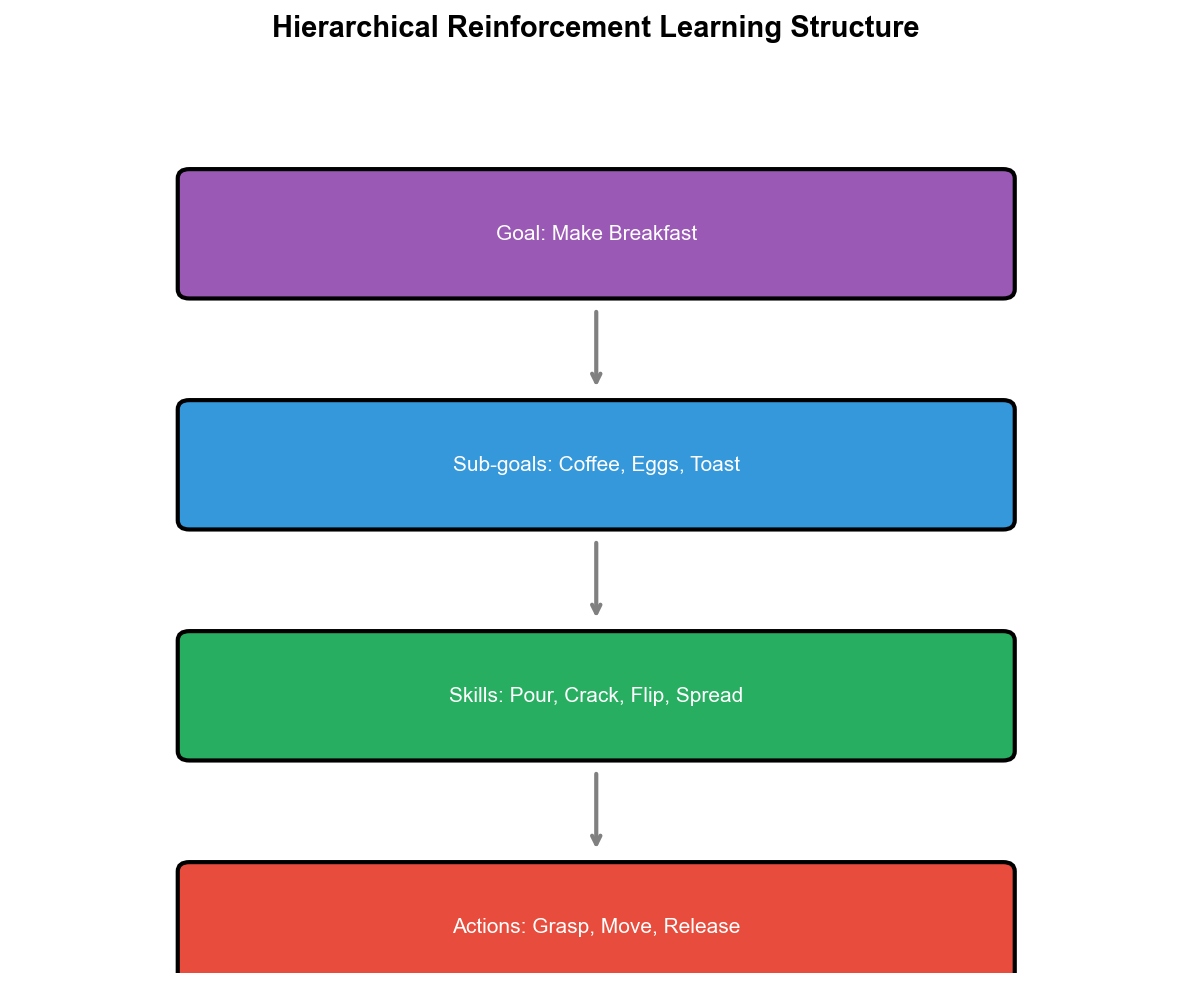
传统强化学习将复杂任务视为扁平的决策序列——每个时间步选择原子动作,通过时序差分逐步优化策略。这种范式在简单任务上有效,但在需要长期规划、多层次决策的任务中(如机器人操作、游戏通关、自动驾驶),学习效率低下且难以泛化。人类解决复杂问题时采用层次化策略:将大目标分解为子目标(如"做早餐"分解为"煮咖啡"、"煎鸡蛋"、"烤面包"),每个子目标对应一组时间延展的动作序列。层次化强化学习(Hierarchical
RL)正是将这种层次化思维引入 RL ——通过时间抽象(Temporal
Abstraction)学习多层次策略,提升样本效率和可解释性。与此同时,传统 RL
在新任务上需要从零开始学习,而人类能够快速适应新场景(如学会骑自行车后快速学会骑摩托车)。元强化学习(Meta-RL)研究如何"学会学习"——在多个相关任务上训练,使智能体在新任务上仅用少量样本就能快速适应。从
Options 的半马尔可夫决策过程到 MAML 的二阶梯度优化,从 MAXQ 的价值分解到
RL
²的记忆增强,层次化与元学习展现了强化学习在结构化和泛化上的巨大潜力。本章将系统梳理这些前沿方法,并通过完整代码帮助你实现
Options 和 MAML 算法。
层次化强化学习:时间抽象与
Options 框架
为什么需要层次化?
扁平 RL 的局限 : -
长期信用分配困难 :在长 episode 中(如 1000
步),难以确定哪些动作导致了最终奖励 -
探索低效 :原子动作的探索空间随时间指数增长,策略不可复用 :在"开门"任务学到的策略无法迁移到"开窗"任务
-
难以解释 :扁平策略是状态到动作的黑盒映射,缺乏人类可理解的结构
层次化的优势 : -
时间抽象 :将多步动作打包为"宏动作"(macro-action),减少决策点
- 模块化 :学习可复用的子策略(如"走到门前"、"转动把手") -
更快探索 :在抽象层次上探索,每步"跨越"更多状态 -
可解释性 :策略分解为高层目标和低层执行,易于理解和调试
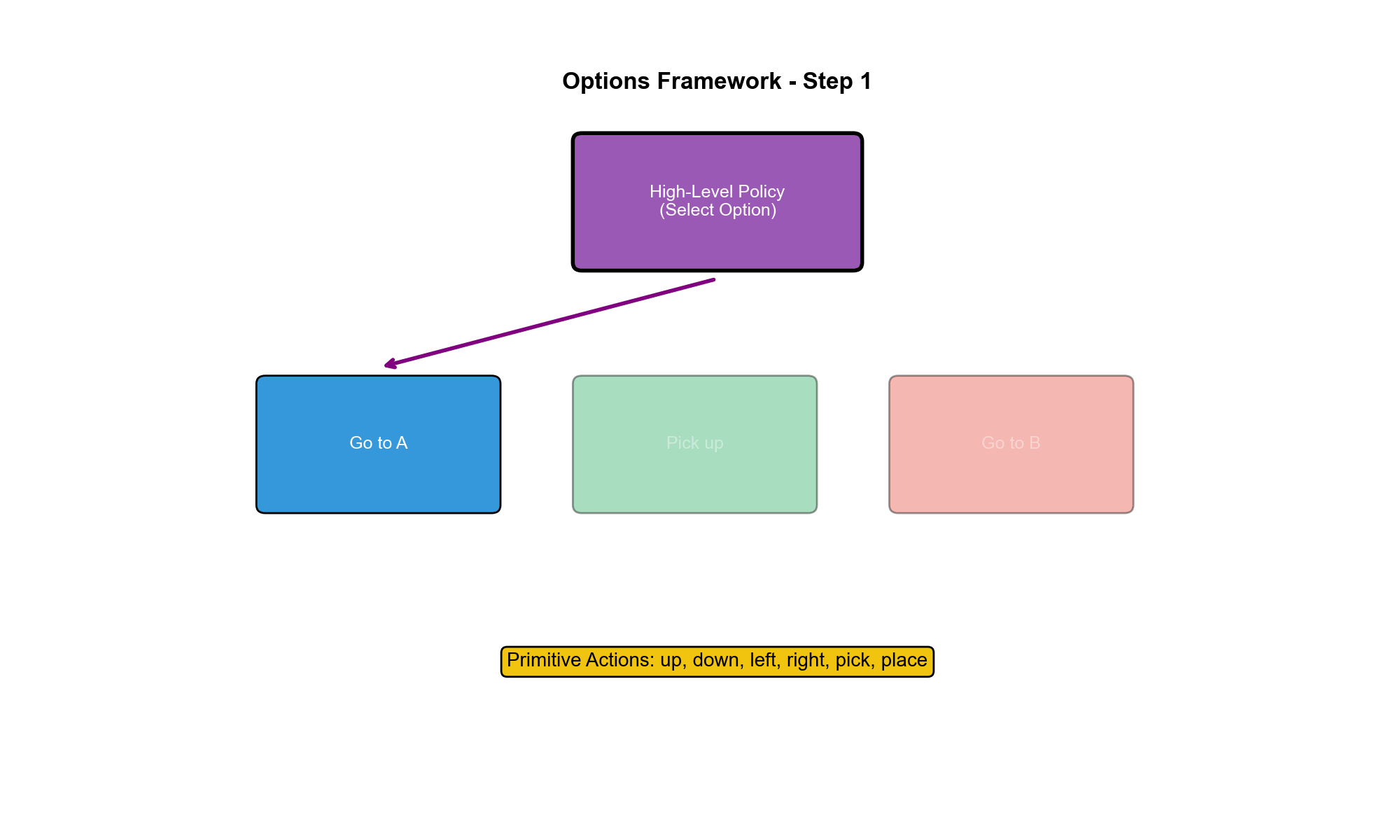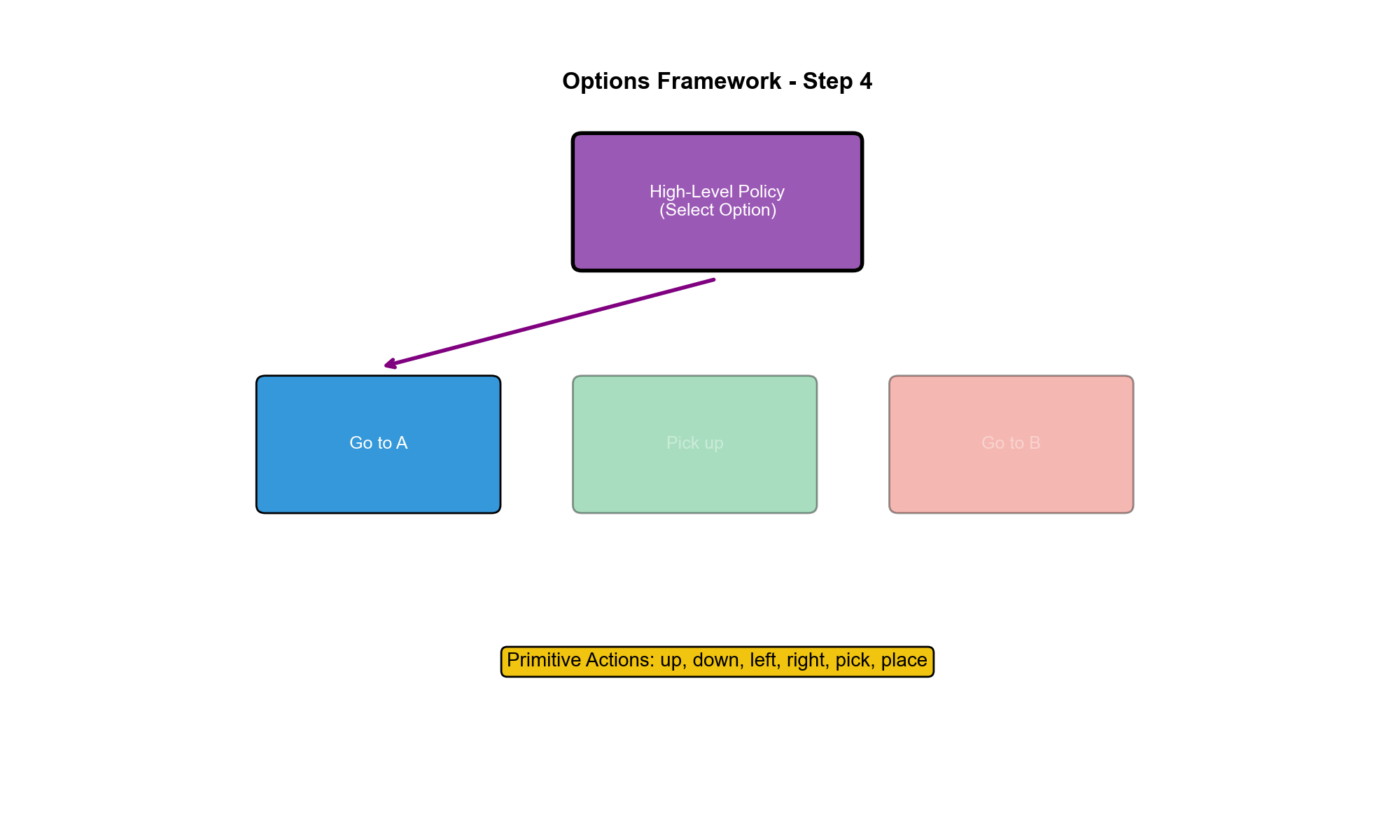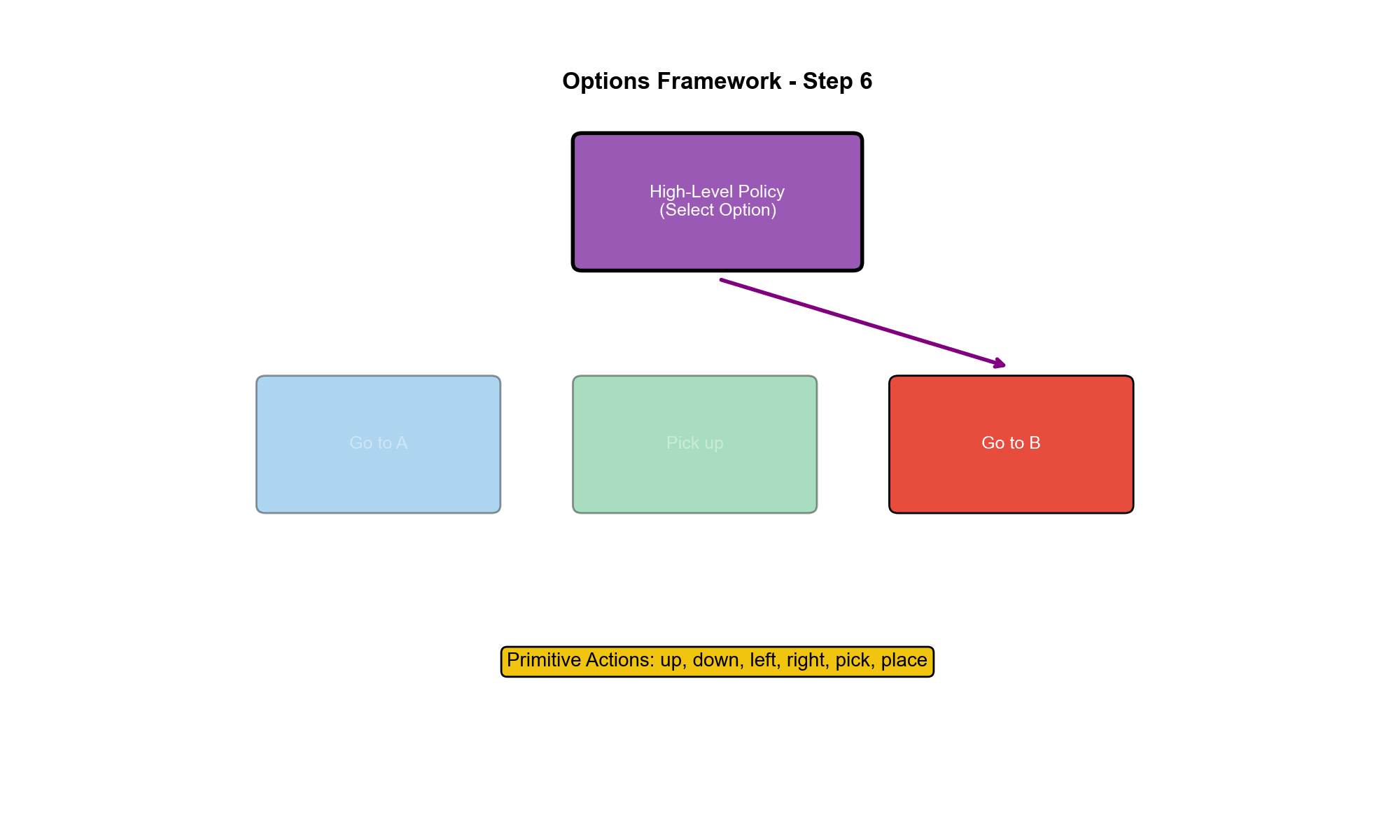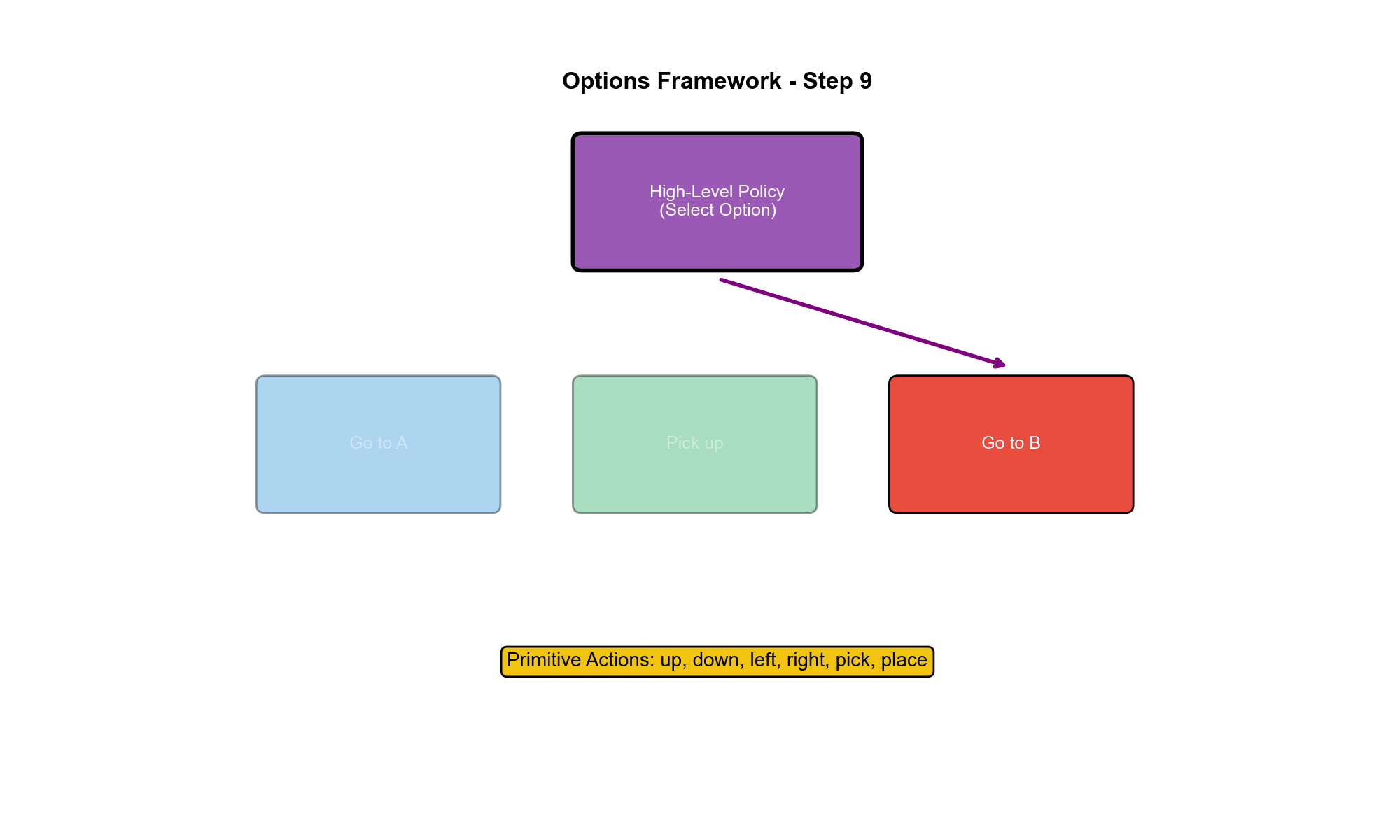
Options
框架:半马尔可夫决策过程
Options 定义 :一个 Option初始集 $ 内部策略 终止条件
执行流程 :
在状态$s 按 照
选择下一个 Option,重复
与 MDP 的关系 :Options 将原始 MDP
转化为半马尔可夫决策过程 (SMDP): -
状态空间不变,但动作空间从
价值函数 :定义 Option-value 函数
其中
Bellman 方程 :
其中
Options
的学习:Intra-Option Q-Learning
核心思想 :不需要等待 Option
执行完毕,可以在Option 执行过程中的每一步 更新 Q 值。
Intra-Option 更新 :假设当前执行 Option
其中
直觉 : - 如果 Option 在
优势 : - 每步都能更新,不浪费经验 - 支持 off-policy
学习(当前执行
Options 的发现:自动学习子目标
手工设计 Options
的问题 :需要领域知识,难以扩展到新任务。
自动发现方法 :
1. 基于瓶颈状态(Bottleneck States) : -
分析状态转移图,找到"必经之地"(如房间之间的门) -
将瓶颈状态作为子目标,训练到达该状态的 Option - 算法:Betweenness
Centrality 、 Graph Clustering
2. 基于状态覆盖(State Coverage) : - 训练多样化的
Options,最大化访问状态的多样性 - 目标:
3. 基于技能学习(Skill Learning) : -
用无监督学习发现有用的行为原语 - 目标:最大化互信息
DIAYN 算法 : - 学习技能策略
四房间实验:Options 的经典案例
环境 :一个格子世界,4
个房间,房间间有通道,智能体从随机位置出发,到达目标位置。
手工 Options : - 4 个 Options,每个对应"走到房间 X
的出口" - 初始集:房间 X 的所有格子 - 终止条件:到达出口
实验结果 : - 使用 Options 的 Q-learning 比原始
Q-learning 快 3-5 倍 - Options 可以在不同目标位置间复用,无需重新训练
代码实现 见后文。
MAXQ:价值函数分解
核心思想:任务层次化与价值分解
MAXQ 将复杂任务分解为任务层次图 (Task Hierarchy
Graph): - 根节点:主任务(如"做早餐") -
中间节点:子任务(如"煮咖啡"、"煎鸡蛋") -
叶节点:原子动作(如"开火"、"倒水")
价值函数分解 :每个任务完成值 完成后值
递归定义 :
叶节点 (原子动作
非叶节点 (复合任务
MAXQ 的学习算法
MAXQ-Q Learning :递归更新
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def MAXQ-Q(task i, state s): if i 是叶节点(原子动作): 执行动作 i, 观测 r, s' return (r, s', 1) # (奖励, 新状态, 步数) while s 不是 i 的终止状态: 选择子任务 a = argmax_a [V(a, s) + C(i, s, a)] (r, s', N) = MAXQ-Q(a, s) # 递归执行 # 更新 V(a, s) V(a, s) += alpha * [r + gamma^N * V(a, s') - V(a, s)] # 更新 C(i, s, a) C(i, s, a) += alpha * [gamma^N * V(i, s') - C(i, s, a)] s = s' return (累积奖励, s, 总步数)
关键特性 : - 状态抽象 :子任务并行学习 :多个父任务可以共享子任务的收敛保证 :在 Tabular 设置下,MAXQ-Q
收敛到分层最优策略(hierarchically optimal policy)
MAXQ 的优势与局限
优势 : -
样本效率 :价值分解和状态抽象减少需要学习的参数 -
可迁移性 :子任务的可解释性 :任务层次图明确展示决策逻辑
局限 : -
需要手工设计任务层次 :实践中难以自动发现最优分解 -
仅收敛到分层最优 :可能不是全局最优(因为受限于预定义的层次结构)
- Tabular
限制 :扩展到大规模状态空间需要函数逼近,但收敛性证明不再成立
Feudal
强化学习:目标条件层次化
Feudal RL 的思想
封建系统类比 : -
Manager(高层) :设定子目标(如"去坐标(10, 5)") -
Worker(低层) :执行原子动作达到子目标
与 Options 的区别 : - Options 的高层策略选择离散的
Options - Feudal RL 的 Manager
输出连续的子目标 (goal),Worker 学习条件策略
FuN: FeUdal Networks
for Hierarchical RL
架构 : - Manager :每Worker :学习策略
Manager 的目标 :最大化外在奖励:
Worker 的目标 :最大化内在奖励(接近子目标):
其中
训练 : - Worker 用 A3C 训练,优化内在奖励 - Manager
用策略梯度训练,优化外在奖励 - 梯度通过 Worker 传播到 Manager(Worker
的状态嵌入是 Manager 的输入)
优势 : - 自动学习子目标,无需手工设计 - Manager
关注长期规划,Worker 关注短期执行 - 在 Atari 游戏(如 Montezuma's
Revenge)上显著提升性能
HIRO: Data Efficient
Hierarchical RL
改进 :FuN 的训练不稳定(Manager 和 Worker
的目标可能冲突)。 HIRO 提出 off-policy 修正:
核心思想 : - Manager 每重标记 (relabeling)后的子目标
重标记机制 :对于转移
即"假装 Manager 的目标就是实际到达的地方",这样 Worker
总能学到有效的经验。
效果 :HIRO 在连续控制任务(如 Ant Maze)上比 FuN
更稳定,样本效率提升 2-3 倍。
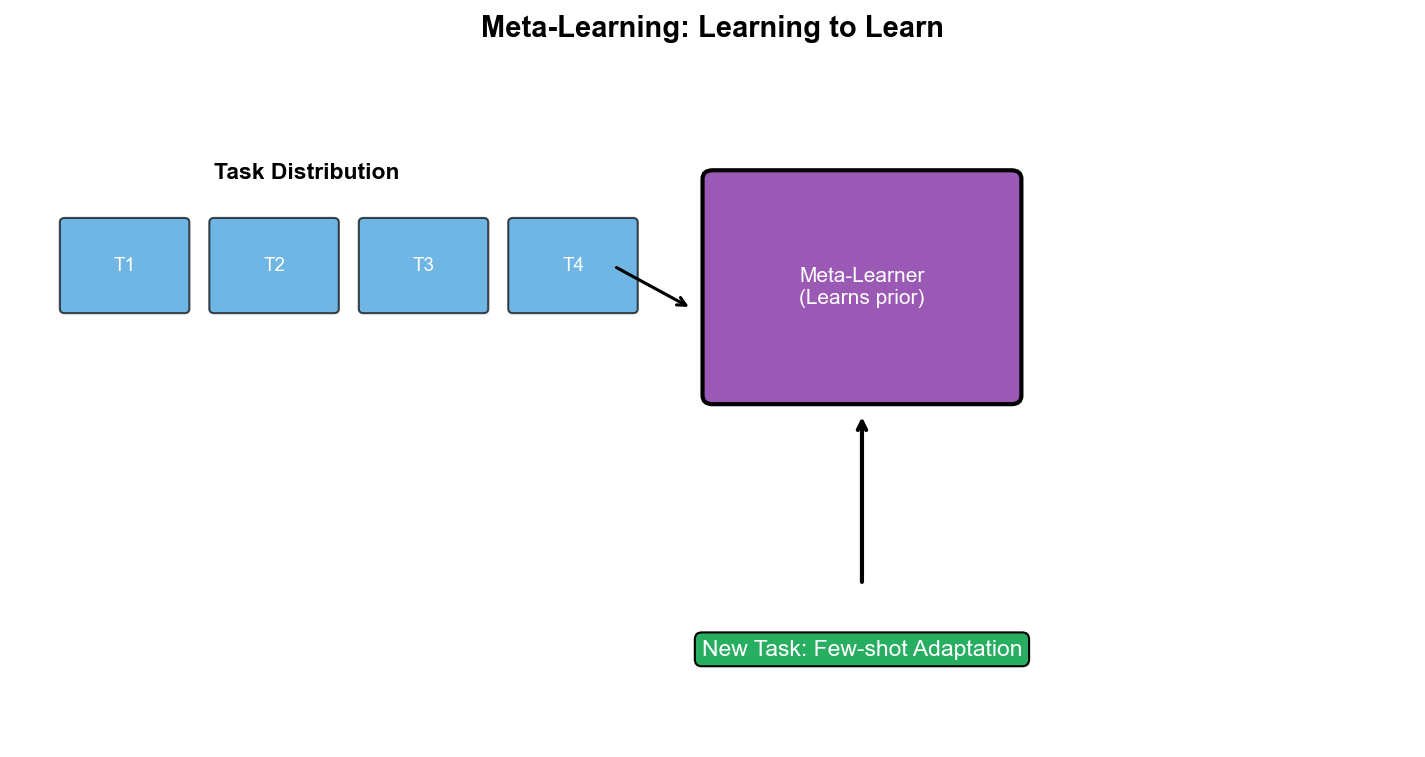
元强化学习:学会快速学习
传统 RL 的局限 : -
每个新任务从零开始学习,浪费相似任务的知识 -
样本效率低,需要数百万步才能收敛 - 无法像人类那样"举一反三"
Meta-RL 的目标 : - 在多个相关任务元策略 或元参数 -
在新任务
应用场景 : -
机器人:在不同物体、重量、摩擦系数下快速适应抓取策略 -
游戏:快速学习新关卡、新角色 - 推荐系统:快速适应新用户偏好
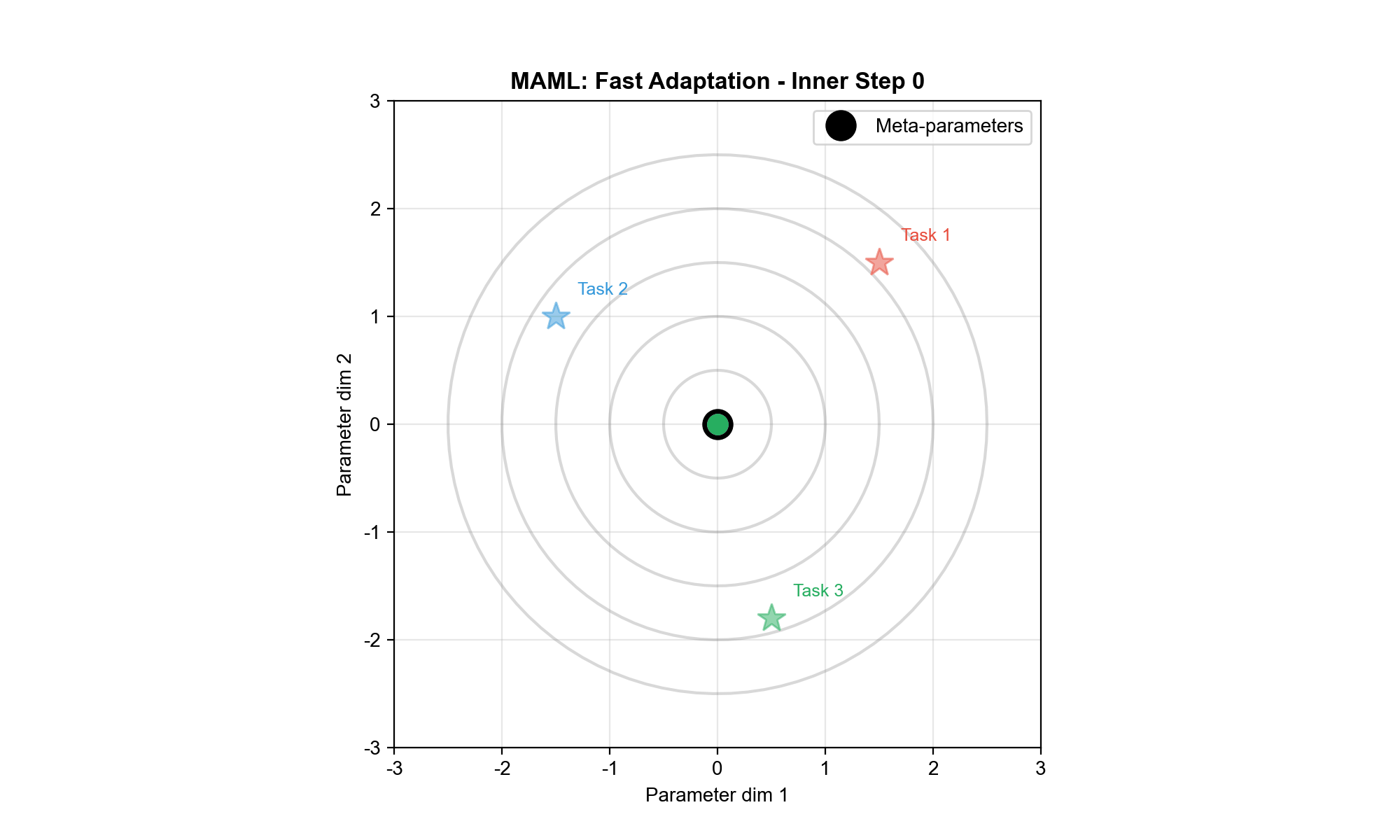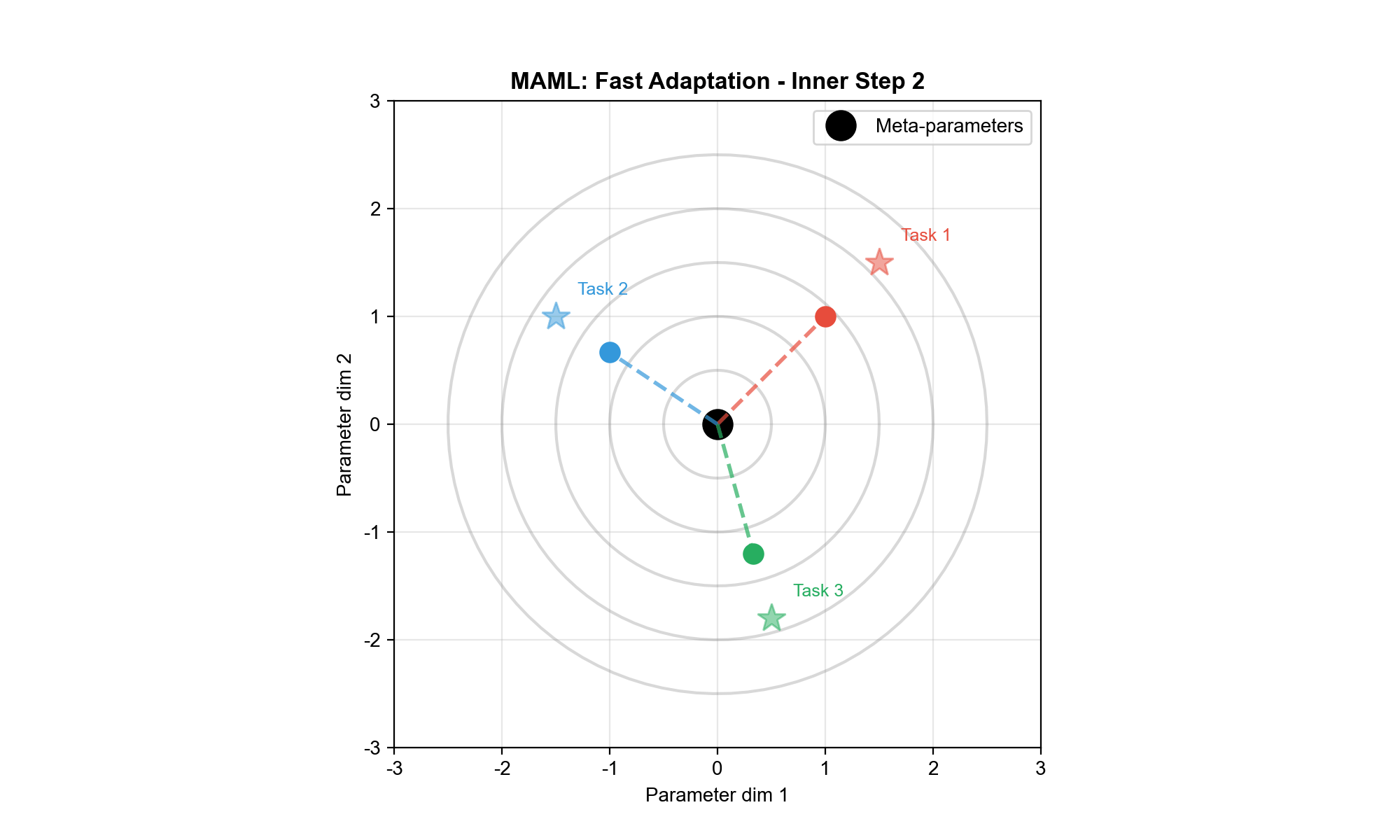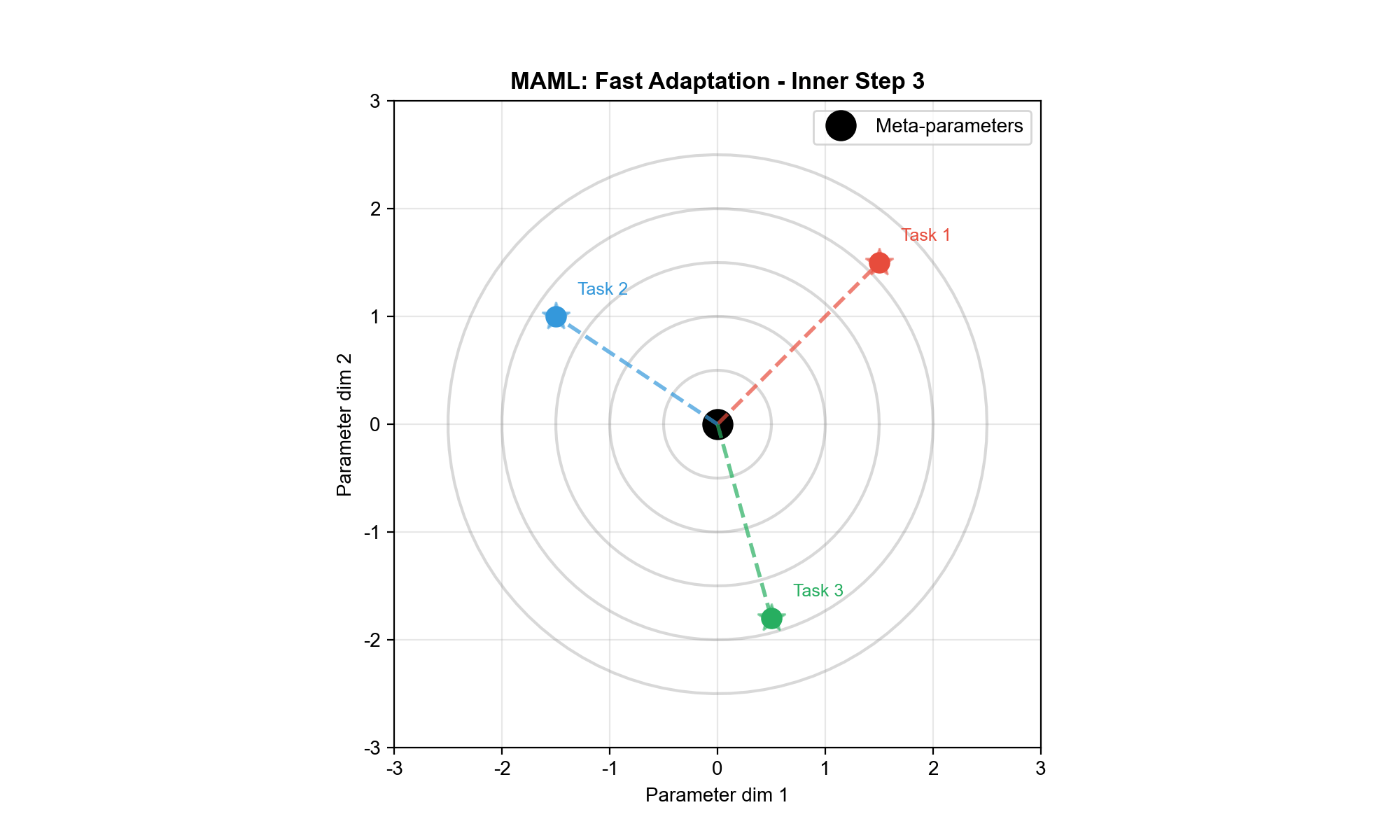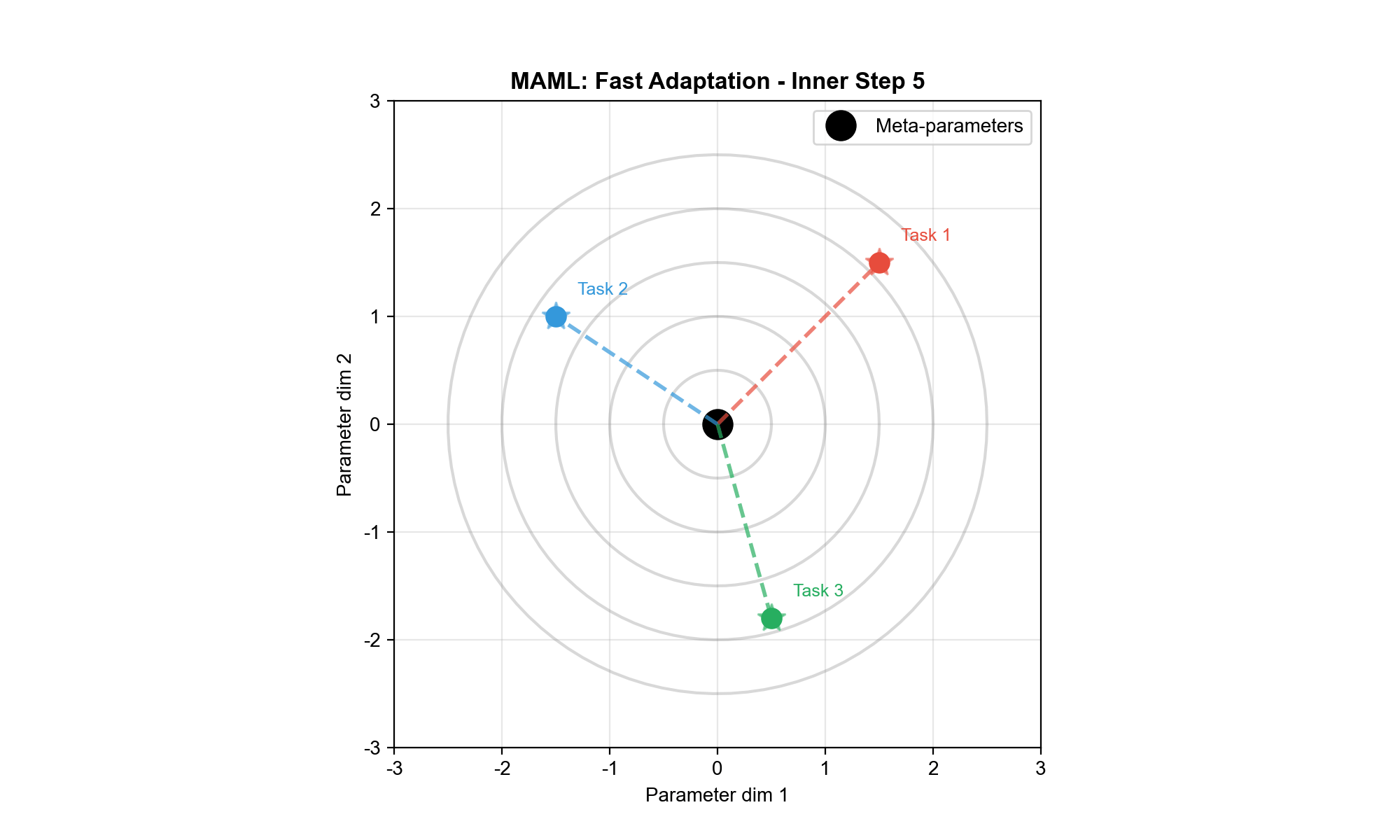
MAML:模型无关元学习
核心思想 :学习一个"好的初始化"参数
算法流程 :
元训练 :
采样任务批次
对每个任务
从
做一步梯度更新:
用
元优化:
元测试 :
给定新任务
从
用
数学形式 :
关键 :这是二阶梯度优化 ——元损失对
展开:
其中
FOMAML (First-Order MAML):忽略二阶项,只用:
实践中 FOMAML 性能接近 MAML,但计算更快。
RL
²:通过慢强化学习实现快强化学习
核心思想 :用 RNN 记忆历史经验,将"学习"编码为 RNN
的隐状态更新。
架构 : - 输入:
与 MAML 的区别 : - MAML 显式做梯度更新适应新任务 - RL
²隐式通过 RNN 记忆适应新任务(RNN 的隐状态
训练过程 : - 每个 episode 开始时,RNN
隐状态重置为第二个及之后 episode 的回报 (第一个
episode 用于探索)
效果 :RL ²在 Bandit 问题、 Tabular MDP
上快速适应新任务,但在复杂环境中(如 Mujoco)不如 MAML 稳定。
元学习的挑战与前沿
挑战 : - 任务分布 :Meta-RL
假设训练任务和测试任务来自同一分布元过拟合 :在训练任务上过拟合,泛化到新任务时失败 -
计算成本 :MAML 的二阶梯度计算昂贵,FOMAML
牺牲部分性能
前沿方向 :
1. 无监督 Meta-RL : -
不依赖任务标签,从单个环境中自动构造任务分布 - 算法:CARML 、 UML
2. 模型基 Meta-RL : - 学习环境模型,在模型中快速适应 -
算法:MAESN 、 Context-based Meta-RL
3. Transformer for Meta-RL : - 用 Transformer 替代
RNN,处理长序列 - 算法:Decision Transformer + Meta-learning
4. Directed-MAML (2024 新进展): -
用任务导向近似减少二阶梯度计算 - 在 CartPole 、 LunarLander 上超越
MAML
完整代码实现:Options in
四房间
下面实现 Options 框架在四房间环境中的应用,包括: - 四房间环境构建 -
手工定义 Options(到达各房间出口) - Intra-Option Q-learning 训练 - 与原始
Q-learning 对比
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 import numpy as npimport matplotlib.pyplot as pltfrom collections import defaultdictclass FourRoomsEnv : """四房间格子世界 Layout (13x13): ######|##### # | # # | # # # # | # # | # ------+------ # | # # | # # # # | # # | # ######|##### """ def __init__ (self, size=13 ): self.size = size self.grid = np.zeros((size, size), dtype=int ) self.grid[:, size//2 ] = 1 self.grid[size//2 , :] = 1 self.grid[size//2 , size//4 ] = 0 self.grid[size//2 , 3 *size//4 ] = 0 self.grid[size//4 , size//2 ] = 0 self.grid[3 *size//4 , size//2 ] = 0 self.actions = [(-1 , 0 ), (0 , 1 ), (1 , 0 ), (0 , -1 )] self.rooms = { 0 : [(i, j) for i in range (size//2 ) for j in range (size//2 ) if self.grid[i, j] == 0 ], 1 : [(i, j) for i in range (size//2 ) for j in range (size//2 +1 , size) if self.grid[i, j] == 0 ], 2 : [(i, j) for i in range (size//2 +1 , size) for j in range (size//2 ) if self.grid[i, j] == 0 ], 3 : [(i, j) for i in range (size//2 +1 , size) for j in range (size//2 +1 , size) if self.grid[i, j] == 0 ], } self.hallways = [ (size//2 , size//4 ), (size//4 , size//2 ), (3 *size//4 , size//2 ), (size//2 , 3 *size//4 ), ] def reset (self, goal=None ): """随机初始化位置""" while True : self.agent_pos = (np.random.randint(0 , self.size), np.random.randint(0 , self.size)) if self.grid[self.agent_pos] == 0 : break if goal is None : while True : self.goal_pos = (np.random.randint(0 , self.size), np.random.randint(0 , self.size)) if self.grid[self.goal_pos] == 0 and self.goal_pos != self.agent_pos: break else : self.goal_pos = goal return self.agent_pos def step (self, action ): """执行动作""" dy, dx = self.actions[action] new_pos = (self.agent_pos[0 ] + dy, self.agent_pos[1 ] + dx) if 0 <= new_pos[0 ] < self.size and 0 <= new_pos[1 ] < self.size and self.grid[new_pos] == 0 : self.agent_pos = new_pos done = (self.agent_pos == self.goal_pos) reward = 1.0 if done else -0.01 return self.agent_pos, reward, done def get_room (self, pos ): """获取位置所在的房间 ID""" for room_id, positions in self.rooms.items(): if pos in positions: return room_id return -1 class Option : """Option = (initiation_set, policy, termination)""" def __init__ (self, name, initiation_set, goal_states ): self.name = name self.initiation_set = initiation_set self.goal_states = goal_states self.policy = {} def can_initiate (self, state ): """是否可以在 state 启动""" return state in self.initiation_set def should_terminate (self, state ): """是否应该在 state 终止""" return state in self.goal_states def act (self, state, epsilon=0.1 ): """根据内部策略选择动作""" if state not in self.policy: return np.random.randint(4 ) if np.random.rand() < epsilon: return np.random.randint(4 ) return self.policy[state] def create_options (env ): """为四房间环境创建 4 个 Options,每个对应一个房间的出口""" options = [] for room_id in range (4 ): option = Option( name=f"GoToHallway{room_id} " , initiation_set=env.rooms[room_id], goal_states=[env.hallways[room_id]] ) options.append(option) return options class IntraOptionQLearning : def __init__ (self, env, options, alpha=0.5 , gamma=0.99 , epsilon=0.1 ): self.env = env self.options = options self.alpha = alpha self.gamma = gamma self.epsilon = epsilon self.Q = defaultdict(lambda : np.zeros(len (options))) self.Q_primitive = defaultdict(lambda : np.zeros(4 )) def select_option (self, state ): """ε-greedy 选择 Option""" available_options = [i for i, o in enumerate (self.options) if o.can_initiate(state)] if not available_options: return None if np.random.rand() < self.epsilon: return np.random.choice(available_options) q_values = self.Q[state][available_options] return available_options[np.argmax(q_values)] def train_episode (self ): """训练一个 episode""" state = self.env.reset() total_reward = 0 steps = 0 while steps < 1000 : option_id = self.select_option(state) if option_id is None : break option = self.options[option_id] while not option.should_terminate(state) and steps < 1000 : action = option.act(state, self.epsilon) next_state, reward, done = self.env.step(action) total_reward += reward steps += 1 if option.should_terminate(next_state): U = np.max (self.Q[next_state]) else : U = self.Q[next_state][option_id] self.Q[state][option_id] += self.alpha * (reward + self.gamma * U - self.Q[state][option_id]) self.Q_primitive[state][action] += self.alpha * (reward + self.gamma * np.max (self.Q_primitive[next_state]) - self.Q_primitive[state][action]) option.policy[state] = np.argmax(self.Q_primitive[state]) state = next_state if done: return total_reward, steps return total_reward, steps class FlatQLearning : def __init__ (self, env, alpha=0.5 , gamma=0.99 , epsilon=0.1 ): self.env = env self.alpha = alpha self.gamma = gamma self.epsilon = epsilon self.Q = defaultdict(lambda : np.zeros(4 )) def train_episode (self ): state = self.env.reset() total_reward = 0 steps = 0 while steps < 1000 : if np.random.rand() < self.epsilon: action = np.random.randint(4 ) else : action = np.argmax(self.Q[state]) next_state, reward, done = self.env.step(action) self.Q[state][action] += self.alpha * (reward + self.gamma * np.max (self.Q[next_state]) - self.Q[state][action]) total_reward += reward steps += 1 state = next_state if done: break return total_reward, steps def run_comparison (num_episodes=500 , num_trials=10 ): """对比 Options 和扁平 Q-learning""" results = { 'options' : {'rewards' : [], 'steps' : []}, 'flat' : {'rewards' : [], 'steps' : []} } for trial in range (num_trials): print (f"Trial {trial+1 } /{num_trials} " ) env_opt = FourRoomsEnv() env_flat = FourRoomsEnv() options = create_options(env_opt) agent_opt = IntraOptionQLearning(env_opt, options) rewards_opt = [] steps_opt = [] for ep in range (num_episodes): r, s = agent_opt.train_episode() rewards_opt.append(r) steps_opt.append(s) results['options' ]['rewards' ].append(rewards_opt) results['options' ]['steps' ].append(steps_opt) agent_flat = FlatQLearning(env_flat) rewards_flat = [] steps_flat = [] for ep in range (num_episodes): r, s = agent_flat.train_episode() rewards_flat.append(r) steps_flat.append(s) results['flat' ]['rewards' ].append(rewards_flat) results['flat' ]['steps' ].append(steps_flat) avg_rewards_opt = np.mean(results['options' ]['rewards' ], axis=0 ) avg_rewards_flat = np.mean(results['flat' ]['rewards' ], axis=0 ) avg_steps_opt = np.mean(results['options' ]['steps' ], axis=0 ) avg_steps_flat = np.mean(results['flat' ]['steps' ], axis=0 ) plt.figure(figsize=(14 , 5 )) plt.subplot(1 , 2 , 1 ) plt.plot(avg_rewards_opt, label='Intra-Option Q-Learning' , linewidth=2 ) plt.plot(avg_rewards_flat, label='Flat Q-Learning' , linewidth=2 ) plt.xlabel('Episode' ) plt.ylabel('Average Reward' ) plt.title('Learning Curves: Rewards' ) plt.legend() plt.grid(True ) plt.subplot(1 , 2 , 2 ) plt.plot(avg_steps_opt, label='Intra-Option Q-Learning' , linewidth=2 ) plt.plot(avg_steps_flat, label='Flat Q-Learning' , linewidth=2 ) plt.xlabel('Episode' ) plt.ylabel('Steps to Goal' ) plt.title('Learning Curves: Steps' ) plt.legend() plt.grid(True ) plt.tight_layout() plt.savefig('options_vs_flat.png' , dpi=300 ) print ("图表已保存为 options_vs_flat.png" ) return results if __name__ == "__main__" : print ("开始四房间 Options 实验..." ) results = run_comparison(num_episodes=500 , num_trials=10 ) print ("实验完成!" ) print (f"Options 最终平均奖励: {np.mean([r[-50 :] for r in results['options' ]['rewards' ]]):.2 f} " ) print (f"Flat Q 最终平均奖励: {np.mean([r[-50 :] for r in results['flat' ]['rewards' ]]):.2 f} " )
代码解析
四房间环境 : - 13x13 格子,4 个房间,房间间有门 -
智能体从随机位置出发,到达目标位置获得奖励
Options 定义 : - 4 个 Options,每个对应"走到房间 X
的出口" - 初始集:房间内所有位置 - 终止条件:到达出口(门)
Intra-Option Q-Learning : -
高层:Q(s, o)选择 Option - 低层:Option
内部策略π_o(a|s)执行原子动作 -
更新:每步都更新Q(s, o),用 continuation value
实验结果 (预期): - Options 在前 100 episode
收敛更快(因为探索空间更小) - 最终性能相近,但 Options 的 steps
更少(因为直接跨房间)
完整代码实现:MAML for RL
下面实现 MAML 在简单 RL 任务上的应用(2D
导航任务,不同任务对应不同目标位置):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 import torchimport torch.nn as nnimport torch.optim as optimimport numpy as npimport matplotlib.pyplot as pltclass Navigation2DEnv : """2D 平面导航任务 智能体从原点出发,导航到目标点 不同任务=不同目标位置 """ def __init__ (self, goal=(5.0 , 5.0 50 ): self.goal = np.array(goal, dtype=np.float32) self.max_steps = max_steps self.reset() def reset (self ): self.pos = np.zeros(2 , dtype=np.float32) self.steps = 0 return self.pos.copy() def step (self, action ): """action: (dx, dy) ∈ [-1, 1]²""" self.pos += action * 0.5 self.steps += 1 dist = np.linalg.norm(self.pos - self.goal) reward = -dist done = (dist < 0.5 ) or (self.steps >= self.max_steps) return self.pos.copy(), reward, done @staticmethod def sample_task (): """采样随机任务(目标位置)""" goal = np.random.uniform(-10 , 10 , size=2 ) return Navigation2DEnv(goal=goal) class PolicyNetwork (nn.Module): """高斯策略网络""" def __init__ (self, state_dim=2 , action_dim=2 , hidden_dim=64 ): super ().__init__() self.fc = nn.Sequential( nn.Linear(state_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim), nn.ReLU() ) self.mean = nn.Linear(hidden_dim, action_dim) self.log_std = nn.Parameter(torch.zeros(action_dim)) def forward (self, state ): x = self.fc(state) mean = torch.tanh(self.mean(x)) std = torch.exp(self.log_std).clamp(min =1e-3 , max =1.0 ) return mean, std def sample (self, state ): mean, std = self.forward(state) dist = torch.distributions.Normal(mean, std) action = dist.sample() log_prob = dist.log_prob(action).sum (dim=-1 ) return action, log_prob class MAML : def __init__ (self, policy, inner_lr=0.1 , outer_lr=0.001 , num_inner_steps=1 ): self.policy = policy self.inner_lr = inner_lr self.outer_lr = outer_lr self.num_inner_steps = num_inner_steps self.optimizer = optim.Adam(policy.parameters(), lr=outer_lr) def collect_trajectory (self, env, policy, max_steps=50 ): """收集一条轨迹""" states, actions, rewards, log_probs = [], [], [], [] state = env.reset() for _ in range (max_steps): state_tensor = torch.FloatTensor(state).unsqueeze(0 ) action, log_prob = policy.sample(state_tensor) action_np = action.detach().numpy()[0 ] next_state, reward, done = env.step(action_np) states.append(state) actions.append(action_np) rewards.append(reward) log_probs.append(log_prob) state = next_state if done: break return states, actions, rewards, log_probs def compute_loss (self, states, actions, rewards, log_probs ): """计算策略梯度损失(REINFORCE)""" returns = [] G = 0 for r in reversed (rewards): G = r + 0.99 * G returns.insert(0 , G) returns = torch.FloatTensor(returns) returns = (returns - returns.mean()) / (returns.std() + 1e-8 ) log_probs = torch.stack(log_probs) loss = -(log_probs * returns).mean() return loss def inner_loop (self, task_env, policy_params ): """内层循环:在单个任务上做梯度更新""" states, actions, rewards, log_probs = self.collect_trajectory(task_env, self.policy) loss = self.compute_loss(states, actions, rewards, log_probs) grads = torch.autograd.grad(loss, self.policy.parameters(), create_graph=True ) adapted_params = [] for param, grad in zip (self.policy.parameters(), grads): adapted_params.append(param - self.inner_lr * grad) return adapted_params, loss.item() def outer_loop (self, task_batch ): """外层循环:元优化""" meta_loss = 0 for task_env in task_batch: adapted_params, train_loss = self.inner_loop(task_env, self.policy.parameters()) original_params = [p.clone() for p in self.policy.parameters()] for param, adapted_param in zip (self.policy.parameters(), adapted_params): param.data = adapted_param.data states, actions, rewards, log_probs = self.collect_trajectory(task_env, self.policy) loss = self.compute_loss(states, actions, rewards, log_probs) meta_loss += loss for param, original_param in zip (self.policy.parameters(), original_params): param.data = original_param.data meta_loss /= len (task_batch) self.optimizer.zero_grad() meta_loss.backward() self.optimizer.step() return meta_loss.item() def adapt_to_task (self, task_env, num_steps=5 ): """在新任务上适应""" adapted_policy = PolicyNetwork() adapted_policy.load_state_dict(self.policy.state_dict()) optimizer = optim.SGD(adapted_policy.parameters(), lr=self.inner_lr) for step in range (num_steps): states, actions, rewards, log_probs = self.collect_trajectory(task_env, adapted_policy) loss = self.compute_loss(states, actions, rewards, log_probs) optimizer.zero_grad() loss.backward() optimizer.step() return adapted_policy def train_maml (num_iterations=500 , task_batch_size=10 ): """训练 MAML""" policy = PolicyNetwork() maml = MAML(policy, inner_lr=0.1 , outer_lr=0.001 ) meta_losses = [] for iteration in range (num_iterations): task_batch = [Navigation2DEnv.sample_task() for _ in range (task_batch_size)] meta_loss = maml.outer_loop(task_batch) meta_losses.append(meta_loss) if iteration % 50 == 0 : print (f"Iteration {iteration} : Meta Loss = {meta_loss:.4 f} " ) plt.figure(figsize=(10 , 5 )) plt.plot(meta_losses) plt.xlabel('Iteration' ) plt.ylabel('Meta Loss' ) plt.title('MAML Training Curve' ) plt.grid(True ) plt.savefig('maml_training.png' , dpi=300 ) print ("训练曲线已保存为 maml_training.png" ) return maml def evaluate_maml (maml, num_test_tasks=10 , num_adapt_steps=5 ): """评估 MAML 在新任务上的快速适应""" results = {'before' : [], 'after' : []} for _ in range (num_test_tasks): test_env = Navigation2DEnv.sample_task() states, actions, rewards, _ = maml.collect_trajectory(test_env, maml.policy) results['before' ].append(sum (rewards)) adapted_policy = maml.adapt_to_task(test_env, num_steps=num_adapt_steps) states, actions, rewards, _ = maml.collect_trajectory(test_env, adapted_policy) results['after' ].append(sum (rewards)) print (f"适应前平均回报: {np.mean(results['before' ]):.2 f} " ) print (f"适应后平均回报: {np.mean(results['after' ]):.2 f} " ) print (f"提升: {np.mean(results['after' ]) - np.mean(results['before' ]):.2 f} " ) return results if __name__ == "__main__" : print ("开始 MAML 训练..." ) maml = train_maml(num_iterations=500 , task_batch_size=10 ) print ("\n 评估 MAML 快速适应能力..." ) results = evaluate_maml(maml, num_test_tasks=20 , num_adapt_steps=5 ) print ("\n 实验完成!" )
代码解析
环境 : - 2D 平面导航,智能体从(0,0)出发,导航到目标点 -
不同任务=不同目标位置(随机采样) - 奖励:负的欧氏距离
MAML 流程 :
采样任务批次 :10 个随机目标位置内层循环 (对每个任务):
外层循环 :
快速适应 :
给定新任务,从
评估适应后的性能
实验结果 (预期): - 适应前:元策略在随机任务上表现一般
- 适应后:5 步梯度更新显著提升性能(如回报从-50 提升到-20) - 说明 MAML
学到了"好的初始化",能快速适应新任务
深度问答
Q1:Options
框架为什么能加速学习?
时间抽象减少决策点 : - 扁平
RL:每步选择原子动作,决策点数=
探索效率提升 : - 扁平 RL:探索空间
值函数复用 : - Option 的 Q 值可以在不同任务间共享 -
例如"开门"Option 在"出房间"和"进房间"任务中都有用
实验验证 :四房间任务中,Options 比扁平 Q-learning 快
3-5 倍收敛。
Q2:MAXQ
的"分层最优"与"全局最优"有何区别?
分层最优 (Hierarchically Optimal): -
在给定任务分解下的最优策略 - 每个子任务独立最优化 -
受限于预定义的任务层次结构
全局最优 (Globally Optimal): - 在原始 MDP
上的最优策略 - 不受任务分解约束
实例 :假设任务"做早餐"分解为"煮咖啡"→"煎鸡蛋"→"烤面包":
- 全局最优:可能并行煮咖啡和煎鸡蛋(更快) -
分层最优:受限于串行分解,无法并行
何时一致? 当任务分解完美捕获最优策略的结构时,分层最优=全局最优。但实践中很难设计完美分解。
MAXQ
的价值 :即使不是全局最优,分层最优也比随机探索好得多,且学习更快。
Q3:Feudal RL 与 Options
的核心区别?
Options : - 离散的行为原语(如"开门"、"走到 A") -
高层策略选择离散的 Option ID - 每个 Option 有固定的内部策略
Feudal RL : - 连续的子目标(如"到达坐标(x, y)") -
Manager 输出连续的子目标向量
优势对比 : - Options 更易解释(离散行为有明确语义) -
Feudal 更灵活(连续子目标覆盖无限种行为)
实例 :机器人抓取任务: -
Options:预定义"张开手"、"闭合手"、"移动到 A" - Feudal:Manager
输出目标位置
Q4:MAML 为什么需要二阶梯度?
问题 :元损失对元参数
元损失 :
梯度展开 :
其中
为什么重要? - 二阶项捕获"梯度的梯度",指导
实践中 :FOMAML 性能接近 MAML(损失<5%),但计算快 10
倍,常作为 MAML 的替代。
Q5:RL ²如何将"学习"编码为
RNN 的隐状态?
核心思想 : - 输入序列:( ) ( )
"学习"的过程 : - 初始 episode:
与 MAML 的对比 : - MAML:显式梯度更新参数 - RL
²:隐式通过 RNN 记忆更新"策略"
实例 :Bandit 任务(10 个臂,每个臂固定奖励): - Episode
1:RNN 随机探索,发现臂 3 奖励高 - Episode 2:RNN 的
局限 :RNN
的记忆容量有限,难以处理复杂任务(如需要理解长期因果关系的任务)。
Q6:如何自动发现有用的
Options?
挑战 :手工设计 Options
需要领域知识,且不一定最优。
方法 1:基于瓶颈状态 : -
分析状态转移图,找到"必经之路"(如房间门、关卡检查点) -
算法:图聚类、介数中心性(Betweenness Centrality) -
优势:符合人类直觉,易于解释 -
局限:需要完整状态转移图(大规模环境不可行)
方法 2:DIAYN(Diversity Is All You Need) : -
学习多样化技能,最大化( ) ( ) ( ) ( ) ( )
方法 3:基于任务成功率 : - 训练多个
Options,评估每个对主任务的贡献 - 删除低贡献 Options,保留高贡献的 -
算法:Evolutionary Options 、 Option-Critic
实践建议 : - 初期:手工设计少量
Options(如基于领域知识) - 中期:用 DIAYN 扩展 Options 库 -
后期:根据任务性能筛选有用 Options
适合 Meta-RL 的任务特征 :
1. 任务间有共享结构 : -
例:不同迷宫布局,但导航策略相似 - 例:不同机器人重量,但平衡策略相似
2. 任务多样性适中 : - 太相似:直接迁移学习更简单 -
太不同:Meta-RL 无法泛化
3. 单任务样本有限 : - Meta-RL 的优势是少样本快速适应
- 如果单任务有百万样本,直接训练即可
成功案例 : -
机器人推箱子 :不同箱子重量、摩擦系数,MAML 快速适应 -
Bandit 问题 :不同臂的奖励分布,RL ²几轮即收敛 -
Atari 游戏关卡 :同一游戏的不同关卡,Meta-RL
快速学会新关卡
失败案例 : -
完全随机任务 :如每个任务都是不同的物理规律,Meta-RL
无法找到共性 - 超长时间依赖 :如需要记忆 1000
步前的信息,RNN 难以处理
实践建议 : -
先验证任务间有共享结构(如用人类先验知识判断) - 尝试 Meta-RL
前,先尝试简单迁移学习(如 fine-tuning 预训练模型)
Q8:Options 与
Hierarchical DQN 有何关系?
Hierarchical DQN (h-DQN): - 2016 年提出,用于 Atari
游戏 - 两层结构:Meta-Controller 选择子目标,Controller 执行原子动作 -
子目标是离散的(如"到达某个关键位置")
与 Options 的关系 : - h-DQN 可以看作 Options
的深度学习版本 - Meta-Controller = 高层 Option 选择策略 - Controller =
Option 内部策略
h-DQN 的创新 : -
用神经网络逼近,适用于大规模状态空间(如 Atari 像素) -
子目标用端到端学习,无需手工设计 - 内在奖励机制:Controller
优化到达子目标的奖励
实例 :Atari 游戏 Montezuma's Revenge: - 扁平
DQN:难以探索(需要连续正确动作才能获得奖励) - h-DQN:Meta-Controller
设定"拿钥匙"→"开门"→"上楼梯",Controller 分步执行,显著提升性能
后续发展 : - HAM-DQN 、 Feudal Networks 、 HIRO
等都是 h-DQN 的延伸 - 核心思想一致:层次化决策+时间抽象
Transfer Learning : - 在源任务训练,在目标任务微调 -
通常假设单一源任务(或少数几个源任务) - 目标:最大化目标任务性能
Meta-RL : - 在任务分布( ) 新任务 上的快速适应能力
数学形式 :
Transfer Learning :
Meta-RL :
即学习"适应能力"最强的初始参数。
实例 : - Transfer:在 ImageNet
预训练视觉模型,在医疗图像上微调 - Meta-RL:在 100
个迷宫任务上训练,在新迷宫上快速适应
何时选哪个? -
源任务和目标任务高度相关(如同领域不同数据集):Transfer Learning -
有多个相关任务,目标是快速适应新任务:Meta-RL
Q10:层次化 RL 的未来方向?
1. 端到端层次发现 : -
当前:大多数方法需要手工设计任务层次 - 未来:完全从数据中自动学习层次结构
- 挑战:如何定义"好的层次"?如何高效搜索层次空间?
2. 语言作为子目标 : -
用自然语言描述子目标(如"拿起红色杯子") -
结合大语言模型(LLM)生成子目标 - 优势:易于人机交互,可解释性强
3. 多模态层次化 : -
不同层次用不同模态表示(如高层用语言,低层用动作) -
视觉-语言-动作的层次化对齐
4. 元学习+层次化 : - 在多个任务上元学习层次结构 -
新任务上快速适应层次策略 - 算法:Meta-HAM 、 Hierarchical MAML
5. 大规模预训练 : -
在大规模离线数据上预训练层次化策略 - 类似 LLM 的预训练范式 -
挑战:如何设计层次化的预训练目标?
Q11:Directed-MAML(2024)有何改进?
MAML 的计算瓶颈 : - 二阶梯度计算需要 Hessian 矩阵 -
内存占用高(需要保存中间梯度) -
训练时间长(每个任务需要多次前向-反向传播)
Directed-MAML 的思想 : -
在二阶梯度前应用任务导向近似 (task-directed
approximation) - 只计算对当前任务最相关的梯度分量 -
减少计算复杂度,同时保持性能
技术细节 : - 用任务特征向量( )
实验结果 (2024 论文): - CartPole-v1:收敛速度提升 40%
- LunarLander-v2:样本效率提升 30% - 计算时间减少 50%
兼容性 :Directed-MAML 可以与 FOMAML 、 Meta-SGD
等结合,进一步提升性能。
Q12:Options
如何与深度学习结合?
挑战 : - Options 框架最初为 Tabular 设置设计 -
大规模状态空间需要函数逼近
Option-Critic Architecture : - 用神经网络参数化: -
高层策略( ) ( ) ( )
损失函数 :
高层策略梯度 :
Option 内部策略梯度 :
终止梯度 :
实验 :Option-Critic 在 Atari 游戏上学到有意义的
Options(如"躲避敌人"、"收集道具")。
优势 : - 无需手工设计 Options - 端到端训练,易于优化
- 可扩展到高维状态空间
局限 : - 训练不稳定(三组参数相互依赖) -
可解释性降低(神经网络黑盒)
相关论文与资源
核心论文
层次化强化学习 :
Options Framework :https://arxiv.org/abs/cs/9905014
MAXQ :https://arxiv.org/abs/cs/9905015
HAM :
Feudal Networks :https://arxiv.org/abs/1703.01161
HIRO :https://arxiv.org/abs/1805.08296
Option-Critic :https://arxiv.org/abs/1609.05140
元强化学习 :
MAML :https://arxiv.org/abs/1703.03400
RL ² :https://arxiv.org/abs/1611.02779
Directed-MAML :https://arxiv.org/abs/2510.00212
DIAYN :https://arxiv.org/abs/1802.06070
综述与资源
Hierarchical RL Survey :
Meta-Learning Survey :https://arxiv.org/abs/2004.05439
代码库
OpenAI Baselines :
[https://github.com/openai/baselines](https://github.com/openai/baselines)learn2learn :
[https://github.com/learnables/learn2learn](https://github.com/learnables/learn2learn)
(MAML 实现)Option-Critic :
[https://github.com/jeanharb/option_critic](https://github.com/jeanharb/option_critic)
总结
层次化强化学习与元学习代表了 RL
从"扁平单任务"向"结构化多任务"的范式转变。
层次化
RL 通过时间抽象和模块化,将复杂任务分解为可管理的子问题: -
Options 提供半马尔可夫决策框架,支持时间延展的行为原语 -
MAXQ 分解价值函数,实现子任务并行学习 - Feudal
RL 用连续子目标实现灵活的层次化控制
元强化学习 让智能体"学会学习",在新任务上快速适应: -
MAML 学习"好的初始化",通过二阶优化实现快速梯度适应 -
RL ² 用 RNN 记忆编码学习过程,隐式实现任务适应 -
Directed-MAML 用任务导向近似加速
MAML,保持性能同时降低计算
未来,层次化与元学习将深度融合——在多任务上元学习层次结构,用语言指导子目标生成,结合大规模预训练实现通用智能体。从机器人到游戏,从推荐到自动驾驶,层次化与元学习正在重塑强化学习的应用边界。