2016 年 3 月,当 AlphaGo 以 4:1
战胜世界围棋冠军李世石时,全球为之震撼——围棋曾被认为是 AI
最难攻克的堡垒,因为其搜索空间达到
蒙特卡洛树搜索:搜索与采样的平衡
为什么需要 MCTS?
在围棋中,每一步平均有 250 种可能的落子,一局棋平均 150
步,完整搜索树的分支数达到不要均匀地搜索所有分支,而是集中计算资源在最有希望的路径上 。
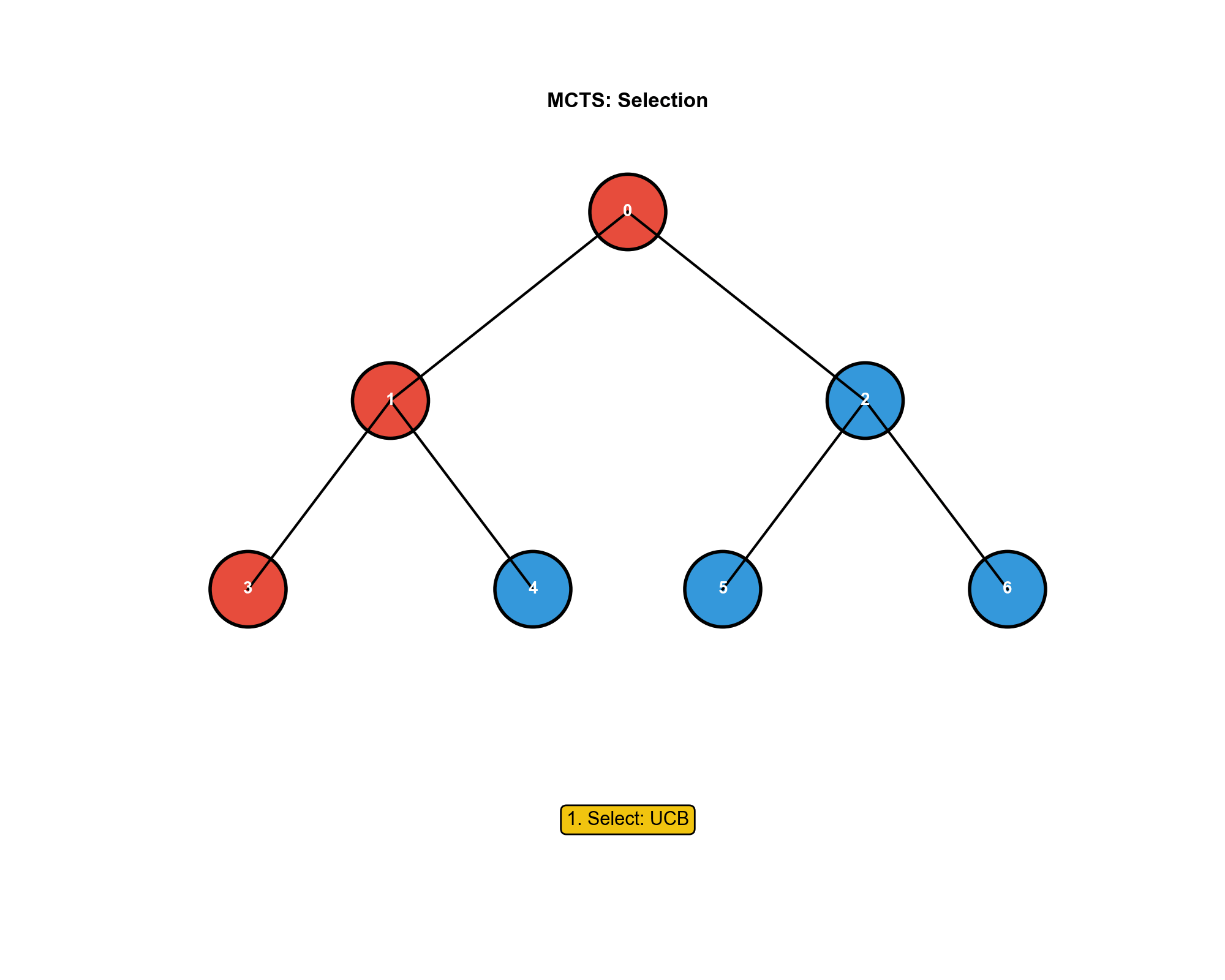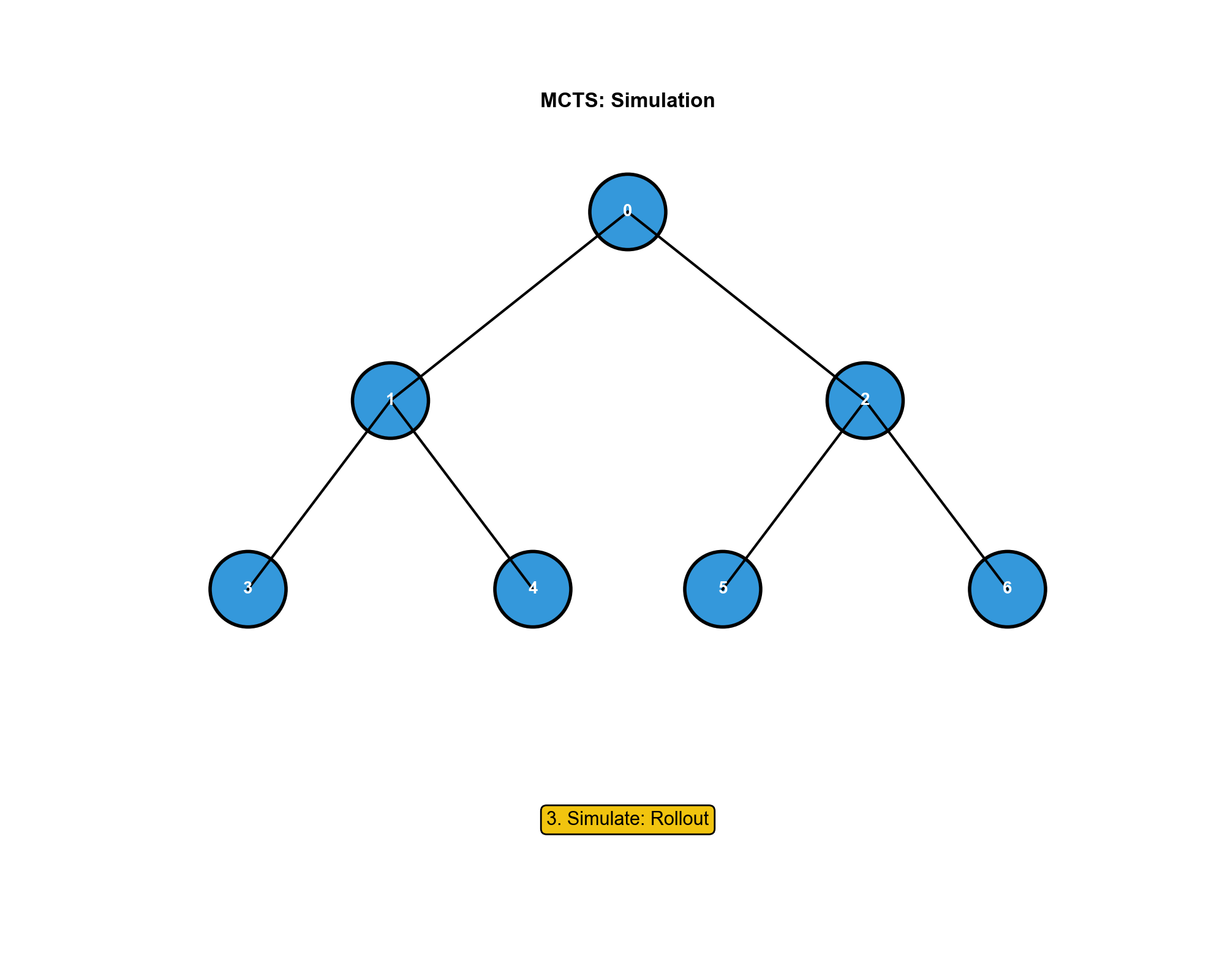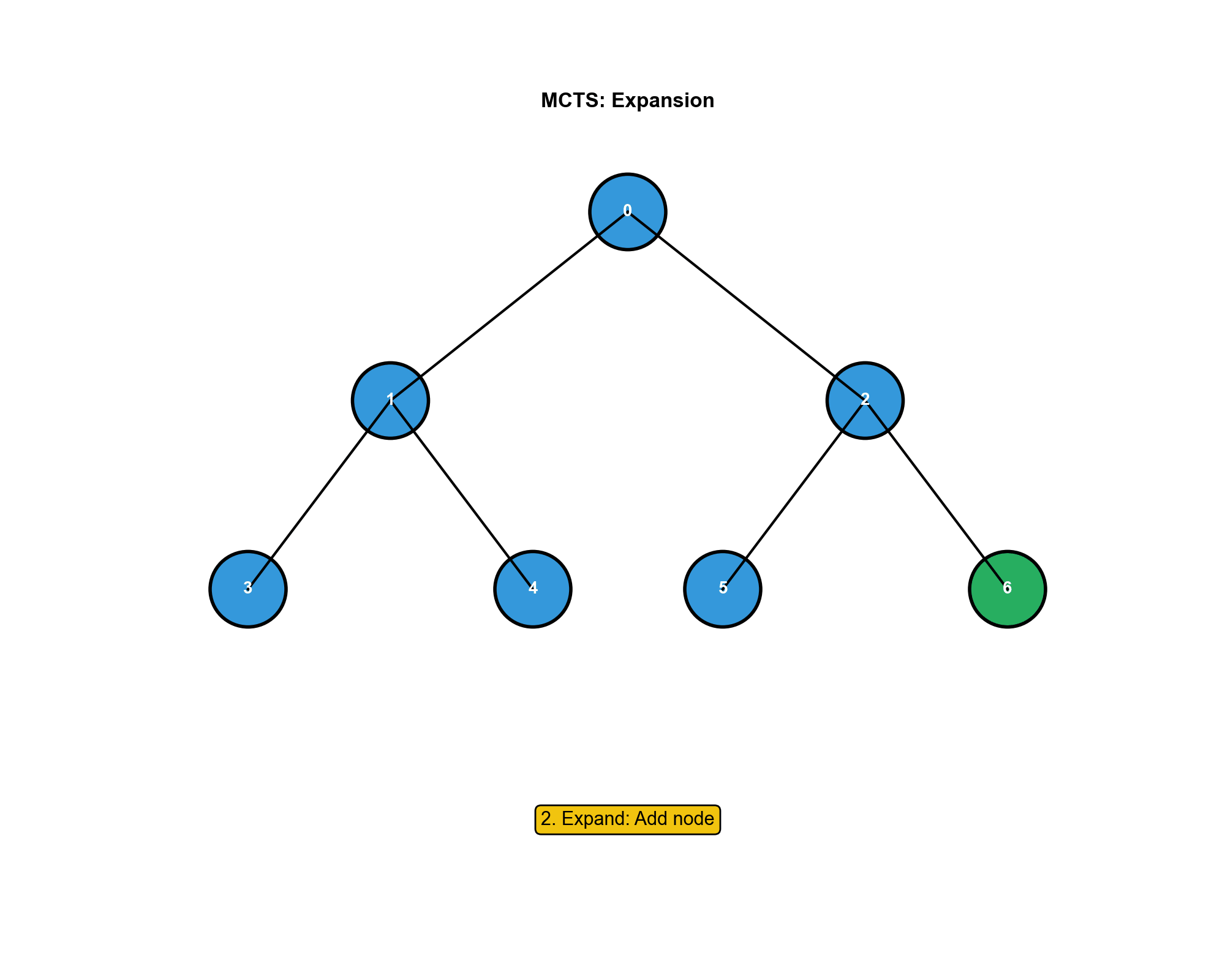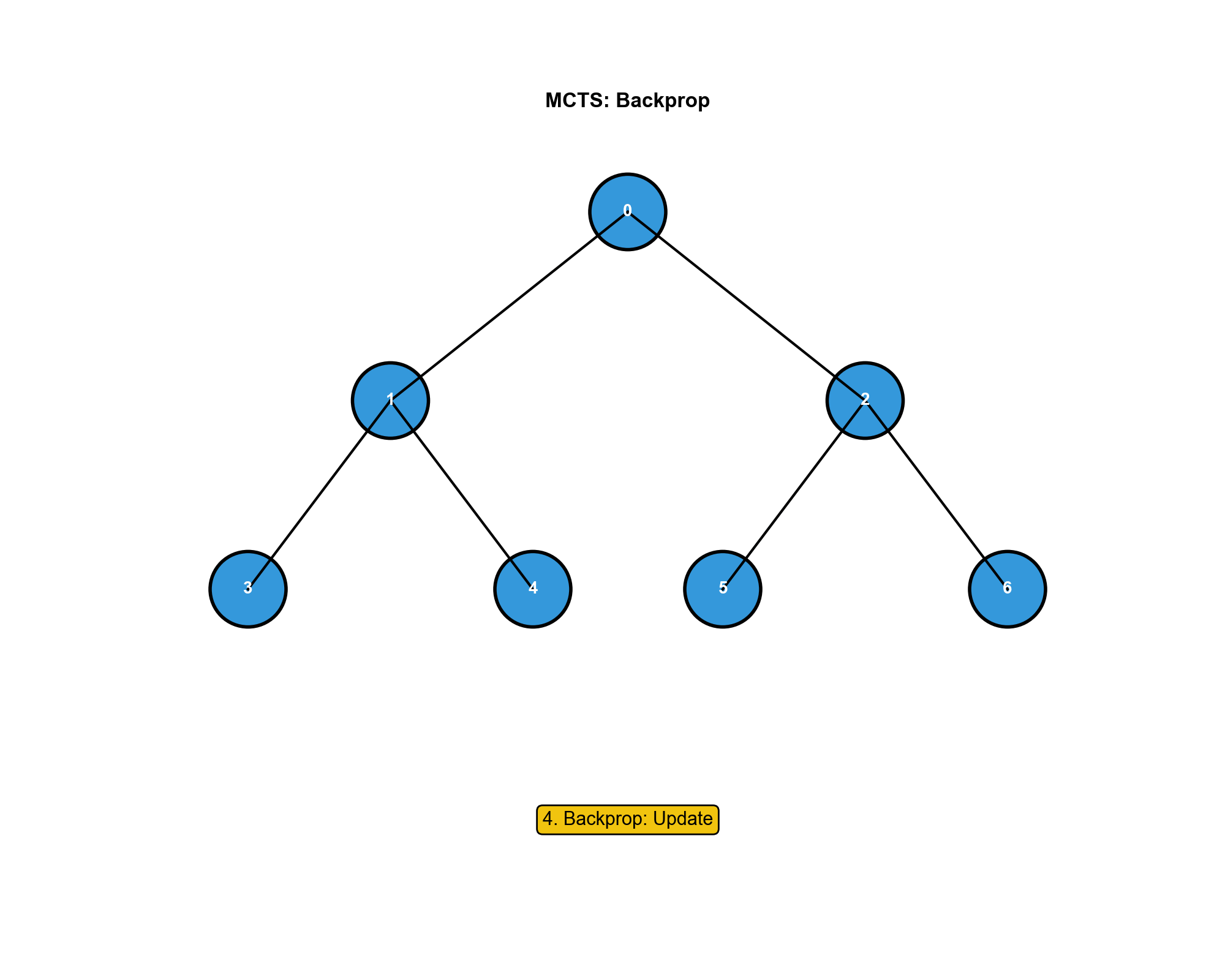
MCTS 的四个步骤
MCTS 通过迭代执行四个步骤构建搜索树:
1. 选择(Selection) :从根节点开始,使用某种策略(如
UCT)选择子节点,直到到达叶子节点。
2.
扩展(Expansion) :如果叶子节点不是终止状态,随机选择一个未探索的动作,添加新的子节点。
3.
模拟(Simulation) :从新节点开始,使用快速策略(如随机策略或简单启发式)模拟到游戏结束,得到回报
4. 回溯(Backpropagation) :将回报
这四个步骤不断重复,搜索树逐渐向有希望的方向生长。最终,在根节点选择访问次数最多的动作作为实际决策。
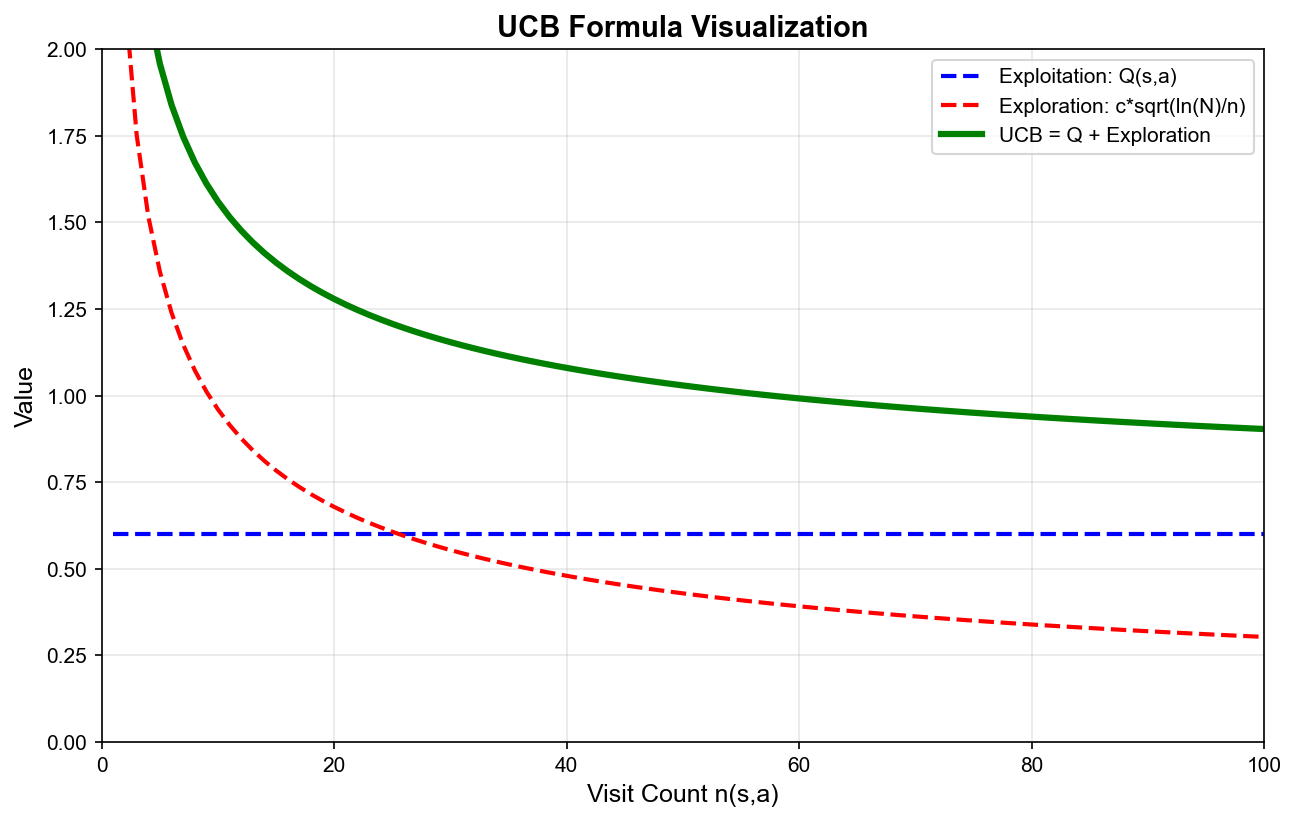
UCT 算法
:探索与利用的数学平衡
选择步骤的关键是如何平衡探索(exploration) 和利用(exploitation) 。
UCT(Upper Confidence bounds applied to Trees)算法使用以下公式:
其中: -
第一项 利用 ——选择已知的好动作。
第二项 探索 ——鼓励尝试访问较少的动作。
这个公式有着深刻的数学根源——它来自多臂老虎机(Multi-Armed
Bandit) 问题的 UCB1 算法。当某个动作
关键性质 :UCT
保证了渐近最优性 ——随着模拟次数趋于无穷,UCT
选择的动作概率收敛到最优动作。数学上,这是通过 Hoeffding
不等式证明的:
这个不等式说明,随着
MCTS 的优势与局限
优势 : - 不需要领域知识 :基础的 MCTS
只需要游戏规则(模拟器),不需要启发式评估函数 -
任何时间算法 :可以随时停止并返回当前最佳动作,计算时间越长结果越好
- 自适应 :自动在有希望的分支上投入更多计算资源
局限 : -
计算昂贵 :需要大量模拟才能得到可靠的估计 -
随机策略效率低 :在复杂游戏中,随机模拟很少到达有意义的状态
- 无法直接处理连续动作空间 :UCT
假设动作是离散且有限的
AlphaGo
的突破正是解决了后两个问题——用神经网络替代随机模拟,并提供先验知识指导搜索。
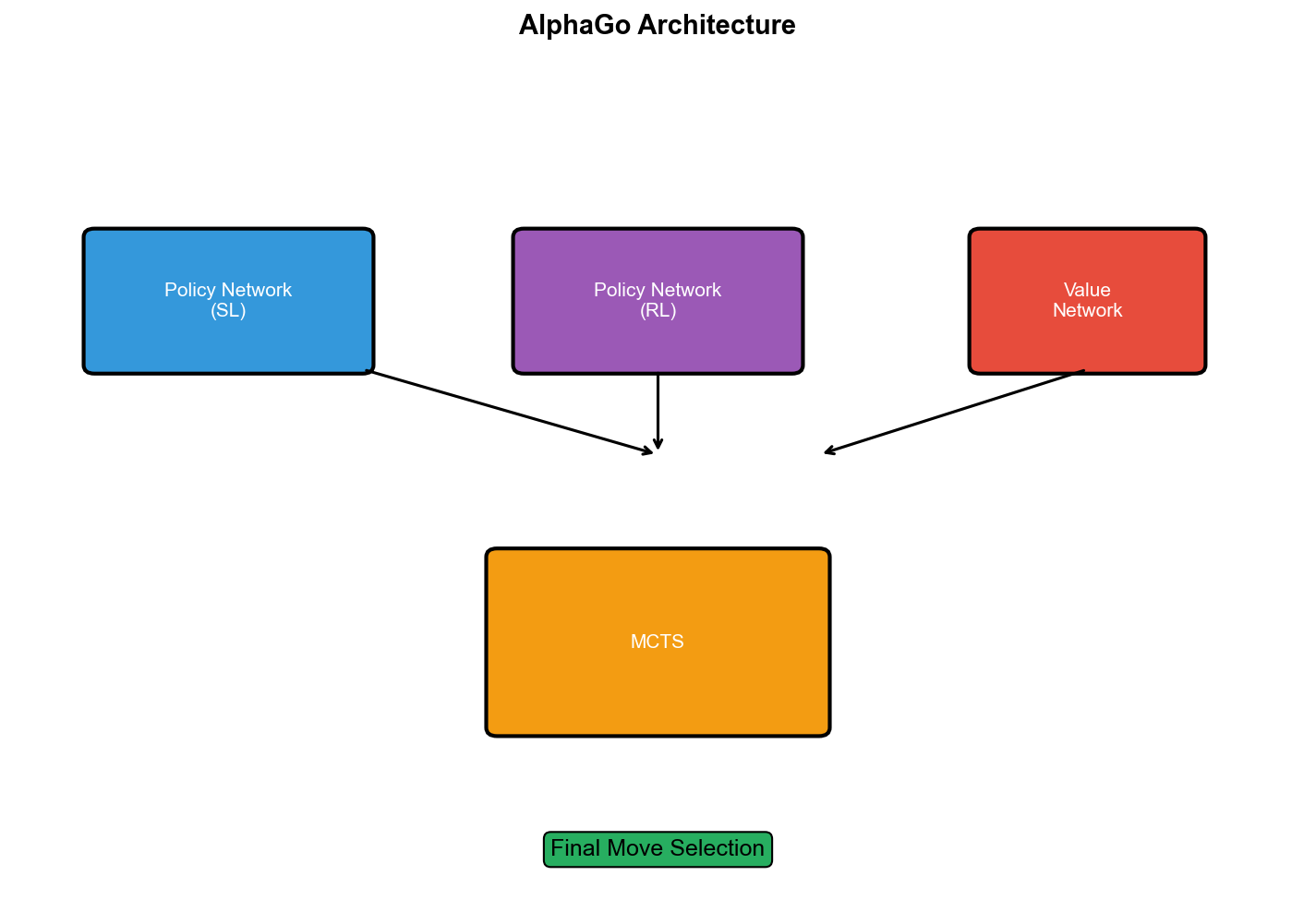
AlphaGo:监督学习+强化学习+搜索
AlphaGo 的三阶段训练
AlphaGo 的训练分为三个阶段:
阶段 1:监督学习策略网络 - 使用 16
万局人类专家棋谱,训练一个 13 层卷积神经网络预测人类落子 - 输入:
阶段 2:强化学习策略网络 - 将监督学习的网络
其中
阶段 3:价值网络 -
训练一个网络预测在状态
数据生成:用 RL 策略自我对弈生成 3000 万个(状态,结果)对
关键技巧:每局棋只采样一个状态,避免同一局棋的状态高度相关导致过拟合
测试集 MSE:0.226(相比随机 baseline 的 0.5 大幅降低)
AlphaGo 的 MCTS 集成
AlphaGo 的 MCTS 不同于传统的四个步骤:
1. 选择(Selection) :使用修改的 UCT 公式:
其中:
这里2.
扩展(Expansion) :到达叶子节点
3.
评估(Evaluation) :不再进行随机模拟,而是用价值网络
其中
4. 回溯(Backpropagation) :更新路径上的节点统计:$
$
最终决策 :在根节点,选择动作的概率正比于访问次数:
其中温度参数
AlphaGo 的网络架构细节
策略网络 : - 输入:
价值网络 : -
架构与策略网络类似,最后一层改为单个神经元输出
快速 rollout 策略 : - 线性
softmax,只使用局部
AlphaGo 对 Lee Sedol 的表现
AlphaGo 使用 1920 个 CPU 和 280 个 GPU,每步思考平均 40 秒,进行约 10
万次 MCTS 模拟。关键的第 37 手(Ledge 2, Game 2)和第 78 手(Ladder, Game
4)展现了 AlphaGo
的创造性——这些落子初看不合理,但实际上是全局最优的深度规划结果。 Lee
Sedol 在第 4 局第 78 手的"神之一手"也证明了人类直觉仍有独特价值,AlphaGo
在那之后的 19 步内陷入混乱,表明其对某些罕见模式的泛化能力不足。
AlphaGo
Zero:从零开始的自我对弈
三大突破
AlphaGo Zero 在 2017 年 10 月发表于 Nature,相比 AlphaGo
有三大根本性改进:
1.
完全抛弃人类棋谱 :只用黑白棋子和游戏规则,从完全随机的策略开始自我对弈学习。
2. 单一网络 :将策略网络和价值网络合并为一个双头网络:
-
这个设计基于直觉:策略和价值都依赖于对局面的理解,共享表示可以加速学习。
3. 不使用快速 rollout :完全依赖价值网络
训练流程
AlphaGo Zero 的训练是一个自我对弈的闭环:
步骤 1:自我对弈
使用当前最佳网络
每一步,MCTS 运行
保存
步骤 2:训练网络 - 从 replay buffer 中采样
mini-batch,优化损失函数:
第一项是价值损失(MSE),第二项是策略损失(交叉熵),第三项是 L2
正则化。
步骤 3:评估与更新 - 让新网络
AlphaGo Zero 的 MCTS
选择步骤的 UCT 公式变为:
其中
评估步骤直接使用:
没有 rollout 混合。
为什么自我对弈有效?
自我对弈的成功依赖于课程学习(Curriculum Learning) : -
初期:双方都是随机策略,游戏很快结束,梯度信号强 -
中期:策略逐渐变强,对手也变强,始终保持适度挑战 -
后期:双方都接近完美策略,探索微妙的战术细节
这比从固定的人类棋谱学习更高效,因为: -
人类棋谱覆盖的状态空间有限(主要是开局定式) - 人类有偏见和错误,AI
可能学到这些缺陷 - 自我对弈可以持续探索未知的局面
数学上,自我对弈类似于虚拟策略迭代(Fictitious
Self-Play) :
在双人零和博弈中,这个迭代会收敛到 Nash 均衡。 AlphaGo Zero 的 MCTS
正是在每一步计算一个"局部
best-response",然后用监督学习将其提炼到网络中。
性能对比
AlphaGo Zero 用 3 天训练(490 万局自我对弈)就以 100:0 击败 AlphaGo Lee
版本;用 40 天训练后,以 89:11 击败 AlphaGo Master 版本(曾在网上 60
连胜人类顶尖棋手)。更惊人的是,AlphaGo Zero 的 Elo
等级分增长曲线几乎是线性的——从 0 到 5000 点只用了 72
小时,而人类从入门到职业需要数年。
AlphaZero:泛化到国际象棋与将棋
从专用到通用
AlphaZero 在 2018 年 Science
论文中展示了相同算法在三种棋类(围棋、国际象棋、将棋)上的统治力。唯一的修改是:
1. 游戏规则编码 :每个游戏使用不同的状态表示 -
围棋:
2. 超参数调整 : - 国际象棋和将棋的 MCTS
模拟次数减少到 800(因为分支因子更小) - 探索常数
3. 网络架构 :统一为 20 个残差块,每块 256
个滤波器,总参数约 4600 万。
训练细节与结果
围棋 :70 万步(相当于 2100 万局自我对弈),Elo
5018,超越 AlphaGo Zero国际象棋 :30 万步(4400 万局),4 小时后超越
Stockfish(传统最强引擎),9 小时后达到 Elo 4450将棋 :10 万步(400 万局),2 小时后超越
Elmo(日本冠军程序),训练后 Elo 4650
AlphaZero 对 Stockfish 的 100 局对决中,胜 28 局,和 72
局,无一败绩。更重要的是,AlphaZero
的棋风更"人类化"——愿意牺牲子力换取位置优势,而传统引擎更依赖物质计算。
Chess.com 的大师们评价 AlphaZero"像来自未来的棋手"。
为什么能泛化?
AlphaZero 的泛化能力来自: - 通用的搜索框架 :MCTS
不依赖游戏特定的启发式 -
强大的表示学习 :残差网络自动学习特征,无需手工设计 -
自我对弈的鲁棒性 :不受人类偏见限制,探索更广阔的策略空间
这一范式的成功表明:搜索+学习 比单纯的记忆(如开局库)或纯暴力计算更接近通用智能。
MuZero:无需规则的规划
核心挑战
AlphaZero 依赖游戏规则进行 MCTS
模拟——在国际象棋中,它知道"马走日"、"吃过路兵"等规则。但许多实际问题(如机器人控制、视频游戏)的规则未知或难以编程。
MuZero 的突破在于:学习一个隐式模型 。
三个学习的函数
MuZero 学习三个函数:
1. 表示函数 :将观测
2. 动态函数 :预测下一个隐状态和即时奖励
注意:
3. 预测函数 :输出策略和价值
三个函数共享参数
MuZero 的 MCTS
在根节点
选择 :与 AlphaZero 相同的 UCT 公式:
扩展 :到达叶子节点
然后用预测函数初始化:
评估 :直接使用
关键区别:整个搜索树在隐空间 中展开,不需要真实的环境模拟器。
训练目标
MuZero 的损失函数包括三项:
其中
这个设计巧妙地将 Model-Based 和 Model-Free 结合: -
在规划时使用学习的模型(Model-Based) - 在训练时用真实经验监督(Model-Free
的数据效率)
重构损失(Reanalysis)
MuZero
引入一个关键技巧:Reanalysis ——用新网络重新分析旧经验: -
Replay buffer 中存储的是
MuZero 的表现
在 Atari 57 个游戏中,MuZero 达到 AlphaZero
同级别的性能,但不需要知道游戏规则。更重要的是,MuZero
在一些高度随机的游戏(如 Ms. Pac-Man)上超越了 Model-Free 的
Agent57,因为规划帮助它在长期策略上更一致。
在围棋和国际象棋上,MuZero 与 AlphaZero
持平——这证明了隐式模型足够表达游戏的关键结构,即使它不预测像素级的下一帧。
完整代码实现:
MCTS+神经网络下五子棋
下面的代码实现一个简化版的 AlphaZero,在
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 import torchimport torch.nn as nnimport torch.optim as optimimport numpy as npfrom collections import dequeimport randomclass GomokuEnv : def __init__ (self, board_size=15 ): self.size = board_size self.reset() def reset (self ): self.board = np.zeros((self.size, self.size), dtype=np.int8) self.current_player = 1 self.done = False self.winner = 0 return self.get_state() def get_state (self ): """返回 3 通道状态: [当前玩家棋子, 对手棋子, 颜色指示]""" state = np.zeros((3 , self.size, self.size), dtype=np.float32) state[0 ] = (self.board == self.current_player).astype(np.float32) state[1 ] = (self.board == -self.current_player).astype(np.float32) state[2 ] = np.full((self.size, self.size), self.current_player) return state def legal_actions (self ): """返回合法动作的坐标列表""" return list (zip (*np.where(self.board == 0 ))) def step (self, action ): """执行动作(row, col)""" if self.board[action] != 0 : raise ValueError(f"非法落子: {action} " ) self.board[action] = self.current_player if self._check_win(action): self.done = True self.winner = self.current_player return self.get_state(), self.winner, True if len (self.legal_actions()) == 0 : self.done = True return self.get_state(), 0 , True self.current_player *= -1 return self.get_state(), 0 , False def _check_win (self, last_move ): """检查 last_move 是否形成五子连珠""" directions = [(0 ,1 ), (1 ,0 ), (1 ,1 ), (1 ,-1 )] player = self.board[last_move] for dr, dc in directions: count = 1 r, c = last_move[0 ] + dr, last_move[1 ] + dc while 0 <= r < self.size and 0 <= c < self.size and self.board[r,c] == player: count += 1 r += dr c += dc r, c = last_move[0 ] - dr, last_move[1 ] - dc while 0 <= r < self.size and 0 <= c < self.size and self.board[r,c] == player: count += 1 r -= dr c -= dc if count >= 5 : return True return False class PolicyValueNet (nn.Module): def __init__ (self, board_size=15 , num_channels=128 ): super ().__init__() self.size = board_size self.conv1 = nn.Conv2d(3 , num_channels, 3 , padding=1 ) self.conv2 = nn.Conv2d(num_channels, num_channels, 3 , padding=1 ) self.conv3 = nn.Conv2d(num_channels, num_channels, 3 , padding=1 ) self.policy_conv = nn.Conv2d(num_channels, 2 , 1 ) self.policy_fc = nn.Linear(2 * board_size * board_size, board_size * board_size) self.value_conv = nn.Conv2d(num_channels, 1 , 1 ) self.value_fc1 = nn.Linear(board_size * board_size, 64 ) self.value_fc2 = nn.Linear(64 , 1 ) def forward (self, x ): x = torch.relu(self.conv1(x)) x = torch.relu(self.conv2(x)) x = torch.relu(self.conv3(x)) p = torch.relu(self.policy_conv(x)) p = p.view(-1 , 2 * self.size * self.size) p = torch.log_softmax(self.policy_fc(p), dim=1 ) v = torch.relu(self.value_conv(x)) v = v.view(-1 , self.size * self.size) v = torch.relu(self.value_fc1(v)) v = torch.tanh(self.value_fc2(v)) return p, v class MCTSNode : def __init__ (self, prior, parent=None ): self.prior = prior self.parent = parent self.children = {} self.visit_count = 0 self.value_sum = 0.0 def value (self ): if self.visit_count == 0 : return 0 return self.value_sum / self.visit_count def is_expanded (self ): return len (self.children) > 0 def select_child (self, c_puct=1.0 ): """UCT 选择""" best_score = -float ('inf' ) best_action = None best_child = None for action, child in self.children.items(): u = c_puct * child.prior * np.sqrt(self.visit_count) / (1 + child.visit_count) score = child.value() + u if score > best_score: best_score = score best_action = action best_child = child return best_action, best_child def expand (self, actions, priors ): """扩展节点""" for action, prior in zip (actions, priors): if action not in self.children: self.children[action] = MCTSNode(prior, parent=self) def backup (self, value ): """回溯更新""" self.visit_count += 1 self.value_sum += value if self.parent: self.parent.backup(-value) class MCTS : def __init__ (self, model, c_puct=1.0 , num_simulations=400 ): self.model = model self.c_puct = c_puct self.num_simulations = num_simulations @torch.no_grad() def search (self, env ): """执行 MCTS,返回改进策略""" root = MCTSNode(prior=0 ) state = env.get_state() legal_actions = env.legal_actions() log_probs, value = self.model(torch.FloatTensor(state).unsqueeze(0 )) probs = torch.exp(log_probs).squeeze(0 ).numpy() action_probs = [] for action in legal_actions: idx = action[0 ] * env.size + action[1 ] action_probs.append(probs[idx]) action_probs = np.array(action_probs) action_probs /= action_probs.sum () root.expand(legal_actions, action_probs) for _ in range (self.num_simulations): node = root env_copy = self._copy_env(env) search_path = [node] while node.is_expanded() and not env_copy.done: action, node = node.select_child(self.c_puct) search_path.append(node) env_copy.step(action) if not env_copy.done: state = env_copy.get_state() legal_actions = env_copy.legal_actions() log_probs, value = self.model(torch.FloatTensor(state).unsqueeze(0 )) probs = torch.exp(log_probs).squeeze(0 ).numpy() action_probs = [] for action in legal_actions: idx = action[0 ] * env_copy.size + action[1 ] action_probs.append(probs[idx]) action_probs = np.array(action_probs) action_probs /= action_probs.sum () node.expand(legal_actions, action_probs) value = value.item() else : value = env_copy.winner * env_copy.current_player for node in reversed (search_path): node.backup(value) value = -value visit_counts = np.zeros(env.size * env.size) for action, child in root.children.items(): idx = action[0 ] * env.size + action[1 ] visit_counts[idx] = child.visit_count return visit_counts / visit_counts.sum () def _copy_env (self, env ): """深拷贝环境""" new_env = GomokuEnv(env.size) new_env.board = env.board.copy() new_env.current_player = env.current_player new_env.done = env.done new_env.winner = env.winner return new_env class AlphaZeroTrainer : def __init__ (self, board_size=15 , num_simulations=100 ): self.env = GomokuEnv(board_size) self.model = PolicyValueNet(board_size) self.mcts = MCTS(self.model, num_simulations=num_simulations) self.optimizer = optim.Adam(self.model.parameters(), lr=1e-3 , weight_decay=1e-4 ) self.replay_buffer = deque(maxlen=10000 ) self.batch_size = 256 def self_play (self, num_games=10 , temperature=1.0 ): """自我对弈生成数据""" for _ in range (num_games): states, policies, current_players = [], [], [] self.env.reset() step = 0 while not self.env.done: state = self.env.get_state() policy = self.mcts.search(self.env) states.append(state) policies.append(policy) current_players.append(self.env.current_player) if step < 30 : action_probs = policy ** (1.0 / temperature) action_probs /= action_probs.sum () action_idx = np.random.choice(len (policy), p=action_probs) else : action_idx = np.argmax(policy) action = (action_idx // self.env.size, action_idx % self.env.size) self.env.step(action) step += 1 winner = self.env.winner for state, policy, player in zip (states, policies, current_players): value = winner * player self.replay_buffer.append((state, policy, value)) def train_step (self ): """训练一步""" if len (self.replay_buffer) < self.batch_size: return None batch = random.sample(self.replay_buffer, self.batch_size) states, target_policies, target_values = zip (*batch) states = torch.FloatTensor(np.array(states)) target_policies = torch.FloatTensor(np.array(target_policies)) target_values = torch.FloatTensor(np.array(target_values)).unsqueeze(1 ) log_probs, values = self.model(states) policy_loss = -torch.mean(torch.sum (target_policies * log_probs, dim=1 )) value_loss = torch.mean((target_values - values) ** 2 ) loss = policy_loss + value_loss self.optimizer.zero_grad() loss.backward() self.optimizer.step() return { 'loss' : loss.item(), 'policy_loss' : policy_loss.item(), 'value_loss' : value_loss.item() } def train (self, num_iterations=100 , games_per_iter=10 , train_steps_per_iter=100 ): """完整训练循环""" for i in range (num_iterations): print (f"\n=== Iteration {i+1 } /{num_iterations} ===" ) print ("自我对弈中..." ) self.self_play(num_games=games_per_iter) print ("训练网络中..." ) losses = [] for _ in range (train_steps_per_iter): loss_dict = self.train_step() if loss_dict: losses.append(loss_dict['loss' ]) if losses: print (f"平均损失: {np.mean(losses):.4 f} " ) print (f"Buffer 大小: {len (self.replay_buffer)} " ) def play_against_ai (model, board_size=15 ): """与训练好的 AI 对弈""" env = GomokuEnv(board_size) mcts = MCTS(model, num_simulations=400 ) print ("你是黑棋(X),AI 是白棋(O)" ) print ("输入坐标如: 7 7" ) while not env.done: print ("\n 当前棋盘:" ) for i in range (board_size): row = [] for j in range (board_size): if env.board[i,j] == 1 : row.append('X' ) elif env.board[i,j] == -1 : row.append('O' ) else : row.append('.' ) print (' ' .join(row)) if env.current_player == 1 : while True : try : r, c = map (int , input ("你的落子: " ).split()) if (r, c) in env.legal_actions(): break else : print ("非法位置!" ) except : print ("输入格式: 行 列" ) action = (r, c) else : print ("AI 思考中..." ) policy = mcts.search(env) action_idx = np.argmax(policy) action = (action_idx // board_size, action_idx % board_size) print (f"AI 落子: {action} " ) env.step(action) print ("\n 最终棋盘:" ) for i in range (board_size): row = [] for j in range (board_size): if env.board[i,j] == 1 : row.append('X' ) elif env.board[i,j] == -1 : row.append('O' ) else : row.append('.' ) print (' ' .join(row)) if env.winner == 1 : print ("\n 你赢了!" ) elif env.winner == -1 : print ("\nAI 赢了!" ) else : print ("\n 平局!" ) if __name__ == "__main__" : trainer = AlphaZeroTrainer(board_size=9 , num_simulations=100 ) trainer.train(num_iterations=50 , games_per_iter=5 , train_steps_per_iter=50 ) torch.save(trainer.model.state_dict(), "alphazero_gomoku.pth" )
代码解析
环境部分 : - GomokuEnv实现get_state()返回 3
通道张量:当前玩家棋子、对手棋子、颜色指示
网络部分 : -
PolicyValueNet是双头网络:策略头输出
MCTS 部分 : - MCTSNode存储先验select_child()实现 UCT
公式 - expand()添加子节点并初始化先验 -
backup()沿路径回溯更新
训练部分 : - self_play()生成train_step()优化策略损失运行示例 : - 在
深度问答:理解 MCTS 与
AlphaGo 系列
Q1: UCT 公式中的
直觉 :这来自统计学中的置信区间(Confidence
Interval) 。假设动作
数学推导 :UCT 基于 Hoeffding 不等式:
令右侧等于
解得:
因此置信上界是:
这正是 UCT 的形式(忽略常数因子)。
物理意义 : - 当
Q2: AlphaGo
为什么需要快速 rollout 策略
历史原因 :AlphaGo 开发时(2015-2016),价值网络
混合使用
为什么 AlphaGo Zero 不需要? :到 2017
年,残差网络和批归一化技术成熟,价值网络的泛化能力大幅提升。更重要的是,AlphaGo
Zero 使用的自我对弈数据覆盖了更广的状态空间,而 AlphaGo
的数据主要来自人类棋谱(有偏)。实验表明,纯价值网络
数值对比 :AlphaGo 的每次 MCTS 模拟耗时约 5ms(其中 2ms
是 rollout),AlphaGo Zero 的纯价值评估只需 3ms,且 Elo 提升了 600 分。
Q3:
自我对弈会不会陷入局部最优?
理论担忧 :在博弈论中,自我对弈类似于虚拟自我博弈(Fictitious
Self-Play) :
其中不保证收敛到 Nash
均衡 ,可能出现循环(如石头剪刀布)。
为什么 AlphaGo Zero 成功? :
双人零和完全信息博弈的特殊性 :这类博弈的 Nash
均衡唯一且可由极小极大值获得。虚拟自我博弈在这类博弈中有收敛保证。探索机制 :MCTS 的 UCT
公式强制探索所有动作,避免策略过早崩塌到单一走法。随机初始化 :早期的随机策略导致多样化的对局,奠定了广泛的基础。对手池 :虽然 AlphaGo Zero
主要与当前最佳网络对弈,训练时的 mini-batch
采样了不同时期的数据,相当于隐式的对手池。
实验证据 :论文的消融实验显示,如果移除探索(令
Q4: AlphaZero 对
Stockfish 的胜利公平吗?
争议点 : - Stockfish 运行在单核 CPU,AlphaZero 使用 4
个 TPU(相当于数千核算力) - Stockfish 使用固定深度的 AlphaBeta 搜索(约
6000 万节点/秒),AlphaZero 只搜索 8 万节点/秒,但每个节点用神经网络评估 -
Stockfish 有开局库和残局表,AlphaZero 完全依赖实时计算
DeepMind 的辩护 : - 对局时间固定(每方 1
分钟),计算资源不是主要因素 - Stockfish
的节点搜索虽快,但大部分是无效探索;AlphaZero 的搜索深度更深(平均 60 层 vs
30 层) - 后续测试用多核 Stockfish,AlphaZero 仍保持优势
更深层的问题 :这反映了两种 AI 范式的差异: -
符号 AI :Stockfish
用手工启发式(如"控制中心"、"王的安全")和暴力搜索 - 连接主义
AI :AlphaZero 用学习的隐式知识和高质量的选择性搜索
AlphaZero
的棋风更接近人类大师——愿意牺牲子力换取长期位置优势,而传统引擎更"物质主义"。
Q5: MuZero 的隐状态
关键洞察 :足够用于规划的抽象表示 。例如在
Atari 的 Ms. Pac-Man 中:
完整状态包括像素、敌人位置、分数、关卡信息等
但规划只需要知道"下一步往哪走不会被抓"这类高层信息 -
数学上 :定义真实环境的转移函数为存 在 隐 轨 迹 使 得 :
其中在规划意义上等价 ——即用
为什么不直接预测下一帧?
像素级预测需要建模无关的视觉细节(如云彩飘动),浪费容量
隐空间的转移可以更抽象,类似人类的"心智模拟"——我们规划不需要想象逼真的画面,只需要功能性的因果关系
实验验证 :论文显示,
Q6: MCTS 与 Model-Free
RL(如 PPO)的本质区别?
规划 vs 学习 :
MCTS :在每一步决策时,实时执行搜索,计算该状态下的局部最优动作。这是规划(planning) ——使用模型前瞻未来。PPO 等
Model-Free :通过大量经验训练一个策略网络学习(learning) ——记忆过去的经验。
计算开销 :
MCTS:每步决策需要数百到数千次模拟,计算昂贵,但不需要训练
PPO:训练阶段需要百万次环境交互,但执行时只需一次前向传播,极快
泛化能力 :
MCTS:只要有模型,可以立即适应新的状态(如中局变化)
PPO:只能泛化到训练分布附近的状态,遇到全新局面可能失效
AlphaZero 的融合 :结合了两者优势:
训练时用 MCTS 生成高质量的策略
用监督学习将
执行时用网络加速 MCTS 的搜索(两者协同)
这种"System 1(快速直觉)+ System
2(慢速推理)"的双系统架构,与人类认知科学的模型不谋而合。
Q7: 为什么
AlphaGo 的价值网络需要每局只采样一个状态?
过拟合风险 :同一局棋的不同状态高度相关——前 10
步的价值都依赖于最终结果
训练集中同一局棋贡献了上百个样本
这些样本不是独立同分布(i.i.d.),违反了监督学习的假设
网络会记住特定对局的模式,而非学习通用的价值估计
数学上 :假设一局棋有
因为样本不独立。实际方差远小于右侧,优化器会过分自信,过早停止探索。
论文实验 :对比了三种采样策略:
每局采样所有状态:价值网络在训练集上 MSE=0.01,测试集
MSE=0.37(严重过拟合)
每局采样一个状态:训练集 MSE=0.19,测试集 MSE=0.23(泛化良好)
每局采样固定比例(如 10%):介于两者之间
最终选择策略 2,用 3000 万局生成 3000 万个独立样本。
Q8: AlphaZero
的残差网络有多少参数?如何训练?
架构细节 : - 20 个残差块,每块包含: -4600 万
训练配置 : - 批大小:4096(使用 64 个 TPU 并行) -
优化器:SGD,动量 0.9 - 学习率:初始 0.2,每 10 万步衰减到 0.02,然后 0.002 -
权重衰减:
关键技巧 :
数据增强 :围棋/将棋使用 8
重对称(旋转+翻转),国际象棋使用左右翻转
温度退火 :训练前 30 步用
Dirichlet
噪声 :在根节点的先验上加噪声,鼓励探索:
其中
Q9: MuZero
如何避免模型误差累积?
挑战 :在 Model-Based RL
中,模型预测误差会随规划步数指数增长:
其中
MuZero 的解决方案 :
隐空间建模 :
短期展开 :训练时只展开 5
步,而非几十步,限制了误差累积
价值引导 :模型不需要完美预测未来,只需保证价值估计
端到端训练 :损失函数直接优化策略和价值,而非重构精度。模型自动学会忽略不影响决策的细节
数学上 :传统 Model-Based RL 优化重构误差:
后者允许模型在不影响
Q10: MCTS
能否用于连续动作空间?
挑战 :UCT
假设动作集有限,可以枚举所有子节点。在连续空间(如机器人关节角度),动作数无穷多,无法展开。
可能的扩展 :
Progressive
Widening :逐步增加展开的动作数,每当节点被访问局部优化 :在叶子节点用梯度优化找到最佳动作,而非遍历离散化 :将连续空间划分为网格,但会引入离散化误差
AlphaGo
系列的选择 :目前所有版本都只应用于离散动作(围棋、国际象棋、
Atari)。 DeepMind 的机器人项目(如灵巧手操作)使用的是 Model-Free 的
DDPG/SAC,而非 MCTS 。
未来方向 :将 MCTS
与连续控制结合是开放问题,可能需要新的树结构或搜索策略。
相关论文与资源
核心论文
MCTS 基础 :https://arxiv.org/abs/cs/0703062
AlphaGo :https://www.nature.com/articles/nature16961
AlphaGo Zero :https://www.nature.com/articles/nature24270
AlphaZero :https://arxiv.org/abs/1712.01815
MuZero :https://arxiv.org/abs/1911.08265
EfficientZero :https://arxiv.org/abs/2111.00210
Gumbel AlphaZero :https://arxiv.org/abs/2106.06613
Sampled MuZero :https://arxiv.org/abs/2104.06303
开源实现
总结与展望
从 MCTS 到 AlphaGo 系列的演进,展示了 AI
如何在人类智慧的巅峰——围棋上实现超越。这一成功不是单一技术的胜利,而是搜索、学习、规划三者的完美融合:
MCTS 提供了探索与利用的数学平衡,让有限的计算资源聚焦在最有希望的路径上。
深度学习 通过策略网络和价值网络,将人类数千年的围棋智慧(AlphaGo)或纯粹的自我对弈(AlphaGo
Zero)压缩到神经网络的权重中,为搜索提供高质量的先验和评估。
自我对弈 构建了一个持续改进的闭环——策略变强,对手也变强,始终保持适度挑战,最终突破人类棋谱的天花板。
AlphaZero 的泛化证明了这一范式的通用性——相同的算法在围棋、国际象棋、将棋上都达到超人水平,展示了"搜索+学习"作为通用智能基础的潜力。
MuZero 进一步摆脱了规则的限制,通过学习隐式模型实现规划,向"无需了解世界即可规划世界"的终极目标迈进。
未来的方向包括: - 扩展到连续空间 :将 MCTS
与机器人控制结合 -
迁移学习 :在一个游戏上训练的模型能否快速适应新游戏? -
多智能体博弈 :从双人零和扩展到多方合作竞争 -
开放式环境 :在没有明确胜负定义的任务中如何规划?
AlphaGo
的胜利不是终点,而是强化学习与搜索结合的起点。它告诉我们:智能不仅是记忆,更是规划;不仅是模仿,更是创造 。从
AlphaGo 到 MuZero 的演进,正是这一理念的最佳诠释。