大语言模型(LLM)的突破性进展——从 GPT-3 到 ChatGPT,从 Claude 到 Gemini ——不仅源于模型规模的扩大和预训练数据的增长,更关键的是人类反馈强化学习(RLHF, Reinforcement Learning from Human Feedback)的引入。预训练的语言模型虽然能生成流畅文本,但往往产生有害内容、错误信息或偏离用户意图的回复。 RLHF 通过收集人类对模型输出的偏好数据,训练奖励模型捕获人类价值观,再用强化学习(PPO)微调模型,使其生成更有帮助、更诚实、更无害的内容。 InstructGPT 首次系统化 RLHF 流程,ChatGPT 将其推向大众视野,而 DPO(Direct Preference Optimization)和 RLAIF(RL from AI Feedback)则简化了训练复杂度和数据收集成本。除了语言领域,强化学习在具身智能(机器人、自动驾驶)中同样扮演核心角色——从模拟到真实世界的策略迁移,从离线数据到在线微调,RL 正在塑造下一代通用智能体。本章将系统梳理 RLHF 的技术细节、 DPO 的理论创新、 RLAIF 的实践方案,以及 RL 在多模态与具身智能中的应用,并通过完整代码帮助你实现简化版 RLHF 流程。
RLHF:从预训练到人类对齐
为什么需要 RLHF?
预训练语言模型的局限: -
目标不对齐:最大化下一词预测似然
人类反馈的价值: - 捕获复杂、隐式的人类偏好(如"有帮助"、"有礼貌"、"避免偏见") - 比手工规则更灵活,比监督学习更高效(只需比较两个输出,不需生成完美答案)
RLHF 的目标: - 让模型输出与人类价值观对齐 - 最大化人类评分(奖励)而非似然
RLHF 的三阶段流程
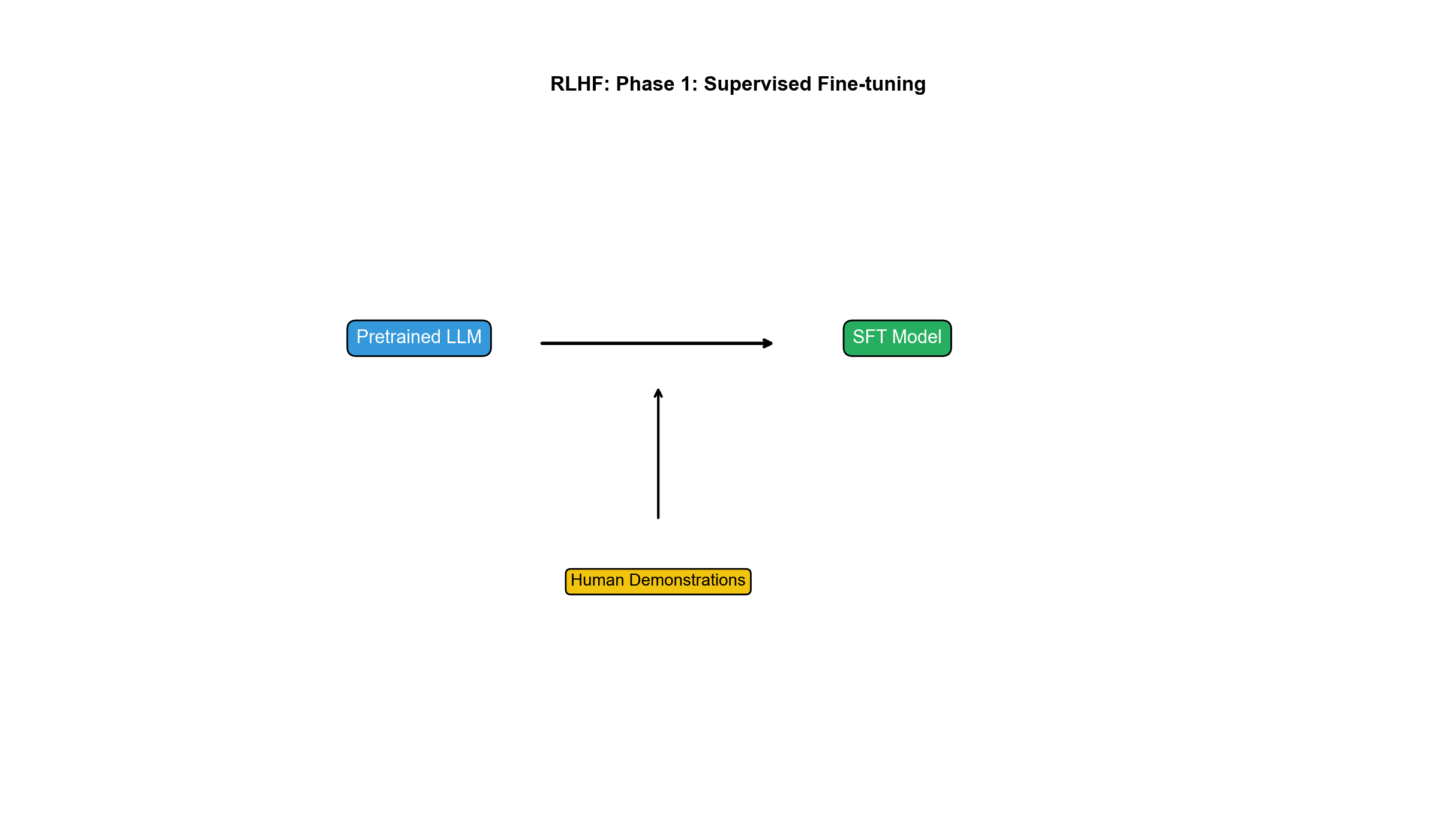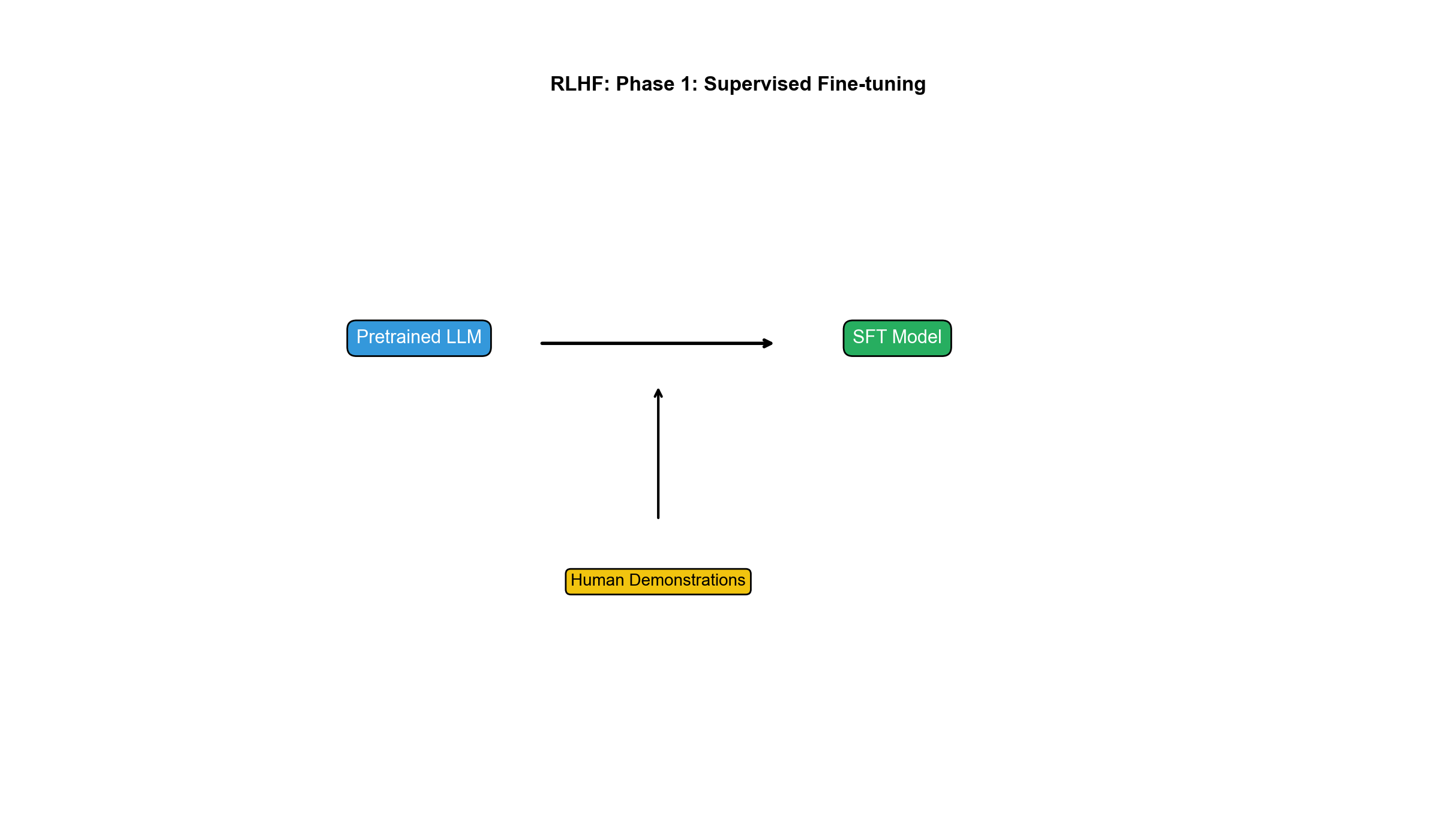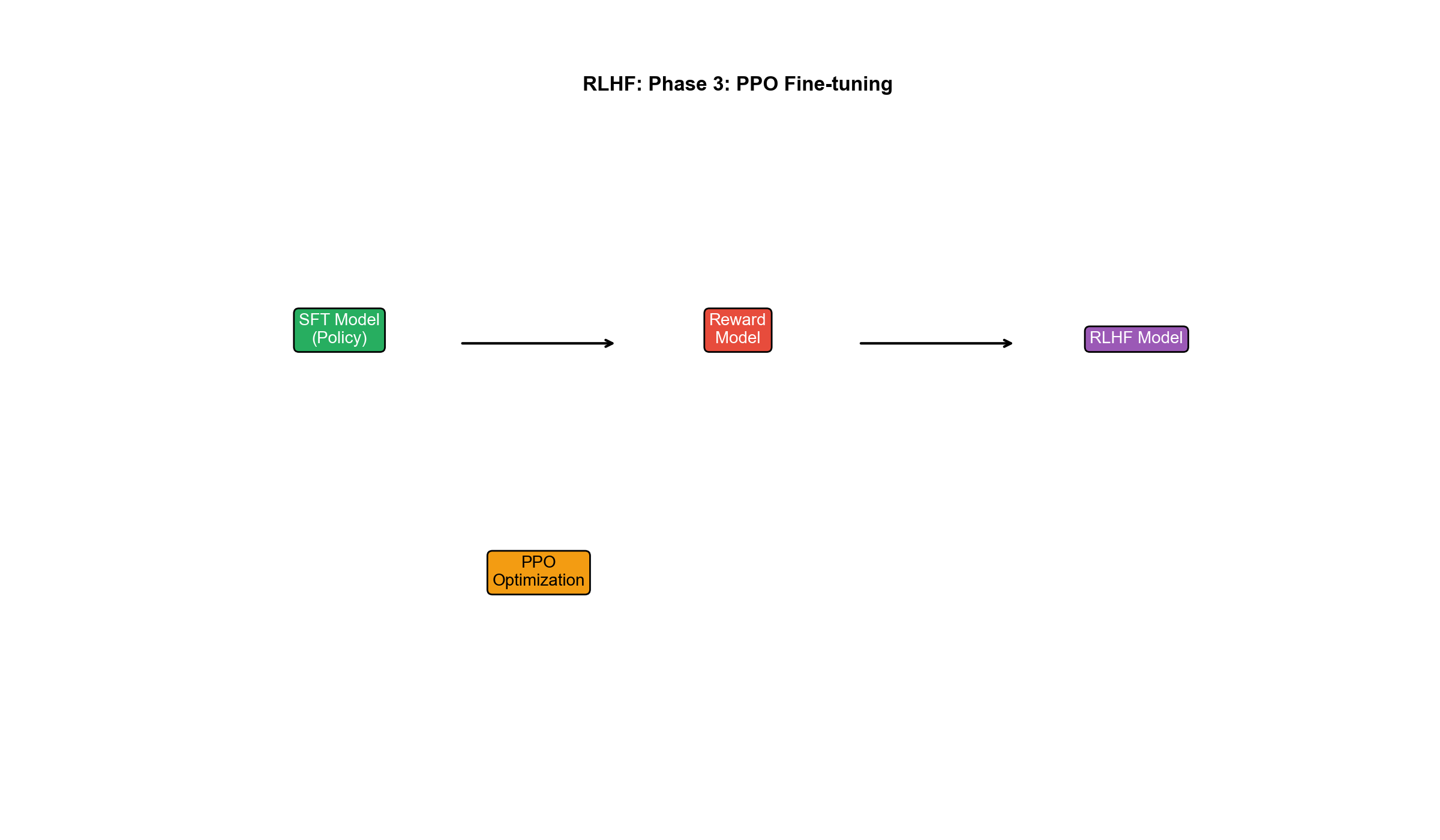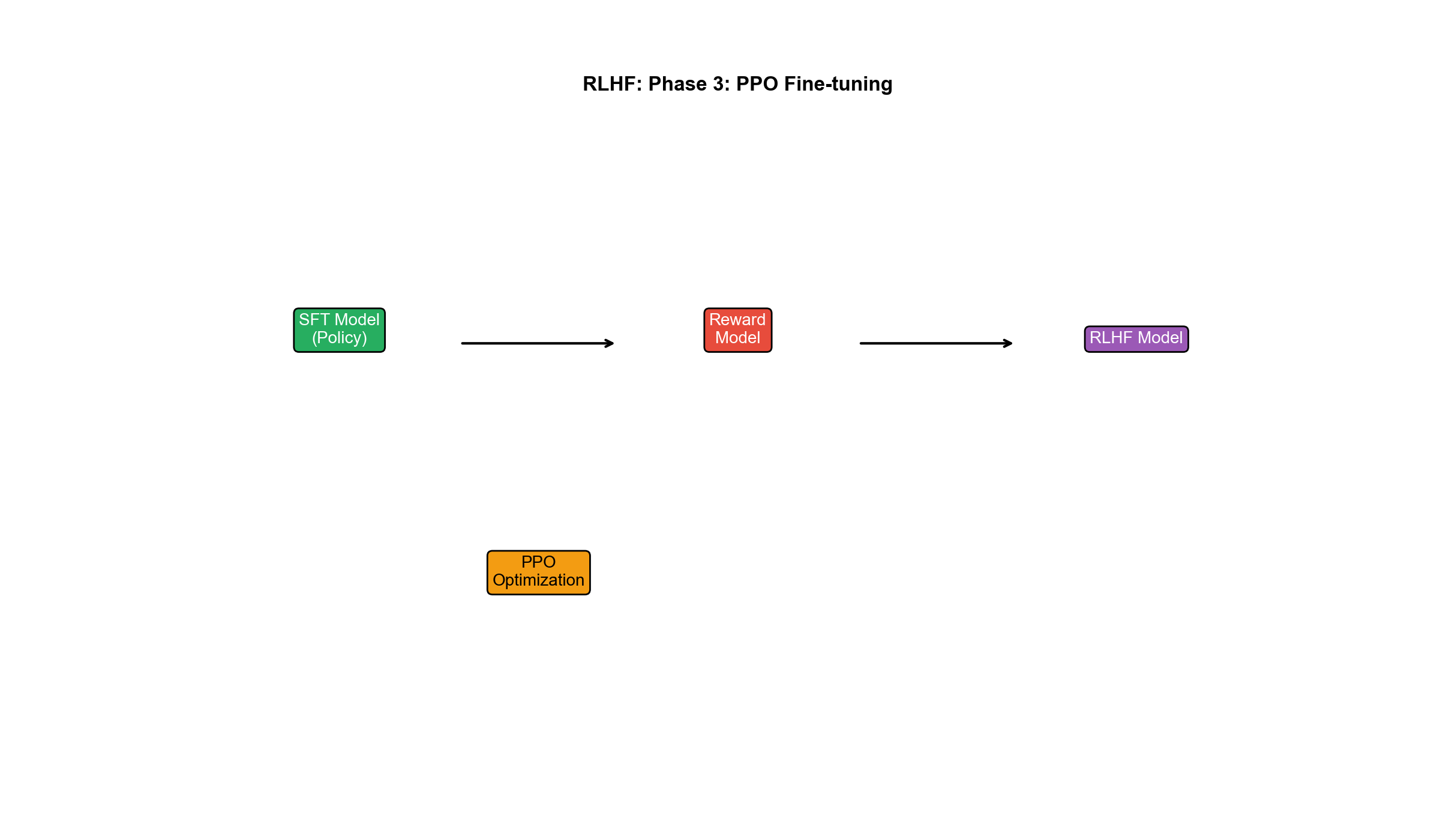
阶段 1:监督微调(SFT, Supervised Fine-Tuning)
从预训练模型(如 GPT-3)出发,在高质量演示数据上微调: -
收集人工标注的(提示, 期望回复)对 - 用标准交叉熵损失微调:
目的: - 给模型提供"格式化"输出的初始化(如对话格式、指令遵循) - 减少 RL 训练的探索难度
数据规模:InstructGPT 用约 13k 演示(labeler 写的高质量回复)。
**阶段 2:奖励模型训练(Reward Model
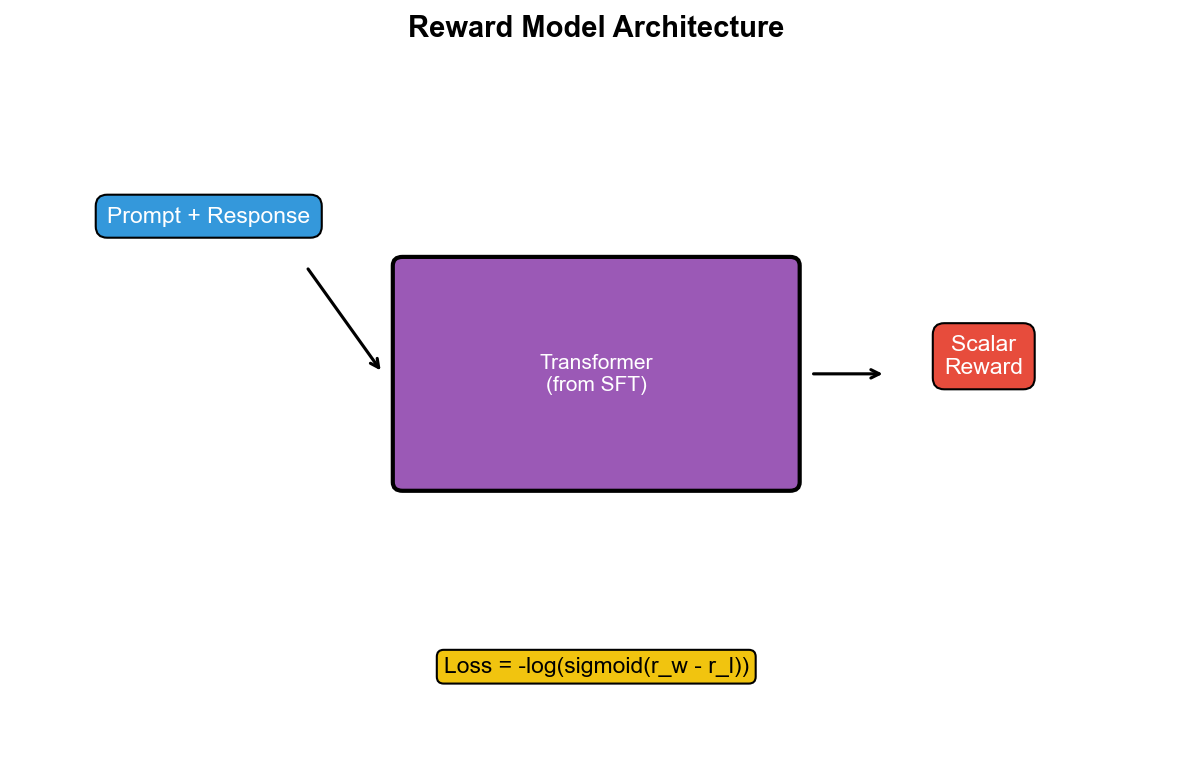
ing)**
训练奖励模型
其中
架构:通常基于 SFT
模型,去掉最后一层,加线性层输出标量奖励
数据规模:InstructGPT 用约 33k 比较(每个提示 4-9 个输出,两两比较)。
阶段 3:PPO 微调(Policy Optimization)
用强化学习(PPO)优化策略
目标函数:
- 第一项
:奖励模型评分,鼓励模型生成高分输出 - 第二项
:KL 散度正则,防止模型偏离 SFT 初始化太远(避免"奖励黑客"——生成奖励模型给高分但人类看起来垃圾的输出)
PPO 算法: - 采样提示
其中
训练细节: - 每次迭代采样一批提示,生成回复,计算奖励,更新策略 - 同时在 SFT 数据上做监督损失(防止遗忘) - 迭代数千步,直到奖励饱和
InstructGPT:RLHF 的系统化实践
InstructGPT 的训练流程
OpenAI 在 2022 年发表 InstructGPT 论文,系统化了 RLHF 流程:
1. 数据收集: - SFT 数据:13k 提示+人工标注回复 - 比较数据:33k 提示,每个提示 4-9 个模型输出,人类标注偏好排序 - 提示来源:API 用户提交的真实请求(去隐私)+labeler 编写的多样化提示
2. 模型规模: - 基于 GPT-3 的 1.3B 、 6B 、 175B 参数模型 - SFT 和 RL 阶段都训练所有尺寸,对比效果
3. 奖励模型: - 6B 参数模型表现最好(比 175B 参数的奖励模型更稳定) - 输入:提示+回复,输出:标量奖励 - 训练:在比较数据上优化 Bradley-Terry 损失
4. PPO 微调: - 初始化:从 SFT 模型出发 - KL
系数:
InstructGPT 的关键发现
1. 模型规模 vs 数据质量: - 1.3B 参数的 InstructGPT(用 RLHF 训练)在人类评估中优于175B 参数的 GPT-3(仅预训练) - 说明对齐训练比规模更重要
2. 泛化能力: - 在 held-out 提示上,InstructGPT 表现良好(未见过的任务类型) - 奖励模型能泛化到新的提示分布
3. 对齐税(Alignment Tax): - RLHF 训练后,模型在某些 NLP 基准(如 SQuAD)上性能略降 - 但实际用户体验显著提升
4. 标注者一致性: - 不同 labeler 的偏好有高度一致性(>70%) - 但在主观任务(如创意写作)上分歧更大
InstructGPT 的局限
1. 奖励模型的局限: - 奖励模型可能被"黑掉"(产生高分但无意义的输出) - 例如:生成极长但重复的文本(奖励模型可能给高分,因为长度)
2. 偏好数据的偏差: - Labeler 的偏好可能反映群体偏见 - 奖励模型继承这些偏见
3. 计算成本: - RLHF 训练成本高(需要在线采样+多次前向传播) - PPO 更新不稳定(需要仔细调参)
ChatGPT:RLHF 的大规模应用
ChatGPT 的技术演进
ChatGPT(2022 年 11 月发布): - 基于 GPT-3.5(改进版 GPT-3) - 完整 RLHF 流程(SFT →奖励模型→ PPO) - 对话优化:多轮对话能力,上下文理解
GPT-4(2023 年 3 月): - 多模态输入(文本+图像) - 更强的推理能力,更少幻觉 - 更复杂的 RLHF:多目标优化(帮助、诚实、无害)
ChatGPT 的训练细节(推测)
OpenAI 未公开完整细节,但从论文和公开信息推测:
1. SFT 数据: - 数十万对话样本(人工标注) - 覆盖多种任务:问答、创意写作、代码生成、翻译等
2. 奖励模型: -
多个奖励模型(分别建模"有帮助"、"诚实"、"无害") - 加权组合:
4. 安全层: - 内容审核模型:过滤有害输出 - Rule-based 系统:硬性约束(如拒绝非法请求)
ChatGPT 的影响
1. 用户体验提升: - 对话流畅,理解指令准确 - 拒绝不当请求(如"教我做炸弹")
2. 新的挑战: - 越狱(Jailbreaking):用户设计提示绕过安全限制 - 偏见:模型输出仍可能带有性别、种族偏见 - 幻觉:模型有时生成听起来合理但事实错误的内容
3. 推动 RLHF 研究: - ChatGPT 成功激发学术界对 RLHF 的兴趣 - 开源替代方案:LLaMA+RLHF 、 Alpaca 、 Vicuna 等
DPO:直接偏好优化
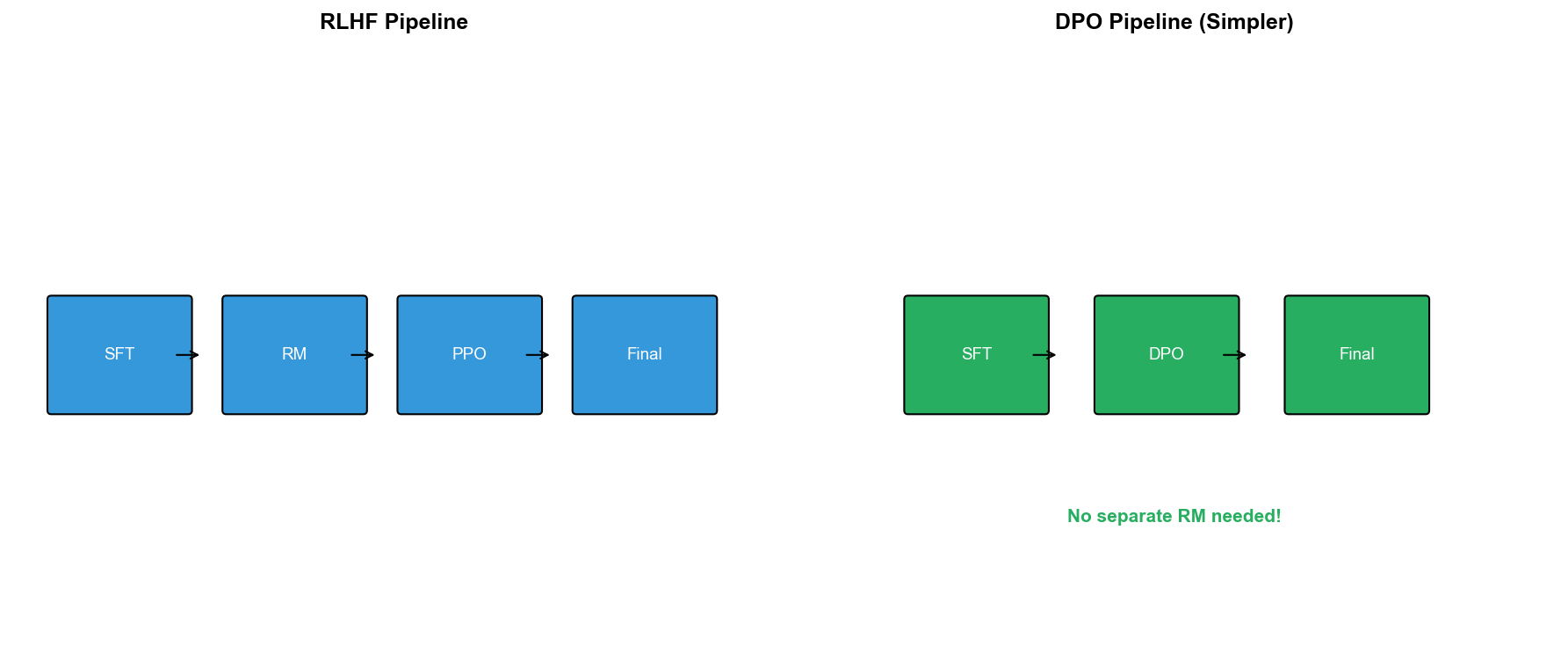
传统 RLHF 的问题
复杂性: - 需要三阶段训练(SFT →奖励模型→ PPO) - PPO 训练不稳定,需要仔细调参
计算成本: - RL 阶段需要在线采样(生成大量文本) - 每次更新需要多次前向传播(计算奖励、优势等)
奖励模型误差传播: - 奖励模型的错误会影响 RL 训练 - 奖励黑客:策略学会利用奖励模型的漏洞
DPO 的核心思想
洞察:RLHF 的最优策略有闭式解:
在标准 RLHF 目标下:
最优策略为:
其中
反解出奖励函数:
代入 Bradley-Terry 模型:
DPO 损失:直接优化策略
DPO 的优势
简单: - 只需一个训练阶段(跳过奖励模型和 RL) - 损失函数是标准交叉熵,用梯度下降优化
稳定: - 无需 PPO 的复杂采样和更新 - 无奖励模型误差传播
高效: - 计算成本低(无需在线采样) - 训练速度快(直接监督学习)
DPO 的实验结果
论文实验(Rafailov et al., 2023): - 任务:控制情感、总结、对话 - 数据:TL;DR(摘要)、 Anthropic HH(对话) - 结果:DPO 性能接近或超越 PPO-based RLHF
后续改进: - ODPO(Offset DPO):考虑偏好强度(不是所有偏好都同等重要) - IPO(Identity Preference Optimization):改进 DPO 的理论基础
DPO 的局限
隐式奖励建模: - DPO 隐式学习奖励,但无法显式查看奖励值 - 难以调试(为什么模型选择这个输出?)
对数据质量敏感: - 需要高质量偏好对
泛化能力: - 在某些任务上不如 RLHF(特别是需要复杂推理的任务)
RLAIF:用 AI 反馈替代人类反馈
人类反馈的瓶颈
成本高昂: - 标注者时间成本(InstructGPT 用 40 个全职 labeler,历时数月) - 质量控制成本(需要培训、质检、一致性检查)
扩展性差: - 人类标注速度慢(每个比较需数十秒) - 难以持续收集新数据
偏差累积: - Labeler 群体可能不代表用户群体 - 主观任务(如创意写作)难以获得一致偏好
RLAIF 的核心思想
用 AI 模型生成偏好标签: - 给定提示1
2
3
4
5Given the following question and two responses, which response is better?
Question: {x}
Response A: {y_1}
Response B: {y_2}
Answer: (A or B)
训练流程: - 用 AI 生成偏好数据
RLAIF 的变体
1. Constitution AI(Anthropic, 2022): - 用预定义规则(constitution)引导 AI 评估 - 规则示例:"输出应该诚实、有帮助、无害" - AI 评估时参考这些规则
2. Self-Critique: - 模型生成输出后,自我评估并改进 - 迭代:生成→评估→修正→生成
3. Direct-RLAIF: - 跳过奖励模型,直接用 AI 评分作为奖励 - 每次 RL 采样时,在线调用 AI 模型评分
RLAIF 的实验结果
论文(Lee et al., 2023): - 任务:摘要、对话、无害性 - 对比:RLAIF vs RLHF - 结果:RLAIF 性能接近 RLHF(在某些任务上甚至超越)
关键发现: - AI 反馈的一致性高(>85%与人类偏好一致) - 成本降低 10 倍以上(无需人工标注) - 可扩展性强(快速收集大量数据)
RLAIF 的局限
AI 评估的偏差: - AI 模型可能继承预训练数据的偏见 - 评估可能过于保守或过于激进
循环依赖: - 用 AI A 训练 AI B,可能导致错误累积 - "模型坍塌"(model collapse):多代训练后性能下降
难以捕获细微偏好: - 某些人类偏好难以用提示表达(如美学、情感细腻度)
完整代码实现:简化版 RLHF
下面实现简化版 RLHF 流程,包括: - 合成数据生成(模拟提示和回复) - 奖励模型训练(基于偏好对) - PPO 微调(简化版,用 REINFORCE+baseline)
1 | import torch |
代码解析
数据生成: -
SyntheticDataset:合成提示和回复 -
create_comparison_data:为每个提示生成 2
个回复,模拟偏好(简化为更长的更好)
奖励模型: - RewardModel:基于
GPT-2,加标量输出头 - train_reward_model:用 Bradley-Terry
损失训练
RLHF 训练: - SimpleRLHF:简化版训练器 -
compute_reward:RM 评分 - KL 惩罚 -
train_step:生成回复,计算奖励,用 REINFORCE 更新策略
注意: - 完整 RLHF 需要更复杂实现(GAE 、 PPO clipping 、多卡训练等) - 此代码仅作教学演示
RL 在具身智能中的应用
机器人学习:从模拟到现实
Sim-to-Real 迁移: - 在模拟器(如 MuJoCo 、 PyBullet)中训练策略 - 迁移到真实机器人(域随机化、域适应)
挑战: - 真实世界动力学复杂(摩擦、接触、传感器噪声) - 模拟器与现实的差距(reality gap)
成功案例: - OpenAI 的 Dactyl:用 RL 训练机械手解魔方(在模拟中训练,迁移到真实) - 波士顿动力:四足机器人的运动控制(结合 RL 和传统控制)
离线 RL for 机器人
数据来源: - 人类演示(teleoperation) - 随机策略探索 - 历史任务数据
算法: - CQL 、 IQL 、 Decision Transformer(见第十章)
优势: - 无需昂贵在线探索 - 利用已有数据
应用: - Robomimic:从演示数据学习机器人操作 - D4RL for Manipulation:离线数据集支持机器人抓取、推拉等任务
自动驾驶中的 RL
端到端学习: - 输入:传感器数据(摄像头、雷达) - 输出:转向、油门、刹车 - 用 RL 优化轨迹(最大化安全性、舒适性、效率)
模型基 RL: - 学习环境模型(预测其他车辆行为) - 在模型中规划(MCTS 、 MPC+RL)
挑战: - 安全性:探索可能危险(需要离线 RL 或高保真模拟) - 泛化:训练环境 vs 实际道路差异
公司应用: - Waymo:结合 RL 和模仿学习 - Tesla:端到端学习(尽管细节未公开)
多模态 RL:视觉-语言-动作
任务:给定语言指令,执行机器人任务 - 输入:"拿起红色杯子" - 输出:机器人动作序列
架构: - 视觉编码器:提取场景特征 -
语言编码器:理解指令 - 策略网络:条件策略
前沿工作: - CLIPort:用 CLIP 嵌入桥接语言和视觉 - RT-1, RT-2(Google):大规模机器人 Transformer,用语言条件 RL
深度问答
Q1: RLHF 为什么比 SFT 更有效?
SFT 的局限: - 学习"模仿"演示数据,但演示数据有限(如 InstructGPT 只有 13k 样本) - 无法泛化到未见过的提示类型 - 难以捕获"隐式"偏好(如"有礼貌"、"避免冗长")
RLHF 的优势: - 奖励模型能从大量比较数据学习(33k 比较 > 13k 演示) - 比较数据更容易标注(判断哪个更好,而非生成完美回复) - RL 优化直接针对人类偏好,而非似然
实验验证:InstructGPT 论文显示,RLHF 训练的 1.3B 模型优于 SFT 训练的 175B 模型。
Q2: DPO 为什么能绕过奖励模型?
数学洞察:DPO 发现 RLHF 的最优策略有闭式解:
反解出:
代入 Bradley-Terry 模型,偏好概率变为:
关键:这个式子只依赖策略
直接优化
Q3: RLAIF 会导致"模型坍塌"吗?
模型坍塌(Model Collapse): - 用 AI 生成数据训练 AI,多代后质量下降 - 原因:AI 生成数据的分布偏差累积
RLAIF 的风险: - 用 AI A(如 GPT-4)标注数据,训练 AI B - 如果 B 接近 A,再用 B 标注数据训练 C...可能坍塌
缓解策略:
- 混合人类数据:RLAIF+部分人类标注
- 多样化 AI 评估器:用多个模型投票
- 定期校准:每隔一段时间用人类数据重新校准
- 任务多样性:避免在单一分布上过拟合
实验证据:目前 RLAIF 论文(1-2 代训练)未观察到明显坍塌,但长期影响未知。
Q4: PPO 为什么是 RLHF 的首选算法?
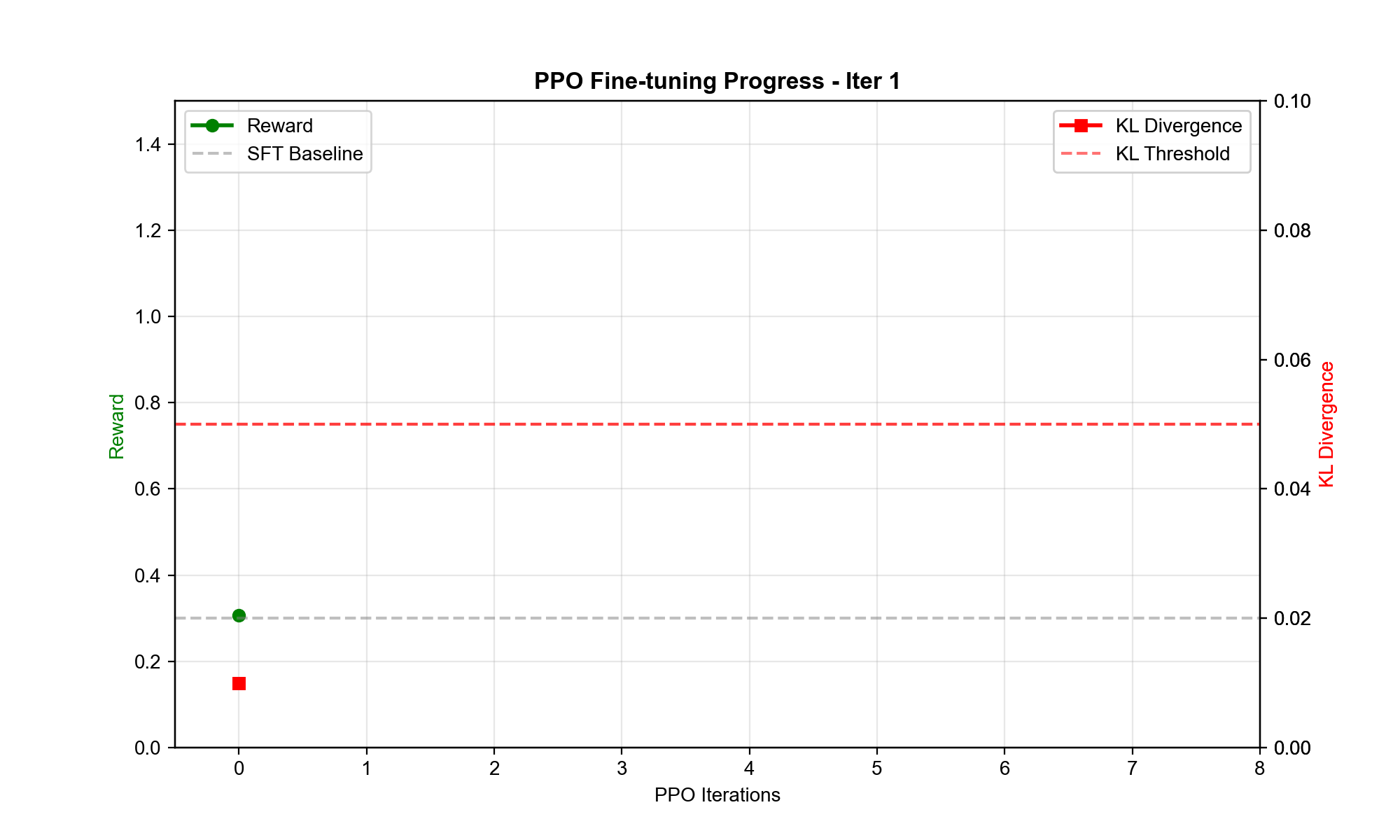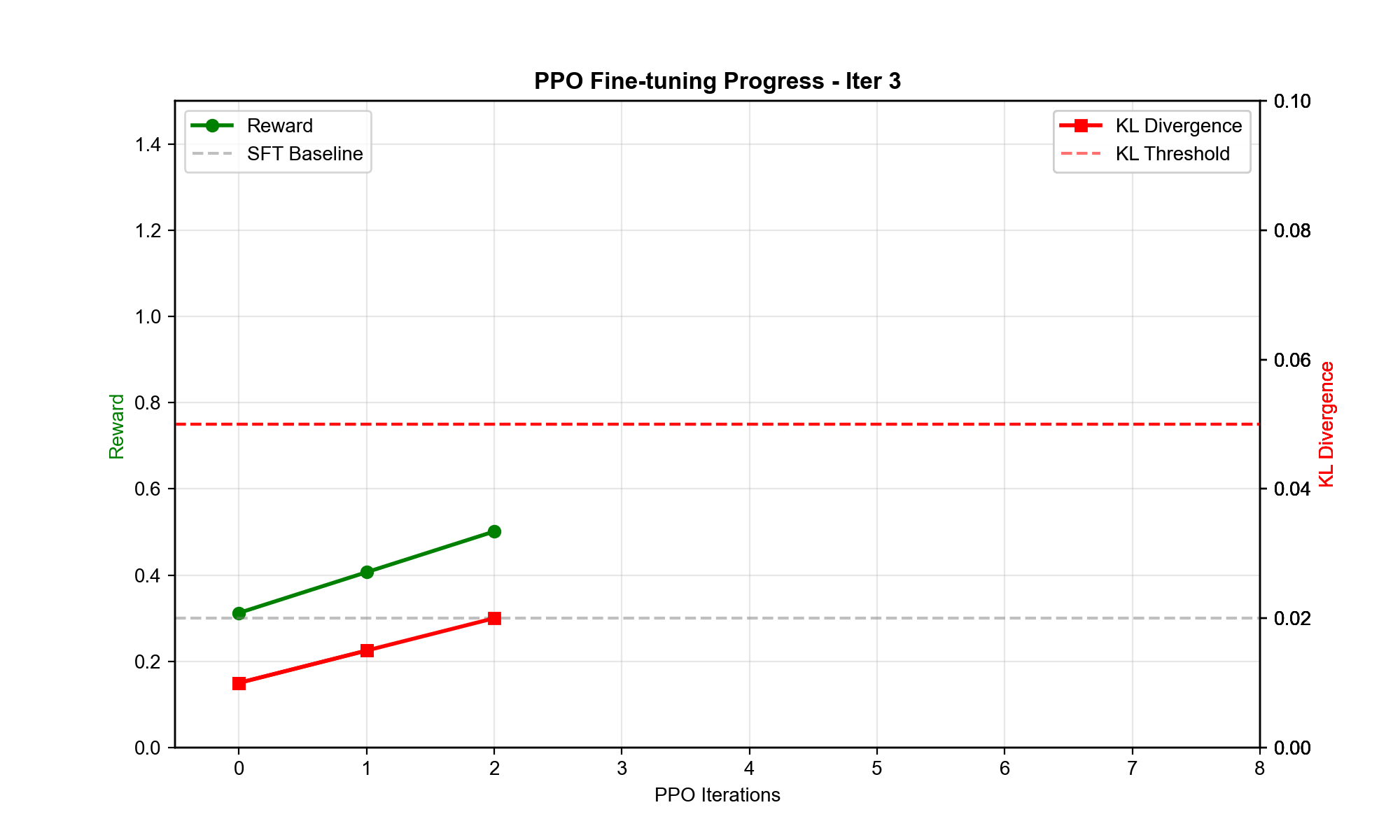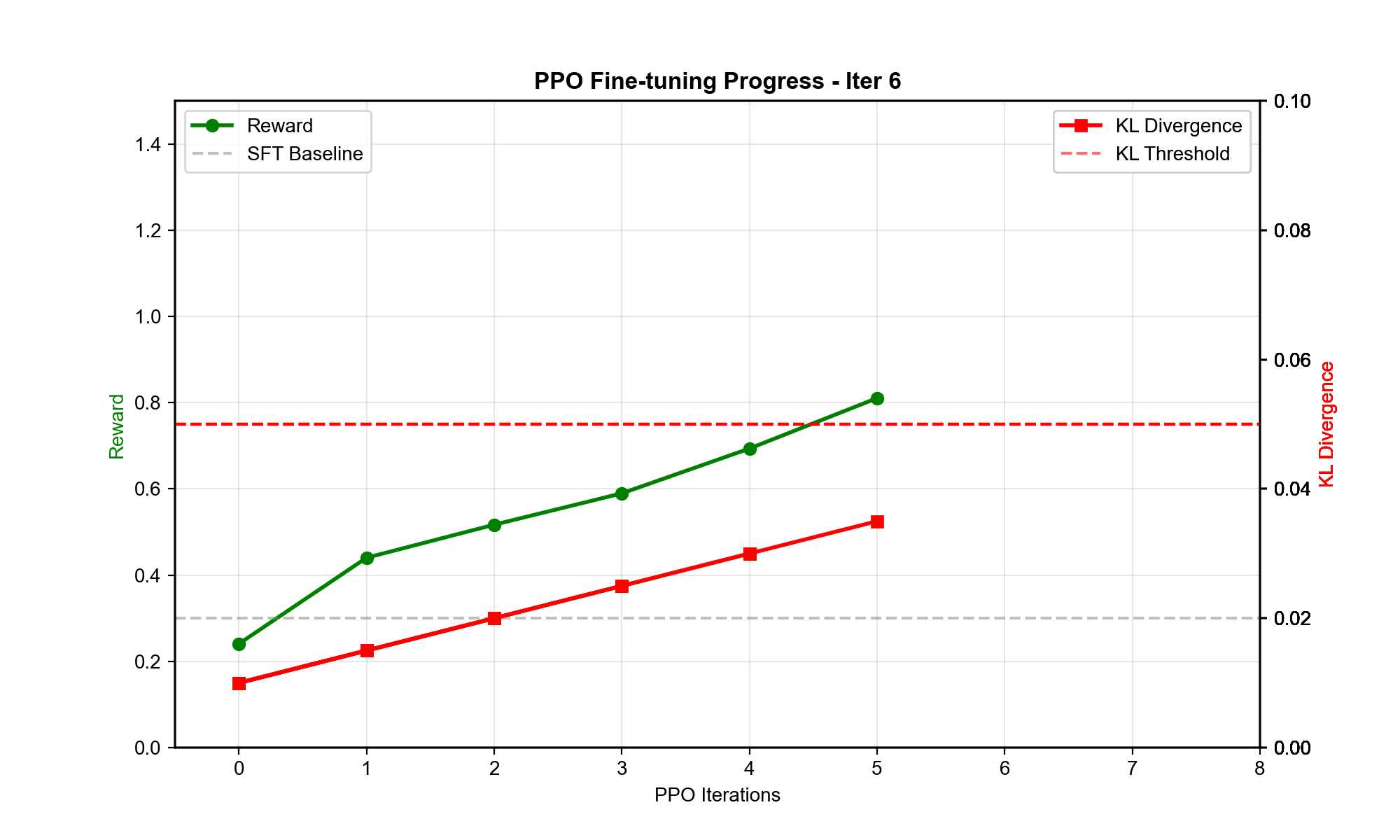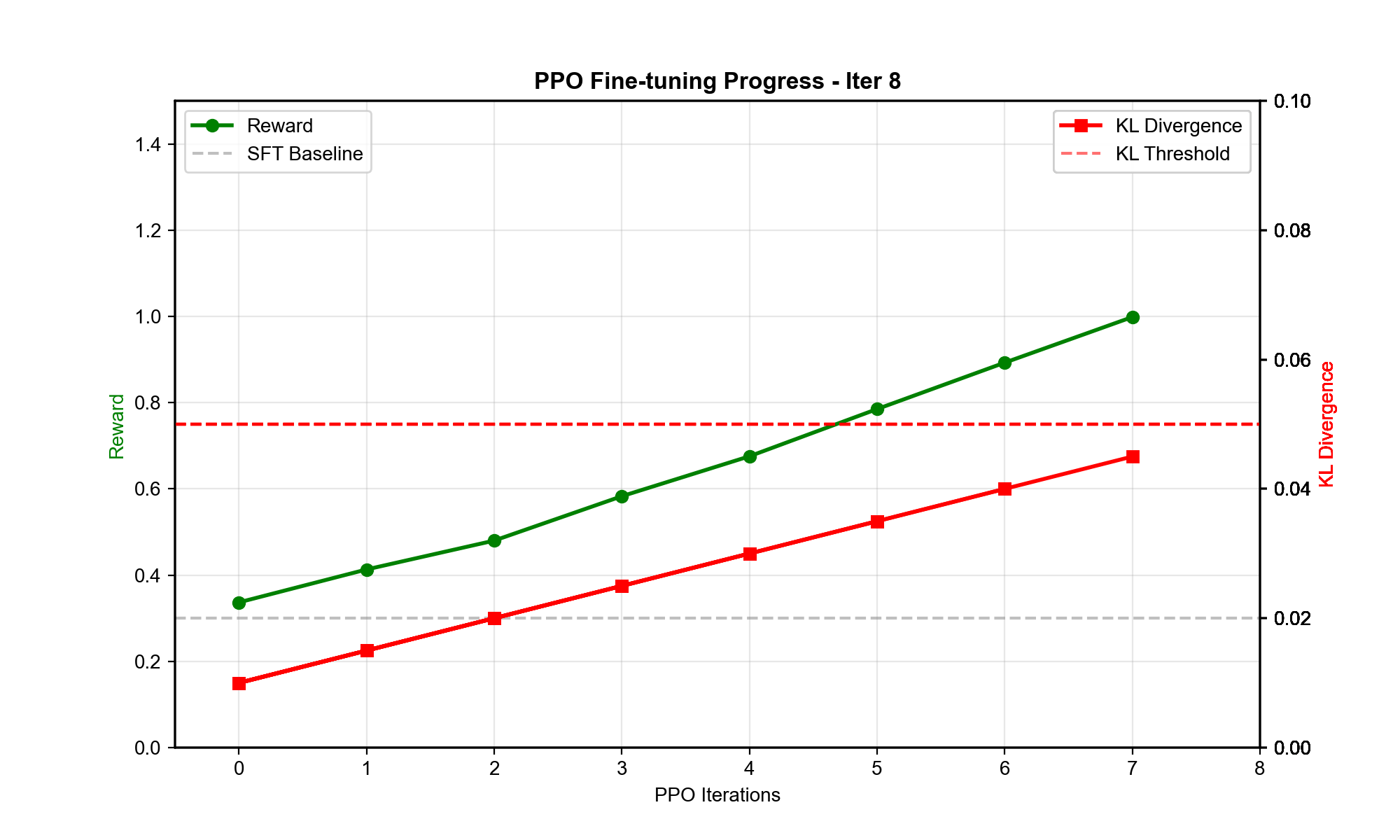
RL 算法对比:
DQN/Q-learning: - 适合离散动作 - LLM 的动作空间是词表(几万维),Q 函数难以表示
A3C/A2C: - 策略梯度+价值函数 - 训练不稳定(高方差)
PPO: - Clipped 目标限制策略更新幅度 - 减少灾难性更新(避免策略突然变差) - 易于实现,超参数鲁棒
RLHF 特定挑战: - LM 的动作空间巨大(每步选一个 token) - 奖励稀疏(只在序列结束时给奖励) - 需要稳定训练(避免遗忘 SFT 初始化)
PPO 的 clipping 和 KL 惩罚天然适合这些需求。
Q5: RLHF 如何处理多目标(有帮助、诚实、无害)?
朴素方法:加权组合奖励
挑战: - 权重
改进方法:
1. 多奖励模型: - 训练 3 个独立奖励模型 - RL 阶段用帕累托优化(多目标 RL)
2. Constitutional AI: - 用规则约束(如"必须拒绝有害请求") - 奖励模型只建模"有帮助"和"诚实"
3. 人类反馈指定权重: -
让用户选择偏好(如"我更看重安全性") - 根据用户偏好调整
Q6: Offline RL 在机器人中为何重要?
在线 RL 的困难: - 安全性:机器人探索可能损坏硬件或造成危险 - 时间成本:真实机器人交互慢(如抓取一次需数秒),收集百万样本不可行 - 数据浪费:已有大量人类演示数据,但在线 RL 从零开始
Offline RL 的优势: - 利用演示数据、历史任务数据 - 安全(无需在线探索) - 高效(并行训练)
挑战: - 数据分布偏移(演示数据 vs 最优策略) - 真实机器人动力学复杂(模拟数据难以迁移)
实践方案: - Offline 预训练(CQL 、 IQL) - Online 微调(少量安全探索) - 结合模型(学习动力学模型,在模型中规划)
Q7: 如何评估 RLHF 训练的模型?
自动指标: - 奖励模型评分:在
held-out 数据上,RM 预测的偏好准确率 - KL 散度:
人类评估: - 偏好率(Win Rate):人类比较模型输出 vs 基线,计算"胜率" - 绝对评分:Likert 量表(1-5 分)评估有帮助、诚实、无害 - 任务成功率:对特定任务(如代码生成),运行代码检查正确性
NLP 基准: - MMLU(多任务语言理解) - HumanEval(代码生成) - TruthfulQA(真实性) - 但 RLHF 可能在基准上表现下降(对齐税),实际用户体验提升
A/B 测试: - 部署两个版本(RLHF vs 基线),收集用户反馈 - ChatGPT 的成功很大程度上基于实际用户满意度
Q8: RLHF 训练中的"奖励黑客"是什么?
定义:策略学会利用奖励模型的漏洞,产生高奖励但实际质量差的输出。
实例: - 长度黑客:奖励模型可能偏好长文本,策略生成极长但重复/无意义的输出 - 格式黑客:奖励模型偏好特定格式(如列表),策略过度使用列表 - Sycophancy:策略学会"讨好"奖励模型,生成听起来好但实际错误的内容
原因: - 奖励模型是不完美代理(proxy),不完全等价于人类偏好 - RL 会过度优化代理目标
缓解方法: - KL 惩罚:限制策略偏离
SFT 初始化(在 RLHF 目标中加
Q9: Constitutional AI 与 RLHF 有何不同?
Constitutional AI(CAI): - Anthropic 提出,用预定义规则(constitution)引导训练 - 流程: 1. 模型生成输出 2. 用规则评估(如"是否有害?") 3. 模型自我修正(生成改进版本) 4. 用改进版本训练
与 RLHF 的区别:
RLHF: - 人类标注偏好数据 - 奖励模型隐式学习人类价值观
CAI: - 人类定义显式规则 - AI 评估是否遵守规则
优势: - 可解释:规则明确,易于审查 - 可控:直接修改规则改变行为 - 可扩展:无需大量人工标注
局限: - 规则难以穷尽(如何定义"有礼貌"?) - 规则可能冲突(如诚实 vs 无害)
实践中:CAI 和 RLHF 常结合使用(CAI 定义硬约束,RLHF 优化软偏好)。
Q10: RL 在 LLM 之后的未来方向?
1. 多模态 RLHF: - 不仅文本,还有图像、视频、音频 - 奖励模型评估多模态输出(如"这个视频是否有帮助?")
2. 在线 RLHF: - 持续从用户交互中学习 - 用户点赞/点踩作为实时反馈 - 挑战:分布偏移、隐私
3. 个性化 RLHF: - 每个用户有不同偏好 - 训练用户特定奖励模型 - Meta-learning 跨用户泛化
4. RL for 推理: - LLM 的推理能力仍有限(如数学、逻辑) - 用 RL 优化推理过程(如 AlphaGo 的 MCTS+RL) - 算法:Process Reward Model(PRM)、 STaR
5. RL for 具身智能: - LLM 作为高层规划器(生成子目标) - RL 训练低层执行器(机器人动作) - 语言-视觉-动作联合训练
6. 安全对齐: - 超越"有帮助、诚实、无害",研究长期安全 - AI 对齐理论(如 CIRL 、 IRL) - 机制设计(让 AI 目标与人类目标天然一致)
Q11: RT-1 和 RT-2(Google 的机器人 Transformer)如何工作?
RT-1(Robotics Transformer 1, 2022): -
输入:图像+语言指令 -
输出:机器人动作(离散化的关节角度、抓取状态) -
架构: - 视觉编码器:EfficientNet 提取图像特征 -
语言编码器:Universal Sentence Encoder 处理指令 - Transformer:Decoder
处理序列
RT-2(2023): - 改进:用预训练 VLM(Vision-Language Model)初始化 - backbone:PaLI-X(视觉-语言大模型) - 训练: 1. 在网页图像-文本数据上预训练 VLM 2. 在机器人数据上微调(co-fine-tuning:语言任务+机器人任务) - 效果:泛化能力显著提升(零样本推理新任务)
关键创新: - 大规模数据(RT-1:130k,RT-2:结合网页数据) - 多任务学习(一个模型处理 700+任务) - 语言条件(自然语言指令控制)
RL 的角色: - 主要用 BC(模仿学习) - RL 用于 online 微调(提升任务成功率)
Q12: RLHF 的计算成本有多高?
训练阶段成本估算(以 InstructGPT 175B 为例):
SFT: - 数据:13k 样本 - 计算:约等于在 13k 样本上微调 GPT-3(数小时,单机多卡)
奖励模型训练: - 数据:33k 比较 - 模型:6B 参数(比策略小) - 计算:数小时
PPO 微调: - 数据:256k 提示 - 每次迭代: - 生成:256k 个回复(每个几十 token) - 计算奖励:256k 次前向传播(RM+策略) - PPO 更新:多次梯度步(每次需要计算优势、 clip 等) - 总计算:约等于在百万级样本上训练数天(多机多卡)
对比: - 预训练 GPT-3:约 10^23 FLOPs(数千 GPU-月) - RLHF(SFT+RM+PPO):约 10^21 FLOPs(数十 GPU-月) - RLHF 约为预训练成本的 1-10%
DPO 的成本: - 跳过 RM 和 RL,直接监督学习 - 约等于 SFT 成本(数小时-数天) - 比 RLHF 低 1-2 个数量级
相关论文与资源
核心论文
RLHF:
InstructGPT:
Ouyang et al. (2022). "Training language models to follow instructions with human feedback". NeurIPS.
https://arxiv.org/abs/2203.02155ChatGPT Technical Report:
OpenAI (2022). Blog post.
https://openai.com/blog/chatgptRLHF Survey:
Wang et al. (2024). "A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO, DPO and More". arXiv.
https://arxiv.org/abs/2407.16216
DPO:
DPO:
Rafailov et al. (2023). "Direct Preference Optimization: Your Language Model is Secretly a Reward Model". NeurIPS.
https://arxiv.org/abs/2305.18290DPO Survey:
(2024). "A Survey of Direct Preference Optimization". arXiv.
RLAIF:
RLAIF:
Lee et al. (2023). "RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback". arXiv.
https://arxiv.org/abs/2309.00267Constitutional AI:
Bai et al. (2022). "Constitutional AI: Harmlessness from AI Feedback". arXiv.
https://arxiv.org/abs/2212.08073
具身智能:
RT-1:
Brohan et al. (2022). "RT-1: Robotics Transformer for Real-World Control at Scale". arXiv.
https://arxiv.org/abs/2212.06817RT-2:
Brohan et al. (2023). "RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control". arXiv.
https://arxiv.org/abs/2307.15818Dactyl:
OpenAI (2018). "Learning Dexterous In-Hand Manipulation". arXiv.
https://arxiv.org/abs/1808.00177
代码库
TRL(Transformer Reinforcement Learning):
https://github.com/huggingface/trl
HuggingFace 的 RLHF 库,支持 PPO 、 DPOOpenAI Baselines:
https://github.com/openai/baselines
包含 PPO 实现Anthropic's RLHF:
https://github.com/anthropics/hh-rlhf
Helpful & Harmless 数据集DeepSpeed-Chat:
https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-chat
高效 RLHF 训练
总结
强化学习从游戏 AI 走向语言模型对齐,再到具身智能,展现了其在塑造通用 AI 中的核心地位。
RLHF将人类价值观注入大语言模型: - 通过三阶段流程(SFT →奖励模型→ PPO),使模型生成更有帮助、诚实、无害的内容 - InstructGPT 和 ChatGPT 证明了 RLHF 的有效性,推动了 LLM 的大规模应用
DPO简化了 RLHF 的训练复杂度: - 直接从偏好数据优化策略,绕过奖励模型和 RL 采样 - 保持性能的同时降低计算成本,为 RLHF 的民主化提供可能
RLAIF用 AI 反馈替代人类标注: - 降低数据收集成本 10 倍以上,提升可扩展性 - Constitutional AI 等方法结合规则与 AI 反馈,增强可控性
具身智能中的 RL: - 从离线演示数据到在线微调,RL 帮助机器人学习复杂操作 - 多模态学习(语言-视觉-动作)开启通用智能体的新篇章
未来,强化学习将与大规模预训练、多模态学习、因果推理深度融合——从对话助手到自动驾驶,从科研助手到家庭机器人,RL 正在定义 AI 与人类交互的新范式。强化学习系列至此完结,但 RL 的征程才刚刚开始。
- 本文标题:强化学习(十二)—— RLHF 与大语言模型应用
- 本文作者:Chen Kai
- 创建时间:2024-10-04 15:00:00
- 本文链接:https://www.chenk.top/%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0%EF%BC%88%E5%8D%81%E4%BA%8C%EF%BC%89%E2%80%94%E2%80%94-RLHF%E4%B8%8E%E5%A4%A7%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%E5%BA%94%E7%94%A8/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!