当多个智能体在同一环境中交互时,单智能体强化学习的基本假设——环境的平稳性——被打破了。在自动驾驶中,每辆车都是智能体,它们的决策相互影响;在多人游戏中,对手的策略演化决定了你的最优策略;在机器人协作中,团队的成功依赖于每个成员的配合。多智能体强化学习(Multi-Agent
Reinforcement Learning,
MARL)研究如何让多个智能体在复杂交互中学习协作、竞争或混合策略。这个领域的挑战远超单智能体:环境从智能体视角看是非平稳的(其他智能体在不断学习),信用分配变得困难(团队成功时如何归功于个体?),部分可观测性加剧了不确定性(你看不到队友在做什么)。但这些挑战也带来了新的机会——通过建模其他智能体、通信协议、集中式训练+分布式执行等技术,MARL
在星际争霸、 Dota 2 、自动驾驶仿真等复杂任务中取得了突破。 DeepMind 的
AlphaStar 达到星际争霸大师级水平,OpenAI Five 在 Dota 2
上击败世界冠军,这些成功展示了 MARL
作为通向通用智能的关键路径。本章将从博弈论的数学基础讲起,逐步深入独立学习、值分解、多智能体
Actor-Critic 等核心方法,并通过完整代码帮助你实现协作任务中的 QMIX
算法。
多智能体系统的核心挑战
挑战
1:非平稳性(Non-stationarity)
在单智能体 RL 中,环境的转移概率
其中非平稳 的。这导致: -
过去收集的经验
实例 :在足球游戏中,如果对手从"随机踢球"进化到"防守反击",你的"全场压上"策略的价值会突然崩溃。
挑战 2:信用分配(Credit
Assignment)
在协作任务中,团队获得全局奖励
懒惰智能体(Lazy Agent) :如果智能体
相对过拟合(Relative
Overgeneralization) :假设有两个动作
数学上 :全局奖励
如何从
挑战
3:部分可观测性(Partial Observability)
在许多任务中,每个智能体只能观测到局部信息部分可观测马尔可夫博弈(Partially
Observable Stochastic Game, POSG) :
全局状态
智能体需要基于历史观测
这需要记忆机制(如 RNN)来推断隐藏状态
实例 :在星际争霸中,你看不到地图未探索区域的敌军,必须根据侦察历史推断对手战略。
挑战 4:可扩展性(Scalability)
联合动作空间随智能体数量指数增长:
对于
博弈论基础:理解多智能体交互
马尔可夫博弈(Markov Game)
多智能体系统可以形式化为马尔可夫博弈 (也称随机博弈):
-
每个智能体
注意
Nash 均衡
定义 :策略组合Nash
均衡 ,如果对所有智能体
即:给定其他智能体的策略
实例:囚徒困境
两个囚徒同时选择"合作"或"背叛",奖励矩阵:
合作
背叛
合作
(3,3)
(0,5)
背叛
(5,0)
(1,1)
-合 作 合 作 背 叛 背 叛
性质 :
存在性 :任何有限博弈至少有一个混合策略 Nash
均衡(Nash, 1950)非唯一性 :可能存在多个均衡(如协调博弈)次优性 :Nash 均衡不一定 Pareto 最优(如囚徒困境)
Pareto 最优
定义 :策略组合Pareto
最优 ,如果不存在其他策略组合
协作任务的特例 :如果所有智能体共享奖励
这时 Nash 均衡和 Pareto 最优重合,问题简化为团队优化。
零和博弈与极小极大
在零和博弈 中,极小极大定理 计算:$
这正是 AlphaGo 等棋类 AI 的理论基础。
独立学习 vs 联合学习
独立学习(Independent
Learning)
最简单的方法:每个智能体将其他智能体视为环境的一部分,独立运行单智能体
RL 算法(如 DQN 、 PPO)。
优点 : - 简单:直接复用现有算法 -
可扩展:与智能体数量线性复杂度
缺点 : - 非平稳性:其他智能体的策略变化导致环境不稳定
- 无协调:智能体无法预测或适应队友行为 -
收敛性差:可能震荡或陷入次优均衡
经验上的成功 :尽管理论问题多,独立学习在某些任务中仍有效——如果环境足够稳定或智能体足够多(其他智能体的平均行为相对平稳)。
联合学习(Joint Learning)
学习联合策略
优点 : - 考虑了智能体间的协调 - 收敛到团队最优
缺点 : - 指数复杂度:联合动作空间
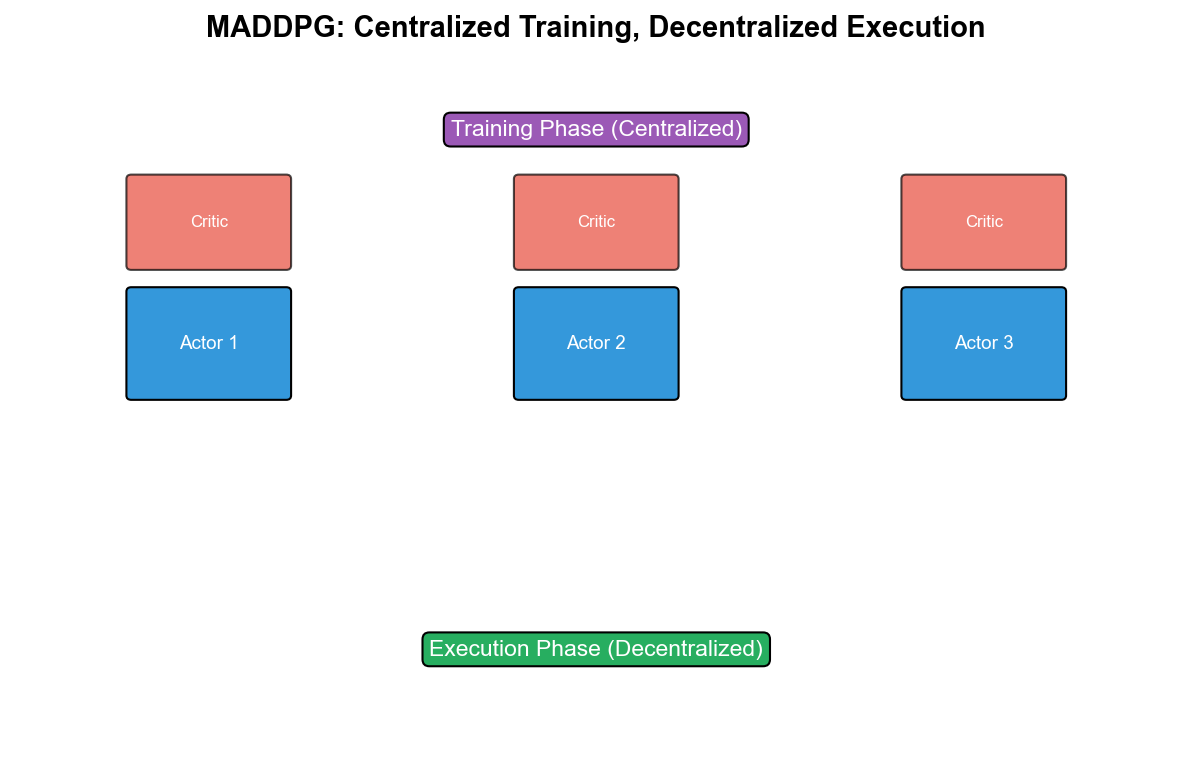
折中方案 :集中训练+分散执行(Centralized Training with
Decentralized Execution,
CTDE)——训练时使用全局信息,执行时每个智能体只依赖局部观测。
值分解方法:从 VDN 到 QMIX
值分解方法的核心思想:将全局 Q 函数
VDN:值分解网络
VDN (Value Decomposition Networks, 2017)假设全局 Q
函数是局部 Q 函数的简单和 :
训练 : - 集中:用全局奖励
关键性质 :个体贪心
因为求和可以分解:
局限性 :线性分解限制了表达能力。考虑一个场景: -
两个智能体在通道中,如果同时走会碰撞(
QMIX:单调值分解
QMIX (2018)用神经网络混合单调性约束 :
这保证了个体贪心仍是联合贪心(称为个体-全局最大一致性,Individual-Global-Max,IGM )。
网络架构 :
其中混合网络
超网络 :从全局状态
两层前馈网络 :
单调性 :
直觉 : - 当
训练与 VDN 相同 :用全局 TD 误差更新所有参数。
性能 :QMIX 在 StarCraft 多智能体挑战(SMAC)上大幅超越
VDN,因为它能捕捉非线性协调模式。
QTRAN:更一般的分解
QMIX
的局限 :单调性约束仍然限制了表达能力。例如,如果最优联合动作需要某个智能体
QTRAN (2019)提出更一般的分解,不要求单调性,而是用额外的网络强制
IGM 条件:
其中
这通过两个额外损失实现:
最优动作损失 :
次优动作惩罚 :效果 :QTRAN
在某些需要复杂协调的任务上超越 QMIX,但训练不稳定且计算昂贵。
QPLEX:Duplex Dueling 架构
QPLEX (2021)结合 Dueling 架构,将
并通过变换层保持单调性。这提升了样本效率和稳定性。
多智能体 Actor-Critic 方法
MADDPG:多智能体 DDPG
MADDPG (Multi-Agent DDPG, 2017)将 DDPG
扩展到多智能体,采用 CTDE 范式:
训练阶段 : - 每个智能体更新规则 :
Critic 更新(类似 DDPG):
其中
Actor 更新(策略梯度):
执行阶段 :每个智能体只用自己的 Actor
优点 : - 适用于连续动作空间 - 每个智能体的 Critic
建模了其他智能体的策略
挑战 : - 需要通信或假设可以观测其他智能体的动作 -
当智能体数量
COMA:Counterfactual
Multi-Agent Policy Gradients
COMA (2018)用反事实基线 解决信用分配:
核心思想 :智能体
后一项是反事实基线 ——如果智能体
直觉 :
网络架构 : - 集中 Critic:实现细节 : - Critic 需要评估性能 :COMA
在需要精细信用分配的任务(如星际争霸微操)上表现优异。
MAPPO:多智能体 PPO
MAPPO 是 PPO
在多智能体的直接扩展,结合价值分解(如用一个共享 Critic)。 DeepMind 在
2021 年的研究表明,精心调参的 MAPPO 可以在许多任务上匹敌
QMIX/MADDPG,且训练更稳定。
关键技巧 : - 集中价值函数
AlphaStar:星际争霸中的多智能体
RL
任务挑战
星际争霸 II 是极其复杂的多智能体任务: -
状态空间 :动作空间 :每步可选择上百个单位,对每个单位选择上百种动作
- 部分可观测 :战争迷雾隐藏未探索区域 -
长期规划 :一局游戏平均 20 分钟(约 3 万步) -
多智能体协调 :控制几十到上百个作战单位
AlphaStar 的架构
AlphaStar(2019)结合了多种技术:
1. 策略网络 : -
输入 :空间特征(地图、单位位置)+ 标量特征(资源、人口) -
编码器 :ResNet 处理空间特征,MLP 处理标量特征,Transformer
整合 - 核心 :LSTM 维持长期记忆(隐藏状态输出 :分层动作选择
- 选择哪个单位(或单位组) - 选择什么动作类型(移动/攻击/建造...) -
选择目标位置或单位
2. 价值网络 :估计胜率3. 训练流程 : -
监督学习 :从人类 replay 学习模仿策略(如 AlphaGo) -
强化学习 :通过自我对弈优化 - 策略梯度:V-trace
算法(off-policy 修正) - 对手池:维护历史策略,防止循环(类似石头剪刀布) -
League 训练 : - 主要智能体(Main Agents):持续学习 -
主要利用者(Main Exploiters):专门找主要智能体的弱点 - 联盟利用者(League
Exploiters):对付整个对手池
4. 多智能体控制 : -
每个作战单位是一个"智能体",共享策略网络 -
用注意力机制(Transformer)聚合所有单位的表示 - 用指针网络(Pointer
Network)选择目标单位
性能与影响
AlphaStar 在 2019 年 1 月达到大师级 (排名前
0.2%),随后在与人类职业选手的表演赛中 10:1 获胜。 2019 年 10 月,AlphaStar
的最终版本在公开天梯达到宗师级 (前 0.15%)。
关键创新 : - League
训练 解决了策略多样性——避免过拟合到单一策略 -
分层动作空间 将长期记忆 (LSTM)使智能体能追踪几分钟前的侦察信息
局限 : - 需要巨大算力(16 个 TPU 训练 14 天) -
固定种族(只训练特定种族对战) - APM
限制(每分钟操作数)仍高于人类平均水平
完整代码实现:QMIX 协作任务
下面实现一个简化版 QMIX,在多智能体粒子环境(Multi-Agent Particle
Environment)的协作导航任务中训练。任务:3 个智能体需要覆盖 3
个地标,每个智能体只能看到局部信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 import torchimport torch.nn as nnimport torch.optim as optimimport numpy as npfrom collections import dequeimport randomclass CooperativeNavigation : """3 个智能体协作覆盖 3 个地标""" def __init__ (self, n_agents=3 , n_landmarks=3 , world_size=2.0 ): self.n_agents = n_agents self.n_landmarks = n_landmarks self.world_size = world_size self.reset() def reset (self ): self.agent_pos = np.random.uniform(-self.world_size, self.world_size, (self.n_agents, 2 )) self.landmark_pos = np.random.uniform(-self.world_size, self.world_size, (self.n_landmarks, 2 )) self.t = 0 return self._get_obs() def _get_obs (self ): """每个智能体的局部观测:自己位置+所有地标的相对位置""" obs = [] for i in range (self.n_agents): agent_obs = np.concatenate([ self.agent_pos[i], (self.landmark_pos - self.agent_pos[i]).flatten() ]) obs.append(agent_obs) return obs def _get_state (self ): """全局状态:所有智能体和地标的绝对位置""" return np.concatenate([ self.agent_pos.flatten(), self.landmark_pos.flatten() ]) def step (self, actions ): """ actions: list of [dx, dy] for each agent """ for i, action in enumerate (actions): velocity = np.clip(action, -0.1 , 0.1 ) self.agent_pos[i] += velocity self.agent_pos[i] = np.clip(self.agent_pos[i], -self.world_size, self.world_size) reward = 0 for landmark in self.landmark_pos: min_dist = min (np.linalg.norm(agent - landmark) for agent in self.agent_pos) reward -= min_dist self.t += 1 done = self.t >= 25 return self._get_obs(), reward, done, self._get_state() class AgentNetwork (nn.Module): """每个智能体的 Q 网络""" def __init__ (self, obs_dim, n_actions, hidden_dim=64 ): super ().__init__() self.fc1 = nn.Linear(obs_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, n_actions) def forward (self, obs ): x = torch.relu(self.fc1(obs)) x = torch.relu(self.fc2(x)) q = self.fc3(x) return q class QMixerNetwork (nn.Module): """混合各智能体的 Q 值""" def __init__ (self, n_agents, state_dim, hidden_dim=32 ): super ().__init__() self.n_agents = n_agents self.hyper_w1 = nn.Sequential( nn.Linear(state_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, n_agents * hidden_dim) ) self.hyper_b1 = nn.Linear(state_dim, hidden_dim) self.hyper_w2 = nn.Sequential( nn.Linear(state_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim) ) self.hyper_b2 = nn.Sequential( nn.Linear(state_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, 1 ) ) def forward (self, agent_qs, state ): """ agent_qs: (batch, n_agents) - 各智能体选择的 Q 值 state: (batch, state_dim) 返回: (batch, 1) - 混合的全局 Q 值 """ batch_size = agent_qs.size(0 ) w1 = torch.abs (self.hyper_w1(state)) w1 = w1.view(batch_size, self.n_agents, -1 ) b1 = self.hyper_b1(state).unsqueeze(1 ) agent_qs = agent_qs.unsqueeze(2 ) hidden = torch.relu((w1 * agent_qs).sum (dim=1 ) + b1.squeeze(1 )) w2 = torch.abs (self.hyper_w2(state)).unsqueeze(1 ) b2 = self.hyper_b2(state) q_tot = (w2 * hidden.unsqueeze(1 )).sum (dim=2 ) + b2 return q_tot class QMIXAgent : def __init__ (self, n_agents, obs_dim, n_actions, state_dim, lr=5e-4 , gamma=0.99 , buffer_size=5000 , batch_size=32 ): self.n_agents = n_agents self.n_actions = n_actions self.gamma = gamma self.batch_size = batch_size self.agent_nets = [AgentNetwork(obs_dim, n_actions) for _ in range (n_agents)] self.target_agent_nets = [AgentNetwork(obs_dim, n_actions) for _ in range (n_agents)] self.mixer = QMixerNetwork(n_agents, state_dim) self.target_mixer = QMixerNetwork(n_agents, state_dim) for target_net, net in zip (self.target_agent_nets, self.agent_nets): target_net.load_state_dict(net.state_dict()) self.target_mixer.load_state_dict(self.mixer.state_dict()) params = [] for net in self.agent_nets: params += list (net.parameters()) params += list (self.mixer.parameters()) self.optimizer = optim.Adam(params, lr=lr) self.replay_buffer = deque(maxlen=buffer_size) self.epsilon = 1.0 self.epsilon_decay = 0.995 self.epsilon_min = 0.05 def select_actions (self, obs, explore=True ): """选择动作(epsilon-greedy)""" actions = [] for i, o in enumerate (obs): if explore and random.random() < self.epsilon: action_id = random.randint(0 , self.n_actions - 1 ) else : with torch.no_grad(): o_tensor = torch.FloatTensor(o).unsqueeze(0 ) q_values = self.agent_nets[i](o_tensor) action_id = q_values.argmax(dim=1 ).item() action = self._id_to_action(action_id) actions.append(action) return actions def _id_to_action (self, action_id ): """离散动作 ID -> 连续控制""" actions_map = { 0 : [0.0 , 0.0 ], 1 : [0.0 , 0.1 ], 2 : [0.0 , -0.1 ], 3 : [-0.1 , 0.0 ], 4 : [0.1 , 0.0 ] } return actions_map[action_id] def store_transition (self, obs, actions, reward, next_obs, done, state, next_state ): """存储经验""" action_ids = [self._action_to_id(a) for a in actions] self.replay_buffer.append((obs, action_ids, reward, next_obs, done, state, next_state)) def _action_to_id (self, action ): """连续控制 -> 离散动作 ID""" actions_map = { (0.0 , 0.0 ): 0 , (0.0 , 0.1 ): 1 , (0.0 , -0.1 ): 2 , (-0.1 , 0.0 ): 3 , (0.1 , 0.0 ): 4 } return actions_map[tuple (action)] def train (self ): """训练一步""" if len (self.replay_buffer) < self.batch_size: return None batch = random.sample(self.replay_buffer, self.batch_size) obs, actions, rewards, next_obs, dones, states, next_states = zip (*batch) obs_tensor = torch.FloatTensor(np.array(obs)) next_obs_tensor = torch.FloatTensor(np.array(next_obs)) actions_tensor = torch.LongTensor(actions) rewards_tensor = torch.FloatTensor(rewards).unsqueeze(1 ) dones_tensor = torch.FloatTensor(dones).unsqueeze(1 ) states_tensor = torch.FloatTensor(states) next_states_tensor = torch.FloatTensor(next_states) chosen_action_qs = [] for i in range (self.n_agents): q_values = self.agent_nets[i](obs_tensor[:, i, :]) chosen_q = q_values.gather(1 , actions_tensor[:, i].unsqueeze(1 )) chosen_action_qs.append(chosen_q) chosen_action_qs = torch.cat(chosen_action_qs, dim=1 ) q_tot = self.mixer(chosen_action_qs, states_tensor) with torch.no_grad(): next_max_qs = [] for i in range (self.n_agents): next_q_values = self.target_agent_nets[i](next_obs_tensor[:, i, :]) next_max_q = next_q_values.max (dim=1 , keepdim=True )[0 ] next_max_qs.append(next_max_q) next_max_qs = torch.cat(next_max_qs, dim=1 ) target_q_tot = self.target_mixer(next_max_qs, next_states_tensor) target = rewards_tensor + self.gamma * target_q_tot * (1 - dones_tensor) loss = nn.MSELoss()(q_tot, target) self.optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(self.optimizer.param_groups[0 ]['params' ], 10.0 ) self.optimizer.step() return loss.item() def update_target_networks (self ): """软更新目标网络""" tau = 0.01 for target_net, net in zip (self.target_agent_nets, self.agent_nets): for target_param, param in zip (target_net.parameters(), net.parameters()): target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data) for target_param, param in zip (self.target_mixer.parameters(), self.mixer.parameters()): target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data) def decay_epsilon (self ): """衰减探索率""" self.epsilon = max (self.epsilon_min, self.epsilon * self.epsilon_decay) def train_qmix (n_episodes=2000 ): env = CooperativeNavigation(n_agents=3 , n_landmarks=3 ) obs_dim = 8 n_actions = 5 state_dim = 12 agent = QMIXAgent(n_agents=3 , obs_dim=obs_dim, n_actions=n_actions, state_dim=state_dim) episode_rewards = [] for episode in range (n_episodes): obs = env.reset() state = env._get_state() episode_reward = 0 for step in range (25 ): actions = agent.select_actions(obs, explore=True ) next_obs, reward, done, next_state = env.step(actions) agent.store_transition(obs, actions, reward, next_obs, done, state, next_state) loss = agent.train() obs = next_obs state = next_state episode_reward += reward if done: break if episode % 10 == 0 : agent.update_target_networks() agent.decay_epsilon() episode_rewards.append(episode_reward) if episode % 100 == 0 : avg_reward = np.mean(episode_rewards[-100 :]) print (f"Episode {episode} , Avg Reward: {avg_reward:.2 f} , Epsilon: {agent.epsilon:.3 f} " ) return agent, episode_rewards if __name__ == "__main__" : agent, rewards = train_qmix(n_episodes=2000 )
代码解析
环境部分 : - CooperativeNavigation:3
个智能体需要覆盖 3 个地标 - 局部观测
网络部分 : - AgentNetwork:每个智能体的 Q
网络,输入局部观测,输出 5 个动作的 Q 值 - QMixerNetwork:QMIX
混合网络 - 超网络从全局状态torch.abs保证权重为正(单调性约束)
训练部分 : -
select_actions:epsilon-greedy 选择动作,执行时只需局部观测 -
train: - 从 replay buffer 采样 batch - 计算各智能体的update_target_networks:软更新目标网络(tau=0.01)
运行示例 : - 训练 2000 个 episode 后,平均奖励从-15
提升到-3 左右 - 智能体学会了协作:分散到不同地标,而非都聚集在一个地标
深度问答
Q1: 为什么 QMIX
需要单调性约束?
直觉 :单调性
数学证明 :假设
反证法:假设存在
由单调性:
这与
为什么 VDN 天然满足单调性? :线性和
Q2: MADDPG 的
Critic 为什么要用其他智能体的动作?
非平稳性问题 :如果 Critic
MADDPG 的解决 :Critic 使用
Critic 建模了完整的环境动态,是平稳的
Actor
训练时,Actor 通过 Critic
的梯度学习"如何在给定其他智能体行为下做最优决策"
类比 :就像你在团队项目中,需要知道队友的能力(Critic
的输入)来规划自己的任务(Actor
的输出),但执行时只用自己的信息(分散执行)。
Q3: 为什么 COMA
的反事实基线能正确归因信用?
问题 :在全局奖励
COMA 的反事实基线 :
右边是"如果智能体
直觉 :
为什么叫"反事实"(Counterfactual)? :我们在问"如果智能体
Q4:
多智能体系统什么时候会陷入次优均衡?
相对过拟合(Relative
Overgeneralization) 的典型例子:
最优联合动作:
次优联合动作:
不协调:
训练过程 :
初期,智能体 1 随机探索,先学会
智能体 2 观察到智能体 1 倾向陷 入
根本原因 : -
探索不足 :没有足够样本观测到信息不对称 :智能体不知道队友的 Q
函数,只能通过观测队友的动作推断
解决方案 : - 联合探索 :如
epsilon-greedy 应用于联合动作 - 通信 :智能体共享 Q
值或意图 - 对手建模 :学习其他智能体的策略模型
Q5: 多智能体 RL
的样本复杂度如何随智能体数量缩放?
理论结果 (非正式): -
独立学习 :样本复杂度集中学习 :样本复杂度值分解(如
QMIX) :在某些结构化任务中,关键假设 :值分解方法假设全局 Q
函数可以近似分解,这在许多协作任务中成立(如每个智能体负责局部子目标)。
实验观察 : - SMAC(星际争霸微操)中,3 个智能体 vs 3
个敌人,QMIX 训练 200 万步收敛 - 5 个智能体 vs 5 个敌人,需要 500 万步 -
10 个智能体 vs 10 个敌人,需要 2000 万步——接近线性增长
Q6:
如何在多智能体中处理部分可观测性?
方法 1:记忆(RNN/LSTM) - 每个智能体维护隐藏状态
方法 2:通信 - 智能体之间传递消息
方法 3:集中式状态估计 - 训练阶段,用全局状态
实例 :在星际争霸中,你看不到战争迷雾后的敌军。 LSTM
记住了"5 分钟前侦察兵在左上角看到敌人的兵营",推断"现在敌人可能有 10
个士兵"。
Q7: AlphaStar 的 League
训练为什么有效?
问题 :纯自我对弈在复杂游戏中可能陷入循环 ——类似石头剪刀布,策略
A 打败 B,B 打败 C,C 打败 A,没有全局最优。
League 训练的设计 :
Main
Agents :持续学习的主要智能体,与对手池中的所有对手对弈Main Exploiters :专门找 Main Agents 的弱点,防止 Main
Agents 陷入局部策略League
Exploiters :对付整个对手池的平均水平,保证多样性
类比 : - Main Agents 像职业选手,与各种对手比赛 - Main
Exploiters 像陪练,专门针对职业选手的弱点设计战术 - League Exploiters
像业余高手,保持策略池的多样性
数学上 :League 训练近似求解多智能体 Nash
均衡,通过维护策略分布
Q8: 多智能体 RL
在现实中的应用有哪些限制?
安全性 : - 自动驾驶中,多车协调的失败可能导致事故 - RL
的探索可能产生危险行为(如闯红灯) - 需要约束优化或 safe RL 技术
通信延迟与部分失效 : - 真实网络中,通信有延迟和丢包 -
智能体可能掉线或传感器失效 - 需要鲁棒性设计(如冗余、降级策略)
异构性 : - 真实系统中,智能体能力不同(如无人机 vs
地面车辆) - 目标可能冲突(如企业间竞争) - 需要更复杂的博弈论模型
可解释性 : - 人类操作员难以理解多智能体的联合决策 -
"为什么无人机 A 去了左边而 B 去了右边?" - 需要可视化和自然语言解释
Q9:
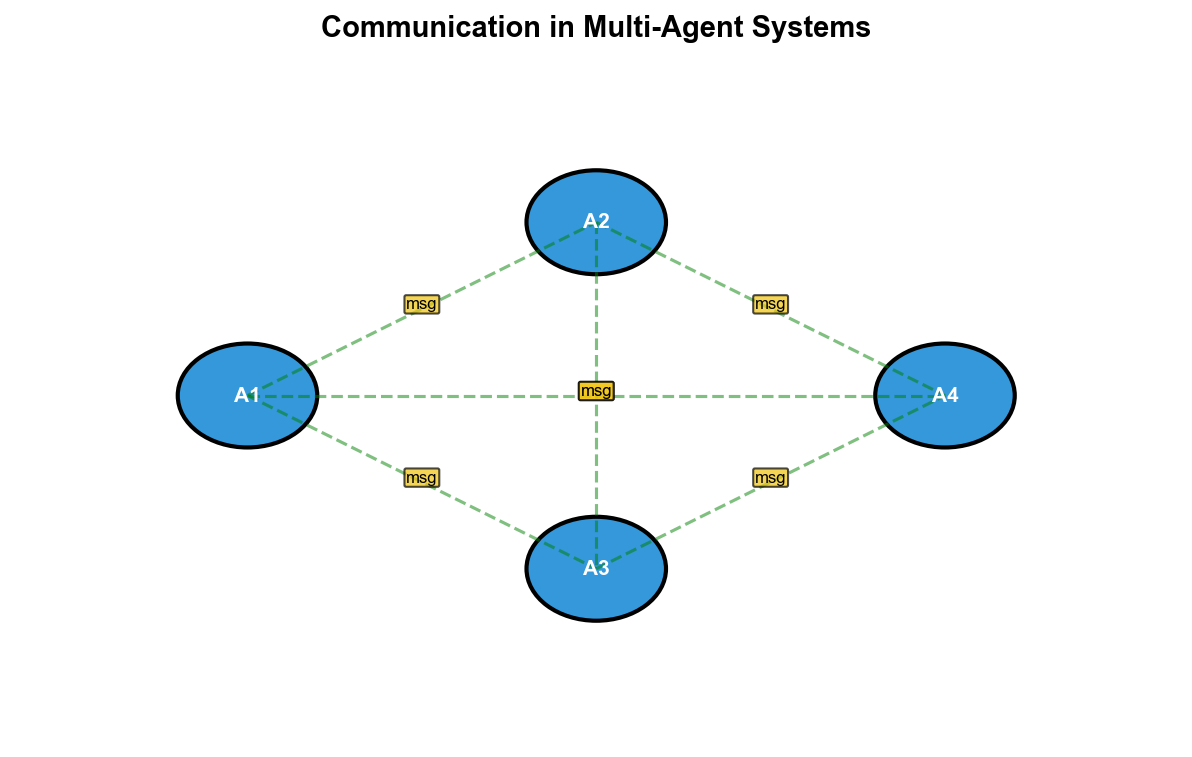
如何在多智能体系统中实现通信学习?
CommNet (2016)架构: - 每个智能体TarMAC (2018)架构: - 每个智能体生成消息挑战 : - 符号基础(Symbol
Grounding) :智能体发明的"语言"(向量带宽限制 :真实系统中通信有代价,需要学习"何时说"和"说什么"
- 对抗鲁棒性 :通信可能被窃听或干扰
Q10: 多智能体 RL
的未来方向是什么?
1. 大规模协作 : - 当前:几十个智能体(如 AlphaStar 的
200 单位) - 目标:数千智能体(如交通网络、电网) -
需要:层次化控制、图神经网络、分布式优化
2. 人机协作 : - 当前:AI 与 AI 对弈 - 目标:AI
与人类队友协作(如辅助驾驶、医疗诊断) -
需要:建模人类意图、可解释决策、适应人类习惯
3. 开放式环境 : - 当前:固定规则的游戏(如星际争霸) -
目标:真实世界(如灾难救援、科学探索) -
需要:迁移学习、元学习、终身学习
4. 理论保证 : - 当前:经验上的成功 -
目标:收敛性、样本复杂度、 Nash 均衡计算的理论 -
需要:博弈论、优化理论、学习理论的深度结合
相关论文与资源
核心论文
VDN :https://arxiv.org/abs/1706.05296
QMIX :https://arxiv.org/abs/1803.11485
MADDPG :https://arxiv.org/abs/1706.02275
COMA :https://arxiv.org/abs/1705.08926
AlphaStar :https://www.nature.com/articles/s41586-019-1724-z
QTRAN :https://arxiv.org/abs/1905.05408
CommNet :https://arxiv.org/abs/1605.07736
MAPPO :https://arxiv.org/abs/2103.01955
基准测试
开源实现
总结
多智能体强化学习将 RL
的挑战提升到了新的维度——智能体不仅要学习环境动态,还要理解、预测、协调其他智能体的行为。从博弈论的
Nash 均衡到值分解的 QMIX,从 MADDPG 的集中训练分散执行到 AlphaStar 的
League 训练,MARL 的方法论展现了丰富的创造性。
值分解方法 (VDN/QMIX/QTRAN)通过分解全局 Q
函数,在保持分散执行的同时利用集中训练,适用于协作任务。
多智能体 Actor-Critic (MADDPG/COMA)用 Critic
建模其他智能体的影响,缓解非平稳性,并通过反事实基线精确归因信用。
AlphaStar 的成功展示了 MARL
在超复杂环境中的潜力——通过 League
训练、分层动作空间、长期记忆,智能体达到了人类顶尖水平。
未来的 MARL
将走向更大规模(数千智能体)、更真实(人机协作、开放环境)、更可靠(理论保证、安全约束)的应用。从自动驾驶车队到智能电网,从机器人协作到在线广告竞价,MARL
正在成为解决复杂多主体系统的关键技术。