从棋盘游戏到 Atari
电子游戏,价值函数方法一直是强化学习的核心技术路线。 Q-Learning
通过迭代更新状态-动作对的价值,让智能体学会选择最优动作;但面对高维状态空间(比如一个
84x84 像素的游戏画面),传统的表格方法会遭遇维度诅咒。 DeepMind 在 2013
年提出的深度 Q 网络(
DQN)通过引入神经网络作为函数逼近器,结合经验回放和目标网络两大创新,首次让计算机在多款
Atari
游戏中达到超越人类的表现。这一突破不仅推动了深度强化学习的快速发展,也催生了
Double DQN 、 Dueling DQN 、 Prioritized Experience Replay
等一系列改进技术,最终集大成于 Rainbow 算法。本章将从 Q-Learning
的数学原理出发,逐步解构 DQN
的核心机制,并深入分析各种变体的设计动机与实现细节。
Q-Learning
基础:从动态规划到时序差分
Bellman 最优方程与 Q 值
在第一章中我们介绍了价值函数
这个方程的直觉是:在状态
与策略评估中的
Q-Learning 算法:增量式更新
Q-Learning 是一种 off-policy 时序差分( TD)算法,由 Watkins 在 1989
年提出。它的更新规则是:
这里
为什么叫 off-policy?因为更新公式中使用的是
收敛性保证: Watkins & Dayan
(1992)
Q-Learning 的收敛性由 Watkins 和 Dayan 在 1992
年证明,需要满足以下条件:
表格表示 :状态和动作空间都是有限的, Q
值用表格存储所有状态-动作对被无限次访问 :每个学习率满足 Robbins-Monro 条件 :
直觉上,第一个条件保证
在这些条件下, Q-Learning 以概率 1 收敛到最优 Q 函数
Cliff Walking 示例:
Q-Learning 的直觉
让我们用一个经典例子来建立直觉。 Cliff Walking
是一个网格世界:智能体从左下角出发,要到达右下角的目标点,但底部有一排悬崖,掉下去会获得-100
的奖励并回到起点。每走一步获得-1 的奖励。
在这个环境中,最优路径是紧贴悬崖走(最短路径),但探索时很容易掉下去。
Q-Learning 的更新会发生什么?
初始时所有 Q 值为 0 。当智能体第一次掉下悬崖后,转移
这个负值会传播到前一个状态:当从
如果
这个例子展示了 Q-Learning 的两个特性: 1.
负奖励的传播 :危险区域的低 Q 值会向前传播,形成"禁区"
2. off-policy
的优势 :即使行为策略经常掉崖(探索),学习的
完整的 Python 实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 import numpy as npimport matplotlib.pyplot as pltclass CliffWalkingEnv : """ Cliff Walking 环境: 4x12 的网格世界 起点:(3,0),终点:(3,11) 悬崖:(3,1)到(3,10) """ def __init__ (self ): self.height = 4 self.width = 12 self.start = (3 , 0 ) self.goal = (3 , 11 ) self.cliff = [(3 , i) for i in range (1 , 11 )] def reset (self ): self.state = self.start return self.state def step (self, action ): row, col = self.state if action == 0 : row = max (0 , row - 1 ) elif action == 1 : col = min (self.width - 1 , col + 1 ) elif action == 2 : row = min (self.height - 1 , row + 1 ) elif action == 3 : col = max (0 , col - 1 ) next_state = (row, col) if next_state in self.cliff: reward = -100 done = False next_state = self.start elif next_state == self.goal: reward = 0 done = True else : reward = -1 done = False self.state = next_state return next_state, reward, done def q_learning (env, episodes=500 , alpha=0.1 , gamma=0.99 , epsilon=0.1 ): """ Q-Learning 算法 """ Q = {} for s in [(i,j) for i in range (env.height) for j in range (env.width)]: for a in range (4 ): Q[(s, a)] = 0.0 rewards_per_episode = [] for ep in range (episodes): state = env.reset() total_reward = 0 steps = 0 while steps < 1000 : if np.random.rand() < epsilon: action = np.random.randint(4 ) else : q_values = [Q[(state, a)] for a in range (4 )] action = np.argmax(q_values) next_state, reward, done = env.step(action) total_reward += reward best_next_q = max ([Q[(next_state, a)] for a in range (4 )]) td_error = reward + gamma * best_next_q - Q[(state, action)] Q[(state, action)] += alpha * td_error state = next_state steps += 1 if done: break rewards_per_episode.append(total_reward) if (ep + 1 ) % 100 == 0 : avg_reward = np.mean(rewards_per_episode[-100 :]) print (f"Episode {ep+1 } , Avg Reward: {avg_reward:.2 f} " ) return Q, rewards_per_episode env = CliffWalkingEnv() Q, rewards = q_learning(env, episodes=500 ) plt.figure(figsize=(10 , 5 )) plt.plot(rewards, alpha=0.3 ) plt.plot(np.convolve(rewards, np.ones(50 )/50 , mode='valid' ), linewidth=2 ) plt.xlabel('Episode' ) plt.ylabel('Total Reward' ) plt.title('Q-Learning on Cliff Walking' ) plt.grid(True ) plt.show() def extract_policy (Q, env ): policy = {} for s in [(i,j) for i in range (env.height) for j in range (env.width)]: q_values = [Q[(s, a)] for a in range (4 )] policy[s] = np.argmax(q_values) return policy optimal_policy = extract_policy(Q, env) print ("最优策略示例(起点附近):" , {s: ['↑' ,'→' ,'↓' ,'←' ][optimal_policy[s]] for s in [(3 ,0 ), (2 ,0 ), (2 ,1 ), (2 ,2 )]})
这段代码展示了 Q-Learning 的完整流程:初始化 Q 表、与环境交互、计算
TD 误差、更新 Q
值。运行后你会发现,学习曲线在初期震荡很大(频繁掉崖),但随着训练进行,智能体逐渐学会绕开悬崖,最终稳定在-13
左右的回报(最优路径长度)。
函数逼近的必要性与挑战
维度诅咒:为什么表格不够用
Cliff Walking 只有 48 个状态,用表格存储 Q 值完全没问题。但考虑 Atari
游戏:
Breakout(打砖块) :输入是 84x84x4 的灰度帧栈( 4
帧历史),状态空间大小约为Go(围棋) : 19x19 棋盘,每个交叉点有 3
种状态(黑/白/空),状态空间
解决方案是函数逼近( function
approximation):用一个参数化的函数
Deadly
Triad:稳定性的三重威胁
然而,函数逼近带来了严重的稳定性问题。 Sutton 和 Barto 在《
Reinforcement Learning: An Introduction 》中总结了 Deadly
Triad(致命三角):
Bootstrapping(自举) :用估计值更新估计值
Q-Learning 的更新目标
Function
Approximation(函数逼近) :用参数化函数替代表格
更新一个状态的 Q 值会影响到其他"相似"状态的 Q 值
Off-Policy(离策略) :学习的策略与行为策略不同
这三者结合会导致训练发散。让我们用数学分析为什么会这样。
发散的数学机制
考虑线性函数逼近:
问题在于,目标
更糟糕的是,函数逼近会引入泛化:更新
更新
但
再次泛化回
Baird 在 1995
年构造了一个反例,展示了即使是简单的线性函数逼近+Q-Learning
也会发散。在他的"star counterexample"中, 7 个状态连接成星形结构,用 6
个特征表示,标准的 Q-Learning 更新会导致参数
早期尝试:神经拟合 Q 迭代(
NFQ)
在 DQN 之前, Riedmiller 在 2005 年提出了神经拟合 Q 迭代( Neural
Fitted Q-Iteration, NFQ)。它的思路是:
收集一批经验$(s,a,r,s')用 当 前 网 络 计 算 目 标 用 监 督 学 习 训 练 网 络 , 最 小 化
NFQ 在一些简单任务上有效,但在 Atari
这样的高维环境中仍然不稳定。原因是: -
样本相关性 :连续收集的经验分布非平稳 :每次策略更新后,新收集的数据分布都会改变
DQN 的两大创新正是针对这两个问题。
DQN 的核心创新
经验回放( Experience
Replay):打破相关性
经验回放的想法来自于监督学习中的"打乱数据"(
shuffling)。在监督学习中,如果按顺序训练(比如先训练所有猫的图片,再训练所有狗的图片),模型容易过拟合到数据的顺序,导致灾难性遗忘(
catastrophic forgetting)。解决方法是在每个 epoch
开始时随机打乱数据。
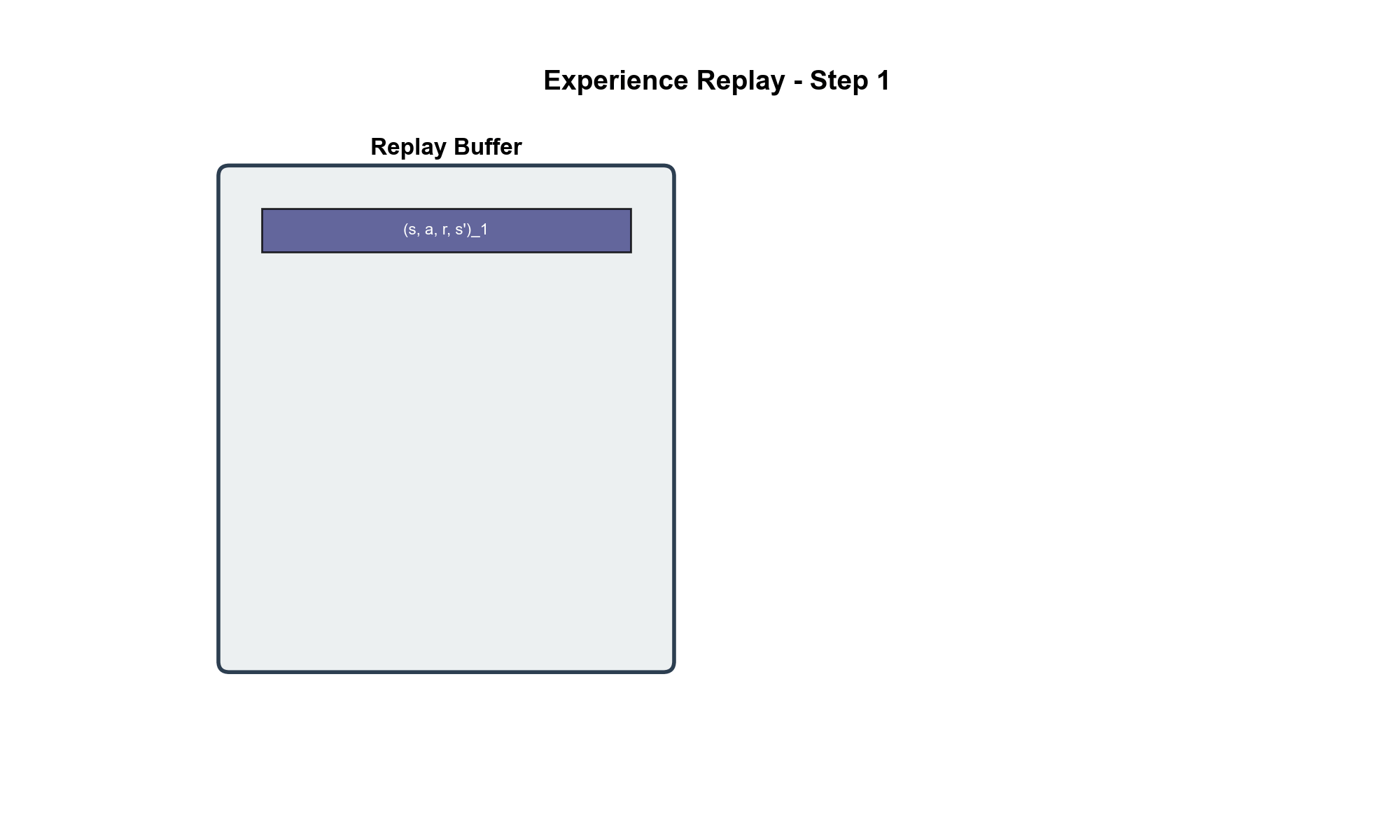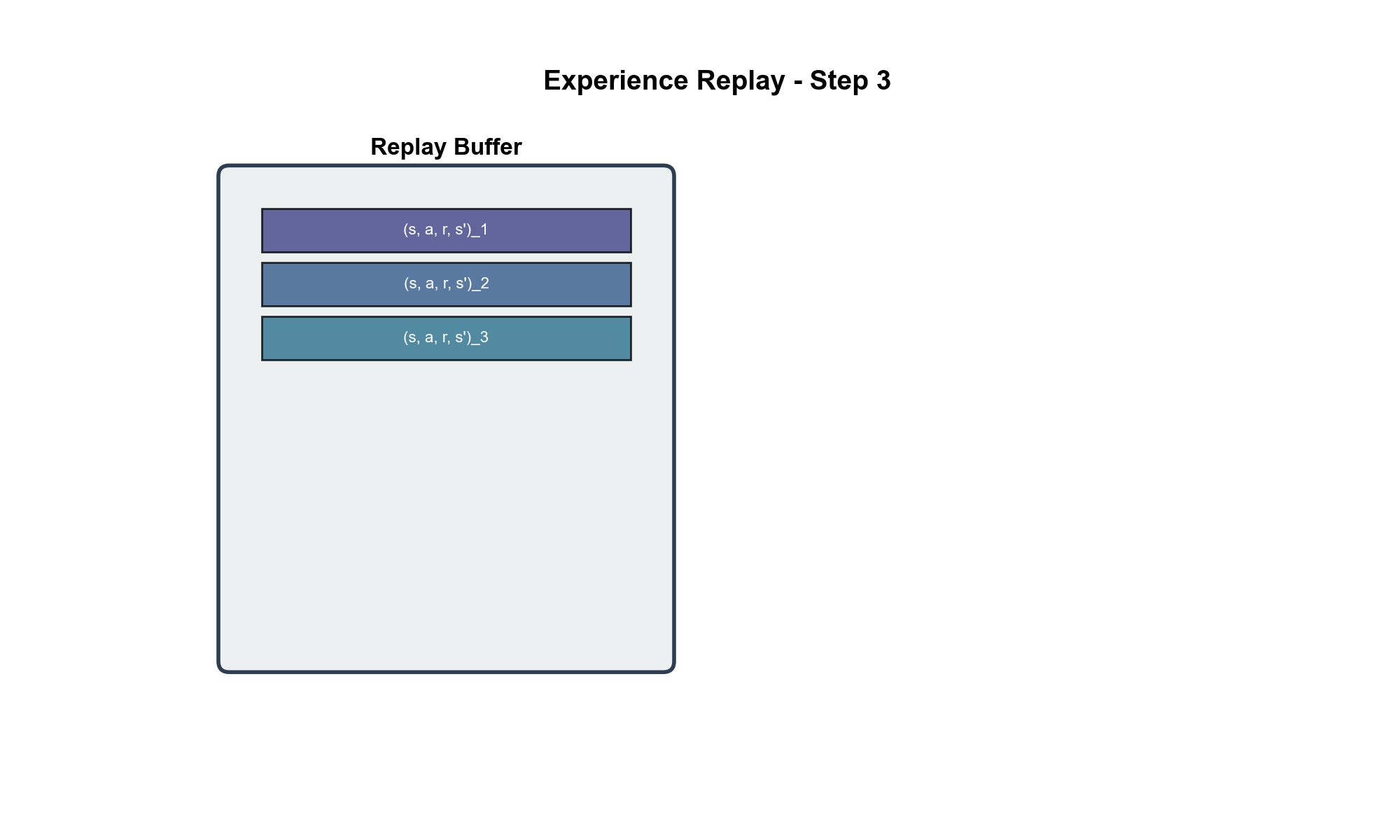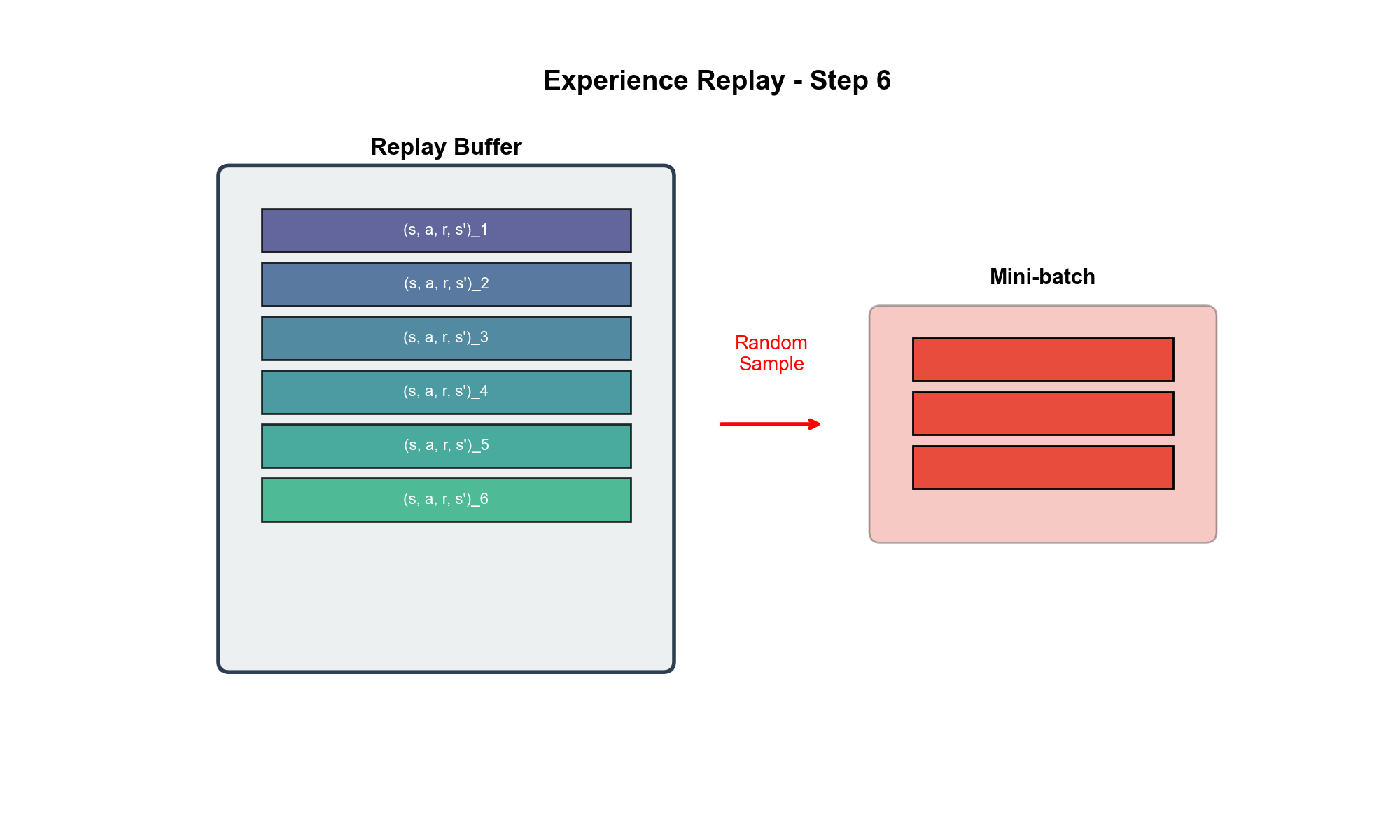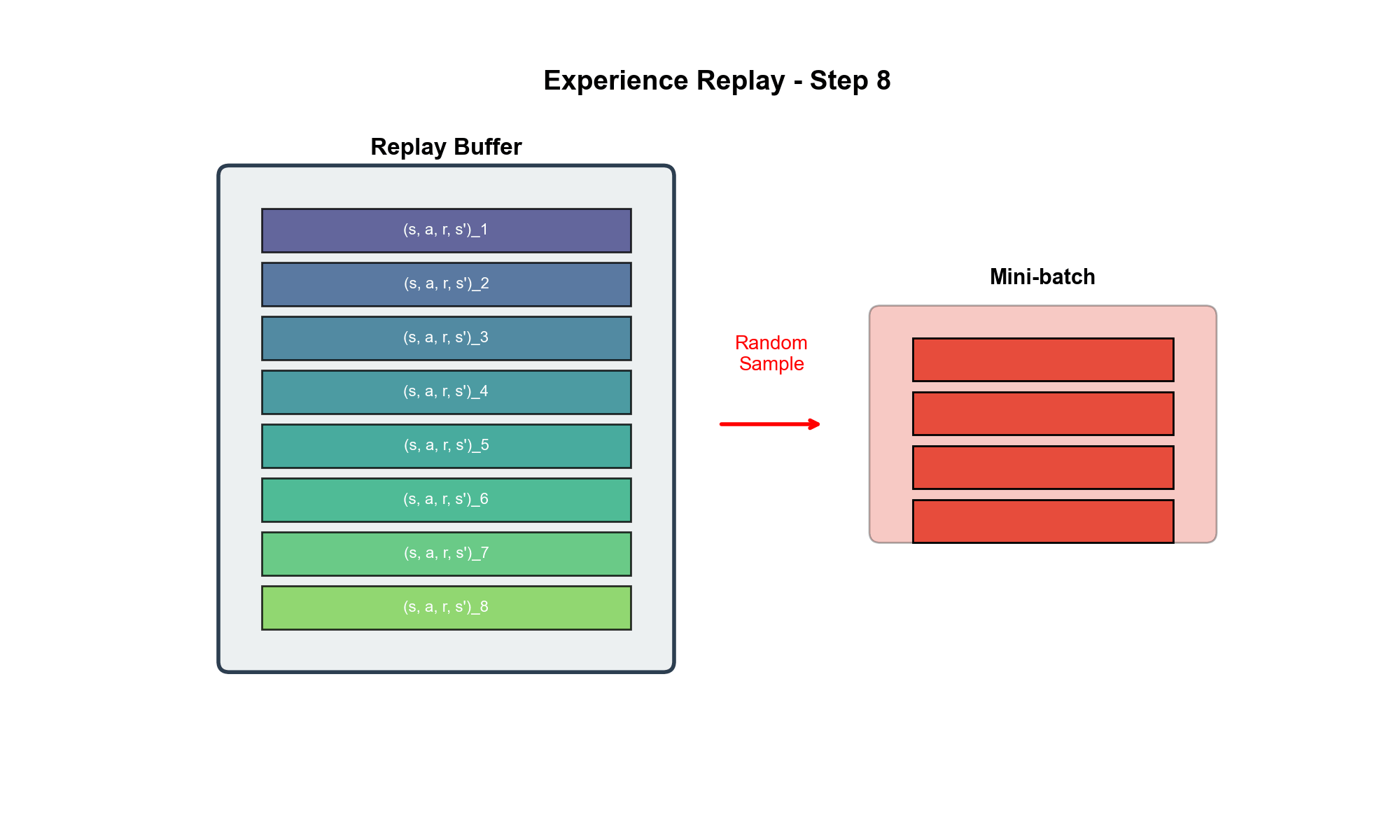
DQN 将这个思想应用到强化学习:
存储经验 :维护一个回放缓冲区( replay
buffer)
添加经验 :每次与环境交互得到
采样训练 :每次更新时,从
覆盖旧数据 :当
这样做有三大好处:
好处 1:打破时间相关性
连续的经验
从信息论角度看,设连续样本的互信息为足 够 大
这使得梯度估计的方差降低,训练更稳定。
好处 2:提高样本效率
在 on-policy
方法中,每条经验只能用一次(用完即扔)。而经验回放允许我们多次使用同一条经验——只要它还在
buffer
中,就可能被采样到。这对于样本昂贵的环境(比如机器人控制)特别重要。
设每条经验平均被使用
好处 3:平滑分布变化
策略更新时,新策略收集的数据分布会改变。但由于 buffer
中存储了大量旧策略的数据,当前训练用的数据分布是多个策略的混合,变化更加平滑。这避免了"急转弯"——一次策略更新导致数据分布剧变,进而导致下一次更新的目标完全不同。
数学上,设第
其中
实现细节: ReplayBuffer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import numpy as npimport randomfrom collections import dequeclass ReplayBuffer : """ 经验回放缓冲区 """ def __init__ (self, capacity=100000 ): self.buffer = deque(maxlen=capacity) def push (self, state, action, reward, next_state, done ): """添加一条经验""" self.buffer.append((state, action, reward, next_state, done)) def sample (self, batch_size ): """随机采样一批经验""" batch = random.sample(self.buffer, batch_size) states = np.array([x[0 ] for x in batch]) actions = np.array([x[1 ] for x in batch]) rewards = np.array([x[2 ] for x in batch]) next_states = np.array([x[3 ] for x in batch]) dones = np.array([x[4 ] for x in batch], dtype=np.float32) return states, actions, rewards, next_states, dones def __len__ (self ): return len (self.buffer)
这个实现用deque(双端队列)自动处理容量限制,新元素会挤掉最旧的元素。采样时用random.sample保证均匀性。
目标网络( Target
Network):稳定移动目标
即使有了经验回放, DQN 仍然面临"移动目标"问题:更新参数用一个独立的网络来计算目标,并定期同步 。
具体来说, DQN 维护两个网络:
在线网络( online network) :参数目标网络( target network) :参数
更新规则变为:
关键在于:在一定时间内(如 10000 步),
每隔
或者用软更新( soft update),每步都执行:
理论分析:为什么目标网络有效
考虑 TD 误差的期望:
如果目标
两者的变化可能相互抵消,导致更新无效。更糟糕的是,如果
目标网络切断了这个反馈循环:在
从优化角度看,固定目标网络相当于将目标函数
DQN 算法完整解析
伪代码与流程
现在我们可以写出完整的 DQN 算法:
算法: Deep Q-Network (DQN)
输入 : - 环境输出 :训练好的 Q
网络参数$初 始 化 回 放 缓 冲 区 ( 容 量 ) 随 机 初 始 化 网 络 参 数 初 始 化 目 标 网 络 参 数
for episodedo 5.a Q (s_t, a)i) {a'} Q_{^-}(s'i, a')计 算 损 失 : i (y_i -
Q (s_i, a_i))^2 ()衰 减 探 索 率 : {} , {}
)then breakend for
几个关键点:
第 11 行 :第 10 行 :只有当探索率衰减 :初期
损失函数与梯度计算
DQN 的损失函数是均方 TD 误差:
对
注意: 1. 目标
这与监督学习的回归损失
训练技巧
梯度裁剪( Gradient Clipping)
Atari 环境的奖励范围很大(比如 Breakout
的砖块得分可以累积到几百),导致 TD 误差也很大,梯度可能爆炸。 DQN
使用梯度裁剪:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10)。
学习率调度( Learning Rate Schedule)
DQN 通常使用固定学习率(如
奖励裁剪与归一化
Atari 游戏的奖励尺度差异很大( Pong 是-1/0/+1, Breakout
可以到几百)。 DQN 论文对所有正奖励裁剪到+1,负奖励裁剪到-1:
这使得不同游戏可以用相同的超参数。但代价是丢失了奖励的幅度信息——在某些任务中可能不合适。
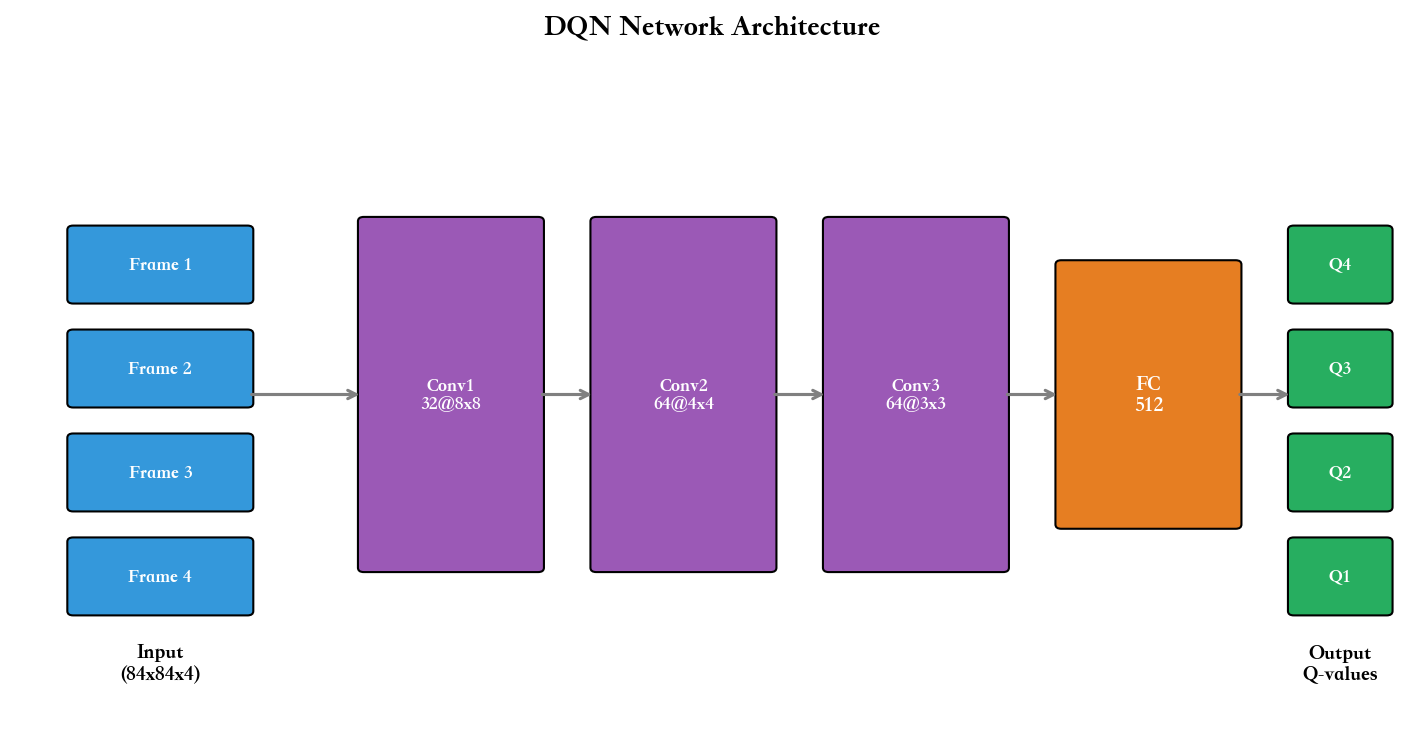
完整 Atari DQN 实现
下面是一个完整的 DQN 实现,用于 Atari Pong 游戏(约 350
行代码):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Fimport numpy as npimport randomfrom collections import dequeimport gymclass DQN (nn.Module): """ DQN 网络: 3 个卷积层 + 2 个全连接层 输入: 84x84x4 的状态( 4 帧灰度图像栈) 输出:每个动作的 Q 值 """ def __init__ (self, n_actions ): super (DQN, self).__init__() self.conv1 = nn.Conv2d(4 , 32 , kernel_size=8 , stride=4 ) self.conv2 = nn.Conv2d(32 , 64 , kernel_size=4 , stride=2 ) self.conv3 = nn.Conv2d(64 , 64 , kernel_size=3 , stride=1 ) self.fc1 = nn.Linear(64 * 7 * 7 , 512 ) self.fc2 = nn.Linear(512 , n_actions) def forward (self, x ): x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = F.relu(self.conv3(x)) x = x.view(x.size(0 ), -1 ) x = F.relu(self.fc1(x)) x = self.fc2(x) return x class ReplayBuffer : def __init__ (self, capacity ): self.buffer = deque(maxlen=capacity) def push (self, state, action, reward, next_state, done ): self.buffer.append((state, action, reward, next_state, done)) def sample (self, batch_size ): batch = random.sample(self.buffer, batch_size) states, actions, rewards, next_states, dones = zip (*batch) return (np.array(states), np.array(actions), np.array(rewards), np.array(next_states), np.array(dones, dtype=np.float32)) def __len__ (self ): return len (self.buffer) class DQNAgent : def __init__ (self, n_actions, device='cuda' ): self.n_actions = n_actions self.device = device self.policy_net = DQN(n_actions).to(device) self.target_net = DQN(n_actions).to(device) self.target_net.load_state_dict(self.policy_net.state_dict()) self.target_net.eval () self.optimizer = optim.Adam(self.policy_net.parameters(), lr=2.5e-4 ) self.memory = ReplayBuffer(capacity=100000 ) self.gamma = 0.99 self.batch_size = 32 self.epsilon_start = 1.0 self.epsilon_end = 0.01 self.epsilon_decay = 0.995 self.epsilon = self.epsilon_start self.target_update_freq = 10000 self.steps_done = 0 def select_action (self, state, training=True ): """选择动作( epsilon-greedy)""" if training and random.random() < self.epsilon: return random.randrange(self.n_actions) else : with torch.no_grad(): state_t = torch.FloatTensor(state).unsqueeze(0 ).to(self.device) q_values = self.policy_net(state_t) return q_values.argmax(dim=1 ).item() def train_step (self ): """执行一次训练更新""" if len (self.memory) < self.batch_size: return None states, actions, rewards, next_states, dones = self.memory.sample(self.batch_size) states = torch.FloatTensor(states).to(self.device) actions = torch.LongTensor(actions).to(self.device) rewards = torch.FloatTensor(rewards).to(self.device) next_states = torch.FloatTensor(next_states).to(self.device) dones = torch.FloatTensor(dones).to(self.device) current_q = self.policy_net(states).gather(1 , actions.unsqueeze(1 )).squeeze(1 ) with torch.no_grad(): next_q = self.target_net(next_states).max (1 )[0 ] target_q = rewards + (1 - dones) * self.gamma * next_q loss = F.mse_loss(current_q, target_q) self.optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(self.policy_net.parameters(), max_norm=10 ) self.optimizer.step() self.steps_done += 1 if self.steps_done % self.target_update_freq == 0 : self.target_net.load_state_dict(self.policy_net.state_dict()) if self.epsilon > self.epsilon_end: self.epsilon *= self.epsilon_decay return loss.item() def save (self, path ): torch.save(self.policy_net.state_dict(), path) def load (self, path ): self.policy_net.load_state_dict(torch.load(path)) self.target_net.load_state_dict(self.policy_net.state_dict()) class AtariPreprocessing : """Atari 环境预处理:灰度化、缩放、帧栈""" def __init__ (self, env, frame_stack=4 ): self.env = env self.frame_stack = frame_stack self.frames = deque(maxlen=frame_stack) def reset (self ): obs = self.env.reset() obs = self._preprocess(obs) for _ in range (self.frame_stack): self.frames.append(obs) return self._get_state() def step (self, action ): obs, reward, done, info = self.env.step(action) obs = self._preprocess(obs) self.frames.append(obs) return self._get_state(), np.sign(reward), done, info def _preprocess (self, frame ): """灰度化并缩放到 84x84""" frame = frame[34 :194 ] frame = frame[::2 , ::2 , 0 ] frame = frame / 255.0 return frame def _get_state (self ): """返回 4 帧栈""" return np.array(self.frames) def train_dqn (env_name='PongNoFrameskip-v4' , n_episodes=1000 , device='cuda' ): env = gym.make(env_name) env = AtariPreprocessing(env) n_actions = env.env.action_space.n agent = DQNAgent(n_actions, device=device) episode_rewards = [] episode_losses = [] for episode in range (n_episodes): state = env.reset() total_reward = 0 losses = [] while True : action = agent.select_action(state) next_state, reward, done, _ = env.step(action) total_reward += reward agent.memory.push(state, action, reward, next_state, done) loss = agent.train_step() if loss is not None : losses.append(loss) state = next_state if done: break episode_rewards.append(total_reward) avg_loss = np.mean(losses) if losses else 0 episode_losses.append(avg_loss) if (episode + 1 ) % 10 == 0 : avg_reward = np.mean(episode_rewards[-10 :]) print (f"Episode {episode+1 } , Avg Reward: {avg_reward:.2 f} , " f"Epsilon: {agent.epsilon:.3 f} , Loss: {avg_loss:.4 f} " ) if (episode + 1 ) % 100 == 0 : agent.save(f'dqn_pong_{episode+1 } .pth' ) return agent, episode_rewards, episode_losses if __name__ == '__main__' : device = 'cuda' if torch.cuda.is_available() else 'cpu' print (f"Using device: {device} " ) agent, rewards, losses = train_dqn(n_episodes=1000 , device=device) import matplotlib.pyplot as plt plt.figure(figsize=(12 , 5 )) plt.subplot(1 , 2 , 1 ) plt.plot(rewards, alpha=0.3 ) plt.plot(np.convolve(rewards, np.ones(50 )/50 , mode='valid' ), linewidth=2 ) plt.xlabel('Episode' ) plt.ylabel('Total Reward' ) plt.title('Training Rewards' ) plt.grid(True ) plt.subplot(1 , 2 , 2 ) plt.plot(losses, alpha=0.3 ) plt.plot(np.convolve(losses, np.ones(50 )/50 , mode='valid' ), linewidth=2 ) plt.xlabel('Episode' ) plt.ylabel('Loss' ) plt.title('Training Loss' ) plt.grid(True ) plt.tight_layout() plt.savefig('dqn_training.png' ) plt.show()
这段代码包含了 DQN 的所有关键组件:卷积神经网络、经验回放、目标网络、
epsilon-greedy 探索、梯度裁剪。在 Pong 游戏上训练约 200-300 个 episode
后,智能体通常能达到接近最优的表现(平均奖励接近+21,即每局赢 21
分)。
DQN 变体:从 Double 到
Rainbow
Double DQN:解决 Q 值过估计
问题:
DQN 的更新目标
设真实 Q 值为
即使
这个不等式是 Jensen 不等式(对于凸函数
解决方案:解耦选择与评估
Double DQN( van Hasselt et al.,
2016)的思想是:用在线网络选择动作,用目标网络评估该动作的价值。更新目标变为:
注意到
数学上,设两个独立估计的误差为
因为
数值示例
考虑一个状态
DQN :Double DQN :在线网络选择动作 2(
Q=12),目标网络评估为
实现
只需修改一行代码:
1 2 3 4 5 6 7 8 9 10 with torch.no_grad(): next_q = self.target_net(next_states).max (1 )[0 ] target_q = rewards + (1 - dones) * self.gamma * next_q with torch.no_grad(): next_actions = self.policy_net(next_states).argmax(1 ) next_q = self.target_net(next_states).gather(1 , next_actions.unsqueeze(1 )).squeeze(1 ) target_q = rewards + (1 - dones) * self.gamma * next_q
实验表明, Double DQN 在多数 Atari
游戏上都能减少过估计,提升稳定性和最终性能。
Dueling
DQN:分离状态价值与优势
动机:不是所有状态都需要关心动作
考虑 Atari 游戏中的两种场景: 1. 紧急情况 (比如 Pong
中球即将错过):选择哪个动作至关重要 2.
平淡时刻 (比如球远离挡板):无论选什么动作,价值都差不多
传统 DQN 用同一个网络头输出所有
其中: -
直觉上,
可识别性问题
直接分离
或者用最大优势为 0(实践中更常用):
这样,最优动作的
网络架构
Dueling DQN 的卷积层与 DQN 相同,但全连接层分为两个流(
stream):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class DuelingDQN (nn.Module): def __init__ (self, n_actions ): super (DuelingDQN, self).__init__() self.conv1 = nn.Conv2d(4 , 32 , kernel_size=8 , stride=4 ) self.conv2 = nn.Conv2d(32 , 64 , kernel_size=4 , stride=2 ) self.conv3 = nn.Conv2d(64 , 64 , kernel_size=3 , stride=1 ) self.value_fc = nn.Linear(64 * 7 * 7 , 512 ) self.value_head = nn.Linear(512 , 1 ) self.advantage_fc = nn.Linear(64 * 7 * 7 , 512 ) self.advantage_head = nn.Linear(512 , n_actions) def forward (self, x ): x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = F.relu(self.conv3(x)) x = x.view(x.size(0 ), -1 ) value = F.relu(self.value_fc(x)) value = self.value_head(value) advantage = F.relu(self.advantage_fc(x)) advantage = self.advantage_head(advantage) q_values = value + (advantage - advantage.mean(dim=1 , keepdim=True )) return q_values
为什么有效
Dueling
架构的优势在于价值函数的学习更高效 。在很多状态下,动作的选择对价值影响很小——此时
实验表明, Dueling DQN 在需要长期规划的任务(如 Seaquest 、
Enduro)中提升明显,因为这些任务中状态价值的差异更重要。
Prioritized Experience
Replay:重要性采样
问题:并非所有经验同等重要
均匀随机采样的经验回放假设所有经验同等重要,但直觉上: - TD
误差大的经验 更"出乎意料",包含更多信息 - TD
误差小的经验 已经被学得很好,重复训练意义不大
Prioritized Experience Replay( PER, Schaul et al., 2016)根据 TD
误差的大小来分配采样概率。
优先级定义
每条经验的优先级定义为:
其中
其中
重要性采样权重
Prioritized
采样改变了数据分布,会引入偏差。为了修正,使用重要性采样权重:
并归一化:
实现
需要维护一个优先级队列,可以用 SumTree 数据结构实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class PrioritizedReplayBuffer : def __init__ (self, capacity, alpha=0.6 ): self.capacity = capacity self.alpha = alpha self.buffer = [] self.priorities = np.zeros(capacity, dtype=np.float32) self.position = 0 def push (self, transition ): max_priority = self.priorities.max () if self.buffer else 1.0 if len (self.buffer) < self.capacity: self.buffer.append(transition) else : self.buffer[self.position] = transition self.priorities[self.position] = max_priority self.position = (self.position + 1 ) % self.capacity def sample (self, batch_size, beta=0.4 ): N = len (self.buffer) priorities = self.priorities[:N] probs = priorities ** self.alpha probs /= probs.sum () indices = np.random.choice(N, batch_size, p=probs) weights = (N * probs[indices]) ** (-beta) weights /= weights.max () batch = [self.buffer[i] for i in indices] return batch, indices, weights def update_priorities (self, indices, td_errors ): """更新 TD 误差对应的优先级""" for idx, td_error in zip (indices, td_errors): self.priorities[idx] = abs (td_error) + 1e-6
PER
在样本效率上有显著提升,但实现复杂度更高,训练时间也略有增加。
其他 Rainbow 组件
Noisy Networks :用可学习的噪声替代
其中
Multi-step Learning :用 n-step return 替代 1-step TD
目标:
Distributional RL (C51) :不学习 Q
值的期望,而是学习整个分布。将值域离散化为 51 个桶(
bins),用交叉熵损失训练分布预测。这能捕捉风险(方差)信息,在探索中更有利。
Rainbow :将以上 6 种技术( Double DQN 、 Dueling 、
PER 、 Noisy Nets 、 Multi-step 、 C51)全部组合,在 Atari 上达到当时的
SOTA
性能。消融实验表明,每种技术都有贡献,且组合效果超过单独叠加(协同作用)。
理论分析
经验回放的理论保证
从优化角度看,经验回放相当于从经验分布
如果
好消息是, Munos 等人( 2016)证明了:如果 replay buffer
中的数据满足一定的覆盖性条件( coverage),且目标网络更新足够慢, DQN
仍然能以一定概率收敛到近似最优解,误差界为
目标网络的方差分析
目标网络的作用可以从方差-偏差权衡来理解。考虑 TD 目标的方差:
如果
代价是引入了偏差:
数学上,可以用 Bellman 误差的期望来量化:
其中
实战技巧与调试
超参数选择
超参数
典型值
说明
buffer_size100k-1M
越大越好,但内存有限; Atari 用 1M
batch_size32-128
太小不稳定,太大训练慢; 32 是常见选择
learning_rate1e-4 到 1e-3
Adam 优化器通常用 2.5e-4
gamma0.99
折扣因子,长期任务用 0.99,短期任务可用 0.9
epsilon_start1.0
初始探索率
epsilon_end0.01-0.1
最终探索率, 0.01 适合 Atari
epsilon_decay0.995
每轮衰减因子,或用线性衰减
target_update_freq1k-10k
目标网络更新频率, 10k 步是常见选择
调参建议 : 1.
先用较小的buffer_size和较大的learning_rate快速验证代码正确性
2. 确认 loss 在下降、 reward 在上升后,再用完整超参数长时间训练 3.
如果训练不稳定( loss 振荡、 reward
崩溃),减小learning_rate或增大target_update_freq
训练曲线分析
正常曲线 : reward 逐渐上升, loss 先上升后下降 -
初期 ( 0-100 episodes): reward 接近随机水平, loss
上升(因为 Q 值从 0 开始增长, TD 误差变大) - 中期 (
100-500 episodes): reward 快速提升, loss 达到峰值后下降( Q
值趋于稳定) - 后期 ( 500+ episodes): reward
收敛到接近最优, loss 稳定在低水平
异常现象 : - Loss 爆炸 :突然增大到
1e3 甚至 1e6 - 原因:梯度爆炸或 Q 值发散 -
解决:检查梯度裁剪,降低学习率,检查奖励是否未归一化 - Reward
崩溃 :先上升后突然下降并不再恢复 -
原因:灾难性遗忘或陷入局部最优 - 解决:增大
buffer_size,降低学习率,检查目标网络更新是否过于频繁 - Reward
不涨 :长时间停留在随机水平 - 原因:探索不足或网络容量不够 -
解决:增大 epsilon 或延长 epsilon_decay,检查网络架构
调试技巧
1. 监控 Q 值分布
在训练过程中打印 Q 值的统计量:
1 2 3 4 with torch.no_grad(): q_values = agent.policy_net(states) print (f"Q mean: {q_values.mean():.2 f} , Q std: {q_values.std():.2 f} , " f"Q max: {q_values.max ():.2 f} , Q min: {q_values.min ():.2 f} " )
正常情况下, Q 值应该逐渐增大并稳定。如果 Q 值持续爆炸(如超过
1000),说明有问题。
2. 检查 TD 误差
打印 TD 误差的分布:
1 2 td_errors = (target_q - current_q).abs () print (f"TD error mean: {td_errors.mean():.4 f} , max: {td_errors.max ():.4 f} " )
TD
误差应该逐渐减小。如果长期停留在高位,说明网络没有学到有用的模式。
3. 可视化动作分布
统计智能体选择各个动作的频率:
1 2 3 4 5 action_counts = np.zeros(n_actions) for _ in range (100 ): action = agent.select_action(state, training=False ) action_counts[action] += 1 print ("Action distribution:" , action_counts / 100 )
如果某个动作从不被选择,可能是网络陷入了局部最优。
4. 简化环境测试
在复杂环境(如 Atari)调试时,先在简单环境(如
CartPole)上验证代码正确性:
1 2 env = gym.make('CartPole-v1' )
如果简单环境都不 work,说明代码有 bug 。
深度 Q&A
Q1:为什么 DQN 用
off-policy 而不是 on-policy?
A : Off-policy
的核心优势是数据利用效率 。 On-policy 方法(如 SARSA 、
A3C)要求训练数据必须来自当前策略——每次更新策略后,旧数据就作废了。而
off-policy 方法(如 Q-Learning 、
DQN)可以使用任意策略收集的数据,只要它探索了相关的状态-动作对。
DQN 的经验回放正是利用了这一点: buffer
中的数据来自过去的多个策略(
代价是 off-policy
方法更难收敛(因为数据分布与目标策略不匹配),需要额外的稳定化技术(如目标网络)。但在样本昂贵的场景(如机器人、
Atari),这个 trade-off 是值得的。
Q2:经验回放的 buffer
大小如何选择?
A : Buffer 大小
覆盖性 :新鲜度 :内存限制 :存储
典型选择: - Atari : 1M(约 28GB 内存) -
简单环境 (如 CartPole): 10k-100k -
连续控制 (如 MuJoCo): 100k-1M
经验法则: buffer 应该能容纳至少 100 个完整 episode
的数据。如果太小(如只有 10 个 episode), buffer
会频繁被覆盖,样本多样性不足。
实验建议:先用较小的 buffer(如 10k)快速迭代,确认代码正确后再用大
buffer 训练。
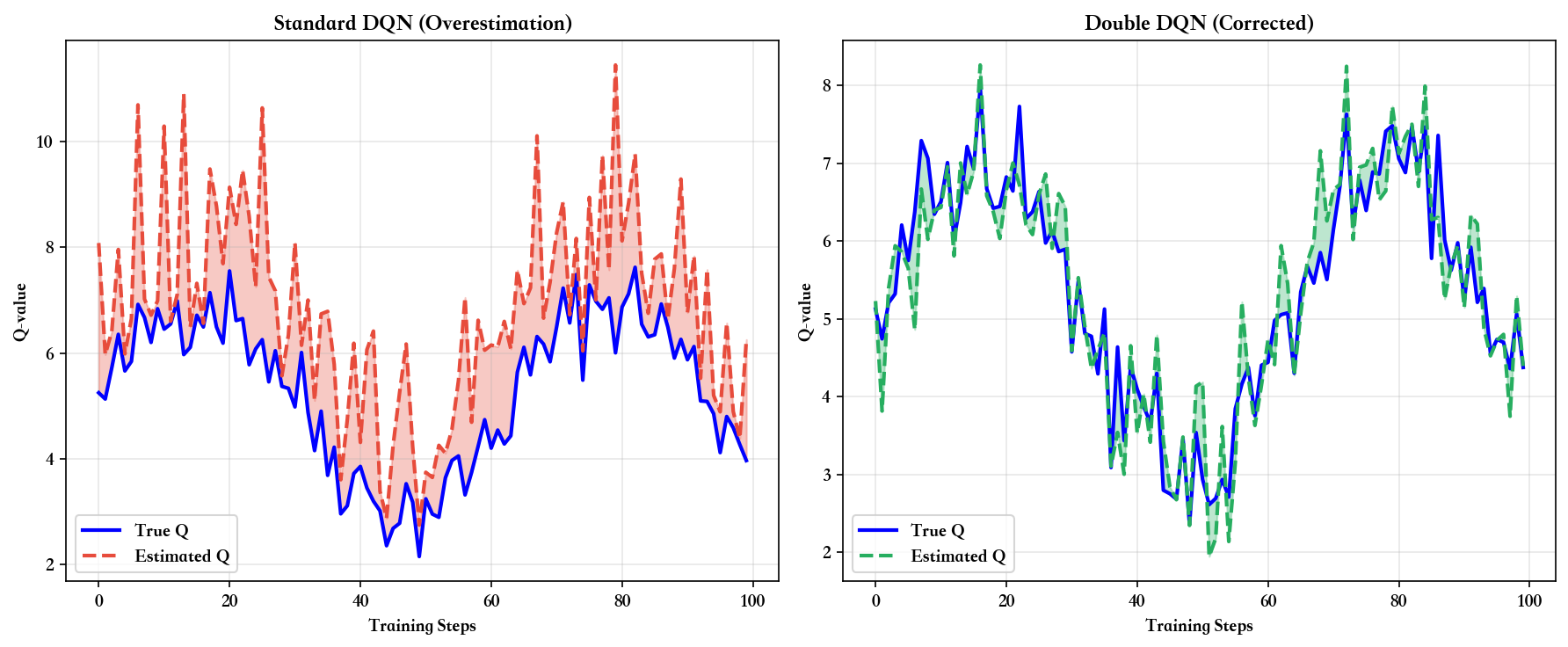
Q3: Double DQN
解决的过估计问题有多严重?
A :在很多 Atari 游戏中, DQN 的 Q 值过估计非常显著。
van Hasselt 等人在论文中展示了一个例子:
Pong 游戏 :真实 Q 值范围约为-21
到+21(游戏得分)DQN 估计 : Q 值逐渐膨胀到+50 甚至+100Double DQN 估计 :稳定在-21 到+21 附近
过估计的严重性取决于环境的随机性和动作空间大小: -
随机性大 (如噪声奖励)→ 估计误差大 → 过估计严重 -
动作多 (如 18 个动作)→
在某些游戏中(如
Seaquest),过估计会导致智能体选择次优策略——因为某些"看起来很好"的动作(
Q 值被高估)实际上很差。 Double DQN 通过解耦选择与评估,能减少
50%-90%的过估计偏差。
但也有例外:在确定性环境(如下棋)中,过估计问题较轻, Double DQN
的提升有限。
Q4: Dueling DQN
在什么场景下效果最好?
A : Dueling DQN
在动作的影响差异小 的场景中提升最大。具体包括:
长期规划任务 (如 Seaquest 、
Enduro):大部分时间在"巡航",只有少数关键时刻需要精确动作。状态价值
动作冗余度高 (如 Atari
中某些动作几乎等价):比如"向左"和"向左+射击"在没有敌人时效果相同。
Dueling 能自动识别这种冗余,集中学习
稀疏奖励环境 :在大部分状态下,所有动作的 Q
值都接近(因为奖励稀疏),此时
反例:在动作差异大 的环境(如格斗游戏,每个动作都至关重要)中,
Dueling 的优势不明显,因为优势函数
Q5: Rainbow 为什么不是简单的
1+1=2?
A : Rainbow
的性能提升并非各技术的简单叠加,而是有协同作用 (
synergy)。消融实验表明:
单独的 Double DQN:提升 30%
单独的 Dueling DQN:提升 20%
两者组合:提升 60%(大于 30%+20%)
原因是: - Double DQN 减少过估计 → Dueling 的PER
优先训练重要样本 → 加速 Double DQN 的过估计修正 → 更快收敛 -
Multi-step Learning 加速信用分配 → 配合 Distributional
RL 捕捉不确定性 → 探索更高效
但也有负面交互: PER 的重要性采样权重
Q6: DQN
为什么不能处理连续动作空间?
A : DQN 的核心操作是
但在连续动作空间(如机器人关节角度
没有解析解,需要用优化算法(如梯度上升、遗传算法)求解。这不仅计算昂贵,还会引入额外的近似误差。
解决方案: - 离散化 :将连续动作空间划分为网格(如
10x10),但维度灾咒会导致组合爆炸 - Actor-Critic
方法 :用单独的 actor 网络NAF( Normalized Advantage
Functions) :将 Q 函数参数化为二次型
Q7:如何判断 DQN
训练是否收敛?
A :判断收敛的多个指标:
Reward 稳定 :在测试环境中(
deterministic,无探索),连续 100 个 episode 的平均 reward
不再增长,且方差小于 5%。
Q 值稳定 :监控
如果连续 1000 步的
策略稳定 :在相同状态下,连续多次推理的动作一致性:相 同 动 作 总 次 数
TD 误差稳定 :测试集上的平均 TD 误差
实践中, Atari 游戏通常需要 10M-50M 帧(约 200-1000
episodes)才能收敛。如果训练 1000 episodes 后 reward
仍在随机游走,说明有问题。
Q8: DQN vs
PPO,什么时候用哪个?
A : DQN 和 PPO 各有适用场景:
特性
DQN
PPO
动作空间 离散(小规模)
离散+连续
样本效率 高(经验回放)
低( on-policy)
稳定性 需调参(目标网络等)
开箱即用
并行化 单环境训练
多环境并行
适用任务 Atari 、离散控制
机器人、连续控制
选择建议 : - 离散动作 +
样本昂贵 (如机器人抓取每次尝试 5 分钟) → DQN -
连续动作 + 可大量采样 (如模拟器环境) → PPO -
需要快速原型 (不想调参) → PPO -
追求极致性能 (愿意精调) → Rainbow DQN
有趣的现象:在 Atari 上, DQN 的最终性能通常高于 PPO,但 PPO
的训练曲线更平滑。这反映了 off-policy 方法的"高风险高回报"特性。
Q9:如何处理高维图像输入(
Atari)?
A : Atari 环境的原始观测是 210x160x3 的 RGB
图像,直接作为输入会导致:
维度过高 : 210x160x3 = 100,800
维,网络参数量爆炸冗余信息 :大部分像素是背景(黑色),信息密度低时间相关性 :单帧无法判断速度(如球的运动方向)
DQN 的预处理流程:
步骤 1:灰度化 1 gray = np.dot(rgb[...,:3 ], [0.299 , 0.587 , 0.114 ])
步骤 2:裁剪无关区域 1 cropped = gray[34 :194 , :]
步骤 3:下采样 1 resized = cv2.resize(cropped, (84 , 84 ))
步骤 4:帧栈( Frame Stacking) 1 state = np.stack([frame_t, frame_{t-1 }, frame_{t-2 }, frame_{t-3 }], axis=0 )
帧栈解决了速度信息问题——网络可以通过比较相邻帧推断运动方向。
步骤 5:归一化
经过这些处理,输入从 100,800 维降到 84x84x4 = 28,224
维,信息密度大幅提升。
Q10: DQN 的 sample
efficiency 如何?
A : Sample efficiency
衡量的是"达到目标性能需要多少样本"。 DQN 在这方面表现中等:
与表格方法比较 : - 表格
Q-Learning ( CartPole):约 5000 步 - DQN (
CartPole):约 50,000 步
DQN 需要 10 倍样本,因为神经网络需要更多数据来拟合 Q 函数。
与 on-policy 方法比较 : - DQN (
Atari Pong):约 200 万帧 - A3C ( on-policy):约 1000
万帧
DQN 的经验回放提升了 5 倍样本效率。
与 model-based 方法比较 : -
DQN (模拟器环境):约 10 万步 -
Dyna-Q ( model-based):约 1 万步
Model-based
方法通过学习环境模型并在模型中模拟,可以用更少的真实交互。
绝对数值 :在 Atari 上, DQN 通常需要 10M-50M 帧(约
40-200
小时游戏时间)才能达到人类水平。这对于机器人等真实环境来说是不可接受的——因此实际应用中,
DQN 更多用于模拟器环境,或结合 sim-to-real 技术。
提升 sample efficiency 的方向: - 更好的网络架构 (如
ResNet 、 Transformer) -
辅助任务 (如自监督学习、对比学习) -
迁移学习 (预训练+微调)
参考文献
以下是 DQN 及其变体的核心论文(按时间顺序):
Watkins, C. J., & Dayan, P. (1992).
Q-learning. Machine Learning , 8(3-4), 279-292.论文链接 Q-Learning 算法的收敛性证明
Mnih, V., Kavukcuoglu, K., Silver, D., et al.
(2013). Playing Atari with Deep Reinforcement Learning.
NIPS Deep Learning Workshop .arXiv:1312.5602 DQN 首次提出,引入经验回放和目标网络
Mnih, V., Kavukcuoglu, K., Silver, D., et al.
(2015). Human-level control through deep reinforcement
learning. Nature , 518(7540), 529-533.Nature
论文 DQN 完整版,在 49 款 Atari 游戏上达到人类水平
van Hasselt, H., Guez, A., & Silver, D.
(2016). Deep Reinforcement Learning with Double Q-learning.
AAAI .arXiv:1509.06461 Double DQN,解决 Q 值过估计
Wang, Z., Schaul, T., Hessel, M., et al. (2016).
Dueling Network Architectures for Deep Reinforcement Learning.
ICML .arXiv:1511.06581 Dueling DQN,分离状态价值与优势函数
Schaul, T., Quan, J., Antonoglou, I., & Silver, D.
(2016). Prioritized Experience Replay. ICLR .arXiv:1511.05952 PER,根据 TD 误差优先采样
Fortunato, M., Azar, M. G., Piot, B., et al.
(2018). Noisy Networks for Exploration. ICLR .arXiv:1706.10295 Noisy Networks,可学习的探索噪声
Bellemare, M. G., Dabney, W., & Munos, R.
(2017). A Distributional Perspective on Reinforcement Learning.
ICML .arXiv:1707.06887 C51,学习值分布而非期望
Hessel, M., Modayil, J., van Hasselt, H., et al.
(2018). Rainbow: Combining Improvements in Deep Reinforcement
Learning. AAAI .arXiv:1710.02298 Rainbow,集成 6 种 DQN 改进技术
Sutton, R. S., & Barto, A. G. (2018).
Reinforcement Learning: An Introduction (2nd ed.). MIT Press.在线版 强化学习经典教材,详细讲解 Q-Learning 和 Deadly Triad
从 Q-Learning 的表格更新到 DQN 的深度学习,从单一算法到 Rainbow
的技术集成, value-based 方法在过去三十年经历了巨大演进。 DQN
的两大创新——经验回放和目标网络——不仅解决了深度 Q
网络的稳定性问题,也为后续的 Deep RL 算法提供了设计范式。 Double DQN 、
Dueling DQN 、 PER
等变体各有侧重,针对性地解决过估计、学习效率、样本效率等问题。 Rainbow
的成功表明,精心组合的技术栈能产生超过简单叠加的协同效应。
然而, DQN
的局限也很明显:仅适用于离散动作空间,在连续控制任务中捉襟见肘。下一章我们将转向
Policy Gradient 方法和 Actor-Critic
架构,探讨如何直接优化策略,并自然地处理连续动作空间——这将引领我们进入
DDPG 、 TD3 、 SAC 等现代算法的世界。