2016 年, Google 在 Google Play 应用商店的推荐系统中提出了 Wide &
Deep
模型,标志着深度学习正式进入推荐系统的主流。在此之前,推荐系统主要依赖矩阵分解、协同过滤等传统方法。虽然这些方法在
Netflix Prize
竞赛中取得了成功,但它们存在明显的局限性:难以处理高维稀疏特征、无法捕捉非线性关系、特征工程依赖人工经验。
深度学习为推荐系统带来了革命性的变化。通过多层神经网络,可以自动学习用户和物品的表示(
Embedding),捕捉复杂的交互模式,处理多模态特征,并在大规模数据上端到端训练。从
NCF( Neural Collaborative Filtering)到 AutoEncoder 推荐,从 Wide &
Deep 到 DeepFM,深度学习模型在 CTR
预估、召回、排序等各个环节都展现出了强大的能力。
本文深入讲解深度学习推荐系统的核心概念、主流模型和实现细节。我们将从
Embedding 的本质讲起,理解为什么它如此重要;然后深入 NCF 、
AutoEncoder( CDAE/VAE)、 Wide & Deep
等经典模型;接着探讨特征工程和训练技巧;最后通过 10+个完整的代码实现和
10+个 Q&A
解答常见问题。无论你是推荐系统的新手,还是想系统梳理深度学习推荐模型,这篇文章都能帮你建立完整的知识体系。
深度学习 vs 传统方法
传统推荐方法的局限性
在深度学习兴起之前,推荐系统主要依赖以下方法:
矩阵分解( Matrix Factorization) : -
将用户-物品评分矩阵分解为低维向量 - 用向量内积预测评分:
协同过滤( Collaborative Filtering) : -
基于用户或物品的相似度进行推荐 - 优点:无需内容特征,能发现意外关联 -
缺点:数据稀疏性问题严重,冷启动困难
因子分解机( Factorization Machine) : -
引入特征交互项:
这些传统方法的核心问题是:它们都是线性的或只能捕捉低阶交互,而用户行为往往包含复杂的非线性模式 。例如,用户可能同时喜欢"科幻+动作+大制作"的电影,这种组合特征很难用简单的线性模型表达。
深度学习的优势
深度学习通过多层神经网络,为推荐系统带来了以下优势:
自动特征学习 : -
传统方法需要人工设计特征(如"用户年龄×物品类别") -
深度学习通过多层非线性变换,自动学习特征表示 - Embedding 层将高维稀疏的
one-hot 编码映射到低维稠密向量
非线性建模能力 : -
多层神经网络可以捕捉任意复杂的非线性关系 - ReLU 、 Sigmoid
等激活函数引入非线性 - 深层网络可以学习高阶特征交互
多模态特征融合 : -
可以同时处理用户画像、物品属性、行为序列、文本、图像等多种特征 -
通过不同的网络结构( CNN 、 RNN 、 Transformer)处理不同模态 -
在统一的框架下进行端到端训练
端到端训练 : -
从原始特征到最终预测,整个流程可以联合优化 -
梯度反向传播自动调整所有参数 -
避免了传统方法中特征工程和模型训练分离的问题
性能对比
在实际应用中,深度学习模型相比传统方法通常能带来
5-30%的性能提升:
方法
AUC
提升
矩阵分解
0.750
baseline
FM
0.780
+4.0%
Wide & Deep
0.810
+8.0%
DeepFM
0.825
+10.0%
DIN
0.845
+12.7%
这些提升主要来自于: 1. 更好的特征表示 : Embedding
层学习到的向量比 one-hot 编码包含更多信息 2.
更复杂的交互模式 :深层网络捕捉到传统方法无法表达的特征组合
3. 序列建模能力 : RNN/Transformer
可以建模用户行为序列的时序依赖
深度学习的挑战
尽管深度学习有诸多优势,但也带来了一些挑战:
计算复杂度 : - 深层网络需要大量计算资源 -
训练时间可能比传统方法长 10-100 倍 - 需要 GPU 加速才能在生产环境使用
可解释性 : - 黑盒模型难以解释为什么推荐某个物品 -
传统方法(如矩阵分解)的向量可以直观理解 - 需要额外的可解释性工具(如
SHAP 、 LIME)
数据需求 : - 深度学习需要大量训练数据 -
冷启动问题仍然存在(新用户/新物品) -
需要精心设计的数据增强和迁移学习策略
超参数调优 : -
网络结构、学习率、正则化等超参数需要大量实验 -
相比传统方法,调参空间更大 - 需要自动化工具(如 AutoML)辅助
Embedding 详解
什么是 Embedding
Embedding(嵌入)是深度学习的核心概念之一。简单来说,Embedding
是将高维稀疏的离散特征映射到低维稠密连续向量空间的技术 。
在推荐系统中,最常见的离散特征是用户 ID 和物品 ID 。假设我们有 1000
万用户和 100 万物品,如果用 one-hot 编码: - 用户 ID: 1000
万维向量,只有 1 个位置是 1,其余都是 0 - 物品 ID: 100 万维向量,只有 1
个位置是 1,其余都是 0
这种表示方式存在严重问题: 1.
维度灾难 :向量维度等于类别数量,存储和计算成本巨大 2.
信息稀疏 : 99.9999%的元素都是 0,信息密度极低 3.
无法表达相似性 :任意两个 one-hot
向量的距离都相同(如欧氏距离都是
Embedding 解决了这些问题: - 将 1000 万维的用户 ID 映射到 128
维的稠密向量 - 将 100 万维的物品 ID 映射到 128 维的稠密向量 -
相似的用户/物品在向量空间中距离更近
Embedding 的数学原理
Embedding 本质上是一个查找表( Lookup Table)。设用户集合为
One-hot 编码 : - 用户Extra close brace or missing open brace \mathbf{e}_i \in \{0,1} ^m Extra close brace or missing open brace \mathbf{f}_j \in \{0,1} ^n Embedding 层 : -
用户 Embedding 矩阵:
在实现中, Embedding 层通常是一个可学习的参数矩阵: 1 2 3 4 5 6 7 user_embedding = Embedding(num_users, embedding_dim) item_embedding = Embedding(num_items, embedding_dim) user_id = 123 user_vec = user_embedding[user_id]
Embedding 的学习过程
Embedding
向量不是预先定义的,而是通过训练数据学习得到的。学习目标是:让相似的用户/物品在向量空间中距离更近,不相似的更远 。
协同过滤视角 : - 如果用户神经网络视角 : - Embedding 层是神经网络的第一层 -
通过反向传播,梯度会更新 Embedding 矩阵的参数 -
最终学到的向量包含了用户/物品的潜在特征
Embedding 的维度选择
Embedding 维度数据规模 :用户/物品数量越大,通常需要更大的维度 -
任务复杂度 : CTR 预估可能需要 32-64 维,召回可能需要
128-256 维 - 计算资源 :维度越大,存储和计算成本越高
经验法则: - 小规模(<10 万):
Embedding 的可视化
通过降维技术(如 t-SNE 、 PCA),可以将高维 Embedding 可视化到 2D
平面,观察学习到的结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import numpy as npfrom sklearn.manifold import TSNEimport matplotlib.pyplot as pltembeddings_subset = item_embeddings[:1000 ] tsne = TSNE(n_components=2 , random_state=42 ) embeddings_2d = tsne.fit_transform(embeddings_subset) plt.scatter(embeddings_2d[:, 0 ], embeddings_2d[:, 1 ]) plt.title('Item Embeddings Visualization' ) plt.show()
通常会发现: - 相同类别的物品聚集在一起 - 相似功能的物品距离较近 -
热门物品和冷门物品可能分布在不同的区域
Embedding 的预训练与微调
在实际应用中, Embedding 可以: 1.
随机初始化 :从零开始训练(最常见) 2.
预训练 :先用其他任务(如物品分类)预训练
Embedding,再微调 3. 迁移学习 :从其他领域(如 NLP 的
Word2Vec)迁移 Embedding
预训练 Embedding 的优势: - 加速收敛:不需要从随机状态开始 -
提升性能:利用外部知识 - 缓解冷启动:新物品可以利用预训练的
Embedding
代码示例: Embedding 层实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import torchimport torch.nn as nnimport torch.nn.functional as Fclass EmbeddingLayer (nn.Module): """基础的 Embedding 层实现""" def __init__ (self, num_embeddings, embedding_dim, padding_idx=None ): """ Args: num_embeddings: 词汇表大小(用户数或物品数) embedding_dim: Embedding 维度 padding_idx: 填充索引(用于序列 padding) """ super (EmbeddingLayer, self).__init__() self.num_embeddings = num_embeddings self.embedding_dim = embedding_dim self.embedding = nn.Embedding( num_embeddings=num_embeddings, embedding_dim=embedding_dim, padding_idx=padding_idx ) nn.init.xavier_uniform_(self.embedding.weight) def forward (self, indices ): """ Args: indices: 输入索引,形状: [batch_size] 或 [batch_size, seq_len] Returns: embeddings: Embedding 向量,形状: [batch_size, embedding_dim] 或 [batch_size, seq_len, embedding_dim] """ return self.embedding(indices) num_users = 10000 embedding_dim = 64 user_embedding = EmbeddingLayer(num_users, embedding_dim) user_ids = torch.LongTensor([0 , 1 , 2 , 3 , 4 ]) user_vectors = user_embedding(user_ids) print (f"Input user IDs: {user_ids} " )print (f"Output embeddings shape: {user_vectors.shape} " )print (f"Sample embedding (user 0): {user_vectors[0 ][:5 ]} " )
多字段 Embedding
在实际推荐系统中,除了用户 ID 和物品
ID,还有很多其他离散特征(如用户年龄、物品类别、城市等)。每个特征都需要一个
Embedding 层:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 class MultiFieldEmbedding (nn.Module): """多字段 Embedding 层""" def __init__ (self, field_dims, embedding_dim ): """ Args: field_dims: 每个字段的类别数,如 [10000, 1000, 50] 表示 3 个字段 embedding_dim: Embedding 维度 """ super (MultiFieldEmbedding, self).__init__() self.field_dims = field_dims self.embedding_dim = embedding_dim self.num_fields = len (field_dims) self.embeddings = nn.ModuleList([ nn.Embedding(field_dim, embedding_dim) for field_dim in field_dims ]) def forward (self, x ): """ Args: x: 输入特征,形状: [batch_size, num_fields] Returns: embeddings: 所有字段的 Embedding,形状: [batch_size, num_fields, embedding_dim] """ embeddings = [] for i in range (self.num_fields): embeddings.append(self.embeddings[i](x[:, i])) return torch.stack(embeddings, dim=1 ) field_dims = [10000 , 1000 , 50 , 20 ] embedding_dim = 32 multi_embedding = MultiFieldEmbedding(field_dims, embedding_dim) x = torch.LongTensor([ [123 , 456 , 5 , 10 ], [124 , 457 , 5 , 11 ], [125 , 458 , 6 , 10 ], [126 , 459 , 6 , 12 ] ]) embeddings = multi_embedding(x) print (f"Input shape: {x.shape} " )print (f"Output embeddings shape: {embeddings.shape} " )
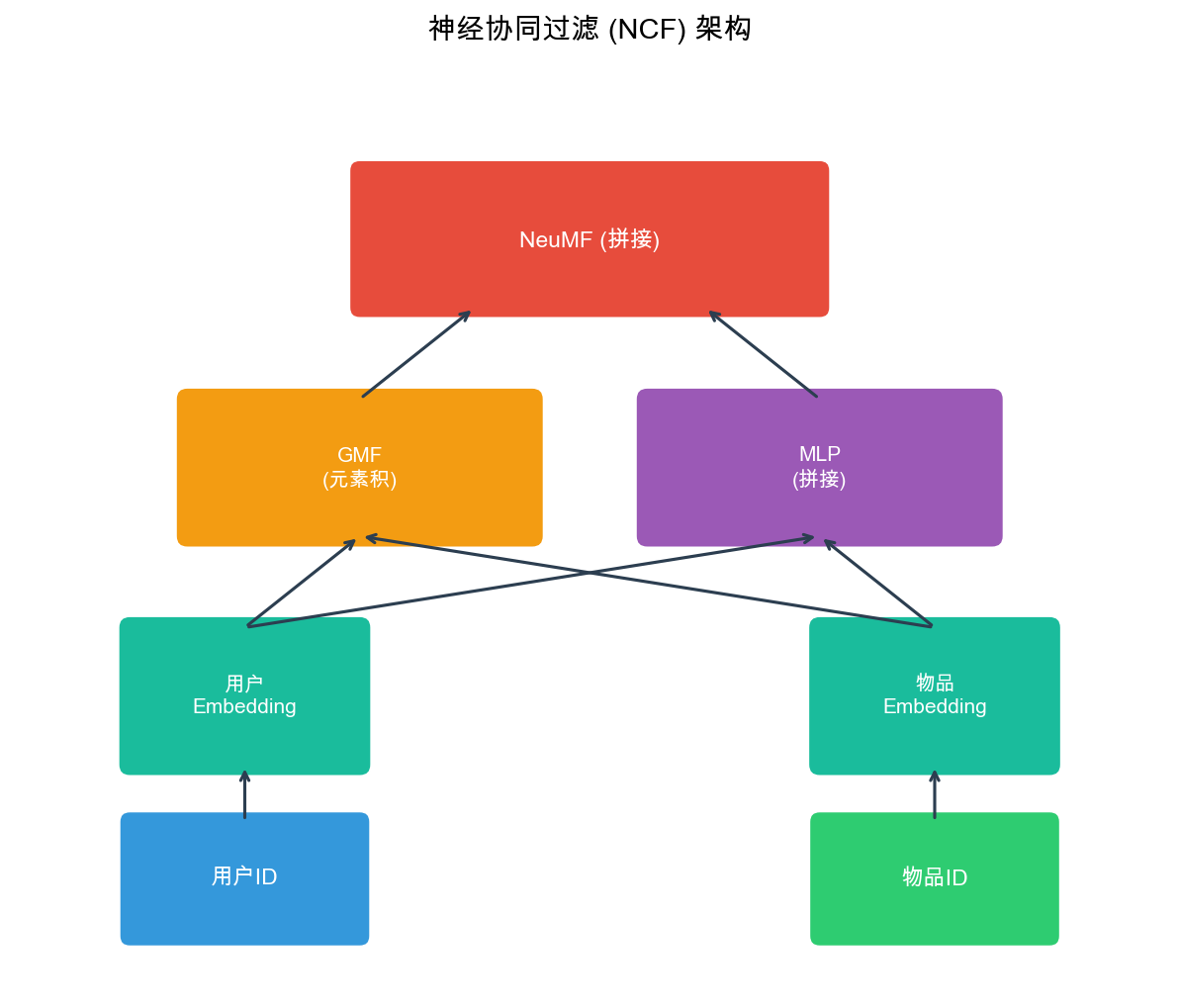
NCF:神经协同过滤
NCF 的背景
传统的矩阵分解方法用向量内积预测评分:
这种方法存在一个根本性问题:内积是线性的,无法捕捉用户和物品之间的复杂非线性关系 。例如,用户可能喜欢"科幻+动作"的组合,但这种组合特征无法用简单的内积表达。
NCF( Neural Collaborative Filtering)是 2017
年提出的模型,它用多层神经网络替代内积,从而能够学习用户和物品之间的非线性交互。
NCF 的模型架构
NCF 模型包含三个组件:
1. GMF( Generalized Matrix Factorization) : - 用户
Embedding:
2. MLP( Multi-Layer Perceptron) : - 将用户和物品
Embedding 拼接:3. NeuMF( Neural Matrix
Factorization) : - 融合 GMF 和 MLP:
NCF 的数学公式
完整的 NCF 模型可以表示为:
其中: -
NCF 的损失函数
对于隐式反馈(点击/未点击), NCF 使用二元交叉熵损失:
其中
对于显式反馈(评分),可以使用均方误差:
NCF 的完整实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 import torchimport torch.nn as nnimport torch.nn.functional as Fclass GMF (nn.Module): """Generalized Matrix Factorization""" def __init__ (self, num_users, num_items, embedding_dim ): super (GMF, self).__init__() self.user_embedding = nn.Embedding(num_users, embedding_dim) self.item_embedding = nn.Embedding(num_items, embedding_dim) self.output_layer = nn.Linear(embedding_dim, 1 ) nn.init.normal_(self.user_embedding.weight, std=0.01 ) nn.init.normal_(self.item_embedding.weight, std=0.01 ) def forward (self, user_ids, item_ids ): user_emb = self.user_embedding(user_ids) item_emb = self.item_embedding(item_ids) element_product = user_emb * item_emb output = self.output_layer(element_product) return output.squeeze() class MLP (nn.Module): """Multi-Layer Perceptron""" def __init__ (self, num_users, num_items, embedding_dim, layers, dropout=0.0 ): super (MLP, self).__init__() self.user_embedding = nn.Embedding(num_users, embedding_dim) self.item_embedding = nn.Embedding(num_items, embedding_dim) mlp_layers = [] input_dim = embedding_dim * 2 for output_dim in layers: mlp_layers.append(nn.Linear(input_dim, output_dim)) mlp_layers.append(nn.ReLU()) if dropout > 0 : mlp_layers.append(nn.Dropout(dropout)) input_dim = output_dim self.mlp = nn.Sequential(*mlp_layers) self.output_layer = nn.Linear(layers[-1 ], 1 ) nn.init.normal_(self.user_embedding.weight, std=0.01 ) nn.init.normal_(self.item_embedding.weight, std=0.01 ) def forward (self, user_ids, item_ids ): user_emb = self.user_embedding(user_ids) item_emb = self.item_embedding(item_ids) concat = torch.cat([user_emb, item_emb], dim=1 ) mlp_output = self.mlp(concat) output = self.output_layer(mlp_output) return output.squeeze() class NeuMF (nn.Module): """Neural Matrix Factorization""" def __init__ (self, num_users, num_items, embedding_dim, mlp_layers, dropout=0.0 ): super (NeuMF, self).__init__() self.embedding_dim = embedding_dim self.gmf_user_embedding = nn.Embedding(num_users, embedding_dim) self.gmf_item_embedding = nn.Embedding(num_items, embedding_dim) self.mlp_user_embedding = nn.Embedding(num_users, embedding_dim) self.mlp_item_embedding = nn.Embedding(num_items, embedding_dim) mlp_modules = [] input_dim = embedding_dim * 2 for output_dim in mlp_layers: mlp_modules.append(nn.Linear(input_dim, output_dim)) mlp_modules.append(nn.ReLU()) if dropout > 0 : mlp_modules.append(nn.Dropout(dropout)) input_dim = output_dim self.mlp = nn.Sequential(*mlp_modules) self.output_layer = nn.Linear(embedding_dim + mlp_layers[-1 ], 1 ) self._init_weights() def _init_weights (self ): nn.init.normal_(self.gmf_user_embedding.weight, std=0.01 ) nn.init.normal_(self.gmf_item_embedding.weight, std=0.01 ) nn.init.normal_(self.mlp_user_embedding.weight, std=0.01 ) nn.init.normal_(self.mlp_item_embedding.weight, std=0.01 ) def forward (self, user_ids, item_ids ): gmf_user_emb = self.gmf_user_embedding(user_ids) gmf_item_emb = self.gmf_item_embedding(item_ids) gmf_output = gmf_user_emb * gmf_item_emb mlp_user_emb = self.mlp_user_embedding(user_ids) mlp_item_emb = self.mlp_item_embedding(item_ids) mlp_concat = torch.cat([mlp_user_emb, mlp_item_emb], dim=1 ) mlp_output = self.mlp(mlp_concat) concat = torch.cat([gmf_output, mlp_output], dim=1 ) output = self.output_layer(concat) return torch.sigmoid(output.squeeze()) num_users = 10000 num_items = 5000 embedding_dim = 64 mlp_layers = [128 , 64 , 32 ] model = NeuMF(num_users, num_items, embedding_dim, mlp_layers, dropout=0.2 ) user_ids = torch.LongTensor([0 , 1 , 2 , 3 , 4 ]) item_ids = torch.LongTensor([10 , 20 , 30 , 40 , 50 ]) labels = torch.FloatTensor([1 , 1 , 0 , 1 , 0 ]) predictions = model(user_ids, item_ids) print (f"Predictions: {predictions} " )criterion = nn.BCELoss() loss = criterion(predictions, labels) print (f"Loss: {loss.item()} " )
NCF 的训练技巧
1. 负采样 : -
对于隐式反馈,负样本(未点击)数量远大于正样本(点击) -
需要负采样来平衡正负样本比例 - 常见比例:正:负 = 1:1 到 1:4
2. 学习率调度 : - 初始学习率: 0.001-0.01 -
使用学习率衰减(如每 10 个 epoch 减半) - 或使用自适应优化器( Adam 、
AdamW)
3. 正则化 : - L2 正则化:防止过拟合 - Dropout:在
MLP 层使用, dropout 率 0.2-0.5 - 早停( Early
Stopping):监控验证集性能
4. 预训练 : - 先用 GMF 和 MLP 分别预训练 - 再用
NeuMF 进行联合训练 - 可以加速收敛并提升性能
AutoEncoder 推荐: CDAE 与
VAE
AutoEncoder 的基本思想
AutoEncoder(自编码器)是一种无监督学习模型,它试图学习数据的低维表示(编码),然后从低维表示重构原始数据(解码)。
在推荐系统中, AutoEncoder 可以用来: 1.
降维 :将高维的用户-物品交互矩阵压缩到低维空间 2.
去噪 :从稀疏、有噪声的交互数据中恢复完整的用户偏好 3.
生成 :生成用户可能感兴趣的物品
CDAE:去噪自编码器
CDAE( Collaborative Denoising Auto-Encoder)是 2015
年提出的模型,它将用户的交互历史作为输入,通过去噪自编码器重构完整的用户偏好。
模型架构 : -
输入层 :用户的交互向量Extra close brace or missing open brace \mathbf{x}_u \in \{0,1} ^n 编码层 :解码层 :损失函数 :重构误差去噪机制 : -
训练时随机将部分输入置零( dropout) -
迫使模型学习从部分信息恢复完整信息 - 提高模型的鲁棒性
CDAE 的完整实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 import torchimport torch.nn as nnimport torch.nn.functional as Fclass CDAE (nn.Module): """Collaborative Denoising Auto-Encoder""" def __init__ (self, num_users, num_items, hidden_dim, corruption_ratio=0.5 ): """ Args: num_users: 用户数量 num_items: 物品数量 hidden_dim: 隐藏层维度 corruption_ratio: 噪声比例(输入 dropout 的比例) """ super (CDAE, self).__init__() self.num_users = num_users self.num_items = num_items self.hidden_dim = hidden_dim self.corruption_ratio = corruption_ratio self.user_embedding = nn.Embedding(num_users, hidden_dim) self.encoder = nn.Linear(num_items, hidden_dim) self.decoder = nn.Linear(hidden_dim, num_items) nn.init.xavier_uniform_(self.user_embedding.weight) nn.init.xavier_uniform_(self.encoder.weight) nn.init.xavier_uniform_(self.decoder.weight) def forward (self, user_ids, user_items, training=True ): """ Args: user_ids: 用户 ID,形状: [batch_size] user_items: 用户交互向量,形状: [batch_size, num_items] training: 是否训练模式(影响是否添加噪声) Returns: reconstructed: 重构的交互向量,形状: [batch_size, num_items] """ batch_size = user_items.size(0 ) if training and self.corruption_ratio > 0 : mask = torch.rand_like(user_items) > self.corruption_ratio corrupted_input = user_items * mask.float () else : corrupted_input = user_items user_emb = self.user_embedding(user_ids) encoded = self.encoder(corrupted_input) hidden = F.relu(encoded + user_emb) reconstructed = torch.sigmoid(self.decoder(hidden)) return reconstructed def predict (self, user_ids, user_items ): """预测用户对所有物品的评分""" self.eval () with torch.no_grad(): predictions = self.forward(user_ids, user_items, training=False ) return predictions num_users = 1000 num_items = 500 hidden_dim = 128 model = CDAE(num_users, num_items, hidden_dim, corruption_ratio=0.5 ) user_ids = torch.LongTensor([0 , 1 , 2 , 3 , 4 ]) user_items = torch.FloatTensor([ [1 , 0 , 1 , 0 , 0 , 1 , 0 , ...], [0 , 1 , 0 , 1 , 1 , 0 , 0 , ...], [1 , 1 , 0 , 0 , 0 , 1 , 1 , ...], [0 , 0 , 1 , 1 , 0 , 0 , 1 , ...], [1 , 0 , 0 , 0 , 1 , 1 , 0 , ...], ]) reconstructed = model(user_ids, user_items, training=True ) print (f"Reconstructed shape: {reconstructed.shape} " )mask = user_items > 0 loss = F.mse_loss(reconstructed * mask, user_items * mask) print (f"Loss: {loss.item()} " )predictions = model.predict(user_ids, user_items) top_k = 10 top_items = torch.topk(predictions[0 ], top_k).indices print (f"Top-{top_k} recommended items for user 0: {top_items} " )
VAE:变分自编码器
VAE( Variational Auto-Encoder)是 2013 年提出的生成模型,它将
AutoEncoder 的概率化,通过学习数据的潜在分布来生成新样本。
在推荐系统中, VAE 可以用来: 1.
生成推荐 :从用户潜在分布采样,生成可能感兴趣的物品 2.
不确定性建模 :不仅预测评分,还预测不确定性 3.
多样性推荐 :通过采样增加推荐的多样性
VAE 的数学原理 : -
编码器 :学习后验分布解码器 :学习生成分布损失函数 : ELBO( Evidence Lower BOund)
VAE 推荐模型( Mult-VAE)
Mult-VAE 是 2018 年提出的 VAE
推荐模型,它假设用户交互向量服从多项分布。
模型架构 : - 编码器 :采样 :解码器 :
Mult-VAE 的完整实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.distributions as distclass MultVAE (nn.Module): """Multinomial Variational Auto-Encoder for Recommendation""" def __init__ (self, num_items, hidden_dims, latent_dim, dropout=0.5 ): """ Args: num_items: 物品数量 hidden_dims: 编码器和解码器的隐藏层维度列表,如 [600, 200] latent_dim: 潜在变量维度 dropout: Dropout 比例 """ super (MultVAE, self).__init__() self.num_items = num_items self.latent_dim = latent_dim encoder_layers = [] input_dim = num_items for hidden_dim in hidden_dims: encoder_layers.append(nn.Linear(input_dim, hidden_dim)) encoder_layers.append(nn.Tanh()) encoder_layers.append(nn.Dropout(dropout)) input_dim = hidden_dim self.encoder = nn.Sequential(*encoder_layers) self.mu_layer = nn.Linear(hidden_dims[-1 ], latent_dim) self.logvar_layer = nn.Linear(hidden_dims[-1 ], latent_dim) decoder_layers = [] input_dim = latent_dim for hidden_dim in reversed (hidden_dims): decoder_layers.append(nn.Linear(input_dim, hidden_dim)) decoder_layers.append(nn.Tanh()) decoder_layers.append(nn.Dropout(dropout)) input_dim = hidden_dim self.decoder = nn.Sequential(*decoder_layers) self.output_layer = nn.Linear(hidden_dims[0 ], num_items) self._init_weights() def _init_weights (self ): for layer in self.modules(): if isinstance (layer, nn.Linear): nn.init.xavier_uniform_(layer.weight) nn.init.zeros_(layer.bias) def encode (self, user_items ): """编码:用户交互向量 -> 潜在变量分布""" h = self.encoder(user_items) mu = self.mu_layer(h) logvar = self.logvar_layer(h) return mu, logvar def reparameterize (self, mu, logvar ): """重参数化技巧""" std = torch.exp(0.5 * logvar) eps = torch.randn_like(std) z = mu + eps * std return z def decode (self, z ): """解码:潜在变量 -> 重构的交互向量""" h = self.decoder(z) logits = self.output_layer(h) return logits def forward (self, user_items, beta=1.0 ): """ Args: user_items: 用户交互向量,形状: [batch_size, num_items] beta: KL 散度的权重(用于 beta-VAE) Returns: reconstructed: 重构的交互向量 mu: 潜在变量的均值 logvar: 潜在变量的对数方差 kl_loss: KL 散度损失 """ mu, logvar = self.encode(user_items) z = self.reparameterize(mu, logvar) logits = self.decode(z) kl_loss = -0.5 * torch.sum (1 + logvar - mu.pow (2 ) - logvar.exp(), dim=1 ) kl_loss = beta * kl_loss.mean() return logits, mu, logvar, kl_loss def predict (self, user_items ): """预测用户对所有物品的评分""" self.eval () with torch.no_grad(): mu, logvar = self.encode(user_items) z = self.reparameterize(mu, logvar) logits = self.decode(z) predictions = logits.clone() predictions[user_items > 0 ] = float ('-inf' ) return predictions num_items = 500 hidden_dims = [600 , 200 ] latent_dim = 50 model = MultVAE(num_items, hidden_dims, latent_dim, dropout=0.5 ) user_items = torch.FloatTensor([ [1 , 0 , 1 , 0 , 0 , 1 , 0 , ...], [0 , 1 , 0 , 1 , 1 , 0 , 0 , ...], [1 , 1 , 0 , 0 , 0 , 1 , 1 , ...], ]) logits, mu, logvar, kl_loss = model(user_items, beta=0.2 ) reconstruction_loss = -torch.sum ( F.log_softmax(logits, dim=1 ) * user_items, dim=1 ).mean() total_loss = reconstruction_loss + kl_loss print (f"Reconstruction loss: {reconstruction_loss.item()} " )print (f"KL loss: {kl_loss.item()} " )print (f"Total loss: {total_loss.item()} " )predictions = model.predict(user_items) top_k = 10 top_items = torch.topk(predictions[0 ], top_k).indices print (f"Top-{top_k} recommended items: {top_items} " )
CDAE vs VAE 对比
特性
CDAE
VAE
模型类型
确定性自编码器
概率生成模型
潜在变量
固定向量
概率分布
生成能力
弱(只能重构)
强(可以采样生成)
不确定性
无法建模
可以建模
训练难度
简单
较复杂(需要 KL 散度)
推荐多样性
较低
较高(通过采样)
适用场景
密集交互数据
稀疏交互数据
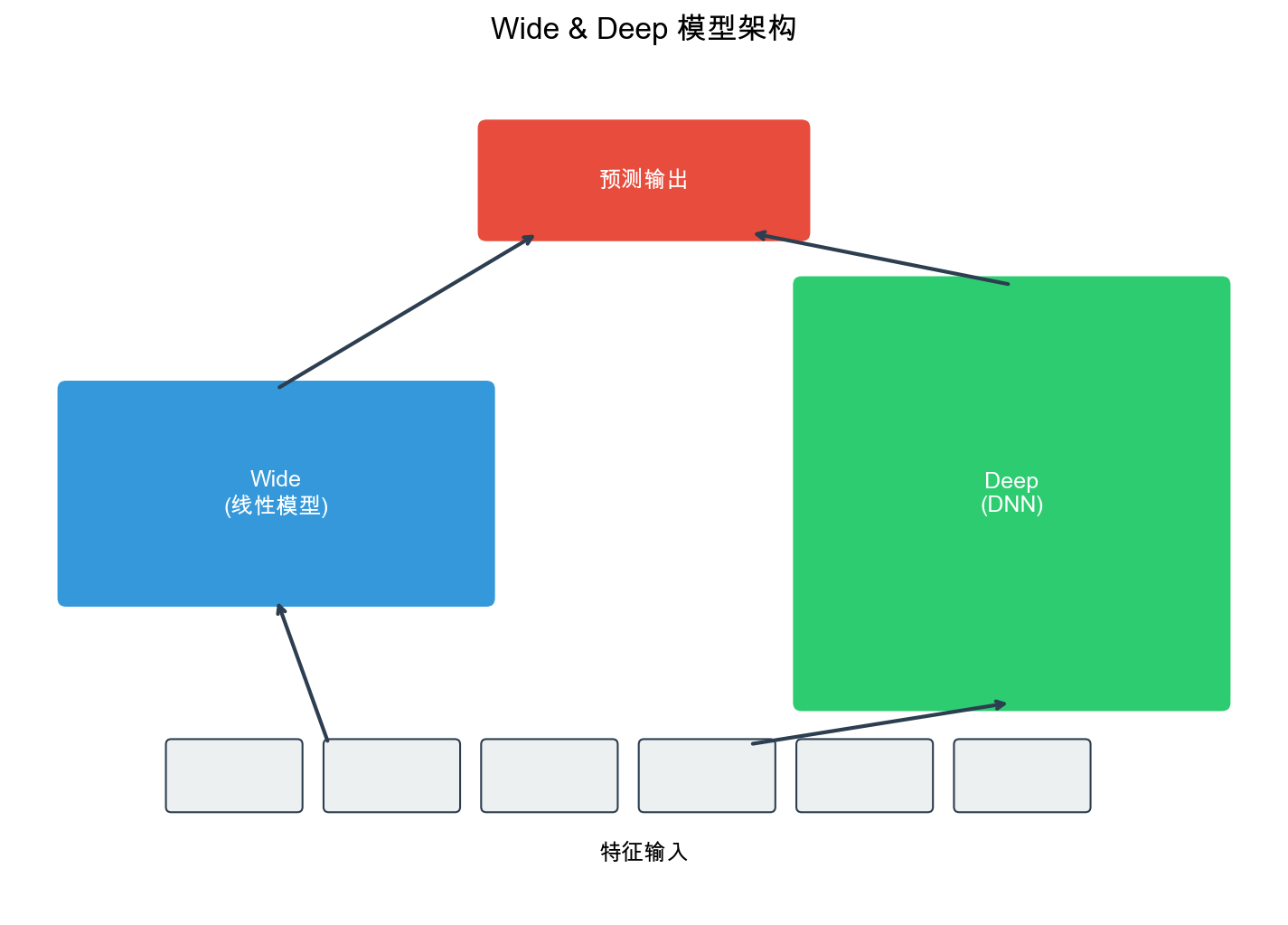
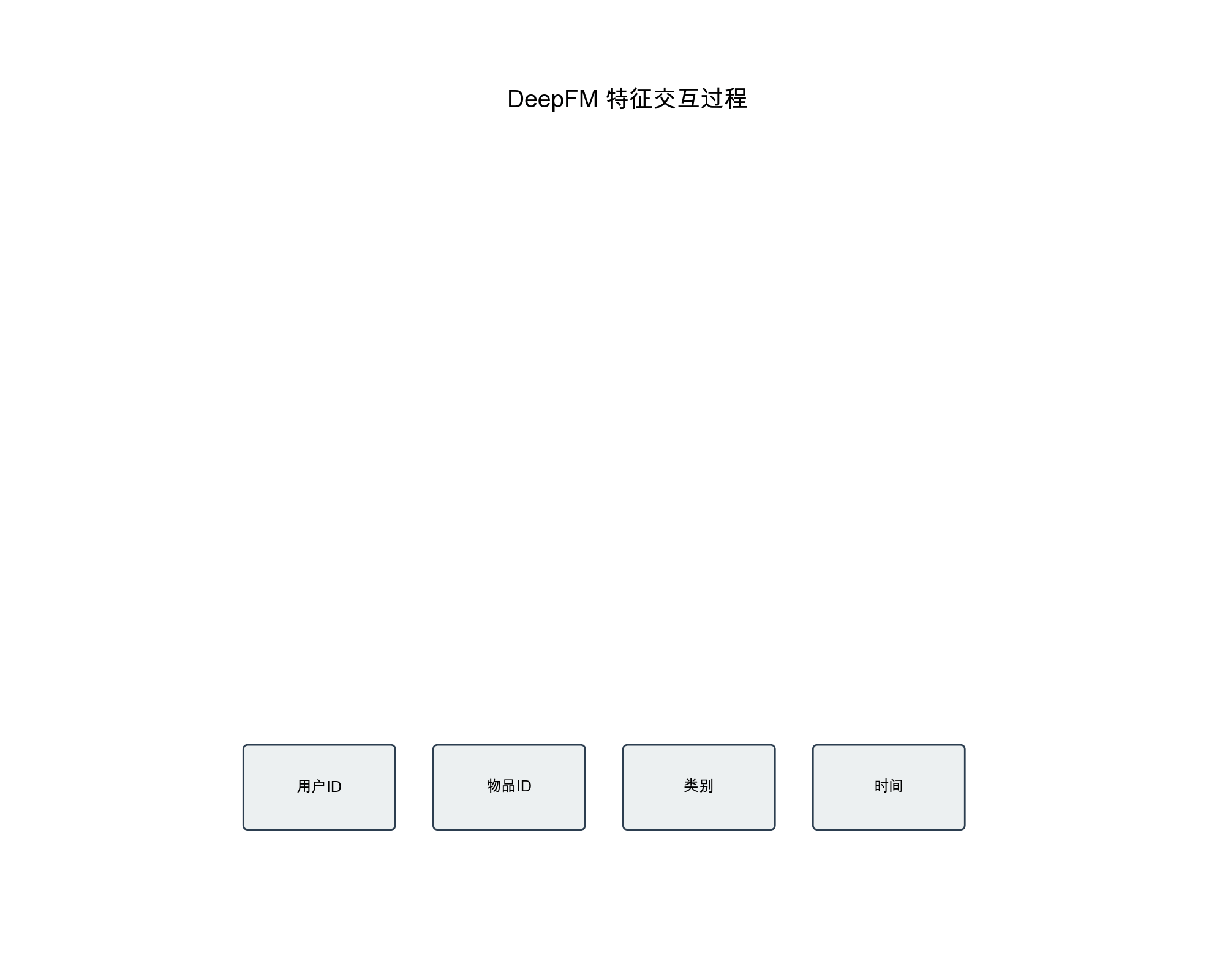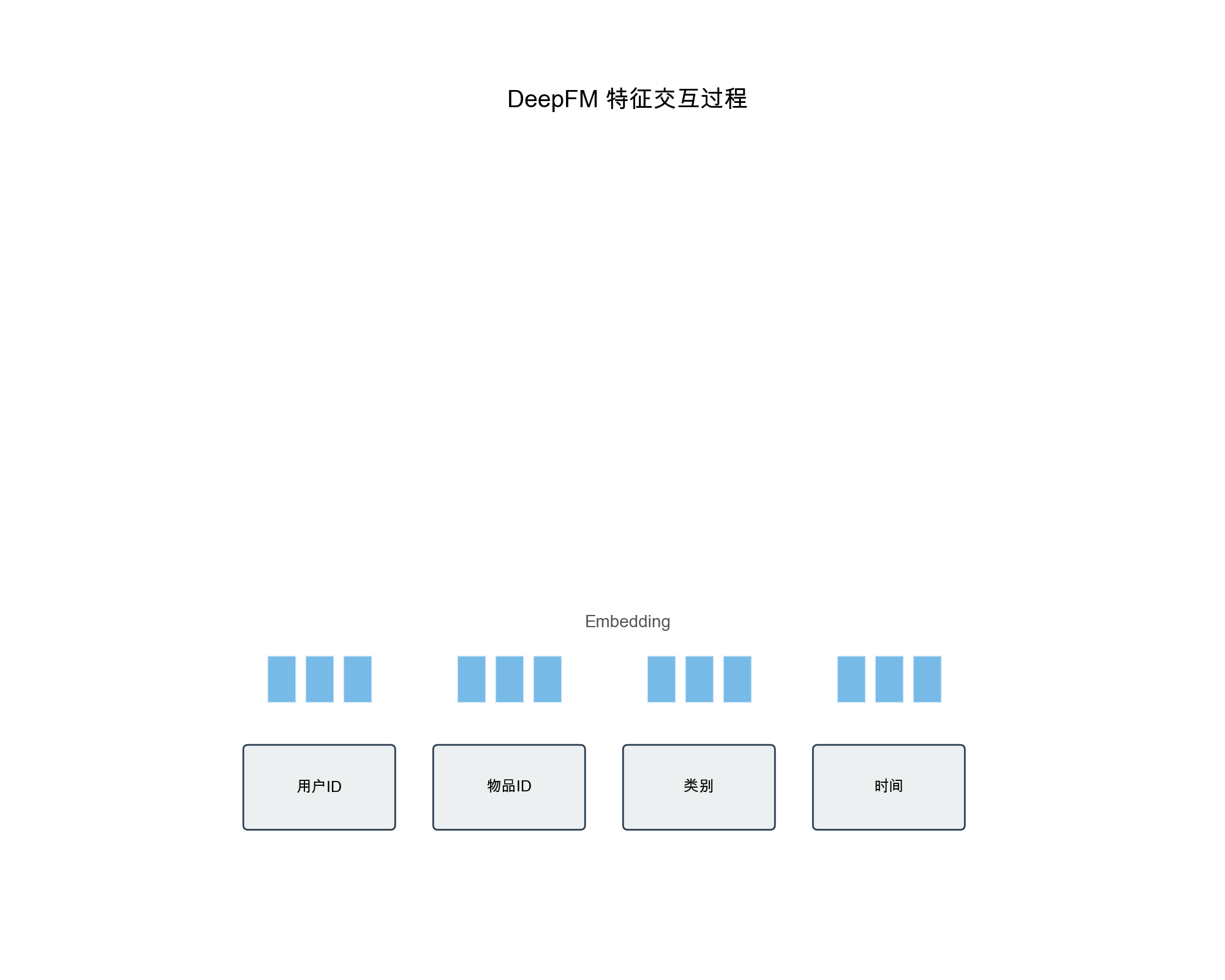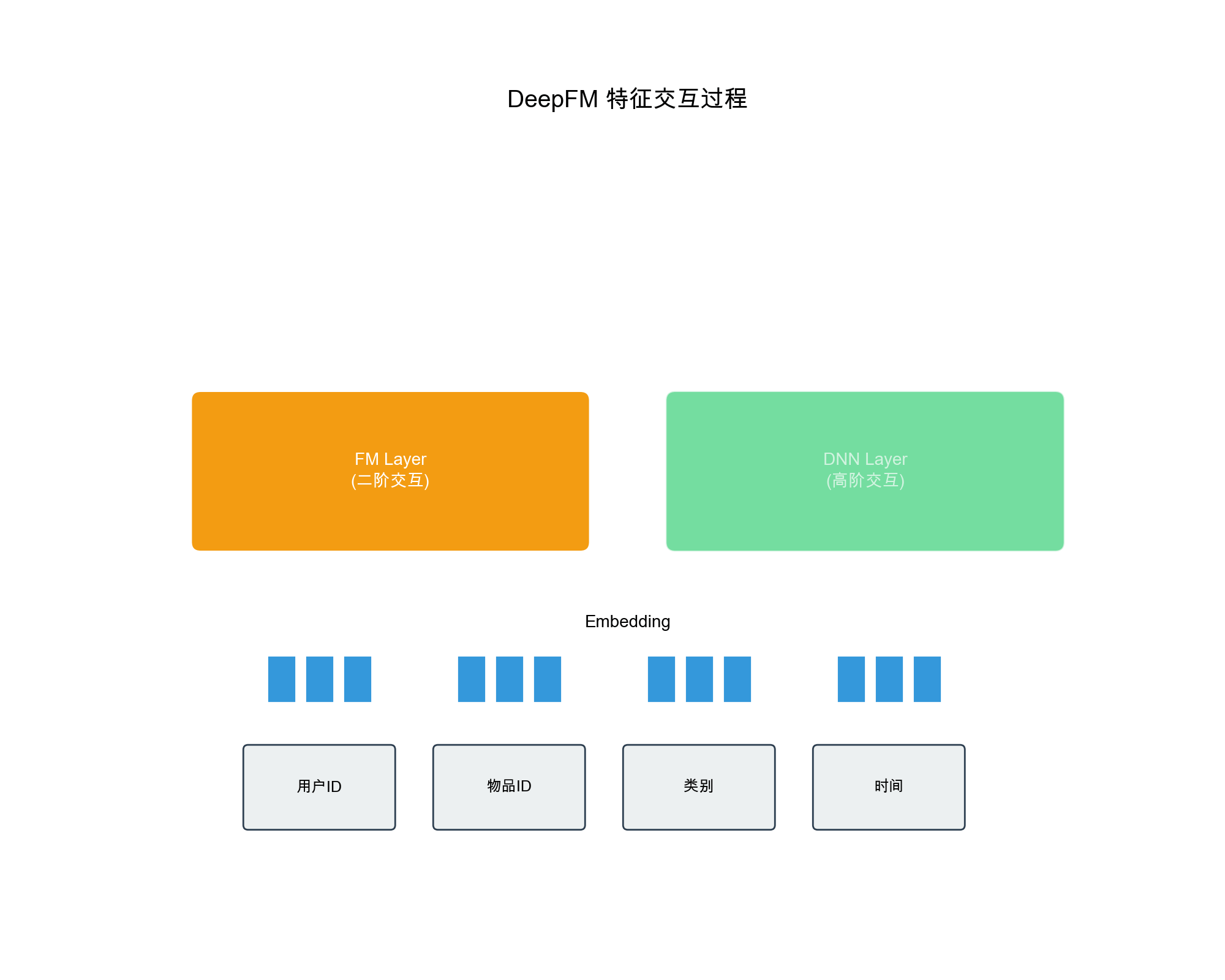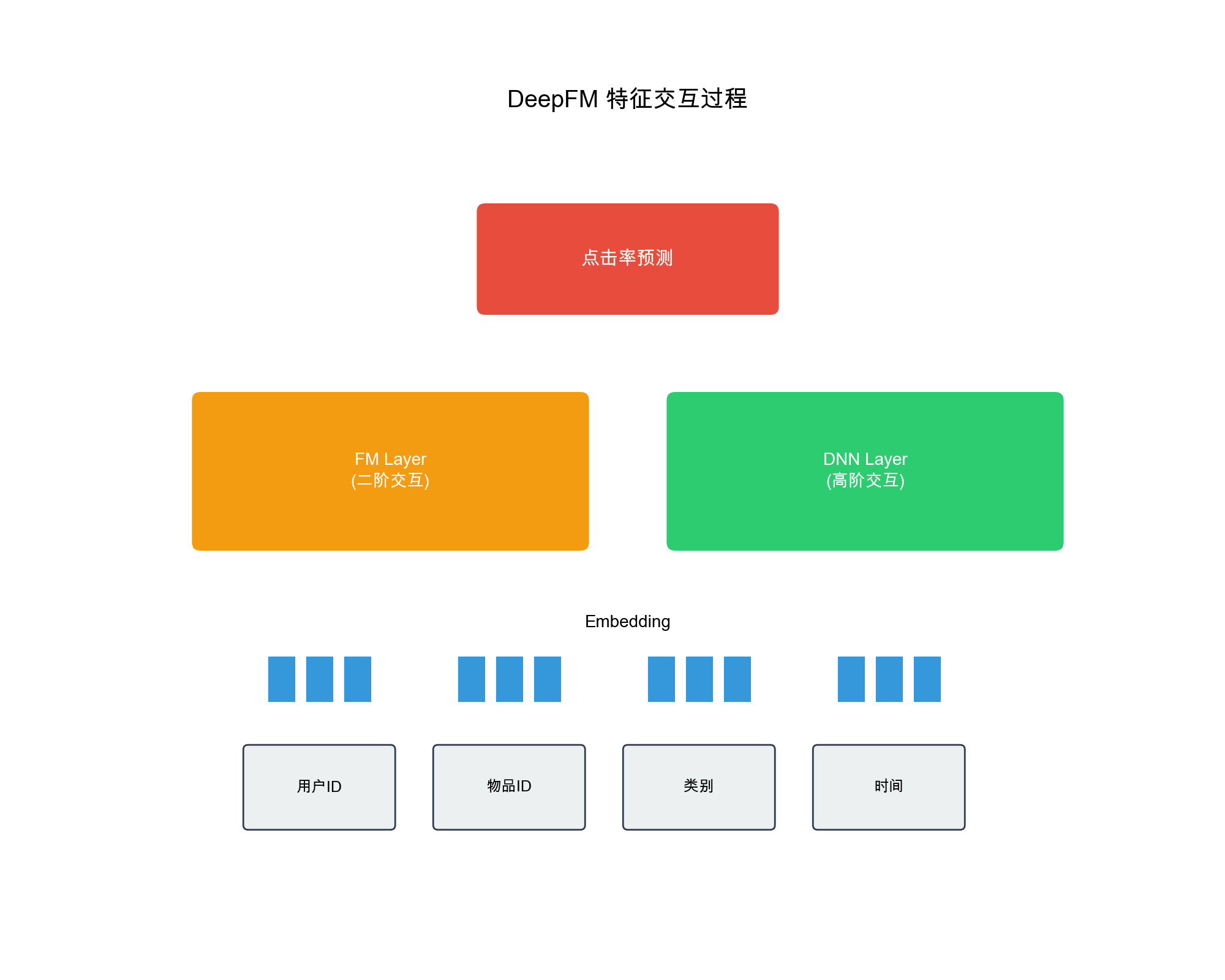
Wide & Deep 模型
Wide & Deep 的背景
2016 年, Google 在 Google Play 应用商店的推荐系统中提出了 Wide &
Deep 模型。这个模型的基本思路:结合记忆( Memorization)和泛化(
Generalization) 。
记忆( Wide
部分) :学习特征之间的直接关联,如"安装了 Pandora
的用户也安装了 YouTube"泛化( Deep 部分) :学习特征的 Embedding
表示,捕捉稀疏特征之间的潜在关联
Wide & Deep 的模型架构
Wide & Deep 模型包含两个组件:
1. Wide 部分(线性模型) : -
输入:原始特征和交叉特征(如"用户年龄×物品类别") - 输出:
2. Deep 部分(深度神经网络) : - 输入:稀疏特征的
Embedding 向量 - 结构:多层全连接网络 - 输出:
3. 融合 : - 最终输出:
Wide & Deep 的数学公式
完整的 Wide & Deep 模型可以表示为:
其中: -
Deep 部分的计算过程: -
Wide & Deep 的完整实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 import torchimport torch.nn as nnimport torch.nn.functional as Fclass WideAndDeep (nn.Module): """Wide & Deep 模型""" def __init__ (self, field_dims, embedding_dim, deep_layers, dropout=0.0 ): super (WideAndDeep, self).__init__() self.field_dims = field_dims self.num_fields = len (field_dims) self.embedding_dim = embedding_dim self.wide_linear = nn.Linear(sum (field_dims), 1 ) self.embeddings = nn.ModuleList([ nn.Embedding(field_dim, embedding_dim) for field_dim in field_dims ]) deep_input_dim = self.num_fields * embedding_dim deep_layers_list = [] for deep_dim in deep_layers: deep_layers_list.append(nn.Linear(deep_input_dim, deep_dim)) deep_layers_list.append(nn.ReLU()) if dropout > 0 : deep_layers_list.append(nn.Dropout(dropout)) deep_input_dim = deep_dim self.deep_mlp = nn.Sequential(*deep_layers_list) self.deep_output = nn.Linear(deep_layers[-1 ], 1 ) self._init_weights() def _init_weights (self ): nn.init.xavier_uniform_(self.wide_linear.weight) nn.init.zeros_(self.wide_linear.bias) for embedding in self.embeddings: nn.init.xavier_uniform_(embedding.weight) for layer in self.deep_mlp: if isinstance (layer, nn.Linear): nn.init.xavier_uniform_(layer.weight) nn.init.zeros_(layer.bias) nn.init.xavier_uniform_(self.deep_output.weight) nn.init.zeros_(self.deep_output.bias) def forward (self, x_wide, x_deep ): """ Args: x_wide: Wide 部分的输入( one-hot 编码),形状: [batch_size, sum(field_dims)] x_deep: Deep 部分的输入(字段索引),形状: [batch_size, num_fields] Returns: output: 预测值,形状: [batch_size] """ wide_output = self.wide_linear(x_wide) deep_embeddings = [] for i in range (self.num_fields): deep_embeddings.append(self.embeddings[i](x_deep[:, i])) deep_concat = torch.cat(deep_embeddings, dim=1 ) deep_output = self.deep_mlp(deep_concat) deep_output = self.deep_output(deep_output) output = wide_output + deep_output output = torch.sigmoid(output.squeeze()) return output field_dims = [10000 , 1000 , 50 , 20 ] embedding_dim = 32 deep_layers = [128 , 64 , 32 ] model = WideAndDeep(field_dims, embedding_dim, deep_layers, dropout=0.2 ) batch_size = 4 x_wide = torch.zeros(batch_size, sum (field_dims)) x_wide[0 , 123 ] = 1 x_wide[0 , 10000 + 456 ] = 1 x_wide[0 , 10000 + 1000 + 5 ] = 1 x_wide[0 , 10000 + 1000 + 50 + 10 ] = 1 x_deep = torch.LongTensor([ [123 , 456 , 5 , 10 ], [124 , 457 , 5 , 11 ], [125 , 458 , 6 , 10 ], [126 , 459 , 6 , 12 ] ]) predictions = model(x_wide, x_deep) print (f"Predictions: {predictions} " )labels = torch.FloatTensor([1 , 1 , 0 , 1 ]) criterion = nn.BCELoss() loss = criterion(predictions, labels) print (f"Loss: {loss.item()} " )
Wide & Deep 的优化版本
在实际应用中, Wide & Deep 有几个优化版本:
1. DeepFM : - 用 FM 替代 Wide 部分 -
自动学习二阶特征交互 - 避免了人工设计交叉特征
2. xDeepFM : - 引入 CIN( Compressed Interaction
Network) - 显式建模高阶特征交互 - 比 DeepFM 更强的交互建模能力
3. DCN( Deep & Cross Network) : - 用 Cross
Network 替代 Wide 部分 - 自动学习任意阶的特征交互 - 计算效率高
特征工程
特征类型
推荐系统中的特征可以分为以下几类:
1. 用户特征 : - 用户 ID 、年龄、性别、城市、职业 -
用户历史行为统计(点击率、购买率、平均评分) -
用户画像标签(兴趣标签、消费能力)
2. 物品特征 : - 物品 ID 、类别、品牌、价格 -
物品统计特征(点击率、购买率、平均评分) -
物品内容特征(文本描述、图像)
3. 上下文特征 : -
时间特征(小时、星期、月份、是否节假日) -
设备特征(设备类型、操作系统、 APP 版本) - 位置特征( GPS
坐标、城市、商圈)
4. 交互特征 : - 用户-物品交互历史(最近 N
次点击、购买) - 用户-类别交互统计(各类别的点击次数) -
物品-用户交互统计(点击该物品的用户画像)
5. 交叉特征 : -
用户特征×物品特征(如"用户年龄×物品类别") -
时间特征×物品特征(如"时间段×物品类别") -
高阶交叉特征(如"用户年龄×物品类别×时间段")
特征编码
1. 数值特征 : - 标准化 :归一化 :分桶(
Binning) :将连续值离散化,如年龄分为"0-18, 19-30, 31-50,
50+"
2. 类别特征 : - One-hot
编码 :每个类别一个维度 - Embedding
编码 :映射到低维稠密向量(深度学习常用) - Hash
编码 :用哈希函数将类别映射到固定维度
3. 序列特征 : -
Padding :将不同长度的序列 padding 到相同长度 -
Pooling :平均池化、最大池化、注意力池化 -
RNN/Transformer :用序列模型处理
特征选择
不是所有特征都有用,需要进行特征选择:
1. 统计方法 : - 互信息( Mutual
Information) :衡量特征与目标的相关性 -
卡方检验 :检验特征与目标的独立性 -
相关系数 :计算特征与目标的线性相关性
2. 模型方法 : - L1
正则化 :自动将不重要特征的权重置零 -
特征重要性 :基于树模型(如 XGBoost)的特征重要性 -
Permutation
Importance :打乱特征值,观察模型性能下降
3. 业务方法 : - A/B
测试 :上线特征,观察指标变化 -
特征分析 :分析特征分布、缺失率、覆盖率
特征工程代码示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 import numpy as npimport pandas as pdfrom sklearn.preprocessing import StandardScaler, LabelEncoderfrom sklearn.feature_selection import mutual_info_classifclass FeatureEngineer : """特征工程工具类""" def __init__ (self ): self.scalers = {} self.encoders = {} self.feature_names = [] def process_numerical_features (self, df, numerical_cols ): """处理数值特征:标准化""" processed_df = df.copy() for col in numerical_cols: scaler = StandardScaler() processed_df[col] = scaler.fit_transform(df[[col]]) self.scalers[col] = scaler return processed_df def process_categorical_features (self, df, categorical_cols ): """处理类别特征: Label Encoding""" processed_df = df.copy() for col in categorical_cols: encoder = LabelEncoder() processed_df[col] = encoder.fit_transform(df[col].astype(str )) self.encoders[col] = encoder return processed_df def create_cross_features (self, df, field1, field2 ): """创建交叉特征""" cross_feature = f"{field1} _x_{field2} " df[cross_feature] = df[field1].astype(str ) + "_" + df[field2].astype(str ) return df def create_binning_features (self, df, numerical_col, bins ): """创建分桶特征""" bin_feature = f"{numerical_col} _bin" df[bin_feature] = pd.cut(df[numerical_col], bins=bins, labels=False ) return df def create_statistical_features (self, df, group_col, agg_col, agg_funcs ): """创建统计特征(如用户平均点击率)""" stats = df.groupby(group_col)[agg_col].agg(agg_funcs) stats.columns = [f"{group_col} _{agg_col} _{func} " for func in agg_funcs] df = df.merge(stats, left_on=group_col, right_index=True , how='left' ) return df def select_features (self, X, y, k=10 ): """特征选择:基于互信息""" mi_scores = mutual_info_classif(X, y, random_state=42 ) top_k_indices = np.argsort(mi_scores)[-k:] return top_k_indices data = { 'user_id' : [1 , 1 , 2 , 2 , 3 , 3 ], 'item_id' : [10 , 20 , 10 , 30 , 20 , 30 ], 'category' : ['A' , 'B' , 'A' , 'C' , 'B' , 'C' ], 'price' : [10.5 , 20.3 , 10.5 , 15.7 , 20.3 , 15.7 ], 'age' : [25 , 25 , 30 , 30 , 35 , 35 ], 'click' : [1 , 1 , 0 , 1 , 1 , 0 ] } df = pd.DataFrame(data) fe = FeatureEngineer() df = fe.process_numerical_features(df, ['price' , 'age' ]) df = fe.process_categorical_features(df, ['category' ]) df = fe.create_cross_features(df, 'user_id' , 'category' ) df = fe.create_binning_features(df, 'age' , bins=[0 , 25 , 30 , 40 , 100 ]) df = fe.create_statistical_features( df, group_col='user_id' , agg_col='click' , agg_funcs=['mean' , 'sum' ] ) print (df.head())
训练技巧
数据准备
1. 负采样 : - 对于隐式反馈,负样本数量远大于正样本 -
需要负采样来平衡正负样本比例 -
常见策略:随机负采样、热门负采样、困难负采样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def negative_sampling (user_items, num_negatives=4 ): """负采样:为每个正样本采样 N 个负样本""" positive_samples = [] negative_samples = [] for user_id, item_id in user_items: positive_samples.append((user_id, item_id, 1 )) user_interacted = set (user_items[user_items[:, 0 ] == user_id][:, 1 ]) all_items = set (range (num_items)) negative_candidates = list (all_items - user_interacted) negative_items = np.random.choice( negative_candidates, size=min (num_negatives, len (negative_candidates)), replace=False ) for neg_item in negative_items: negative_samples.append((user_id, neg_item, 0 )) return positive_samples, negative_samples
2. 数据增强 : -
时间窗口滑动 :用不同时间窗口构建训练集 -
数据混合 :混合不同来源的数据 -
噪声注入 :训练时添加噪声提高鲁棒性
3. 数据划分 : -
时间划分 :按时间顺序划分训练集和测试集(更符合实际) -
随机划分 :随机划分(可能导致数据泄露) -
用户划分 :按用户划分(避免用户出现在训练集和测试集)
模型训练
1. 优化器选择 : -
Adam/AdamW :自适应学习率,适合大多数场景 -
SGD :需要手动调学习率,但可能收敛到更好的解 -
Adagrad :适合稀疏梯度
1 2 3 4 5 6 7 8 9 10 11 import torch.optim as optimoptimizer = optim.Adam(model.parameters(), lr=0.001 , weight_decay=1e-5 ) optimizer = optim.AdamW(model.parameters(), lr=0.001 , weight_decay=1e-4 ) optimizer = optim.SGD(model.parameters(), lr=0.01 , momentum=0.9 ) scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10 , gamma=0.5 )
2. 学习率调度 : - StepLR :每 N 个
epoch 衰减一次 - ExponentialLR :指数衰减 -
CosineAnnealingLR :余弦退火 -
ReduceLROnPlateau :根据验证集性能自动调整
1 2 3 4 5 6 7 8 9 10 scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10 , gamma=0.5 ) scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=50 ) scheduler = optim.lr_scheduler.ReduceLROnPlateau( optimizer, mode='min' , factor=0.5 , patience=5 )
3. 正则化 : - L2 正则化 :通过
weight_decay 实现 - Dropout :随机置零部分神经元 -
Batch Normalization :归一化激活值 - Early
Stopping :验证集性能不提升时提前停止
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 model = nn.Sequential( nn.Linear(100 , 64 ), nn.ReLU(), nn.Dropout(0.2 ), nn.Linear(64 , 32 ), nn.ReLU(), nn.Dropout(0.2 ), nn.Linear(32 , 1 ) ) class EarlyStopping : def __init__ (self, patience=5 , min_delta=0 ): self.patience = patience self.min_delta = min_delta self.counter = 0 self.best_score = None def __call__ (self, val_score ): if self.best_score is None : self.best_score = val_score elif val_score < self.best_score + self.min_delta: self.counter += 1 if self.counter >= self.patience: return True else : self.best_score = val_score self.counter = 0 return False
训练循环示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 def train_model (model, train_loader, val_loader, num_epochs=50 ): """完整的训练循环""" device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) model = model.to(device) criterion = nn.BCELoss() optimizer = optim.Adam(model.parameters(), lr=0.001 , weight_decay=1e-5 ) scheduler = optim.lr_scheduler.ReduceLROnPlateau( optimizer, mode='min' , factor=0.5 , patience=5 ) early_stopping = EarlyStopping(patience=10 ) best_val_loss = float ('inf' ) for epoch in range (num_epochs): model.train() train_loss = 0.0 for batch in train_loader: user_ids, item_ids, labels = batch user_ids = user_ids.to(device) item_ids = item_ids.to(device) labels = labels.to(device) optimizer.zero_grad() predictions = model(user_ids, item_ids) loss = criterion(predictions, labels) loss.backward() optimizer.step() train_loss += loss.item() train_loss /= len (train_loader) model.eval () val_loss = 0.0 with torch.no_grad(): for batch in val_loader: user_ids, item_ids, labels = batch user_ids = user_ids.to(device) item_ids = item_ids.to(device) labels = labels.to(device) predictions = model(user_ids, item_ids) loss = criterion(predictions, labels) val_loss += loss.item() val_loss /= len (val_loader) scheduler.step(val_loss) if early_stopping(val_loss): print (f"Early stopping at epoch {epoch} " ) break if val_loss < best_val_loss: best_val_loss = val_loss torch.save(model.state_dict(), 'best_model.pth' ) print (f"Epoch {epoch+1 } /{num_epochs} : " f"Train Loss: {train_loss:.4 f} , Val Loss: {val_loss:.4 f} " ) return model
评估指标
1. 分类任务( CTR 预估) : - AUC :
ROC 曲线下面积,衡量排序能力 -
LogLoss :对数损失,衡量预测概率的准确性 -
Precision@K : Top-K 推荐中正样本的比例 -
Recall@K : Top-K 推荐覆盖的正样本比例
2. 回归任务(评分预测) : -
RMSE :均方根误差 - MAE :平均绝对误差 -
NDCG :归一化折损累积增益(排序指标)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from sklearn.metrics import roc_auc_score, log_loss, precision_recall_fscore_supportdef evaluate_model (model, test_loader ): """评估模型""" device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) model.eval () all_predictions = [] all_labels = [] with torch.no_grad(): for batch in test_loader: user_ids, item_ids, labels = batch user_ids = user_ids.to(device) item_ids = item_ids.to(device) predictions = model(user_ids, item_ids) all_predictions.extend(predictions.cpu().numpy()) all_labels.extend(labels.numpy()) auc = roc_auc_score(all_labels, all_predictions) logloss = log_loss(all_labels, all_predictions) k = 10 sorted_indices = np.argsort(all_predictions)[::-1 ] top_k_labels = [all_labels[i] for i in sorted_indices[:k]] precision_k = sum (top_k_labels) / k recall_k = sum (top_k_labels) / sum (all_labels) return { 'AUC' : auc, 'LogLoss' : logloss, f'Precision@{k} ' : precision_k, f'Recall@{k} ' : recall_k }
Q&A 常见问题
Q1: Embedding 维度如何选择?
A : Embedding 维度
小规模数据 (<10 万用户/物品):中规模数据 ( 10 万-100 万):大规模数据 (>100 万):
经验法则: 1. 从
Q2: 为什么 NCF
比矩阵分解效果好?
A : NCF 的优势主要在于:
非线性建模 :矩阵分解只能捕捉线性关系(内积), NCF
通过 MLP 可以捕捉非线性关系特征融合 : NCF 的 GMF 和 MLP 部分可以互补, GMF
捕捉简单交互, MLP 捕捉复杂交互端到端训练 :整个模型可以联合优化,而矩阵分解通常需要交替优化
但 NCF 也有缺点: - 计算复杂度更高(需要前向传播) -
可解释性较差(黑盒模型) - 需要更多数据才能训练好
Q3: CDAE 和 VAE 的区别是什么?
A : 主要区别:
模型类型 :
CDAE:确定性自编码器,潜在变量是固定向量
VAE:概率生成模型,潜在变量是概率分布
生成能力 :
CDAE:只能重构输入,无法生成新样本
VAE:可以从潜在分布采样,生成新样本
不确定性 :
CDAE:无法建模不确定性
VAE:通过潜在分布的方差可以建模不确定性
训练 :
CDAE:训练简单,只需要重构损失
VAE:需要 KL 散度项,训练更复杂
推荐多样性 :
CDAE:推荐结果相对固定
VAE:通过采样可以增加多样性
Q4: Wide
& Deep 中 Wide 部分和 Deep 部分的作用分别是什么?
A :
Wide 部分(记忆) : - 学习特征之间的直接关联 -
例如:"安装了 Pandora 的用户也安装了 YouTube" -
适合处理稀疏、高维的交叉特征 - 可以快速记忆历史数据中的模式
Deep 部分(泛化) : - 学习特征的 Embedding 表示 -
捕捉稀疏特征之间的潜在关联 - 可以泛化到未见过的特征组合 - 适合处理稠密的
Embedding 特征
为什么需要两者结合 : - 只有
Wide:无法泛化,只能记忆历史数据 - 只有
Deep:可能过度泛化,忽略重要的直接关联 - Wide +
Deep:既记忆又泛化,达到最佳效果
Q5: 如何处理冷启动问题?
A : 冷启动是推荐系统的经典问题,有以下解决方案:
1. 新用户冷启动 : -
热门推荐 :推荐热门物品 -
内容推荐 :基于用户注册信息(年龄、性别等)推荐 -
迁移学习 :从相似用户迁移偏好 -
多臂老虎机 :探索-利用平衡
2. 新物品冷启动 : -
内容特征 :基于物品属性(类别、标签)推荐给相似用户 -
Embedding 预训练 :用物品内容特征预训练 Embedding -
协同过滤 :基于相似物品的交互数据
3. 系统冷启动 : -
外部数据 :利用其他平台的数据 -
专家规则 :人工设计的推荐规则 - A/B
测试 :快速迭代优化
Q6: 负采样策略如何选择?
A : 负采样策略影响模型性能:
1. 随机负采样 : - 最简单,从所有未交互物品中随机采样
- 适合大多数场景 - 可能采样到"用户不感兴趣但也不讨厌"的物品
2. 热门负采样 : - 从热门物品中采样负样本 -
假设用户没点击热门物品说明不喜欢 - 可能引入流行度偏差
3. 困难负采样( Hard Negative Sampling) : -
采样模型预测分数较高的负样本 - 让模型学习区分"容易混淆"的正负样本 -
提升模型性能,但需要动态采样(训练过程中模型在变化)
4. 混合策略 : - 50%随机 + 50%热门 -
或根据训练阶段调整:早期随机,后期困难负采样
Q7: 如何防止过拟合?
A : 防止过拟合的方法:
1. 正则化 : - L2 正则化 :通过
weight_decay 实现,通常 1e-5 到 1e-3 -
Dropout :随机置零部分神经元, dropout 率 0.2-0.5 -
Batch Normalization :归一化激活值,稳定训练
2. 数据增强 : -
负采样 :增加负样本数量 -
噪声注入 :训练时添加噪声 -
数据混合 :混合不同来源的数据
3. 模型复杂度控制 : -
减少层数 :从深层网络开始,逐步减少 - 减少
Embedding 维度 :降低模型容量 -
早停 :验证集性能不提升时停止训练
4. 交叉验证 : - 用 K 折交叉验证评估模型 -
避免单次划分的偶然性
Q8: 如何加速模型训练?
A : 加速训练的方法:
1. 硬件加速 : - GPU :使用 CUDA
加速,速度提升 10-100 倍 - 多 GPU :数据并行或模型并行 -
TPU : Google 的专用芯片,适合大规模训练
2. 数据优化 : -
数据预处理 :提前处理好特征,避免训练时计算 -
数据加载 :使用多进程 DataLoader( num_workers>0) -
批量大小 :增大 batch size,提高 GPU 利用率
3. 模型优化 : - 混合精度训练 :使用
FP16,速度提升 2 倍 - 梯度累积 :模拟大批量训练 -
模型剪枝 :减少模型参数
4. 算法优化 : - 学习率调度 :使用
warmup,加速收敛 - 优化器选择 : Adam 通常比 SGD
收敛更快 - 异步训练 :多机多卡异步更新
Q9: 如何评估推荐系统的效果?
A : 推荐系统评估需要多维度指标:
1. 离线指标 : - 准确率指标 : AUC 、
LogLoss 、 RMSE 、 MAE - 排序指标 : NDCG 、 MRR 、 MAP
- 覆盖率指标 : Coverage(推荐物品的多样性) -
多样性指标 : Intra-list
Diversity(推荐列表内物品的差异)
2. 在线指标 : - CTR :点击率 -
CVR :转化率(购买/下载) -
GMV :总交易额 -
用户留存率 :用户回访比例
3. 业务指标 : -
用户满意度 :评分、反馈 -
长尾物品推荐 :是否推荐了冷门物品 -
实时性 :推荐响应时间
4. A/B 测试 : - 对比新旧模型的效果 -
需要足够的样本量(通常>1000 用户) - 关注统计显著性
Q10: Embedding 可以可视化吗?
A : 可以,常用的可视化方法:
1. t-SNE : - 将高维 Embedding 降维到 2D -
可以观察相似物品是否聚集 - 适合探索性分析
2. PCA : - 线性降维,计算快速 - 保留主要方差 -
适合初步分析
3. UMAP : - 比 t-SNE 更快,效果类似 -
保留局部和全局结构 - 适合大规模数据
4. 可视化工具 : - TensorBoard :
TensorFlow 的可视化工具 - Weights &
Biases :在线可视化平台 -
Plotly :交互式可视化
可视化可以帮助: - 理解模型学到了什么 - 发现异常(如某些物品
Embedding 异常) - 解释推荐结果(为什么推荐这个物品)
Q11:
如何处理类别特征中的新类别?
A : 新类别( OOV,
Out-of-Vocabulary)是常见问题:
1. 默认 Embedding : - 为新类别分配一个特殊的
Embedding 向量 - 可以随机初始化或用零向量 - 训练过程中会更新
2. 哈希技巧 : - 用哈希函数将新类别映射到已知类别 -
例如:hash(new_category) % num_categories -
可能有哈希冲突,但可以处理任意新类别
3. 内容特征 : -
如果新类别有内容特征(如文本描述),可以用内容特征初始化 Embedding -
例如:用 Word2Vec 对类别名称编码
4. 迁移学习 : - 从相似类别迁移 Embedding -
例如:新电影类别可以用相似类别的 Embedding 初始化
Q12:
深度学习推荐模型和传统方法如何结合?
A : 可以多种方式结合:
1. 模型融合 : -
加权平均 :多个模型的预测结果加权平均 -
Stacking :用元模型学习如何组合多个模型 -
Blending :不同模型负责不同场景
2. 特征融合 : -
传统方法的输出作为深度学习模型的输入特征 -
例如:矩阵分解的预测分数作为特征
3. 两阶段推荐 : -
召回阶段 :用传统方法(如 Item-CF)快速召回候选集 -
排序阶段 :用深度学习模型精细排序
4. 集成学习 : - 训练多个不同结构的模型 -
投票或平均得到最终结果 - 通常比单模型效果好
总结
深度学习为推荐系统带来了革命性的变化。从 Embedding 的自动特征学习,到
NCF 的非线性建模,从 AutoEncoder 的去噪重构,到 Wide & Deep
的记忆-泛化结合,深度学习模型在各个推荐场景都展现出了强大的能力。
但深度学习不是银弹。它需要大量数据、计算资源和调参经验。在实际应用中,需要:
1. 理解业务场景 :选择适合的模型架构 2.
做好特征工程 :特征质量决定模型上限 3.
精心设计训练流程 :数据准备、负采样、正则化、评估指标 4.
持续迭代优化 : A/B 测试、在线监控、快速迭代
推荐系统是一个复杂的系统工程,深度学习只是其中的一环。只有将算法、工程、业务三者结合,才能构建出真正有效的推荐系统。
未来,推荐系统的发展方向包括: - 序列推荐 :用
Transformer 建模用户行为序列 -
强化学习 :动态调整推荐策略 -
多模态推荐 :融合文本、图像、视频等多种模态 -
可解释推荐 :让用户理解为什么推荐这个物品 -
公平性推荐 :避免推荐偏差,保护用户隐私
希望这篇文章能帮助你建立深度学习推荐系统的完整知识体系。如果你有任何问题,欢迎在评论区讨论。