传统强化学习依赖智能体与环境的在线交互——通过试错收集经验,逐步优化策略。但在许多现实场景中,在线交互成本高昂甚至不可行:自动驾驶无法在真实道路上随意探索,医疗
AI
不能在病人身上做危险实验,机器人在生产环境中的错误可能造成巨大损失。更重要的是,许多领域已经积累了大量历史数据——医疗记录、交通日志、用户行为数据——如果能从这些离线数据中学习,将大幅降低
RL 的部署门槛。离线强化学习(Offline RL,也称 Batch
RL)正是研究如何从固定数据集
离线强化学习的动机与挑战
为什么需要 Offline RL?
在线 RL 的局限 : -
安全性 :探索可能产生危险行为(如自动驾驶撞车、医疗误诊) -
成本 :与真实环境交互昂贵(如工业机器人的磨损、数据中心的电费)
-
效率 :从零开始学习浪费已有数据(如历史用户日志、专家演示)
Offline RL 的优势 : - 利用已有数据,无需在线探索 -
可以从次优甚至随机策略的数据中学习 -
支持反事实推理:"如果当时选择了不同的动作会怎样?"
应用场景 : -
医疗 :从电子病历学习治疗策略 -
推荐系统 :从用户历史行为优化推荐算法 -
自动驾驶 :从人类驾驶日志学习安全策略 -
机器人 :从演示数据快速初始化策略
核心挑战
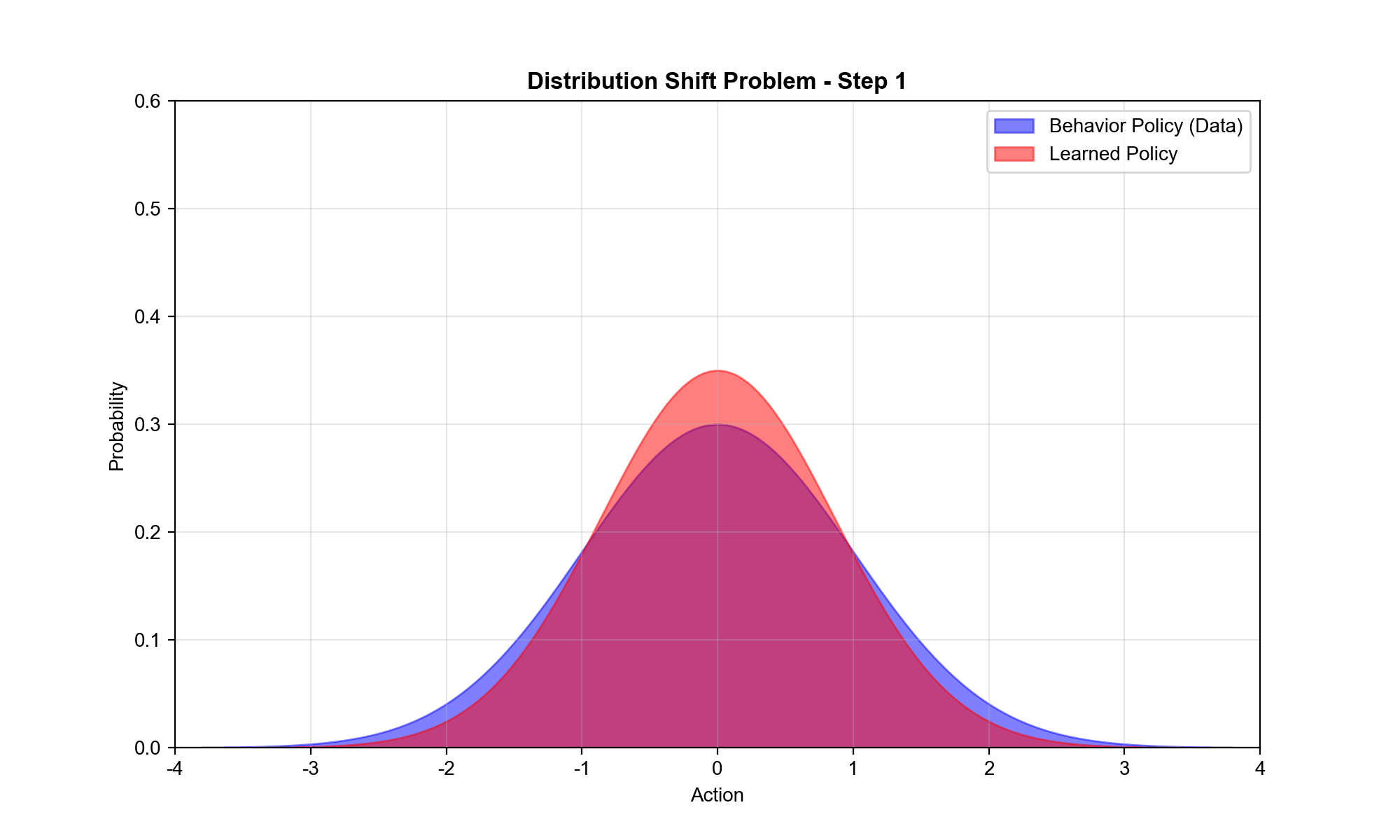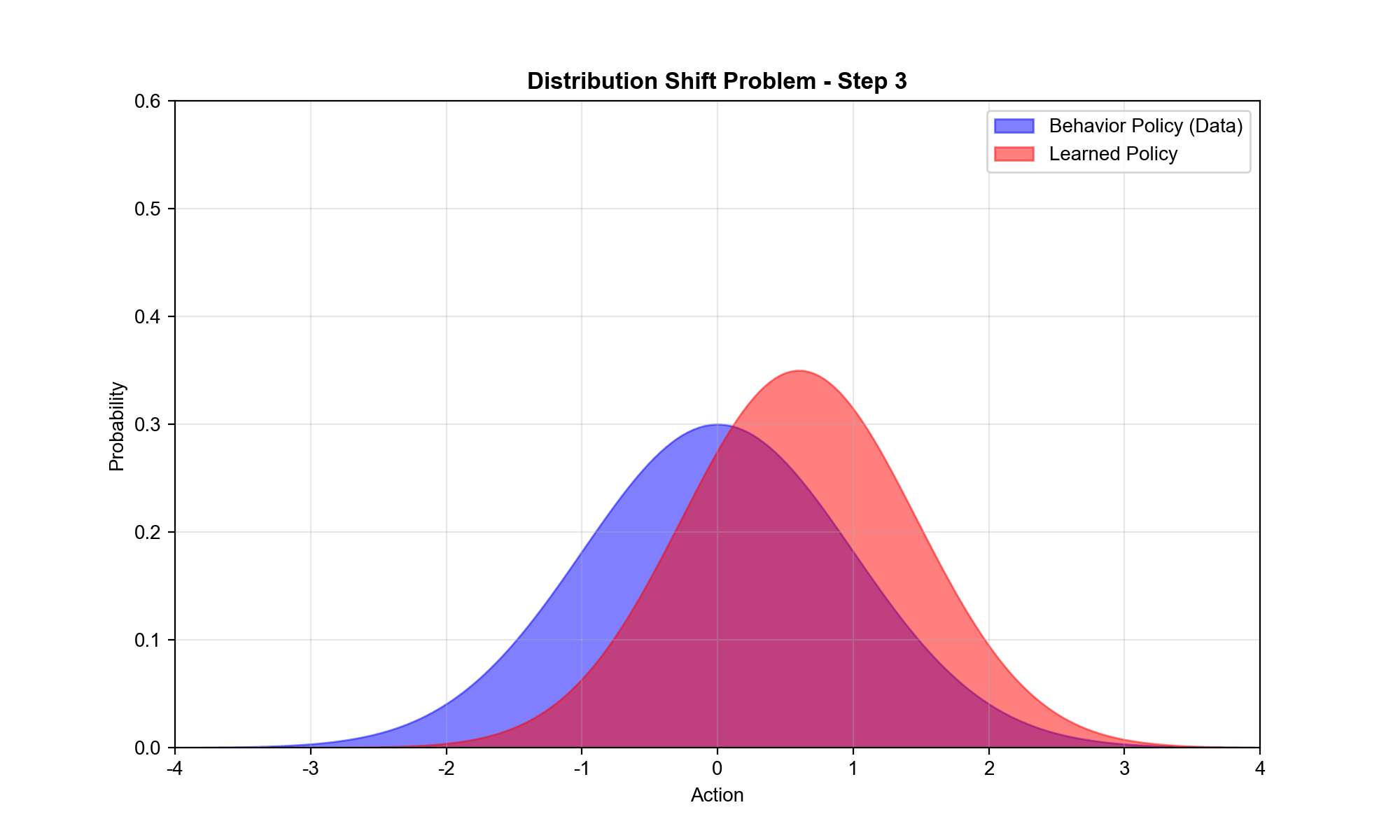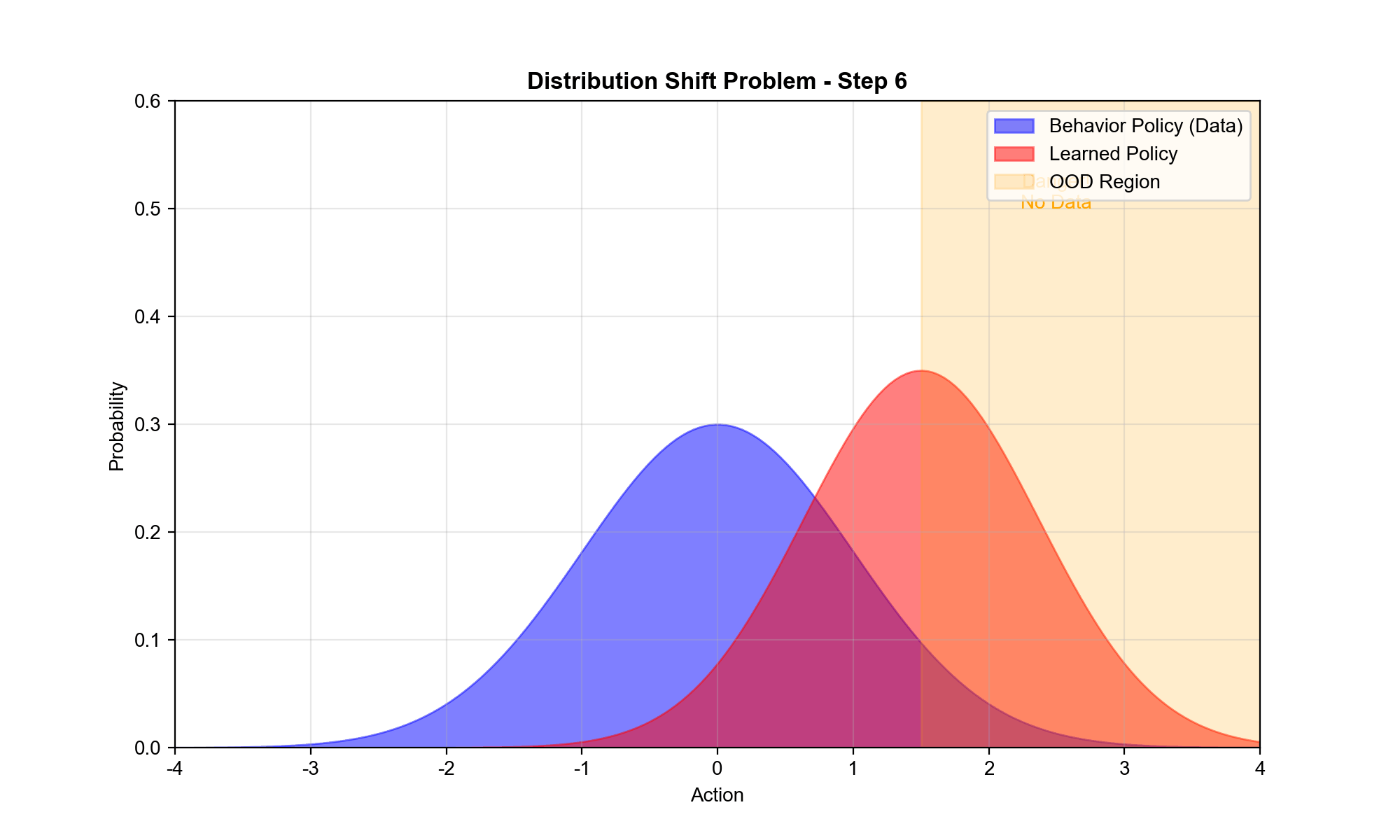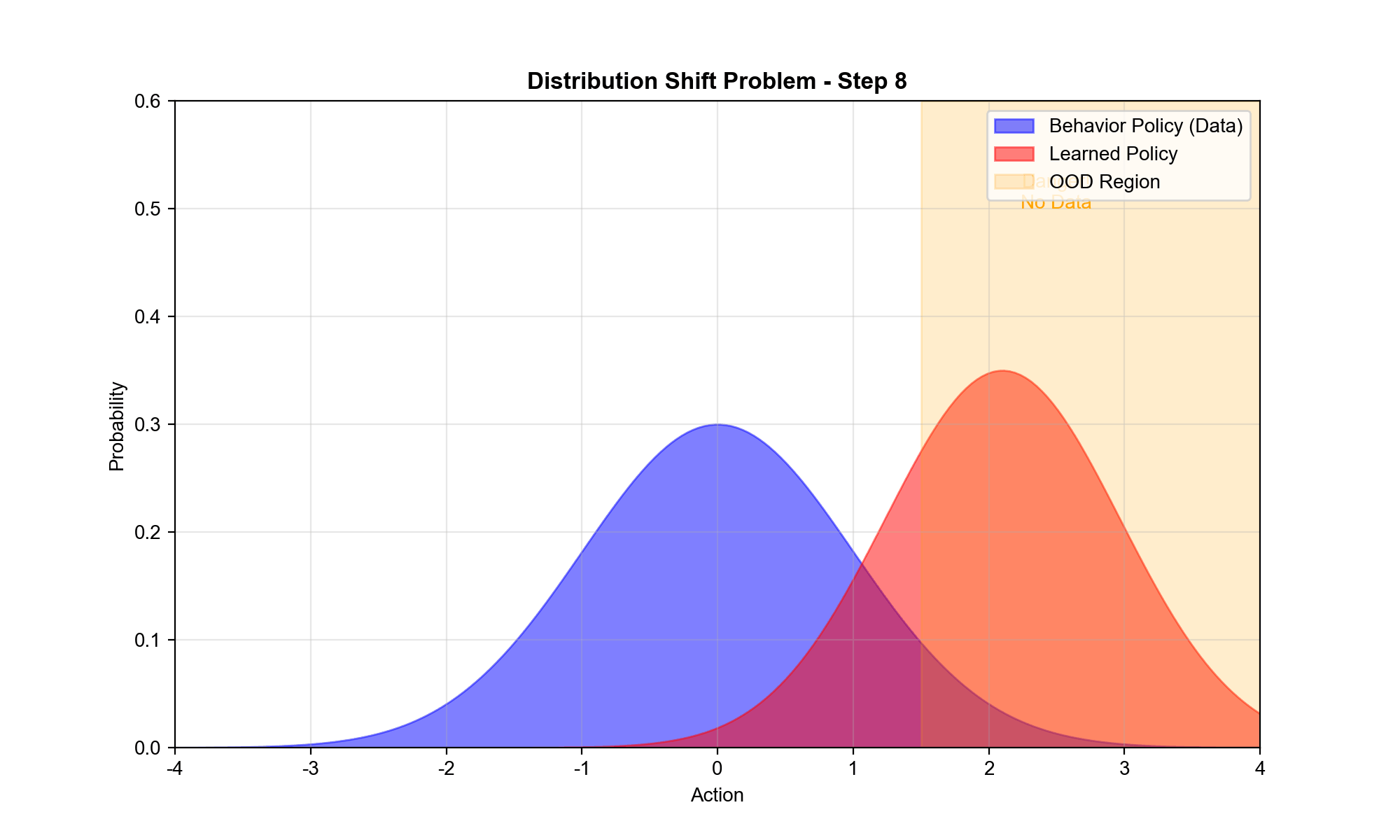
1:分布偏移(Distributional Shift)
数据集
问题 :当学习的策略
实例 :假设
Q-learning 通过 Bellman 方程更新:
问题在于
数学上 :定义外推误差 为:
对于当 远 离 数 据 分 布
后果 :学习的策略
核心挑战
3:价值高估(Overestimation)
在线 RL 中,高估 Q
值会被探索纠正——智能体尝试高估的动作,发现实际回报低,更新 Q 函数。但在
Offline RL 中,没有新的探索,高估无法被纠正。
Double Q-learning 的不足 :虽然 Double Q
缓解了最大化偏差,但在 Offline
设置下仍不够——因为问题不是算法的随机性,而是数据覆盖不足。
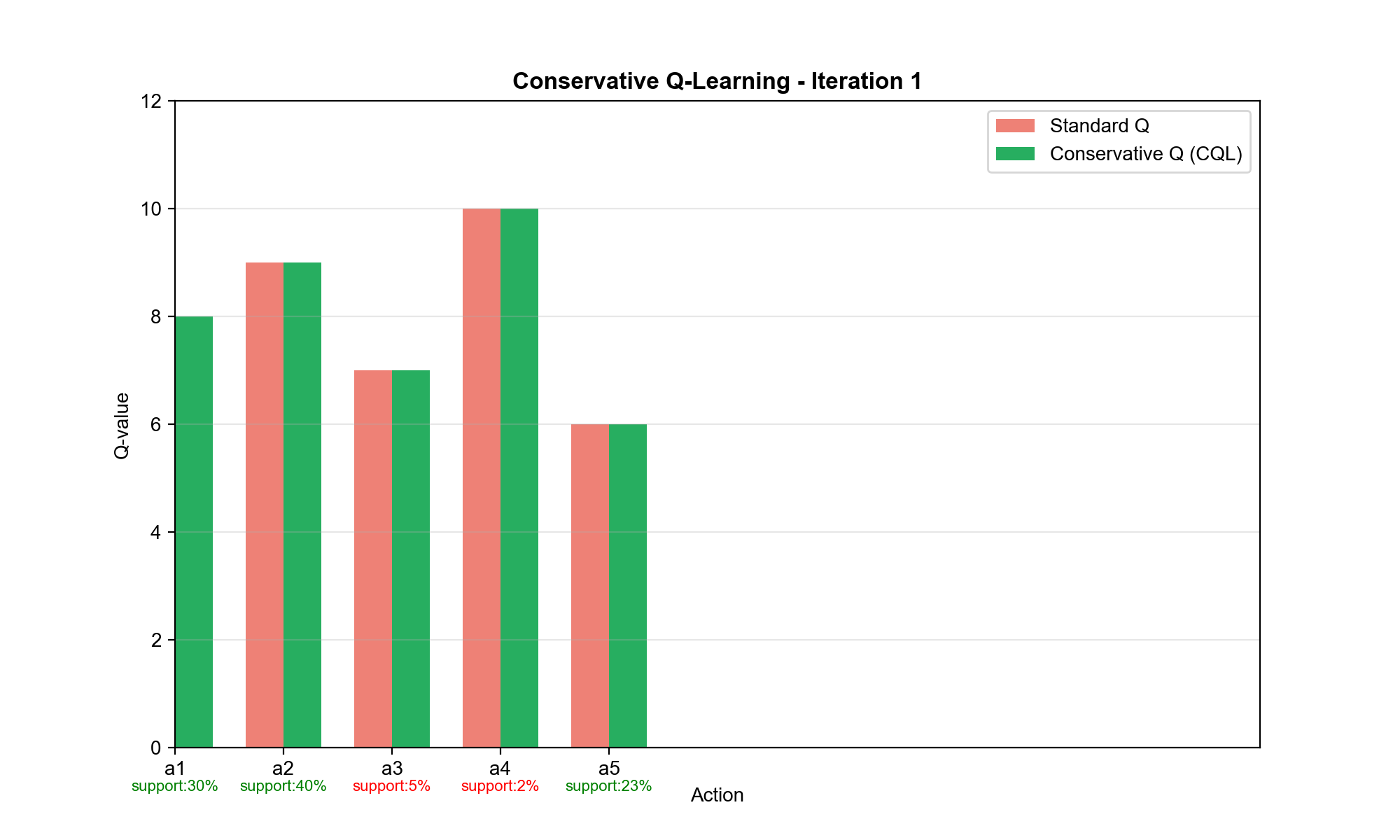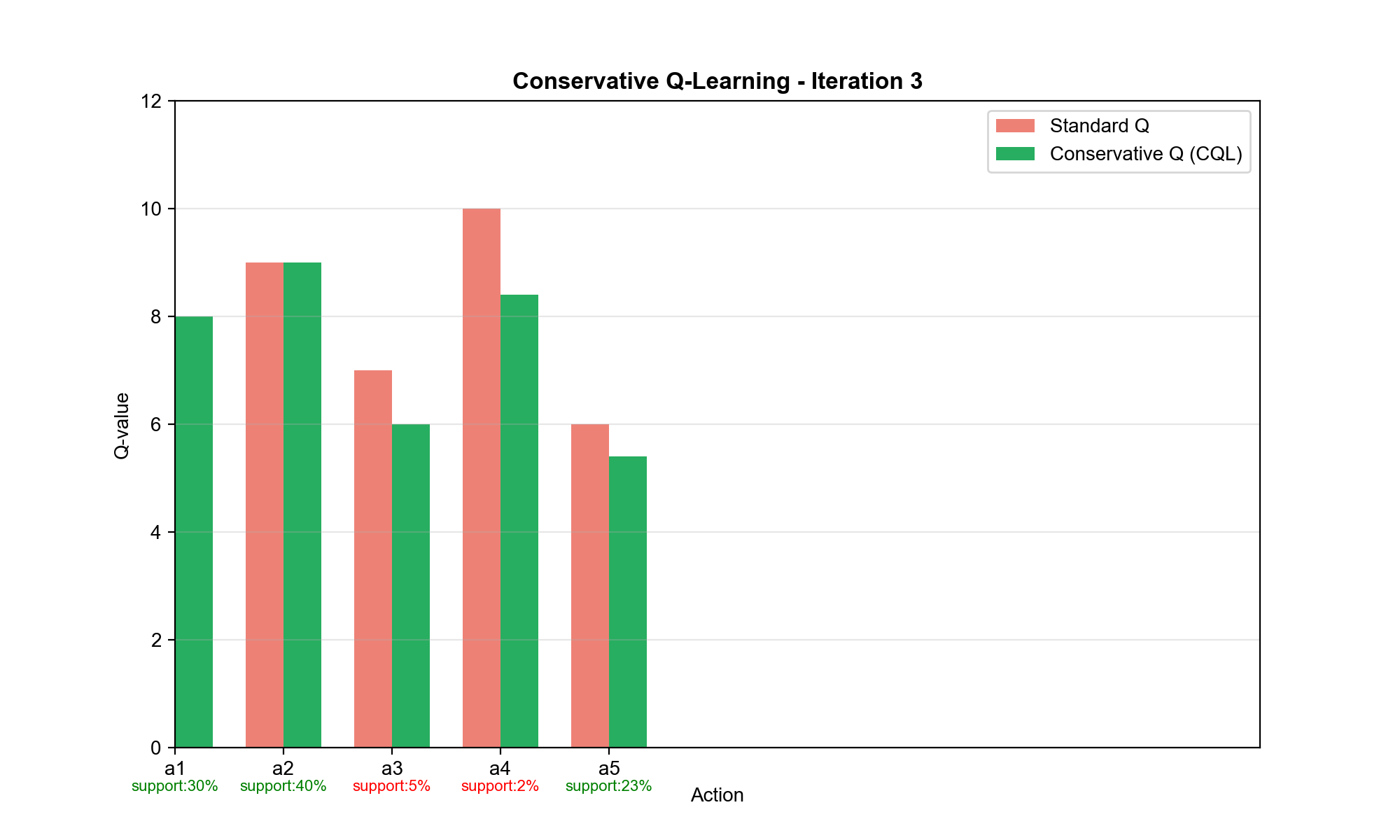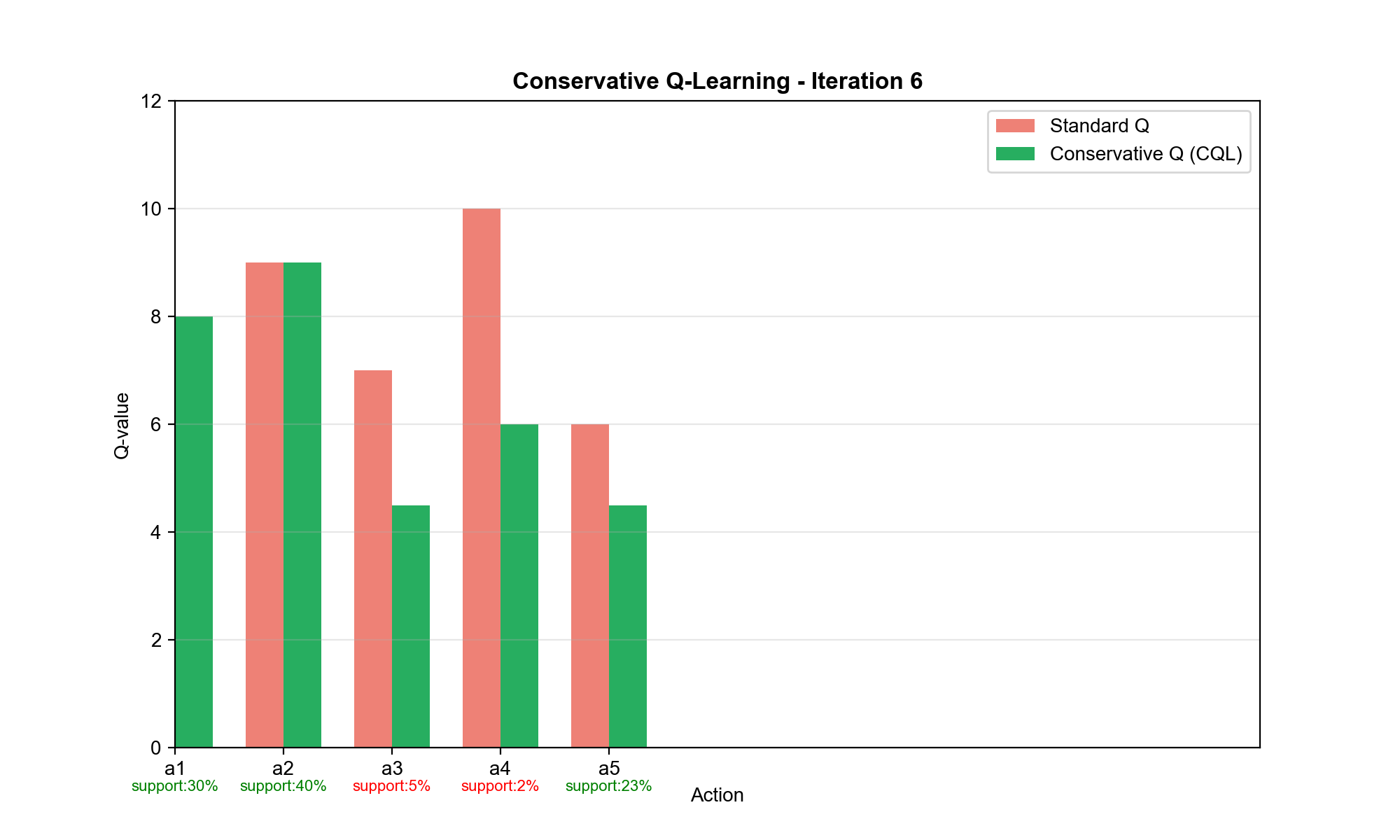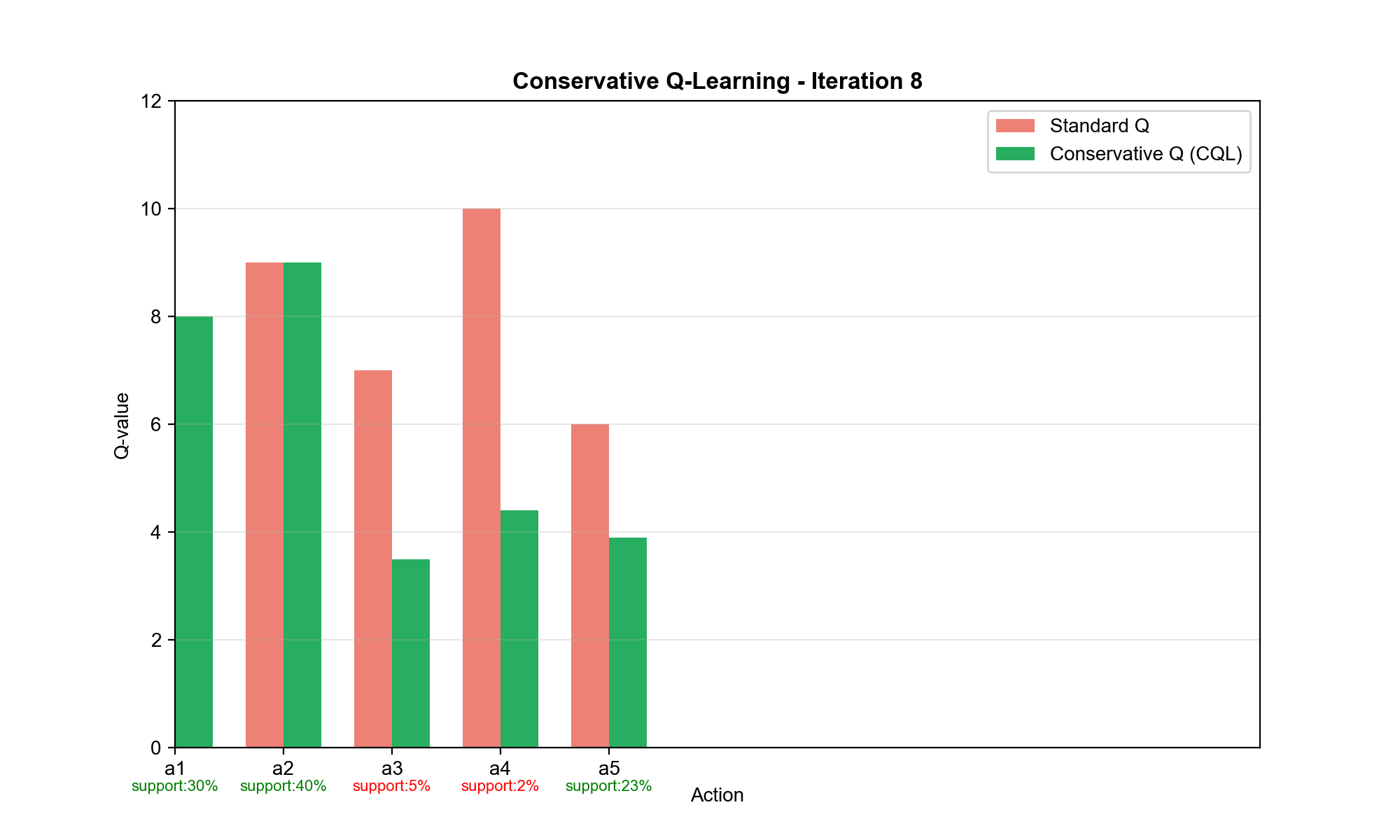
Conservative Q-Learning (CQL)
核心思想:悲观估计
CQL 的策略是:在数据分布内保守估计 Q 值,在数据分布外严厉惩罚高
Q 值 。这强制策略只选择数据充分支持的动作。
CQL 的目标函数
标准 Q-learning 优化 Bellman 误差:保守正则项 :
第一项 最大化 所有动作的 Q 值期望(类似 softmax
的 log-sum-exp)。
第二项 最小化 数据中动作的 Q 值。
效果 : - 对于数据中出现的
直觉 :CQL 在说:"我要惩罚我不确定的动作的 Q
值,只信任数据中见过的动作。"
CQL 的变体
CQL(H) :用策略
这更直接地惩罚策略
CQL(R) :加入重要性权重,调整分布:
其中
理论保证
CQL 证明了:在一定正则化强度
其中
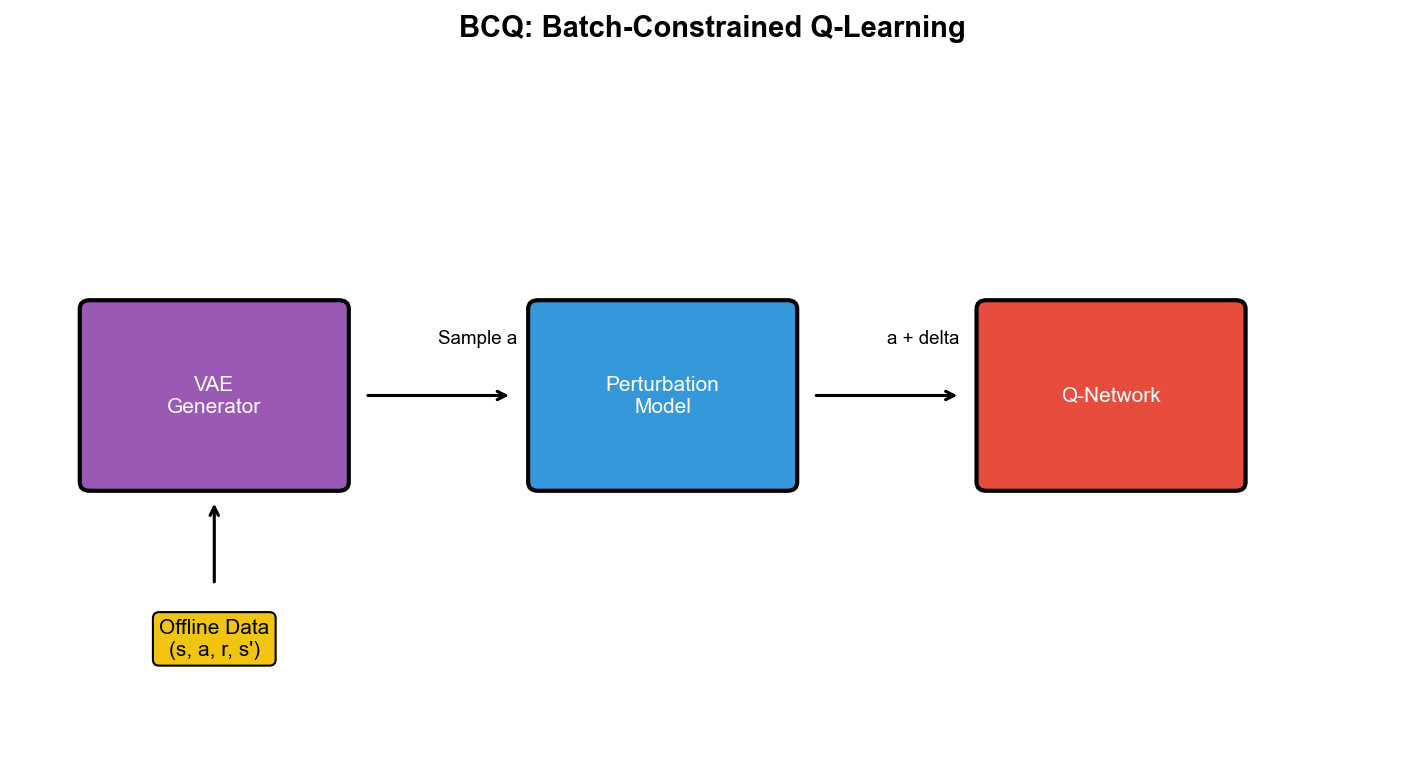
Batch-Constrained Q-Learning
(BCQ)
核心思想:行为克隆约束
BCQ 认为:策略行为策略 ,避免外推误差。
BCQ 的架构(连续动作)
VAE
建模行为策略 :训练变分自编码器(VAE)重构数据中的动作:
其中
策略被约束在 VAE 的支持内 :
其中
Q 函数更新 :与标准 Q-learning 类似,但目标中的
BCQ 的优势与局限
优势 : - 显式建模行为策略,易于理解 -
在连续动作空间表现优异
局限 : - 过于保守——如果
Implicit Q-Learning (IQL)
核心思想:避免动态规划
IQL 观察到:Q-learning 的问题根源是期望
Bellman 方程 呢?
IQL 的目标函数
IQL 学习三个函数:
Q 函数
值函数 $V(s)策 略 Q 函数更新 (expectile
regression):
其中𝟙
当Q
值被拉向上分位数 。
值函数更新 (expectile of Q):
策略更新 (加权行为克隆):
权重
IQL 的优势
无需动态规划 :
灵活性 :通过调节
实验表现 :IQL 在 D4RL 基准的许多任务上超越 CQL 和
BCQ,且训练更稳定。
重新定义 RL
Decision Transformer(DT)提出了颠覆性观点:RL
是序列建模问题,而非动态规划问题 。
给定轨迹
关键 :DT 不学习价值函数,只学习"在目标回报
DT 的架构
输入序列 :
其中
嵌入 : - 回报嵌入:Transformer : - 自注意力层处理序列损失 :
仅监督学习,无需 TD 误差或 Bellman 方程。
DT 的优势与局限
优势 : -
简单 :无需价值函数、目标网络、经验回放——只是监督学习 -
避免 BootStrapping :不传播误差,不受外推误差影响 -
可控 :测试时指定期望回报,控制策略行为(如"追求高分"vs"追求安全")
局限 : -
缺乏泛化 :只能达到数据中的最高回报,无法超越 -
长期依赖 :Transformer 的上下文长度限制(如 512 步) -
无因果推理 :不理解动作-奖励的因果关系,只是模式匹配
后续改进 : - Trajectory
Transformer :同时预测状态和奖励,支持模型规划 -
Q-learning Decision Transformer :结合 DT 和
Q-learning,支持在线微调 - Online Decision
Transformer :在线收集数据,持续改进 DT
完整代码实现:CQL
下面实现 CQL 在 D4RL 的 Gym 环境(如 HalfCheetah)上训练。包括: - CQL
的保守正则项 - 离线数据集加载 - Q 函数和策略网络的训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Fimport numpy as npimport gymimport d4rl class QNetwork (nn.Module): """双 Q 网络(减少过估计)""" def __init__ (self, state_dim, action_dim, hidden_dim=256 ): super ().__init__() self.q1 = nn.Sequential( nn.Linear(state_dim + action_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, 1 ) ) self.q2 = nn.Sequential( nn.Linear(state_dim + action_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, 1 ) ) def forward (self, state, action ): sa = torch.cat([state, action], dim=1 ) return self.q1(sa), self.q2(sa) def q1_forward (self, state, action ): sa = torch.cat([state, action], dim=1 ) return self.q1(sa) class GaussianPolicy (nn.Module): """高斯策略(连续动作)""" def __init__ (self, state_dim, action_dim, hidden_dim=256 , log_std_min=-20 , log_std_max=2 ): super ().__init__() self.log_std_min = log_std_min self.log_std_max = log_std_max self.net = nn.Sequential( nn.Linear(state_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim), nn.ReLU() ) self.mean = nn.Linear(hidden_dim, action_dim) self.log_std = nn.Linear(hidden_dim, action_dim) def forward (self, state ): x = self.net(state) mean = self.mean(x) log_std = self.log_std(x) log_std = torch.clamp(log_std, self.log_std_min, self.log_std_max) std = torch.exp(log_std) return mean, std def sample (self, state ): mean, std = self.forward(state) normal = torch.distributions.Normal(mean, std) z = normal.rsample() action = torch.tanh(z) log_prob = normal.log_prob(z) - torch.log(1 - action.pow (2 ) + 1e-6 ) log_prob = log_prob.sum (dim=1 , keepdim=True ) return action, log_prob def get_action (self, state ): with torch.no_grad(): mean, std = self.forward(state) action = torch.tanh(mean) return action class CQLAgent : def __init__ (self, state_dim, action_dim, device='cpu' , lr=3e-4 , gamma=0.99 , tau=0.005 , alpha=1.0 , cql_weight=1.0 ): self.gamma = gamma self.tau = tau self.alpha = alpha self.cql_weight = cql_weight self.device = device self.q_net = QNetwork(state_dim, action_dim).to(device) self.target_q_net = QNetwork(state_dim, action_dim).to(device) self.target_q_net.load_state_dict(self.q_net.state_dict()) self.policy = GaussianPolicy(state_dim, action_dim).to(device) self.q_optimizer = optim.Adam(self.q_net.parameters(), lr=lr) self.policy_optimizer = optim.Adam(self.policy.parameters(), lr=lr) self.target_entropy = -action_dim self.log_alpha = torch.zeros(1 , requires_grad=True , device=device) self.alpha_optimizer = optim.Adam([self.log_alpha], lr=lr) def compute_cql_loss (self, states, actions, next_states ): """CQL 保守正则项""" batch_size = states.size(0 ) sampled_actions, _ = self.policy.sample(states) random_actions = torch.FloatTensor(batch_size, actions.size(1 )).uniform_(-1 , 1 ).to(self.device) q1_data, q2_data = self.q_net(states, actions) q1_policy, q2_policy = self.q_net(states, sampled_actions) q1_random, q2_random = self.q_net(states, random_actions) q1_all = torch.cat([q1_policy, q1_random], dim=0 ) q2_all = torch.cat([q2_policy, q2_random], dim=0 ) q1_logsumexp = torch.logsumexp(q1_all, dim=0 , keepdim=True ) q2_logsumexp = torch.logsumexp(q2_all, dim=0 , keepdim=True ) cql_loss = (q1_logsumexp.mean() + q2_logsumexp.mean()) - (q1_data.mean() + q2_data.mean()) return cql_loss def update (self, states, actions, rewards, next_states, dones ): """更新 Q 函数和策略""" states = torch.FloatTensor(states).to(self.device) actions = torch.FloatTensor(actions).to(self.device) rewards = torch.FloatTensor(rewards).unsqueeze(1 ).to(self.device) next_states = torch.FloatTensor(next_states).to(self.device) dones = torch.FloatTensor(dones).unsqueeze(1 ).to(self.device) with torch.no_grad(): next_actions, next_log_probs = self.policy.sample(next_states) target_q1, target_q2 = self.target_q_net(next_states, next_actions) target_q = torch.min (target_q1, target_q2) - self.alpha * next_log_probs target = rewards + self.gamma * (1 - dones) * target_q current_q1, current_q2 = self.q_net(states, actions) q_loss = F.mse_loss(current_q1, target) + F.mse_loss(current_q2, target) cql_loss = self.compute_cql_loss(states, actions, next_states) total_q_loss = q_loss + self.cql_weight * cql_loss self.q_optimizer.zero_grad() total_q_loss.backward() self.q_optimizer.step() sampled_actions, log_probs = self.policy.sample(states) q1_pi, q2_pi = self.q_net(states, sampled_actions) min_q_pi = torch.min (q1_pi, q2_pi) policy_loss = (self.alpha * log_probs - min_q_pi).mean() self.policy_optimizer.zero_grad() policy_loss.backward() self.policy_optimizer.step() alpha_loss = -(self.log_alpha * (log_probs + self.target_entropy).detach()).mean() self.alpha_optimizer.zero_grad() alpha_loss.backward() self.alpha_optimizer.step() self.alpha = self.log_alpha.exp().item() for param, target_param in zip (self.q_net.parameters(), self.target_q_net.parameters()): target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data) return { 'q_loss' : q_loss.item(), 'cql_loss' : cql_loss.item(), 'policy_loss' : policy_loss.item(), 'alpha' : self.alpha } def select_action (self, state ): """选择动作(测试时)""" state = torch.FloatTensor(state).unsqueeze(0 ).to(self.device) action = self.policy.get_action(state) return action.cpu().numpy()[0 ] def train_cql (env_name='halfcheetah-medium-v2' , num_steps=100000 , batch_size=256 ): env = gym.make(env_name) dataset = d4rl.qlearning_dataset(env) state_dim = env.observation_space.shape[0 ] action_dim = env.action_space.shape[0 ] print (f"环境: {env_name} " ) print (f"状态维度: {state_dim} , 动作维度: {action_dim} " ) print (f"数据集大小: {len (dataset['observations' ])} " ) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) agent = CQLAgent(state_dim, action_dim, device=device) for step in range (num_steps): indices = np.random.randint(0 , len (dataset['observations' ]), batch_size) states = dataset['observations' ][indices] actions = dataset['actions' ][indices] rewards = dataset['rewards' ][indices] next_states = dataset['next_observations' ][indices] dones = dataset['terminals' ][indices] info = agent.update(states, actions, rewards, next_states, dones) if step % 1000 == 0 : print (f"Step {step} : Q_loss={info['q_loss' ]:.4 f} , CQL_loss={info['cql_loss' ]:.4 f} , " f"Policy_loss={info['policy_loss' ]:.4 f} , Alpha={info['alpha' ]:.4 f} " ) if step % 10000 == 0 and step > 0 : eval_rewards = [] for _ in range (10 ): state = env.reset() episode_reward = 0 done = False while not done: action = agent.select_action(state) state, reward, done, _ = env.step(action) episode_reward += reward eval_rewards.append(episode_reward) avg_reward = np.mean(eval_rewards) normalized_score = env.get_normalized_score(avg_reward) * 100 print (f"=== 评估 Step {step} : 平均回报={avg_reward:.2 f} , D4RL 分数={normalized_score:.2 f} ===" ) return agent if __name__ == "__main__" : agent = train_cql(env_name='halfcheetah-medium-v2' , num_steps=100000 , batch_size=256 )
代码解析
网络部分 : - QNetwork:双 Q 网络(Q1 和
Q2),减少过估计 -
GaussianPolicy:高斯策略,输出均值和标准差,用
reparameterization trick 采样动作,并修正 tanh 变换的 log 概率
CQL 核心 : - compute_cql_loss: -
从策略采样动作
更新流程 :
Q 函数 :Bellman loss + CQL loss策略 :最大化Alpha :自动调节温度参数,平衡探索与利用目标网络 :软更新训练 :
从 D4RL 数据集采样 batch
更新 10 万步
每 1 万步评估 10 个 episode,计算 D4RL 归一化分数
性能 : - HalfCheetah-medium-v2:CQL 达到约 45-50
分(满分 100) - Walker2d-medium-expert-v2:CQL 达到约 110 分
深度问答
Q1: CQL
的保守正则项为什么有效?
数学直觉 :CQL 的目标是学习 Q 函数的下界
正则项
(通过 softmax 的 log-sum-exp 与期望的关系)。
效果 : - 第一项 增大所有动作的平均 Q
值 - 第二项 减小数据中动作的 Q 值 -
结果 :数据外动作的 Q
值被相对增大,但由于第二项无法抵消,它们最终被惩罚
实验验证 :论文显示,CQL 学习的 Q 值在数据分布上比真实
Q 值低 10-20%,但在数据外低 50%以上——这正是我们想要的悲观估计。
Q2: BCQ 为什么用 VAE
而不是简单的行为克隆?
问题 :简单的行为克隆学习
VAE 的优势 :
显式密度模型 :VAE 的解码器平滑插值 :隐变量扰动机制 :扰动网络
缺点 :VAE
训练复杂,特别是在高维动作空间(如机器人控制)需要大量超参数调优。
Q3: IQL
为什么不需要显式的动态规划?
关键洞察 :IQL 用 expectile 回归学习 Q
值的上分位数,而不是最大值。这避免了
数学上 :expectile 回归的目标是:
当
优势 : - 不需要选择特定的
实验 :IQL 在 D4RL 的许多任务上超越
CQL,特别是在数据质量差的任务(如 antmaze-medium-play)。
争议 :DT 不学习价值函数,不用 Bellman
方程,不做策略改进——它到底算不算 RL?
支持者 : - RL
的本质是学习策略最大化回报,而不是特定的算法(如 TD 学习) - DT
通过条件化回报
反对者 : - DT
是条件行为克隆,只能模仿数据中的轨迹,无法发现新策略 - RL
应该涉及信用分配(哪个动作导致了回报),而 DT 只是序列预测
折中观点 :DT 是"隐式
RL"——它不显式优化价值,但通过监督学习达到了类似效果。它在 Offline
设置下有效,但不适合在线学习或需要长期规划的任务。
Q5: Offline RL
什么时候会失败?
场景 1:数据覆盖不足 -
如果数据集只包含专家轨迹,策略从未见过"如何从错误中恢复" -
测试时,策略犯了一个小错误,进入未见过的状态,然后灾难性失败
场景 2:数据质量极差 -
如果数据全是随机策略生成的,Offline RL 很难学到有用的东西 - CQL
会过度保守,BCQ 会克隆随机行为,DT 会模仿随机轨迹
场景 3:分布偏移太大 -
如果测试环境与训练数据的环境不同(如物理参数变化),策略泛化失败 - Offline
RL 没有探索机制,无法适应新环境
解决方案 : - Hybrid RL :先 Offline
预训练,再 Online 微调 - 保守探索 :Offline
学习后,用低风险的探索改进策略 -
模型辅助 :学习环境模型,在模型中模拟探索
Q6: CQL 的超参数
理论指导 :论文证明,
实践中 : - 数据质量好 (如 expert
数据):数据质量中等 (如 medium 数据):数据质量差 (如 random 数据):
自动调节 :最新版本的 CQL 用 Lagrange
乘子法自动调节
Q7: Offline RL
与模仿学习的区别?
模仿学习 : - 学习专家策略
Offline RL : - 学习最优策略,目标是
实例 :假设数据集包含: - 专家在前半段游戏做得很好 -
新手在后半段偶然发现了高分技巧
模仿学习只会学专家的前半段,忽略后半段;Offline RL
会学习两者,结合成更优策略。
Q8: 为什么 Offline RL
在机器人上应用困难?
挑战 1:部分可观测性 -
机器人传感器有限(如摄像头视野、触觉范围) -
状态表示不完整,需要记忆或状态估计 - Offline
数据缺乏探索,无法覆盖所有隐状态
挑战 2:高维连续控制 - 机器人动作空间大(如 7
自由度机械臂) - 连续控制的分布偏移更严重 - BCQ 的 VAE
在高维空间不稳定
挑战 3:物理约束 -
真实机器人有动力学约束、碰撞检测、稳定性要求 - Offline
策略可能输出不安全动作(如过大的力矩) - 需要额外的安全层
解决方案 : - 用模拟器生成大量数据(sim-to-real) -
Offline 预训练+Online 微调(先安全学习,再谨慎探索) -
结合专家知识(如物理先验、安全约束)
训练时 : - 输入真实轨迹
测试时 : - 手动设定高回报
直觉 :模型内化了"不同回报目标对应不同行为"——低回报对应保守策略,高回报对应激进策略。测试时指定高回报,模型就表现得像专家。
局限 :如果数据中没有高回报轨迹,
Q10: Offline RL 的未来方向?
1. 与在线 RL 结合 : - Offline 预训练提供初始化,Online
微调提升性能 - 如何平衡两者?何时切换?
2. 多模态数据 : - 利用视频、文本、多传感器数据 -
与大模型(如 GPT)结合,用语言指导策略
3. 因果推理 : - 从数据推断动作-奖励的因果关系 -
反事实推理:"如果当时选了另一个动作会怎样?"
4. 可解释性 : - 为什么策略选择这个动作? -
哪些数据样本对学习最重要?
5. 理论保证 : - 更严格的收敛性分析 - 样本复杂度的界 -
安全性保证(避免灾难性失败)
相关论文与资源
核心论文
CQL :https://arxiv.org/abs/2006.04779
BCQ :https://arxiv.org/abs/1812.02900
IQL :https://arxiv.org/abs/2110.06169
Decision Transformer :https://arxiv.org/abs/2106.01345
D4RL Benchmark :https://arxiv.org/abs/2004.07219
AWAC :https://arxiv.org/abs/2006.09359
TD3+BC :https://arxiv.org/abs/2106.06860
基准与代码
总结
离线强化学习将 RL
从"边做边学"的在线范式转变为"从历史数据学习"的离线范式,大幅降低了部署门槛。但这也带来了新的挑战:分布偏移、外推误差、价值高估——这些问题迫使我们重新思考
RL 的基本原理。
CQL 通过悲观估计,确保 Q
函数在数据外是保守的,避免策略选择未见过的动作。
BCQ 通过 VAE
显式建模行为策略,将策略约束在数据分布附近,防止外推。
IQL 避免动态规划,用 expectile 回归学习 Q
值的上分位数,绕过了
Decision Transformer 将 RL 重塑为序列建模,用
Transformer 直接学习回报条件策略,摆脱了价值函数的束缚。
未来的 Offline RL 将与在线 RL
、模仿学习、因果推理深度融合,成为从大规模数据中学习智能决策的核心技术——从医疗到自动驾驶,从推荐系统到机器人,Offline
RL 正在开启 AI 应用的新纪元。