.append(test_seq) return train_sequences, test_sequences sequences = {1 : [10 , 20 , 30 , 40 , 50 ], 2 : [20 , 30 , 40 ]} train_seqs, test_seqs = split_sequences(sequences, test_ratio=0.2 ) print (f"训练序列: {train_seqs} " )print (f"测试序列: {test_seqs} " )
示例 3:评估指标实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 def hit_rate_at_k (y_true: List [int ], y_pred: List [int ], k: int = 10 ) -> float : """ 计算 Hit Rate@K Args: y_true: 真实物品列表 y_pred: 预测物品列表(已排序) k: Top-K Returns: Hit Rate@K """ if len (y_true) == 0 : return 0.0 top_k_pred = set (y_pred[:k]) hits = len (set (y_true) & top_k_pred) return hits / len (y_true) def ndcg_at_k (y_true: List [int ], y_pred: List [int ], k: int = 10 ) -> float : """ 计算 NDCG@K Args: y_true: 真实物品列表 y_pred: 预测物品列表(已排序) k: Top-K Returns: NDCG@K """ if len (y_true) == 0 : return 0.0 dcg = 0.0 for i, item in enumerate (y_pred[:k]): if item in y_true: dcg += 1.0 / np.log2(i + 2 ) idcg = sum (1.0 / np.log2(i + 2 ) for i in range (min (len (y_true), k))) if idcg == 0 : return 0.0 return dcg / idcg def mrr (y_true: List [int ], y_pred: List [int ] ) -> float : """ 计算 MRR( Mean Reciprocal Rank) Args: y_true: 真实物品列表 y_pred: 预测物品列表(已排序) Returns: MRR """ if len (y_true) == 0 : return 0.0 for rank, item in enumerate (y_pred, start=1 ): if item in y_true: return 1.0 / rank return 0.0 y_true = [10 , 20 ] y_pred = [30 , 10 , 40 , 20 , 50 ] print (f"HR@3: {hit_rate_at_k(y_true, y_pred, k=3 )} " )print (f"NDCG@3: {ndcg_at_k(y_true, y_pred, k=3 )} " )print (f"MRR: {mrr(y_true, y_pred)} " )
示例 4:批量评估
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 def evaluate_model (model, test_sequences: List [List [int ]], k: int = 10 , device: str = 'cpu' ): """ 评估模型性能 Args: model: 推荐模型 test_sequences: 测试序列列表 k: Top-K device: 设备 Returns: 评估指标字典 """ model.eval () model = model.to(device) hr_scores = [] ndcg_scores = [] mrr_scores = [] for seq in test_sequences: if len (seq) < 2 : continue input_seq = seq[:-1 ] true_next = seq[-1 ] recommendations = model.predict(input_seq, k=k) pred_items = [item for item, _ in recommendations] hr_scores.append(hit_rate_at_k([true_next], pred_items, k)) ndcg_scores.append(ndcg_at_k([true_next], pred_items, k)) mrr_scores.append(mrr([true_next], pred_items)) return { 'HR@{}' .format (k): np.mean(hr_scores), 'NDCG@{}' .format (k): np.mean(ndcg_scores), 'MRR' : np.mean(mrr_scores) }
示例 5:负采样训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 def negative_sampling_train (model, train_loader, n_epochs: int = 10 , lr: float = 0.001 , device: str = 'cuda' , n_negatives: int = 1 ): """ 使用负采样训练模型 Args: model: 推荐模型 train_loader: 数据加载器 n_epochs: 训练轮数 lr: 学习率 device: 设备 n_negatives: 每个正样本的负样本数 """ model = model.to(device) optimizer = torch.optim.Adam(model.parameters(), lr=lr) model.train() for epoch in range (n_epochs): total_loss = 0 for batch_idx, (input_seqs, targets, lengths) in enumerate (train_loader): input_seqs = input_seqs.to(device) targets = targets.squeeze().to(device) optimizer.zero_grad() output = model(input_seqs, lengths) batch_size = input_seqs.size(0 ) loss = 0 for i in range (batch_size): seq_len = lengths[i].item() if seq_len > 0 : pos_score = output[i, seq_len-2 , targets[i]] neg_items = torch.randint(1 , model.n_items+1 , (n_negatives,), device=device) neg_scores = output[i, seq_len-2 , neg_items] loss += -torch.log(torch.sigmoid(pos_score - neg_scores.mean())) loss = loss / batch_size loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0 ) optimizer.step() total_loss += loss.item() print (f"Epoch {epoch+1 } /{n_epochs} , Loss: {total_loss/len (train_loader):.4 f} " )
示例 6:序列增强
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def augment_sequences (sequences: List [List [int ]], augmentation_ratio: float = 0.5 ): """ 数据增强:通过滑动窗口生成更多训练样本 Args: sequences: 原始序列列表 augmentation_ratio: 增强比例 Returns: 增强后的序列列表 """ augmented = [] for seq in sequences: augmented.append(seq) if len (seq) > 3 : for i in range (1 , len (seq) - 1 ): sub_seq = seq[i:] if len (sub_seq) >= 2 : augmented.append(sub_seq) return augmented sequences = [[1 , 2 , 3 , 4 , 5 ], [2 , 3 , 4 ]] augmented = augment_sequences(sequences) print (f"原始序列数: {len (sequences)} " )print (f"增强后序列数: {len (augmented)} " )
示例 7:序列填充和截断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 def pad_sequences (sequences: List [List [int ]], max_len: int , pad_value: int = 0 , truncate: str = 'post' ): """ 填充和截断序列 Args: sequences: 序列列表 max_len: 最大长度 pad_value: 填充值 truncate: 截断方式('pre'或'post') Returns: 填充后的序列列表和长度列表 """ padded_seqs = [] lengths = [] for seq in sequences: length = len (seq) lengths.append(min (length, max_len)) if length > max_len: if truncate == 'post' : seq = seq[:max_len] else : seq = seq[-max_len:] elif length < max_len: if truncate == 'post' : seq = seq + [pad_value] * (max_len - length) else : seq = [pad_value] * (max_len - length) + seq padded_seqs.append(seq) return padded_seqs, lengths sequences = [[1 , 2 , 3 ], [1 , 2 , 3 , 4 , 5 ], [1 ]] padded, lengths = pad_sequences(sequences, max_len=4 , truncate='post' ) print (f"填充后: {padded} " )print (f"长度: {lengths} " )
示例 8:物品频率统计
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 def compute_item_frequency (sequences: List [List [int ]] ): """ 计算物品频率 Args: sequences: 序列列表 Returns: 物品频率字典 """ item_freq = defaultdict(int ) for seq in sequences: for item in seq: item_freq[item] += 1 return dict (item_freq) def filter_rare_items (sequences: List [List [int ]], min_freq: int = 2 ): """ 过滤低频物品 Args: sequences: 序列列表 min_freq: 最小频率 Returns: 过滤后的序列列表和物品映射 """ item_freq = compute_item_frequency(sequences) valid_items = {item for item, freq in item_freq.items() if freq >= min_freq} item_mapping = {item: item if item in valid_items else 0 for item in item_freq.keys()} filtered_sequences = [] for seq in sequences: filtered_seq = [item_mapping.get(item, 0 ) for item in seq] filtered_seq = [item for item in filtered_seq if item > 0 ] if len (filtered_seq) >= 2 : filtered_sequences.append(filtered_seq) return filtered_sequences, item_mapping sequences = [[1 , 2 , 3 ], [1 , 2 , 4 ], [5 , 6 ]] filtered, mapping = filter_rare_items(sequences, min_freq=2 ) print (f"过滤后序列: {filtered} " )print (f"物品映射: {mapping} " )
示例 9:时间衰减权重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def apply_time_decay (sequences: List [List [int ]], timestamps: List [List [int ]] = None , decay_factor: float = 0.9 ): """ 应用时间衰减权重(越近的行为权重越大) Args: sequences: 序列列表 timestamps: 时间戳列表(可选) decay_factor: 衰减因子 Returns: 加权序列 """ weighted_sequences = [] for i, seq in enumerate (sequences): if timestamps is None : weights = [decay_factor ** (len (seq) - j - 1 ) for j in range (len (seq))] else : ts = timestamps[i] max_ts = max (ts) weights = [decay_factor ** (max_ts - t) for t in ts] weighted_sequences.append({ 'sequence' : seq, 'weights' : weights }) return weighted_sequences sequences = [[1 , 2 , 3 , 4 ], [1 , 2 , 3 ]] weighted = apply_time_decay(sequences, decay_factor=0.9 ) for w_seq in weighted: print (f"序列: {w_seq['sequence' ]} " ) print (f"权重: {[f'{w:.3 f} ' for w in w_seq['weights' ]]} " )
示例 10:多目标优化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 class MultiTaskSequentialRecommender (nn.Module): """多任务序列推荐模型(同时预测点击和购买)""" def __init__ (self, n_items: int , embedding_dim: int = 128 , hidden_dim: int = 128 ): super (MultiTaskSequentialRecommender, self).__init__() self.n_items = n_items self.item_embedding = nn.Embedding(n_items + 1 , embedding_dim, padding_idx=0 ) self.gru = nn.GRU(embedding_dim, hidden_dim, batch_first=True ) self.click_head = nn.Linear(hidden_dim, n_items + 1 ) self.purchase_head = nn.Linear(hidden_dim, n_items + 1 ) def forward (self, item_seqs: torch.Tensor, lengths: torch.Tensor = None ): embedded = self.item_embedding(item_seqs) if lengths is not None : embedded = nn.utils.rnn.pack_padded_sequence( embedded, lengths.cpu(), batch_first=True , enforce_sorted=False ) gru_out, hidden = self.gru(embedded) if lengths is not None : gru_out, _ = nn.utils.rnn.pad_packed_sequence( gru_out, batch_first=True ) last_hidden = hidden[-1 ] click_logits = self.click_head(last_hidden) purchase_logits = self.purchase_head(last_hidden) return click_logits, purchase_logits def predict (self, item_seq: List [int ], task: str = 'click' , k: int = 10 ): """预测(支持多任务)""" self.eval () with torch.no_grad(): seq_tensor = torch.LongTensor([item_seq]).to(next (self.parameters()).device) click_logits, purchase_logits = self.forward(seq_tensor) if task == 'click' : logits = click_logits[0 ] else : logits = purchase_logits[0 ] probs = F.softmax(logits, dim=0 ) top_probs, top_indices = torch.topk(probs, k) return [ (idx.item(), prob.item()) for idx, prob in zip (top_indices, top_probs) if idx.item() > 0 ]
Q&A:常见问题解答
Q1:
序列推荐和传统推荐有什么区别?
A : 主要区别在于:
时间顺序 :序列推荐考虑用户行为的时间顺序,传统推荐将历史行为视为无序集合动态性 :序列推荐捕捉用户兴趣的动态演变,传统推荐关注静态偏好短期 vs
长期 :序列推荐更关注短期行为模式,传统推荐更关注长期偏好应用场景 :序列推荐适合实时推荐、会话推荐,传统推荐适合个性化主页推荐
Q2: GRU4Rec 为什么使用
GRU 而不是 LSTM?
A : 主要原因包括:
参数更少 : GRU 的参数比 LSTM 少约
1/3,训练更快性能相当 :在序列推荐任务中, GRU 的性能与 LSTM
相当甚至更好更容易收敛 : GRU 的结构更简单,更容易训练计算效率 : GRU
的计算量更小,适合大规模推荐系统
Q3: SASRec 和 BERT4Rec
的主要区别是什么?
A : 主要区别:
编码方向 :
SASRec:单向编码(只能看到过去的信息)
BERT4Rec:双向编码(可以看到整个序列的上下文)
训练方式 :
SASRec:直接预测下一个物品
BERT4Rec:使用掩码语言模型( MLM)预训练
应用场景 :
SASRec:适合在线推荐(实时预测)
BERT4Rec:适合离线推荐(可以访问完整序列)
计算复杂度 :
SASRec:需要因果掩码,计算相对简单
BERT4Rec:双向注意力,计算复杂度更高
Q4:
如何处理序列长度不一致的问题?
A : 常见方法:
填充( Padding) :用特殊 token(如
0)填充短序列截断(
Truncation) :截断长序列(通常保留最近的行为)动态批处理 :使用 pack_padded_sequence
处理变长序列分段处理 :将长序列分成多个固定长度的段
推荐做法 : - 训练时:使用动态批处理,保留所有信息 -
推理时:截断到固定长度(如最近 50 个行为),提高效率
Q5:
序列推荐中的冷启动问题如何解决?
A : 冷启动包括用户冷启动和物品冷启动:
用户冷启动 : 1.
利用会话信息 :即使没有用户历史,也可以使用当前会话 2.
内容特征 :使用物品的内容特征(类别、标签等) 3.
热门推荐 :推荐热门物品作为初始策略 4.
迁移学习 :从相似用户的学习中迁移知识
物品冷启动 : 1.
内容嵌入 :使用物品的内容特征初始化嵌入 2.
多模态信息 :融合文本、图像等多模态特征 3.
知识图谱 :利用物品之间的关联关系
Q6: 如何选择序列的最大长度?
A : 选择原则:
数据分布 :分析序列长度分布,选择覆盖大部分数据的长度计算资源 :考虑模型的计算复杂度( Transformer
的复杂度是业务需求 :根据推荐场景选择(实时推荐用短序列,个性化推荐用长序列)实验验证 :通过实验找到性能和效率的平衡点
常见设置 : - 短序列: 10-20(会话推荐) - 中等序列:
50-100(个性化推荐) - 长序列: 200+(深度个性化推荐)
Q7: 负采样策略有哪些?
A : 常见策略:
随机负采样 :随机选择未交互的物品流行度负采样 :根据物品流行度采样(热门物品更容易被采样)困难负采样 :选择模型预测分数较高的负样本批次内负采样 :使用同一批次中其他用户的物品作为负样本
推荐策略 : - 训练初期:使用随机负采样 -
训练后期:使用困难负采样提高模型性能 - 平衡正负样本比例:通常 1:1 到
1:4
Q8: 如何评估序列推荐模型?
A : 评估指标:
准确率指标 : - HR@K :前 K
个推荐中命中真实物品的比例 - NDCG@K :考虑排序质量的指标
- MRR :平均倒数排名
多样性指标 : -
Coverage :推荐物品的覆盖率 -
Diversity :推荐列表的多样性(如类别多样性)
效率指标 : -
训练时间 :模型训练所需时间 -
推理时间 :单次推荐所需时间
评估方法 : -
留一法 :每个用户保留最后一个交互作为测试 -
时间分割 :按时间顺序分割训练集和测试集 - K
折交叉验证 :将数据分成 K 折进行交叉验证
A : 主要优势:
并行计算 :可以并行处理序列中的所有位置,训练速度快长距离依赖 : Self-Attention
可以直接建模任意距离的依赖关系可解释性 :注意力权重提供了模型决策的可解释性灵活性 :可以轻松融合多种特征(用户特征、物品特征等)
局限性 : - 计算复杂度高(
Q10:
会话推荐和序列推荐的区别?
A : 主要区别:
特性
序列推荐
会话推荐
用户身份
已知用户 ID
可能匿名
历史数据
长期历史(数周/月)
仅当前会话(几分钟)
时间跨度
长
短
数据量
每个用户多条序列
每个会话一条序列
应用场景
个性化主页推荐
实时推荐、匿名推荐
模型选择 : - 序列推荐: SASRec 、 BERT4Rec 、
GRU4Rec - 会话推荐: SR-GNN 、 NARM 、 GRU4Rec
Q11:
如何处理序列中的噪声数据?
A : 处理方法:
过滤短序列 :移除长度过短的序列(如 < 2)过滤异常行为 :移除明显异常的行为(如连续点击同一物品)时间窗口 :只考虑最近一段时间的行为频率过滤 :过滤低频物品和用户数据清洗 :移除重复、错误的数据
推荐流程 : 1. 统计序列长度分布,设置最小长度阈值 2.
统计物品频率,过滤低频物品 3. 检查数据质量(缺失值、异常值) 4.
应用时间窗口过滤
Q12:
序列推荐模型如何部署到生产环境?
A : 部署考虑:
模型优化 : 1.
模型压缩 :量化、剪枝、蒸馏 2.
批处理 :批量处理请求提高吞吐量 3.
缓存 :缓存热门用户的推荐结果
系统架构 : 1.
离线训练 :定期(如每天)重新训练模型 2.
在线服务 :使用模型服务框架(如 TensorFlow Serving) 3.
A/B 测试 :对比不同模型的效果 4.
监控 :监控延迟、错误率等指标
性能优化 : - 使用 GPU 加速推理 -
使用模型量化减少内存占用 - 使用批处理提高吞吐量 -
使用缓存减少重复计算
Q13:
如何融合多种序列推荐模型?
A : 融合方法:
加权平均 :对不同模型的预测分数加权平均Stacking :训练一个元模型学习如何组合不同模型投票 :多个模型投票选择推荐物品级联 :先用简单模型筛选,再用复杂模型精排
推荐策略 : - 在线推荐:使用轻量级模型(如 Caser) -
离线推荐:使用复杂模型(如 BERT4Rec) - 混合策略:结合多种模型的优势
Q14:
序列推荐中的位置编码有什么作用?
A : 位置编码的作用:
位置信息 : Self-Attention
本身不包含位置信息,需要位置编码相对位置 :帮助模型理解序列中的相对位置关系距离衰减 :通常距离越远,影响越小
位置编码类型 : - 绝对位置编码 :
SASRec 使用可学习的位置嵌入 -
相对位置编码 :考虑相对距离的位置编码 -
正弦位置编码 : Transformer 原始论文中的方法
选择建议 : - 短序列:可学习的位置嵌入 -
长序列:正弦位置编码(可以外推到更长序列)
Q15: 如何处理用户兴趣的演变?
A : 处理方法:
时间衰减 :给最近的行为更高的权重时间窗口 :只考虑最近一段时间的行为多时间尺度 :同时考虑短期和长期行为时间特征 :将时间信息作为特征输入模型
模型设计 : - 使用注意力机制自动学习时间权重 -
使用时间感知的序列模型 - 使用多任务学习(预测不同时间段的兴趣)
总结
序列推荐是推荐系统领域的重要分支,它通过捕捉用户行为序列中的模式来预测下一个兴趣。从简单的马尔可夫链到复杂的
Transformer 模型,序列推荐方法不断演进。
关键要点 :
选择合适的模型 :根据序列长度、场景需求选择合适的方法数据预处理 :序列填充、截断、过滤等预处理很重要评估指标 :使用多种指标全面评估模型性能工程实践 :考虑模型部署、性能优化等实际问题
未来方向 :
多模态融合 :融合文本、图像等多模态信息强化学习 :使用强化学习优化长期用户体验可解释性 :提高模型的可解释性效率优化 :在保证性能的前提下提高计算效率
序列推荐是一个快速发展的领域,新的方法和技术不断涌现。希望这篇文章能帮助你理解序列推荐的核心概念和方法,并在实际项目中应用这些知识。