在推荐系统的实际应用中,我们往往需要同时优化多个目标:点击率(
CTR)、转化率(
CVR)、停留时长、点赞、评论、分享等。传统的单任务学习模型为每个目标单独训练一个模型,这不仅增加了模型维护成本,还忽略了任务之间的关联性。多任务学习(
Multi-Task Learning,
MTL)通过共享底层特征表示,让多个任务共同学习,既能提升模型性能,又能降低计算和存储成本。
多任务学习在推荐系统中已经得到了广泛应用。阿里巴巴的 ESMM 模型解决了
CVR 预估中的样本选择偏差问题, Google 的 MMoE
模型通过多门控机制实现了任务间的灵活共享,腾讯的 PLE
模型进一步解决了负迁移问题。这些模型在工业实践中都取得了显著的效果提升:
ESMM 在淘宝的 CVR 预估中提升了 2.18%, MMoE 在 YouTube
推荐中提升了多个指标的离线效果, PLE 在腾讯视频推荐中相比 MMoE 提升了
0.39%的 AUC 。
然而,多任务学习并非简单的"共享参数就能提升性能"。任务之间的关系复杂:有些任务高度相关(如
CTR 和
CVR),有些任务存在冲突(如点击率和停留时长),有些任务数据分布差异巨大(如
CTR 样本量是 CVR 的 100
倍)。如何设计合适的网络架构、如何平衡不同任务的损失、如何处理负迁移问题,都是多任务学习中的核心挑战。
本文系统梳理多任务学习在推荐系统中的应用。我们将从多任务学习的动机开始,理解为什么需要多任务学习;然后深入
Shared-Bottom 、 ESMM 、 MMoE 、 PLE
等经典架构;接着探讨负迁移问题、任务关系建模、损失平衡策略等关键技术;最后通过完整的代码实现和工业实践案例,帮助读者掌握多任务学习的核心技术和实践方法。无论你是多任务学习的新手,还是想系统掌握工业级多任务推荐模型,这篇文章都能帮你建立完整的知识体系。
多任务学习的动机
推荐系统中的多目标问题
在推荐系统中,我们通常需要同时优化多个业务指标:
点击率(
CTR) :用户点击推荐物品的概率,直接影响推荐系统的曝光效果。
转化率(
CVR) :用户点击后发生转化(购买、下载、注册等)的概率,直接影响业务收益。
停留时长 :用户在推荐内容上的停留时间,反映内容质量和用户兴趣。
互动行为 :点赞、评论、分享、收藏等,反映用户对内容的深度参与。
长期价值 :用户留存、复购、生命周期价值等,反映推荐系统的长期影响。
这些目标之间存在复杂的关系: CTR 和 CVR
是顺序关系(先点击后转化),停留时长和互动行为可能正相关,但 CTR
和停留时长可能存在冲突(高 CTR
可能带来低停留时长)。传统的单任务学习为每个目标单独训练模型,存在以下问题:
模型维护成本高 :每个任务需要独立的模型、特征工程、训练流程和线上服务,维护成本随任务数量线性增长。
特征表示不共享 :不同任务的模型学习到的特征表示可能不一致,无法利用任务间的关联性。
数据利用不充分 :某些任务(如
CVR)的样本量远小于其他任务(如 CTR),单独训练容易过拟合。
线上服务复杂 :需要同时部署多个模型,推理延迟和资源消耗都较高。
多任务学习的优势
多任务学习通过共享底层特征表示,让多个任务共同学习,具有以下优势:
提升模型性能 :通过任务间的知识共享,每个任务都能从其他任务中学习到有用的特征表示,特别是在数据稀疏的任务上效果更明显。
降低模型复杂度 :共享底层参数,减少了总参数量,降低了过拟合风险。
提高训练效率 :一次训练可以同时优化多个目标,比单独训练多个模型更高效。
简化线上服务 :只需要部署一个模型,降低了服务复杂度和资源消耗。
更好的泛化能力 :多任务学习相当于一种正则化,提高了模型的泛化能力。
多任务学习的挑战
尽管多任务学习有诸多优势,但在实际应用中仍面临挑战:
任务关系复杂 :任务之间可能相关、冲突或独立,如何建模任务关系是多任务学习的核心问题。
负迁移问题 :当任务之间存在冲突时,共享参数可能导致某些任务性能下降,这就是负迁移(
Negative Transfer)。
损失平衡困难 :不同任务的损失尺度、梯度大小、优化难度都不同,如何平衡多个任务的损失是关键技术。
样本分布差异 :不同任务的样本量、正负样本比例、数据分布都不同,需要合适的采样和加权策略。
架构设计复杂 :如何在共享和独立之间找到平衡,设计合适的网络架构是多任务学习的关键。
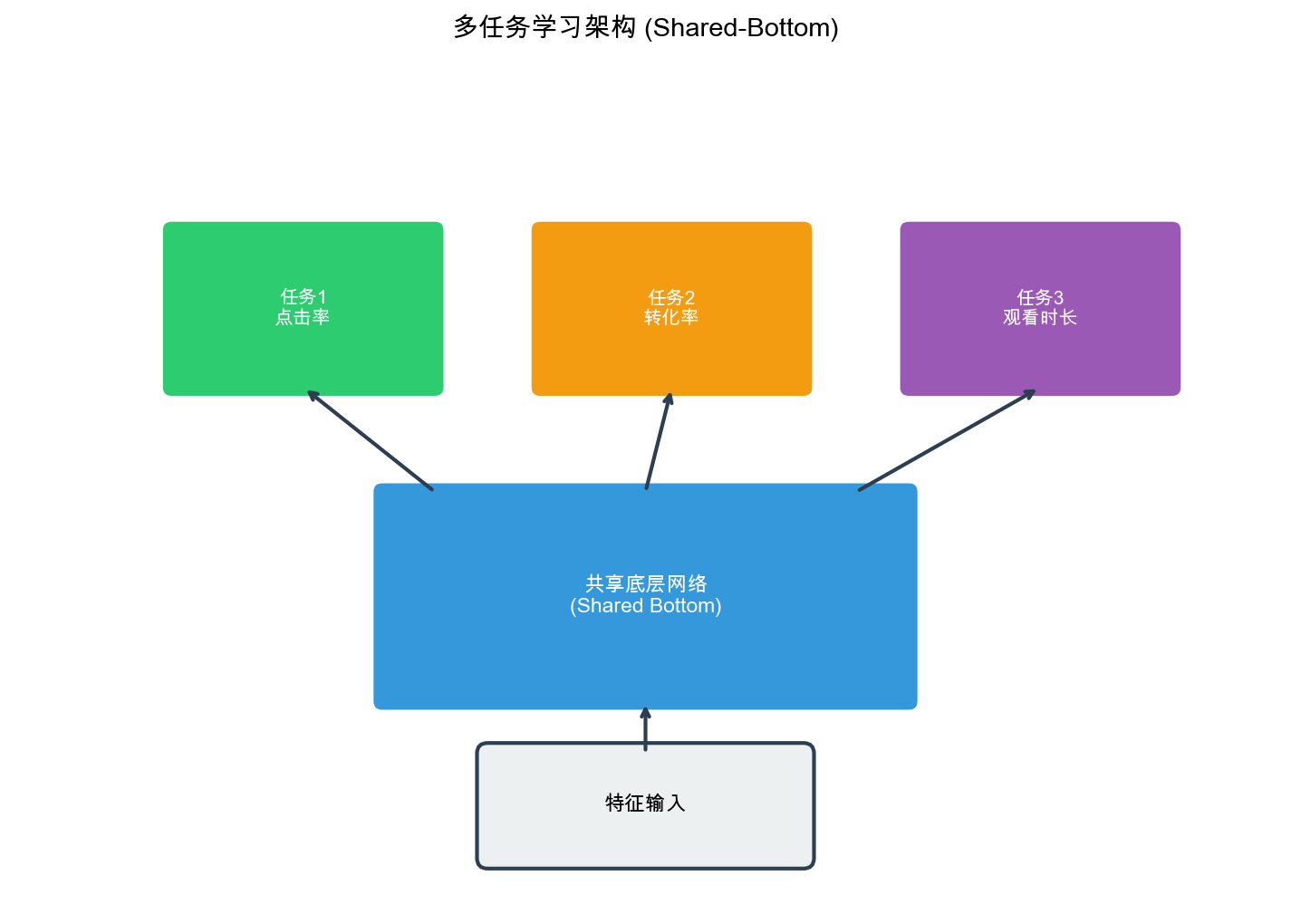
Shared-Bottom
架构:多任务学习的基础
架构设计
Shared-Bottom
架构是多任务学习最基础的架构,基本思路:多个任务共享底层特征表示(
Shared Bottom),每个任务有独立的顶层网络( Task-Specific Tower)。
共享底层网络将输入特征
每个任务的顶层网络基于共享表示
其中$f_{} 是 共 享 的 底 层 网 络 , 是 第 个 任 务 的 顶 层 网 络 ,
数学原理
Shared-Bottom 架构的损失函数为多个任务损失的加权和:
其中
在反向传播时,共享参数的梯度是多个任务梯度的加权和:
这意味着共享参数会同时受到多个任务的影响,学习到的特征表示需要同时满足多个任务的需求。
代码实现
下面我们实现一个完整的 Shared-Bottom
多任务学习模型。这个实现的基本思路:所有任务共享一个底层特征提取网络,然后每个任务有自己独立的预测塔 。这样做的好处是可以让不同任务在学习底层特征时相互帮助,特别是当某些任务的数据较少时,可以借助其他任务的数据学习到更好的特征表示。
在实际应用中,共享底层通常是一个多层的全连接网络(也可以是 CNN 、
Transformer
等),它将原始输入特征映射到一个共享的隐藏空间。每个任务的预测塔也是一个多层网络,它基于共享表示进行任务特定的预测。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 import torchimport torch.nn as nnimport torch.nn.functional as Fclass SharedBottom (nn.Module): """ Shared-Bottom 多任务学习架构 这是最基础的多任务学习架构,所有任务共享底层特征提取器。 适用于任务高度相关的场景,如 CTR 和 CVR 预估。 """ def __init__ (self, input_dim, shared_hidden_dims, task_hidden_dims, num_tasks, dropout=0.1 ): """ 初始化 Shared-Bottom 模型 Args: input_dim: 输入特征维度,例如 1000 维的用户和物品特征 shared_hidden_dims: 共享层隐藏层维度列表,如[512, 256] 表示两层全连接网络,维度依次为 512 和 256 task_hidden_dims: 任务塔隐藏层维度列表,如[128, 64] 每个任务塔都有相同的架构 num_tasks: 任务数量,例如 2 表示 CTR 和 CVR 两个任务 dropout: Dropout 比率,用于防止过拟合,通常设置为 0.1-0.3 """ super (SharedBottom, self).__init__() self.num_tasks = num_tasks shared_layers = [] prev_dim = input_dim for hidden_dim in shared_hidden_dims: shared_layers.append(nn.Linear(prev_dim, hidden_dim)) shared_layers.append(nn.ReLU()) shared_layers.append(nn.Dropout(dropout)) prev_dim = hidden_dim self.shared_bottom = nn.Sequential(*shared_layers) self.task_towers = nn.ModuleList() for _ in range (num_tasks): tower_layers = [] prev_dim = shared_hidden_dims[-1 ] for hidden_dim in task_hidden_dims: tower_layers.append(nn.Linear(prev_dim, hidden_dim)) tower_layers.append(nn.ReLU()) tower_layers.append(nn.Dropout(dropout)) prev_dim = hidden_dim tower_layers.append(nn.Linear(prev_dim, 1 )) self.task_towers.append(nn.Sequential(*tower_layers)) def forward (self, x ): """ 前向传播 Args: x: 输入特征, shape 为[batch_size, input_dim] batch_size 是批次大小, input_dim 是特征维度 Returns: outputs: 各任务的输出, list of [batch_size, 1] 每个任务返回一个预测值( logit) """ shared_output = self.shared_bottom(x) outputs = [] for tower in self.task_towers: output = tower(shared_output) outputs.append(output) return outputs model = SharedBottom( input_dim=1000 , shared_hidden_dims=[512 , 256 ], task_hidden_dims=[128 , 64 ], num_tasks=2 , dropout=0.1 ) x = torch.randn(32 , 1000 ) outputs = model(x) print (f"Task 1 output shape: {outputs[0 ].shape} " ) print (f"Task 2 output shape: {outputs[1 ].shape} " )
代码关键点解析 :
共享底层的作用 :共享底层网络是所有任务的"公共知识库",它学习的特征表示需要同时满足所有任务的需求。这要求任务之间有一定的相关性,否则共享可能导致负迁移。
任务塔的独立性 :虽然底层是共享的,但每个任务有独立的预测塔。这些塔可以学习任务特定的模式,例如
CTR 塔学习"什么样的特征容易被点击", CVR
塔学习"什么样的特征容易转化"。
参数量分析 :假设输入维度 1000,共享层[512,
256],任务塔[128, 64], 2 个任务。共享部分参数量约为: 1000 × 512 + 512
× 256 ≈ 643K 。每个任务塔参数量约为: 256 × 128 + 128 × 64 + 64 × 1 ≈
41K 。总参数量约为: 643K + 2 × 41K = 725K 。相比于两个独立模型(约 1.4M
参数),参数量减少了约 48%。
梯度流动 :在反向传播时,共享底层的梯度来自所有任务。如果任务
1 的梯度是
潜在问题 :当任务冲突时(例如梯度方向相反),共享底层可能学不好。这时需要考虑
MMoE 或 PLE 等更灵活的架构。
Shared-Bottom 的局限性
Shared-Bottom 架构虽然简单有效,但存在明显的局限性:
任务关系假设过强 :假设所有任务都高度相关,共享所有底层参数。当任务之间存在冲突时,共享参数可能导致负迁移。
灵活性不足 :所有任务共享相同的底层表示,无法根据任务特点进行差异化处理。
难以处理任务差异 :当任务的样本量、数据分布、优化难度差异很大时,
Shared-Bottom 难以平衡不同任务的需求。
ESMM:解决 CVR
预估的样本选择偏差
问题背景
在电商推荐系统中, CVR(转化率)预估是一个关键任务。 CVR
定义为:用户点击后发生转化(购买、下载等)的概率:转 化 数 点 击 数
然而, CVR 预估面临一个严重的问题:样本选择偏差( Sample
Selection Bias) 。
样本选择偏差的原因 : - CVR
模型只在点击样本上训练(只有点击的用户才能转化) -
但线上推理时需要在所有曝光样本上预测(包括未点击的样本) -
训练分布和推理分布不一致,导致模型性能下降
数据稀疏问题 : - CTR 样本量通常是 CVR 的 10-100 倍 -
CVR 样本极度稀疏,单独训练容易过拟合
ESMM 架构设计
ESMM( Entire Space Multi-Task Model)通过多任务学习解决了 CVR
预估的样本选择偏差问题。 ESMM 的基本思路:
利用 CTR 和 CTCVR 的完整空间 : - CTR:
数学关系 :
即:
其中
网络架构
ESMM 的网络架构包含: - 共享底层 :共享的特征提取层 -
CTR 塔 :预测点击率 - CVR
塔 :预测转化率(但只在点击样本上有标签) -
CTCVR :通过 CTR 和 CVR 的乘积计算
下面我们实现 ESMM( Entire Space Multi-Task Model)。 ESMM
的核心创新在于通过巧妙的多任务建模解决 CVR
预估中的样本选择偏差问题 。
问题背景 :传统的 CVR
模型只在点击样本上训练(因为只有点击的用户才可能转化),但在推理时需要在所有曝光样本上预测。这导致训练和推理的数据分布不一致,产生样本选择偏差。
ESMM 的解决方案 :不直接预测 CVR,而是同时预测 CTR 和
CTCVR 两个辅助任务,然后通过
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 class ESMM (nn.Module): """ ESMM: Entire Space Multi-Task Model for CVR Prediction ESMM 通过同时建模 CTR 和 CTCVR 两个任务,解决 CVR 预估中的样本选择偏差问题。 核心公式: CTCVR = CTR × CVR,因此 CVR = CTCVR / CTR """ def __init__ (self, input_dim, shared_hidden_dims, tower_hidden_dims, dropout=0.1 ): """ 初始化 ESMM 模型 Args: input_dim: 输入特征维度 shared_hidden_dims: 共享层隐藏层维度列表,如[256, 128] tower_hidden_dims: 任务塔隐藏层维度列表,如[64, 32] dropout: Dropout 比率 """ super (ESMM, self).__init__() shared_layers = [] prev_dim = input_dim for hidden_dim in shared_hidden_dims: shared_layers.append(nn.Linear(prev_dim, hidden_dim)) shared_layers.append(nn.ReLU()) shared_layers.append(nn.Dropout(dropout)) prev_dim = hidden_dim self.shared_bottom = nn.Sequential(*shared_layers) ctr_layers = [] prev_dim = shared_hidden_dims[-1 ] for hidden_dim in tower_hidden_dims: ctr_layers.append(nn.Linear(prev_dim, hidden_dim)) ctr_layers.append(nn.ReLU()) ctr_layers.append(nn.Dropout(dropout)) prev_dim = hidden_dim ctr_layers.append(nn.Linear(prev_dim, 1 )) ctr_layers.append(nn.Sigmoid()) self.ctr_tower = nn.Sequential(*ctr_layers) cvr_layers = [] prev_dim = shared_hidden_dims[-1 ] for hidden_dim in tower_hidden_dims: cvr_layers.append(nn.Linear(prev_dim, hidden_dim)) cvr_layers.append(nn.ReLU()) cvr_layers.append(nn.Dropout(dropout)) prev_dim = hidden_dim cvr_layers.append(nn.Linear(prev_dim, 1 )) cvr_layers.append(nn.Sigmoid()) self.cvr_tower = nn.Sequential(*cvr_layers) def forward (self, x ): """ ESMM 的前向传播 Args: x: 输入特征, shape 为[batch_size, input_dim] Returns: ctr: CTR 预测值, shape 为[batch_size, 1],范围(0, 1) cvr: CVR 预测值, shape 为[batch_size, 1],范围(0, 1) ctcvr: CTCVR 预测值, shape 为[batch_size, 1],范围(0, 1) """ shared_output = self.shared_bottom(x) ctr = self.ctr_tower(shared_output) cvr = self.cvr_tower(shared_output) ctcvr = ctr * cvr return ctr, cvr, ctcvr def esmm_loss (ctr_pred, cvr_pred, ctcvr_pred, ctr_label, cvr_label, ctcvr_label ): """ ESMM 的损失函数 关键点: 1. CTR 损失在所有曝光样本上计算 2. CTCVR 损失也在所有曝光样本上计算 3. CVR 没有直接的损失,而是通过 CTCVR = CTR × CVR 的约束间接优化 Args: ctr_pred: CTR 预测值, shape 为[batch_size, 1] cvr_pred: CVR 预测值, shape 为[batch_size, 1](实际不用于损失计算) ctcvr_pred: CTCVR 预测值, shape 为[batch_size, 1] ctr_label: CTR 标签, shape 为[batch_size, 1], 1 表示点击, 0 表示未点击 cvr_label: CVR 标签(实际不用于损失计算) ctcvr_label: CTCVR 标签, shape 为[batch_size, 1], 1 表示点击且转化, 0 表示其他 Returns: total_loss: 总损失 ctr_loss: CTR 任务的损失 ctcvr_loss: CTCVR 任务的损失 """ ctr_loss = F.binary_cross_entropy(ctr_pred, ctr_label) ctcvr_loss = F.binary_cross_entropy(ctcvr_pred, ctcvr_label) total_loss = ctr_loss + ctcvr_loss return total_loss, ctr_loss, ctcvr_loss
ESMM 的关键技术细节 :
完整空间建模 : CTR 和 CTCVR
都在所有曝光样本上计算损失,这是避免样本选择偏差的关键。对于未点击的样本,
CTR 标签为 0, CTCVR 标签也为 0(未点击就不可能转化)。
隐式 CVR 监督 :虽然 CVR
塔没有直接的损失函数,但通过
推理时的 CVR 计算 :在推理阶段,可以直接使用 CVR
塔的输出,或者使用
数据标签构造 :
CTR 标签:所有曝光样本都有, 1 表示点击, 0 表示未点击
CVR 标签:理论上只有点击样本有,但在 ESMM 中我们不直接使用
CTCVR 标签:所有曝光样本都有, 1 表示点击且转化, 0
表示其他情况
优势分析 :假设 CTR 样本量是 100 万,但只有 10
万次点击,其中 1 万次转化。传统 CVR 模型只能在 10 万点击样本上训练,而
ESMM 可以在 100 万曝光样本上训练 CTCVR
任务,大大增加了可用数据量。
ESMM 的优势
解决样本选择偏差 : CTR 和 CTCVR
都在完整空间(所有曝光样本)上训练,避免了样本选择偏差。
利用 CTR 数据 :通过共享底层参数, CVR 塔可以从 CTR
任务中学习有用的特征表示,缓解数据稀疏问题。
端到端训练 : CTR 和 CTCVR 同时训练,保证了 CVR =
CTCVR / CTR 的关系一致性。
ESMM 的局限性
假设 CTR 和 CVR 共享底层 :当 CTR 和 CVR
的特征需求差异很大时,共享底层可能导致负迁移。
CVR 塔缺乏直接监督 : CVR
塔只在点击样本上有标签,训练信号较弱。
除零问题 :当 CTR 很小时, CVR = CTCVR / CTR
可能不稳定。
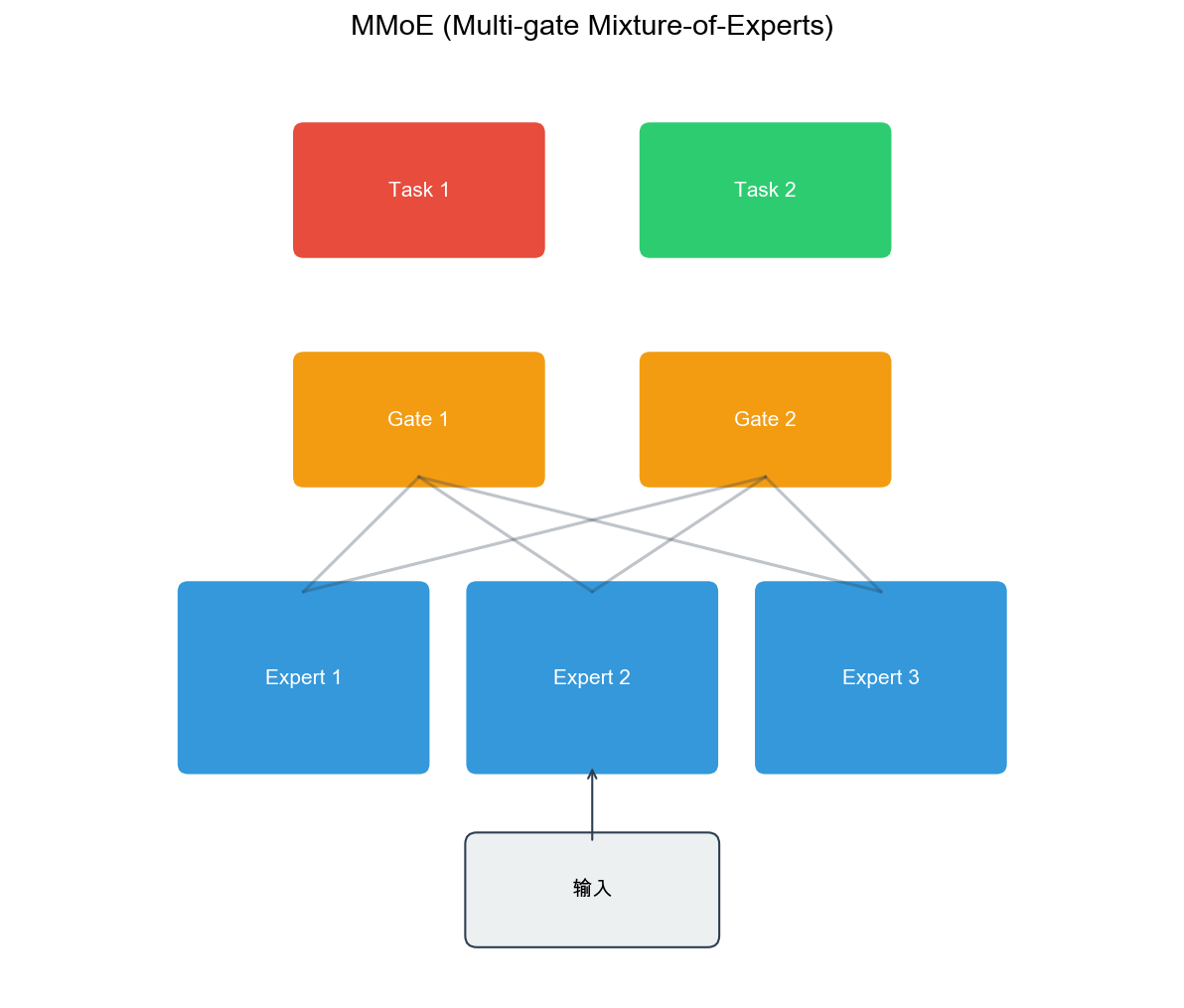
MMoE:多门控混合专家模型
动机:解决任务冲突问题
Shared-Bottom
架构假设所有任务高度相关,但当任务之间存在冲突时,共享参数可能导致负迁移。
MMoE( Multi-gate Mixture-of-Experts)通过引入多个专家(
Expert)和门控网络( Gate),让模型自动学习任务间的共享和独立关系。
架构设计
MMoE 的核心组件:
专家网络(
Expert) :多个独立的专家网络,每个专家学习不同的特征表示。
门控网络(
Gate) :每个任务有独立的门控网络,决定如何组合专家网络的输出。
任务塔(
Tower) :每个任务有独立的顶层网络,处理任务特定的特征。
数学表示:输 出 门 控 权 重 任 务 输 入 任 务 输 出
其中
代码实现
MMoE( Multi-gate Mixture-of-Experts)是 Google
提出的一个经典多任务学习架构。基本思路:使用多个专家网络学习不同的特征表示,每个任务通过独立的门控网络决定如何组合这些专家 。这样,相关性高的任务可以共享相同的专家,而冲突的任务可以选择不同的专家,从而避免负迁移。
在实现时,需要注意以下几点: 1. 专家网络的数量通常设置为任务数量的
1-3 倍 2. 门控网络使用 Softmax 确保权重和为 1 3.
每个任务的输入是所有专家输出的加权和 4.
梯度可以通过门控权重反向传播到各个专家
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 class Expert (nn.Module): """ 专家网络 每个专家是一个独立的多层全连接网络,学习特定的特征变换。 不同的专家可能关注输入特征的不同方面。 """ def __init__ (self, input_dim, hidden_dim, dropout=0.1 ): """ Args: input_dim: 输入特征维度 hidden_dim: 专家网络的输出维度 dropout: Dropout 比率 """ super (Expert, self).__init__() self.network = nn.Sequential( nn.Linear(input_dim, hidden_dim), nn.ReLU(), nn.Dropout(dropout), nn.Linear(hidden_dim, hidden_dim), nn.ReLU(), nn.Dropout(dropout) ) def forward (self, x ): """ Args: x: 输入特征, shape 为[batch_size, input_dim] Returns: 输出特征, shape 为[batch_size, hidden_dim] """ return self.network(x) class Gate (nn.Module): """ 门控网络 门控网络为每个任务生成一组权重,决定如何组合各个专家的输出。 使用 Softmax 确保权重和为 1,可以理解为专家的"重要性分布"。 """ def __init__ (self, input_dim, num_experts ): """ Args: input_dim: 输入特征维度(原始输入,不是专家输出) num_experts: 专家数量 """ super (Gate, self).__init__() self.gate_network = nn.Sequential( nn.Linear(input_dim, num_experts), nn.Softmax(dim=-1 ) ) def forward (self, x ): """ Args: x: 输入特征, shape 为[batch_size, input_dim] Returns: 门控权重, shape 为[batch_size, num_experts] 每一行的权重和为 1 """ return self.gate_network(x) class MMoE (nn.Module): """ MMoE: Multi-gate Mixture-of-Experts MMoE 通过多个专家网络和门控机制,让每个任务自动学习如何组合专家, 从而适应任务间的相关性和冲突,避免负迁移。 """ def __init__ (self, input_dim, num_experts, expert_hidden_dim, task_hidden_dims, num_tasks, dropout=0.1 ): """ 初始化 MMoE 模型 Args: input_dim: 输入特征维度 num_experts: 专家数量,通常设置为任务数量的 1-3 倍 expert_hidden_dim: 专家网络的输出维度 task_hidden_dims: 任务塔隐藏层维度列表 num_tasks: 任务数量 dropout: Dropout 比率 """ super (MMoE, self).__init__() self.num_experts = num_experts self.num_tasks = num_tasks self.experts = nn.ModuleList([ Expert(input_dim, expert_hidden_dim, dropout) for _ in range (num_experts) ]) self.gates = nn.ModuleList([ Gate(input_dim, num_experts) for _ in range (num_tasks) ]) self.task_towers = nn.ModuleList() for _ in range (num_tasks): tower_layers = [] prev_dim = expert_hidden_dim for hidden_dim in task_hidden_dims: tower_layers.append(nn.Linear(prev_dim, hidden_dim)) tower_layers.append(nn.ReLU()) tower_layers.append(nn.Dropout(dropout)) prev_dim = hidden_dim tower_layers.append(nn.Linear(prev_dim, 1 )) self.task_towers.append(nn.Sequential(*tower_layers)) def forward (self, x ): """ MMoE 的前向传播 流程: 1. 所有专家网络处理输入,得到多个专家输出 2. 每个任务的门控网络计算专家权重 3. 每个任务将专家输出加权求和,得到任务特定的输入 4. 每个任务塔基于加权输入进行预测 Args: x: 输入特征, shape 为[batch_size, input_dim] Returns: outputs: 各任务的输出, list of [batch_size, 1] """ expert_outputs = [] for expert in self.experts: expert_outputs.append(expert(x)) expert_outputs = torch.stack(expert_outputs, dim=1 ) outputs = [] for i in range (self.num_tasks): gate_weights = self.gates[i](x) gate_weights = gate_weights.unsqueeze(-1 ) task_input = (expert_outputs * gate_weights).sum (dim=1 ) output = self.task_towers[i](task_input) outputs.append(output) return outputs model = MMoE( input_dim=1000 , num_experts=4 , expert_hidden_dim=256 , task_hidden_dims=[128 , 64 ], num_tasks=2 , dropout=0.1 ) x = torch.randn(32 , 1000 ) outputs = model(x) print (f"Task 1 output shape: {outputs[0 ].shape} " ) print (f"Task 2 output shape: {outputs[1 ].shape} " )
MMoE 的关键技术细节 :
门控权重的含义 :假设任务 1 的门控权重为[0.5,
0.3, 0.1, 0.1],这意味着任务 1 主要依赖专家 1( 50%)和专家 2(
30%),较少依赖专家 3 和专家 4 。如果任务 2 的权重为[0.1, 0.1, 0.4,
0.4],则说明两个任务关注不同的专家,可能学习不同的特征模式。
专家数量的选择 :专家数量是一个重要的超参数。太少的专家可能无法捕获任务间的多样性,太多的专家会增加计算成本和过拟合风险。通常设置为:
2 个任务: 3-6 个专家
3-5 个任务: 4-8 个专家
更多任务: 8-12 个专家
与 Shared-Bottom 的对比 : Shared-Bottom
可以看作是 MMoE 的一个特例——只有 1 个专家,所有任务的门控权重都是 1 。
MMoE 通过增加专家数量和引入门控机制,提供了更大的灵活性。
梯度流动分析 :在反向传播时,每个专家接收到的梯度是所有任务梯度的加权和,权重由门控网络决定。如果某个专家对任务
1 的权重是 0.8,对任务 2 的权重是 0.2,那么该专家的梯度主要来自任务 1
。
计算复杂度 :假设输入维度
门控网络的设计变体 :标准 MMoE
使用简单的线性门控,但也可以使用:
多层 MLP 门控:提高门控的表达能力
注意力机制:让门控权重依赖于输入的局部特征
可学习的温度参数:控制 Softmax 的锐度
MMoE 的优势
灵活的任务关系建模 :通过门控网络,每个任务可以自动学习如何组合专家,适应任务间的相关性和冲突。
避免负迁移 :当任务冲突时,门控网络可以给冲突的专家分配低权重,减少负迁移。
参数效率 :相比为每个任务单独训练模型, MMoE
共享专家网络,参数更少。
MMoE 的局限性
专家数量选择困难 :专家数量需要人工设定,不同任务组合可能需要不同的专家数量。
门控网络可能退化 :当任务高度相关时,门控网络可能退化为均匀分配,失去灵活性。
计算复杂度 :相比 Shared-Bottom, MMoE
需要额外的门控网络计算。
PLE:渐进式分层提取
动机:解决负迁移和跷跷板现象
MMoE 虽然解决了任务冲突问题,但在实际应用中仍存在两个问题:
负迁移 :当任务相关性较低时,共享专家可能导致某些任务性能下降。
跷跷板现象( Seesaw
Phenomenon) :优化一个任务时,另一个任务的性能下降,难以同时提升多个任务。
PLE( Progressive Layered Extraction)通过引入任务特定专家(
Task-Specific Expert)和共享专家( Shared
Expert),并采用渐进式分层结构,进一步解决了这些问题。
架构设计
PLE 的核心思想:
任务特定专家 + 共享专家 : -
每个任务有独立的专家网络(任务特定专家) -
所有任务共享部分专家网络(共享专家) - 通过门控网络决定如何组合
渐进式分层 : - 底层:任务特定专家和共享专家 -
中层:可以进一步提取任务特定和共享特征 - 顶层:任务塔
数学表示(以两层为例):Extra close brace or missing open brace \text{底层共享专家: } E_s^1(\mathbf{x}) = \{e_{s,1}^1(\mathbf{x}), \dots, e_{s,n_s}^1(\mathbf{x})} Extra close brace or missing open brace \text{底层任务特定专家: } E_k^1(\mathbf{x}) = \{e_{k,1}^1(\mathbf{x}), \dots, e_{k,n_k}^1(\mathbf{x})} , \quad k \in \{1, \dots, T\} 底 层 门 控 底 层 输 出 Extra close brace or missing open brace \text{中层共享专家: } E_s^2(\mathbf{h}_k^1) = \{e_{s,1}^2(\mathbf{h}_k^1), \dots, e_{s,n_s}^2(\mathbf{h}_k^1)} Extra close brace or missing open brace \text{中层任务特定专家: } E_k^2(\mathbf{h}_k^1) = \{e_{k,1}^2(\mathbf{h}_k^1), \dots, e_{k,n_k}^2(\mathbf{h}_k^1)} 中 层 门 控 最 终 输 出
代码实现
PLE( Progressive Layered Extraction)是腾讯提出的改进架构,它解决了
MMoE 在任务相关性较低时的负迁移问题。 PLE
的核心创新是:引入任务特定专家( Task-Specific
Expert)和共享专家( Shared
Expert)的分离,并采用渐进式分层结构 。
设计思路 : 1.
每个任务有专属的专家网络,只为该任务服务,避免被其他任务的梯度"污染" 2.
保留共享专家,让任务间仍能学习公共知识 3.
多层渐进提取,让任务在不同抽象层次上进行不同程度的共享
这种设计在保持任务间知识共享的同时,给每个任务足够的独立性,有效缓解了跷跷板现象(优化一个任务导致另一个任务性能下降)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 class PLE (nn.Module): """ PLE: Progressive Layered Extraction PLE 通过分离任务特定专家和共享专家,并采用多层渐进式结构, 解决了 MMoE 的负迁移和跷跷板现象。 """ def __init__ (self, input_dim, num_layers, num_shared_experts, num_task_specific_experts, expert_hidden_dim, task_hidden_dims, num_tasks, dropout=0.1 ): """ 初始化 PLE 模型 Args: input_dim: 输入特征维度 num_layers: PLE 层数,通常设置为 2-3 层 num_shared_experts: 每层的共享专家数量 num_task_specific_experts: 每层每个任务的任务特定专家数量 expert_hidden_dim: 专家网络的输出维度 task_hidden_dims: 任务塔隐藏层维度列表 num_tasks: 任务数量 dropout: Dropout 比率 """ super (PLE, self).__init__() self.num_layers = num_layers self.num_shared_experts = num_shared_experts self.num_task_specific_experts = num_task_specific_experts self.num_tasks = num_tasks self.ple_layers = nn.ModuleList() prev_dim = input_dim for layer_idx in range (num_layers): shared_experts = nn.ModuleList([ Expert(prev_dim, expert_hidden_dim, dropout) for _ in range (num_shared_experts) ]) task_specific_experts = nn.ModuleList() for _ in range (num_tasks): task_experts = nn.ModuleList([ Expert(prev_dim, expert_hidden_dim, dropout) for _ in range (num_task_specific_experts) ]) task_specific_experts.append(task_experts) gates = nn.ModuleList() for task_idx in range (num_tasks): num_total_experts = num_shared_experts + num_task_specific_experts gate_input_dim = prev_dim gate = Gate(gate_input_dim, num_total_experts) gates.append(gate) self.ple_layers.append(nn.ModuleDict({ 'shared_experts' : shared_experts, 'task_specific_experts' : task_specific_experts, 'gates' : gates })) prev_dim = expert_hidden_dim self.task_towers = nn.ModuleList() for _ in range (num_tasks): tower_layers = [] prev_dim = expert_hidden_dim for hidden_dim in task_hidden_dims: tower_layers.append(nn.Linear(prev_dim, hidden_dim)) tower_layers.append(nn.ReLU()) tower_layers.append(nn.Dropout(dropout)) prev_dim = hidden_dim tower_layers.append(nn.Linear(prev_dim, 1 )) self.task_towers.append(nn.Sequential(*tower_layers)) def forward (self, x ): """ PLE 的前向传播 流程: 1. 逐层处理:每层都有共享专家和任务特定专家 2. 在每层,每个任务通过门控组合专家输出 3. 最后通过任务塔输出最终预测 Args: x: 输入特征, shape 为[batch_size, input_dim] Returns: outputs: 各任务的输出, list of [batch_size, 1] """ task_outputs = [x] * self.num_tasks for layer_idx, layer in enumerate (self.ple_layers): shared_experts = layer['shared_experts' ] task_specific_experts = layer['task_specific_experts' ] gates = layer['gates' ] shared_outputs = [] for expert in shared_experts: shared_outputs.append(expert(task_outputs[0 ])) shared_outputs = torch.stack(shared_outputs, dim=1 ) new_task_outputs = [] for task_idx in range (self.num_tasks): task_expert_outputs = [] for expert in task_specific_experts[task_idx]: task_expert_outputs.append(expert(task_outputs[task_idx])) task_expert_outputs = torch.stack(task_expert_outputs, dim=1 ) all_expert_outputs = torch.cat([shared_outputs, task_expert_outputs], dim=1 ) gate_weights = gates[task_idx](task_outputs[task_idx]) gate_weights = gate_weights.unsqueeze(-1 ) task_output = (all_expert_outputs * gate_weights).sum (dim=1 ) new_task_outputs.append(task_output) task_outputs = new_task_outputs outputs = [] for i, tower in enumerate (self.task_towers): output = tower(task_outputs[i]) outputs.append(output) return outputs model = PLE( input_dim=1000 , num_layers=2 , num_shared_experts=2 , num_task_specific_experts=2 , expert_hidden_dim=256 , task_hidden_dims=[128 , 64 ], num_tasks=2 , dropout=0.1 ) x = torch.randn(32 , 1000 ) outputs = model(x) print (f"Task 1 output shape: {outputs[0 ].shape} " ) print (f"Task 2 output shape: {outputs[1 ].shape} " )
PLE 的关键技术细节 :
任务特定专家 vs 共享专家 :
任务特定专家只接收特定任务的梯度,学习任务特有的模式
共享专家接收所有任务的梯度,学习任务间的公共知识
门控网络决定两类专家的权重比例
渐进式提取的好处 :
底层:学习基础特征,任务间共享较多
中层:学习中级特征,开始出现任务特定模式
顶层:学习高级特征,任务独立性增强
多层结构允许任务在不同抽象层次上有不同的共享程度
参数量分析 :假设 2 个任务, 2 层 PLE,每层 2
个共享专家和 2 个任务特定专家,输入维度 1000,专家输出 256 。
第 1 层: 2 个共享专家 + 2 × 2 个任务特定专家 = 6 个专家,参数量约 6
× 1000 × 256 ≈ 1.5M
第 2 层:同样约 1.5M 参数(输入变为 256 维)
总共约 3M 参数 + 门控参数 + 任务塔参数
相比 MMoE( 4 个专家), PLE 参数量更大,但避免了负迁移
与 MMoE 的对比 :
MMoE:所有专家共享,灵活性高但可能负迁移
PLE:分离任务特定和共享专家,牺牲部分参数效率换取更好的任务平衡
跷跷板现象的缓解 :当任务 1
需要优化时,它可以更多地依赖任务特定专家,而不影响共享专家(任务 2
也在使用)。这样任务 1 的优化不会直接伤害任务 2 的性能。
工业实践建议 :
任务高度相关:可以减少任务特定专家,增加共享专家
任务存在冲突:增加任务特定专家,减少共享专家
层数选择: 2 层通常足够, 3 层在复杂场景下可能有提升
调试技巧:可以打印门控权重,观察任务如何使用不同类型的专家
PLE 的优势
解决负迁移 :通过任务特定专家,每个任务可以学习独立的特征表示,避免负迁移。
缓解跷跷板现象 :渐进式分层结构允许任务在不同层次上进行不同程度的共享和独立。
更好的任务平衡 :任务特定专家和共享专家的组合,让模型更好地平衡任务间的相关性和独立性。
PLE 的局限性
架构复杂度高 :相比 MMoE, PLE
的架构更复杂,需要更多的超参数调优。
计算成本高 :任务特定专家增加了参数量和计算量。
STEM-Net:解决负迁移问题
负迁移问题
负迁移( Negative
Transfer)是多任务学习中的核心问题:当任务之间存在冲突或相关性较低时,共享参数可能导致某些任务性能下降。
负迁移的原因 : -
任务冲突:优化一个任务的方向与另一个任务相反 -
任务相关性低:任务之间没有足够的共同知识可以共享 -
数据分布差异:不同任务的数据分布差异很大
STEM-Net 架构
STEM-Net( Selective Transfer and Extraction
Network)通过选择性迁移机制解决负迁移问题。与 PLE 不同, STEM-Net
的核心创新在于显式学习任务间的相似度,并根据相似度动态调整共享程度 。
核心设计思想 : 1.
任务相似度学习 :通过可学习的任务嵌入( Task
Embedding)和相似度网络,自动学习任务间的相似度矩阵。相似度高的任务可以更多地共享参数,相似度低的任务则减少共享。
2.
双重特征提取路径 :每个任务同时拥有共享底层和任务特定底层两个特征提取路径。共享底层学习任务间的公共知识,任务特定底层学习任务特有的模式。
3.
选择性组合 :根据任务相似度,动态决定如何组合共享特征和任务特定特征。相似度高的任务更依赖共享特征,相似度低的任务更依赖任务特定特征。
与 Shared-Bottom 和 PLE 的对比 : -
Shared-Bottom:所有任务强制共享所有底层参数,无法处理任务冲突 -
PLE:通过任务特定专家和共享专家的分离缓解负迁移,但不显式建模任务相似度
- STEM-Net:显式学习任务相似度,根据相似度动态调整共享策略,更加灵活
下面我们实现 STEM-Net
模型。这个实现展示了如何通过任务嵌入和相似度网络来学习任务关系,以及如何通过双重特征提取路径来平衡共享和独立。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 class STEMNet (nn.Module): """ STEM-Net: Selective Transfer and Extraction Network STEM-Net 通过显式学习任务相似度来解决负迁移问题。 核心机制: 1. 任务嵌入:将每个任务映射到一个低维向量空间 2. 相似度网络:基于任务嵌入计算任务间的相似度 3. 双重路径:共享底层 + 任务特定底层 4. 选择性组合:根据相似度动态组合两种特征 """ def __init__ (self, input_dim, shared_hidden_dims, task_hidden_dims, num_tasks, similarity_dim=64 , dropout=0.1 ): """ 初始化 STEM-Net 模型 Args: input_dim: 输入特征维度,例如 1000 维的用户和物品特征 shared_hidden_dims: 共享层隐藏层维度列表,如[512, 256] 共享底层和任务特定底层都使用相同的维度结构 task_hidden_dims: 任务塔隐藏层维度列表,如[128, 64] 任务塔的输入维度是共享维度× 2(共享特征+任务特定特征拼接) num_tasks: 任务数量,例如 2 表示 CTR 和 CVR 两个任务 similarity_dim: 任务相似度表示维度,用于任务嵌入 较大的维度可以学习更复杂的任务关系,但会增加参数量 通常设置为 32-128 之间 dropout: Dropout 比率,用于防止过拟合 """ super (STEMNet, self).__init__() self.num_tasks = num_tasks self.similarity_dim = similarity_dim self.task_embedding = nn.Embedding(num_tasks, similarity_dim) self.similarity_network = nn.Sequential( nn.Linear(similarity_dim * 2 , similarity_dim), nn.ReLU(), nn.Linear(similarity_dim, 1 ), nn.Sigmoid() ) shared_layers = [] prev_dim = input_dim for hidden_dim in shared_hidden_dims: shared_layers.append(nn.Linear(prev_dim, hidden_dim)) shared_layers.append(nn.ReLU()) shared_layers.append(nn.Dropout(dropout)) prev_dim = hidden_dim self.shared_bottom = nn.Sequential(*shared_layers) self.task_specific_bottoms = nn.ModuleList() for task_idx in range (num_tasks): task_layers = [] prev_dim = input_dim for hidden_dim in shared_hidden_dims: task_layers.append(nn.Linear(prev_dim, hidden_dim)) task_layers.append(nn.ReLU()) task_layers.append(nn.Dropout(dropout)) prev_dim = hidden_dim self.task_specific_bottoms.append(nn.Sequential(*task_layers)) self.task_towers = nn.ModuleList() for task_idx in range (num_tasks): tower_layers = [] prev_dim = shared_hidden_dims[-1 ] * 2 for hidden_dim in task_hidden_dims: tower_layers.append(nn.Linear(prev_dim, hidden_dim)) tower_layers.append(nn.ReLU()) tower_layers.append(nn.Dropout(dropout)) prev_dim = hidden_dim tower_layers.append(nn.Linear(prev_dim, 1 )) self.task_towers.append(nn.Sequential(*tower_layers)) def compute_task_similarity (self, task_i, task_j ): """ 计算两个任务之间的相似度 这个方法展示了如何基于任务嵌入计算相似度。 在实际应用中,相似度可以用于: 1. 动态调整共享程度(相似度高的任务更多共享) 2. 分析任务关系(理解哪些任务相关,哪些冲突) 3. 指导架构设计(相似度低的任务应该减少共享) Args: task_i: 任务 i 的 ID(标量或 tensor) task_j: 任务 j 的 ID(标量或 tensor) Returns: similarity: 任务相似度,范围[0, 1], shape 取决于输入 """ task_i_emb = self.task_embedding(task_i) task_j_emb = self.task_embedding(task_j) similarity_input = torch.cat([task_i_emb, task_j_emb], dim=-1 ) similarity = self.similarity_network(similarity_input) return similarity def forward (self, x, task_ids=None ): """ STEM-Net 的前向传播 前向传播流程: 1. 提取共享特征:所有任务共享的底层特征 2. 提取任务特定特征:每个任务独立的底层特征 3. 选择性组合:根据任务相似度(简化实现中直接拼接)组合两种特征 4. 任务塔预测:基于组合特征进行任务特定的预测 Args: x: 输入特征, shape 为[batch_size, input_dim] task_ids: 任务 ID, shape 为[batch_size](可选,用于动态计算相似度) 在当前简化实现中未使用,但可以扩展为根据相似度动态调整组合权重 Returns: outputs: 各任务的输出, list of [batch_size, 1] 每个任务返回一个预测值( logit) """ shared_output = self.shared_bottom(x) task_specific_outputs = [] for task_bottom in self.task_specific_bottoms: task_specific_output = task_bottom(x) task_specific_outputs.append(task_specific_output) outputs = [] for task_idx in range (self.num_tasks): task_specific_output = task_specific_outputs[task_idx] combined_output = torch.cat([shared_output, task_specific_output], dim=-1 ) output = self.task_towers[task_idx](combined_output) outputs.append(output) return outputs
STEM-Net 的关键技术细节 :
任务相似度学习的意义 :任务嵌入和相似度网络让模型能够自动发现任务间的关系。例如,如果
CTR 和 CVR
任务的嵌入向量在嵌入空间中距离很近,相似度网络会输出较高的相似度分数,表示这两个任务可以更多地共享参数。这种显式的相似度学习比隐式的共享机制(如
Shared-Bottom)更加灵活和可解释。
双重特征提取路径的设计 :
共享底层 :学习所有任务的公共知识,参数量为任务特定底层 :每个任务独立的底层,总参数量为总参数量 :共享参数量 +
任务特定参数量,比完全独立的模型少,但比完全共享的模型多 选择性组合的扩展 :当前实现中,我们简单地拼接共享特征和任务特定特征。更高级的实现可以根据任务相似度动态调整组合权重:
1 2 3 4 5 6 similarities = [self.compute_task_similarity(task_idx, j) for j in range (self.num_tasks)] avg_similarity = torch.mean(torch.stack(similarities)) combined_output = avg_similarity * shared_output + (1 - avg_similarity) * task_specific_output
与 PLE 的对比 :
PLE :通过任务特定专家和共享专家的分离来缓解负迁移,但不显式学习任务相似度STEM-Net :显式学习任务相似度,并根据相似度动态调整共享策略适用场景 : STEM-Net
更适合任务关系复杂、需要精细控制共享程度的场景 参数量分析 :假设输入维度 1000,共享层[512,
256], 2 个任务,相似度维度 64 。
任务嵌入:
相似度网络:
共享底层:
任务特定底层:
任务塔:
总参数量约 2.1M,比两个完全独立的模型(约 2.8M)少约 25%
训练技巧 :
任务嵌入的初始化:可以使用预训练的任务嵌入,或者根据任务标签的相似度初始化
相似度正则化:可以添加正则化项,鼓励相似度高的任务嵌入接近,相似度低的任务嵌入远离
动态相似度更新:在训练过程中,任务相似度会随着模型学习而更新,反映任务间的实际关系
任务关系建模
任务相似度度量
在多任务学习中,理解任务间的关系至关重要。常见的任务相似度度量方法:
相关性分析 : -
皮尔逊相关系数:衡量任务标签之间的线性相关性 -
互信息:衡量任务标签之间的非线性相关性
梯度相似度 : - 计算不同任务在共享参数上的梯度相似度
- 梯度方向相似表示任务相关,相反表示任务冲突
特征相似度 : - 计算不同任务学习到的特征表示的相似度
- 使用余弦相似度、欧氏距离等度量
动态任务关系学习
在多任务学习中,任务间的关系不是静态的,而是会随着训练过程动态变化。例如,在训练初期,
CTR 和 CVR 任务可能都关注基础的用户特征,关系较密切;但随着训练的深入,
CVR 任务可能开始关注更细粒度的转化相关特征,与 CTR
的关系可能发生变化。
动态任务关系学习通过可学习的任务嵌入和关系预测网络,让模型自动发现和更新任务间的关系。这种方法比固定的人工设计关系更加灵活,能够适应不同训练阶段的任务关系变化。
下面我们实现一个通用的任务关系建模模块。这个模块可以学习任务间的三种基本关系:相关(可以共享参数)、冲突(应该独立学习)、独立(互不影响)。在实际应用中,可以根据学习到的关系动态调整多任务架构的共享策略。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 class TaskRelationshipModel (nn.Module): """ 任务关系建模模块 这个模块通过学习任务嵌入和关系预测网络,自动发现任务间的关系。 关系类型: 1. 相关( Positive):任务可以共享参数,相互促进 2. 冲突( Negative):任务存在冲突,应该减少共享 3. 独立( Neutral):任务互不影响,可以独立学习 应用场景: - 指导多任务架构设计(哪些任务应该共享,哪些应该独立) - 动态调整损失权重(相关任务可以共享权重,冲突任务需要平衡) - 分析任务关系(理解为什么某些任务组合效果好,某些效果差) """ def __init__ (self, num_tasks, embedding_dim=64 ): """ 初始化任务关系建模模块 Args: num_tasks: 任务数量,例如 2 表示 CTR 和 CVR 两个任务 embedding_dim: 任务嵌入维度,用于表示任务的"身份特征" - 较大的维度可以学习更复杂的任务关系 - 但会增加参数量和计算成本 - 通常设置为 32-128 之间 """ super (TaskRelationshipModel, self).__init__() self.num_tasks = num_tasks self.embedding_dim = embedding_dim self.task_embeddings = nn.Embedding(num_tasks, embedding_dim) self.relationship_network = nn.Sequential( nn.Linear(embedding_dim * 2 , embedding_dim), nn.ReLU(), nn.Linear(embedding_dim, 3 ) ) def forward (self, task_i, task_j ): """ 预测任务 i 和任务 j 的关系 这个方法展示了如何基于任务嵌入预测任务关系。 在实际应用中,预测的关系可以用于: 1. 动态调整多任务架构的共享策略 2. 指导损失权重的设置 3. 分析任务间的相互作用 Args: task_i: 任务 i 的 ID,可以是标量(单个任务)或 tensor(批量任务) 例如: torch.tensor(0) 表示 CTR 任务 task_j: 任务 j 的 ID,格式同 task_i 例如: torch.tensor(1) 表示 CVR 任务 Returns: relationship_logits: 关系类型的 logits, shape 为[3]或[batch_size, 3] - relationship_logits[0]: "相关"关系的 logit - relationship_logits[1]: "冲突"关系的 logit - relationship_logits[2]: "独立"关系的 logit 可以通过 Softmax 得到概率分布 """ task_i_emb = self.task_embeddings(task_i) task_j_emb = self.task_embeddings(task_j) relationship_input = torch.cat([task_i_emb, task_j_emb], dim=-1 ) relationship_logits = self.relationship_network(relationship_input) return relationship_logits def get_task_similarity_matrix (self ): """ 计算所有任务对的相似度矩阵 这个方法返回一个对称矩阵,表示所有任务对之间的相似度。 可以用于可视化任务关系,或者指导多任务架构的设计。 Returns: similarity_matrix: 任务相似度矩阵, shape 为[num_tasks, num_tasks] similarity_matrix[i][j] 表示任务 i 和任务 j 的相似度 """ similarity_matrix = torch.zeros(self.num_tasks, self.num_tasks) with torch.no_grad(): for i in range (self.num_tasks): for j in range (self.num_tasks): logits = self.forward(torch.tensor(i), torch.tensor(j)) probs = torch.softmax(logits, dim=-1 ) similarity_matrix[i][j] = probs[0 ].item() return similarity_matrix
任务关系建模的关键技术细节 :
任务嵌入的学习 :任务嵌入是可学习的参数,在训练过程中会不断更新。如果两个任务在训练过程中经常产生相似的梯度(表示它们关注相似的特征),它们的嵌入向量会在嵌入空间中逐渐靠近;反之,如果两个任务的梯度方向相反(表示它们存在冲突),它们的嵌入向量会逐渐远离。
关系类型的定义 :
相关(
Positive) :任务可以共享参数,相互促进。例如, CTR 和 CVR
任务都关注用户对商品的兴趣,可以共享底层特征。冲突(
Negative) :任务存在冲突,应该减少共享。例如, CTR
和"停留时长"可能存在冲突:高 CTR
可能带来低停留时长(用户快速点击但快速离开)。独立(
Neutral) :任务互不影响,可以独立学习。例如, CTR
和"分享"任务可能相对独立。 关系预测的应用 :
架构设计 :如果预测两个任务"相关",可以让它们共享更多参数;如果预测"冲突",应该减少共享或使用任务特定参数。损失权重 :相关任务的损失权重可以设置为相似的值,冲突任务的权重需要仔细平衡。任务分析 :通过可视化任务相似度矩阵,可以理解任务间的关系,指导多任务学习的设计。 训练策略 :
联合训练 :任务关系模型可以与多任务模型联合训练,让关系预测和任务学习相互促进。预训练 :也可以先单独训练任务关系模型,然后用学习到的关系指导多任务模型的训练。动态更新 :在训练过程中,任务关系会动态更新,反映任务间的实际关系变化。 扩展方向 :
层次化关系 :可以学习更细粒度的任务关系,如"高度相关"、"中度相关"、"轻度相关"等。上下文相关的关系 :任务关系可能依赖于输入特征,可以学习上下文相关的任务关系。多关系类型 :除了"相关/冲突/独立",还可以学习其他关系类型,如"顺序关系"(
CTR → CVR)、"竞争关系"等。
Loss 平衡策略
问题:不同任务的损失尺度差异
在多任务学习中,不同任务的损失尺度可能差异很大: - CTR 损失通常在
0.1-0.5 之间 - CVR 损失通常在 0.01-0.1 之间 - 回归任务的 MSE 损失可能在
1-100 之间
如果直接相加,损失尺度大的任务会 dominate 训练过程。
常见平衡策略
固定权重 :
需要人工调参,难以找到最优权重。
不确定性加权( Uncertainty Weighting) :
其中
GradNorm :
动态调整任务权重,使得不同任务的梯度范数相似。
动态权重调整( Dynamic Weight Adjustment) :
根据任务性能动态调整权重。
代码实现
在多任务学习中,不同任务的损失尺度可能差异巨大。例如, CTR 损失可能在
0.3 左右, CVR 损失可能在 0.03 左右,而回归任务的 MSE 损失可能在 100
以上。如果直接将这些损失相加,损失大的任务会主导训练过程,导致其他任务优化不充分。
下面我们实现两种常用的自动损失平衡策略:不确定性加权(
Uncertainty Weighting)和
GradNorm 。这两种方法都能自动学习任务权重,无需人工调参。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 class UncertaintyWeighting (nn.Module): """ 不确定性加权损失平衡( Multi-Task Learning Using Uncertainty to Weigh Losses) 核心思想:为每个任务学习一个不确定性参数σ_i,用它来自动调整任务权重。 损失函数: L = Σ[1/(2 σ_i ²) * L_i + log(σ_i)] - 第一项:损失被不确定性归一化,不确定性大的任务权重小 - 第二项: log(σ_i)是正则化项,防止σ_i 无限增大 这种方法在论文"Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics"中提出。 """ def __init__ (self, num_tasks ): """ Args: num_tasks: 任务数量 """ super (UncertaintyWeighting, self).__init__() self.num_tasks = num_tasks self.log_sigma = nn.Parameter(torch.zeros(num_tasks)) def forward (self, losses ): """ 计算加权后的总损失 数学原理: 假设任务 i 的噪声服从高斯分布,方差为σ_i ²,则负对数似然为: -log p(y_i|f_i) = 1/(2 σ_i ²) * L_i + log(σ_i) + const Args: losses: 各任务的损失, list of scalar tensors 例如:[ctr_loss, cvr_loss] Returns: weighted_loss: 加权后的总损失(标量) """ weighted_losses = [] for i, loss in enumerate (losses): precision = torch.exp(-2 * self.log_sigma[i]) weighted_loss_term = 0.5 * precision * loss regularization_term = self.log_sigma[i] weighted_loss = weighted_loss_term + regularization_term weighted_losses.append(weighted_loss) total_loss = sum (weighted_losses) return total_loss class GradNorm (nn.Module): """ GradNorm:动态调整任务权重,使得不同任务的梯度范数相似 核心思想: 1. 任务权重是可学习参数 2. 计算每个任务对共享参数的梯度范数 3. 让梯度范数与任务的相对训练速度成正比 4. 通过梯度范数损失调整任务权重 目标:优化快的任务(损失下降快)应该有更大的梯度,优化慢的任务应该有更小的梯度。 这样可以平衡不同任务的优化速度。 """ def __init__ (self, num_tasks, alpha=0.12 ): """ Args: num_tasks: 任务数量 alpha: 梯度范数平衡系数,控制权重调整的激进程度 - α=0: 所有任务梯度范数相等(完全平衡) - α>0: 优化快的任务梯度范数更大(按相对速度加权) - 通常设置为 0.12(经验值) """ super (GradNorm, self).__init__() self.num_tasks = num_tasks self.alpha = alpha self.task_weights = nn.Parameter(torch.ones(num_tasks)) self.initial_losses = None def compute_grad_norm (self, model, losses ): """ 计算各任务在共享参数上的梯度范数 梯度范数反映了当前任务的损失对模型参数的影响程度。 梯度范数大:该任务对参数更新的"拉力"大 梯度范数小:该任务对参数更新的"拉力"小 Args: model: 多任务模型(需要有共享参数) losses: 各任务的损失, list of scalar tensors Returns: grad_norms: 各任务的梯度范数, shape 为[num_tasks] """ grad_norms = [] for i, loss in enumerate (losses): weighted_loss = self.task_weights[i] * loss grad = torch.autograd.grad( weighted_loss, model.parameters(), retain_graph=True , create_graph=True ) grad_norm = torch.norm(torch.cat([g.flatten() for g in grad])) grad_norms.append(grad_norm) return torch.stack(grad_norms) def forward (self, model, losses ): """ GradNorm 的前向传播 Args: model: 多任务模型 losses: 各任务的损失, list of scalar tensors Returns: total_loss: 加权后的总任务损失 grad_norm_loss: GradNorm 正则化损失(用于更新任务权重) """ if self.initial_losses is None : self.initial_losses = torch.stack([l.detach() for l in losses]) weighted_losses = [self.task_weights[i] * losses[i] for i in range (self.num_tasks)] total_loss = sum (weighted_losses) grad_norms = self.compute_grad_norm(model, losses) avg_grad_norm = grad_norms.mean() losses_tensor = torch.stack(losses) relative_losses = losses_tensor / (self.initial_losses + 1e-8 ) relative_losses = relative_losses.detach() target_grad_norms = avg_grad_norm * (relative_losses ** self.alpha) grad_norm_loss = torch.abs (grad_norms - target_grad_norms).sum () return total_loss, grad_norm_loss
损失平衡策略的使用方法 :
不确定性加权的训练流程 : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 model = MMoE(...) loss_balancer = UncertaintyWeighting(num_tasks=2 ) optimizer = torch.optim.Adam( list (model.parameters()) + list (loss_balancer.parameters()), lr=0.001 ) for batch in dataloader: outputs = model(features) task_losses = [criterion(outputs[i], labels[i]) for i in range (2 )] total_loss = loss_balancer(task_losses) optimizer.zero_grad() total_loss.backward() optimizer.step() print (f"Sigma: {torch.exp(loss_balancer.log_sigma).detach()} " )
GradNorm 的训练流程 : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 model = MMoE(...) loss_balancer = GradNorm(num_tasks=2 , alpha=0.12 ) model_optimizer = torch.optim.Adam(model.parameters(), lr=0.001 ) weight_optimizer = torch.optim.Adam([loss_balancer.task_weights], lr=0.025 ) for batch in dataloader: outputs = model(features) task_losses = [criterion(outputs[i], labels[i]) for i in range (2 )] total_loss, grad_norm_loss = loss_balancer(model, task_losses) model_optimizer.zero_grad() total_loss.backward(retain_graph=True ) model_optimizer.step() weight_optimizer.zero_grad() grad_norm_loss.backward() weight_optimizer.step() with torch.no_grad(): loss_balancer.task_weights.div_(loss_balancer.task_weights.sum () / 2 )
两种方法的对比 :
特性
不确定性加权
GradNorm
原理
基于任务不确定性的贝叶斯解释
基于梯度范数的动态平衡
参数
每个任务 1 个不确定性参数
每个任务 1 个权重参数 + α
计算成本
低(只需要计算损失)
高(需要计算梯度范数)
优化难度
容易(与模型参数一起优化)
中等(需要分离优化器)
适用场景
通用,适合大多数场景
任务差异大、需要精细平衡的场景
缺点
可能陷入局部最优(某些任务被忽略)
计算开销大,需要仔细调参
实践建议 : - 优先尝试不确定性加权,实现简单效果好 -
任务差异极大时考虑 GradNorm -
可以结合人工权重:先用固定权重训练几轮,再启用自动平衡 -
监控各任务的权重变化,防止某些任务权重趋近于 0
工业实践案例
阿里巴巴 ESMM 实践
业务场景 :淘宝商品推荐,需要同时预估 CTR 和 CVR
。
模型架构 : ESMM 模型,共享底层特征提取, CTR 和 CVR
独立塔。
效果提升 : - CVR 预估 AUC 提升 2.18% - 通过 CTCVR
间接计算 CVR,解决了样本选择偏差问题
关键经验 : - CTR 和 CVR 共享底层特征,充分利用 CTR
的丰富样本 - CTCVR 损失在所有曝光样本上计算,避免了样本选择偏差 - 通过
CTR 和 CTCVR 的除法得到 CVR,保证了概率的一致性
腾讯 PLE 实践
业务场景 :腾讯视频推荐,需要同时优化 CTR
、播放时长、完播率等多个目标。
模型架构 : PLE 模型, 2
层渐进式提取,每层包含共享专家和任务特定专家。
效果提升 : - 相比 MMoE, AUC 提升 0.39% - 解决了
MMoE 的负迁移和跷跷板现象
关键经验 : - 任务特定专家解决了负迁移问题 -
渐进式分层结构允许任务在不同层次上进行不同程度的共享 -
门控网络自动学习任务间的共享和独立关系
Google MMoE 实践
业务场景 : YouTube
视频推荐,需要同时优化点击、观看时长、互动等多个目标。
模型架构 : MMoE 模型, 4
个专家网络,每个任务独立的门控网络。
效果提升 : - 多个离线指标均有提升 -
相比单任务模型,参数量减少但性能提升
关键经验 : - 专家数量需要根据任务复杂度调整 -
门控网络可以自动学习任务关系,无需人工设计 -
多任务学习提升了模型的泛化能力
完整代码实现
在实际应用中,多任务学习不仅需要模型架构,还需要完整的数据处理、训练流程、评估指标等配套代码。本节提供一套完整的实现,包括数据准备、训练流程、评估指标、样本平衡策略等,帮助读者快速上手多任务学习的实践。
数据准备
多任务学习的数据准备与单任务学习的主要区别在于:每个样本需要同时包含多个任务的标签 。例如,一个曝光样本需要同时有
CTR 标签(是否点击)和 CVR
标签(是否转化)。这要求我们在数据收集和预处理阶段就要考虑多任务的需求。
下面我们实现一个通用的多任务数据集类,它可以处理任意数量的任务,并支持灵活的数据格式。同时,我们还提供了一个合成数据生成函数,用于快速测试多任务模型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 import numpy as npimport pandas as pdfrom torch.utils.data import Dataset, DataLoaderclass MultiTaskDataset (Dataset ): """ 多任务学习数据集 这个数据集类支持同时加载多个任务的标签,每个样本包含: - 输入特征:所有任务共享的特征向量 - 多个任务标签:每个任务一个标签 设计要点: 1. 支持不同任务的不同标签格式(二分类、多分类、回归等) 2. 支持任务标签的缺失(某些样本可能没有某些任务的标签) 3. 支持灵活的数据加载和批处理 """ def __init__ (self, features, labels_dict ): """ 初始化多任务数据集 Args: features: 特征矩阵, shape 为[n_samples, n_features] - n_samples: 样本数量 - n_features: 特征维度 - 可以是 numpy 数组或 torch tensor labels_dict: 标签字典,格式为 {task_name: labels} - task_name: 任务名称,如'ctr'、'cvr' - labels: 该任务的标签, shape 为[n_samples]或[n_samples, label_dim] - 对于二分类任务, labels 通常是 0/1 - 对于回归任务, labels 是连续值 - 对于缺失标签,可以使用-1 或 NaN 表示 """ self.features = features self.labels_dict = labels_dict self.task_names = list (labels_dict.keys()) n_samples = len (features) for task_name, labels in labels_dict.items(): assert len (labels) == n_samples, \ f"Task {task_name} has {len (labels)} labels, but features have {n_samples} samples" def __len__ (self ): """返回数据集大小""" return len (self.features) def __getitem__ (self, idx ): """ 获取单个样本 返回格式: { 'features': 特征向量, 'task1': 任务 1 的标签, 'task2': 任务 2 的标签, ... } Args: idx: 样本索引 Returns: sample: 包含特征和所有任务标签的字典 """ sample = { 'features' : self.features[idx], **{task: self.labels_dict[task][idx] for task in self.task_names} } return sample def generate_synthetic_data (n_samples=10000 , n_features=100 , num_tasks=2 ): """ 生成合成多任务数据 这个函数用于快速生成测试数据,模拟真实推荐系统中的多任务场景。 生成的数据包括: - CTR 任务:模拟点击率预测,使用前 50 个特征 - CVR 任务:模拟转化率预测,使用后 50 个特征,且只在点击样本上有标签 在实际应用中,应该使用真实的数据集,如: - MovieLens 数据集(评分、点击等多任务) - 电商数据集( CTR 、 CVR 、 GMV 等多任务) - 新闻推荐数据集(点击、阅读时长、分享等多任务) Args: n_samples: 样本数量,默认 10000 n_features: 特征维度,默认 100 num_tasks: 任务数量,默认 2( CTR 和 CVR) Returns: features: 特征矩阵, shape 为[n_samples, n_features] labels_dict: 标签字典,{task_name: labels} """ features = np.random.randn(n_samples, n_features) ctr_weights = np.random.randn(50 ) ctr_logits = np.dot(features[:, :50 ], ctr_weights) + np.random.randn(n_samples) * 0.1 ctr_probs = 1 / (1 + np.exp(-ctr_logits)) ctr_labels = (ctr_probs > np.random.rand(n_samples)).astype(float ) cvr_weights = np.random.randn(50 ) cvr_logits = np.dot(features[:, 50 :], cvr_weights) + np.random.randn(n_samples) * 0.1 cvr_probs = 1 / (1 + np.exp(-cvr_logits)) cvr_labels = np.zeros(n_samples) clicked_indices = np.where(ctr_labels == 1 )[0 ] if len (clicked_indices) > 0 : cvr_labels[clicked_indices] = ( cvr_probs[clicked_indices] > np.random.rand(len (clicked_indices)) ).astype(float ) labels_dict = { 'ctr' : ctr_labels, 'cvr' : cvr_labels } return features, labels_dict features, labels_dict = generate_synthetic_data(n_samples=10000 , n_features=100 , num_tasks=2 ) dataset = MultiTaskDataset(features, labels_dict) dataloader = DataLoader(dataset, batch_size=32 , shuffle=True ) print (f"Dataset size: {len (dataset)} " )print (f"Task names: {dataset.task_names} " )print (f"Feature shape: {features.shape} " )print (f"CTR positive ratio: {labels_dict['ctr' ].mean():.2 %} " )print (f"CVR positive ratio (among clicks): {labels_dict['cvr' ][labels_dict['ctr' ]==1 ].mean():.2 %} " )
训练流程
多任务学习的训练流程与单任务学习类似,但有几个关键区别:
多任务损失计算 :需要为每个任务单独计算损失,然后通过损失平衡策略组合损失平衡 :不同任务的损失尺度可能差异很大,需要使用不确定性加权或
GradNorm 等方法平衡梯度处理 :共享参数的梯度来自多个任务,需要确保梯度正确聚合评估指标 :需要同时评估所有任务的性能,不能只看单一指标
下面我们实现一个完整的训练函数,它支持多种损失平衡策略,并提供了详细的训练日志。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 import torch.optim as optimfrom torch.nn import BCEWithLogitsLossdef train_multi_task_model (model, dataloader, num_epochs=10 , lr=0.001 , loss_balancer=None , device='cuda' ): """ 训练多任务模型 这个训练函数实现了多任务学习的完整训练流程,包括: 1. 前向传播:同时预测多个任务 2. 损失计算:为每个任务单独计算损失 3. 损失平衡:使用不确定性加权或 GradNorm 等方法平衡多任务损失 4. 反向传播:更新模型参数 5. 训练监控:记录训练过程中的损失和指标 Args: model: 多任务模型(如 MMoE 、 PLE 等),需要有以下属性: - num_tasks: 任务数量 - task_names: 任务名称列表(可选) dataloader: 数据加载器,每个 batch 包含 features 和所有任务的标签 num_epochs: 训练轮数,通常设置为 10-100 lr: 学习率,通常设置为 0.001-0.01 loss_balancer: 损失平衡器,可以是 UncertaintyWeighting 或 GradNorm 如果为 None,则使用默认的 UncertaintyWeighting device: 训练设备,'cuda'或'cpu' Returns: model: 训练好的模型 """ model = model.to(device) if isinstance (loss_balancer, GradNorm): optimizer = optim.Adam(model.parameters(), lr=lr) else : if loss_balancer is not None : optimizer = optim.Adam( list (model.parameters()) + list (loss_balancer.parameters()), lr=lr ) else : optimizer = optim.Adam(model.parameters(), lr=lr) criterion = BCEWithLogitsLoss() if loss_balancer is None : loss_balancer = UncertaintyWeighting(model.num_tasks) loss_balancer = loss_balancer.to(device) optimizer = optim.Adam( list (model.parameters()) + list (loss_balancer.parameters()), lr=lr ) else : loss_balancer = loss_balancer.to(device) for epoch in range (num_epochs): model.train() epoch_total_loss = 0 epoch_task_losses = [0.0 ] * model.num_tasks for batch_idx, batch in enumerate (dataloader): features = batch['features' ].float ().to(device) if hasattr (model, 'task_names' ): task_labels = [batch[task].float ().to(device) for task in model.task_names] else : task_labels = [batch[f'task_{i} ' ].float ().to(device) for i in range (model.num_tasks)] outputs = model(features) task_losses = [] for i, (output, label) in enumerate (zip (outputs, task_labels)): loss = criterion(output.squeeze(), label) task_losses.append(loss) epoch_task_losses[i] += loss.item() if isinstance (loss_balancer, GradNorm): total_loss, grad_norm_loss = loss_balancer(model, task_losses) total_loss = total_loss + grad_norm_loss else : total_loss = loss_balancer(task_losses) optimizer.zero_grad() total_loss.backward() optimizer.step() epoch_total_loss += total_loss.item() avg_total_loss = epoch_total_loss / len (dataloader) avg_task_losses = [loss / len (dataloader) for loss in epoch_task_losses] print (f"Epoch {epoch+1 } /{num_epochs} , Total Loss: {avg_total_loss:.4 f} " ) for i, task_loss in enumerate (avg_task_losses): task_name = model.task_names[i] if hasattr (model, 'task_names' ) else f"Task {i+1 } " print (f" {task_name} Loss: {task_loss:.4 f} " ) if isinstance (loss_balancer, UncertaintyWeighting): sigmas = torch.exp(loss_balancer.log_sigma).detach().cpu().numpy() print (f" Task Uncertainties (σ): {sigmas} " ) if isinstance (loss_balancer, GradNorm): weights = loss_balancer.task_weights.detach().cpu().numpy() print (f" Task Weights: {weights} " ) return model model = MMoE( input_dim=100 , num_experts=4 , expert_hidden_dim=64 , task_hidden_dims=[32 , 16 ], num_tasks=2 , dropout=0.1 ) model.task_names = ['ctr' , 'cvr' ] loss_balancer = UncertaintyWeighting(num_tasks=2 ) trained_model = train_multi_task_model( model, dataloader, num_epochs=10 , lr=0.001 , loss_balancer=loss_balancer )
评估指标
多任务学习的评估与单任务学习不同,需要同时评估所有任务的性能。评估时需要注意:
任务特定指标 :每个任务可能有不同的评估指标(如 CTR
用 AUC, CVR 用 AUC,回归任务用 MSE)标签缺失处理 :某些任务(如
CVR)可能只在部分样本上有标签,需要正确处理综合评估 :需要综合考虑所有任务的性能,不能只看单一任务
下面我们实现一个通用的多任务模型评估函数,支持多种评估指标和标签缺失处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 from sklearn.metrics import roc_auc_score, log_lossdef evaluate_multi_task_model (model, dataloader, task_names, device='cuda' ): """ 评估多任务模型 这个函数实现了多任务学习的完整评估流程,包括: 1. 收集所有任务的预测和标签 2. 处理标签缺失(某些任务可能只在部分样本上有标签) 3. 计算每个任务的评估指标 4. 返回所有任务的评估结果 Args: model: 多任务模型,需要支持前向传播返回多个任务的预测 dataloader: 数据加载器,每个 batch 包含 features 和所有任务的标签 task_names: 任务名称列表,如['ctr', 'cvr'] device: 评估设备,'cuda'或'cpu' Returns: metrics: 评估指标字典,格式为 {task_name: {metric_name: value }} 例如:{'ctr': {'AUC': 0.75, 'LogLoss': 0.45}, 'cvr': {'AUC': 0.68, 'LogLoss': 0.32 }} """ model.eval () all_outputs = {task: [] for task in task_names} all_labels = {task: [] for task in task_names} with torch.no_grad(): for batch in dataloader: features = batch['features' ].float ().to(device) outputs = model(features) for i, task in enumerate (task_names): all_outputs[task].extend(outputs[i].cpu().numpy()) all_labels[task].extend(batch[task].numpy()) metrics = {} for task in task_names: outputs = np.array(all_outputs[task]).squeeze() labels = np.array(all_labels[task]) valid_mask = labels >= 0 if valid_mask.sum () > 0 : valid_outputs = outputs[valid_mask] valid_labels = labels[valid_mask] auc = roc_auc_score(valid_labels, valid_outputs) probs = 1 / (1 + np.exp(-valid_outputs)) logloss = log_loss(valid_labels, probs) metrics[task] = {'AUC' : auc, 'LogLoss' : logloss} else : metrics[task] = {'AUC' : np.nan, 'LogLoss' : np.nan} return metrics metrics = evaluate_multi_task_model(trained_model, dataloader, ['ctr' , 'cvr' ]) for task, task_metrics in metrics.items(): print (f"{task} : AUC={task_metrics['AUC' ]:.4 f} , LogLoss={task_metrics['LogLoss' ]:.4 f} " )
样本平衡策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 def balance_multi_task_samples (features, labels_dict, target_ratio=1.0 ): """ 平衡多任务样本量 Args: features: 特征矩阵 labels_dict: 标签字典 target_ratio: 目标样本比例(相对于最大任务) Returns: balanced_features, balanced_labels_dict """ task_sizes = {task: len (labels) for task, labels in labels_dict.items()} max_size = max (task_sizes.values()) target_size = int (max_size * target_ratio) balanced_indices = [] for task, labels in labels_dict.items(): task_indices = np.arange(len (labels)) if len (task_indices) > target_size: sampled_indices = np.random.choice(task_indices, target_size, replace=False ) else : sampled_indices = np.random.choice(task_indices, target_size, replace=True ) balanced_indices.append(sampled_indices) final_indices = balanced_indices[0 ] balanced_features = features[final_indices] balanced_labels_dict = {task: labels[final_indices] for task, labels in labels_dict.items()} return balanced_features, balanced_labels_dict
动态权重调整
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class DynamicWeightAdjuster : """动态权重调整器""" def __init__ (self, num_tasks, initial_weights=None , alpha=0.1 ): """ Args: num_tasks: 任务数量 initial_weights: 初始权重,如果为 None 则均匀分配 alpha: 权重更新速率 """ self.num_tasks = num_tasks self.alpha = alpha if initial_weights is None : self.weights = torch.ones(num_tasks) / num_tasks else : self.weights = torch.tensor(initial_weights) self.task_performances = {i: [] for i in range (num_tasks)} def update (self, task_performances ): """ 根据任务性能更新权重 Args: task_performances: 各任务的性能指标(越大越好), list of floats """ task_performances = torch.tensor(task_performances) normalized_perf = task_performances / (task_performances.sum () + 1e-8 ) self.weights = (1 - self.alpha) * self.weights + self.alpha * normalized_perf self.weights = self.weights / (self.weights.sum () + 1e-8 ) return self.weights.numpy() def get_weights (self ): """获取当前权重""" return self.weights.numpy()
模型对比工具
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 def compare_models (models_dict, dataloader, task_names, device='cuda' ): """ 对比多个模型的性能 Args: models_dict: 模型字典,{model_name: model} dataloader: 数据加载器 task_names: 任务名称列表 device: 设备 Returns: comparison_results: 对比结果字典 """ comparison_results = {} for model_name, model in models_dict.items(): model = model.to(device) metrics = evaluate_multi_task_model(model, dataloader, task_names, device) comparison_results[model_name] = metrics print ("Model Comparison Results:" ) print ("-" * 80 ) for task in task_names: print (f"\n{task} :" ) for model_name, metrics in comparison_results.items(): if task in metrics: print (f" {model_name} : AUC={metrics[task]['AUC' ]:.4 f} , " f"LogLoss={metrics[task]['LogLoss' ]:.4 f} " ) return comparison_results models_to_compare = { 'SharedBottom' : SharedBottom(input_dim=100 , shared_hidden_dims=[64 ], task_hidden_dims=[32 ], num_tasks=2 ), 'MMoE' : MMoE(input_dim=100 , num_experts=4 , expert_hidden_dim=64 , task_hidden_dims=[32 ], num_tasks=2 ), 'PLE' : PLE(input_dim=100 , num_layers=2 , num_shared_experts=2 , num_task_specific_experts=2 , expert_hidden_dim=64 , task_hidden_dims=[32 ], num_tasks=2 ) } comparison_results = compare_models(models_to_compare, dataloader, ['ctr' , 'cvr' ])
特征重要性分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 def analyze_feature_importance (model, dataloader, feature_names, task_idx=0 , device='cuda' ): """ 分析特征重要性(简化版本,使用梯度) Args: model: 多任务模型 dataloader: 数据加载器 feature_names: 特征名称列表 task_idx: 要分析的任务索引 device: 设备 Returns: feature_importance: 特征重要性字典 """ model.eval () feature_gradients = {name: [] for name in feature_names} for batch in dataloader: features = batch['features' ].float ().to(device) features.requires_grad = True outputs = model(features) loss = F.binary_cross_entropy_with_logits( outputs[task_idx].squeeze(), batch[list (batch.keys())[task_idx+1 ]].float ().to(device) ) gradients = torch.autograd.grad(loss, features, retain_graph=False )[0 ] for i, name in enumerate (feature_names): feature_gradients[name].append(torch.abs (gradients[:, i]).mean().item()) feature_importance = {name: np.mean(grads) for name, grads in feature_gradients.items()} feature_importance = dict (sorted (feature_importance.items(), key=lambda x: x[1 ], reverse=True )) return feature_importance feature_names = [f'feature_{i} ' for i in range (100 )] importance = analyze_feature_importance(trained_model, dataloader, feature_names, task_idx=0 ) print ("Top 10 Important Features:" )for i, (feature, imp) in enumerate (list (importance.items())[:10 ]): print (f"{i+1 } . {feature} : {imp:.4 f} " )
Q&A:常见问题解答
Q1:
多任务学习和单任务学习相比,性能一定更好吗?
A :
不一定。多任务学习的性能提升取决于任务间的相关性: -
当任务高度相关时,多任务学习通常能提升性能 -
当任务冲突或相关性很低时,可能出现负迁移,性能下降 -
需要根据任务特点选择合适的架构(如 PLE 处理负迁移)
Q2: 如何选择多任务学习的架构?
A : 架构选择需要考虑: -
任务相关性 :高度相关用 Shared-Bottom,存在冲突用
MMoE/PLE - 样本量差异 :样本量差异大时, MMoE/PLE
的灵活性更好 - 计算资源 : Shared-Bottom 最简单, PLE
最复杂 - 业务需求 : ESMM 专门解决 CVR
样本选择偏差问题
Q3: 如何平衡不同任务的损失?
A : 常见方法: -
固定权重 :简单但需要调参 -
不确定性加权 :可学习权重,适合大多数场景 -
GradNorm :动态平衡梯度,适合任务差异大的场景 -
动态权重 :根据任务性能调整,需要设计调整策略
Q4:
ESMM 中的 CVR 为什么通过 CTCVR/CTR 计算,而不是直接预测?
A : 原因: - 样本选择偏差 : CVR
只在点击样本上有标签,但推理时需要预测所有样本 -
数据稀疏 : CVR 样本量远小于 CTR,直接预测容易过拟合 -
概率一致性 : CTCVR = CTR ×
CVR,通过除法保证概率关系一致
Q5: MMoE
中的专家数量如何选择?
A : 专家数量选择: -
任务数量 :通常专家数量 >= 任务数量 -
任务复杂度 :复杂任务需要更多专家 -
计算资源 :专家数量影响计算量 -
经验值 :通常 2-8 个专家,可以通过实验选择
Q6: PLE 相比 MMoE
的优势在哪里?
A : PLE 的优势: -
解决负迁移 :任务特定专家避免任务冲突 -
缓解跷跷板现象 :渐进式分层允许任务在不同层次共享 -
更好的任务平衡 :共享专家和任务特定专家的组合更灵活
Q7:
如何处理任务样本量差异很大的情况?
A : 处理方法: -
样本采样 :对样本量大的任务进行下采样,平衡样本量 -
损失加权 :给样本量小的任务更大的权重 -
课程学习 :先训练样本量大的任务,再逐步加入小样本任务 -
数据增强 :对样本量小的任务进行数据增强
Q8:
多任务学习中的负迁移如何检测和解决?
A : 检测和解决: -
检测 :对比单任务和多任务性能,如果多任务性能下降,可能存在负迁移
- 解决 : - 使用 MMoE/PLE 等架构,减少任务间的强制共享 -
增加任务特定参数,减少共享参数 - 调整损失权重,降低冲突任务的权重
Q9:
多任务学习的线上服务如何部署?
A : 部署考虑: -
模型大小 :多任务模型通常比多个单任务模型小 -
推理延迟 :共享底层计算,延迟可能更低 - A/B
测试 :需要同时评估多个任务的性能 -
监控指标 :需要监控所有任务的性能指标
Q10:
如何评估多任务学习的效果?
A : 评估方法: -
单任务指标 :每个任务的 AUC 、 LogLoss 等 -
综合指标 :多个任务的加权平均 -
业务指标 : CTR 、 CVR 、 GMV 等业务指标 -
对比实验 :与单任务模型、其他多任务模型对比
Q11:
多任务学习可以用于哪些推荐场景?
A : 适用场景: - 电商推荐 : CTR 、
CVR 、 GMV 等多目标 -
内容推荐 :点击、播放时长、完播率、互动等 -
广告推荐 : CTR 、 CVR 、 ROI 等 -
社交推荐 :点击、关注、互动等
Q12:
多任务学习的未来发展方向?
A : 发展方向: -
自动架构搜索 :自动设计多任务架构 -
任务关系学习 :更好地建模任务关系 -
可解释性 :理解任务间的知识共享机制 -
在线学习 :支持任务的动态添加和删除 -
跨域迁移 :不同领域间的任务迁移
总结
多任务学习是推荐系统中的重要技术,通过共享底层特征表示,可以同时优化多个业务目标,提升模型性能和降低维护成本。从
Shared-Bottom 到 ESMM 、 MMoE 、
PLE,多任务学习架构不断演进,解决了样本选择偏差、负迁移、任务冲突等关键问题。
在实际应用中,需要根据任务特点选择合适的架构,平衡不同任务的损失,处理样本分布差异,才能充分发挥多任务学习的优势。随着研究的深入,多任务学习将在推荐系统中发挥越来越重要的作用。