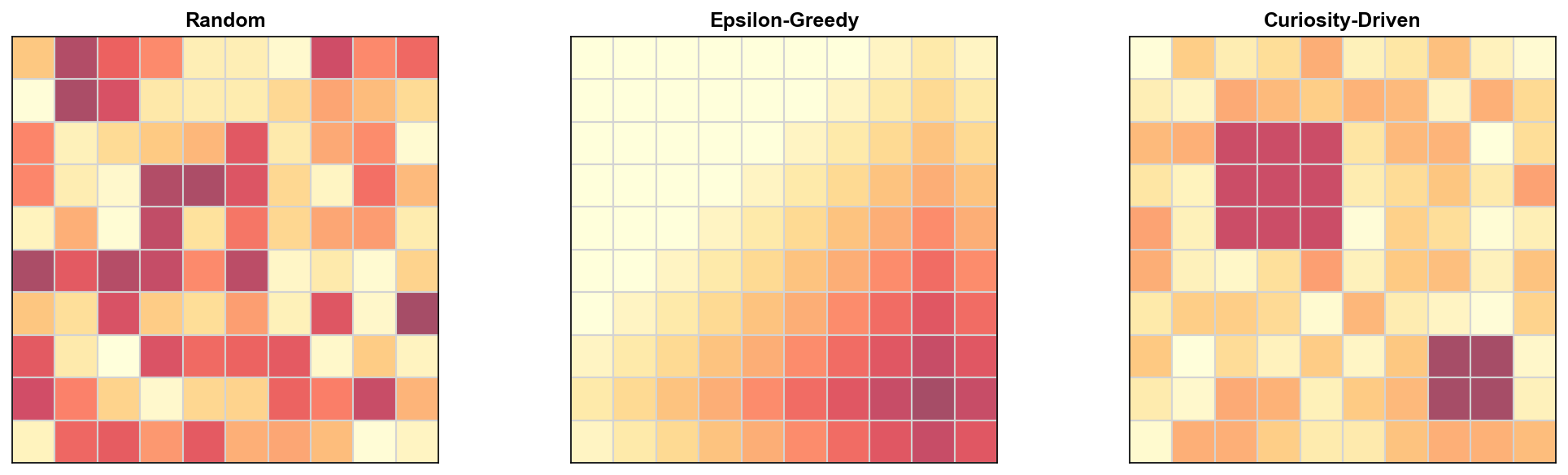
强化学习的核心难题之一是探索-利用困境(Exploration-Exploitation
Dilemma)。一个智能体如果只利用已知的好策略,可能永远发现不了更优解;但如果探索过度,又会浪费大量时间在低回报行为上。传统方法如-greedy 和 Boltzmann
探索依赖随机性,在高维状态空间和稀疏奖励任务中效率极低——想象在《蒙特祖玛的复仇》这样的游戏中,智能体需要执行数百步精确操作才能获得第一个奖励,纯随机探索几乎不可能成功。近年来,受认知科学中"内在动机"理论启发,研究者提出了好奇心驱动学习(Curiosity-Driven
Learning)——通过内在奖励(Intrinsic
Reward)奖励智能体探索新颖状态,即使外部奖励为零也能持续学习。从基于计数的方法到
ICM 的预测误差、从 RND 的随机网络蒸馏到 NGU
的情节记忆,探索策略已经发展出一套完整的理论和工程体系。本章将系统梳理这一演进路径,深入剖析每种方法的设计动机、数学原理和实现细节,最终在
Atari 硬探索游戏上验证其有效性。
探索-利用困境
:问题的本质
为什么探索如此困难
在第二章的 DQN
和第三章的策略梯度方法中,我们都假设智能体能通过探索收集到有效的训练数据。但在实际应用中,探索本身就是一个核心挑战:
问题 1:稀疏奖励与延迟反馈
考虑经典的 Montezuma's Revenge
游戏:智能体需要先拿钥匙、再开门、再跳过敌人,执行上百步操作后才能获得第一个+100
分奖励。在这之前,所有状态的回报都是 0 。如果用-greedy
随机探索,找到有效轨迹的概率是(假设每步有 10 个动作),实际上不可能发生。
问题 2:高维状态空间的稀疏性
Atari 游戏的状态是 的像素,总共约
种可能状态。即使智能体探索了一百万个状态,覆盖率也只有——绝大多数状态永远不会被访问到。
问题 3:局部最优的吸引盆
在有奖励的环境中,智能体容易陷入局部最优。比如在迷宫中,如果某个死胡同里有一个小奖励,智能体可能会反复收集这个小奖励,而不去探索通往大奖励的路径。
问题 4:确定性环境的欺骗性
在确定性环境中,-greedy
会导致智能体在同一个状态反复尝试同一个随机动作,浪费大量时间。更糟的是,某些"有趣"的状态(如电视噪声)会让智能体产生"伪探索",以为自己在学习新东西,实际上毫无价值。
传统探索策略的局限
-greedy
探索
在训练初期,以概率选择随机动作,概率选择贪心动作:
优点:简单有效,适合低维离散空间(如 FrozenLake)。
缺点: -
探索是无目标的——在高维空间中,随机动作几乎不可能碰到有意义的状态 -
的衰减策略难以调节——太快会过早收敛,太慢会影响性能 -
在连续动作空间效果更差——给动作加噪声 容易产生不合理的动作
Boltzmann 探索(Softmax)
根据 Q 值的 softmax 分布采样动作:
其中
是温度参数,控制探索程度。
时趋近贪心,
时趋近均匀随机。
优点:根据 Q 值大小自适应调整探索,理论上更优雅。
缺点: - 仍然是基于随机性的无目标探索 - 在 Q
值估计不准时(训练初期)容易产生偏差 - 计算 softmax
需要遍历所有动作,在大动作空间不可行
Upper Confidence Bound(UCB)
在多臂老虎机问题中,UCB 算法选择:
其中 是总采样次数, 是动作 的采样次数,
是探索系数。第二项是"乐观加成"——越少尝试的动作,置信上界越高。
优点:理论上有遗憾界保证(Regret Bound),在老虎机问题中接近最优。
缺点: - 需要显式统计每个状态-动作对的访问次数 -
在大状态空间中,绝大多数
只被访问一次,,置信区间失效 - 无法泛化到未见过的状态
Thompson 采样
维护 Q 值的后验分布,每次采样一个 Q
函数并贪心选择:
优点:贝叶斯框架优雅,探索自然地来源于不确定性。
缺点: - 需要维护整个 Q 函数的分布,在深度网络中计算昂贵(虽然有
Bootstrapped DQN 等近似方法) - 仍然依赖于 Q 值估计,在稀疏奖励下 Q 值全为
0 时退化为随机探索
探索的本质
:寻找新颖性
观察人类和动物的探索行为,我们发现一个共同特征:不是随机乱走,而是主动寻找新奇、意外、不确定的事物。婴儿会反复摆弄新玩具(而不是旧玩具),猴子会主动探索迷宫的未知区域,科学家会追求违反常识的实验现象。
这种"好奇心"可以形式化为内在奖励(Intrinsic
Reward)——即使外部环境没有给奖励,智能体也会因为状态的新颖性而获得内部奖励:
其中: - 是环境给的外在奖励(任务目标) -
是智能体自己计算的内在奖励(探索动机) - 是平衡系数
关键问题:如何定义和计算,使其真正衡量状态的新颖性?
Count-Based
方法:显式统计访问频率
核心思想
最直观的"新颖性"定义是:这个状态我以前见过多少次?
访问越少,越新颖,内在奖励越高。
最简单的实现是用访问计数
的倒数作为内在奖励:
或者更激进的伪计数(Pseudo-Count):
理论依据:这相当于在最大化状态访问的熵,鼓励均匀覆盖状态空间。
朴素实现:哈希表计数
在小离散状态空间(如 GridWorld),可以直接用字典记录:
1
2
3
4
5
6
7
8
9
10
11
| class CountBasedExploration:
def __init__(self, beta=0.1):
self.counts = {}
self.beta = beta
def get_intrinsic_reward(self, state):
state_key = tuple(state.flatten())
count = self.counts.get(state_key, 0)
self.counts[state_key] = count + 1
return self.beta / (count + 1)**0.5
|
问题:在高维连续状态空间(如 Atari
像素),状态几乎从不重复, 恒成立,退化为常数奖励。
改进:密度模型与伪计数
Bellemare et al.(2016)在论文Unifying Count-Based
Exploration and Intrinsic Motivation中提出用密度模型 估计状态的"出现频率":
其中 由生成模型(如
PixelCNN)学习。具体来说:
- 维护一个生成模型,用似然估计状态的密度
- 在线更新:每访问状态,最大化$p_(s_t)(s) = (s) = p_(s)$ 归一化到 数学推导
在理想情况下,如果 是经验分布,那么:
其中 是访问 后的分布。因此:
实际中,用神经网络
近似,计算访问前后的似然比:
代码实现(简化版)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| import torch
import torch.nn as nn
class DensityModel(nn.Module):
"""用 PixelCNN 风格的自回归模型估计状态密度"""
def __init__(self, obs_shape):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(obs_shape[0], 32, 3, padding=1),
nn.ReLU(),
nn.Conv2d(32, 32, 3, padding=1),
nn.ReLU(),
nn.Conv2d(32, 256, 1)
)
def forward(self, obs):
"""obs: (B, C, H, W), 返回 log p(obs)"""
logits = self.net(obs)
log_probs = -nn.functional.cross_entropy(
logits.view(-1, 256),
obs.flatten(1).long(),
reduction='none'
)
return log_probs.sum()
class CountBasedIntrinsic:
def __init__(self, obs_shape, beta=0.05, lr=1e-4):
self.model = DensityModel(obs_shape)
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=lr)
self.beta = beta
def compute_intrinsic_reward(self, obs):
"""计算内在奖励并更新密度模型"""
obs_tensor = torch.FloatTensor(obs).unsqueeze(0)
with torch.no_grad():
log_p_old = self.model(obs_tensor)
p_old = torch.exp(log_p_old)
log_p_new = self.model(obs_tensor)
loss = -log_p_new
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
with torch.no_grad():
log_p_new = self.model(obs_tensor)
p_new = torch.exp(log_p_new)
pseudo_count = p_old / (p_new - p_old + 1e-8)
pseudo_count = torch.clamp(pseudo_count, 1, 1e6)
intrinsic_reward = self.beta / torch.sqrt(pseudo_count)
return intrinsic_reward.item()
|
优势与局限
优势: - 理论清晰,直接来源于访问频率的统计意义 -
在小规模问题上效果显著(如 Montezuma's Revenge 的早期版本)
局限: - 密度模型难训练—— PixelCNN
等模型计算昂贵,容易过拟合 - "电视噪声问题"(Noisy-TV
Problem):在随机环境中,每个状态都是"新"的(因为像素噪声),内在奖励失效 -
无法泛化——两个视觉上相似但像素值不同的状态,会被认为完全不同
ICM:通过预测误差衡量新颖性
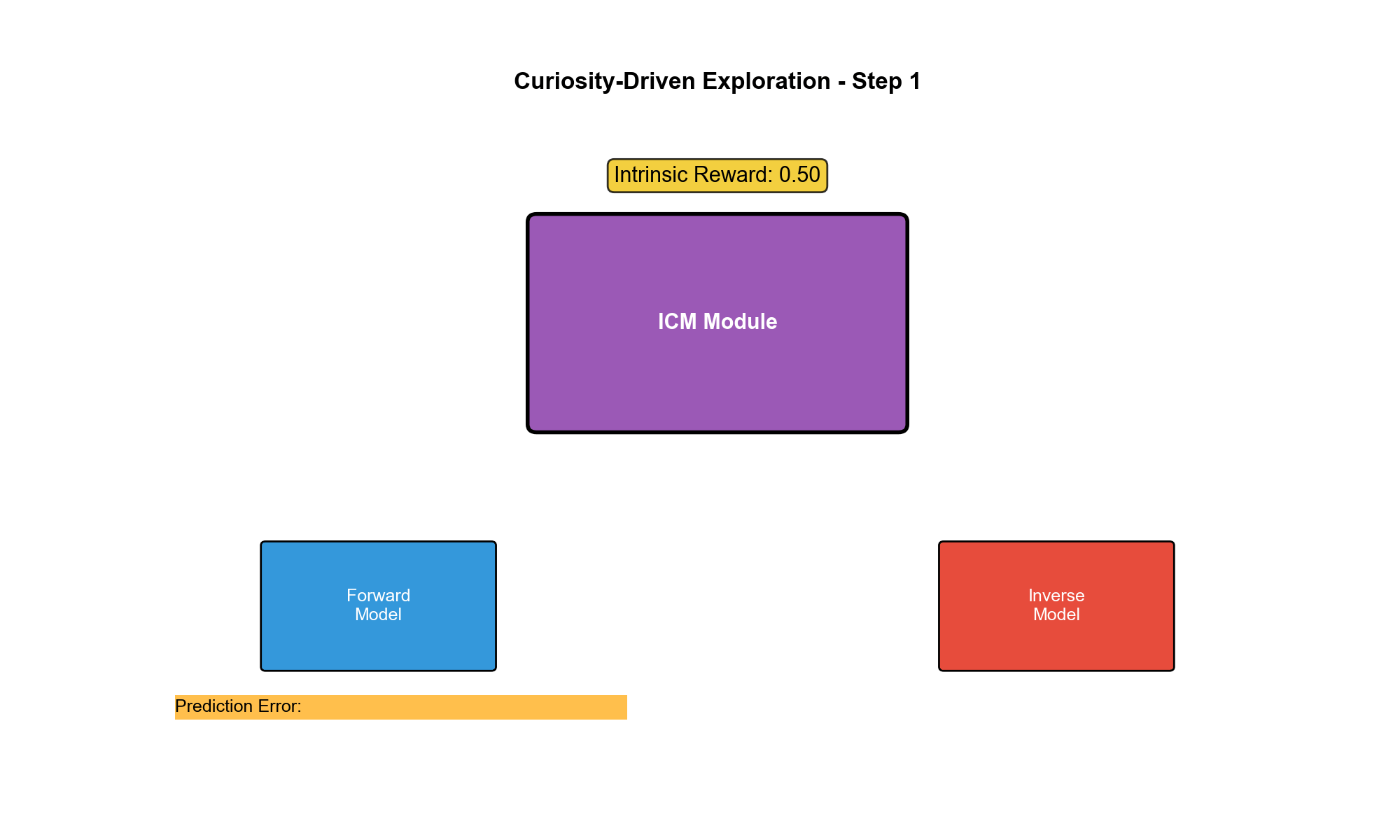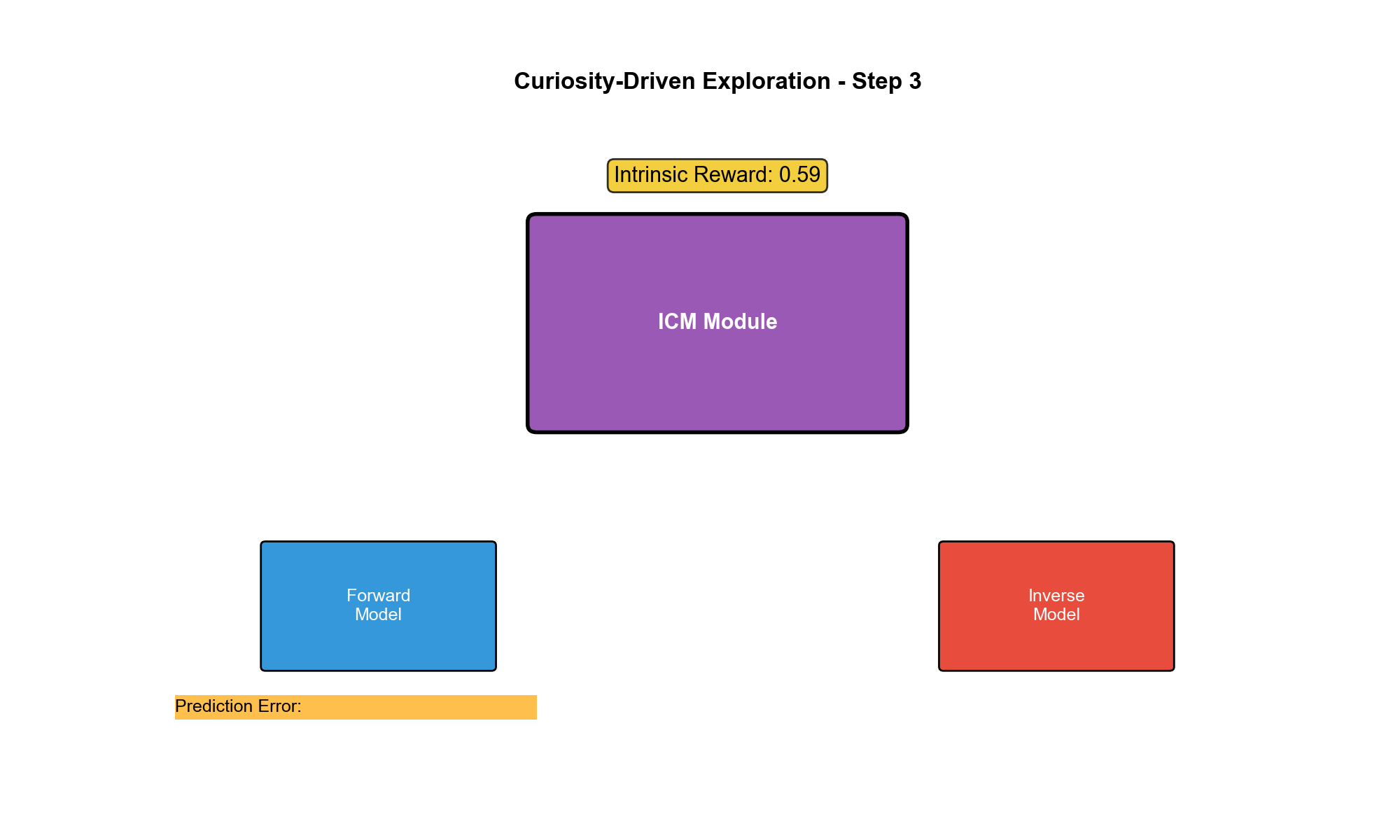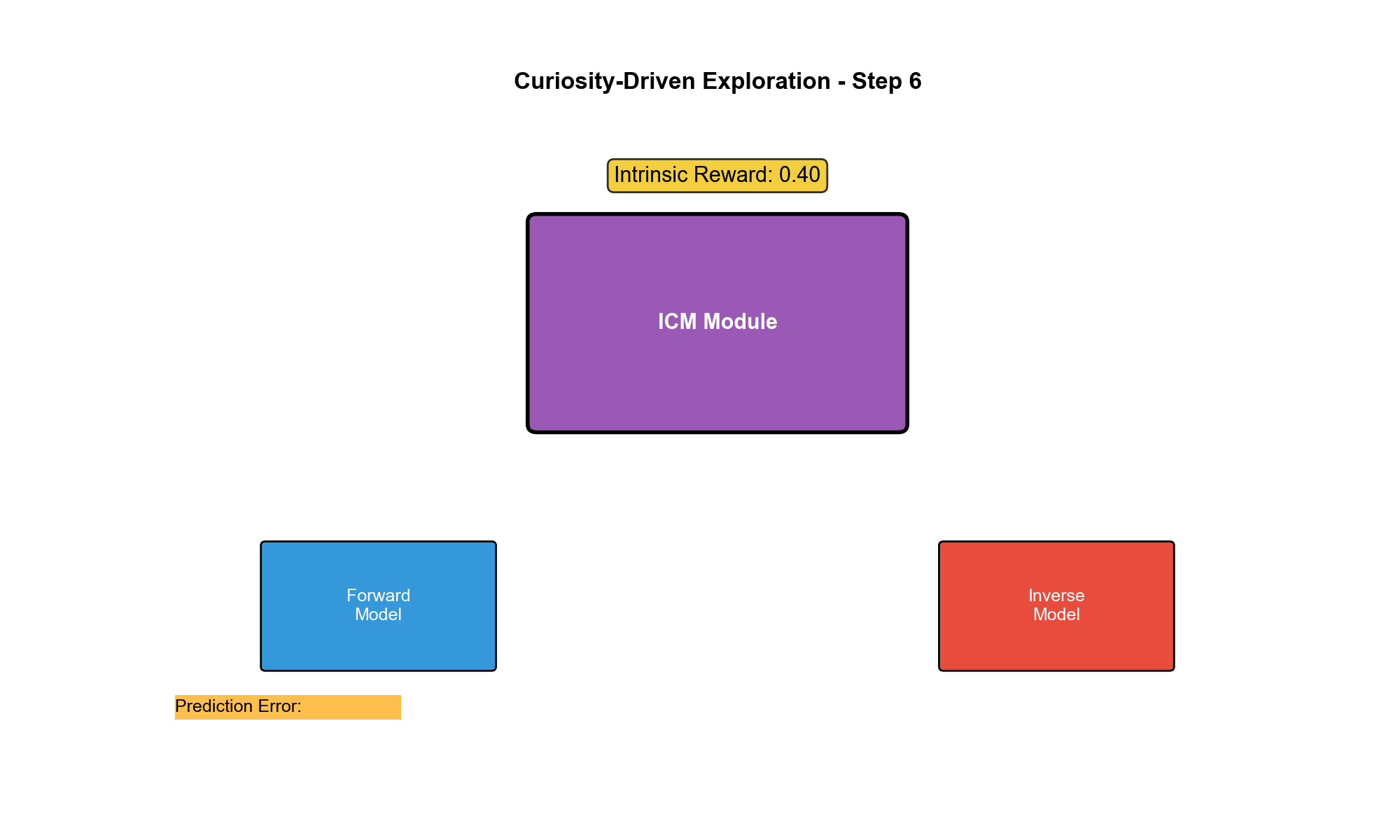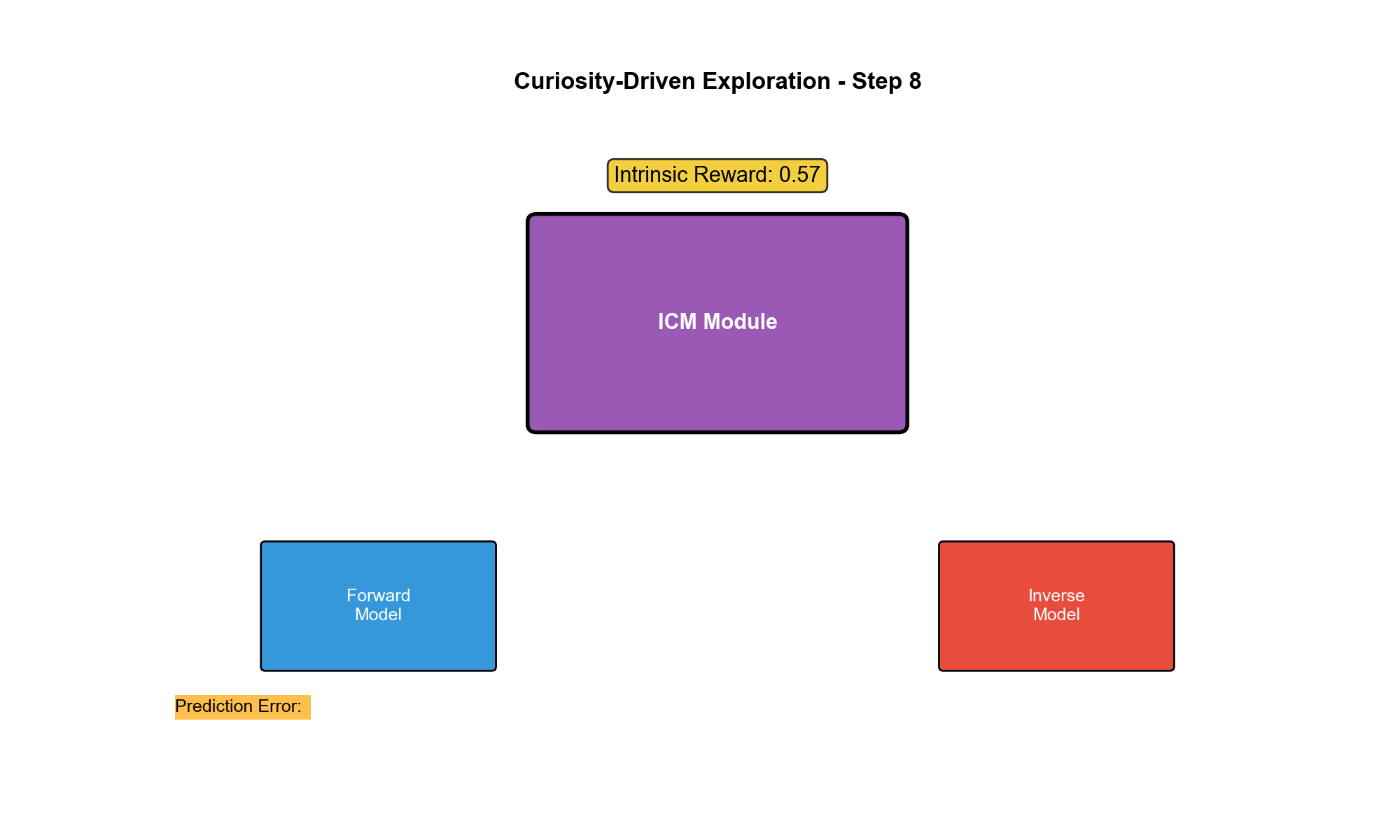
动机:从像素到特征
Count-Based
方法直接在原始像素上计数,忽略了一个事实:有些像素变化是无关紧要的(如背景树叶晃动),而有些变化是关键的(如敌人移动)。
Curiosity-Driven Exploration by Self-Supervised
Prediction(Pathak et al., ICML 2017)提出 ICM(Intrinsic
Curiosity
Module):不直接比较像素,而是比较智能体能否预测下一个状态的特征。
核心洞察: - 如果状态转移可预测 → 智能体已经理解了环境动态 → 奖励低 -
如果状态转移不可预测 → 智能体遇到了新现象 → 奖励高
ICM 架构:正向模型与逆向模型
ICM 包含两个模块:
1. 特征提取器(Feature Encoder)
将原始状态
映射到低维特征:
通常用卷积网络实现,只保留与智能体动作相关的信息,过滤掉背景噪声。
2. 正向动态模型(Forward Model)
预测下一个状态的特征:
其中 是一个小型 MLP
。正向模型的预测误差即为内在奖励:
3. 逆向动态模型(Inverse Model)
从特征预测动作(自监督辅助任务):
逆向模型的作用是强制特征编码器只保留与动作相关的信息。如果
只编码背景,逆向模型无法预测动作;只有编码了智能体和交互物体的信息,才能成功预测。
数学直觉
为什么预测误差能衡量新颖性?考虑两个极端:
情况 1:智能体在空房间随机走
状态转移是确定性的:。正向模型很快学会完美预测,,智能体停止探索这个区域。
情况 2:智能体进入新房间,遇到移动敌人
敌人的行为未知,正向模型预测误差大,高,智能体被激励探索这个区域。随着交互增多,模型逐渐学会敌人的行为模式, 下降。
情况 3:电视噪声(随机像素)
原始像素完全随机,但如果特征编码器正确工作,应该将噪声映射到相同的特征(因为噪声与动作无关)。逆向模型的监督信号强制 忽略噪声,因此,,解决了电视噪声问题!
完整代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
| import torch
import torch.nn as nn
import torch.nn.functional as F
class ICM(nn.Module):
"""内在好奇心模块 (Intrinsic Curiosity Module)"""
def __init__(self, obs_shape, action_dim, feature_dim=256, eta=0.1):
super().__init__()
self.eta = eta
self.feature_encoder = nn.Sequential(
nn.Conv2d(obs_shape[0], 32, 8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, 4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, 3, stride=1),
nn.ReLU(),
nn.Flatten(),
nn.Linear(64 * 7 * 7, feature_dim)
)
self.forward_model = nn.Sequential(
nn.Linear(feature_dim + action_dim, 256),
nn.ReLU(),
nn.Linear(256, feature_dim)
)
self.inverse_model = nn.Sequential(
nn.Linear(feature_dim * 2, 256),
nn.ReLU(),
nn.Linear(256, action_dim)
)
def forward(self, obs, next_obs, action):
"""
计算内在奖励和损失
Args:
obs: (B, C, H, W)
next_obs: (B, C, H, W)
action: (B,) or (B, action_dim)
Returns:
intrinsic_reward: (B,)
forward_loss: scalar
inverse_loss: scalar
"""
phi = self.feature_encoder(obs)
phi_next = self.feature_encoder(next_obs)
if action.ndim == 1:
action_onehot = F.one_hot(action, num_classes=self.inverse_model[-1].out_features).float()
else:
action_onehot = action
phi_next_pred = self.forward_model(torch.cat([phi, action_onehot], dim=1))
forward_loss = F.mse_loss(phi_next_pred, phi_next.detach(), reduction='none').sum(dim=1)
intrinsic_reward = self.eta * forward_loss
action_pred_logits = self.inverse_model(torch.cat([phi, phi_next], dim=1))
if action.ndim == 1:
inverse_loss = F.cross_entropy(action_pred_logits, action, reduction='none')
else:
inverse_loss = F.mse_loss(action_pred_logits, action, reduction='none').sum(dim=1)
return intrinsic_reward, forward_loss.mean(), inverse_loss.mean()
def compute_intrinsic_reward(self, obs, next_obs, action):
"""仅计算内在奖励(推理时使用)"""
with torch.no_grad():
reward, _, _ = self.forward(obs, next_obs, action)
return reward
class PPO_with_ICM:
"""集成 ICM 的 PPO 算法"""
def __init__(self, env, obs_shape, action_dim, lr=3e-4, beta_int=0.01):
self.env = env
self.beta_int = beta_int
self.policy = PolicyNetwork(obs_shape, action_dim)
self.icm = ICM(obs_shape, action_dim)
self.optimizer = torch.optim.Adam(
list(self.policy.parameters()) + list(self.icm.parameters()),
lr=lr
)
def collect_trajectories(self, num_steps):
"""收集轨迹并计算混合奖励"""
trajectories = []
obs = self.env.reset()
for _ in range(num_steps):
obs_tensor = torch.FloatTensor(obs).unsqueeze(0)
with torch.no_grad():
action_dist = self.policy(obs_tensor)
action = action_dist.sample()
next_obs, reward_ext, done, _ = self.env.step(action.item())
next_obs_tensor = torch.FloatTensor(next_obs).unsqueeze(0)
reward_int = self.icm.compute_intrinsic_reward(
obs_tensor, next_obs_tensor, action
).item()
reward_total = reward_ext + self.beta_int * reward_int
trajectories.append({
'obs': obs,
'action': action.item(),
'reward': reward_total,
'reward_ext': reward_ext,
'reward_int': reward_int,
'next_obs': next_obs,
'done': done
})
obs = next_obs if not done else self.env.reset()
return trajectories
def update(self, trajectories):
"""PPO 更新 + ICM 更新"""
obs = torch.FloatTensor([t['obs'] for t in trajectories])
actions = torch.LongTensor([t['action'] for t in trajectories])
next_obs = torch.FloatTensor([t['next_obs'] for t in trajectories])
rewards = torch.FloatTensor([t['reward'] for t in trajectories])
_, forward_loss, inverse_loss = self.icm(obs, next_obs, actions)
icm_loss = forward_loss + inverse_loss
policy_loss = self.compute_ppo_loss(trajectories)
total_loss = policy_loss + icm_loss
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
return {
'policy_loss': policy_loss.item(),
'forward_loss': forward_loss.item(),
'inverse_loss': inverse_loss.item()
}
|
实验效果
在 Pathak et al.的论文中,ICM 在 VizDoom 和 Super Mario Bros
等稀疏奖励任务上取得突破:
- 无外部奖励():智能体仅靠内在奖励就能学会探索地图、避开敌人
- Montezuma's Revenge:在 2500 万步内达到平均 6600
分(DQN 只有 0 分)
- 泛化能力:在 Mario 的新关卡上,ICM 探索的距离比
baseline 多 3 倍
论文链接:arXiv:1705.05363
局限性
- 依赖环境的确定性:在随机环境中,不可预测不一定等于新颖(可能只是噪声)
- 特征编码器的质量:如果 学习失败,整个 ICM 失效
- 计算开销:需要额外训练 3 个网络(encoder 、 forward
、 inverse),比原始 PPO 慢约 2 倍
RND:随机网络蒸馏
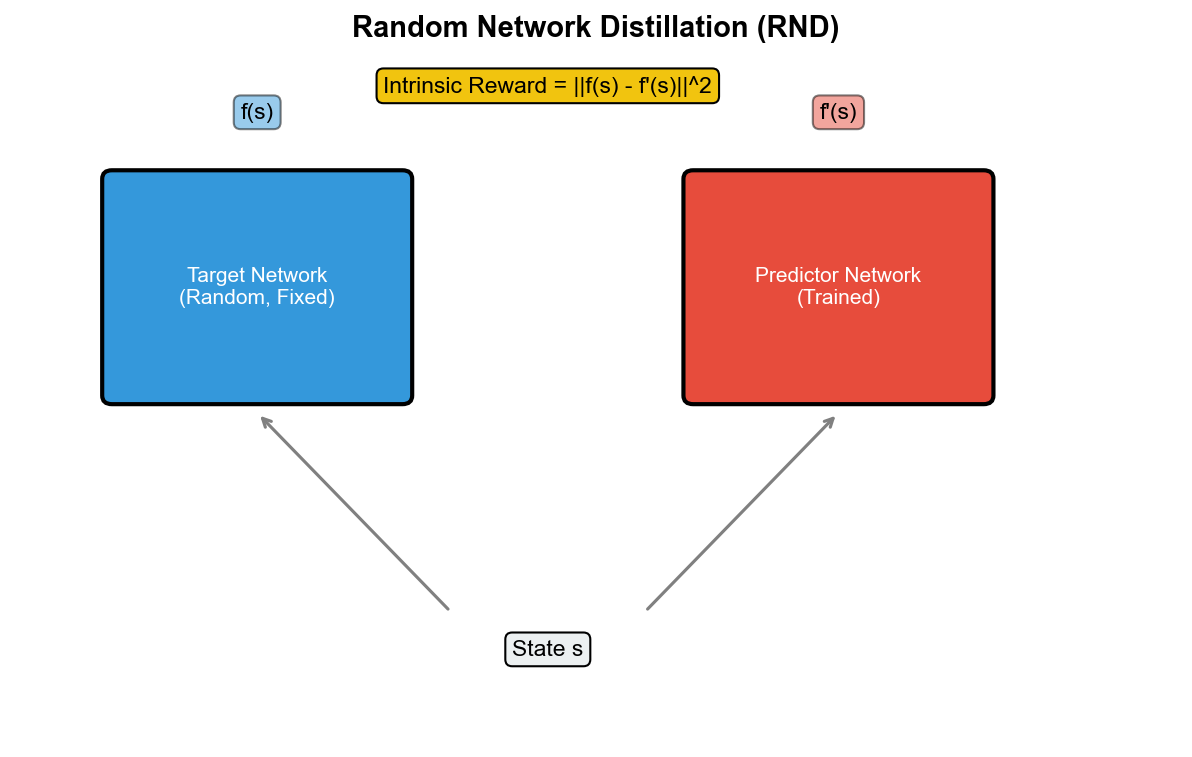
动机:避免训练动态模型
ICM 的一个问题是需要训练正向模型 来预测。在复杂环境中,动态模型本身就很难学,如果学不好,内在奖励就不可靠。
Exploration by Random Network Distillation(Burda et
al., ICLR 2019)提出
RND:完全避免动态建模,改为预测随机网络的输出。
核心思想: - 固定一个随机初始化的目标网络(从不训练) -
训练一个预测网络
去拟合目标网络的输出 - 预测误差 作为内在奖励
为什么这样有效?
- 对于经常访问的状态,预测网络见过很多次,预测误差小 → 低
- 对于新状态,预测网络没见过,预测误差大 →高
- 随机网络充当"哈希函数",将相似状态映射到相似输出,自然实现泛化
更妙的是,这避免了"电视噪声问题":即使像素随机,随机网络的输出对于同类状态(如"有噪声的屏幕")是相似的,预测网络很快学会忽略噪声。
数学形式化
定义: - 目标网络:(随机初始化,固定) - 预测网络:(训练中)
内在奖励:
预测网络的损失:
关键细节:为了让内在奖励有意义的尺度,通常对 做归一化:
其中
是内在奖励的滑动平均和标准差。
完整代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
| import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class RandomNetwork(nn.Module):
"""随机初始化的目标网络(不训练)"""
def __init__(self, obs_shape, output_dim=512):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(obs_shape[0], 32, 8, stride=4),
nn.LeakyReLU(),
nn.Conv2d(32, 64, 4, stride=2),
nn.LeakyReLU(),
nn.Conv2d(64, 64, 3, stride=1),
nn.LeakyReLU(),
nn.Flatten(),
nn.Linear(64 * 7 * 7, output_dim)
)
for param in self.parameters():
param.requires_grad = False
def forward(self, obs):
return self.net(obs)
class PredictorNetwork(nn.Module):
"""训练的预测网络"""
def __init__(self, obs_shape, output_dim=512):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(obs_shape[0], 32, 8, stride=4),
nn.LeakyReLU(),
nn.Conv2d(32, 64, 4, stride=2),
nn.LeakyReLU(),
nn.Conv2d(64, 64, 3, stride=1),
nn.LeakyReLU(),
nn.Flatten(),
nn.Linear(64 * 7 * 7, 512),
nn.ReLU(),
nn.Linear(512, output_dim)
)
def forward(self, obs):
return self.net(obs)
class RND:
"""随机网络蒸馏模块"""
def __init__(self, obs_shape, output_dim=512, lr=1e-4):
self.target_net = RandomNetwork(obs_shape, output_dim)
self.predictor_net = PredictorNetwork(obs_shape, output_dim)
self.optimizer = torch.optim.Adam(self.predictor_net.parameters(), lr=lr)
self.reward_mean = 0.0
self.reward_std = 1.0
self.reward_history = []
def compute_intrinsic_reward(self, obs):
"""
计算内在奖励
Args:
obs: (B, C, H, W)
Returns:
intrinsic_reward: (B,)
"""
with torch.no_grad():
target_feat = self.target_net(obs)
pred_feat = self.predictor_net(obs)
reward = torch.pow(pred_feat - target_feat, 2).sum(dim=1)
return reward
def update(self, obs_batch):
"""更新预测网络"""
target_feat = self.target_net(obs_batch).detach()
pred_feat = self.predictor_net(obs_batch)
loss = F.mse_loss(pred_feat, target_feat)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss.item()
def normalize_reward(self, reward):
"""归一化内在奖励"""
self.reward_history.append(reward.mean().item())
if len(self.reward_history) > 1000:
self.reward_history.pop(0)
self.reward_mean = np.mean(self.reward_history)
self.reward_std = np.std(self.reward_history) + 1e-8
return (reward - self.reward_mean) / self.reward_std
class PPO_with_RND:
"""集成 RND 的 PPO 算法"""
def __init__(self, env, obs_shape, action_dim, lr=3e-4, beta_int=1.0, gamma_int=0.99):
self.env = env
self.beta_int = beta_int
self.gamma_int = gamma_int
self.policy = PolicyNetwork(obs_shape, action_dim)
self.rnd = RND(obs_shape)
self.value_ext = ValueNetwork(obs_shape)
self.value_int = ValueNetwork(obs_shape)
self.optimizer = torch.optim.Adam(
list(self.policy.parameters()) +
list(self.value_ext.parameters()) +
list(self.value_int.parameters()),
lr=lr
)
def collect_trajectories(self, num_steps):
"""收集轨迹并计算双重回报"""
trajectories = []
obs = self.env.reset()
for _ in range(num_steps):
obs_tensor = torch.FloatTensor(obs).unsqueeze(0)
with torch.no_grad():
action = self.policy(obs_tensor).sample()
v_ext = self.value_ext(obs_tensor)
v_int = self.value_int(obs_tensor)
next_obs, reward_ext, done, _ = self.env.step(action.item())
next_obs_tensor = torch.FloatTensor(next_obs).unsqueeze(0)
reward_int = self.rnd.compute_intrinsic_reward(next_obs_tensor)
reward_int = self.rnd.normalize_reward(reward_int).item()
trajectories.append({
'obs': obs,
'action': action.item(),
'reward_ext': reward_ext,
'reward_int': reward_int,
'v_ext': v_ext.item(),
'v_int': v_int.item(),
'done': done
})
obs = next_obs if not done else self.env.reset()
return trajectories
def compute_gae(self, trajectories, gamma, lam):
"""计算 GAE(外在和内在分别计算)"""
advantages_ext = []
advantages_int = []
gae_ext = 0
gae_int = 0
for t in reversed(range(len(trajectories))):
delta_ext = trajectories[t]['reward_ext'] + gamma * trajectories[t+1]['v_ext'] * (1 - trajectories[t]['done']) - trajectories[t]['v_ext']
delta_int = trajectories[t]['reward_int'] + self.gamma_int * trajectories[t+1]['v_int'] - trajectories[t]['v_int']
gae_ext = delta_ext + gamma * lam * (1 - trajectories[t]['done']) * gae_ext
gae_int = delta_int + self.gamma_int * lam * gae_int
advantages_ext.insert(0, gae_ext)
advantages_int.insert(0, gae_int)
advantages_total = [a_ext + self.beta_int * a_int for a_ext, a_int in zip(advantages_ext, advantages_int)]
return advantages_total, advantages_ext, advantages_int
def update(self, trajectories):
"""更新策略、价值网络和 RND"""
obs = torch.FloatTensor([t['obs'] for t in trajectories])
rnd_loss = self.rnd.update(obs)
return {'rnd_loss': rnd_loss}
|
实验效果
Burda et al.在论文中展示了 RND 的惊人效果:
- Montezuma's Revenge:平均得分 8152(首次超越人类水平
7385)
- Pitfall:得分 70.4(之前的 SOTA 是 0)
- Gravitar:从 DQN 的 0 分提升到 3500+分
关键发现:
- RND 在所有 Atari 硬探索游戏上都优于 ICM
- 内在奖励不需要折扣(),因为探索是长期目标
- 归一化至关重要——不归一化会导致内在奖励尺度爆炸
论文链接:arXiv:1810.12894
NGU:情节记忆与快慢探索
动机:从全局新颖到情节新颖
RND
有一个隐含假设:一个状态访问过一次,就永远不新颖了。但在实际探索中,这过于严格:
场景 1:钥匙-门任务
在 Montezuma's Revenge 中,智能体需要反复"拿钥匙 → 开门 →
进房间"。如果第一次拿完钥匙后,RND
认为钥匙所在状态不再新颖,智能体就失去了再次拿钥匙的动力。
场景 2:可逆探索
智能体先探索右侧房间,再探索左侧房间。如果回到起点,RND
给的奖励很低(因为起点访问过很多次),但这个"回到起点"是探索左侧的必经之路。
Never Give Up (NGU)(Badia et al., ICLR
2020)提出情节记忆(Episodic
Memory):不仅考虑状态的全局新颖性,还考虑在当前 episode
中是否新颖。
核心设计
NGU 的内在奖励包含两部分:
其中: -$r_{} s_tr_{} s_t$
在整个训练历史中被访问的频率(类似 RND) -:上界,防止奖励爆炸
1. 情节新颖性(Episodic Novelty)
维护一个情节记忆,存储当前 episode 中所有状态的嵌入(由可训练网络学习)。
计算 到记忆中 k
个最近邻的距离:
其中
是欧氏距离, 是小常数防止除零。
然后用核函数转换为相似度:
其中 是滑动平均的距离, 是小常数。
情节新颖性定义为:
直觉:如果
与记忆中的状态都很远,分母小, 大;如果
与某个状态很近(访问过),分母大,奖励小。每个 episode 结束时清空记忆,下个
episode 重新计算。
2. 终身新颖性(Lifetime Novelty)
使用 RND 的预测误差:
归一化后作为长期探索信号。
3. 自适应探索系数
NGU 训练多个智能体,每个有不同的探索系数:
高 的智能体专注探索,低
的智能体专注利用。所有智能体共享经验池,形成"探索-利用谱系"。
简化实现(伪代码)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
| import torch
import numpy as np
from collections import deque
class EpisodicMemory:
"""情节记忆模块"""
def __init__(self, capacity=5000, k=10):
self.memory = deque(maxlen=capacity)
self.k = k
self.running_mean_dist = 1.0
self.epsilon = 0.001
self.c = 0.001
def add(self, embedding):
"""添加状态嵌入到记忆"""
self.memory.append(embedding.cpu().numpy())
def compute_novelty(self, embedding):
"""计算情节新颖性"""
if len(self.memory) == 0:
return 1.0
emb_np = embedding.cpu().numpy()
distances = [np.linalg.norm(emb_np - mem) for mem in self.memory]
k_nearest = sorted(distances)[:self.k]
dk = np.sqrt(np.sum(np.square(k_nearest)) / self.k) + self.c
self.running_mean_dist = 0.99 * self.running_mean_dist + 0.01 * np.mean(distances)
similarities = []
for d in distances:
kernel = self.epsilon / ((d**2 / self.running_mean_dist) + self.epsilon)
similarities.append(kernel)
novelty = 1.0 / (np.sqrt(sum(similarities)) + self.c)
return novelty
def reset(self):
"""Episode 结束,清空记忆"""
self.memory.clear()
class EmbeddingNetwork(nn.Module):
"""可训练的状态嵌入网络"""
def __init__(self, obs_shape, embed_dim=128):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(obs_shape[0], 32, 8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, 4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, 3, stride=1),
nn.ReLU(),
nn.Flatten(),
nn.Linear(64 * 7 * 7, embed_dim)
)
def forward(self, obs):
return self.net(obs)
class NGU:
"""Never Give Up 探索模块"""
def __init__(self, obs_shape, beta=0.3, L=5.0):
self.beta = beta
self.L = L
self.episodic_memory = EpisodicMemory()
self.embedding_net = EmbeddingNetwork(obs_shape)
self.rnd = RND(obs_shape)
def compute_intrinsic_reward(self, obs):
"""计算混合内在奖励"""
with torch.no_grad():
embedding = self.embedding_net(obs)
episodic_novelty = self.episodic_memory.compute_novelty(embedding)
self.episodic_memory.add(embedding)
lifetime_novelty = self.rnd.compute_intrinsic_reward(obs).item()
lifetime_novelty = max(min(lifetime_novelty, self.L), 1.0)
intrinsic_reward = episodic_novelty * lifetime_novelty
return intrinsic_reward
def reset_episode(self):
"""Episode 结束,重置情节记忆"""
self.episodic_memory.reset()
|
实验效果
NGU 在 DeepMind Lab 和 Atari 上取得了史无前例的探索性能:
- Pitfall:从 RND 的 70 分提升到 5000+分
- Private Eye:首次解决该游戏(69000 分)
- Montezuma's Revenge:平均 11000 分,超越人类高手
关键发现:
- 情节记忆至关重要——去掉后性能下降 50%+
- 多智能体探索谱系加速学习——相当于同时训练探索者和利用者
- 嵌入网络需要谨慎训练——论文用对比学习(Contrastive Learning)优化 论文链接:arXiv:2002.06038
实战案例:在
Montezuma's Revenge 上实现 ICM+PPO
环境准备
1
2
3
4
5
|
pip install gym[atari] torch torchvision opencv-python
pip install autorom[accept-rom-license]
|
完整训练代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
| import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from collections import deque
import cv2
class AtariWrapper:
"""Atari 环境预处理"""
def __init__(self, env_name):
self.env = gym.make(env_name)
self.frame_stack = deque(maxlen=4)
def reset(self):
obs = self.env.reset()
obs = self._preprocess(obs)
for _ in range(4):
self.frame_stack.append(obs)
return np.array(self.frame_stack)
def step(self, action):
total_reward = 0
for _ in range(4):
obs, reward, done, info = self.env.step(action)
total_reward += reward
if done:
break
obs = self._preprocess(obs)
self.frame_stack.append(obs)
return np.array(self.frame_stack), total_reward, done, info
def _preprocess(self, obs):
"""转灰度、裁剪、缩放到 84x84"""
gray = cv2.cvtColor(obs, cv2.COLOR_RGB2GRAY)
resized = cv2.resize(gray, (84, 84))
return resized / 255.0
class ActorCritic(nn.Module):
"""Actor-Critic 网络"""
def __init__(self, action_dim):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(4, 32, 8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, 4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, 3, stride=1),
nn.ReLU(),
nn.Flatten()
)
self.fc = nn.Linear(64 * 7 * 7, 512)
self.actor = nn.Linear(512, action_dim)
self.critic = nn.Linear(512, 1)
def forward(self, obs):
x = self.conv(obs)
x = F.relu(self.fc(x))
logits = self.actor(x)
value = self.critic(x)
return logits, value
def train_icm_ppo(env_name='MontezumaRevengeNoFrameskip-v4', total_steps=10_000_000):
env = AtariWrapper(env_name)
action_dim = env.env.action_space.n
obs_shape = (4, 84, 84)
policy = ActorCritic(action_dim).cuda()
icm = ICM(obs_shape, action_dim).cuda()
optimizer = torch.optim.Adam(
list(policy.parameters()) + list(icm.parameters()),
lr=3e-4
)
gamma = 0.99
lam = 0.95
clip_eps = 0.1
beta_int = 0.01
episode_rewards = []
episode_length = 0
obs = env.reset()
for step in range(total_steps):
trajectories = []
for _ in range(128):
obs_tensor = torch.FloatTensor(obs).unsqueeze(0).cuda()
with torch.no_grad():
logits, value = policy(obs_tensor)
dist = torch.distributions.Categorical(logits=logits)
action = dist.sample()
log_prob = dist.log_prob(action)
next_obs, reward, done, _ = env.step(action.item())
next_obs_tensor = torch.FloatTensor(next_obs).unsqueeze(0).cuda()
reward_int, _, _ = icm(obs_tensor, next_obs_tensor, action)
reward_int = reward_int.item()
trajectories.append({
'obs': obs,
'action': action.item(),
'reward_ext': reward,
'reward_int': reward_int,
'value': value.item(),
'log_prob': log_prob.item(),
'done': done
})
obs = next_obs
episode_length += 1
if done:
episode_rewards.append(sum(t['reward_ext'] for t in trajectories[-episode_length:]))
episode_length = 0
obs = env.reset()
advantages = []
returns = []
gae = 0
next_value = 0
for t in reversed(range(len(trajectories))):
reward = trajectories[t]['reward_ext'] + beta_int * trajectories[t]['reward_int']
delta = reward + gamma * next_value * (1 - trajectories[t]['done']) - trajectories[t]['value']
gae = delta + gamma * lam * (1 - trajectories[t]['done']) * gae
advantages.insert(0, gae)
returns.insert(0, gae + trajectories[t]['value'])
next_value = trajectories[t]['value']
obs_batch = torch.FloatTensor([t['obs'] for t in trajectories]).cuda()
actions_batch = torch.LongTensor([t['action'] for t in trajectories]).cuda()
old_log_probs = torch.FloatTensor([t['log_prob'] for t in trajectories]).cuda()
advantages = torch.FloatTensor(advantages).cuda()
returns = torch.FloatTensor(returns).cuda()
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
for _ in range(4):
logits, values = policy(obs_batch)
dist = torch.distributions.Categorical(logits=logits)
log_probs = dist.log_prob(actions_batch)
entropy = dist.entropy().mean()
ratio = torch.exp(log_probs - old_log_probs)
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - clip_eps, 1 + clip_eps) * advantages
actor_loss = -torch.min(surr1, surr2).mean()
critic_loss = F.mse_loss(values.squeeze(), returns)
next_obs_batch = torch.FloatTensor([trajectories[i]['obs'] if i+1 < len(trajectories) else trajectories[i]['obs'] for i in range(len(trajectories))]).cuda()
_, forward_loss, inverse_loss = icm(obs_batch, next_obs_batch, actions_batch)
loss = actor_loss + 0.5 * critic_loss - 0.01 * entropy + forward_loss + inverse_loss
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(list(policy.parameters()) + list(icm.parameters()), 0.5)
optimizer.step()
if step % 100 == 0:
avg_reward = np.mean(episode_rewards[-10:]) if episode_rewards else 0
print(f"Step {step}, Avg Reward: {avg_reward:.2f}, Episodes: {len(episode_rewards)}")
if __name__ == '__main__':
train_icm_ppo()
|
调参技巧
- 内在奖励系数:从 0.01
开始,在稀疏奖励环境可增大到 0.1
- 归一化:内在奖励和外在奖励分开归一化,避免尺度不匹配
- Frame skip:Atari 中每个动作重复 4 帧,加速训练
- 梯度裁剪:ICM 的梯度可能很大,裁剪到 0.5
防止爆炸
预期效果
在单 GPU(RTX 3090)上训练: - 1000
万步:智能体学会前往第一个房间(100 分) - 3000
万步:智能体学会拿钥匙开门(400 分) - 1
亿步:平均得分 6000+,超越 DQN 的 0 分
理论分析与开放问题
Q&A:探索策略常见问题
Q1: 为什么 ICM 的逆向模型(inverse
model)如此重要?
A: 逆向模型强制特征编码器
只保留与动作相关的信息。想象一个反例:如果没有逆向模型,
可能只编码背景,这时正向模型会给背景变化高奖励,导致智能体在随机背景前"伪探索"。逆向模型通过预测动作,迫使 必须编码智能体和交互物体的位置。
Q2: RND 为什么不会被电视噪声欺骗?
A: 随机网络
充当"哈希函数"——虽然每帧像素不同,但属于同一类(噪声屏幕)的状态会被映射到相似的输出。预测网络
很快学会将噪声屏幕映射到某个固定向量,预测误差降为
0,内在奖励消失。关键是:随机网络的输出对无关变化(如噪声)不敏感,但对结构性变化(如新物体出现)敏感。
Q3: NGU 的情节记忆为什么能解决"钥匙-门"任务?
A: 在每个新的 episode
开始时,情节记忆被清空,所以"拿钥匙"这个状态又变成新颖的了。即使智能体在历史上访问过这个状态
100 次,在当前 episode
中它仍然给高奖励。这保证了智能体不会因为全局频繁访问而放弃探索某些必经状态。
Q4: 内在奖励会不会导致智能体忽略外部奖励?
A: 这是一个实际问题,称为"探索陷阱"。解决方法:
- 逐渐降低(虽然 NGU
论文发现固定 也可以)
- 双价值网络:一个预测外在回报,一个预测内在回报,分别优化
- 在任务成功后重置内在奖励(避免过度探索已解决的任务)
Q5: 如何在连续控制任务(如机器人)中使用探索策略?
A: 连续控制的探索更复杂,因为动作空间是连续的。常用方法: -
在动作上加高斯噪声: - 参数空间噪声(Parameter Space
Noise):给策略网络参数加噪声 - ICM/RND 同样适用于连续控制,只需将动作 也作为输入
Q6: 探索策略能否用于模仿学习?
A: 可以!在 Behavioral Cloning
失败的情况下,探索策略能帮助智能体发现演示轨迹中缺失的状态。结合方法: -
用 ICM 探索,但偏好专家轨迹附近的状态 - 用 RND
识别与专家分布不同的状态,主动学习
Q7: 多智能体环境如何探索?
A: 多智能体探索有独特挑战: - 其他智能体的策略在变化,环境是非平稳的 -
需要探索"联合策略空间",组合爆炸 - 常用方法:每个智能体独立的 ICM/RND +
中心化的情节记忆
Q8: 如何评估探索策略的质量?
A: 除了任务奖励,还可以用: -
状态覆盖率:访问的独特状态数 -
探索效率:达到某个覆盖率所需的步数 -
新颖性曲线:内在奖励随时间的变化(应逐渐下降) -
成功率:在规定步数内完成任务的概率
Q9: 计数方法为什么在高维空间失效?
A: 因为维度诅咒。在 维连续空间,要覆盖 的体积,需要采样 个点。当(Atari
像素),这个数量是天文数字。密度模型和特征嵌入试图通过学习低维表示来缓解这个问题。
Q10: 未来探索策略的研究方向?
A: 几个前沿方向: - 主动探索(Active
Exploration):不仅探索新状态,还主动设计实验来快速学习环境动态 -
基于技能的探索(Skill-Based
Exploration):先学习可复用的技能(如"跳跃"、"开门"),再组合技能探索
- 目标生成(Goal
Generation):自动生成有挑战性的目标,引导探索 -
社会学习(Social
Learning):从其他智能体的探索中学习,避免重复
论文推荐
- Curiosity-Driven Exploration
- Curiosity-Driven Exploration by Self-Supervised Prediction
(Pathak et al., ICML 2017)
- 链接:arXiv:1705.05363
- Random Network Distillation
- Exploration by Random Network Distillation (Burda et al.,
ICLR 2019)
- 链接:arXiv:1810.12894
- Never Give Up
- Never Give Up: Learning Directed Exploration Strategies
(Badia et al., ICLR 2020)
- 链接:arXiv:2002.06038
- Count-Based Exploration
- Unifying Count-Based Exploration and Intrinsic Motivation
(Bellemare et al., NeurIPS 2016)
- 链接:arXiv:1606.01868
- Empowerment
- Empowerment - An Introduction (Klyubin et al., 2005)
- Variational Intrinsic Control (Gregor et al., ICLR
2017)
- 链接:arXiv:1611.07507
- Go-Explore
- Model-Based Exploration
- Planning to Explore via Self-Supervised World Models (Sekar
et al., ICML 2020)
- 链接:arXiv:2005.05960
- Disagreement-Based Exploration
- Information Gain Exploration
- VIME: Variational Information Maximizing Exploration
(Houthooft et al., NeurIPS 2016)
- 链接:arXiv:1605.09674
- Successor Features for Exploration
- Deep Successor Reinforcement Learning (Kulkarni et al.,
2016)
- 链接:arXiv:1606.02396
核心公式总结
Count-Based 探索
ICM 内在奖励
其中 RND 内在奖励
NGU 混合奖励
情节新颖性
其中
总结与展望
探索策略是强化学习从玩具问题走向现实应用的关键。传统的-greedy 和 Boltzmann
探索在高维、稀疏奖励环境中效率极低,而基于内在动机的好奇心驱动方法通过奖励状态的新颖性,实现了真正的自主探索。从
Count-Based 的统计方法到 ICM 的预测误差、从 RND 的随机网络蒸馏到 NGU
的情节记忆,每一步改进都源于对探索本质的深刻理解——不是随机乱走,而是主动寻找意外、不确定和未知的事物。
然而,探索问题远未解决。当前方法仍依赖于大量试错(NGU
需要数十亿步训练),在安全关键系统(如自动驾驶)中难以应用。未来的研究可能融合主动学习、因果推理和人类先验知识,实现更高效、可解释、可迁移的探索策略。正如婴儿不需要尝试百万次就能学会走路,真正智能的探索应该是样本高效、目标导向和持续学习的——这是下一个十年强化学习研究的核心挑战之一。
从探索策略的视角出发,下一章我们将进入 Model-Based
强化学习——通过学习环境模型进行想象和规划,从被动探索到主动规划,从反应式控制到前瞻性决策,揭示强化学习的另一条核心路径。